为什么要给大模型"瘦身"?
在AI技术飞速发展的今天,大语言模型已经成为各行各业的得力助手。但你是否知道,部署一个大模型的成本有多高?
一个千亿参数级别的模型,不仅需要占用大量的存储空间,在实际运行时更是需要惊人的计算资源。对于企业来说,这意味着高昂的硬件成本和运营开支。因此,如何在保持模型性能的同时降低部署成本,成为了AI工程师们必须面对的挑战。
今天,我们就来聊聊大模型压缩的两大主流技术------量化(Quantization)和蒸馏(Distillation)。
量化:用更少的位数存储参数
什么是量化?
要理解量化,我们首先需要知道:大模型本质上是由海量参数组成的。比如GPT-3,就包含了1750亿个参数。每个参数都是一个数值,而这些数值的存储方式,直接决定了模型占用的空间大小。
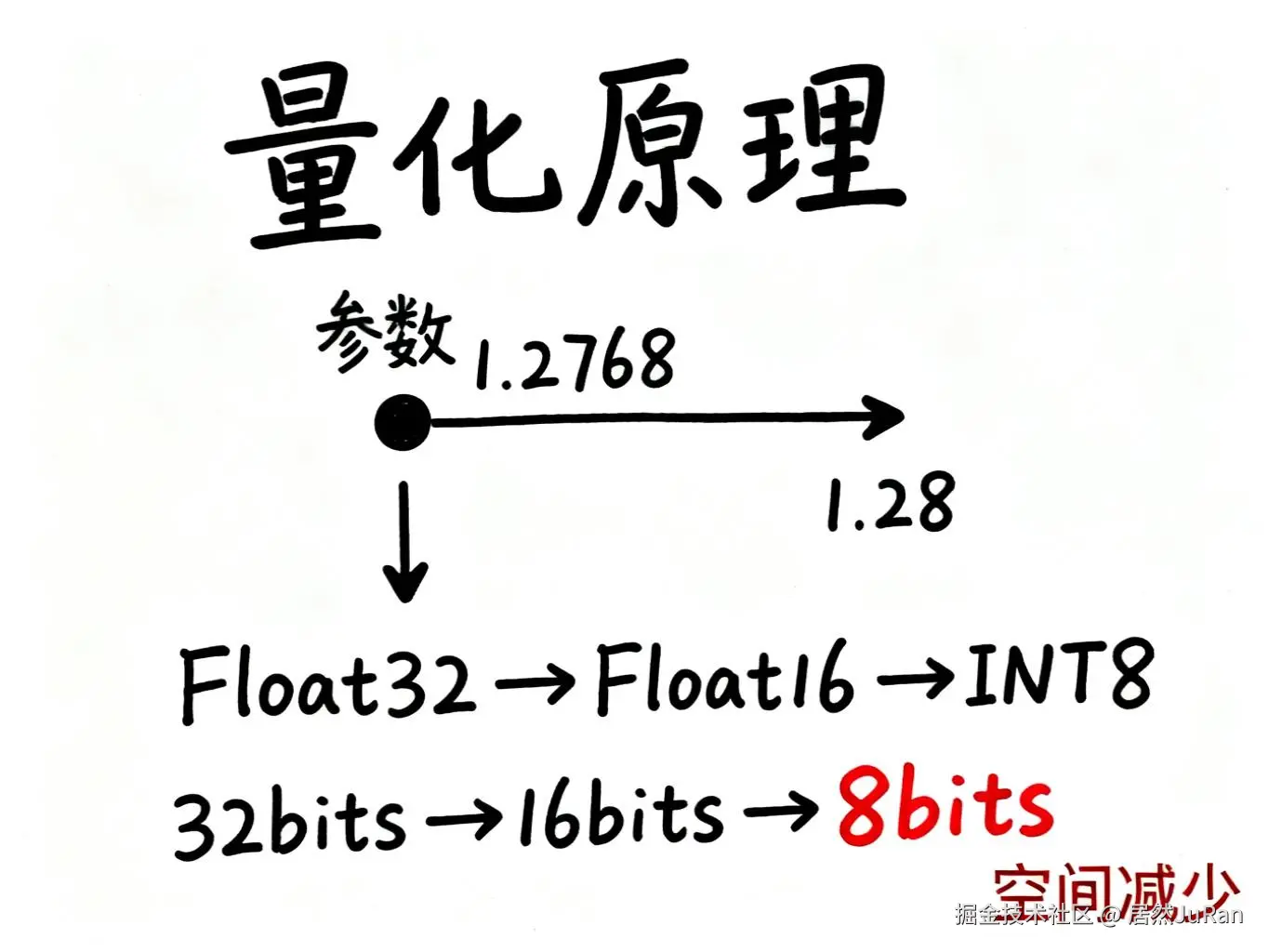
让我们举个简单的例子。假设某个参数的值是1.2768,为了在计算机中存储这个精确的数值,我们需要开辟一定的内存空间。但如果我们做个"四舍五入",把它简化成1或者1.28,所需的存储空间就会大大减少。
这就是量化的核心思想------通过降低数值精度来节省存储空间。
从Float32到INT8的转变
在深度学习中,参数通常以Float32的格式存储,也就是说每个参数占用32个bits(4个字节)的空间。但通过量化技术,我们可以将这些参数转换为更低精度的数据类型:
-
Float32 → Float16:空间减半,每个参数仅占16个bits
-
Float32 → INT8:空间压缩至1/4,每个参数仅占8个bits
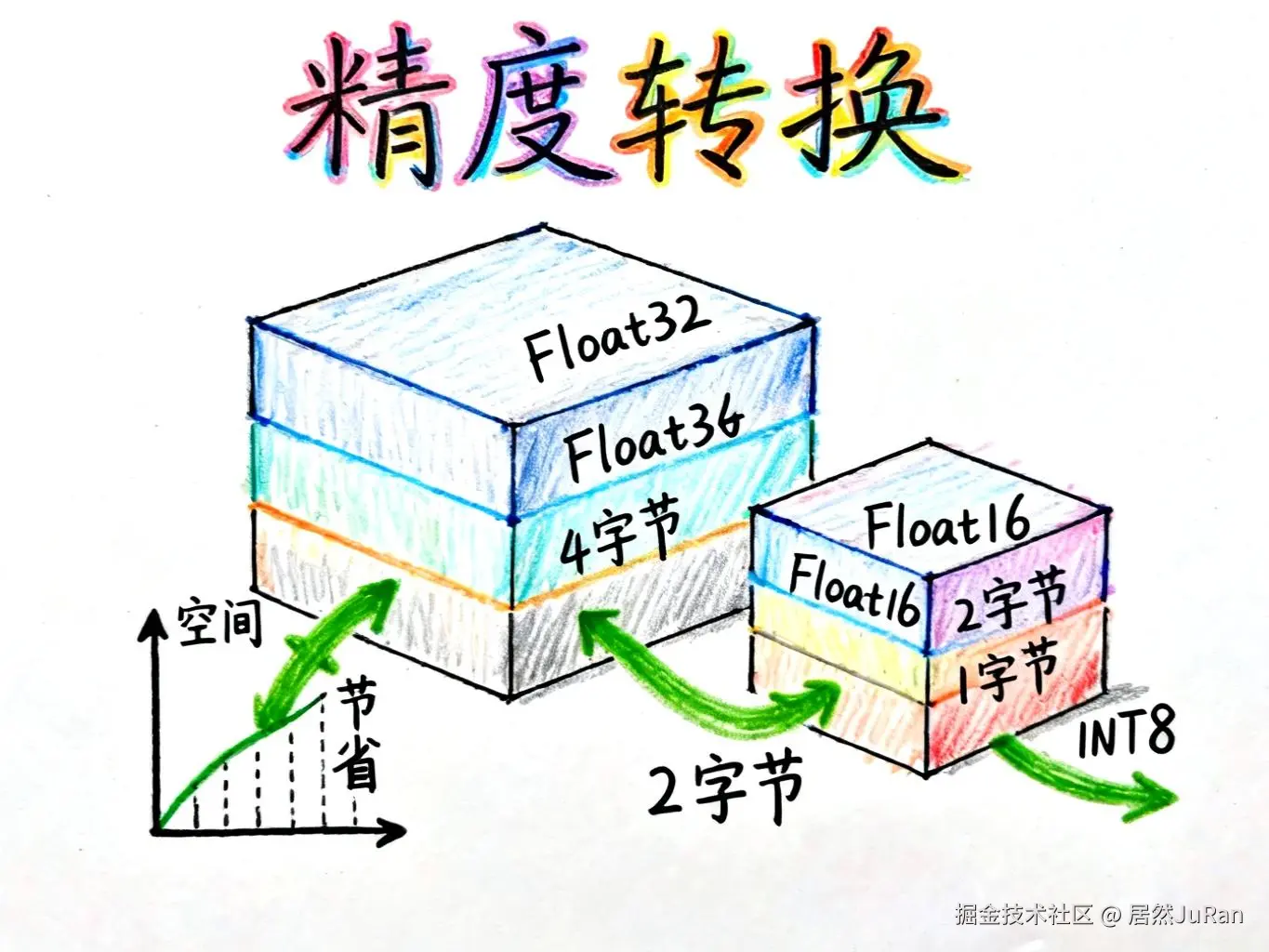
这种转换带来的好处是显而易见的:
-
大幅降低存储需求:模型文件变小,更容易部署
-
加速推理速度:计算量减少,响应更快
-
降低成本:对硬件的要求大幅下降
你可能会担心:精度降低了,模型的准确率会不会受影响?
答案是:**如果量化过程把控得当,模型的准确率是有保障的。**这也是为什么量化成为目前大模型压缩最常用的方法之一。
蒸馏:让小模型学会"模仿"
蒸馏的本质是什么?
如果说量化是"压缩参数",那么蒸馏则是完全不同的思路------让一个小模型去模仿大模型的行为。
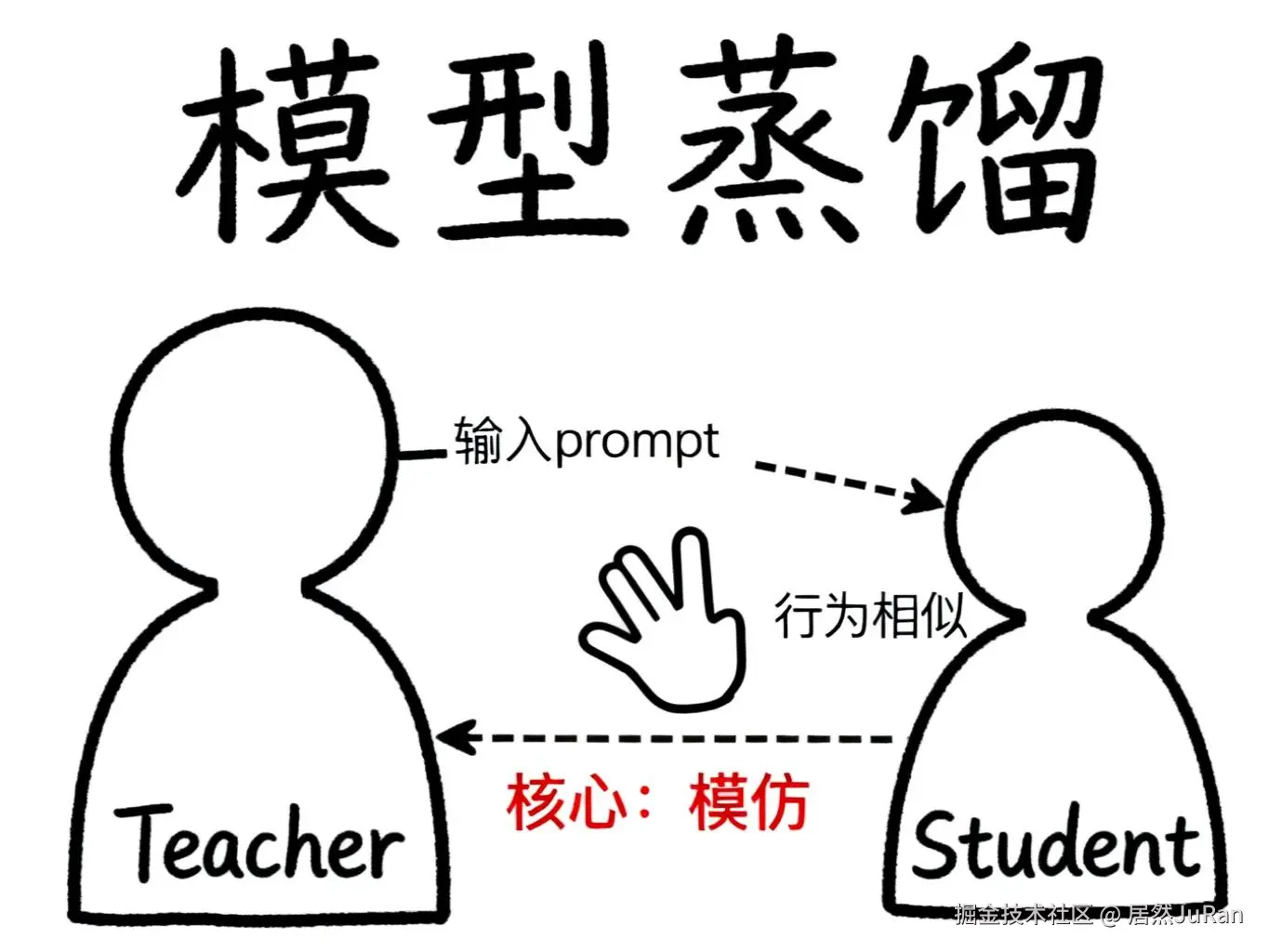
想象一个场景:我们已经训练好了一个千亿参数的大模型,但它太大太重,部署成本太高。这时候,我们可以构造一个小得多的模型,然后让这个"学生模型"(Student Model)去学习"教师模型"(Teacher Model)的行为。
蒸馏是如何工作的?
具体来说,蒸馏的过程是这样的:
-
给定一个输入(比如一个prompt)
-
将这个输入同时喂给大模型和小模型
-
观察大模型的输出
-
训练小模型,让它的输出尽可能接近大模型的输出
就像小孩子模仿大人一样,大模型做什么,小模型也学着做什么。
通过这种方式,小模型逐渐学会了大模型的"行为模式",最终能够在保持相似性能的同时,大幅减少模型规模和计算开销。
蒸馏在实际中的应用
蒸馏技术不仅用于模型压缩,在训练新模型时也经常使用。
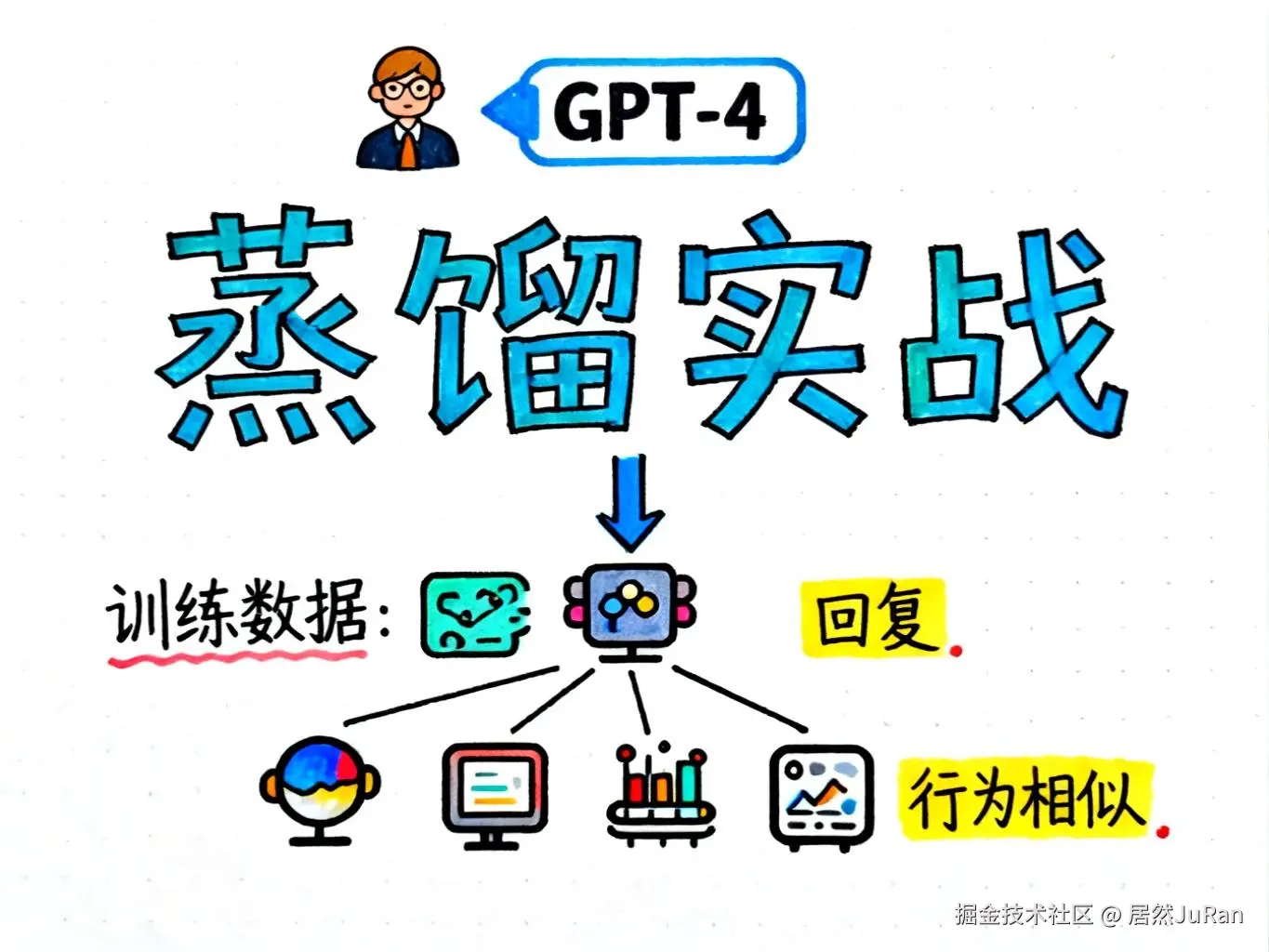
一个典型的例子是:市面上很多开源大模型,都是通过"模仿"GPT-4训练出来的。具体做法是:
-
收集GPT-4对各种问题的回复
-
将这些输入-输出对作为训练数据
-
用这些数据训练自己的模型
通过这种方式,开源模型能够逐步接近GPT-4的表现,同时保持更低的部署成本。
量化vs蒸馏:该选哪一个?
这两种技术各有特点,适用于不同场景:
量化技术:
-
优势:实施简单,不需要重新训练,压缩效果明显
-
适用场景:已有模型的快速优化,对精度要求不是特别严格的应用
-
主流方法:目前大模型压缩最常用的手段
蒸馏技术:
-
优势:可以获得一个全新的小模型,灵活性更高
-
适用场景:需要大幅度缩小模型规模,或训练新模型时借鉴大模型能力
-
应用广泛:很多开源模型都基于蒸馏思路训练
在实际应用中,这两种技术也可以结合使用,达到更好的压缩效果。
其他压缩技术
除了量化和蒸馏,还有一些其他的模型压缩技术,比如剪枝(Pruning)------通过移除模型中不重要的参数或连接来减小模型规模。
但在大模型领域,剪枝的实用性相对较弱,量化和蒸馏仍然是最主流、最实用的两种方法。
写在最后
随着大模型应用的不断普及,模型压缩技术变得越来越重要。无论是量化还是蒸馏,它们的目标都是在保证模型性能的前提下,让AI技术更加"平民化"------降低部署门槛,让更多人能够用得起、用得好大模型。
对于开发者来说,理解这些技术原理,不仅能帮助我们更好地部署模型,也能在设计AI应用时做出更明智的技术选择。
你在实际项目中使用过这些技术吗?欢迎在评论区分享你的经验!