4. 哨兵机制
4.1 引入
前一篇文章中将主节点挂了的情况时,提到了哨兵机制。
主节点挂了,人工恢复的一般步骤:
- 先看主节点能不能抢救,好不好抢救。
- 如何挂的原因不好定位,或短时间难以解决。就要在从节点中选一个作为新的主节点:a. 选中的从节点通过slaveof no one 变为主节点;b. 其他从节点通过 slaveof 修改从属关系,连上新的主节点;c. 通知客户端(修改客户端配置),连接新的主节点。d. 主节点修好后,可以作为从节点,再添进去。
人工实时监测去修改,并不靠谱。因而要通过程序来自动化解决。
哨兵机制:即 通过一个 独立的进程 redis-sentinel(和 redis-server 是不同进程) 来监控 redis-server 进程。redis-sentinel 不存储数据,只监视。
4.2 工作流程
通常会存在多个 redis-sentinel 进程(单个哨兵存在单点问题,且容易误判(例如:没有挂,只是网络延迟较大)。一般为奇数个,即最少 三 个),监控现有redis master 和 slave 。
监控:这些进程间建立 tcp 长连接,定期发送心跳包
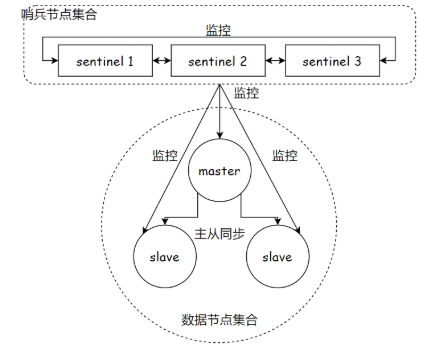
- 如果是从节点挂了,没什么影响。如果是主节点挂了,哨兵就有发挥作用了。 只有 一个哨兵判断主节点挂了,还不行,只有多个哨兵都判断主节点挂了才会认为主节点真挂了。(避免误判)
- 哨兵判定主节点真挂了,就会推举一个 leader,由 leader 负责在从节点中选出一个主节点
- 选出主节点后,哨兵节点,就会控制该节点,执行 slaveof no one,并控制其他节点,变为新主节点的从属
- 哨兵自动通知客户端程序,告知其新的主节点,后续写操作,针对新主节点进行
从上面可以得出 哨兵核心功能即 ① 监控;② 自动故障转移;③ 通知。
4.3 部署哨兵
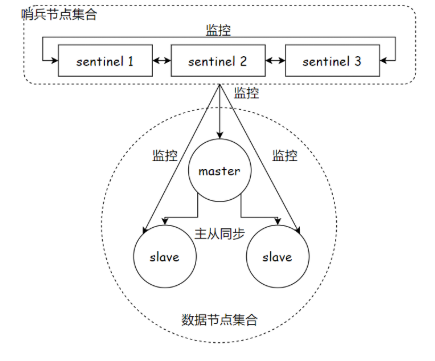
以该图为例,一共六个节点(三个 server,三个 sentinel)。正常应部署在 6 台不同的服务器上的,但是当前只有一个(实际中,部署在同一个上,没有意义)
由于节点较大,容易冲突如 端口号/配置文件/数据文件,直接部署就要很小心,此外在不同主机上部署时,也存在较大差异。所以,这里我们使用 docker 来解决这些问题
虚拟机,是通过软件在电脑上模拟一个虚拟的电脑,但是很吃配置,对于我们 2G/4G 的云服务器来说基本没法用。
docker 可以看作是一个 "轻量级虚拟机" (和虚拟机差别还是挺大的),能像虚拟机一样进行环境隔离,但又不吃太多硬件。
4.3.1 docker & docker-compose 安装及前置操作
系统为 ubuntu24
docker安装
bash
sudo apt install curl -y
sudo rm -f /etc/apt/keyrings/docker.gpg
sudo rm -f /etc/apt/keyrings/hashicorp.gpg
sudo rm -f /etc/apt/sources.list.d/docker.list
sudo rm -f /etc/apt/sources.list.d/hashicorp.list
sudo install -m 0755 -d /etc/apt/keyrings
sudo install -m 0755 -d /etc/apt/keyrings
curl -fsSL https://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
sudo apt update
sudo apt install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
sudo systemctl daemon-reload
sudo systemctl start docker
sudo systemctl enable docker照着一行一行执行即可
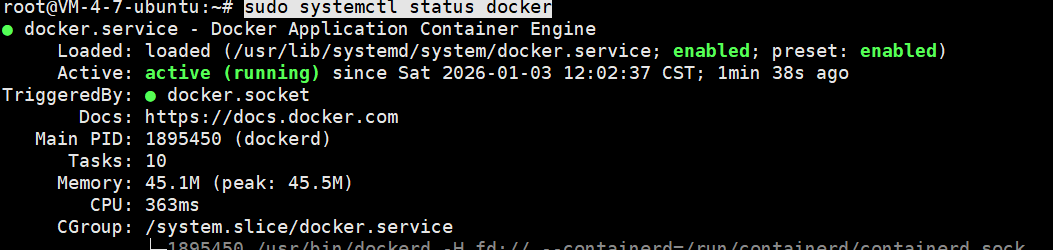
完成之后执行 sudo systemctl status docker ,结果是这样说明没有问题
docker-compose 安装
docker-compose 是用来通过配置文件批量操作容器的(容器可以看作是 轻量级虚拟机)
bash
apt install docker-compose关闭之前的redis-server,使用 docker 获取 redis 镜像
bash
docker pull redis:5.0.9这个镜像包含了一个精简的 Linux 操作系统,且上面上面装了 redis,只要直接基于这个镜像创建一个容器,运行容器,redis服务器就搭好了。
镜像和容器,类似于可执行程序和进程的关系
4.3.2 docker 加速器配置
由于是国内的服务器,所以没法正常访问国外 Docker Hub, 没法用。这里用的腾讯云服务器,加速器就用的腾讯云的。其他厂商的可在网上看看。
创建及修改文件
bash
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://mirror.ccs.tencentyun.com"]
}
EOF重启服务
bash
sudo systemctl daemon-reload
sudo systemctl restart docker通过 docker info 命令查看是否成功配置

这就是配置成功了。
4.3.3 容器编排
使用 docker-compose 进行容器编排,通过一个配置文件,将要创建容器,容器参数,描述清楚。后续通过一个命令,就能批量启动/停止这些容器
这里的配置文件采用 yml 的格式,虽然 6 个容器可以放在一个 yml 文件中,但是 6 个容器同时启动,哪个容器先启动完成是不确定的。
所以这里节点和哨兵各一个配置文件
4.3.3.1 编排节点
先创建配置文件,同时进入文件所在目录
bash
mkdir /root/redis/docker-compose.yml
cd /root/redis
touch docker-compose.yml修改配置文件内容如下:
bash
version: '3.7'
services:
master:
image: 'redis:5.0.9'
container_name: redis-master
restart: always
command: redis-server --appendonly yes
ports:
- 6379:6379
slave1:
image: 'redis:5.0.9'
container_name: redis-slave1
restart: always
command: redis-server --appendonly yes --slaveof redis-master 6379
ports:
- 6380:6379
slave2:
image: 'redis:5.0.9'
container_name: redis-slave2
restart: always
command: redis-server --appendonly yes --slaveof redis-master 6379
ports:
- 6381:6379注意:如果粘乱了,不能用 tab 键,只能用空格,用 tab 会解析失败,后续无法启动。
-
version:docker compose 文件的语法版本
-
services:有哪些服务
-
master,slave1,slave2: 为服务名,容器逻辑名,自己定的
-
image:使用哪个镜像启动容器,这里用之前下的那个镜像
-
contcontainer_name:容器实际名,如果不指定,则自动生成名字,如:project_master_1
-
restart:容器挂了,总是重新启动,手动关停不算
-
command :覆盖镜像默认启动的命令,上面的
--slaveof redis-master 6379中的 redis-master 是容器名,起到类似域名的作用,因为不知道容器启动后,会分配到哪个ip,虽然能配置静态ip,但是比较麻烦,直接用 容器名,docker 会自动解析得到对应域名 -
ports:容器端口映射到主机哪个端口,前一个是主机端口后一个是容器端口。每个容器的端口自成一派,容器间,容器主机间不冲突(即 容器1 的 6379 和 容器2 的 6379 不冲突这种,映射到一个还是会冲突)。
通过
bash
docker-compose up -d启动容器。
bash
docker-compose down停止并删除刚才创建的容器
通过 docker ps -a 查看所有容器的端口映射。
4.3.3.2 编排哨兵
先创建文件夹
bash
root@VM-4-7-ubuntu:~# mkdir redis-sentinel
root@VM-4-7-ubuntu:~# cd redis-sentinel/
root@VM-4-7-ubuntu:~/redis-sentinel# touch docker-compose.yml配置 yml 文件
bash
version: '3.7'
services:
sentinel1:
image: 'redis:5.0.9'
container_name: redis-sentinel-1
restart: always
command: redis-sentinel /etc/redis/sentinel.conf
volumes:
- ./sentinel1.conf:/etc/redis/sentinel.conf
ports:
- 26379:26379
sentinel2:
image: 'redis:5.0.9'
container_name: redis-sentinel-2
restart: always
command: redis-sentinel /etc/redis/sentinel.conf
volumes:
- ./sentinel2.conf:/etc/redis/sentinel.conf
ports:
- 26380:26379
sentinel3:
image: 'redis:5.0.9'
container_name: redis-sentinel-3
restart: always
command: redis-sentinel /etc/redis/sentinel.conf
volumes:
- ./sentinel3.conf:/etc/redis/sentinel.conf
ports:
- 26381:26379这里多了一个 volumes 字段,- ./sentinel2.conf:/etc/redis/sentinel.conf 含义是把宿主机当前目录下的 sentinel2.conf 文件,映射(挂载)到容器内部的 /etc/redis/sentinel.conf 路径。
原因是 redis sentinel 必须通过配置文件启动,不能只靠命令行参数,而容器内的文件是临时的,在宿主机上创建一个配置文件,通过 volumes "共享"进容器,即使容器重启,配置文件依然存在。
格式:宿主机路径:容器路径
宿主机路径:可以是相对路径(如 ./file)或绝对路径(如 /home/user/file)
容器路径:必须是完整路径
权限问题:确保宿主机上的 sentinel3.conf 可读(一般默认即可)
热更新:修改宿主机的 sentinel3.conf 后,需要重启容器才能生效(Sentinel 不支持动态重载配置)
如果宿主上不存在对应文件,Linux 就会自动创建一个空目录(不是文件)
配置 conf 文件
bash
bind 0.0.0.0
port 26379
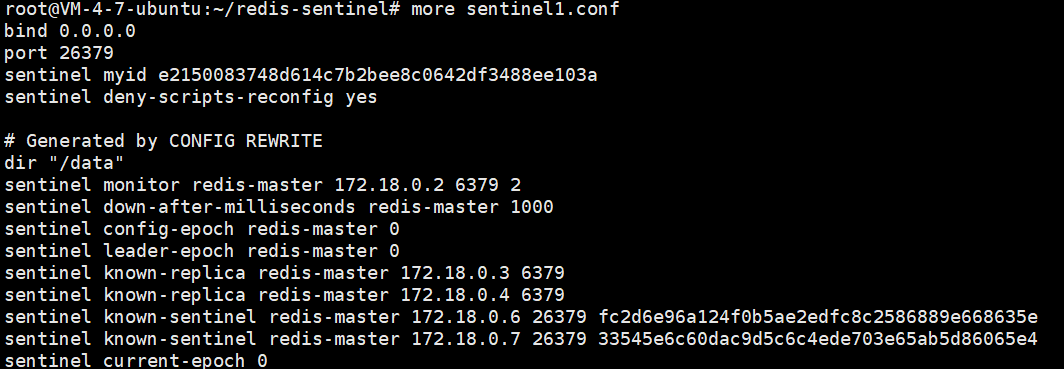
sentinel monitor redis-master redis-master 6379 2
sentinel down-after-milliseconds redis-master 1000三个哨兵一人一份, conf 文件。
sentinel monitor redis-master redis-master 6379 2
规定了监视哪个节点, 前一个 redis-master 为主节点名,后一个为 主节点ip,6379 为容器端口,2 为法定票数(即大于等于2台哨兵,认为主节点挂了,就认为主节点真挂了)
`sentinel down-after-milliseconds redis-master 1000``
主节点和哨兵间通过心跳包沟通,这里是超时时间。
三个哨兵的conf 文件内容一致,还要要创建多份配置文件,是因为 redis-sentinel 在运行时可能会 rewrite 配置,共用一份会写乱。
通过 docker-compose logs 查看日志,发现 sentinel 说找不到主节点
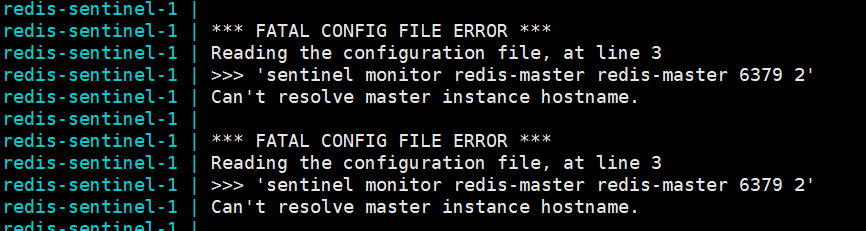
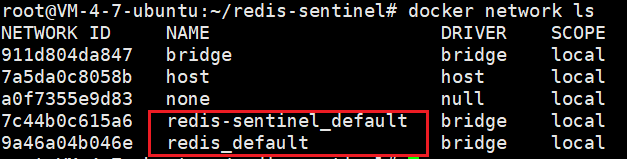
这是因为 server 和 sentinel 是分别启动的,而同一个 yml 文件内的容器自动划分到同一个局域网。这就使得 三台节点,三台哨兵处在不在同一局域网内,因而无法解析 redis-master,进而找不到。
通过 docker network ls 命令,可以看到他们位于不同局域网中
处理方法
在 yml 文件最下面加上如下配置,让 sentinel 加入 server 的局域网中
bash
networks:
default:
external:
name: redis-data_default注意这里的 name 和前面 docker network ls 中的名字要一致。
接着重新启动 sentinel 即可。
同时,观察主机上的 sentinel.conf 文件,发现已经被哨兵 rewrite 了
4.4 哨兵功能实验
通过 docker stop 容器名 关闭容器
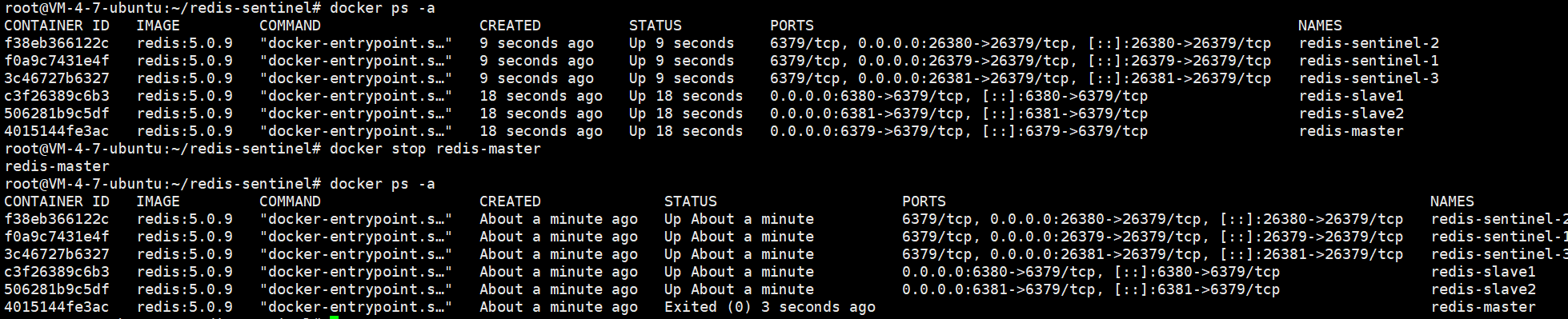
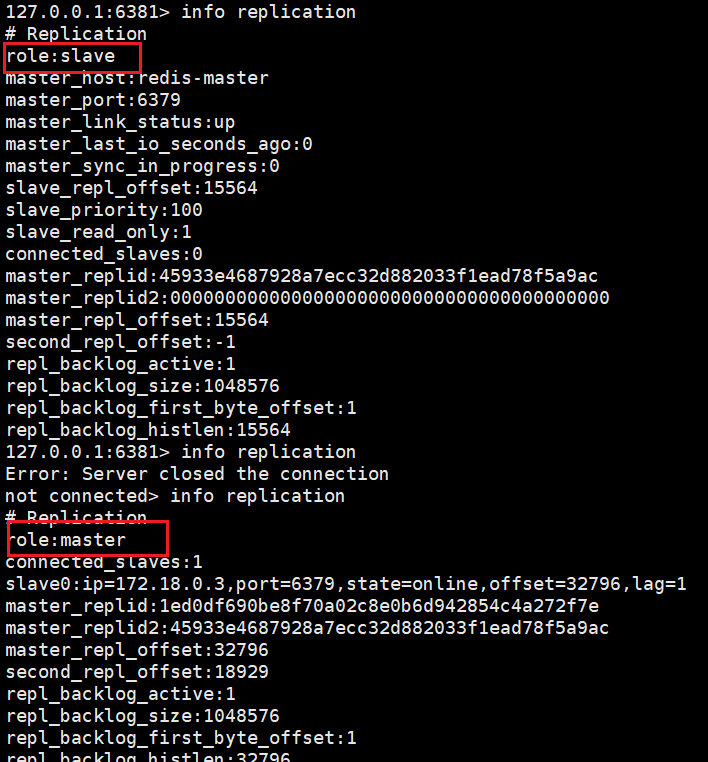
发现 6381 端口的从节点 变为了主节点
4.5 重选流程
查看 sentinel 日志

sdown 主观下线,本哨兵认为主节点下线
odown 客观下线,认为主节点挂的达到法定票数(一兵一票)

更改了主节点,和余下从属节点的所属关系。
如果 旧主节点恢复了,就作为从节点再加进去,这里不做演示。
- 主观下线
- 客观下线
- 哨兵推选 leader, leader 负责挑选主节点,并更该余下节点从属关系(所以一般为奇数,不然容易平票)
- leader 推举出后,选主节点先看 1)优先级,每个redis数据节点,配置文件中都有一个优先级设置 slave-priority,优先级高的,作主节点;优先级相同则看 2)offset ,offset 大的作主;还相同则看 3)runid,runid 是启动时随机的,所以就是随便选一个了。
leader 选举,每个哨兵一票,可投自己,当所得票数超哨兵个数一半,就选举完成了(为什么为奇数个哨兵),一般都会先投自己,其他节点如果感知到了前面有人投他自己,就会投那个哨兵。大致就是看谁最早投票。
- 哨兵节点,不能只一个,不然哨兵挂了会影响系统可用性
- 哨兵最后奇数个,方便选 leader
- 哨兵 + 主从复制 解决的是高可用性问题,不能解决 "极端情况下写丢失" 问题
- 哨兵 + 主从复制 不能提高数据的存储容量,当要存的数据接近或超过物理内存,这样的结构就难以胜任了。