一、高并发内存池整体框架设计
我们实现的内存池需要考虑以下几方面的问题:
- 性能问题。
- 多线程环境下,锁竞争问题。
- 内存碎片问题。
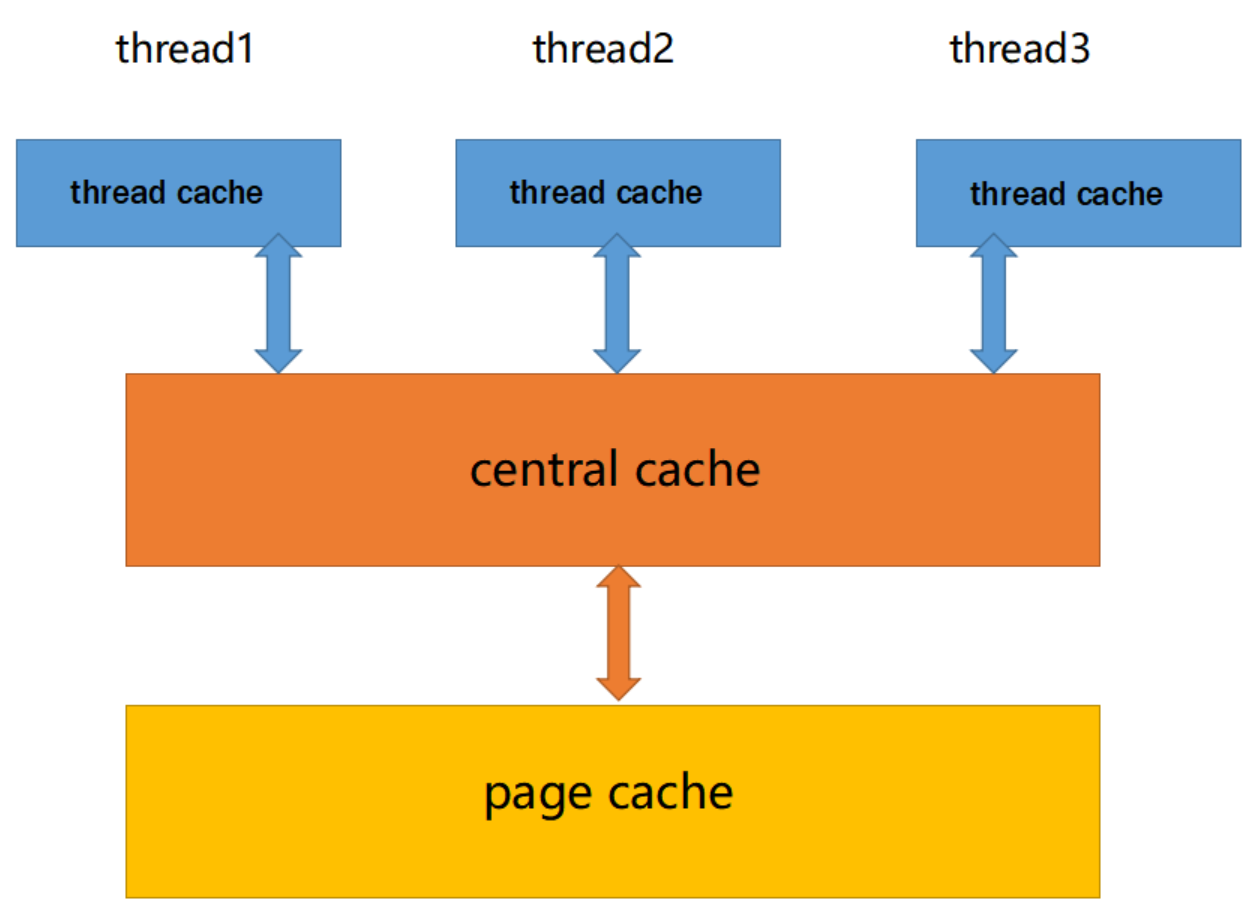
高并发内存池主要由以下3个部分构成:
ThreadCache
ThreadCache:线程缓存是每个线程独有的,用于小于256KB的内存的分配,线程从这里申请内存。不需要加锁(采用TLS无锁访问),每个线程独享一个cache,这也就是这个并发线程池高效的地方。
CentralCache
CentralCache:中心缓存是所有线程共享,ThreadCache是按需从CentralCache中获取的对象。CentralCache合适的时机回收CentralCache中的对象,避免一个线程占用了太多的内存,而其他线程的内存吃紧,达到内存分配在多个线程中更均衡的按需调度的目的。CentralCache是存在竞争的,所以从这里取内存对象是需要加锁,首先这里用的是桶锁,其次只有ThreadCache的没有内存对象时才会找CentralCache,所以这里竞争不会很激烈。
PageCache
PageCache:页缓存是在CentralCache缓存上面的一层缓存,存储的内存是以页为单位存储及分配的,CentralCache没有内存对象时,从PageCache分配出一定数量的page,并切割成定⻓大小的小块内存,分配给CentralCache。当一个span的几个跨度页的对象都回收以后,PageCache会回收CentralCache满足条件的span对象,并且合并相邻的页,组成更大的页,缓解内存碎片的问题。
Common.h
cpp
#pragma once
#include <iostream>
#include <vector>
#include <algorithm>
#include <cassert>
#include <ctime>
#include <cstdint>
#include <thread>
#include <mutex>
#include <unordered_map>
#ifdef _WIN32
#include <Windows.h>
#else // Linux
#include <sys/mman.h>
#endif
using std::cout;
using std::endl;
static const size_t MAX_MEMORYSIZE = 256 * 1024; // threadcache最大的内存大小
static const size_t MAX_BUCKETSIZE = 208; // threadcache CentralCache 最大桶数
static const size_t MAX_PAGESIZE = 129; // PageCache最大页数: 128
static const size_t PAGE_SHIFT = 13; // 8K一页
#ifdef _WIN64
typedef uint64_t PAGE_ID;
#elif _WIN32
typedef uint32_t PAGE_ID;
#else // Linux
typedef uint64_t PAGE_ID;
#endif
// 获取obj的下一个对象指针
static inline void *&NextObj(void *obj)
{
return *(void **)obj;
}
inline static void *SystemAlloc(size_t kpage)
{
#ifdef _WIN32
void *ptr = VirtualAlloc(NULL, kpage << PAGE_SHIFT, MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE);
#else
void *ptr = mmap(NULL, kpage << PAGE_SHIFT, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
#endif
if (ptr == nullptr)
throw std::bad_alloc();
return ptr;
}
inline static void SystemFree(void *ptr)
{
#ifdef _WIN32
VirtualFree(ptr, 0, MEM_RELEASE);
#else
#endif
}
// 自由链表类
class FreeList
{
public:
// 归还内存块到自由链表
void push(void *obj)
{
NextObj(obj) = _freelist;
_freelist = obj;
++_size;
}
void PushRange(void *start, void *end, size_t n)
{
assert(start);
assert(end);
NextObj(end) = _freelist;
_freelist = start;
_size += n;
}
void PopRange(void *&start, void *&end, size_t n)
{
assert(n > 0 && n <= _size);
start = _freelist;
end = start;
for (size_t i = 0; i < n - 1; i++)
end = NextObj(end);
_freelist = NextObj(end);
NextObj(end) = nullptr; // 截断
_size -= n;
}
// 从自由链表获取内存块
void *pop()
{
void *obj = _freelist;
_freelist = NextObj(_freelist);
--_size;
return obj;
}
bool isEmpty()
{
return _freelist == nullptr;
}
size_t &maxSize()
{
return _maxSize;
}
size_t size()
{
return _size;
}
private:
void *_freelist = nullptr;
size_t _maxSize = 1; //
size_t _size = 0;
};
class SizeClass
{
public:
// Bytes:[1, 128] 对齐到8 index范围[0, 16)
// Bytes:[128+1, 1024] 对齐到16 index范围[16,72)
// Bytes:[1024+1, 8*1024] 对齐到128 index范围[72,128)
// Bytes:[8*1024+1, 64*1024] 对齐到1024 index范围[128,184)
// Bytes:[64*1024+1, 256*1024] 对齐到8*1024 index范围[184,208)
static size_t _RoundUp(size_t size, size_t alignNum)
{
return (size + alignNum - 1) & ~(alignNum - 1);
}
// 获得对齐之后的内存大小
static size_t RoundUp(size_t size)
{
assert(size > 0);
if (size <= 8)
return _RoundUp(size, 8);
else if (size > 8 && size <= 16)
return _RoundUp(size, 16);
else if (size > 16 && size <= 128)
return _RoundUp(size, 128);
else if (size > 128 && size <= 1024)
return _RoundUp(size, 1024);
else if (size > 1024 && size <= 8 * 1024)
return _RoundUp(size, 8 * 1024);
else
return _RoundUp(size, 1 << PAGE_SHIFT);
return -1;
}
// 找到"桶"的位置:数组下标
static size_t _Index(size_t size, size_t alignShifted)
{
return ((size + ((long long)1 << alignShifted) - 1) >> alignShifted) - 1;
}
static size_t Index(size_t size)
{
assert(size < MAX_MEMORYSIZE);
static int CountArray[] = {16, 56, 56, 56};
if (size <= 128)
return _Index(size, 3);
else if (size > 128 && size <= 1024)
return _Index(size - 128, 4) + CountArray[0];
else if (size > 1024 && size <= 8 * 1024)
return _Index(size - 1024, 7) + CountArray[0] + CountArray[1];
else if (size > 8 * 1024 && size <= 64 * 1024)
return _Index(size - 8 * 1024, 10) + CountArray[0] + CountArray[1] + CountArray[2];
else if (size > 64 * 1024 && size <= 256 * 1024)
return _Index(size - 64 * 1024, 13) + CountArray[0] + CountArray[1] + CountArray[2] + CountArray[3];
else
assert(false);
return -1;
}
// 一次ThreadCache向CentralCache申请多少个
static size_t NumMoveSize(size_t size)
{
assert(size > 0);
size_t num = MAX_MEMORYSIZE / size;
if (num < 2)
num = 2; // 大对象申请少
if (num > 512)
num = 512; // 小对象申请多
return num;
}
static size_t NumMovePage(size_t size)
{
size_t num = NumMoveSize(size);
size_t npage = num * size;
npage >>= PAGE_SHIFT;
if (npage == 0)
npage = 1;
return npage;
}
};
struct Span
{
PAGE_ID _pageId = 0; // 起始页号
size_t _n = 0; // 页的数量
Span *_prev = nullptr; // 上一个span
Span *_next = nullptr; // 下一个span
size_t _useCount = 0; // 使用计数
void *_freeList = nullptr; // 切好的小块内存的自由链表
bool _isUse = false; // 标记span是否在使用中 -> 用于合并
size_t _objSize = 0;
};
class SpanList
{
public:
std::mutex _mtx; // 桶锁
SpanList()
{
_head = new Span;
_head->_next = _head;
_head->_prev = _head;
}
Span *begin()
{
return _head->_next;
}
Span *end()
{
return _head;
}
bool empty()
{
return begin() == end();
}
Span *pop_front()
{
assert(!empty());
Span *first = begin();
erase(first);
return first;
}
void push_front(Span *newSpan)
{
insert(begin(), newSpan);
}
void insert(Span *pos, Span *newSpan)
{
assert(pos);
assert(newSpan);
Span *prev = pos->_prev;
newSpan->_next = pos;
newSpan->_prev = prev;
prev->_next = newSpan;
pos->_prev = newSpan;
}
void erase(Span *pos)
{
assert(pos);
assert(pos != _head);
Span *prev = pos->_prev;
Span *next = pos->_next;
prev->_next = next;
next->_prev = prev;
}
private:
Span *_head = nullptr;
};二、ThreadCache实现
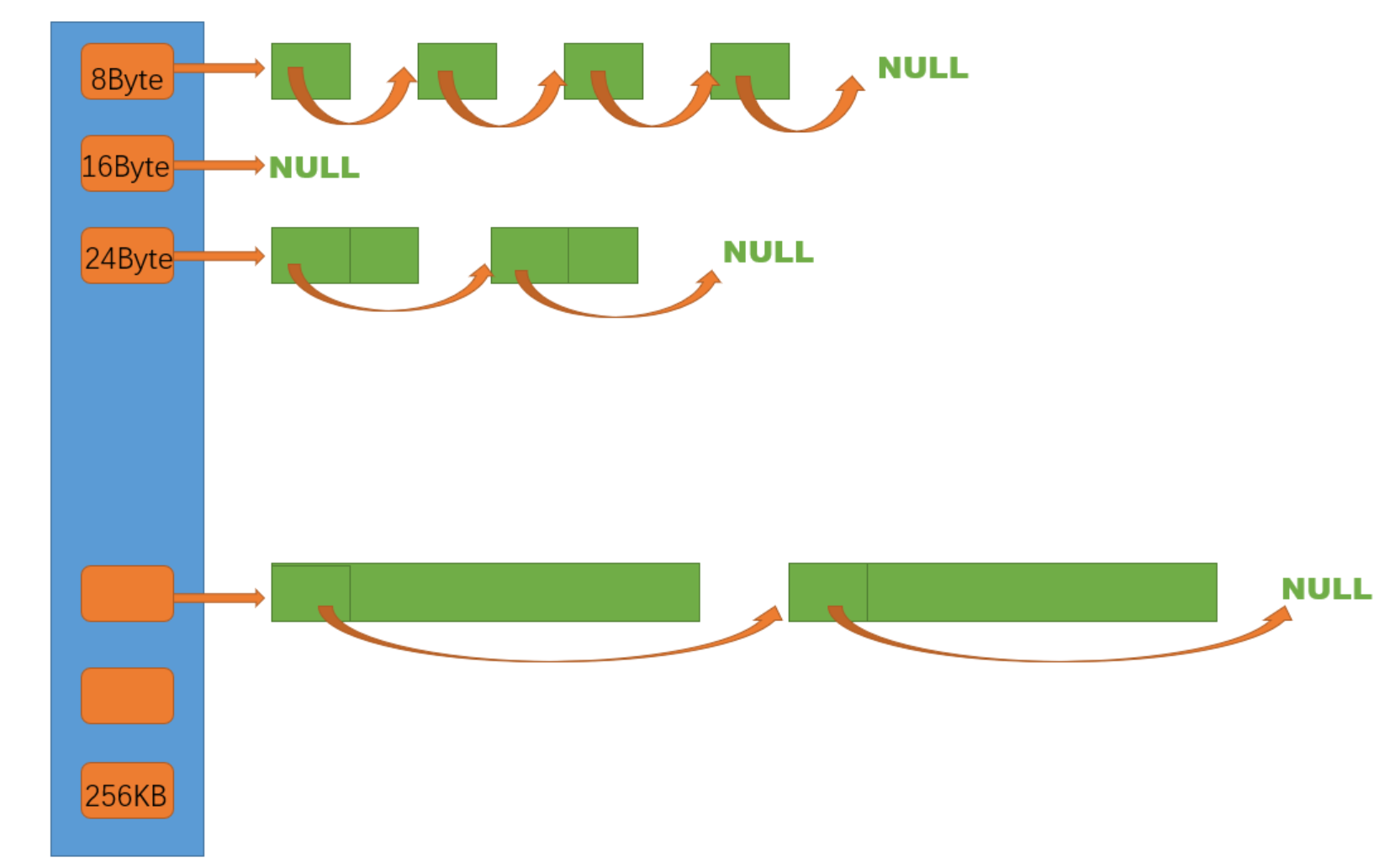
1、哈希桶结构
ThreadCache是哈希桶结构,每个桶是一个按桶位置映射大小的内存块对象的自由链表。每个线程都会有一个ThreadCache对象,这样每个线程在这里获取对象和释放对象时是无锁的。
2、申请内存
- 当内存申请
size<=256KB,先获取到线程本地存储的ThreadCache对象,计算size映射的哈希桶自由链表下标i。 - 如果自由链表
_freeLists[i]中有对象,则直接Pop一个内存对象返回。 - 如果
_freeLists[i]中没有对象时,则批量从CentralCache中获取一定数量的对象,插入到自由链表并返回一个对象。
3、释放内存
- 当释放内存小于256KB时将内存释放回
ThreadCache,计算size映射自由链表桶位置i,将对象Push到_freeLists[i]。 - 当链表的⻓度过⻓,则回收一部分内存对象到
CentralCache。
4、Thread Local Storage
Thread Local Storage线程局部存储(TLS),是一种变量的存储方法,这个变量在它所在的线程内是全局可访问的,但是不能被其他线程访问到,这样就保持了数据的线程独立性。而熟知的全局变量,是所有线程都可以访问的,这样就不可避免需要锁来控制,增加了控制成本和代码复杂度。
cpp
// C++11 TLS Thread-Local Storage
thread_local static ThreadCache *pTLSThreadCache = nullptr; // 线程私有的ThreadCache指针C++11中线程局部存储(TLS) 通过thread_local关键字为多线程环境中的ThreadCache指针创建了线程私有副本,核心作用是实现线程独立的内存缓存管理。
(1)代码解析
thread_local 关键字
这是C++11引入的语言级TLS支持,标记pTLSThreadCache为线程局部变量。意味着:
- 每个线程都会拥有该变量的独立副本,线程A对其修改不会影响线程B的副本。
- 副本的生命周期与线程一致:线程创建时初始化(这里初始为
nullptr),线程销毁时自动释放。
static 关键字
结合thread_local使用时,static控制变量的链接属性:
- 若在全局/命名空间作用域:变量仅在当前编译单元(
.cpp文件)内可见(内部链接),避免跨文件命名冲突。 - 若在函数内:变量的线程副本是"线程内的静态变量",只会在线程首次访问时初始化一次。
ThreadCache * 指针
通常用于内存池设计 中(如TCMalloc、ptmalloc等),ThreadCache是线程本地的内存缓存:
- 每个线程通过自己的
pTLSThreadCache指针访问私有缓存,避免多线程竞争全局内存池的锁开销。 - 小内存分配/释放可直接操作线程本地缓存,大幅提升性能(无需加锁)。
(2)典型使用场景(伪代码)
cpp
// 线程首次使用时初始化本地缓存
void initThreadCache() {
if (pTLSThreadCache == nullptr) {
pTLSThreadCache = new ThreadCache(); // 每个线程创建独立缓存
}
}
// 线程内分配内存(无需锁)
void* threadMalloc(size_t size) {
initThreadCache();
return pTLSThreadCache->allocate(size); // 操作线程私有缓存
}
// 线程退出时自动销毁(需配合线程清理函数)
void threadExit() {
if (pTLSThreadCache != nullptr) {
delete pTLSThreadCache;
pTLSThreadCache = nullptr;
}
}(3)核心优势
- 无锁效率 :线程操作自己的
ThreadCache副本时无需加锁,解决多线程内存分配的性能瓶颈。 - 隔离性:避免线程间数据干扰,每个线程的内存管理状态独立。
- 语言级支持 :相比操作系统API(如Windows的
TlsAlloc、Linux的pthread_key_create),thread_local更简洁,跨平台性更好。
三、核心实现
用户申请空间接口(具体实现之后会说明)
cpp
static void *ConcurrencyAlloc(size_t size)
{
if (pTLSThreadCache == nullptr)
{
static ObjectPool<ThreadCache> tcPool; // 定长内存池来控制
pTLSThreadCache = tcPool.New();
}
return pTLSThreadCache->Allocate(size);
}
static void ConcurrencyFree(void *ptr){}ThreadCache.h
cpp
#pragma once
#include "Common.h"
class ThreadCache
{
public:
// 从threadcache分配内存
void *Allocate(size_t size);
// 归还内存到threadcache
void Deallocate(void *ptr, size_t size);
// 从CentralCache中获取内存
void *FetchFromCentralCache(size_t index, size_t size);
// 回收内存
void ListTooLong(FreeList &list, size_t size);
private:
FreeList _freeList[MAX_BUCKETSIZE]; // 哈希桶, 每个桶一个自由链表
};
// C++11 TLS Thread-Local Storage
thread_local static ThreadCache *pTLSThreadCache = nullptr; // 线程私有的ThreadCache指针ThreadCache.cpp
cpp
#include "ThreadCache.h"
#include "CentralCache.h"
// 从CentralCache中获取内存
void *ThreadCache::FetchFromCentralCache(size_t index, size_t size)
{
// 慢开始反馈调节算法
size_t batchNum = std::min(SizeClass::NumMoveSize(size), _freeList[index].maxSize());
if (_freeList[index].maxSize() == batchNum)
_freeList[index].maxSize() += 2;
void *start = nullptr, *end = nullptr;
size_t actualNum = CentralCache::GetInstance()->FetchRangeObj(start, end, batchNum, size); // 可能不够batchNum
assert(actualNum > 0);
if (actualNum == 1)
{
assert(start == end);
return start;
}
else
{
_freeList[index].PushRange(NextObj(start), end, actualNum - 1);
return start;
}
}
// 从threadcache分配内存
void *ThreadCache::Allocate(size_t size)
{
assert(size < MAX_MEMORYSIZE);
size_t alignSize = SizeClass::RoundUp(size);
size_t freeListPos = SizeClass::Index(size);
if (!_freeList[freeListPos].isEmpty())
{
return _freeList[freeListPos].pop();
}
else
return FetchFromCentralCache(freeListPos, alignSize);
}
// 归还内存到threadcache
void ThreadCache::Deallocate(void *ptr, size_t size)
{
assert(size < MAX_MEMORYSIZE);
size_t freeListPos = SizeClass::Index(size);
_freeList[freeListPos].push(ptr);
// 当链表长度大于maxsize(一次批量申请的内存)时,归还一部分给CentralCache(还可以通过内存大小判断)
if (_freeList[freeListPos].size() >= _freeList[freeListPos].maxSize())
{
ListTooLong(_freeList[freeListPos], size);
}
}
void ThreadCache::ListTooLong(FreeList &list, size_t size)
{
void *start = nullptr, *end = nullptr;
list.PopRange(start, end, list.maxSize());
CentralCache::GetInstance()->ReleaseListToSpan(start, size);
}