之前了解到,Qwen3 Next 通过激活 80B 参数中的 3B 参数,即可实现接近 Qwen3-32B 的效果。
当时就很好奇,到底怎么实现的。
今天,我专门学习了下,一并分享给大家。

激活参数的通俗理解
我们设想一个场景:公司有 80 人,现在来了一个新项目,只需要 3 人即可处理。
Qwen3 Next 的思路就是:挑选 3 人响应这个项目,其他人待命 。而传统大模型则是不管项目需要,每次来项目都把 80 人叫上处理。
大家应该都了解,一个项目并不是人越多越好,当人员超出一定规模时,沟通成本、协调成本会随着人员的增加激增,进而造成项目效率低下。
而大模型中也是一样道理,3B 参数就能处理的任务,使用太大规模参数,只会造成推理成本和推理速度的无效增加。
Qwen3 Next 的激活率低至 3.75%,达到了行业最低。
这个思路其实还有更深的一个思考,3B 激活参数不一定正好达到最优效果,那能否实现动态激活参数?这个后续还得继续研究下。
为什么少参数能够实现大效果
上面的思路理解后,我又想到了下一个问题:为什么原有的稠密模型(3B)达不到激活参数(3B)的效果呢?
这是因为:激活的 3B 参数并不是固定的,而是随着任务不同,根据情况分配的。
80B 的参数池保证了模型知识的广度,动态路由则保证了计算效率 ,这样 Qwen3 Next 就能高效适配各种场景了。
为什么要研究这个方向
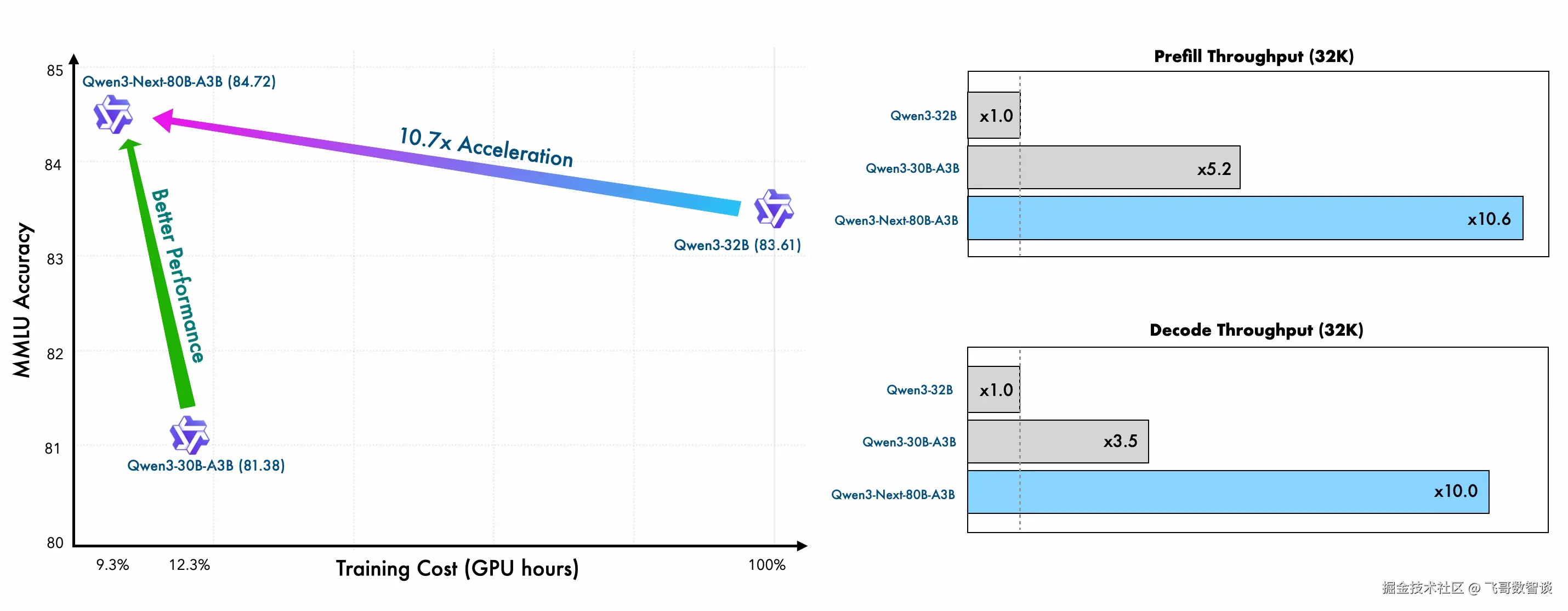
速度提升:每秒钟多处理10倍内容
- 解码速度:4K上下文下,每秒生成3.2个token(传统模型0.8个)
- 长文本优势:32K以上文本处理时,吞吐量提升10倍(从100 tokens/秒→1000 tokens/秒)
- 应用场景:实时代码助手响应延迟从2秒→0.5秒
成本暴跌:90%算力费用省下了
- 训练成本:仅需Qwen3-32B密集模型9.3%的GPU小时
- 推理成本:每千tokens费用从0.3元→0.18元(降低40%)
- 硬件门槛:单台4卡GPU服务器即可部署(传统模型需8卡A100)
结语
今天就分享这么多,希望可以帮助大家更好的理解"激活参数"类的模型。
假期快要结束了,好好享受最后的假期吧~