博客的参考资料: 小林coding | Java面试学习 请大家多多支持小林coding , 讲的确实细我只能说
前言,博主在学习Redis时就思考过加入Redis 挂了 或者 同时有大量数据没有写入Redis 导致数据被冲击 等 问题, 当时没有系统总结, 最近看了小林coding 和一些 博客 , 我自己也 做了一些总结,同时对于我认为难以理解的地方,我加了一些示例,希望能帮助到读者
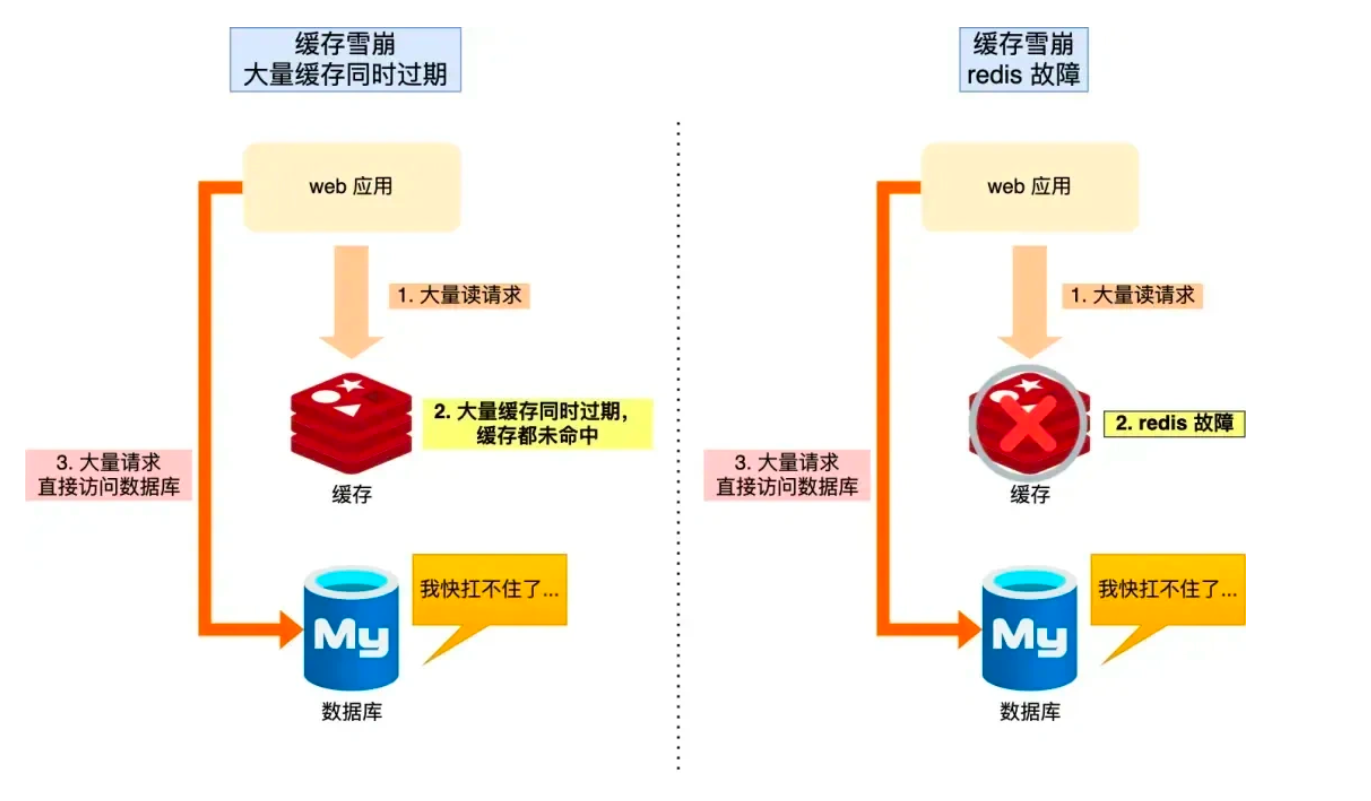
1. 缓存雪崩 (大量缓存失效,或者Redis 挂了)
当大量缓存数据 在同一时间过期(失效) 或者 Redis 故障宕机 时 , 如果此时有大量的用户请求, 都无法从Redis 中 处理 ,于是全部请求都访问数据库 ,从而导致数据库的压力骤增,严重的可能会导致数据库宕机, 从而形成一系列连锁反应, 造成整个系统的崩溃,这就是缓存雪崩的问题
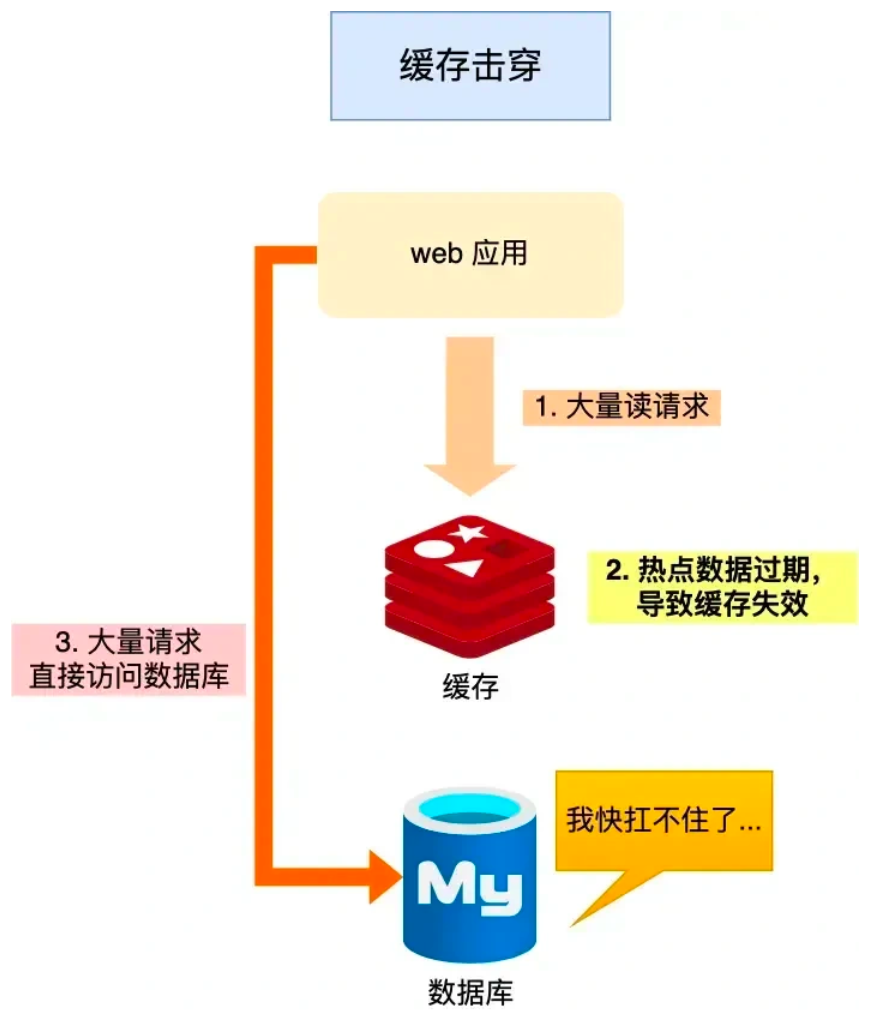
2. 缓存击穿 (热点数据过期了,数据库被击穿了):
如果缓存中的某个热点数据过期了,此时大量的请求还访问了该热点数据, 因为无法从缓存中读取, 所以直接从数据库中读取, 导致数据库被高并发的请求冲垮了,这就是缓存击穿问题.
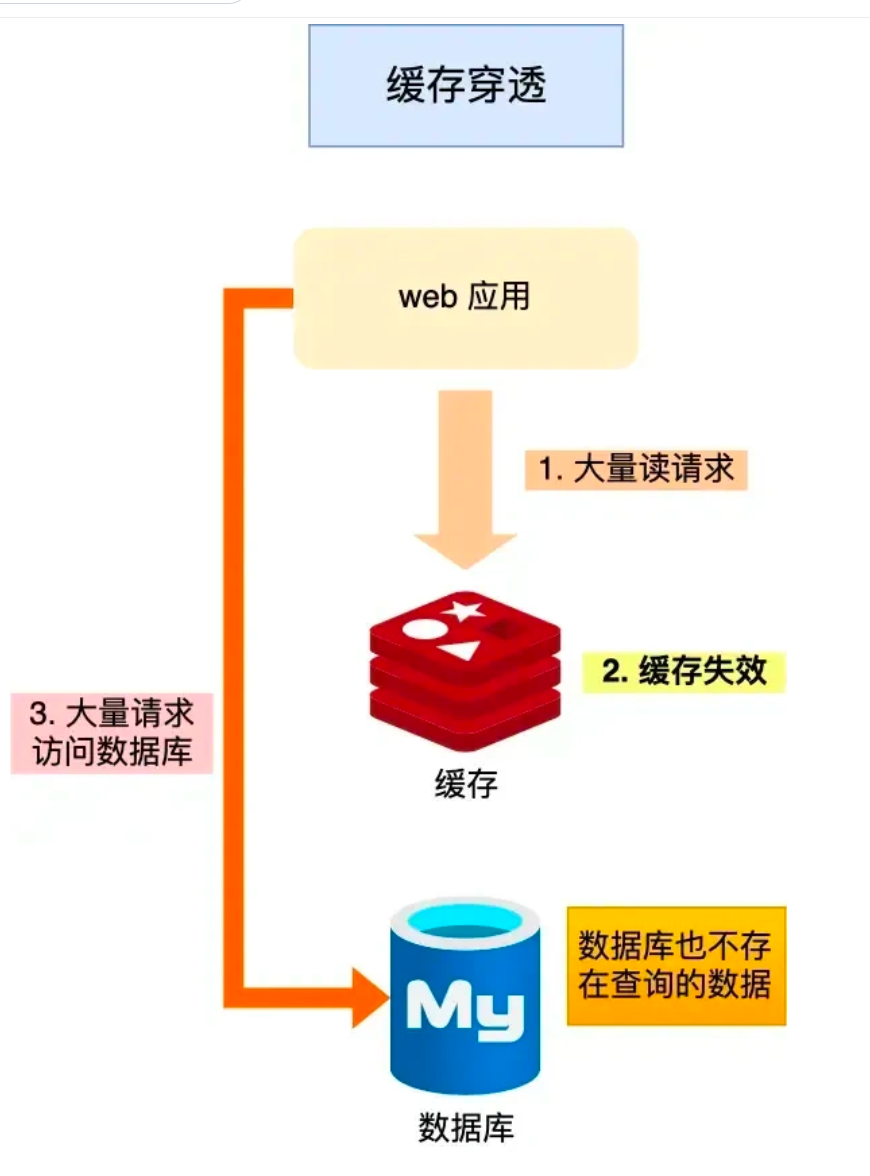
3. 缓存穿透 (无法构建缓存):
当用户访问的数据, 既不在缓存中,也不在数据库中 , 导致请求访问缓存,发现缺失以后,又去访问数据库,发现数据库中也没有要访问的数据,没办法构建缓存数据 ,来服务后续的请求. 那么当有大量这样类似的请求到来时 ,数据库压力骤增, 这就是缓存穿透问题
4. 缓存雪崩解决方案:
- 均匀设置过期时间 : 如果要给缓存数据设置过期时间,应该避免将大量的数据设置成同一个过期时间. 以此避免大规模缓存没命中的问题.
- 互斥锁 : 当业务线程在处理用户请求时, 如果发现访问的数据不在Redis里,就加一个互斥锁, 保证同一时间只有一个请求来构建缓存(从数据库读取数据,然后把它更新到Redis中), 当缓存构建完成以后,再释放锁. 未能获取互斥锁的请求,要么等待锁释放后重新读取缓存,要么就返回空值或者默认值. 实现互斥锁的时候, 最好设置超时时间,以免因某种以外而一直线程阻塞,一直不释放锁,这样的话其他请求也一直拿不到锁, 导致整个系统出现无响应的现象.
为什么互斥锁能解决雪崩问题:
互斥锁的核心思想是将大量并发回源数据库的请求转化为单个请求。在没有锁的情况下,缓存一旦过期,所有请求会同时穿透到数据库,造成数据库压力骤增,引发雪崩。而有了互斥锁后,即使有成千上万的请求同时发现缓存失效,只有第一个抢到锁的线程会去查询数据库并回填缓存,其余请求要么等待锁释放后直接从缓存读取,要么返回默认值。这就避免了数据库被同时打爆,从而缓解雪崩问题。
- 后台更新缓存: 业务线程不再负责更新缓存,缓存也不设置有效期,而是让 缓存"永久有效" , 并且将缓存的工作交给后台线程定时更新.
5. 缓存击穿解决方案
- 互斥锁方案
保证同一时间只有一个业务线程更新缓存。未能获取互斥锁的请求,要么等待锁释放后重新读取缓存,要么就返回空值或者默认值。 - 不给热点数据设置过期时间
由后台异步更新缓存,或者在热点数据准备要过期前,提前通知后台线程更新缓存以及重新设置过期时间。
6. 缓存穿透解决方案
-
非法请求的限制
当有大量恶意请求访问不存在的数据时,也会发生缓存穿透。因此在 API 入口处需要判断请求参数是否合理,例如是否含有非法值、请求字段是否存在。如果判断出是恶意请求就直接返回错误,避免进一步访问缓存和数据库。
示例:
比如接口是 /user?id=123**,正常情况下** id****应该是正整数。若有人不断传 id=-1**、** id=abc****或者特别大的数值(比如 999999999**),这些本身就不合法。我们可以在 API 层直接拦截,返回错误信息,而不是继续查缓存或数据库。** -
缓存空值或者默认值
当线上业务发现缓存穿透的现象时,可以针对查询的数据,在缓存中设置空值或者默认值。这样后续请求就可以直接从缓存中读取,而不会继续查询数据库。
示例:
假设有人请求 id=9999****的用户,而数据库根本不存在这个用户。如果直接查数据库,每次都会打到数据库。改进做法是:第一次查数据库发现没有结果,就在 Redis 里写入 user:9999 = null**(同时设置一个较短的过期时间,比如 5 分钟)。下次再有人请求** id=9999**,就直接从缓存读到** null**,而不会反复查数据库。** -
布隆过滤器
在写入数据库数据时,使用布隆过滤器做标记。在用户请求到来时,如果缓存失效,可以通过布隆过滤器快速判断数据是否存在。如果不存在,就无需再访问数据库。即使发生缓存穿透,大量请求只会查询 Redis 和布隆过滤器,而不会查询数据库,保证数据库能正常运行。Redis 本身也支持布隆过滤器。
示例:
假设系统里用户 ID 只存在 1~100000 之间。如果有人传 id=200000**,在没有布隆过滤器时,系统会先查缓存(没有),再查数据库(也没有),等于白白增加了一次数据库压力。**
但如果用了布隆过滤器,直接判断 id=200000****不存在,就立刻返回错误或者空值,不会再去查数据库。这样即使恶意请求很多,也保护了数据库。