点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-31- 千呼万唤始出来 GPT-5 发布!"快的模型 + 深度思考模型 + 实时路由",持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年10月07日更新到: Java-141 深入浅出 MySQL Spring事务失效的常见场景与解决方案详解(3) MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解

章节内容
上节我们完成了如下的内容:
- Flink Sink JDBC
- Flink Sink Kafka

注意事项
DataSetAPI 和 DataStream API一样有三个部分组成,各部分的作用对应一致,此处不再赘述。
Flink DataSet API 详解
概述
Apache Flink 的 DataSet API 是 Flink 批处理的核心编程接口,专门设计用于处理静态的、有限的数据集。与流处理(DataStream API)不同,DataSet API 针对的是已经完整存在的数据集合,适合处理TB甚至PB级别的批量数据。
核心特性
- 批处理优化:DataSet API 采用延迟执行和优化策略,整个计算过程会在执行前经过优化器处理
- 内存管理:Flink 实现了自己的内存管理机制,可以高效处理大规模数据集
- 丰富的算子:提供map、filter、join、groupBy、reduce等丰富的转换操作
- 容错机制:基于检查点(checkpoint)的容错机制确保作业可靠性
典型应用场景
-
ETL(抽取-转换-加载)
- 从关系型数据库抽取数据
- 进行数据清洗和转换
- 加载到数据仓库或分析系统
-
批量数据分析
- 执行复杂的聚合计算
- 生成报表和统计分析
- 大规模图计算
-
机器学习预处理
- 特征工程
- 数据集准备
- 模型评估
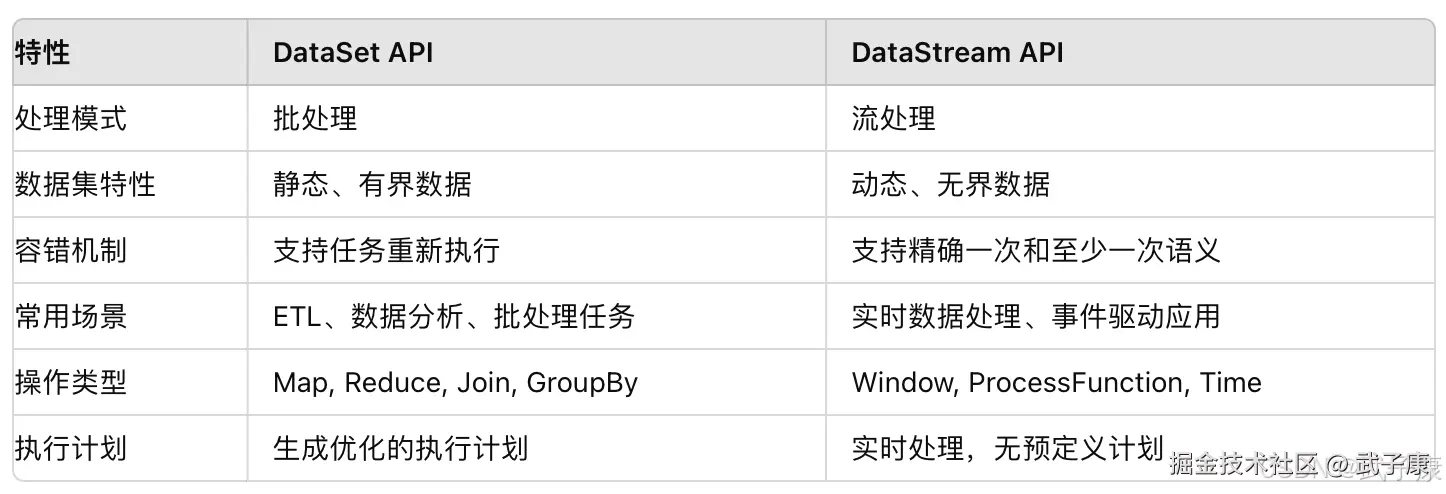
与DataStream API对比
| 特性 | DataSet API | DataStream API |
|---|---|---|
| 数据处理模型 | 批处理 | 流处理 |
| 数据边界 | 有界数据 | 无界数据 |
| 执行模式 | 一次性执行 | 持续执行 |
| 典型延迟 | 分钟到小时级 | 毫秒到秒级 |
| 主要应用 | 离线分析 | 实时处理 |
发展趋势
虽然近年来Flink社区更关注流处理的发展,但批处理仍然在以下场景中保持优势:
- 历史数据分析:需要处理完整历史数据集时
- 高精度计算:要求精确结果的场景
- 资源密集型任务:需要高效利用集群资源的计算任务
Flink社区正在通过批流一体的方式,将DataSet API的某些特性整合到DataStream API中,以实现更统一的编程模型。
DataSource
在Flink的DataSet批处理API中,DataSource是数据输入的起点,负责从各种外部系统或内存中读取数据。其中,从HDFS文件系统读取数据是最常见的使用场景,因为批处理作业通常需要处理存储在分布式文件系统中的大规模数据集。
主要DataSource组件
1. 基于集合的DataSource
fromCollection方法主要用于从内存中的集合对象创建DataSet,这个组件的主要特点是:
- 测试用途:非常适合在开发和测试阶段使用,可以快速创建小规模数据集验证业务逻辑
- 内存数据:数据完全存储在内存中,不需要访问外部存储系统
- 简单易用:支持各种集合类型,包括List、Set等
- 性能优势:由于数据在本地内存,处理速度非常快
典型使用场景:
java
// 创建测试数据集
List<String> testData = Arrays.asList("A", "B", "C", "D");
DataSet<String> dataSet = env.fromCollection(testData);2. 基于文件的DataSource
readTextFile方法是最常用的文件数据源读取方式,主要用于从HDFS等分布式文件系统读取文本数据:
- HDFS集成:原生支持HDFS文件系统,可以处理存储在HDFS上的大规模数据集
- 文本格式:默认按行读取文本文件,每行作为DataSet的一个元素
- 分布式读取:自动并行读取文件的不同部分,充分利用集群资源
- 容错机制:内置故障恢复机制,确保数据读取的可靠性
典型使用场景:
java
// 从HDFS读取文本文件
DataSet<String> hdfsData = env.readTextFile("hdfs://namenode:8020/user/flink/input/data.txt");高级文件处理特性:
- 支持多种压缩格式(如gzip、bzip2)
- 可以递归读取目录下的所有文件
- 支持文件通配符匹配
- 提供多种文件系统实现(HDFS、S3、本地文件系统等)
在实际生产环境中,基于文件的DataSource更为常用,因为批处理作业通常需要处理TB甚至PB级别的数据集,这些数据通常存储在HDFS等分布式文件系统中。而基于集合的DataSource则更多用于算法验证、单元测试等场景。
基本概念
Flink 的 DataSet API 是一个功能强大的批处理 API,专为处理静态、离线数据集设计。DataSet 中的数据是有限的,处理时系统会先等待整个数据集加载完毕。DataSet 可以通过多种方式创建,例如从文件、数据库、集合等加载数据,然后通过一系列转换操作(如 map、filter、join 等)进行处理。
核心特性
- 支持丰富的转换操作。
- 提供多种输入输出数据源。
- 支持复杂的数据类型,包括基本类型、元组、POJO、列表等。
- 支持优化计划,例如通过 cost-based optimizer 来优化查询执行计划。
DataSet 创建
在 Flink 中,可以通过多种方式创建 DataSet。以下是常见的数据源:
从本地文件读取
java
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet<String> text = env.readTextFile("path/to/file");从 CSV 文件读取
java
DataSet<Tuple3<Integer, String, Double>> csvData = env.readCsvFile("path/to/file.csv")
.types(Integer.class, String.class, Double.class);从集合中创建
java
List<Tuple2<String, Integer>> data = Arrays.asList(
new Tuple2<>("Alice", 1),
new Tuple2<>("Bob", 2)
);
DataSet<Tuple2<String, Integer>> dataSet = env.fromCollection(data);从数据库中读取
可以通过自定义的输入格式(如 JDBC 输入格式)从数据库中读取数据,虽然 Flink 本身并没有内置 JDBC 源的批处理 API,但可以通过自定义实现。
DataSet 的转换操作(Transformation)
Flink 的 DataSet API 提供了丰富的转换操作,可以对数据进行各种变换,以下是常用的转换操作: 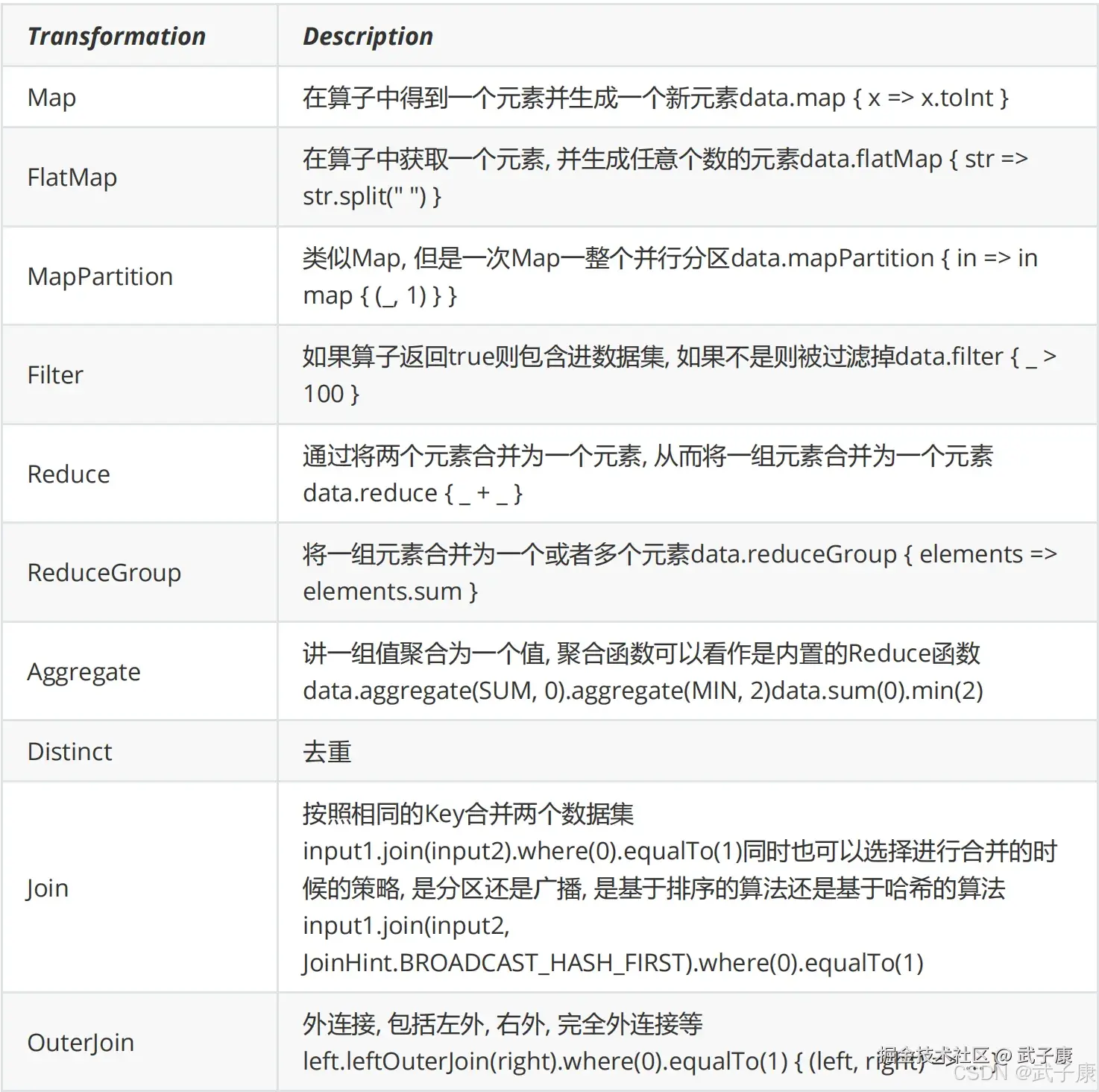
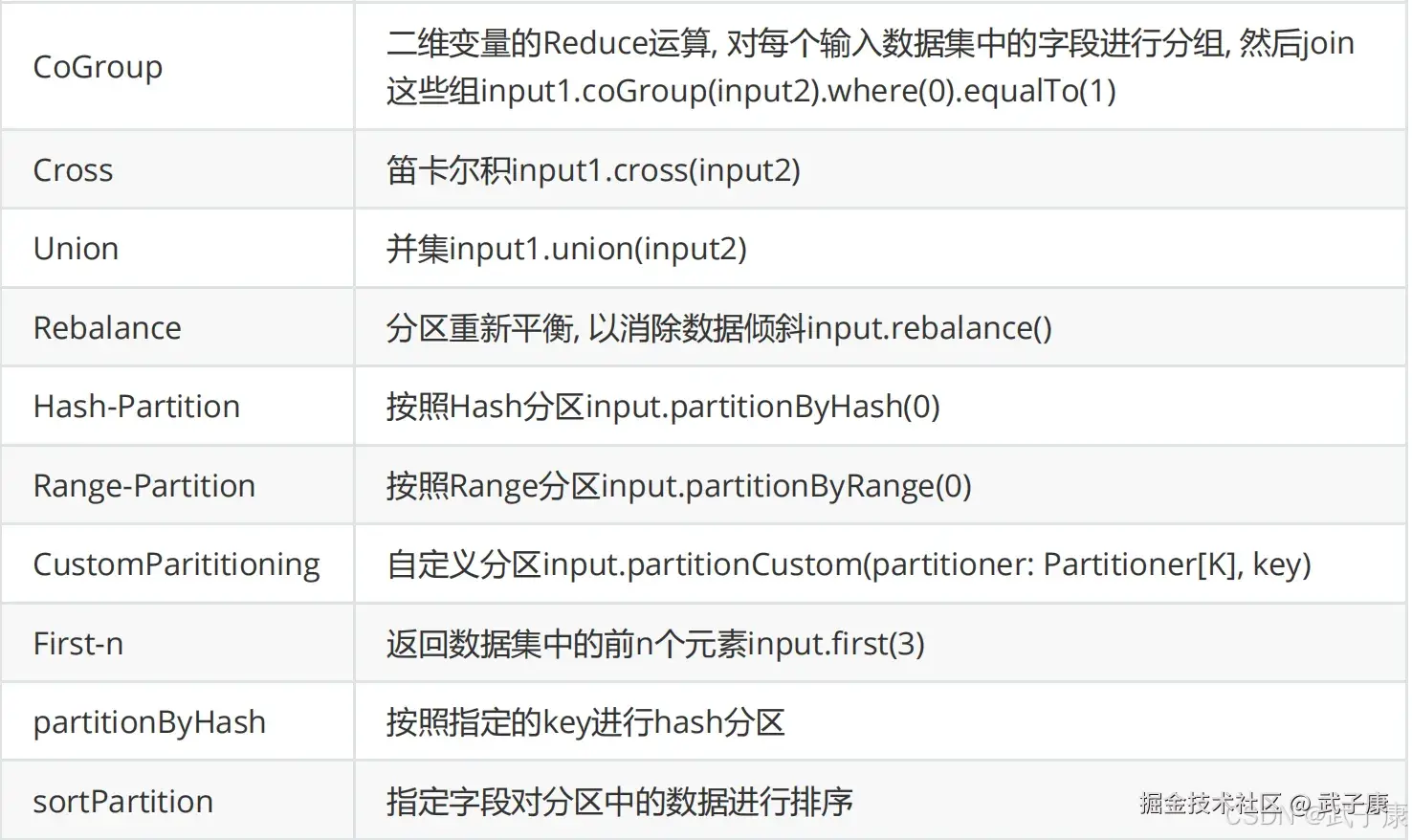
Map
将 DataSet 中的每一条记录进行映射操作,生成新的 DataSet。
java
DataSet<Integer> numbers = env.fromElements(1, 2, 3, 4, 5);
DataSet<Integer> squaredNumbers = numbers.map(n -> n * n);Filter
过滤掉不满足条件的记录。
java
DataSet<Integer> evenNumbers = numbers.filter(n -> n % 2 == 0);FlatMap
类似于 map,但允许一条记录生成多条输出记录。
java
DataSet<String> lines = env.fromElements("hello world", "flink is great");
DataSet<String> words = lines.flatMap((line, collector) -> {
for (String word : line.split(" ")) {
collector.collect(word);
}
});Reduce
将数据集根据某种聚合逻辑进行合并
java
DataSet<Integer> sum = numbers.reduce((n1, n2) -> n1 + n2);GroupBy 和 Reduce
对数据集进行分组,然后在每个组上执行聚合操作
java
DataSet<Tuple2<String, Integer>> wordCounts = words
.map(word -> new Tuple2<>(word, 1))
.groupBy(0)
.reduce((t1, t2) -> new Tuple2<>(t1.f0, t1.f1 + t2.f1));Join
类似于 SQL 中的连接操作,连接两个 DataSet。
java
DataSet<Tuple2<Integer, String>> persons = env.fromElements(
new Tuple2<>(1, "Alice"),
new Tuple2<>(2, "Bob")
);
DataSet<Tuple2<Integer, String>> cities = env.fromElements(
new Tuple2<>(1, "Berlin"),
new Tuple2<>(2, "Paris")
);
DataSet<Tuple2<String, String>> personWithCities = persons.join(cities)
.where(0)
.equalTo(0)
.with((p, c) -> new Tuple2<>(p.f1, c.f1));DataSet 输出
DataSet API 提供多种方式将数据写出到外部系统:
写入文件
java
wordCounts.writeAsCsv("output/wordcounts.csv", "\n", ",");写入数据库
虽然 DataSet API 没有直接提供 JDBC Sink,可以通过自定义 Sink 实现写入数据库功能。
打印控制台
java
wordCounts.print();批处理的优化机制详解
DataSet API 的优化原理
DataSet API 提供了全面的优化机制,主要通过以下三个方面来优化任务执行:
-
成本模型分析:系统会评估不同执行路径的资源消耗和性能表现,包括内存使用、CPU计算量、网络传输成本等因素,选择最优方案。
-
执行计划分析:通过对任务DAG(有向无环图)的分析,识别可以优化的环节,如合并操作、减少数据传输等。
优化执行流程
Flink 内部的优化过程可以分为以下几个阶段:
-
逻辑计划生成:编译器首先将用户定义的转换操作(如map、filter、join等)转换为逻辑执行计划。
-
逻辑优化:
- 谓词下推(Predicate Pushdown):尽早过滤数据
- 投影下推(Projection Pushdown):减少传输的数据量
- 操作合并:如将连续的map操作合并
-
物理计划生成:将优化后的逻辑计划转换为物理执行计划,考虑具体执行环境。
-
物理优化:
- 本地策略选择
- 执行节点分配
- 并行度调整
与SQL查询优化器的相似性
Flink的批处理优化过程借鉴了传统SQL查询优化器的成熟技术,主要体现在:
-
基于规则的优化(Rule-based Optimization):如上述的谓词下推等固定规则
-
基于成本的优化(Cost-based Optimization):
- 估算不同执行计划的成本
- 选择成本最低的执行方案
- 考虑数据统计信息(如基数估计)
实际优化示例
假设有以下批处理作业:
java
DataSet<Tuple2<String, Integer>> input = ...;
DataSet<Tuple2<String, Integer>> result = input
.filter(t -> t.f1 > 100) // 过滤
.map(t -> new Tuple2<>(t.f0, t.f1 * 2)) // 转换
.groupBy(0) // 分组
.sum(1); // 聚合优化器可能执行以下优化:
- 将filter操作尽可能前移,减少后续处理的数据量
- 合并连续的map操作(如果有多个map)
- 为groupBy-sum操作选择合适的聚合策略
- 根据数据量大小决定是否使用基于内存的聚合或基于磁盘的聚合
还有一些概念:
- DataSet 的分区:Flink 可以根据数据集的分区进行优化。例如,通过 partitionByHash 或 partitionByRange 来手动控制数据的分布方式。
- DataSet 的缓存:可以通过 rebalance()、hashPartition() 等方法来均衡数据负载,以提高并行度和计算效率。
DataSet API 的容错机制
Flink 的 DataSet API 提供了容错机制,支持在发生故障时重新执行失败的任务。虽然 DataSet API 没有像 DataStream 那样依赖于 Checkpoint 机制,但其批处理特性允许任务从头开始重新执行,确保数据处理的正确性。
DataSet 与 DataStream 的对比
DataSet API 与 DataStream API 之间有一些重要的区别:
DataSet API 的未来
需要注意的是,Flink 的官方路线图中已经不再优先开发 DataSet API 的新特性,未来的主要开发将集中在 DataStream API,甚至批处理功能都将通过 DataStream API 来实现。 因此,如果可能,建议新项目尽量使用 DataStream API 来替代 DataSet API。 特别是 Flink 的 Table API 和 SQL API 也适用于批处理和流处理,这些高层 API 提供了更简洁的语法和更强的优化能力。