大家好!今天我们继续讲解 LeetCode 热题 100 系列,第二题聚焦高频中等题 "字母异位词分组"。这道题是哈希表的经典应用场景,核心考查对 "字符共性提取" 与 "键值对映射" 的理解。接下来,我们从题目分析、思路推导到 Java 代码实现,逐步拆解这道题。
一、题目描述
首先明确题目要求(基于 LeetCode 官方原题):
- 给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。
- 字母异位词指的是:由相同字母按照不同顺序组成的字符串(例如 "eat" 和 "tea",二者包含的字母及数量完全一致,仅顺序不同)。
示例
输入:strs = "eat","tea","tan","ate","nat","bat"
输出:\["bat","nat","tan","ate","eat","tea"]
解释:"bat" 无其他异位词,单独成组;"tan" 和 "nat" 是一组,"eat""tea""ate" 是另一组。
提示
- 1 <= strs.length <= 10⁴(数组长度可能较大,需考虑效率)
- 0 <= strs i.length <= 100(字符串可能为空,需特殊处理)
- strs i 仅包含小写英文字母(无需考虑大小写或特殊字符)
二、解题思路分析
要解决 "分组" 问题,核心是找到字母异位词的 "共同标识" ------ 即让同一组异位词映射到同一个 "键",不同组映射到不同 "键",再用哈希表将 "键" 与 "对应的字符串列表" 关联,最终输出所有列表。
关键:如何定义 "共同标识"?
字母异位词的本质是 "字符种类和数量完全相同",基于这一特性,有两种常见的标识生成方式:
1. 方式一:排序法(推荐,代码简洁)
- 逻辑:对每个字符串的字符进行排序,排序后相同的字符串即为异位词。
例如:"eat" → 排序后为 "aet","tea" → 排序后也为 "aet",因此二者会映射到同一键 "aet"。
- 优势:代码实现简单,借助 Java 自带的排序函数即可完成,无需手动统计字符。
- 注意:空字符串排序后仍为空字符串,可正常处理。
2. 方式二:计数法(进阶,效率更高)
- 逻辑:统计每个字符串中 26 个小写字母的出现次数,用 "计数数组" 作为标识(可转化为字符串,如 "1,0,0,...1" 表示 a 出现 1 次、z 出现 1 次)。
例如:"eat" 中 a:1、e:1、t:1,计数数组转化为 "1,1,0,...0,1"(共 26 个元素),"tea" 的计数数组完全相同,因此同组。
- 优势:排序的时间复杂度是 O (k log k)(k 为字符串长度),而计数法是 O (k),对于长字符串场景效率更高。
- 注意:需处理空字符串(计数数组全为 0,转化后为 26 个 0 组成的字符串)。
下面我们先以排序法展开讲解(代码更易理解,适合面试快速实现),后续补充计数法的 Java 代码。
三、代码实现(排序法,Java 版)
java
public static List<List<String>> groupAnagrams(String[] strs) {
Map<String,List<String>> map = new HashMap<>();
for (String str : strs){
// 1. 将字符串转为字符数组,便于排序
char[] a = str.toCharArray();
// 2. 对字符数组排序(核心:生成共同标识)
Arrays.sort(a);
// 3. 将排序后的字符数组转回字符串,作为哈希表的key
String key = new String(a);
// 4. 检查key是否在哈希表中:不存在则新建列表,存在则直接添加
if(!map.containsKey(key)) {
map.put(key,new ArrayList<>());
}
map.get(key).add(str);
}
// 5. 哈希表的value集合就是最终的分组结果
return new ArrayList<>(map.values());
}代码解析
- 哈希表初始化:用HashMap<String, List<String>>存储 "标识 - 分组列表" 的映射,key 是排序后的字符串,value 是同一组异位词的列表。
- 遍历字符串数组:对每个字符串str,先转为字符数组并排序,生成唯一标识key。
- 分组逻辑:若key不在哈希表中,新建列表存入;若已存在,直接将s加入对应列表。
- 返回结果:将哈希表的所有 value(即分组列表)转为ArrayList返回,符合题目要求。
四、代码实现(计数法,进阶 Java 版)
java
public static List<List<String>> groupAnagrams(String[] strs) {
Map<String, List<String>> map = new HashMap<>();
for (String s : strs) {
// 1. 初始化计数数组(26个小写字母,初始值0)
int[] count = new int[26];
// 2. 统计每个字符的出现次数:'a'-'a'=0,'b'-'a'=1,对应数组下标
for (char c : s.toCharArray()) {
count[c - 'a']++;
}
// 3. 将计数数组转为字符串作为key(加逗号避免歧义,如11和1,1)
StringBuilder keySb = new StringBuilder();
for (int num : count) {
keySb.append(num).append(',');
}
String key = keySb.toString();
// 4. 添加入哈希表:不存在key则新建列表,存在则直接添加
if (!map.containsKey(key)) {
map.put(key, new ArrayList<>());
}
map.get(key).add(s);
}
// 5. 返回所有分组列表
return new ArrayList<>(map.values());
}代码解析
- 计数数组:用长度为 26 的int数组统计每个小写字母的出现次数,数组下标对应字母(0→a,1→b,...,25→z)。
- 生成 key:通过StringBuilder将计数数组转为字符串(如计数数组1,1,0,...1转为"1,1,0,...,1"),加逗号可避免 "11"(表示某字母出现 11 次)与 "1,1"(表示两个字母各出现 1 次)的歧义。
- 分组逻辑:与排序法一致,通过哈希表关联key和分组列表,最终返回所有列表。
五、测试案例验证
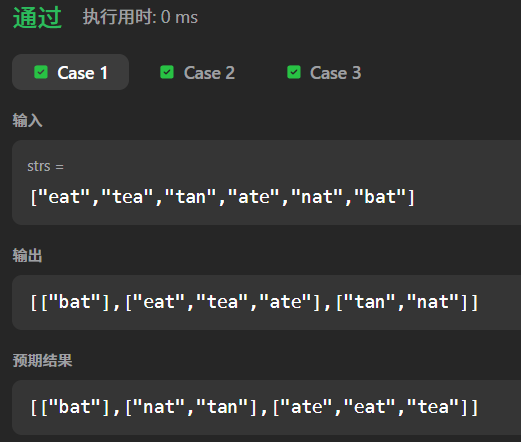
测试案例 1:基础示例
输入:"eat","tea","tan","ate","nat","bat"
排序法处理过程:
- "eat" → 排序后"aet",列表添加 "eat";
- "tea" → 排序后"aet",列表添加 "tea";
- "tan" → 排序后"ant",列表添加 "tan";
- "ate" → 排序后"aet",列表添加 "ate";
- "nat" → 排序后"ant",列表添加 "nat";
- "bat" → 排序后"abt",列表添加 "bat";
输出:"bat"],\["eat","tea","ate","tan","nat"(顺序不影响,符合题目要求)。
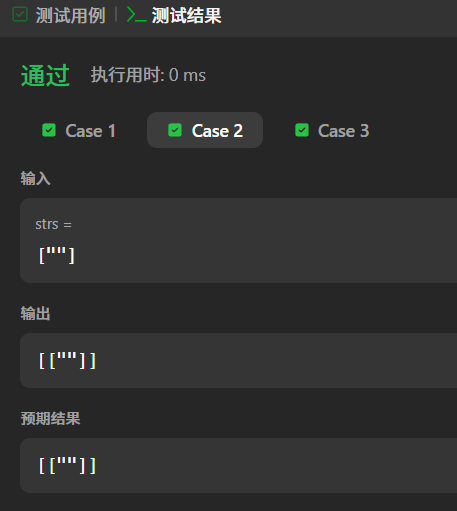
测试案例 2:含空字符串
输入:""
处理过程(以排序法为例):
- 空字符串排序后仍为空,key为"",列表添加空字符串;
输出:\[""]]
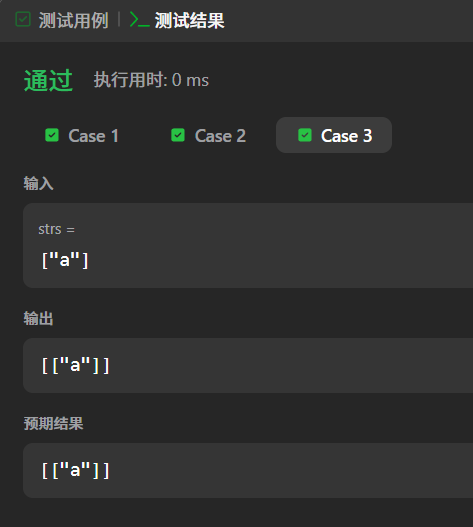
测试案例 3:单个字符
输入:"a"
输出:\["a"]
六、复杂度分析
排序法(Java 版)
- 时间复杂度:O (n * k log k)。n 是字符串数组长度,k 是字符串的平均长度;每个字符串转字符数组并排序耗时 O (k log k),遍历数组耗时 O (n),整体为 O (n * k log k)。
- 空间复杂度:O (n * k)。哈希表存储的所有字符串总长度为 O (n * k),排序过程中字符数组的临时空间可忽略(视为 O (1))。
计数法(Java 版)
- 时间复杂度:O (n * k)。统计每个字符串的字符计数耗时 O (k),遍历数组耗时 O (n),整体为线性时间,效率高于排序法。
- 空间复杂度:O (n * k)。哈希表存储的字符串总长度为 O (n * k),计数数组长度固定为 26(视为 O (1))。
七、总结
"字母异位词分组" 的核心是找到异位词的共同标识,再用哈希表实现 "标识→分组" 的映射,Java 实现的关键要点如下:
- 排序法代码简洁,借助Arrays.sort()即可快速生成标识,适合面试快速写题;
- 计数法效率更高,通过固定长度的计数数组生成标识,避免排序的对数时间开销,适合长字符串场景;
- 处理空字符串时,两种方法均无需额外判断(排序后为空,计数数组全为 0);
- 哈希表的 "键设计" 需确保 "同组同键、异组异键",计数法中加逗号可避免歧义。
下一篇我们会讲解 LeetCode 热题 100 的第3题最长连续序列,感兴趣的同学可以持续关注~如果有疑问,欢迎在评论区留言讨论!