站在2025年10月,如果你正在准备秋招,打开腾讯、阿里、字节的招聘页面,会发现一个让人焦虑的事实:几乎所有技术岗位的JD里都出现了"大模型"、"Agent"、"多模态"这些关键词,而大部分人可能连这些概念的边界都还没摸清楚。三年前,推荐算法工程师还在调召回策略和排序模型,那时候面试题是"Wide&Deep和DeepFM有什么区别";今天,同样的岗位要求你思考"怎么用LLM重构整个推荐系统"。两年前,视觉算法工程师专注于目标检测和图像分割,面试考的是YOLO和Mask R-CNN;现在,你需要掌握Diffusion模型的原理,理解NeRF重建的数学基础,甚至要会用Stable Diffusion做AIGC应用。
这种技术栈的剧变不是渐进的,而是断崖式的。我见过太多准备了一个暑假传统算法的同学,到了面试现场被问"ReAct模式和ReWOO有什么区别"时一脸茫然。也见过刷了半年LeetCode的开发同学,被问"LangChain的LCEL怎么用"时完全不知道从何说起。更糟糕的是,当你试图在网上找学习资料时,会发现大部分内容要么太浅(停留在API调用层面),要么太散(知识点之间没有连接),根本形成不了系统化的认知。
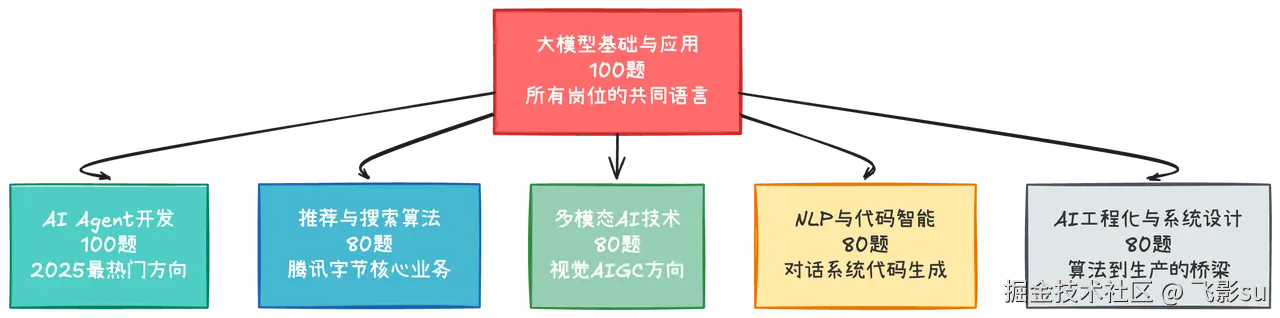
我花了些时间,把今年腾讯、阿里、字节为主的头部大厂秋招的所有AI相关岗位梳理了一遍。从"技术研究-推荐算法方向"到"AI应用全栈开发工程师",从"算法工程师-计算机视觉"到"大模型算法专家(代码智能方向)"。其实这些岗位表面上五花八门,但底层考察的技术能力其实可以归纳为六个核心方向。更重要的是,这六个方向不是孤立的,它们之间有清晰的依赖关系和递进逻辑。我想整理出一些热门题库,根据自己的理解,简单写一下题解,和大家一起边写边学。
为什么是这六个方向而不是别的
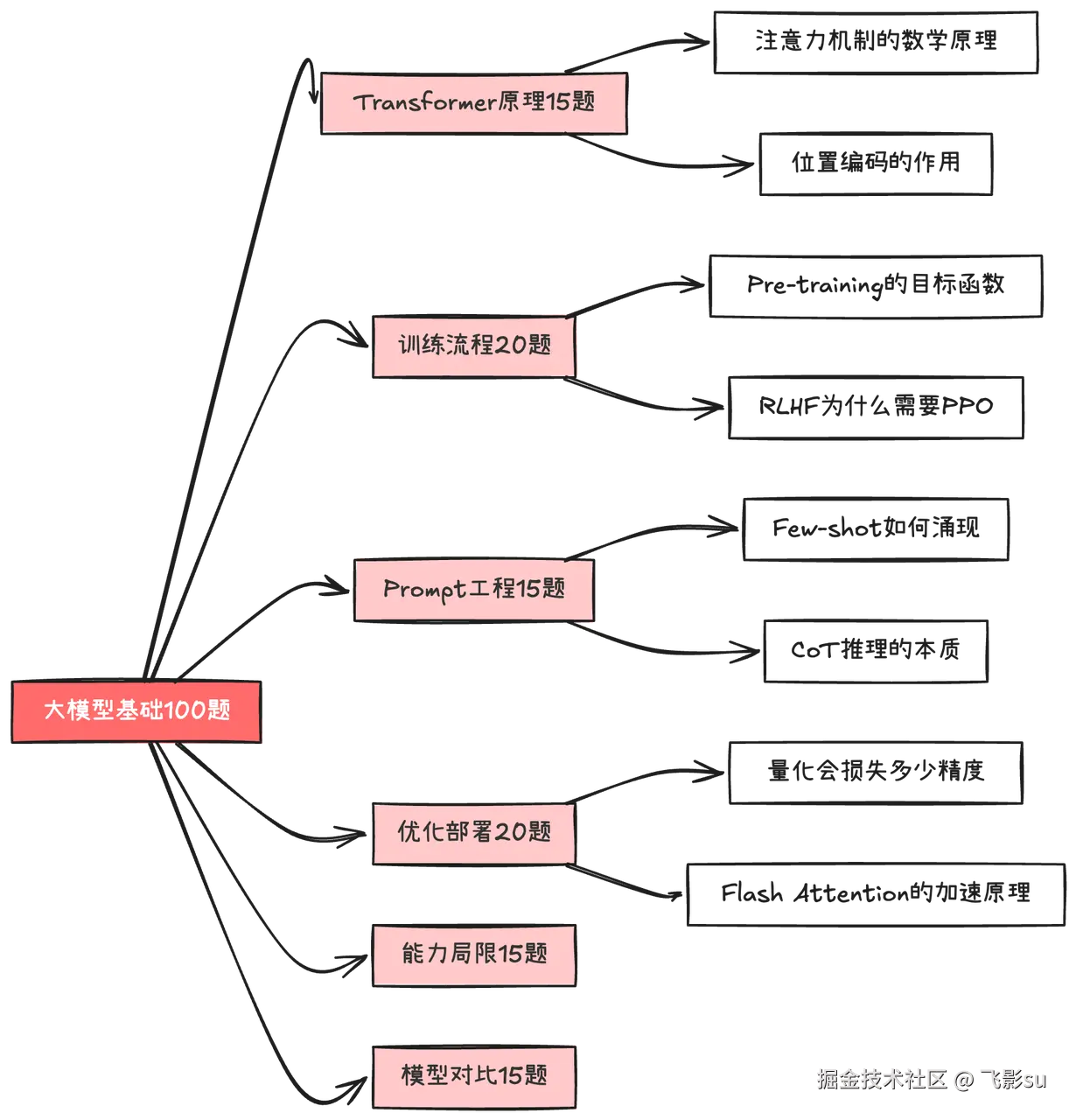
当我把所有岗位要求铺开在面前,用荧光笔标出高频关键词时,发现 "大模型基础"出现的频率是90+% 。无论是腾讯的推荐算法、阿里云的AI应用开发,还是字节的Agent算法工程师,面试官都会先问你"Transformer的Self-Attention是怎么算的"、"RLHF的训练流程是什么"、"大模型的幻觉问题怎么缓解"。这就像盖房子,地基不牢固,上层建筑再漂亮也会塌。所以我打算以 大模型基础与应用 作为第一个方向,梳理出100道常考题。
这100道题不是简单的概念堆砌。从"Self-Attention为什么要除以根号d_k"这种基础原理,到"ZeRO优化器的三个阶段分别优化了什么"这种工程实践,再到"GPT-4和Claude各自的优势是什么"这种模型对比,形成了一个完整的认知体系。更重要的是,这些题目是按照你实际理解技术的思维路径设计的:先理解架构原理,再掌握训练流程,然后学会Prompt Engineering,接着了解模型优化与部署,最后建立对大模型能力边界的清晰认知。
第二个方向是AI Agent开发,这是2025年最炙手可热的技术赛道。字节跳动的Agent算法工程师岗位描述里写着"深入理解业务需求并设计技术解决方案,设计和开发领先的AI应用和解决方案原型",阿里云更是直接说"我们视AI为新的生产力,采用全新的软件开发范式"。这些描述背后指向的就是Agent技术。但Agent到底是什么?很多人的理解停留在"让GPT调用几个API"的层面,这是远远不够的。
Agent的本质是让大模型具备自主规划任务、调用工具、处理复杂流程 的能力。你需要理解为什么ReAct模式(Reasoning + Acting)能提升推理能力,知道Reflexion如何通过自我反思优化决策,懂得Tree of Thoughts和Chain of Thoughts在处理复杂问题时的根本差异。更关键的是,你要会用LangChain和LangGraph这两个框架。LangChain不只是一个工具库,它代表了一种新的AI应用开发范式------把原本需要大量胶水代码的LLM应用开发变成了组装积木式的编程。
就像早年Spring框架改变了Java开发一样,LangChain正在改变AI应用的开发方式。它的Chain组件解决的是工作流编排问题,Memory组件处理对话上下文管理,Agent组件实现自主决策和工具调用。而LangGraph更进一步,用图状态机的方式处理复杂的多步骤流程,支持条件分支、循环迭代、人机交互。这100道Agent题目覆盖了从基础理论到框架实战,从单Agent到Multi-Agent系统,从RAG检索优化到生产化部署的完整链路。
接下来是三个垂直领域方向,它们是根据大厂的核心业务场景提炼出来的。推荐与搜索算法 对应的是腾讯视频号、抖音推荐、淘宝信息流这些每天服务亿级用户的系统。这个方向的面试既考经典算法(协同过滤、矩阵分解、深度学习推荐模型),也考前沿技术(大模型怎么做推荐、图神经网络在推荐中的应用)。腾讯2025秋招的推荐算法岗位明确提到"基于超大规模深度神经网络模型和机器学习系统,探索业界前沿推荐技术",这意味着你不能只停留在调参层面,而要理解推荐系统的范式正在如何被大模型重构。 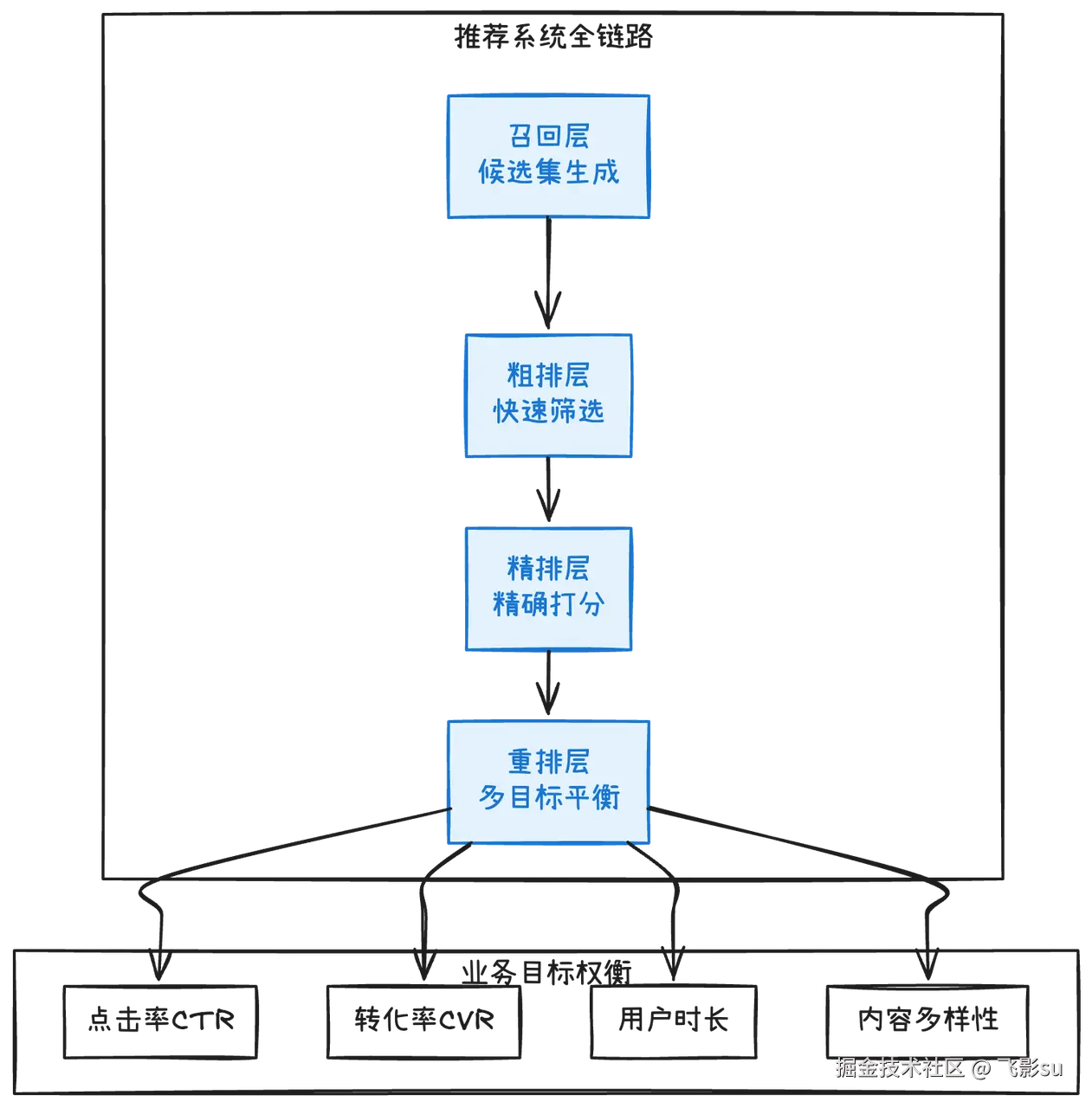
多模态AI技术 是视觉和AIGC方向的核心技术栈。从CLIP的对比学习到Stable Diffusion的可控生成,从NeRF的三维重建到Sora的视频生成,这80道题串起了图文多模态、图像生成、视频理解、3D视觉的完整技术图景。字节的AIGC算法工程师岗位写着"构建支持稀疏模型的混合推理框架,设计跨模态对齐算法",阿里的视觉算法岗位要求"熟悉Diffusion、LLM等大模型相关算法"。这些要求背后是一个明确的信号:纯粹的计算机视觉工程师正在被多模态AI工程师取代。
NLP与代码智能聚焦的是对话系统、知识图谱、代码生成这三个高频场景。腾讯招"自然语言处理方向"要求"负责对话系统,尤其是任务导向型对话系统的技术研究",字节的TRAE(AI程序员)团队明确说"负责代码场景的效果优化,深入研究LLM后训练等相关技术"。这个方向的特点是技术深度和工程化并重。你既要懂传统NLP的意图识别、槽位填充、对话状态跟踪,也要知道大模型时代怎么做端到端对话;既要理解代码大模型的训练技巧(FIM、Pass@k评测),也要会用AI编程工具构建实际的代码生成系统。
最后一个方向是AI工程化与系统设计,这是算法同学最容易忽视但面试必考的内容。阿里云的ABE(AI架构及后端工程师)岗位描述里有一段话特别关键:"系统架构方面:设计系统架构蓝图选择适合的技术栈,通过合理的技术选型和服务拆分,保障系统未来的高可用、可扩展与安全性"。这不是虚的,而是在考你模型服务化部署、高性能推理优化、分布式训练、监控评测这些实打实的工程能力。你的模型训练得再好,不能部署上线就是零。这80道题教你怎么用FastAPI做模型服务,怎么用TensorRT优化推理速度,怎么设计A/B测试框架,怎么监控线上模型的性能衰减。

这六个方向到底在考什么
很多人以为看几篇技术博客就能搞懂Transformer,但面试官会追问"Pre-Norm和Post-Norm哪个训练更稳定,为什么"。这种问题不是死记硬背能应付的,你得真正理解Layer Normalization在梯度传播中的作用,知道Post-Norm在深层网络中容易梯度爆炸,所以现在主流模型都用Pre-Norm。大模型基础 梳理了100道题就是按照这个思路设计的:不只是告诉你答案,而是引导你理解背后的原理。
比如在"大模型训练流程"这个模块,我不会只问"什么是SFT",而是会连环追问:"指令微调的数据怎么构造?什么样的指令数据是高质量的?单轮对话和多轮对话的SFT数据有什么区别?RLHF为什么要用PPO算法而不是直接监督学习?DPO相比RLHF简化了什么?"每一问都在逼你往深层次思考。再比如"Prompt Engineering"这个模块,从Zero-shot到Few-shot,从Chain of Thoughts到Tree of Thoughts,从Self-Consistency到角色设定,每道题都直指实际应用中的关键问题。
AI Agent开发这100道题是我花心思最多的部分,因为这个领域太新了,很多概念还在快速演化。我把它分成了九个子模块:Agent基础理论、LangChain框架、LangGraph工作流、MCP协议、实践应用、Agent进阶理论、Multi-Agent系统、RAG系统优化、Agent评测与生产化。前50题是基础和框架使用层面,后50题是进阶理论和系统设计层面。
这里有个关键认知:Agent不是单纯的大模型调用,而是一个完整的系统工程。你需要理解ReAct模式为什么能提升推理能力------因为它把思考(Reasoning)和行动(Acting)交织在一起,让模型在执行中不断调整策略。你要知道Reflexion的自我反思机制是怎么工作的------通过评估自己的输出质量,识别错误并重新规划。你要懂Tree of Thoughts和Chain of Thoughts的本质差异------前者是树状搜索空间,后者是线性推理链,处理复杂问题时ToT能探索更多可能性。
但光理解理论还不够,你得会用LangChain和LangGraph。LangChain的核心价值在于它把LLM应用开发中的常见模式抽象成了可复用组件。就像Spring框架让Java开发者不用每次都写JDBC连接代码一样,LangChain让你不用每次都处理提示词拼接、对话历史管理、工具调用逻辑。它的LCEL(LangChain Expression Language)语法让链式调用变得简洁优雅,Memory组件解决了对话上下文管理这个老大难问题,Tool集成提供了标准化的外部工具接口。
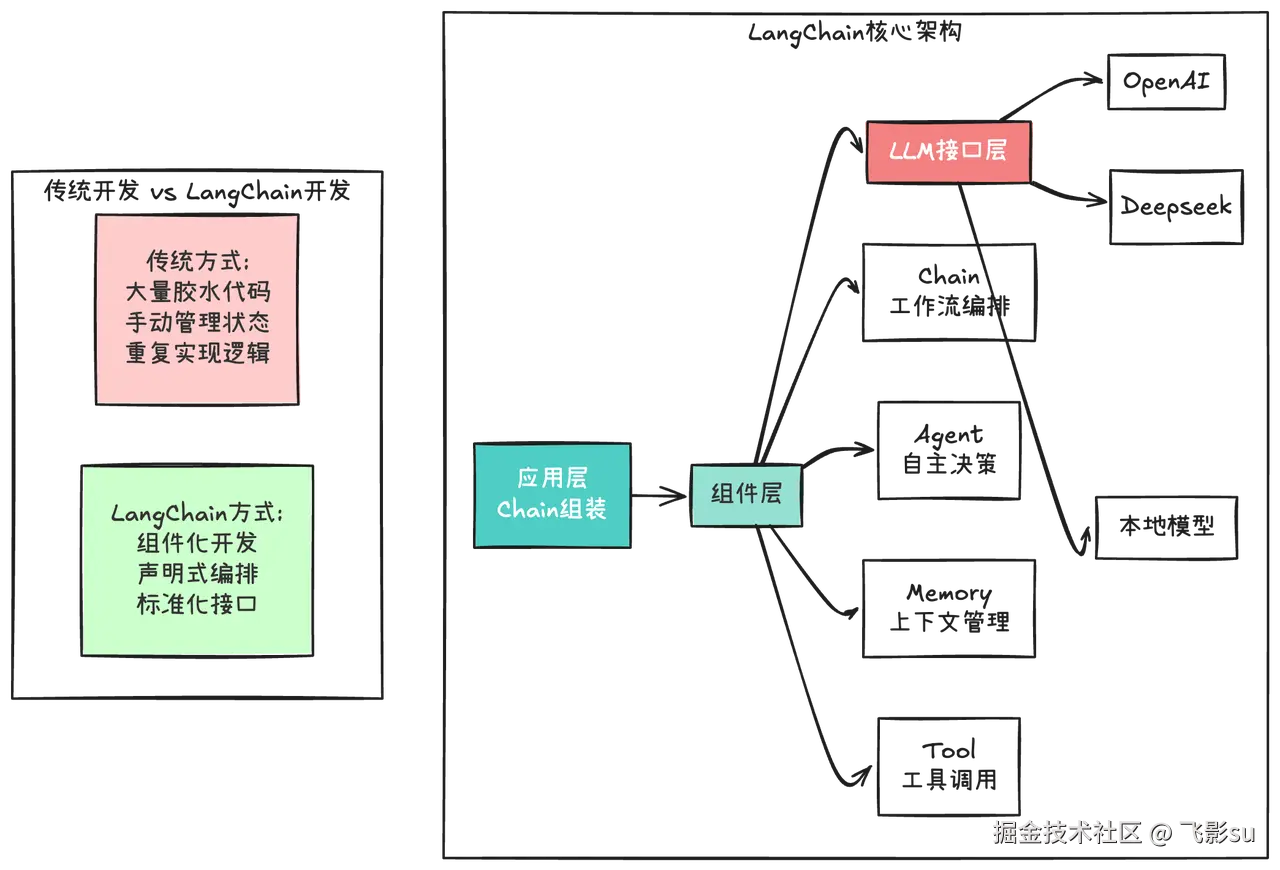
LangGraph更进一步,用图状态机的方式处理复杂的多步骤流程。当你需要实现"先理解用户需求→判断需要什么数据→调用相应工具→综合结果生成回答"这种有分支、有循环的流程时,LangGraph的StateGraph让你能够清晰地定义每个节点的功能、节点之间的连接关系、条件分支的判断逻辑。它的持久化机制让你可以保存执行状态,支持中断续传;它的人机交互功能让你可以在关键节点暂停等待用户确认。
Multi-Agent系统是Agent方向的进阶话题,也是2025年的技术热点。AutoGPT、BabyAGI这些项目你可能听说过,但你真的理解它们的工作原理吗?Manager-Worker模式怎么实现任务分配?Agent之间怎么通信才能避免信息冲突?辩论模式如何通过多个Agent的观点碰撞提升答案质量?这12道题会带你深入Multi-Agent的协作机制,理解涌现行为(Emergent Behavior)是怎么产生的。
RAG(检索增强生成)系统优化那15道题是Agent开发中最实用的部分。当你构建一个企业知识库问答系统时,会遇到一系列具体问题:文档怎么切分才能既保持语义完整又控制chunk大小?用什么Embedding模型效果最好?稀疏检索和稠密检索怎么结合?检索到的文档怎么重排序?这些问题的答案直接决定了系统的可用性。我特意加入了Semantic Chunking、混合检索(Hybrid Search)、HyDE(假设性文档嵌入)、GraphRAG这些前沿技术,因为它们正在被大厂实际采用。
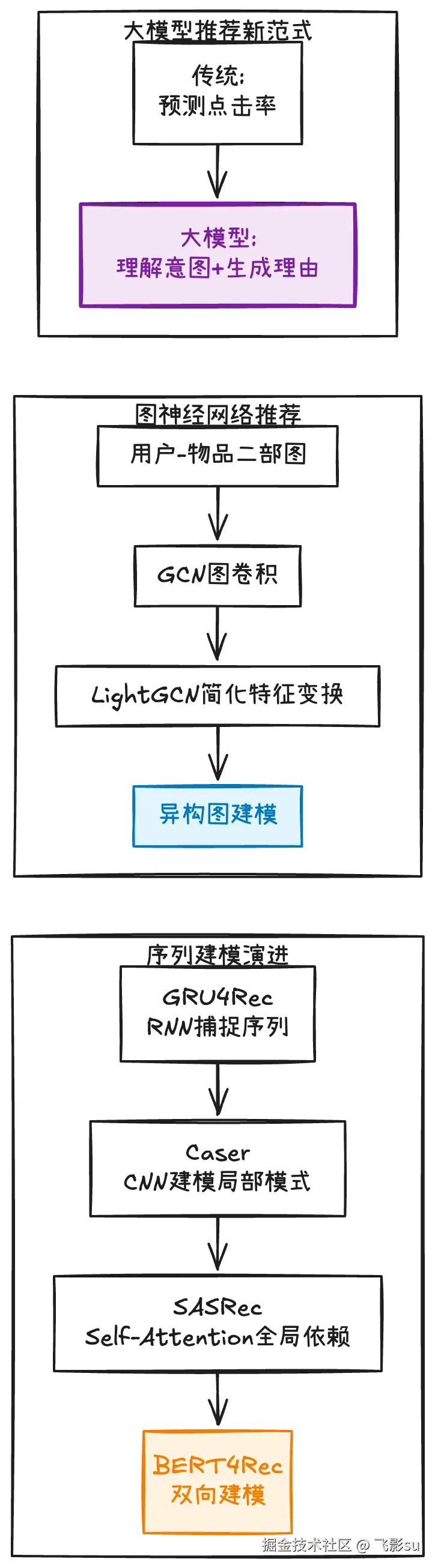
推荐与搜索算法这80道题专门针对投递腾讯推荐算法、字节广告算法这类岗位的同学。推荐系统是个很成熟的领域,从2010年的协同过滤到2015年的矩阵分解,从2018年的深度学习模型到2020年的图神经网络,技术演进路线很清晰。但2025年的推荐已经不是2022年的推荐了。大模型的介入让推荐范式发生了根本性改变:以前是"根据用户历史行为预测点击率",现在可以"理解用户的真实意图并生成个性化推荐理由"。
所以这80道题既包括经典内容(Wide&Deep、DeepFM、DIN、DIEN、DCN这些深度学习模型),也加入了前沿话题:"LLM能直接做推荐吗?和传统推荐模型有什么区别?""怎么用大模型生成推荐理由?""推荐系统的Prompt怎么设计?"这些都是2025年面试的新考点。更重要的是,我加入了"推荐系统全链路"的系统性思考:从召回到粗排到精排到重排,每一层在干什么,为什么要分这么多层,不同层的模型复杂度怎么权衡。
推荐系统的另一个重点是序列建模和图神经网络。用户的行为不是孤立的,而是有时序关系的序列。怎么建模用户兴趣的演化?GRU4Rec用RNN捕捉序列特征,SASRec用Transformer的Self-Attention,BERT4Rec用双向建模。哪个更好?没有绝对答案,取决于具体场景。图神经网络在推荐中的应用更有意思,因为用户-物品-标签构成的异构图天然包含了丰富的结构信息。LightGCN为什么在推荐场景中简化了特征变换?因为推荐任务更关注节点之间的连接关系,而不是节点本身的特征。这种对技术选型背后逻辑的理解,才是面试官想要的。
多模态AI技术这80道题覆盖了从图文多模态到3D视觉的完整技术链条。CLIP是多模态的基石,它用对比学习(Contrastive Learning)让视觉和语言在同一个特征空间中对齐。理解CLIP就理解了为什么大模型能够"看懂"图片------因为图像和文本的Embedding在高维空间中语义相近的会聚在一起。BLIP-2的Q-Former更进一步,它像一个翻译器,把视觉特征转换成语言模型能理解的格式。
图像生成部分是AIGC岗位的必考内容。Diffusion模型的核心原理是什么?前向过程逐步加噪,反向过程逐步去噪,通过学习噪声预测网络来生成图像。Stable Diffusion为什么要在Latent Space做扩散?因为直接在像素空间计算量太大,先用VAE把图像压缩到低维空间,既保留了语义信息又大幅降低了计算成本。ControlNet怎么实现可控生成?通过添加额外的控制条件(边缘、深度、姿态),让生成过程能够遵循特定的结构约束。LoRA为什么微调这么快?因为它只训练低秩分解的小矩阵,而不是调整整个模型参数。
视频理解比图像理解多了时序维度,这带来了新的挑战。TimeSformer怎么设计时空注意力?Sora怎么生成长时间一致性的高质量视频?这些前沿技术虽然还在快速演进,但核心思想是明确的:用Transformer处理视频序列,在时间和空间两个维度上建模依赖关系。3D视觉是个相对小众但很有前景的方向,字节的PICO团队在招3D视觉算法工程师,要求"在NeRF/3DGS、SFM/SLAM/VIO、3D Avatar等领域有研究和实践经验"。这15道3D题目从多视图几何到三维重建,从点云处理到文本生成3D,帮你建立起3D视觉的基本框架。
NLP与代码智能这80道题分成五个部分,每个部分针对一个具体应用场景。对话系统是NLP的经典应用,但大模型时代的对话系统和传统Pipeline式的已经很不一样了。传统方式是NLU(自然语言理解)→DST(对话状态跟踪)→Policy(对话策略)→NLG(自然语言生成)这样的模块化流程,每个模块单独训练。现在可以用端到端的方式,直接让大模型处理整个对话流程。但你既要懂新范式,也要懂传统方法,因为在资源受限或对可控性要求高的场景下,模块化方法仍然有价值。
知识图谱部分包括命名实体识别(NER)、关系抽取、知识推理,以及知识图谱和大模型的结合方式。这个方向的面试题特别强调"联合建模"的思想:为什么联合做意图识别和槽位填充比分开做效果更好?因为两个任务之间有强依赖关系,联合建模可以让信息在两个任务之间流动,提升整体性能。为什么知识图谱能增强RAG系统?因为图谱提供的是结构化知识,可以做多跳推理,而纯向量检索只能做语义匹配。
代码智能是2025年的超级热点。字节的TRAE团队、GitHub Copilot、Cursor这些产品已经深刻改变了开发者的工作方式。代码大模型和文本大模型有什么本质区别?代码有明确的语法约束和逻辑结构,不能像自然语言那样模糊表达。FIM(Fill-in-the-Middle)为什么对代码补全重要?因为代码编写经常是在函数中间插入逻辑,而不是从头到尾顺序生成。Pass@k这个评测指标是什么意思?生成k个候选答案,只要有一个能通过测试就算成功,这比单次生成的准确率更能反映实际使用体验。
更进阶的是代码Agent:怎么让AI自动写代码、改代码、测代码?这不是简单的代码生成,而是要理解需求、规划任务、调用工具、验证结果的完整流程。Devin、OpenDevin这些AI程序员能做什么?它们可以读取文件、运行终端命令、浏览网页、编辑代码,具备了基本的软件工程能力。但目前的局限也很明显:对复杂需求的理解还不够深入,生成的代码可靠性还不够高,需要人工审查和修正。理解这些能力边界,才能在面试中展现出对技术的清醒认知。
AI工程化与系统设计这80道题是从算法到生产的桥梁。很多算法同学觉得自己只要把模型调好就行了,部署的事交给工程师。但实际上,阿里云的ABE岗位、字节的AI应用研发岗位,都明确要求你"具备深厚的后端技术功底,对主流技术栈有深入的理解和实践"。这意味着什么?意味着你不仅要懂算法,还要知道怎么把模型变成能稳定运行的服务。
模型服务化这块,面试官会问你一些很具体的问题。FastAPI为什么适合做模型服务?因为它原生支持异步处理,可以在等待模型推理时处理其他请求,提高并发能力。ONNX格式有什么好处?跨框架通用,PyTorch训练的模型可以在TensorFlow或其他推理引擎上运行。TensorRT怎么优化推理速度?通过算子融合、精度校准、内存优化等技术,可以让推理速度提升3-5倍。这些都不是理论问题,而是你在实际部署中必然会遇到的工程挑战。
高性能推理的核心是理解瓶颈在哪里。模型推理的性能瓶颈可能是计算、IO、内存或网络,不同场景下主要矛盾不同。批处理(Batching)为什么能提升吞吐量?因为GPU是并行计算设备,处理8个样本和处理1个样本的时间差不多,所以把多个请求合并成一个batch可以大幅提高GPU利用率。但batch太大又会增加延迟,因为要等够一定数量的请求才能开始处理。动态批处理就是在延迟和吞吐量之间找平衡,根据实时请求量动态调整batch size。
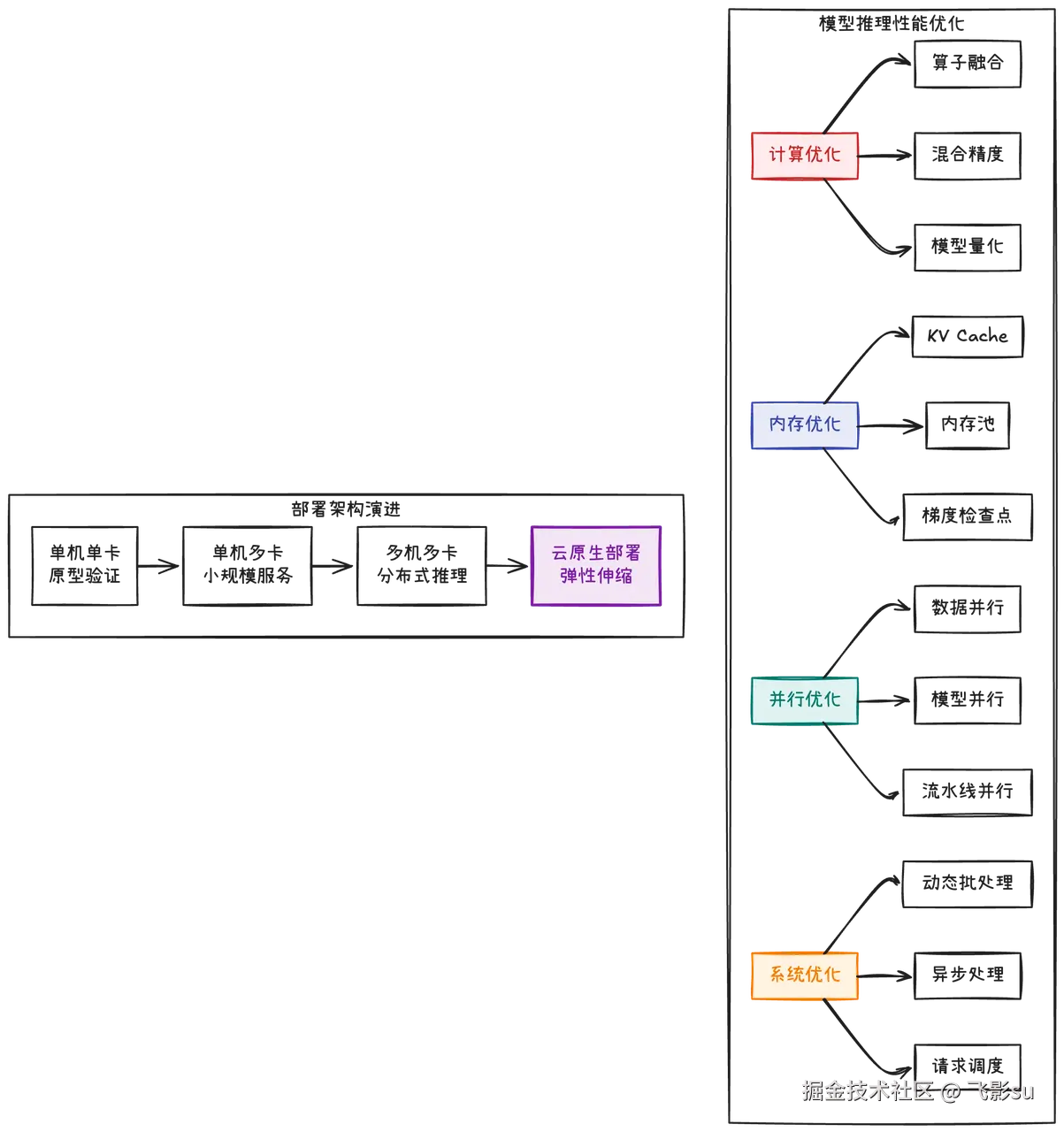
分布式训练是大模型时代的必备技能。数据并行、模型并行、流水线并行这三种并行策略的区别是什么?数据并行是每个GPU有完整模型,处理不同数据,梯度需要All-Reduce同步;模型并行是把模型切分到不同GPU上,每个GPU只有部分参数;流水线并行是把模型按层切分,形成流水线。什么时候用哪种?模型小数据大用数据并行,模型大用模型并行,超大模型用混合并行。
ZeRO优化器是微软提出的显存优化方案,它的三个阶段分别优化了什么?Stage 1只分片优化器状态,Stage 2还分片梯度,Stage 3连模型参数也分片。每深入一层,显存节省更多,但通信开销也更大。DeepSpeed和PyTorch DDP有什么区别?DeepSpeed实现了ZeRO,支持更大模型的训练,还有很多工程优化;DDP只实现了基础的数据并行,但更轻量更稳定。这种对工具选型的判断能力,是面试中的加分项。
数据处理与特征工程这个模块容易被忽视,但其实很重要。深度学习时代特征工程还重要吗?对于结构化数据仍然很重要,类别特征的编码方式、数值特征的归一化方法,直接影响模型效果。向量数据库的选择也是个技术活,Faiss适合离线场景,Milvus适合在线服务,Pinecone是云服务。它们的索引方式不同:IVF(倒排索引)、HNSW(图索引)、PQ(乘积量化),各有优劣。
监控与评测是生产系统的生命线。模型上线后怎么监控性能?QPS(每秒请求数)、延迟(P50/P90/P99)、错误率是基础指标。但更重要的是业务指标:推荐系统的CTR、转化率,对话系统的用户满意度,代码生成的Pass@k。数据漂移(Data Drift)怎么检测?比较线上数据分布和训练数据分布,如果KL散度超过阈值就说明分布发生了偏移,需要重新训练模型。
A/B测试是验证模型效果的金标准。怎么设计A/B测试?分流策略怎么定,对照组和实验组的样本量怎么算,统计显著性怎么判断,这些都是实际工程中的关键问题。更进阶的是多臂老虎机(Multi-Armed Bandit)算法,它比A/B测试更高效,可以动态调整流量分配,让好的策略尽快获得更多流量。
这520道题构成的知识网络
这六套题库总共520道题,它们不是孤立的。当你学Agent开发时,会遇到RAG系统;RAG涉及到向量数据库,这就连接到了工程化部分的数据处理;RAG的检索质量评估,又和监控评测相关。当你学推荐算法时,会看到序列建模用到了Transformer;理解Transformer就要回到大模型基础;而推荐系统的线上部署,又需要工程化的知识。这520道题构成了一个知识网络,你学得越多,就越能发现它们之间的内在联系。
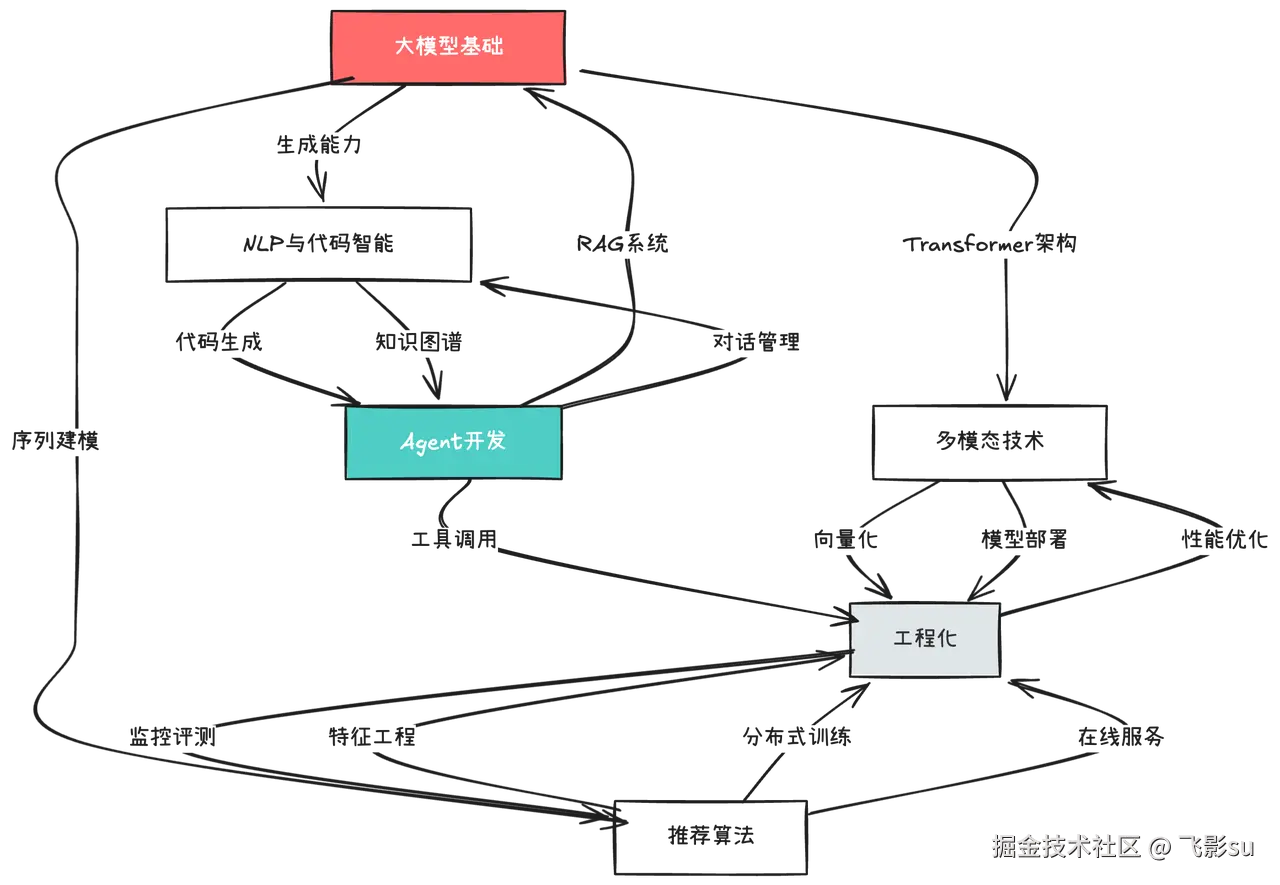
更重要的是,这些题目不是为了难倒你,而是为了帮你建立系统性的认知。每道题背后都对应着实际工作中会遇到的场景。"大模型的幻觉问题怎么缓解"这个问题,对应的是你做客服机器人时怎么保证回答的准确性;"LangChain的Memory组件怎么工作",对应的是你构建多轮对话系统时怎么管理上下文;"推荐系统的冷启动怎么处理",对应的是新用户来了怎么给他推荐内容;"Stable Diffusion的ControlNet怎么用",对应的是你做图像生成应用时怎么让结果可控。
面试官问这些问题的时候,表面上是在考察技术细节,实际上想要了解的是:**你是否具备构建复杂AI应用的能力?你是否理解技术选型背后的权衡?你是否能把学到的知识应用到实际问题中?**所以答题的时候,不要只说是什么,还要说为什么,更要说在什么场景下怎么用。
举个例子,面试官问"什么是ReAct模式",初级回答是"Reasoning和Acting结合的推理方式"。进阶回答是"ReAct让模型在推理过程中可以调用工具获取外部信息,然后根据观察结果调整推理方向,比纯粹的思维链推理更适合需要实时信息的场景"。高级回答是"ReAct解决了LLM知识截止日期的问题,比如用户问'今天天气怎么样',模型可以先推理出需要调用天气API,然后执行工具调用,获取实时天气数据,最后整合信息生成回答。但ReAct的局限是每次工具调用都要等模型推理,延迟较高,所以后来出现了ReWOO这种先规划所有工具调用再批量执行的优化方案"。
这种从技术细节到应用场景再到优化方向的完整思考链条,才是面试官想看到的。而这种思考能力,恰恰是通过系统性地刷题、深度理解每个技术点的来龙去脉、不断追问"为什么"和"怎么用"培养出来的。
写在最后的话
转眼2025年10月,距离大部分企业的秋招截止只剩下一两个月。如果你现在才开始准备,确实有点晚了。但技术学习从来不是为了应付一次面试,而是为了建立长期的竞争力。即使这个秋招没有拿到理想的offer,掌握了这些技术,春招、社招、实习机会依然等着你。
AI技术的变化速度确实很快,今年的热点可能是Agent和多模态,明年可能又会有新的方向。但技术演进有其内在逻辑,大模型基础、系统工程化、垂直领域应用这些核心能力是不变的。打好基础,建立系统性的知识框架,培养快速学习新技术的能力,比追逐每一个热点更重要。
这些题不能保证你一定能拿到offer,但它们能让你在面试中更有底气。当面试官问"什么是Tree of Thoughts"时,你不会一脸茫然;问"怎么优化模型推理延迟"时,你能说出三四种方法并分析各自的适用场景;问"Agent的幻觉问题怎么解决"时,你能结合RAG、Self-Refinement、人工审核等多个维度给出系统性的回答。这种扎实的技术功底和清晰的表达能力,才是通过秋招的关键。
最后想说的是,技术学习是个孤独的过程,尤其是在准备秋招的这几个月。你可能会看到别人拿到offer而焦虑,可能会因为一道题卡壳而沮丧,可能会怀疑自己是不是不适合做技术。但请记住,每个最终拿到好offer的人,都经历过这个过程。区别只在于,有些人坚持下来了,有些人放弃了。
这些题目更多的是我个人的理解,它们不是万能钥匙,但希望至少是一张清晰的地图,能告诉你大厂到底在考什么,你需要掌握哪些技能,怎样建立系统性的认知。剩下的路,需要你自己走。相信自己,保持专注,持续学习,机会终会眷顾有准备的人。
下面是我梳理的题目列表:
这是大模型第 100 题的面试详析: 热题解析:2025年大模型技术发展的趋势是什么?下一个breakthrough会是什么?
更多详情,可见: 牛面题库 我也会挑选评论最多的题进行深度打磨,同步到这里。2025的秋招战场已经打响,愿每个努力的人都能收获满意的结果。加油,同学们!!!