缓存简介
缓存是数据交换的缓冲区,通常读写性能较高,其作用有:
- 降低后端负载,常用数据在缓存中读写,避免请求进入后端服务器;
- 降低响应时间,利用其高读写性能,提高效率。
同时缓存带来的成本有:
- 数据一致性问题,缓存与后端服务器的一致性保证需要额外处理;
- 代码及运维成本,为了保证一致性、缓存健壮性与解耦等问题带来成本。
缓存要保证数据可用,最重要的就是更新策略,下面将详细介绍。
缓存更新策略
| 内存淘汰 | 超时剔除 | 主动更新 | |
|---|---|---|---|
| 说明 | Redis内部因内存不足的自动淘汰策略 | 给缓存添加TTL,到期删除缓存 | 自行编写业务逻辑,保证数据库与缓存同步更新 |
| 一致性 | 低 | 一般 | 高 |
| 维护成本 | 无 | 低 | 高 |
低一致性要求的场景,可以使用内存淘汰或超时剔除策略;
高一致性要求下使用主动更新,同时使用超时剔除作为兜底,避免更新失败。
主动更新策略
在高一致性要求的场景下通常选择主动更新策略,其实现思路有以下几种:
- Cache Aside(缓存旁路):代码层直接操作数据库和缓存,实现逻辑复杂,一致性保证需要自行实现,比较灵活,生产环境中高并发场景多采用该方案;
- Read/Write Through(读穿 / 写穿策略):将缓存和数据库整合为一个服务,调用者无需关注具体细节,缓存作为数据库的代理层,调用者操作缓存,后续持久化操作同步完成,一致性强,性能受限;
- Write Behind Caching(写回策略):调用者只操作缓存,与数据库交互等操作由线程异步完成,性能最优,但一致性弱。
要注意的一些细节:
- 更新策略选择删除而非更新:数据变化时更新到缓存是维护中常想到的方法,但这种方法会导致不必要的写操作,可设置为更新时删除数据,读取时从数据库中调用,直接获取最新值,同时也能避免多线程的脏写入;
- 用事务保证操作原子性:为了保证缓存和数据库的数据一致性,通常将二者的操作整合为一次事务,分布式系统中使用TCC等分布式事务方案。
- 先操作数据库,后操作缓存:数据库操作慢,缓存操作快,多线程场景下可最大程度缩短操作之间的时间窗口,若先删缓存再更数据库,可能出现读请求加载旧数据到缓存的脏读情况。
缓存更新小总结,高一致性要求场景下的方案:主动更新+自编码的Cache Aside+三注意
缓存穿透
缓存穿透是指数据在缓存和数据库中都不存在,并被恶意利用攻击数据库的情况,解决方案有两种:
- 缓存空对象:这种方式简单粗暴,缓存数据库中未命中的空对象为
null,即可避免对数据库的攻击,但带来了额外的内存消耗,需要设置合理的TTL; - 布隆过滤:在用户和缓存中间设置布隆过滤器,该过滤器通过哈希计算id是否已经存在,内存占用少,实现复杂,且不是100%准确,有误判可能。
有关布隆过滤器的详细介绍可见:布隆(Bloom Filter)过滤器,其本质上是一个很长的二进制向量和一系列随机映射函数,可以用于检索一个元素是否在一个集合中。
也可以使用一些主动防御攻击的手段,如:
- 增加id复杂度,避免被攻击者猜测id,找到合理但不存在的id值;
- 基础格式校验,用户id应该满足一定格式才能到数据库中查找;
- 用户权限校验,热点参数限流等,避免重复请求。
使用缓存空对象解决缓存穿透问题的流程示意图如下:
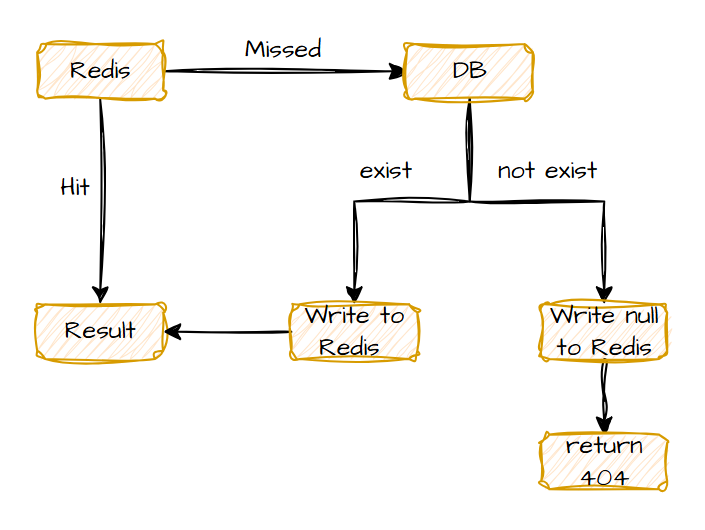
如果数据库查询不存在直接返回404,用户可能多次查询相同id,请求全部穿透缓存直接访问数据库,数据库查询不到结果时,将空对象写入缓存,下次再查询相同id就会被缓存拦截。
缓存雪崩
缓存雪崩是指同一时段大量缓存同时失效,或Redis服务器宕机,导致大量请求同时到达数据库的现象,请求像雪崩一样砸向数据库,形成下图的场景:
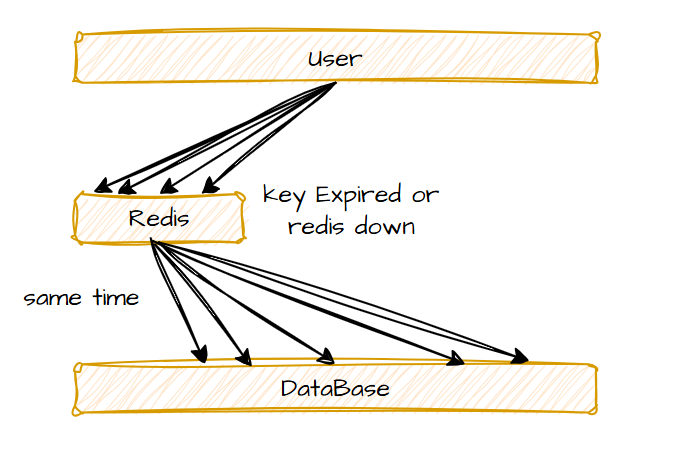
该现象可以通过下面几个方法解决:
- 随机TTL:解决同一时段大量缓存同时失效的问题,缓存过期时间设置随机值,避免因预热导入的key一起过期;
- Redis集群:解决Redis服务器宕机问题,增加系统健壮性;
- 缓存业务添加降级限流策略:如快速失败,拒绝服务等策略,牺牲服务实时性保护数据库;
- 多级缓存:可部署浏览器缓存---Nginx缓存---Redis缓存---JVM本地缓存,多级缓存体系保护数据库。
缓存击穿
缓存击穿是指部分热点、高并发且缓存重建业务复杂的关键key过期,这部分key失效的重建过程长,且长期是访问热点,导致大量并发请求同时穿透缓存,涌向数据库查询并尝试重建缓存。
该场景解决多个线程同时重建缓存的开销,主要解决方案有以下两种:
- 互斥锁:一个线程缓存未命中,要重建缓存时,先获取互斥锁,重建后写入缓存再释放锁,未命中的线程获取锁失败会等待并重新查询,该方案能保证数据一致性,但是线程等待性能受限,且有死锁风险。
- 逻辑过期 :缓存不设置TTL,只加上逻辑过期时间,实质永不过期。获取key时会判断是否过期,弱过期则先返回旧数据,并异步到数据库查询最新数据,性能好,但不保证一致性。(与前面介绍本地缓存文章的降级策略雷同)
总结
本文介绍了威胁缓存健壮性的三大场景,并给出解决方案:
- 缓存穿透 :不存在的数据被用于恶意攻击数据库,缓存空对象或布隆过滤器;
- 缓存雪崩 :缓存服务器宕机或大量key同时失效,随机TTL、Redis集群、降级策略与多级缓存;
- 缓存击穿 :热点key过期并发查询重建,互斥锁或逻辑过期。
但学到这里我有两个疑问:
- 数据库有这么脆弱吗?需要这么复杂的缓存机制来保护,好像访问请求稍微一多就不行了。
- 缓存有这么健壮?所有热点数据都给缓存,内存开销等压力全部交给缓存,难道就不怕缓存崩了?
回答一:不是数据库脆弱,而是"不是他的活,他要干" 。
数据库的核心职责是持久化存储 + 强一致性保证,底层依赖磁盘 IO,同时要处理事务、索引、锁等复杂逻辑,所以其高并发读的能力天然有限。也就是数据库的设计目的就是存储,而不是高频读,只是借助缓存完成需求。
回答二:缓存也需要关心照顾 。
缓存内存存储,确实抗高并发读,但也有一些缺点,如内存有限、单节点宕机,目前也有一些保护缓存的方法,如:缓存只保存热点数据、部署集群、淘汰策略控制内存开销以及多级缓存。
所以本质上高并发的解决方案=缓存+数据库,二者是搭档关系,缓存承接高频读压力、数据库保障持久化与强一致性,二者各司其职、互补短板,共同支撑高并发、高可用的业务需求。