DetLH:Open-Vocabulary Object Detection via Language Hierarchy
4.1. 总览
这篇文章是使用了弱监督的方法,也是就图像级别的标注数据做目标检测。
这类方法可以获取更大规模的图像数据,而不仅限于bbox标注的少量数据。
根据实验结果分析可以看到, 图像级标签 + 大规模训练,能使模型学会更强的"理解"能力,而不仅是"记忆"某些常见类别的位置和特征。使用这种方法获取更多 图像标注级别数据 进行训练可能比在 bbox标注的少量数据 集上训练的效果或许更好。
本文的动机和目标是: learning a generalizable object detector
这是因为不能总是为每个新应用场景重新标注 bbox 数据来训练新模型------太贵、太慢。
所以我们希望训练一个检测器,它能:
- 使用廉价的图像级标签训练(弱监督);
- 学习通用视觉+语言的语义;
- 一劳永逸:不管下游任务怎么变,只要给出词,它就能检测目标。
这篇论文到底是"弱监督目标检测(WSOD)",还是"开放词汇检测(OVD)"?
答案是:它融合了两者,定位在"用于开放词汇检测的弱监督目标检测"这个交叉领域。
训练方式使用的是弱监督,但是实现了OVD能力。

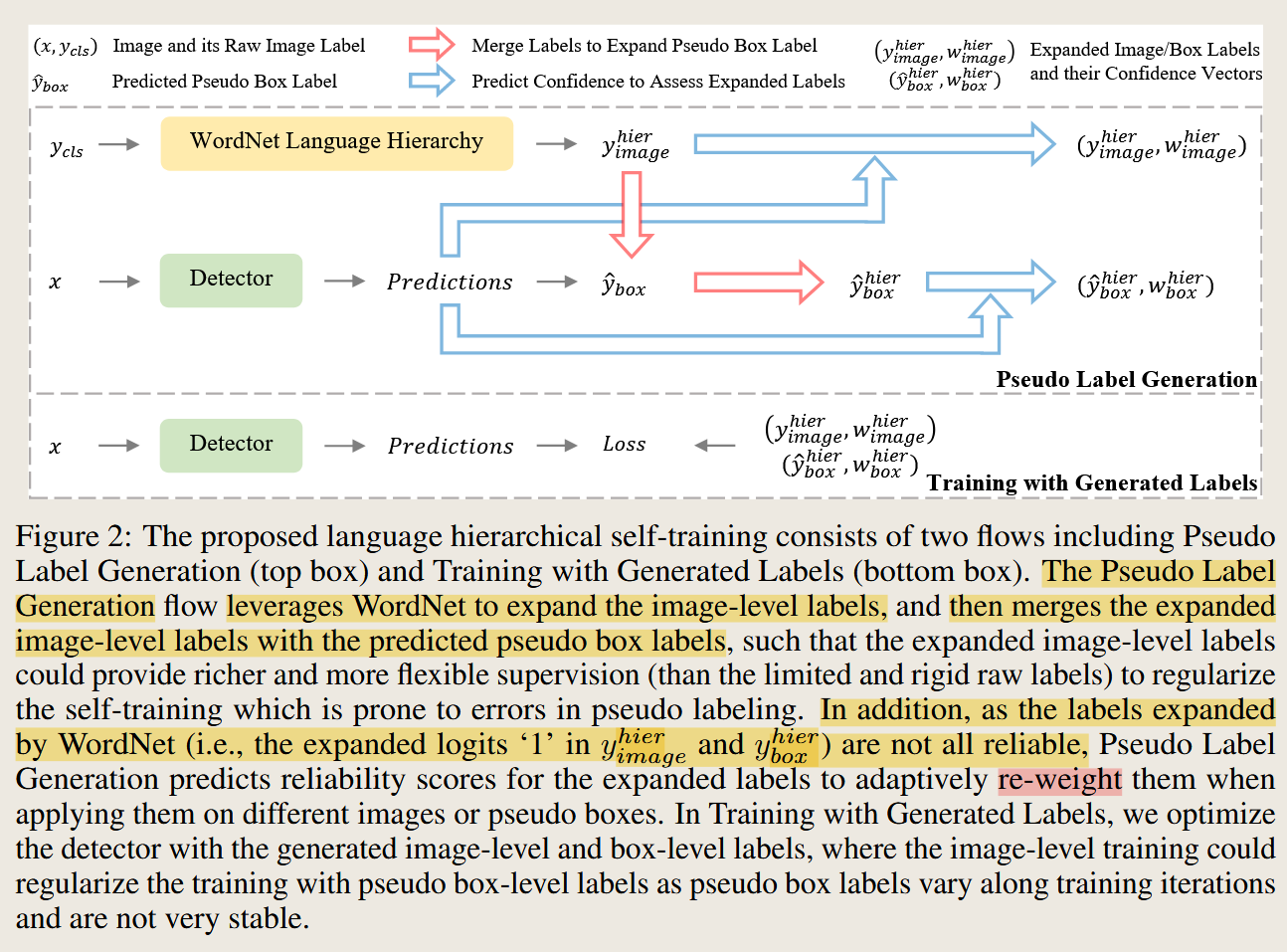
4.2. Part 1:Language Hierarchical Self-Training (LHST)
【step1】:生成伪标签(Pseudo Labels)
利用已有图像级标签 + WordNet 层级结构
假设一张图像标签是 "Aquatic Mammal",它是一个较宽泛的词,WordNet会将其扩展为:
- 上位词(例如:Mammal)
- 下位词(例如:Seal、Dolphin、Whale 等)
通过 WordNet 把图像标签扩展为一个标签集,这就转化成多标签分类问题,使得模型更有机会去定位细粒度目标。
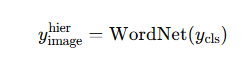
由原始的标签ycls变为多标签向量yhier,这是一个0/1的二值向量,不是概率。

是给这张图像进行多标签。
【Step 2】模型预测伪边框 + 类别
模型对每张图像预测多个目标框(proposal),每个框预测的概率是pnc:
- 每个框输出一个分类概率 pn,这是一个分布,pnc值的是第c类的概率
- 筛掉最大的概率也低于置信度阈值 t的框
除了得到预测框的预测概率分布,还需要一个根据这个概率分布得到伪标签。
- 一张图像中所N个box的label组成ybox(这是一个集合)
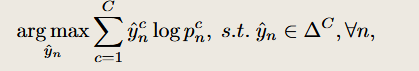
- 找出 pn中最大的那个概率对应的类别
- 把这个类当作第 n 个框的"伪标签"
- 交叉熵最优解下标签选择的一种写法。 含义是找到一个yn^使得yn^logpnc的值最大,而这个值会在选择最大的pnc中的值的时候达到最大,所以目的是找到找出 pn中最大的那个概率对应的类别。
这个分类概率是由经过检测骨干网络得到的propsal和经过CLIP的类别计算相似度得到的。
经过CLIP的类别范围是词汇范围是全部的上下位扩展之后的全部类别。
使用这个CLIP文本计算相似度的方法就是实现OVD的原因。
【Step 3】合并标签用于训练
由于前面选择的伪标签是one-hot向量,因此很可能并不准确,所谓在伪标签中可以还需要加入image的上下位词的标签,因此这个框的伪标签就变成了【0,1,0,1,1,1,0,0,0,...】
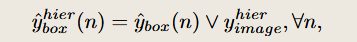
将生成的框伪标签ybox和图像标签yhier 取"逻辑或" 。
这样可以将图像级先验强行注入伪标签中,起到一定"纠偏"作用。
这样这个区域的标签既有上下位扩展的标签又有原来图像级的标签。

【Step 4】置信度加权标签可靠性
由于扩展的标签是logits=1,所以并不是很可靠,因此需要添加置信度。
通过 WordNet 扩展得到的标签不是都可靠的,有些可能是:
- 真正存在(如 "seal")
- 但也可能是语言上的推理关系(如 "aquatic mammal"),并不等于图中确实有对应物体
所以,需要一个方法来为每个标签打分,看看它有多"可信"。
见公式 (6):
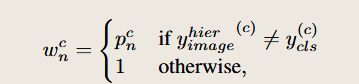
- 当这个类是 WordNet 扩展出来的(即不是原始图像标签):这时不确定它是不是图里真的存在,所以用 pnc(模型自己判断的置信度)当做权重,这个权重是后面计算损失使用的。
- 否则(即它是图像原始标签):那就默认它肯定是对的,置信度 = 1
对于图像标签或伪标签中不是原始类扩展出来的部分,用预测置信度 pnc 作为加权因子 wnc,让模型能"有选择性地相信标签"。
也就是给 扩展标签 y^boxhier 中的每一个"1",赋一个置信度权重 wnc ,来衡量它可信不可信,并用在损失函数中进行加权训练。
这部分是训练中最关键的贡献,用于处理只有图像级标签的数据 Dcls,包含两项损失:
框级伪标签损失 Lbox:不是对边界框,而是对框级的标签
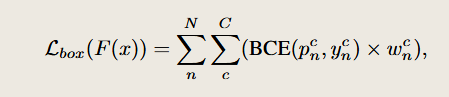
pnc是使用CLIP分类头直接预测的概率值,
ync是在pnc中进行选择后的伪标签。
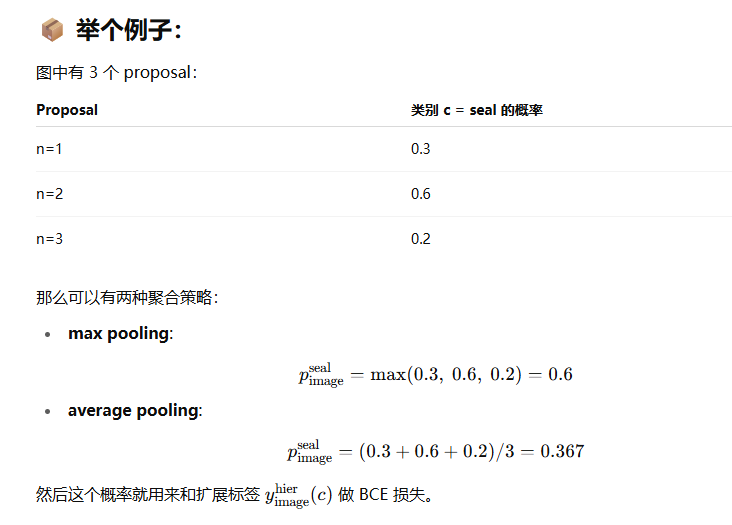
第二部分是 图像级监督损失 Limage:
因为伪框 y^box 在训练过程中是不稳定的,而图像级标签是更稳定的信号。
所以这部分损失起到 正则化作用,帮助训练对图像中存在的类保持敏感性。
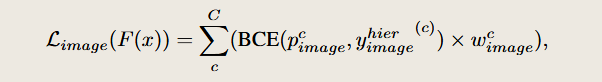

4.3. 模型训练
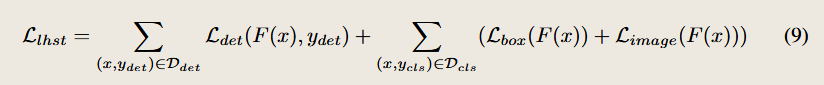
4.4. Part 2:Language Hierarchical Prompt Generation (LHPG)
目的:
测试阶段遇到新类别词(open-vocabulary)时,如何将它转换成模型可识别的表示?
不是新的类别,而是在测试的时候,使用的类别的标签可能与原来训练的时候的标签虽然是一个意思,但是是不同的名称表达。例如"crabeater seal" vs "seal"
其他方法可能是用Prompt 标准化( a photo of a {class}" )的方式来解决这个这种语义不对齐的问题(同时也是依赖CLIP的语义泛化性),这篇文章由于加入wordNet的上下位关系,所以伪标签都是wordnet中的词汇,因此在测试的时候就可以把测试的类的名称通过与在wordnet中找到最相似的类别名称来解决这个语义gap的问题。
可以理解为之前的方法都是一方面是默认使用了CLIP的这种泛化能力,即使是 "crabeater seal" vs "seal"存在与训练集和测试集中,也可以检测出相似的类别。另一方面是,默认测试类来自标准数据集(如 LVIS, Object365) ,这些测试集的类名和训练集中是一致的。
这篇文章提出要解决的这个语义gap的问题,
第一次明确提出并系统解决了测试类 prompt 与训练语义空间不对齐的问题。
- 它没有假设 test class 一定合理,而是主动:
-
- 把测试类名映射到 WordNet 语义空间
- 找到最相近的训练类同义词
- 用统一的 prompt 风格生成更合理的文本嵌入
- 让模型看到的是一个和训练一致的语义空间 → 提高检测准确率
DetLH 为何必须显式解决这个问题?
因为它的训练语料是弱监督(图像级标签),且来自超大词表(ImageNet-21K):
- 无法控制类名风格(可能很"专业")
- 无法保证和测试词表一致(甚至可能没有重合)
- 测试类又是开放的,词来源随机 → 语义 mismatch 是必然的
这就与那些用 COCO、LVIS 等统一标注体系训练的传统 OVD 方法形成鲜明对比。
实现方法:
- 输入测试词汇表 Vtest(如"crabeater seal")
- 用 CLIP 文本编码器把它转成向量
- 查找与 WordNet 中哪个概念最接近,找到最佳匹配词集 VWordNet
- 用这些"标准化词"生成检测时的 prompt 向量
这样,测试类别词和训练时看到的 WordNet 标签空间一致对齐,实现 zero-shot 检测能力。

4.5. 实验部分
在不同的数据集/下游任务上进行了测试
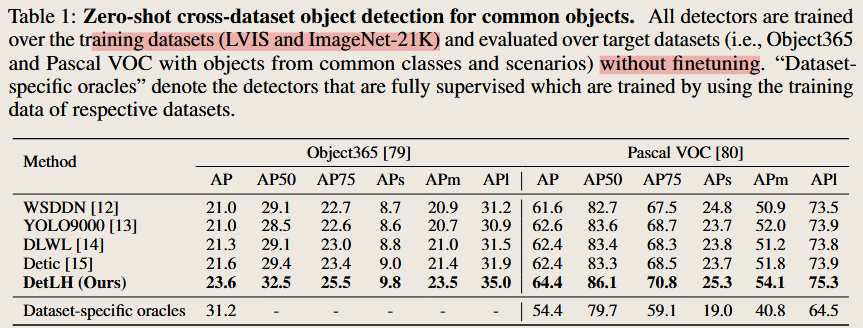
使用不同主干网络架构的性能对比
评估 DetLH 方法是否对主干网络架构具有泛化能力,即是否只在 Swin-B 上有效,还是对 ResNet、ConvNeXt 也成立。