方法一
使用 texcount 命令
texcount -ch -total yanputhesis-sample.tex ,其中最后一个参数 .tex 替换为你的主 tex 文件
这里我通过这个方式统计的字数是 25428
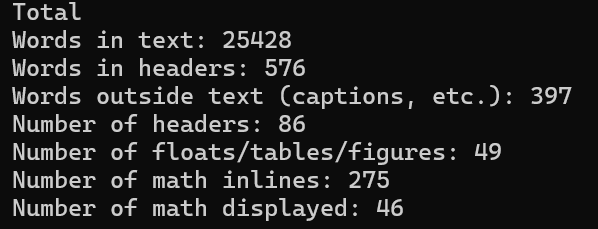
方法二
把 tex 全部复制到 Microsoft Word 里面,然后通过通配符来统计汉字字符数,
在 Microsoft Word 中,可以使用"查找(Find)+ 通配符"功能来统计汉字数量,方法如下:
✅ 使用通配符统计汉字数量(无需 VBA)
📌 步骤如下:
-
打开 Word 文档。
-
按下
Ctrl + H,打开"查找和替换"窗口。 -
切换到 "查找" 选项卡。
-
点击左下角的 "更多(More)" ,然后勾选 "使用通配符(Use wildcards)"。
-
在"查找内容"框中输入以下内容:
[一-龥]这表示匹配所有常用中文汉字(Unicode 范围 4E00 - 9FA5)。
-
点击 "阅读突出显示" → "全部突出显示"。
-
然后点击右侧的 "主文档中共找到 XX 处" ,这里的数字 即为汉字个数。
🔍 说明:
[一-龥]是匹配常用汉字的通配符范围(约2万个字符,涵盖简体与繁体常用字)。- 如果没有显示"共找到 XX 处",你可以点击"替换"→输入空字符→"全部替换"之前会弹出提示"替换了 XXX 处",同样可用来统计。
⚠️ 注意事项:
| 项目 | 是否统计 |
|---|---|
| 中文汉字 | ✅ 是 |
| 中文标点(,。?!) | ❌ 否 |
| 英文字母/数字 | ❌ 否 |
| 繁体字 | ✅ 是(大多数常用繁体字包含在 一-龥 范围内) |
| 冷僻字 | ❌ 可能不被包含,需使用 Unicode 范围扩展 [一-鿿](含扩展A区) |
✅ 扩展:统计所有中文字符(包括标点)的方法
如果你想统计包括中文标点的字符数量,也可以使用更广泛的 Unicode 范围匹配,比如:
[一-龥!-~]或使用:
[一-鿿](但 Word 的"通配符"功能对 Unicode 支持不完美,仅适用于常见字符)

这个方式我统计的汉字字符数是 22777 ,比方式一少了 2651 个。这里因为我在 Word 里删除了 tex 模板的内容,所以实际少的汉字数应该是更少的,可能实际少 1000 余字。