读扩散、写扩散(推拉模式)详解以及混合模式
引言
在现代社交媒体和内容平台中,Feed流(时间线)是用户体验的核心。用户都期望能够快速、准确地获取到他们关注的内容。无论是微博、Twitter、抖音还是朋友圈,用户都期望能够快速、准确地获取到他们关注的内容。然而,当用户规模和帖子数量达到一定量级,如何设计一个高性能、可扩展的Feed系统就成为了一个极具挑战性的技术问题。
1. 基本概念
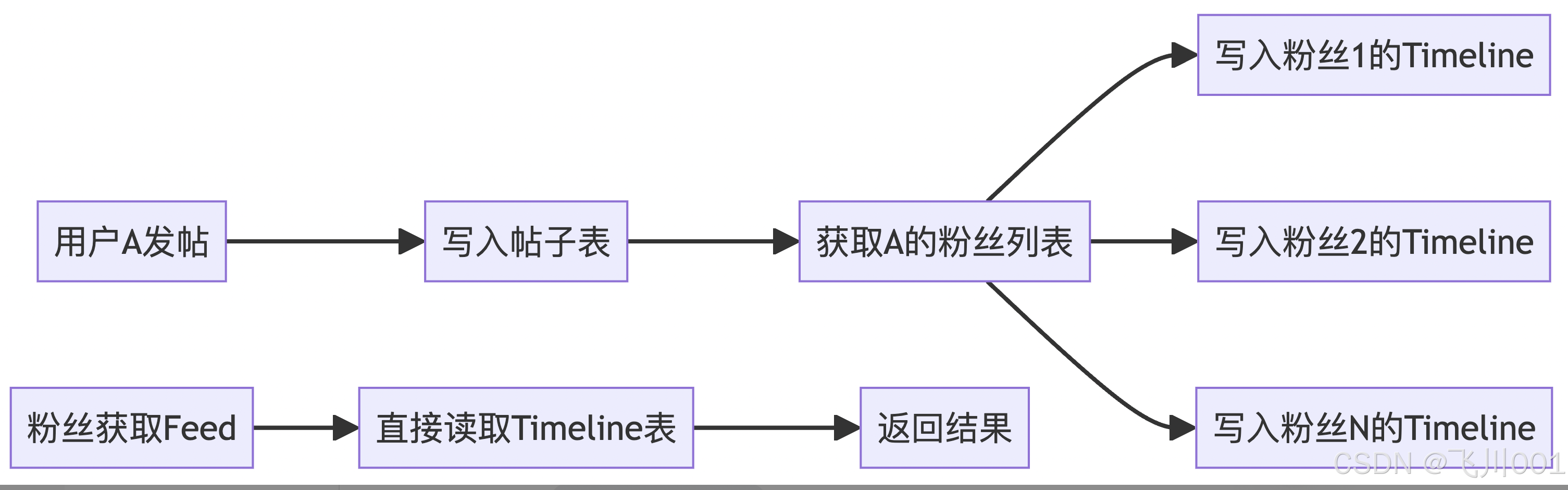
写扩散(推模式 - Push Model)
- 定义:数据在写入时就主动推送给所有相关的接收者
- 特点:写时复杂,读时简单
- 实现方式:当有新内容产生时,立即将内容推送到所有关注者的收件箱
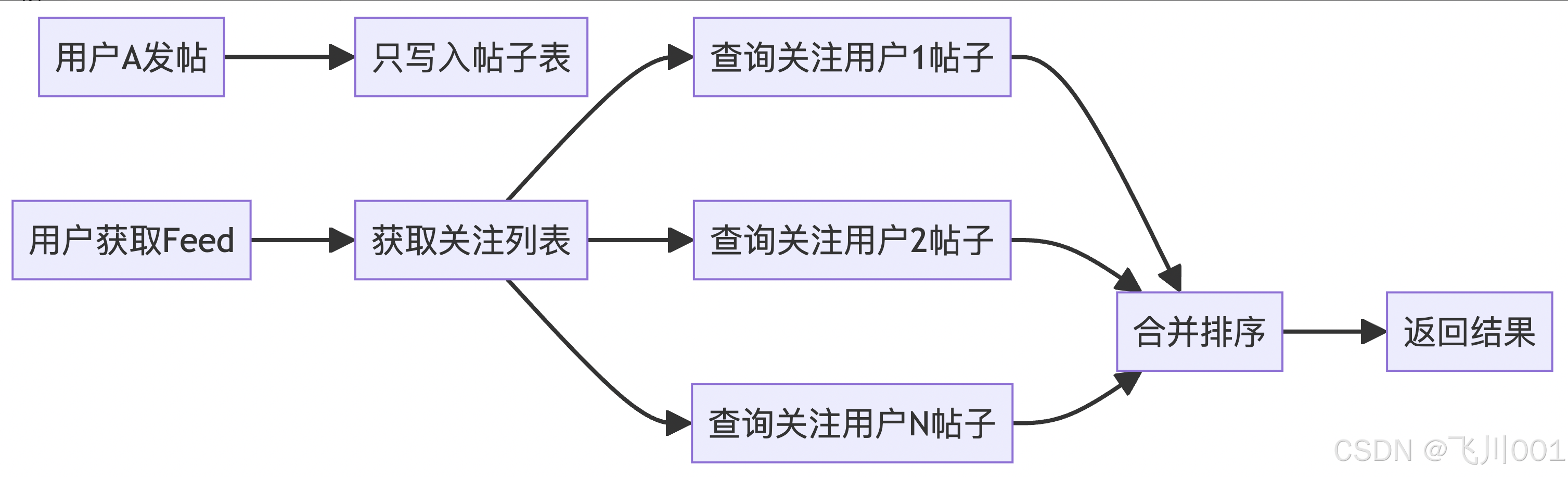
读扩散(拉模式 - Pull Model)
- 定义:数据写入时只存储在源头,读取时才去主动拉取
- 特点:写时简单,读时复杂
- 实现方式:用户请求时才去各个关注对象那里拉取最新内容
2. 详细对比分析
写扩散(推模式)
优点:
- 读取速度快:用户timeline已预计算完成
- 实时性好:内容发布后立即推送给粉丝
- 读取压力分散:避免读取时的计算压力
缺点:
- 写入成本高:需要写入到所有粉丝的timeline
- 存储成本高:每个用户都需要存储timeline数据
- 扩展性差:大V发布内容时需要推送给大量粉丝
读扩散(拉模式)
优点:
- 写入成本低:只需要存储到作者的发件箱
- 存储成本低:避免数据冗余
- 扩展性好:不受粉丝数量影响
缺点:
- 读取延迟高:需要实时计算和聚合
- 系统压力大:每次读取都需要计算
- 实现复杂:需要复杂的排序和去重逻辑
推拉模式的判断逻辑
这是最容易混淆的地方,关键是要理解发帖阶段和读取阶段的判断维度不同 :
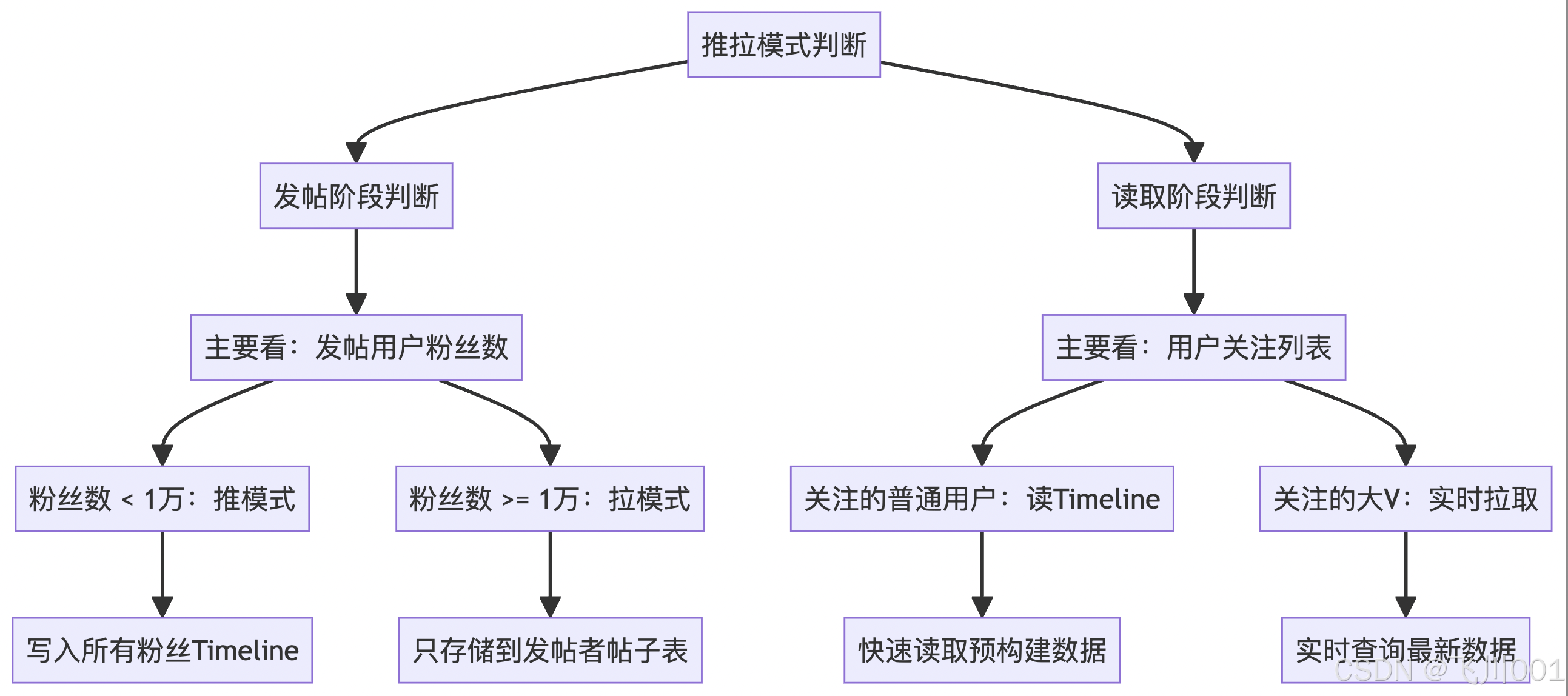
注:这里也有许多细节问题是需要思考解决的,例如:
- 哪些用户可以定义为大V,用户量级较大的时候,如何快速判定是否为大V
- 对于关注量很大的用户,又是如何解决
- 一些优化的边界处理
3. 适用场景分析(以Feed流为例)
注:读写扩散应用场景较多,不仅仅是feed流中使用,群聊消息也会用到(普通群聊、超级大群)
写扩散适用场景:
- 普通用户:粉丝数量适中(<1000)
- 活跃用户较多:读多写少的场景
- 实时性要求高:如即时通讯、实时通知
- 计算资源充足:可承担预计算成本
读扩散适用场景:
- 大V用户:粉丝数量巨大(>10万)
- 发布频率高:写多读少的场景
- 存储成本敏感:避免大量数据冗余
- 用户活跃度低:很多用户不经常查看
4. 在Feed系统中的应用
4.1 社交媒体Timeline
大多数社交模式:
写扩散:普通用户发布 → 推送给所有粉丝timeline
读扩散:大V发布 → 用户请求时实时拉取大V内容
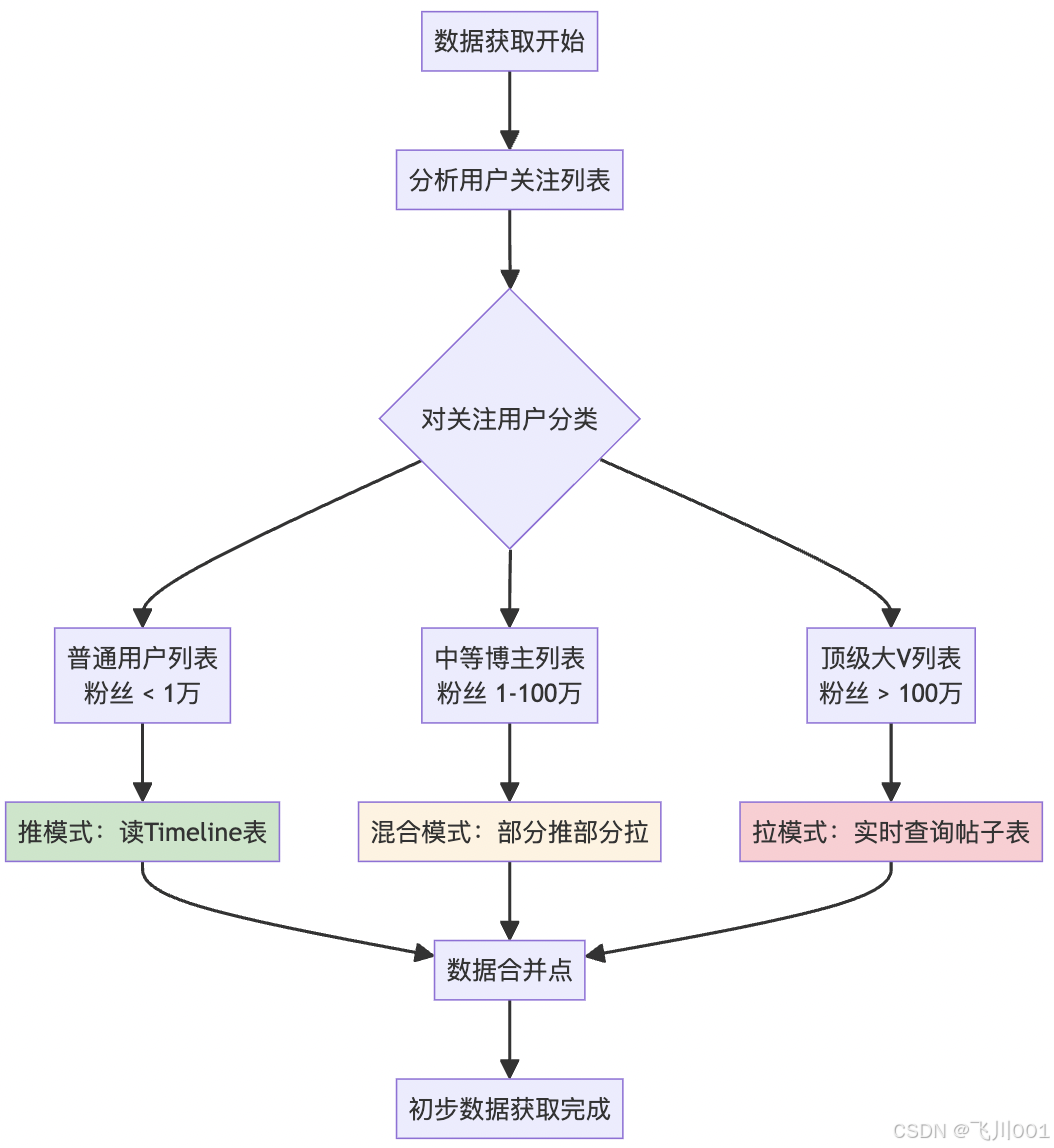
混合模式:根据用户等级动态选择策略4.2 具体实现策略
分层处理:
- 0-1000粉丝:纯写扩散
- 1000-10万粉丝:混合模式
- 10万+粉丝:纯读扩散
时间窗口优化:
- 热点内容:写扩散
- 历史内容:读扩散
4.3 混合模式分发策略
if (用户粉丝数 < 阈值1) {
使用写扩散
} else if (用户粉丝数 < 阈值2) {
活跃粉丝使用写扩散
非活跃粉丝使用读扩散
} else {
使用读扩散
}缓存优化
- 写扩散缓存:Redis存储用户timeline
- 读扩散缓存:缓存热点用户的最新内容
- 多级缓存:L1本地缓存 + L2分布式缓存
5. 关键问题深度分析
5.1 关注爆炸问题
问题场景:
某些用户关注了数万人,如何高效获取和处理这些关注关系?
问题解决:
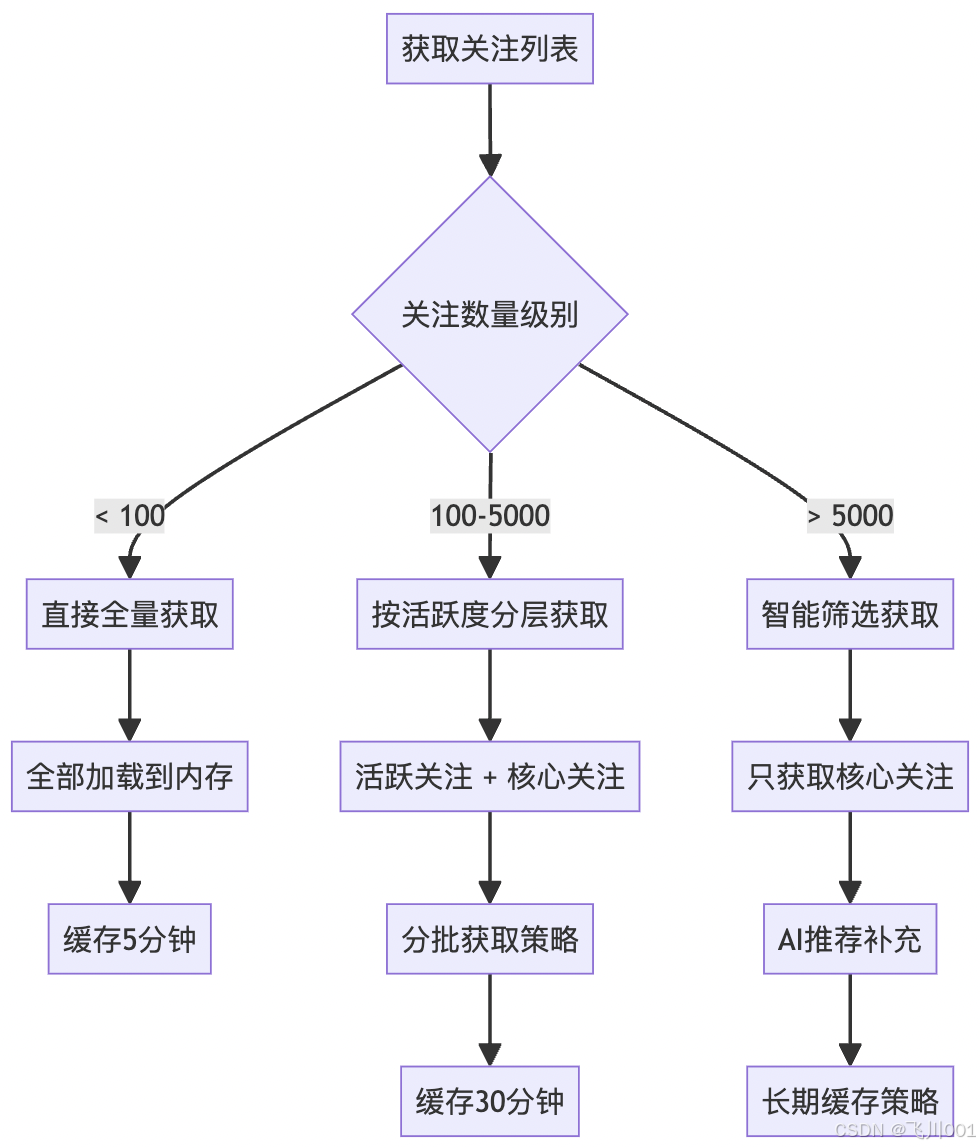
解决策略:
- 分层获取:优先获取活跃用户的内容
- 智能筛选:基于互动频率筛选核心关注
- 缓存策略:不同层级使用不同的缓存时长
- 异步补充:后台异步加载长尾内容
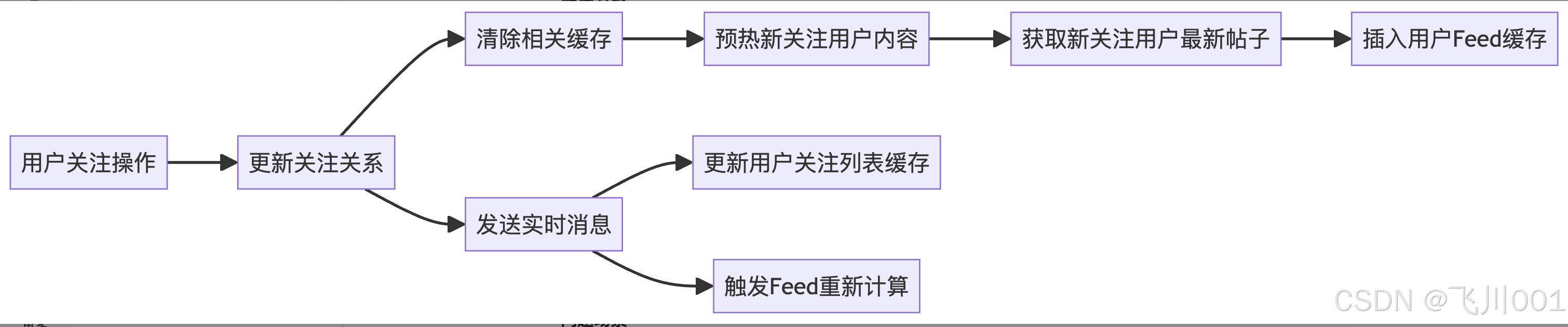
5.2 关注关系变更的实时性
问题描述:
用户新关注某人后,希望立即在Feed中看到对方的内容。
问题解决:
5.3 N+1查询问题解决
问题场景:
用户关注100人,采用拉模式时需要101次查询(1次获取关注列表 + 100次获取各用户帖子)。
批量优化方案:
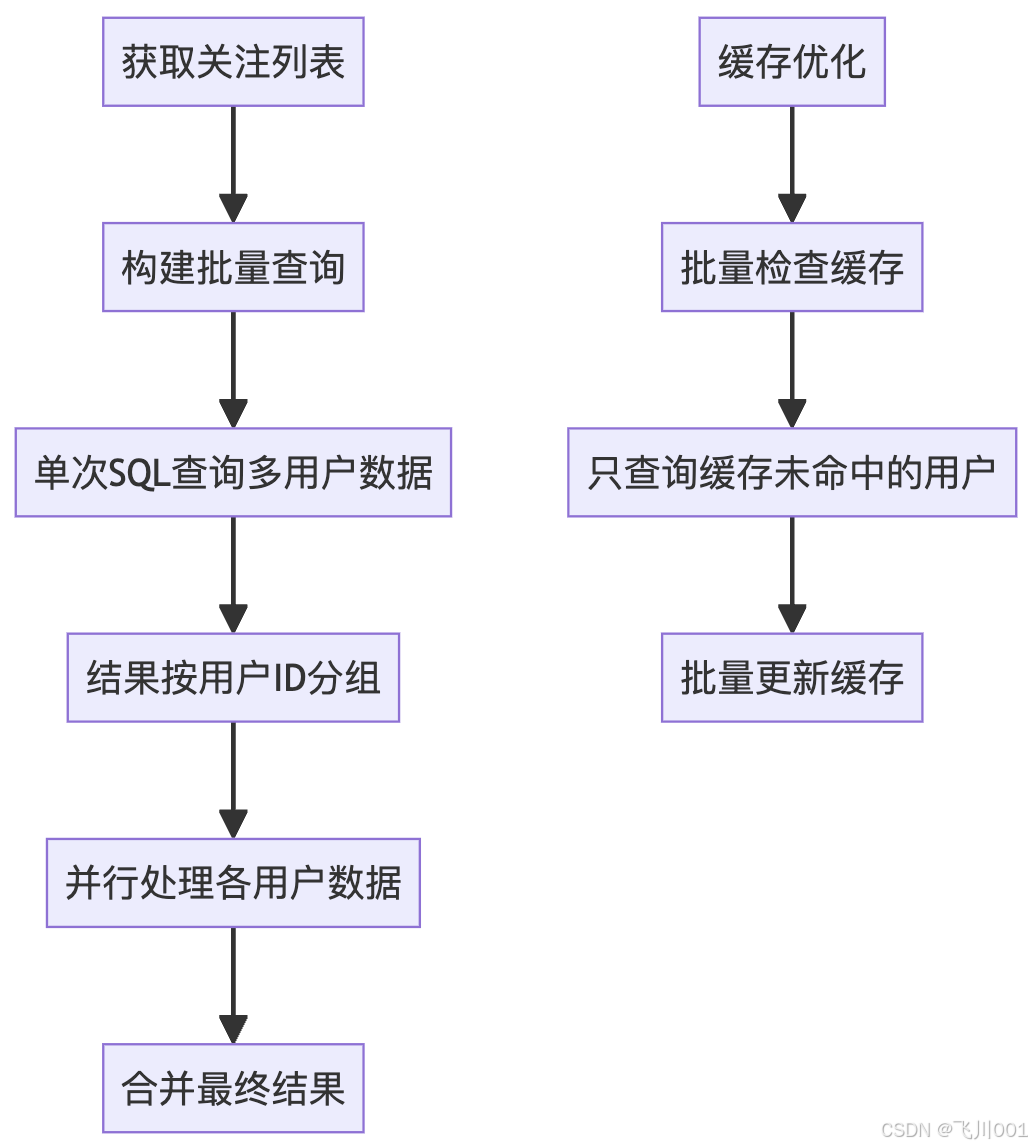
5.4 热点数据缓存策略
问题描述:
大V用户的帖子被大量用户重复查询,造成数据库压力。
多级缓存方案:
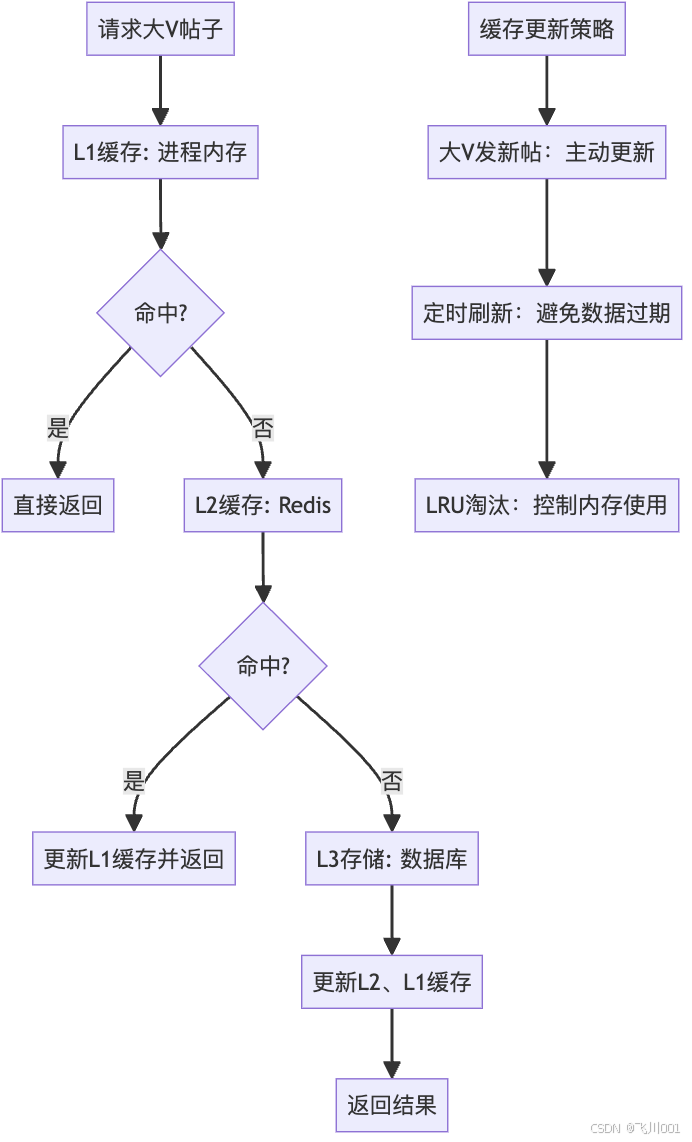
注:这篇文章描述了推拉结合模式的基本设计和实现,如果有些地方有不同看法或者想法的可以一起交流。