這份程式是為了輔助說明李宏毅教授《生成式人工智慧及機器學習導論》第三講的觀念,目的是透過執行此程式,讓學生更清楚理解大型語言模型內部的類神經網路如何運作。在開始執行之前,請先點選上方工具列的「檔案」,選擇「在雲端硬碟中儲存副本」,再於自己的副本中進行操作。
python
!pip install -U transformers #安裝 HuggingFace Transformers 套件
import torch Requirement already satisfied: transformers in /usr/local/lib/python3.12/dist-packages (4.56.1)
Collecting transformers
Downloading transformers-4.56.2-py3-none-any.whl.metadata (40 kB)
[?25l [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m0.0/40.1 kB[0m [31m?[0m eta [36m-:--:--[0m
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m40.1/40.1 kB[0m [31m3.4 MB/s[0m eta [36m0:00:00[0m
[?25hRequirement already satisfied: filelock in /usr/local/lib/python3.12/dist-packages (from transformers) (3.19.1)
Requirement already satisfied: huggingface-hub<1.0,>=0.34.0 in /usr/local/lib/python3.12/dist-packages (from transformers) (0.35.0)
Requirement already satisfied: numpy>=1.17 in /usr/local/lib/python3.12/dist-packages (from transformers) (2.0.2)
Requirement already satisfied: packaging>=20.0 in /usr/local/lib/python3.12/dist-packages (from transformers) (25.0)
Requirement already satisfied: pyyaml>=5.1 in /usr/local/lib/python3.12/dist-packages (from transformers) (6.0.2)
Requirement already satisfied: regex!=2019.12.17 in /usr/local/lib/python3.12/dist-packages (from transformers) (2024.11.6)
Requirement already satisfied: requests in /usr/local/lib/python3.12/dist-packages (from transformers) (2.32.4)
Requirement already satisfied: tokenizers<=0.23.0,>=0.22.0 in /usr/local/lib/python3.12/dist-packages (from transformers) (0.22.0)
Requirement already satisfied: safetensors>=0.4.3 in /usr/local/lib/python3.12/dist-packages (from transformers) (0.6.2)
Requirement already satisfied: tqdm>=4.27 in /usr/local/lib/python3.12/dist-packages (from transformers) (4.67.1)
Requirement already satisfied: fsspec>=2023.5.0 in /usr/local/lib/python3.12/dist-packages (from huggingface-hub<1.0,>=0.34.0->transformers) (2025.3.0)
Requirement already satisfied: typing-extensions>=3.7.4.3 in /usr/local/lib/python3.12/dist-packages (from huggingface-hub<1.0,>=0.34.0->transformers) (4.15.0)
Requirement already satisfied: hf-xet<2.0.0,>=1.1.3 in /usr/local/lib/python3.12/dist-packages (from huggingface-hub<1.0,>=0.34.0->transformers) (1.1.10)
Requirement already satisfied: charset_normalizer<4,>=2 in /usr/local/lib/python3.12/dist-packages (from requests->transformers) (3.4.3)
Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.12/dist-packages (from requests->transformers) (3.10)
Requirement already satisfied: urllib3<3,>=1.21.1 in /usr/local/lib/python3.12/dist-packages (from requests->transformers) (2.5.0)
Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.12/dist-packages (from requests->transformers) (2025.8.3)
Downloading transformers-4.56.2-py3-none-any.whl (11.6 MB)
[2K [90m━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━[0m [32m11.6/11.6 MB[0m [31m76.0 MB/s[0m eta [36m0:00:00[0m
[?25hInstalling collected packages: transformers
Attempting uninstall: transformers
Found existing installation: transformers 4.56.1
Uninstalling transformers-4.56.1:
Successfully uninstalled transformers-4.56.1
Successfully installed transformers-4.56.2以下程式碼將登入 Hugging Face Hub,以便接下來取得模型。但在此之前,我們需先取得 Hugging Face 的「Token」(此處的 Token 指的是認證憑證,與生成式 AI 中的 token 無關)。有關 Hugging Face Token 的取得與使用方式,請參閱作業一助教投影片:https://speech.ee.ntu.edu.tw/\~hylee/GenAI-ML/2025-fall-course-data/hw1.pdf
python
from huggingface_hub import login
login(new_session=False)我們將下載位於此頁面的模型:https://huggingface.co/meta-llama/Llama-3.2-3B-Instruct
如果你之前沒有使用過這個模型,在上述頁面中你可能會看到一行提示:「You need to agree to share your contact information to access this model」。這是因為使用 Llama 模型需要先簽署使用者同意書(並不是每個模型都需要簽署同意書)。請依照該頁面上的指示完成簽署,之後你會收到一封通知信,告知審查是否通過,通過後才能開始使用。這個過程有時可能需要數個小時。詳情請參閱助教投影片。
執行以下程式碼後,我們會從 Hugging Face Hub 下載 tokenizer 和 model 兩個物件。tokenizer 紀錄了模型所使用的 token,而 model 則儲存了模型的參數。下載過程可能需要數分鐘,請耐心等候。
python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-3.2-3B-Instruct")
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-3.2-3B-Instruct")
#如果是 Colab 的免費使用者,可能會無法載入 3B 模型,這個時候可以把 3B 換成 1Btokenizer_config.json: 0%| | 0.00/54.5k [00:00<?, ?B/s]
tokenizer.json: 0%| | 0.00/9.09M [00:00<?, ?B/s]
special_tokens_map.json: 0%| | 0.00/296 [00:00<?, ?B/s]
config.json: 0%| | 0.00/878 [00:00<?, ?B/s]
model.safetensors.index.json: 0%| | 0.00/20.9k [00:00<?, ?B/s]
Fetching 2 files: 0%| | 0/2 [00:00<?, ?it/s]
model-00001-of-00002.safetensors: 0%| | 0.00/4.97G [00:00<?, ?B/s]
model-00002-of-00002.safetensors: 0%| | 0.00/1.46G [00:00<?, ?B/s]
Loading checkpoint shards: 0%| | 0/2 [00:00<?, ?it/s]
generation_config.json: 0%| | 0.00/189 [00:00<?, ?B/s]我們另外下載位於此頁面的模型: https://huggingface.co/google/gemma-3-4b-it
python
tokenizer2 = AutoTokenizer.from_pretrained("google/gemma-3-4b-it")
model2 = AutoModelForCausalLM.from_pretrained("google/gemma-3-4b-it")
#如果是 Colab 的免費使用者,可能會無法跑第二的模型, 這時請將這個 block 直接註解掉tokenizer_config.json: 0%| | 0.00/1.16M [00:00<?, ?B/s]
tokenizer.model: 0%| | 0.00/4.69M [00:00<?, ?B/s]
tokenizer.json: 0%| | 0.00/33.4M [00:00<?, ?B/s]
added_tokens.json: 0%| | 0.00/35.0 [00:00<?, ?B/s]
special_tokens_map.json: 0%| | 0.00/662 [00:00<?, ?B/s]
config.json: 0%| | 0.00/855 [00:00<?, ?B/s]
model.safetensors.index.json: 0%| | 0.00/90.6k [00:00<?, ?B/s]
Fetching 2 files: 0%| | 0/2 [00:00<?, ?it/s]
model-00002-of-00002.safetensors: 0%| | 0.00/3.64G [00:00<?, ?B/s]
model-00001-of-00002.safetensors: 0%| | 0.00/4.96G [00:00<?, ?B/s]
Loading checkpoint shards: 0%| | 0/2 [00:00<?, ?it/s]
generation_config.json: 0%| | 0.00/215 [00:00<?, ?B/s]我們來看看 model 中有什麼
我們先來看看我們載入的模型總共有幾個參數。model是Llama-3.2-3B-Instruct,model2是google/gemma-3-4b-it
model.num_parameters() 會告訴我們 model 的參數量
python
model.num_parameters() #我們來看看 model (meta-llama/Llama-3.2-3B-Instruct) 的參數量3212749824
python
model2.num_parameters() #我們來看看 model2 (google/gemma-3-4b-it) 的參數量4300079472深度學習模型的參數通常以多個矩陣(Matrix)和向量(Vector)的形式儲存(向量、矩陣等統稱為張量(Tensor))。
在模型中,每個包含參數的張量在 model 中具有以下資訊:
- 名稱(name) :表示該參數在模型結構中的位置,例如
model.layers.0.mlp.up_proj.weight,這是第一個 transformer layer 中第一層 MLP 的參數。 - 形狀(shape) :表示該張量的維度,例如
(8192, 3072),代表這是一個矩陣,其中一維為 8192,另一維為 3072。
我們可以用 named_parameters() 方法來逐一查看這些參數。
python
for name, param in model.named_parameters():
print(f"{name:80} | shape: {tuple(param.shape)}")
#根據輸出,Llama-3.2-3B-Instruct 有幾層呢?model.embed_tokens.weight | shape: (128256, 3072)
model.layers.0.self_attn.q_proj.weight | shape: (3072, 3072)
model.layers.0.self_attn.k_proj.weight | shape: (1024, 3072)
model.layers.0.self_attn.v_proj.weight | shape: (1024, 3072)
model.layers.0.self_attn.o_proj.weight | shape: (3072, 3072)
model.layers.0.mlp.gate_proj.weight | shape: (8192, 3072)用 model.state_dict() 可以實際把參數拿出來看看
python
model.state_dict()OrderedDict([('model.embed_tokens.weight',
tensor([[ 1.1292e-02, 9.9487e-03, 1.4160e-02, ..., -3.5706e-03,
-1.9775e-02, 5.3711e-03],
[ 1.3245e-02, -3.8385e-05, 2.2461e-02, ..., -2.6550e-03,
3.1738e-02, -1.0681e-03],
[ 1.9775e-02, 2.0020e-02, 2.8687e-02, ..., -3.5248e-03,
3.1433e-03, -7.6294e-03],
...,
[-3.0975e-03, 2.1057e-03, 4.8828e-03, ..., -2.0905e-03,
-1.2207e-03, -2.8992e-03],
[-3.0975e-03, 2.1057e-03, 4.8828e-03, ..., -2.0905e-03,
-1.2207e-03, -2.8992e-03],
[-3.0975e-03, 2.1057e-03, 4.8828e-03, ..., -2.0905e-03,
-1.2207e-03, -2.8992e-03]])),
('model.layers.0.self_attn.q_proj.weight',
tensor([[-0.0327, 0.0297, 0.0645, ..., 0.0835, -0.0356, -0.0197],
[-0.0099, -0.0227, 0.0439, ..., 0.0525, -0.0053, -0.0349],
[ 0.0214, 0.0134, 0.0352, ..., 0.0503, -0.0415, -0.0129],
...,
[ 0.0021, -0.0085, 0.0615, ..., -0.0105, 0.0020, 0.0067],
[ 0.0079, -0.0128, 0.0205, ..., -0.0103, -0.0214, 0.0051],
[-0.0085, 0.0251, -0.0089, ..., 0.0081, 0.0053, -0.0081]])),
python
weight = model.state_dict()["model.layers.27.mlp.up_proj.weight"].numpy()
#上面這段程式碼可以分成三個步驟來看:1. state_dict() 2. ["參數名稱"] 3. .numpy()
# model.state_dict() 方法會回傳一個字典(dict),其鍵(key)為參數名稱,值(value)為張量(Tensor)。
# 可以使用 [] 根據 key 取得對應的 value。
# 這裡的 value 是一個 PyTorch Tensor,.numpy() 會把 Tensor 轉成 NumPy 格式的陣列
print(weight)
#把 weight 中前100×100區塊畫出來
import matplotlib.pyplot as plt
plt.imshow(weight[:100, :100], cmap="RdBu")
plt.colorbar()
plt.show()
#其實看不出甚麼名堂,對吧 ....[[-0.01361084 -0.04003906 0.01977539 ... 0.02197266 -0.00186157
0.01782227]
[-0.02233887 -0.00927734 -0.0100708 ... -0.00112152 0.02392578
-0.03149414]
[ 0.01177979 0.01953125 -0.01135254 ... 0.00830078 0.01123047
0.0222168 ]
...
[ 0.04052734 0.02758789 -0.00708008 ... 0.02209473 0.00053024
-0.02124023]
[ 0.00256348 -0.01104736 -0.03173828 ... 0.00680542 -0.00952148
0.00187683]
[-0.00830078 0.02722168 0.00230408 ... -0.02453613 0.00457764
-0.04492188]]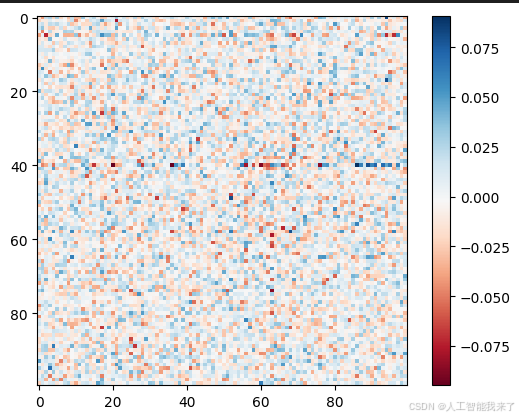
觀察語言模型中的 Embedding Table
python
#先取出model中的 embedding table
input_embedding = model.state_dict()["model.embed_tokens.weight"].numpy()先來看看 input_embedding 的形狀(shape)。
python
'''
把 input_embedding 的 shape 輸出出來觀察看看
你會看到 `(128256, 3072)`,表示 `input_embedding` 是一個具有 128,256 列(row)和 3,072 行(column)的矩陣。
- **128256** → 詞彙表(vocabulary)的大小,共有 128,256 個不同的 token。
- **3072** → 每個 token 以一個 3,072 維度的向量表示。
換句話說,每一列(row)對應到一個 token。
'''
print(input_embedding.shape)(128256, 3072)
python
#把 input_embedding 輸出出來觀察看看
print(input_embedding)
#嗯 ... 其實還是看不出甚麼名堂[[ 1.1291504e-02 9.9487305e-03 1.4160156e-02 ... -3.5705566e-03
-1.9775391e-02 5.3710938e-03]
[ 1.3244629e-02 -3.8385391e-05 2.2460938e-02 ... -2.6550293e-03
3.1738281e-02 -1.0681152e-03]
[ 1.9775391e-02 2.0019531e-02 2.8686523e-02 ... -3.5247803e-03
3.1433105e-03 -7.6293945e-03]
...
[-3.0975342e-03 2.1057129e-03 4.8828125e-03 ... -2.0904541e-03
-1.2207031e-03 -2.8991699e-03]
[-3.0975342e-03 2.1057129e-03 4.8828125e-03 ... -2.0904541e-03
-1.2207031e-03 -2.8991699e-03]
[-3.0975342e-03 2.1057129e-03 4.8828125e-03 ... -2.0904541e-03
-1.2207031e-03 -2.8991699e-03]]
python
#編號為 `token_id` 的 token,其對應的 embedding 就是 `input_embedding` 的第 `token_id` 個列(row)(從 0 開始計數)。
#以下輸出編號為 `token_id` 的 token 以及其對應的 embedding。
token_id = 2
# 從 tokenizer 取得對應 token_id 的 token(文字)
token = tokenizer.decode(token_id)
# 取得該 token 的向量
embedding_vector = input_embedding[token_id]
print(f"Token ID: {token_id}")
print(f"對應的 Token: {token}")
print(f"Token Embedding: {embedding_vector}")Token ID: 2
對應的 Token: #
Token Embedding: [ 0.01977539 0.02001953 0.02868652 ... -0.00352478 0.00314331
-0.00762939]直接觀察 embedding 的數值其實看不出太多資訊,但我們可以計算 token 之間的 embedding 相似程度
這樣就能知道對於這個語言模型來說,哪些 token 的意義是相似的。
這段程式是要讓我們:
- 輸入一個 token(例如
"apple") - 找到它的
token_id(例如"apple") - 根據
token_id從input_embedding中取得它的 embedding - 使用 cosine similarity 計算它與其他所有 token 的 embedding 相似程度
- 列出最相近的前
top_k個 token
python
top_k = 20 #自己設定一個數值
# 1️⃣ 讓使用者輸入一個 token
token = input('請輸入一個 token:') #輸入: apple, Apple, 李, 王 等等
# 2️⃣ 轉換成 token ID
token_id = tokenizer.encode(token)[1]
# 為什麼是 [1]?
# tokenizer.encode() 回傳的是: [BOS_token_id, token_id ...]
# print (tokenizer.encode(token)) <- 跑這一行試試看
# 第一個元素 [0] 是特殊起始符號 (BOS),
# 我們真正想要的是輸入的那個 token 本身 → 所以取 index 1
print("token id 是 ",token_id)
# 3️⃣ 取得 token 的 embedding
embbeding = [input_embedding[token_id]]
# 4️⃣ 計算餘弦相似度
from sklearn.metrics.pairwise import cosine_similarity
sims = cosine_similarity(embbeding, input_embedding)[0]
# 5️⃣ 排序並取最相近 top_k,並輸出結果
nearest = sims.argsort()[::-1][1: top_k+1] #排除自己本身
print(f'和 {token} 最相近的 {top_k} 個 token:')
for idx in nearest:
print(f'{tokenizer.decode(idx)} (score: {sims[idx]:.4f})')請輸入一個 token:王
token id 是 101538
和 王 最相近的 20 個 token:
王 (score: 0.6938)
왕 (score: 0.5473)
King (score: 0.5002)
왕 (score: 0.4793)
king (score: 0.4721)
KING (score: 0.4715)
King (score: 0.4481)
kings (score: 0.4212)
Vương (score: 0.3803)
kingdom (score: 0.3649)
корол (score: 0.3624)
Kings (score: 0.3473)
kingdoms (score: 0.3430)
king (score: 0.3423)
král (score: 0.3412)
Kingdom (score: 0.3364)
الملك (score: 0.3287)
queen (score: 0.3217)
皇 (score: 0.2942)
vua (score: 0.2941)輸出每一層的 representation
把每一層的 representation 都取出來
!layer.png
python
inputs = tokenizer.encode("大家好", return_tensors="pt")
print("編碼後的 Token IDs:", inputs)
outputs = model(inputs, output_hidden_states=True) # output_hidden_states=True 才會回傳每一層的 representation (hidden states)
hidden_states = outputs.hidden_states
# hidden_states[0] -> embedding (把 token 轉成 token embedding 的結果)
# hidden_states[1] ~ hidden_states[N] -> 每一層 Transformer block 的輸出
print(f"一共拿到 {len(hidden_states)} 層 representation(包含 token embedding)。")
# 列出每層輸出的形狀
for idx, h in enumerate(hidden_states):
print(f"Layer {idx:2d} 輸出形狀: {h.shape}")
# h.shape = [batch_size, seq_len, hidden_size]
# batch_size → 一次處理的句子數
# sequence_length → 句子被切成多少 token
# hidden_size → 每個 token 的向量長度
print("\n=== Token Embedding 輸出 ===")
print(hidden_states[0])
print("\n=== 第一個 Transformer Layer 的輸出 ===")
print(hidden_states[1])編碼後的 Token IDs: tensor([[128000, 109429, 53901]])
一共拿到 29 層 representation(包含 token embedding)。
Layer 0 輸出形狀: torch.Size([1, 3, 3072])
Layer 1 輸出形狀: torch.Size([1, 3, 3072])
Layer 2 輸出形狀: torch.Size([1, 3, 3072])
Layer 3 輸出形狀: torch.Size([1, 3, 3072])
Layer 4 輸出形狀: torch.Size([1, 3, 3072])
Layer 5 輸出形狀: torch.Size([1, 3, 3072])
Layer 6 輸出形狀: torch.Size([1, 3, 3072])
Layer 7 輸出形狀: torch.Size([1, 3, 3072])
Layer 8 輸出形狀: torch.Size([1, 3, 3072])
Layer 9 輸出形狀: torch.Size([1, 3, 3072])
Layer 10 輸出形狀: torch.Size([1, 3, 3072])
Layer 11 輸出形狀: torch.Size([1, 3, 3072])
Layer 12 輸出形狀: torch.Size([1, 3, 3072])
Layer 13 輸出形狀: torch.Size([1, 3, 3072])
Layer 14 輸出形狀: torch.Size([1, 3, 3072])
Layer 15 輸出形狀: torch.Size([1, 3, 3072])
Layer 16 輸出形狀: torch.Size([1, 3, 3072])
Layer 17 輸出形狀: torch.Size([1, 3, 3072])
Layer 18 輸出形狀: torch.Size([1, 3, 3072])
Layer 19 輸出形狀: torch.Size([1, 3, 3072])
Layer 20 輸出形狀: torch.Size([1, 3, 3072])
Layer 21 輸出形狀: torch.Size([1, 3, 3072])
Layer 22 輸出形狀: torch.Size([1, 3, 3072])
Layer 23 輸出形狀: torch.Size([1, 3, 3072])
Layer 24 輸出形狀: torch.Size([1, 3, 3072])
Layer 25 輸出形狀: torch.Size([1, 3, 3072])
Layer 26 輸出形狀: torch.Size([1, 3, 3072])
Layer 27 輸出形狀: torch.Size([1, 3, 3072])
Layer 28 輸出形狀: torch.Size([1, 3, 3072])
=== Token Embedding 輸出 ===
tensor([[[-1.1587e-04, 3.8528e-04, -1.9379e-03, ..., 2.3937e-04,
-5.4550e-04, 8.8215e-05],
[ 5.1880e-03, 4.0894e-03, 7.6294e-03, ..., -3.2715e-02,
-1.1902e-02, -2.4658e-02],
[ 7.2021e-03, -2.0264e-02, -2.5269e-02, ..., -2.6611e-02,
8.9111e-03, -1.4526e-02]]], grad_fn=<EmbeddingBackward0>)
=== 第一個 Transformer Layer 的輸出 ===
tensor([[[-0.0031, 0.0019, 0.0603, ..., 0.0512, 0.0022, -0.0048],
[-0.0056, 0.0010, -0.0419, ..., -0.1158, -0.0507, -0.0496],
[-0.0129, -0.0005, -0.1439, ..., -0.0837, -0.0417, -0.0156]]],
grad_fn=<AddBackward0>)讓我們來比較不同輸入的 representation
python
def get_embedding(text, layer_num):
"""
輸入一句文字,印出模型某一個 layer 的每個 token 的 embedding。
"""
print(f"\n=== {text} ===")
inputs = tokenizer.encode(text, return_tensors="pt", add_special_tokens=False)
#print(inputs)
outputs = model(inputs, output_hidden_states=True)
hidden_states = outputs.hidden_states
hidden_states_layer = hidden_states[layer_num]
tokens = tokenizer.tokenize(text)
seq_length = len(tokens)
for t in range(0,seq_length):
print(tokens[t], ":", hidden_states_layer[0][t])
layer_num = 10 # 0: token embedding, >0: contextualized token embedding
get_embedding("How about you?", layer_num )
get_embedding("How are you?", layer_num )
get_embedding("Nice to meet you.", layer_num )=== How about you? ===
How : tensor([-0.3254, 0.6629, 1.4232, ..., 0.9507, 0.1310, 0.1701],
grad_fn=<SelectBackward0>)
Ġabout : tensor([-0.0063, -0.0318, -0.0029, ..., -0.1065, 0.0559, -0.1470],
grad_fn=<SelectBackward0>)
Ġyou : tensor([-0.0422, -0.0210, -0.0051, ..., 0.2646, -0.1229, 0.1200],
grad_fn=<SelectBackward0>)
? : tensor([ 0.0290, -0.0231, 0.1283, ..., -0.1041, -0.1908, 0.0666],
grad_fn=<SelectBackward0>)
=== How are you? ===
How : tensor([-0.3254, 0.6629, 1.4232, ..., 0.9507, 0.1310, 0.1701],
grad_fn=<SelectBackward0>)
Ġare : tensor([ 0.1900, -0.0635, -0.0485, ..., -0.1537, -0.0083, -0.0462],
grad_fn=<SelectBackward0>)
Ġyou : tensor([-0.0213, 0.2584, -0.1349, ..., -0.0338, -0.1031, 0.0006],
grad_fn=<SelectBackward0>)
? : tensor([-0.1206, -0.0452, 0.1317, ..., -0.0608, -0.1253, 0.0235],
grad_fn=<SelectBackward0>)
=== Nice to meet you. ===
Nice : tensor([-0.2649, 0.6018, 1.2515, ..., 1.0346, 0.2204, 0.1627],
grad_fn=<SelectBackward0>)
Ġto : tensor([ 0.0063, -0.0515, -0.2817, ..., -0.1116, -0.0426, 0.0132],
grad_fn=<SelectBackward0>)
Ġmeet : tensor([-0.1064, 0.0620, 0.0096, ..., 0.0299, -0.0525, 0.1674],
grad_fn=<SelectBackward0>)
Ġyou : tensor([-0.0976, 0.1099, -0.0206, ..., 0.0209, -0.0841, 0.0319],
grad_fn=<SelectBackward0>)
. : tensor([-0.0111, 0.0983, 0.3553, ..., -0.0502, -0.0908, 0.0700],
grad_fn=<SelectBackward0>)
python
#比較 sentence1 和 sentence2 中的 "apple" ,在不同層的相似程度
sentence1 = "I ate an apple for breakfast."
idx1 = 4 # apple 在 "I ate an apple for breakfast." 的位置
#[128000, 40, 30912, 459, 24149, 369, 17954, 13]
sentence2 = "The company that brought us the iPad and AirPods is apple."
idx2 = 13 # apple 在 "The tech company apple announced its earnings yesterday." 的位置
#[128000, 791, 2883, 430, 7263, 603, 279, 23067, 323, 6690, 24434, 82,374, 24149, 13]
inputs1 = tokenizer.encode(sentence1,return_tensors="pt")
outputs1 = model(inputs1, output_hidden_states=True)
hidden_states1 = outputs1.hidden_states
inputs2 = tokenizer.encode(sentence2,return_tensors="pt")
outputs2 = model(inputs2, output_hidden_states=True)
hidden_states2 = outputs2.hidden_states
# 計算每一層的 cosine_similarity
distances = []
for l in range(len(hidden_states)):
vec1 = hidden_states1[l][0][idx1].detach().numpy() # 句子1 中 '▁apple' 的向量
vec2 = hidden_states2[l][0][idx2].detach().numpy() # 句子2 中 '▁apple' 的向量
cos_sim = cosine_similarity([vec1], [vec2])[0]
#print(cos_sim)
distances.append(cos_sim)
# 繪製距離隨層數變化圖
layers = list(range(len(distances)))
plt.figure(figsize=(6, 4))
plt.plot(layers, distances, marker='o')
plt.xticks(layers)
plt.xlabel("no of layer")
plt.ylabel("Cosine sim")
plt.grid(True)
plt.show()
python
sentence1 = "I ate an apple for breakfast."
sentence2 = "The company that brought us the iPad and AirPods is apple."
inputs1 = tokenizer.encode(sentence1, return_tensors="pt")
outputs1 = model(inputs1, output_hidden_states=True)
hidden_states1 = outputs1.hidden_states
inputs2 = tokenizer.encode(sentence2, return_tensors="pt")
outputs2 = model(inputs2, output_hidden_states=True)
hidden_states2 = outputs2.hidden_states
distances = []
for l in range(len(hidden_states)):
layer_hidden_states1 = hidden_states1[l][0].detach().numpy() # Shape: [seq_len1, hidden_size]
layer_hidden_states2 = hidden_states2[l][0].detach().numpy() # Shape: [seq_len2, hidden_size]
# Calculate pairwise cosine similarity between all tokens in sentence1 and sentence2 for this layer
pairwise_sim = cosine_similarity(layer_hidden_states1, layer_hidden_states2) # Shape: [seq_len1, seq_len2]
avg_sim_layer = pairwise_sim.mean()
vec1 = hidden_states1[l][0][idx1].detach().numpy() # 句子1 中 '▁apple' 的向量
vec2 = hidden_states2[l][0][idx2].detach().numpy() # 句子2 中 '▁apple' 的向量
cos_sim = cosine_similarity([vec1], [vec2])[0]
distances.append(cos_sim/avg_sim_layer)
# 繪製距離隨層數變化圖
layers = list(range(len(distances)))
plt.figure(figsize=(6, 4))
plt.plot(layers, distances, marker='o')
plt.xticks(layers)
plt.xlabel("no of layer")
plt.ylabel("Cosine sim / Average")
plt.grid(True)
plt.show()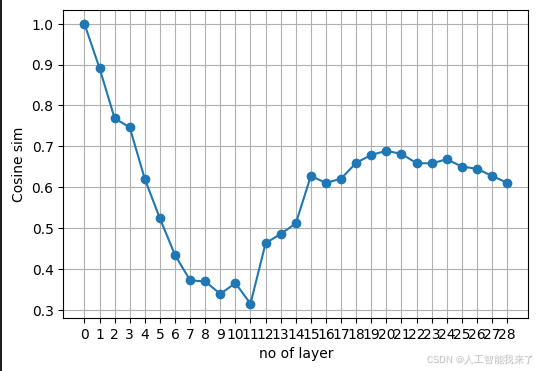
python
# 定義 4 個句子:前兩句是「可食用的 apple」,後兩句是「Apple 公司」
sentences = [
"I ate an apple for breakfast.", # 可食用的 apple 範例 1
"She baked an apple pie for dessert.", # 可食用的 apple 範例 2
"The tech giant apple announced its quarterly earnings.", # Apple 公司範例 1
"Last week the tech giant apple revealed its new iPhone." # Apple 公司範例 2
]
num_sentences = 4
# 編碼並取得所有層的 hidden_states
hidden_states_batch = []
for i in range(num_sentences):
inputs = tokenizer.encode(sentences[i], return_tensors="pt")
#print(inputs)
outputs = model(inputs, output_hidden_states=True)
hidden_states_batch.append(outputs.hidden_states)
# 每句中 'apple' 的索引位置
idxs = [4,4,4,6]
# 為每一對句子組合準備相似度儲存結構
pairs = [(0,1), (0,2), (0,3), (1,2), (1,3), (2,3)]
sim_dict = {pair: [] for pair in pairs}
# 逐層計算每對組合的 Cosine 相似度
num_layer = 28
for l in range(num_layer+1):
for (i, j) in pairs:
vec_i = hidden_states_batch[i][l][0][idxs[i]].detach().numpy()
vec_j = hidden_states_batch[j][l][0][idxs[j]].detach().numpy()
sim = cosine_similarity([vec_i], [vec_j])[0]
sim_dict[(i, j)].append(sim)
# 繪製每對組合隨層數變化的相似度曲線
layers = list(range(len(hidden_states))) # 0 = embedding 層
plt.figure(figsize=(8, 6))
for (i, j), sims in sim_dict.items():
label = f"sentence{i+1} vs sentence{j+1}"
plt.plot(layers, sims, marker='o', label=label)
plt.xticks(layers)
plt.xlabel("layer")
plt.ylabel("Cosine")
plt.legend()
plt.grid(True)
plt.show()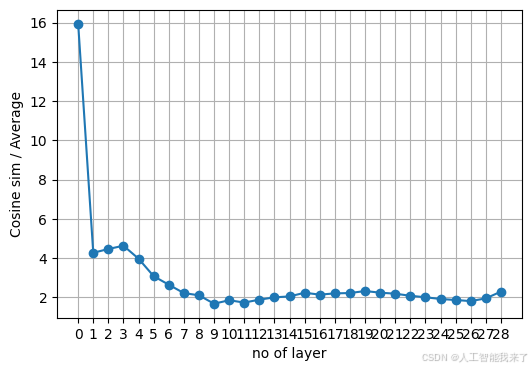
以 logit lens 解析 representation
在典型的語言模型使用中,輸入的 token 會經過多層 Transformer layer 的運算,每一層都會產生一組 representation。我們通常只取最後一層的表示,透過 Unembedding (LM head) 將其轉換到詞彙表大小的空間,得到每個 token 的 logit,最後再經由 softmax 得到下一個 token 的機率分布。換言之,我們平常只關注「最後的輸出層」。
Logit lens 的核心想法是:其實不一定要等到最後一層,我們可以在每一層的 representation 上套用相同的 Unembedding,來觀察如果「此時就直接拿來預測 token」,模型會認為最有可能的輸出是什麼。這樣做就像替每一層「戴上一副眼鏡」來觀察:模型在中間層時,腦中已經傾向哪些詞彙?隨著層數加深,模型又是如何逐步收斂到最終答案的呢?
!lens.png
python
text = "天氣" #天氣, 今天天氣真 ...
input_ids = tokenizer.encode(text, return_tensors="pt")
outputs = model(input_ids, output_hidden_states=True)
hidden_states = outputs.hidden_states # 長度 = layer 數 + 1
print(f"一共拿到 {len(hidden_states)} 層 representation (包含 token embedding)。")
for l in range(len(hidden_states)):
# 用該層 hidden state 經過 lm_head 得到 logits
logits = model.lm_head(hidden_states[l]) # [batch, seq_len, vocab_size]
# 取最後一個 token 的 logits
last_token_logits = logits[0, -1] # [vocab_size]
# 選分數最高的 token
next_token_id = torch.argmax(last_token_logits)
# 轉成字
print(f"Layer {l:2d} → {tokenizer.decode(next_token_id)}")一共拿到 29 層 representation (包含 token embedding)。
Layer 0 → 真
Layer 1 → 真
Layer 2 → 真
Layer 3 → 真
Layer 4 → 真
Layer 5 → 真
Layer 6 → 真
Layer 7 → 真
Layer 8 → 世
Layer 9 → �
Layer 10 → -flex
Layer 11 → fores
Layer 12 → weis
Layer 13 → weather
Layer 14 → /false
Layer 15 → /false
Layer 16 → /false
Layer 17 → /false
Layer 18 → climate
Layer 19 → nice
Layer 20 → climate
Layer 21 → weather
Layer 22 → beautiful
Layer 23 → beautiful
Layer 24 → GOOD
Layer 25 → bad
Layer 26 → beautiful
Layer 27 → 不
Layer 28 → 好觀察 Attention 在做甚麼
python
#text = "how are you"
text = "The apple is green. What color is the apple?"
tokens = tokenizer.tokenize(text,add_special_tokens=True)
inputs = tokenizer.encode(text, return_tensors="pt")
model.config._attn_implementation = "eager"
#為什麼需要這個? 告訴模型請老老實實用普通 PyTorch 一步步算 attention,不要用快的方法,這樣 attentions 才會有內容。
outputs = model(inputs, output_attentions=True)
'''
# 把上面幾行的 model -> model2, tokenizer -> tokenizer2 ,就可以把 llama 換成 gemma 了
tokens = tokenizer2.tokenize(text,add_special_tokens=True)
inputs = tokenizer2.encode(text, return_tensors="pt")
model2.config._attn_implementation = "eager"
outputs = model2(inputs, output_attentions=True)
'''
attentions = outputs.attentions
print(f"總共有 {len(attentions)} 層")
for i, layer_attn in enumerate(attentions):
print(f"Layer {i} attention shape: {layer_attn.shape}")
# 每一層的 attention 權重張量形狀都是 [1, 24, L, L]。
# 1 → batch_size (一次只輸入一段文字,所以 batch_size = 1)
# 24 → num_heads (這個每一層的 attention 有 24 個,每個 head 都有不同的「關注模式」,例如: 有的關注語法、有的關注語意。)
# L → seq_len(你的輸入句子,經過 tokenizer 之後被切成 L 個 token)
# 總之,每一層有 24 個大小為 L×L 的表格,每個格子是注意力權重(通常 0 ~ 1 之間,row方向加總 ≈ 1)總共有 34 層
Layer 0 attention shape: torch.Size([1, 8, 12, 12])
Layer 1 attention shape: torch.Size([1, 8, 12, 12])
Layer 2 attention shape: torch.Size([1, 8, 12, 12])
Layer 3 attention shape: torch.Size([1, 8, 12, 12])
Layer 4 attention shape: torch.Size([1, 8, 12, 12])
Layer 5 attention shape: torch.Size([1, 8, 12, 12])
Layer 6 attention shape: torch.Size([1, 8, 12, 12])
Layer 7 attention shape: torch.Size([1, 8, 12, 12])
Layer 8 attention shape: torch.Size([1, 8, 12, 12])
Layer 9 attention shape: torch.Size([1, 8, 12, 12])
Layer 10 attention shape: torch.Size([1, 8, 12, 12])
Layer 11 attention shape: torch.Size([1, 8, 12, 12])
Layer 12 attention shape: torch.Size([1, 8, 12, 12])
Layer 13 attention shape: torch.Size([1, 8, 12, 12])
Layer 14 attention shape: torch.Size([1, 8, 12, 12])
Layer 15 attention shape: torch.Size([1, 8, 12, 12])
Layer 16 attention shape: torch.Size([1, 8, 12, 12])
Layer 17 attention shape: torch.Size([1, 8, 12, 12])
Layer 18 attention shape: torch.Size([1, 8, 12, 12])
Layer 19 attention shape: torch.Size([1, 8, 12, 12])
Layer 20 attention shape: torch.Size([1, 8, 12, 12])
Layer 21 attention shape: torch.Size([1, 8, 12, 12])
Layer 22 attention shape: torch.Size([1, 8, 12, 12])
Layer 23 attention shape: torch.Size([1, 8, 12, 12])
Layer 24 attention shape: torch.Size([1, 8, 12, 12])
Layer 25 attention shape: torch.Size([1, 8, 12, 12])
Layer 26 attention shape: torch.Size([1, 8, 12, 12])
Layer 27 attention shape: torch.Size([1, 8, 12, 12])
Layer 28 attention shape: torch.Size([1, 8, 12, 12])
Layer 29 attention shape: torch.Size([1, 8, 12, 12])
Layer 30 attention shape: torch.Size([1, 8, 12, 12])
Layer 31 attention shape: torch.Size([1, 8, 12, 12])
Layer 32 attention shape: torch.Size([1, 8, 12, 12])
Layer 33 attention shape: torch.Size([1, 8, 12, 12])
python
layer_idx = 5 #假設我們想觀察第 6 層 (layer_idx=5)
head_idx = 3 #假設我們想觀察第 7 個 Head (head_idx=6) 的注意力分佈 #可以把 6 改成其他數字,例如: 5,4,3
attn_matrix = attentions[layer_idx][0][head_idx].detach().numpy()
print(attn_matrix)
import matplotlib.pyplot as plt # Import matplotlib here
plt.imshow(attn_matrix, cmap="viridis")
plt.xticks(range(len(tokens)), tokens, rotation=90)
plt.yticks(range(len(tokens)), tokens)
plt.title(f"Layer {layer_idx+1}, Head {head_idx+1} Attention")
plt.colorbar()
plt.tight_layout()
plt.show()
#你會看到一個 L X L 的矩陣,嘗試解讀你看到了什麼? 為什麼右上角都是0[[1.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00]
[9.2412418e-01 7.5875796e-02 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00]
[9.3215126e-01 2.4251176e-02 4.3597639e-02 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00]
[9.0338725e-01 4.2990036e-02 3.3513483e-02 2.0109201e-02 0.0000000e+00
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00]
[9.3907905e-01 1.3775425e-02 1.1050792e-02 1.1175026e-03 3.4977227e-02
0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00]
[8.7821317e-01 2.5937418e-02 1.1282353e-02 1.7214144e-03 9.0388414e-03
7.3806785e-02 0.0000000e+00 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00]
[9.1726184e-01 3.2001548e-02 9.0483790e-03 2.3846943e-03 4.7251047e-03
1.1803878e-02 2.2774462e-02 0.0000000e+00 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00]
[2.9145518e-01 8.5326070e-03 3.6001179e-02 1.9675302e-03 5.4360288e-01
8.8410504e-02 4.2343664e-04 2.9606633e-02 0.0000000e+00 0.0000000e+00
0.0000000e+00 0.0000000e+00]
[5.3780776e-01 1.3770431e-02 2.7233433e-02 5.1120538e-03 1.9593906e-01
1.8057679e-01 4.4257087e-03 2.2328654e-02 1.2806170e-02 0.0000000e+00
0.0000000e+00 0.0000000e+00]
[4.1189680e-01 2.0262711e-02 4.4824678e-02 3.6655094e-02 1.9726254e-01
2.5131685e-01 6.9013415e-03 1.8519670e-02 1.9215292e-03 1.0438803e-02
0.0000000e+00 0.0000000e+00]
[2.2494717e-01 7.0537478e-03 5.5169195e-01 1.2875231e-01 1.4350169e-02
2.8740205e-02 1.5554627e-03 2.0242791e-04 9.2860901e-06 8.8781431e-05
4.2608388e-02 0.0000000e+00]
[5.0596154e-01 1.9424669e-02 7.7140585e-02 1.2545764e-02 1.4223762e-01
2.0613685e-01 8.0743777e-03 6.0447762e-03 8.4023277e-04 1.3275535e-03
7.4247399e-04 1.9523542e-02]]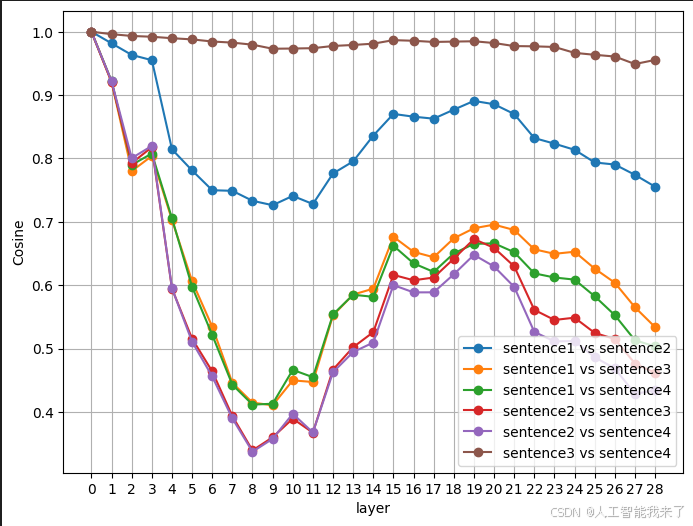
python
num_layers = len(attentions)
num_heads = attentions[0].shape[1] # 每層 head 數
# 建立總圖
fig, axes = plt.subplots(num_layers, num_heads, figsize=(num_heads*1.5, num_layers*1.5))
if num_layers == 1 and num_heads == 1:
axes = [[axes]]
elif num_layers == 1:
axes = [axes]
elif num_heads == 1:
axes = [[ax] for ax in axes]
# 畫每個子圖
for layer_idx in range(num_layers):
for head_idx in range(num_heads):
ax = axes[layer_idx][head_idx]
attn_matrix = attentions[layer_idx][0, head_idx].detach().cpu().numpy()
ax.imshow(attn_matrix, cmap="viridis")
ax.set_xticks([])
ax.set_yticks([])
ax.set_title(f"L{layer_idx+1}\nH{head_idx+1}", fontsize=6)
#plt.suptitle("Attention Maps (Layer × Head)", fontsize=14)
plt.tight_layout()
plt.show()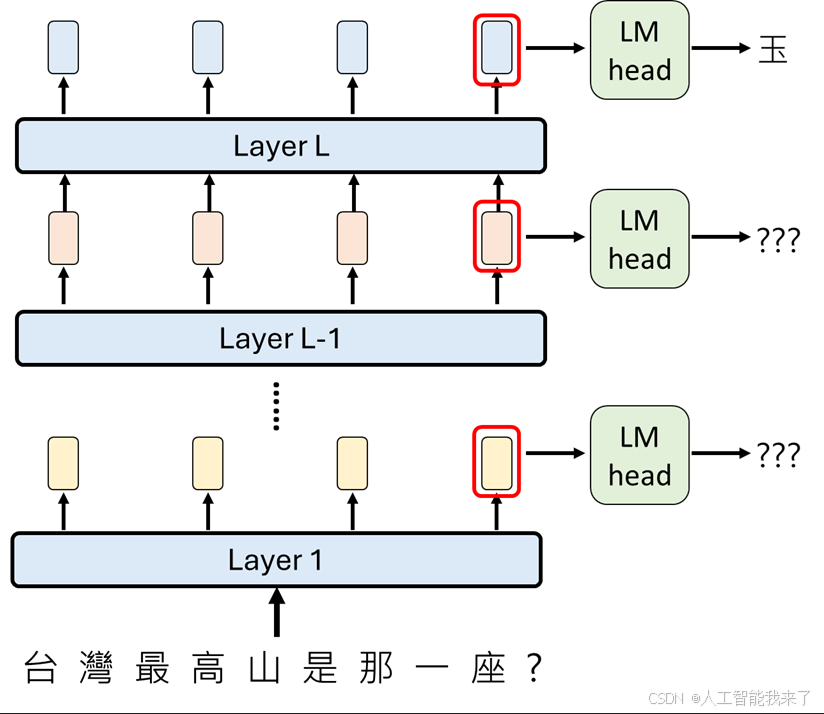
試試看有沒有辦法把 gemma 的 attention 畫出來,看看有什麼不一樣?