.NET+AI: (微家的AI开发框架)大家赶紧学习!!!
什么是内核记忆(Kernel Memory)
Kernel Memory,内核记忆(KM)是一种多模态人工智能服务,旨在为应用程序提供长期记忆解决方案,模仿人类存储信息的记忆能力。专门通过自定义连续数据混合管道对数据集进行高效索引,并支持检索增强生成(RAG)。
KM 可以作为一个Web服务独立部署,也可以作为一个插件集成到ChatGPT/Copilot/Semantic Kernel 中,也可以作为一个.NET 库集成到应用中。
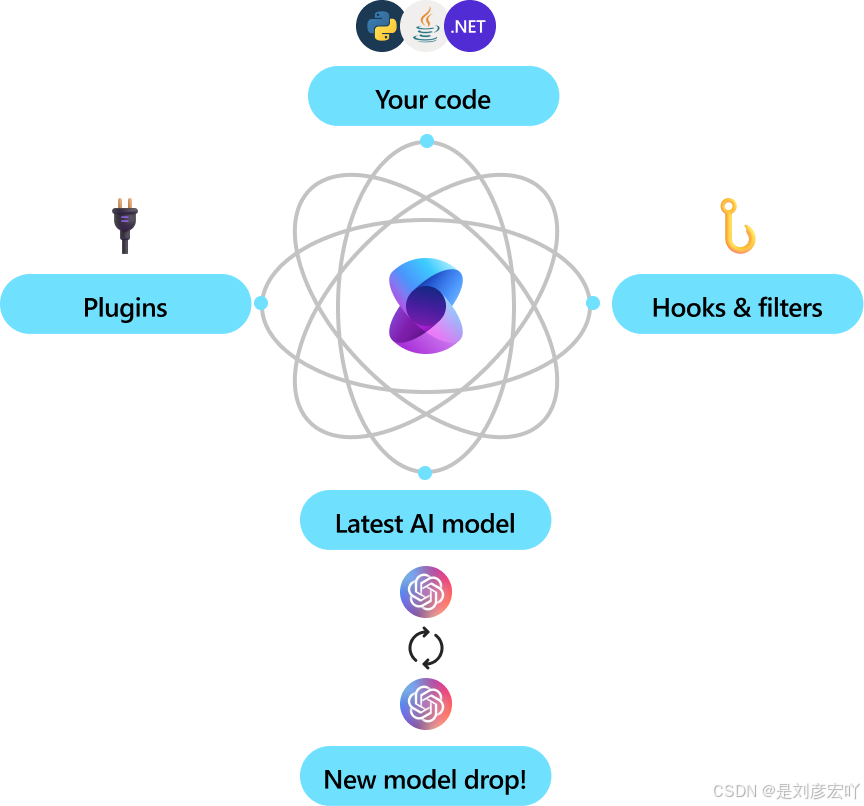
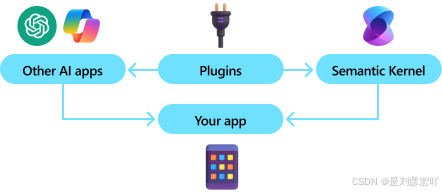
通过利用先进的嵌入和大型语言模型,KM 支持自然语言查询,以便从索引数据中获取答案,并返回带有引用和指向原始来源的链接。
Kernal Memory vs Semantic Memory
内核记忆(KM)是一项基于开发语义内核(SK)和语义记忆(SM)过程中所收到的反馈和汲取的经验教训而构建的服务。它提供了一些原本需要手动开发的功能,例如存储文件、从文件中提取文本、提供保护用户数据的框架等。KM 的代码库完全使用.NET 编写,这消除了用多种语言编写和维护功能的需求。作为一项服务,KM 可以在任何语言、工具或平台上使用,例如浏览器扩展和 ChatGPT 助手。
语义记忆(Semantic Memory,SM)是适用于 C#、Python 和 Java 的库,它包装了对数据库的直接调用并支持向量搜索。它是作为语义内核(Semantic Kernel,SK)项目的一部分开发的,并且是长期记忆的首次公开迭代。核心库以三种语言进行维护,而受支持的存储引擎列表(称为"连接器")因语言而异。
| 特性 | Kernel Memory | Semantic Memory |
|---|---|---|
| 数据格式 | Web页面、PDF、图像、Word、PowerPoint、Excel、Markdown、文本、JSON、HTML | 仅文本 |
| 搜索 | 余弦相似度、带过滤器的混合搜索(AND/OR条件) | 余弦相似度 |
| 语言支持 | 任何语言,命令行工具,浏览器扩展,低代码/无代码应用,聊天机器人,助手等 | C#、Python、Java |
| 存储引擎 | Azure AI Search、Elasticsearch、MongoDB Atlas、Postgres+pgvector、Qdrant、Redis、SQL Server、内存KNN、磁盘KNN | Azure AI Search、Chroma、DuckDB、Kusto、Milvus、MongoDB、Pinecone、Postgres、Qdrant、Redis、SQLite、Weaviate |
| 文件存储 | Disk、Azure Blob、AWS S3、MongoDB Atlas、内存(易失性) | - |
| RAG | 是 | - |
| 摘要 | 是 | - |
| OCR | 是,通过Azure Document Intelligence | - |
| 安全过滤器 | 是 | - |
| 大型文档摄取 | 是,包括使用队列的异步处理(Azure Queues、RabbitMQ、基于文件的或内存队列) | - |
| 文档存储 | 是 | - |
| 自定义存储架构 | 一些DBs | - |
| 带内部嵌入的向量DBs | 是 | - |
| 同时写入多个向量DBs | 是 | - |
| LLMs | Azure OpenAI、OpenAI、Anthropic、Ollama、LLamaSharp、LM Studio、Semantic Kernel Connectors | Azure OpenAI、OpenAI、Gemini、Hugging Face、ONNX、自定义等 |
| 带专用分词器的LLMs | 是 | 否 |
| 云部署 | 是 | - |
| 带OpenAPI的Web服务 | 是 | - |
核心概念
Document
文档,将信息(一个或多个文件,照片,或一段文本)上传到KM时,这些数据被打包为一个文档,并拥有唯一ID,通过这个ID 可以更新、替换或删除该文档的数据。以下示例中一次导入多个不同类型的文件,但它们被命名为doc001 Document。
var memory = new KernelMemoryBuilder()
.WithOpenAIDefaults(env["OPENAI_API_KEY"])
.Build<MemoryServerless>();
await memory.ImportDocumentAsync(new Document("doc001")
.AddFiles(["file1.txt", "file2.docx", "file3.pdf"]);如果再次以相同Document ID 导入新文档,则之前导入的文档会被覆盖。
Tag
标签,是一个键值对,通过给Document 打标签,以便在搜索时,通过指定标签限定搜索文档范围。以下示例中可以看出一个Document 可以有多个Tag,一个Tag 可以有多个值。
var memory = new KernelMemoryBuilder()
.WithOpenAIDefaults(env["OPENAI_API_KEY"])
.Build<MemoryServerless>();
await memory.ImportDocumentAsync(new Document("doc001")
.AddFiles(["file1.txt", "file2.docx", "file3.pdf"])
.AddTag("user", "Taylor")
.AddTag("collection", "meetings")
.AddTag("collection", "NASA")
.AddTag("collection", "space")
.AddTag("type", "news"));Index
索引,KM 利用向量存储来保存摄入的文档信息,像 Azure AI Search、Qdrant、Elastic Search、Redis 等解决方案。
为了对不同的数据加以区分,通过指定不同的索引名称来实现,索引之间的数据是隔离的。在存储信息、搜索和提问时,KM始终在一个索引的范围内工作。
换句话说,可以将多个Document 存储在单个索引下。
var memory = new KernelMemoryBuilder()
.WithOpenAIDefaults(env["OPENAI_API_KEY"])
.Build<MemoryServerless>();
await memory.ImportDocumentAsync(
document: new Document("doc001").AddFiles(["file1.txt", "file2.docx", "file3.pdf"]),
index:"index1");
await memory.ImportDocumentAsync(
document: new Document("doc002").AddFiles(["file4.txt", "file5.docx"]),
index:"index1");当未指定index时,将存储在名为default的索引下。同理,AskAsync和SerachAsync在未指定index时,默认在default索引下进行检索。
// 在index1索引下检索
var result = await memory.AskAsync("What is Kernel Memory?", index: "index1");
// 在default索引下检索
var result2 = await memory.SearchAsync("What is Kernel Memory?");Chunk
对读取的文档数据进行处理,将大块数据分解为更小、更易于处理的单元的过程,称为chunking ,分解得到的单元称为chunk。
通过分块,可以将文本拆分为单词、句子、段落还是整个文档,分块级别决定了检索到的信息的颗粒度。
举例而言:假设您在法律研究应用程序中使用RAG模型,并且您需要从大型法律文档中检索相关部分。用户询问,"法律对医疗保健中的数据隐私有什么规定?"。
如果系统采用文档级分块 ,它将检索整个法律文档,这可能是压倒性和低效的。然而,通过使用段落级分块,系统能检索专门讨论医疗保健数据隐私法的段落,给用户一个高度相关和简洁的答案。
如果没有分块,系统可能会检索文档中不相关的部分,从而提供糟糕的用户体验。通过分块,检索变得有针对性和有意义,增强了模型生成准确和上下文感知响应的能力。
核心技术与框架解析
Semantic Kernel:连接AI与业务逻辑的桥梁
Semantic Kernel是微软推出的开源框架,它能无缝整合大语言模型(LLM)能力与传统代码逻辑,让开发者可以通过自然语言提示词和C#代码结合的方式,快速构建AI驱动的应用。其核心优势在于提供了插件系统(Plugins)、记忆系统(Memory)和规划能力(Planning),这三者共同构成了实现RAG和MCP Agent的基础。
RAG:让应答更精准的知识检索增强
RAG技术的核心是通过检索外部知识库,为LLM提供精准的上下文信息,从而让生成的回答更符合业务事实。在销售场景中,产品手册、价格表、促销政策等都是关键的知识库内容。借助RAG,系统能在回答客户关于"某款产品的折扣力度""售后服务范围"等问题时,不再依赖LLM的通用训练数据,而是从企业内部知识库中检索最新、最准确的信息,避免出现过时或错误的回答。
MCP Agent:多能力协同的销售智能体
MCP Agent(Multi-Capability Agent)指具备多种业务能力的智能代理,它能根据客户问题自动调用不同的功能模块(如产品查询、价格计算、订单状态跟踪等),实现端到端的智能应答。在Semantic Kernel中,MCP Agent可以通过规划能力分析用户意图,然后调用对应的插件完成任务,例如当客户询问"购买100台A产品能享受多少折扣"时,Agent会先调用产品信息插件获取A产品的基础价格,再调用折扣计算插件根据采购量算出具体折扣,最后整合结果生成自然语言回答。

这张图表列出了20个关于AI代理(Agent)的核心概念,每个概念都有简短的描述和图标。以下是这些概念的整理:
- Agent(代理):能够感知、推理并采取行动以实现目标的自主实体。
- Environment(环境):代理操作和交互的周围上下文。
- Perception(感知):代理解释感官或环境数据的过程。
- State(状态):代理对世界当前内部条件或表示。
- Memory(记忆):存储最近或历史信息以供连续性和学习使用。
- Large Language Models(大型语言模型):支持语言理解和生成的基础模型。
- Reflex Agent(反射代理):基于预定义的"条件-行动"规则做出决策的代理。
- Knowledge Base(知识库):代理用于做出决策的结构化或非结构化数据存储库。
- CoT (Chain of Thought)(思维链):代理为复杂任务表达中间步骤的推理方法。
- React(反应):结合逐步推理与环境行动的框架。
- Tools(工具):代理用来增强能力的API或外部系统。
- Action(行动):代理执行的任何任务或行为。
- Planning(规划):制定一系列行动以实现特定目标。
- Orchestration(协调):协调多个步骤、工具或代理以完成任务流程。
- Handoffs(交接):不同代理之间任务或工作的转移。
- Multi-Agent System(多代理系统):多个代理在同一环境中操作和协作的框架。
- Swarm(群体):许多代理遵循局部规则而无需中央控制的涌现智能行为。
- Agent Debate(代理辩论):代理争论对立观点以完善或改进最终响应的机制。
- Evaluation(评估):衡量代理行动有效性的过程。
- Learning Loop(学习循环):代理通过持续从反馈中学习来改进性能的循环。
这些概念涵盖了AI代理的各个方面,从基本的定义和功能到更复杂的交互和学习过程。
系统架构与实现步骤
架构设计
销售业务智能应答系统的架构主要分为三层:
- 数据层:存储产品信息、价格政策、销售案例等知识库数据,可采用向量数据库(如Qdrant、Milvus)存储文本向量,以便高效检索。
- 核心层:基于Semantic Kernel实现,包含RAG模块(负责知识检索)、MCP Agent模块(负责意图解析与能力调用)和LLM接口(对接GPT-4、Azure OpenAI等模型)。
- 应用层:提供API接口或前端交互界面,供销售人员或客户使用,支持文本输入、语音输入等多种交互方式。
具体实现步骤
环境准备与项目初始化
-
安装Semantic Kernel相关NuGet包: Microsoft.SemanticKernel 、 Microsoft.SemanticKernel.Plugins.Memory 等。
-
配置LLM服务:通过API密钥连接Azure OpenAI或其他LLM服务,在Semantic Kernel中初始化 Kernel 对象。
构建RAG模块
-
知识库导入:将产品手册、价格表等文档解析为文本片段,使用Semantic Kernel的 TextChunker 进行分块处理。
-
向量存储:调用 Kernel.Memory.SaveInformationAsync 方法,将文本片段及其向量存储到向量数据库中。
-
检索逻辑:当接收用户问题时,通过 Kernel.Memory.SearchAsync 检索与问题最相关的知识库片段,作为上下文传递给LLM。
开发MCP Agent能力插件
- 产品查询插件:实现 GetProductInfo(string productName) 方法,返回产品规格、价格等信息。
- 折扣计算插件:实现 CalculateDiscount(int quantity, string productId) 方法,根据采购量和产品ID计算折扣。
- 订单查询插件:实现 GetOrderStatus(string orderId) 方法,查询订单的当前状态。
- 将插件注册到Semantic Kernel: kernel.ImportPluginFromObject(new SalesPlugins(), "SalesPlugins") 。
Agent规划与应答生成
- 意图解析:通过Semantic Kernel的 FunctionCalling 能力,让LLM分析用户问题,判断是否需要调用插件或直接使用RAG检索结果。
- 多步骤处理:对于复杂问题(如"对比A和B产品的价格,并计算购买50台的总成本"),Agent会规划调用顺序(先调用产品查询插件获取A、B价格,再调用折扣计算插件分别计算成本,最后汇总)。
- 结果生成:将插件返回的数据或RAG检索到的知识,通过LLM整理为自然、易懂的回答。
场景验证与优势体现
以一个实际销售场景为例:客户询问"你们的旗舰款打印机现在有什么优惠?如果公司采购20台,加上三年保修,总费用是多少?"
系统的处理流程如下:
接收问题后,MCP Agent通过意图解析,确定需要调用"产品查询""折扣计算"和"保修价格"三个插件。
调用产品查询插件获取"旗舰款打印机"的基础价格和产品ID。
调用折扣计算插件,根据采购量20台和产品ID,计算出对应的折扣比例。
调用保修价格插件,获取三年保修的单台费用。
结合RAG检索到的"当前针对企业采购的额外10%补贴"信息,汇总计算总费用。
最后通过LLM生成包含具体价格明细、优惠说明的回答,同时附上产品参数链接(来自知识库)。
该系统的优势在于:
- 准确性:依赖企业内部知识库和业务插件,避免LLM幻觉,确保价格、政策等信息精准无误。
- 高效性:MCP Agent自动完成多步骤处理,无需人工干预,缩短响应时间。
- 扩展性:新增产品或业务规则时,只需更新知识库或开发新插件,无需重构整个系统。
总结与展望
基于Semantic Kernel构建的销售业务智能应答系统,通过RAG解决了知识精准性问题,借助MCP Agent实现了复杂业务场景的自动化处理,为销售团队提供了强大的智能支持。在实际应用中,还可结合用户画像、历史对话记录等数据进一步优化应答效果,例如根据客户过往采购记录推荐合适的优惠方案。
随着LLM技术和Semantic Kernel框架的不断发展,这类智能应答系统将在销售线索挖掘、客户关系维护等领域发挥更大作用,推动销售业务向更高效、更智能的方向转型。