前言
在上一篇《主键表之合并引擎merge-engine》中的结尾,当 'merge-engine' = 'first-row',开启流读的时候,会抛一下错误,提示要使用 lookup 或 full-campaction 这两种 changelog producer 才支持流读,input 模式也支持,但是只会返回输入的记录。

changelog producer的作用
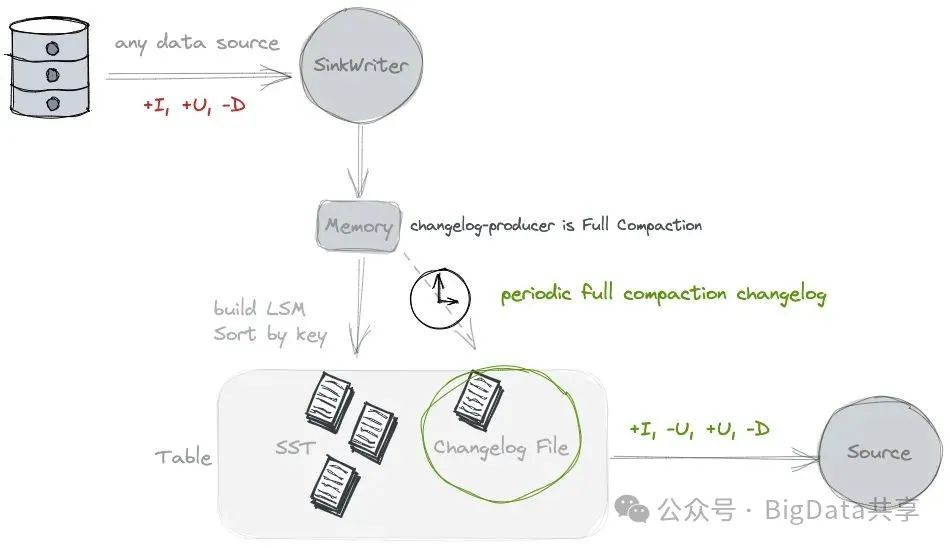
Changelog Producer 的主要作用是生成完整的变更日志,记录数据的插入(+I)、更新(+U/-U)或删除(-D)操作,以便下游消费者(例如流式计算引擎 Flink)能够基于这些变更进行实时分析。为什么需要完整的变更日志呢?举个例子:创建一张paimon表:user_id 和 order_id 组成主键,amount 表示订单金额,业务需求是通过这张表实时计算每个 user_id 的总消费金额(SUM(amount))。上游对表插入2条数据:第一次插入 +I (user1, order1, 100); 第二次更新数据 +I (user1, order1, 150); 如果没有中间变更日志,这个需求就算不出来。
本文依旧使用 Flink-1.16 + Paimon-1.0.1 版本,通过 Flink SQL 进行读写演示。
一. None
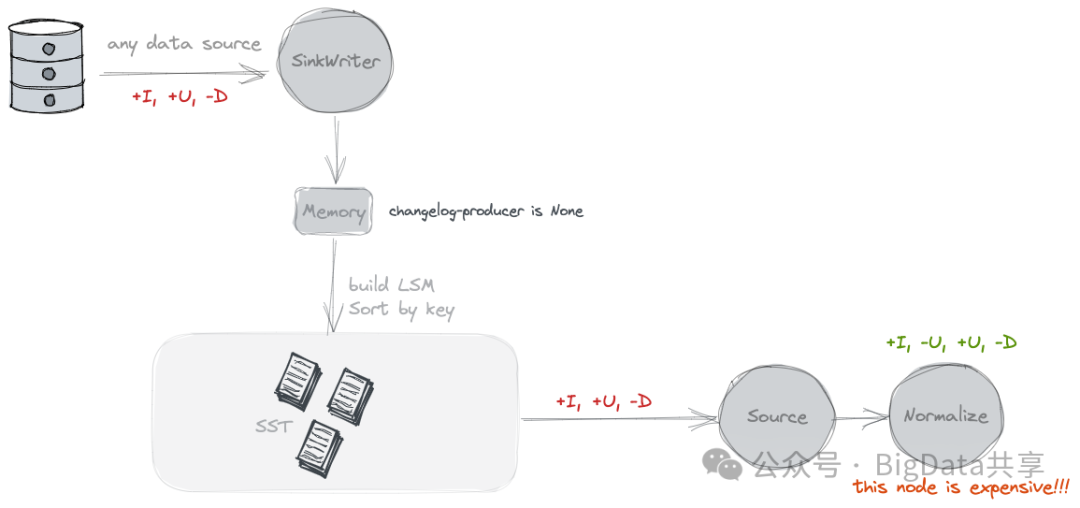
功能:默认情况,'changelog-producer'='none', 不启用额外的 Changelog Producer,不会生成额外的 Changelog 日志文件,Paimon 仅生成快照间的合并变更,无法知道同一快照内的数据变更。
使用场景:对变更日志需求不高的批处理任务。
局限性:无法形成完整的变更日志,消费者可能需要额外的逻辑来处理旧值。
SET 'execution.runtime-mode' = 'streaming';SET 'table.exec.sink.upsert-materialize'='NONE';SET 'execution.checkpointing.interval'='20 s';
CREATE CATALOG paimon WITH ( 'type' = 'paimon', 'warehouse' = 'file:///tmp/paimon');
USE CATALOG paimon;create database if not exists changelog_db;USE changelog_db;
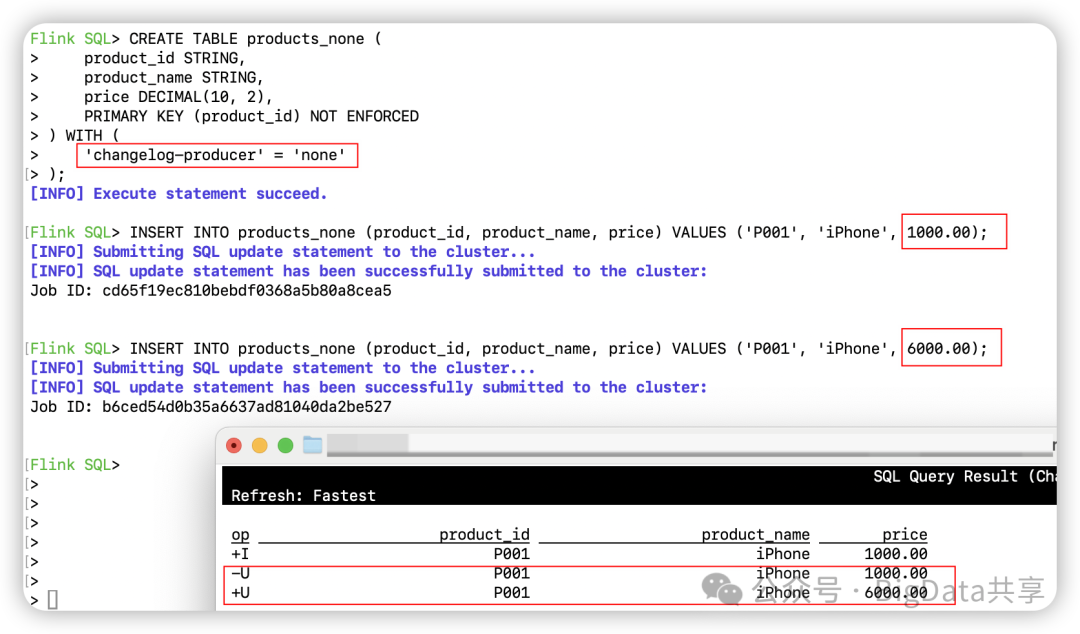
CREATE TABLE products_none ( product_id STRING, product_name STRING, price DECIMAL(10, 2), PRIMARY KEY (product_id) NOT ENFORCED) WITH ( 'changelog-producer' = 'none');
INSERT INTO products_none (product_id, product_name, price) VALUES ('P001', 'iPhone', 1000.00);INSERT INTO products_none (product_id, product_name, price) VALUES ('P001', 'iPhone', 6000.00);另起一个客户端进行流读
CREATE CATALOG paimon WITH ( 'type' = 'paimon', 'warehouse' = 'file:///tmp/paimon');
SET 'execution.runtime-mode' = 'streaming';SET 'sql-client.execution.result-mode' = 'changelog';
SELECT * FROM paimon.changelog_db.products_none;然后插入2条数据,通过流读 changelog 可以看到能看到更新前和更新后的数据,这是因为这2条数据在不同的快照里保存,同时下游消费者状态里记录着快照跟快照之间的数据变更。
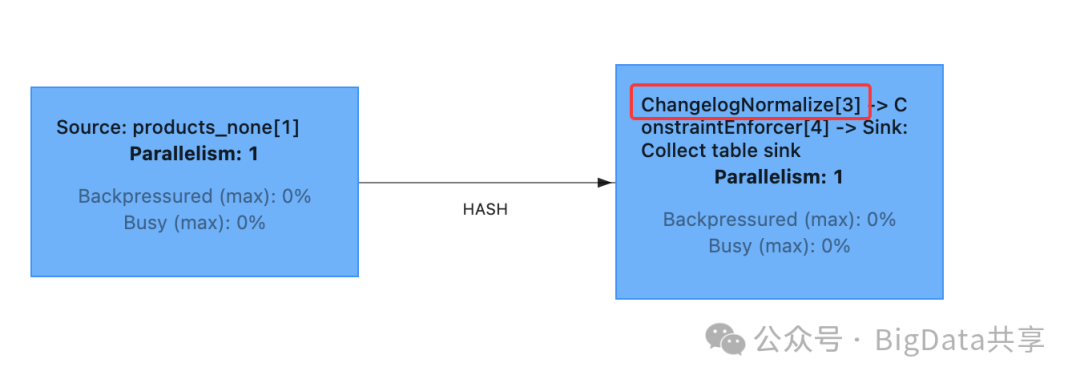
ChangelogNormalize这个算子就是用来记录不同快照间的数据变更,维护这么一个状态,这个成本是非常高的。
通过 'scan.remove-normalize' = 'true',去掉这个算子,就没法看到完整的变更过程。
SELECT * FROM paimon.changelog_db.products_none /*+ OPTIONS('scan.remove-normalize' = 'true') */;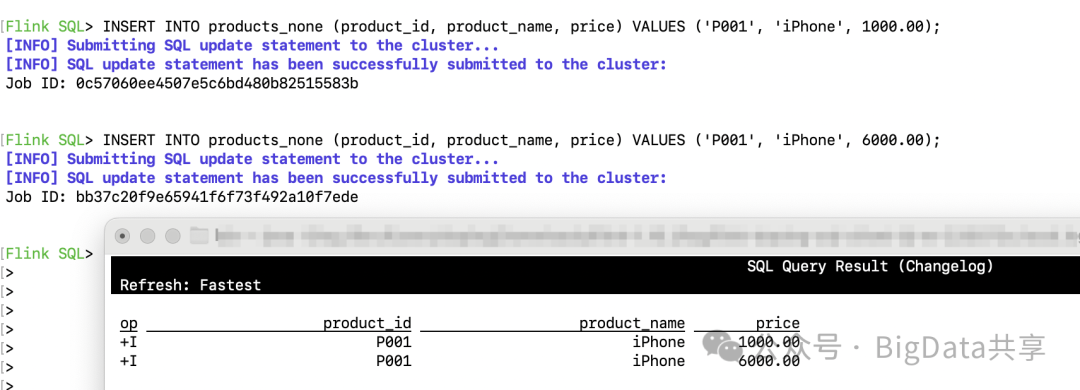

二. Input
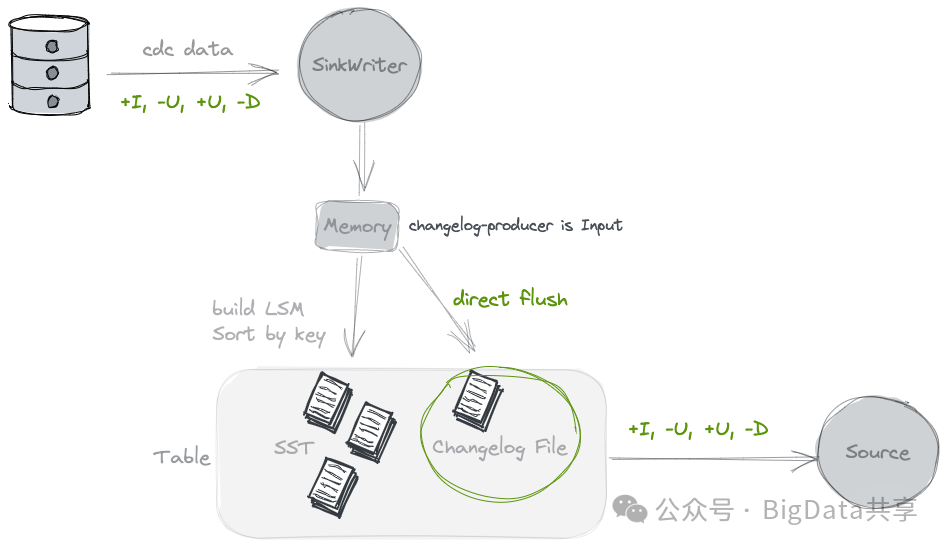
功能:设置 'changelog-producer' = 'input',Paimon 将输入数据直接作为完整的变更日志,保存到独立的 changelog 文件中。
使用场景:入数据已包含完整变更信息,如 mysql binlog 日志。
局限性:如果输入数据无法提供完整的变更日志,则不适用。
CREATE TABLE products_input ( product_id STRING, product_name STRING, price DECIMAL(10, 2), PRIMARY KEY (product_id) NOT ENFORCED) WITH ( 'changelog-producer' = 'input');
INSERT INTO products_input (product_id, product_name, price) VALUES ('P001', 'iPhone', 1000.00);INSERT INTO products_input (product_id, product_name, price) VALUES ('P001', 'iPhone', 6000.00);
SELECT * FROM paimon.changelog_db.products_input;另起一个客户端进行流读,插入2条数据,可以看到changelog数据就是写入的原始数据;
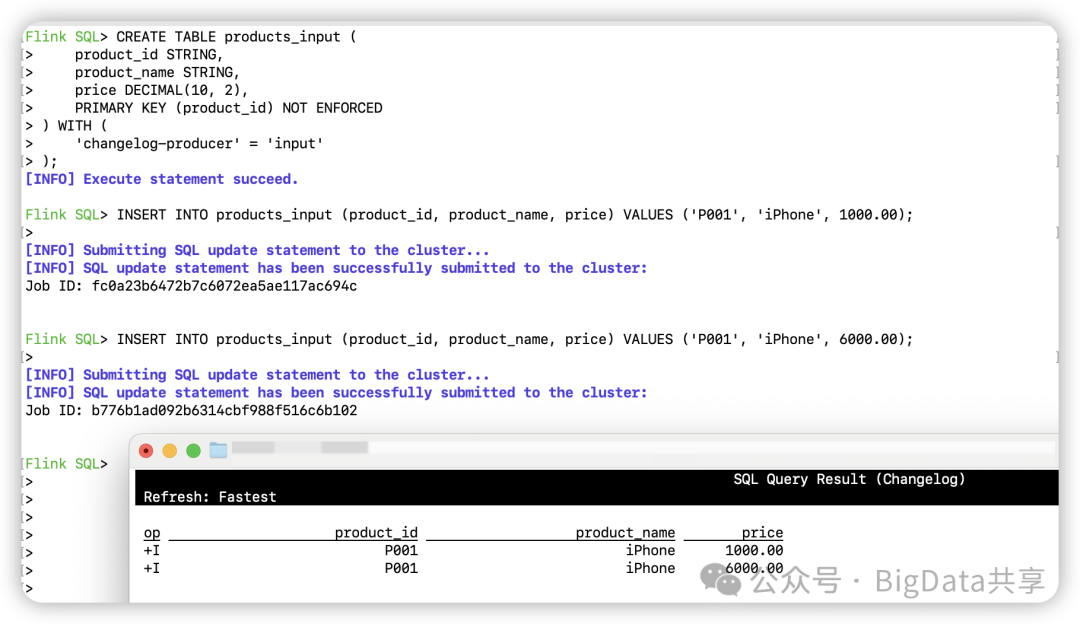
会生成changelog日志

三. Lookup
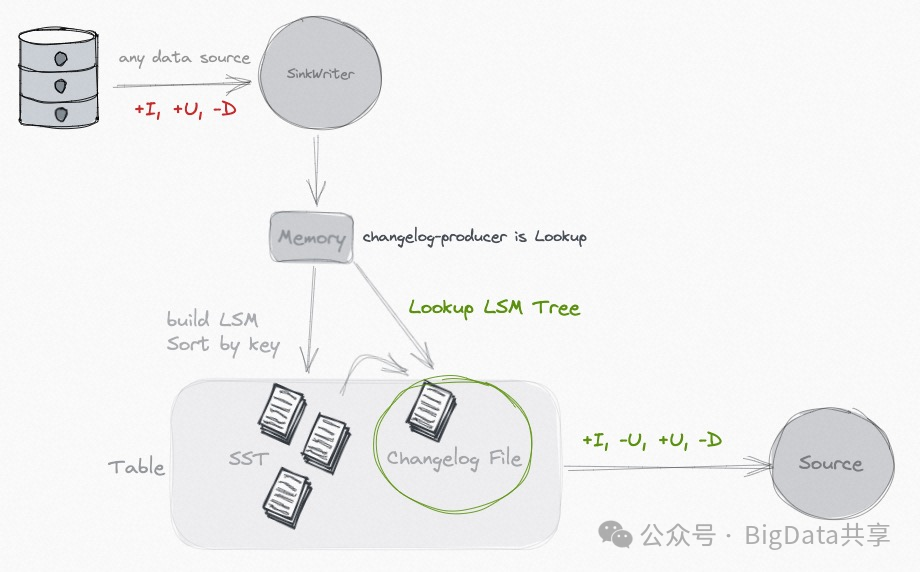
**功能:**设置 'changelog-producer' = 'lookup',Paimon 在提交数据写入前通过查找(lookup)生成变更日志。
使用场景:输入数据不包含完整变更日志,但需要生成完整变更日志的场景;表在写入过程中有计算逻辑(first-row/partial-update/aggregation 等合并引擎)使用该模式,与full-compaction机制相比,lookup机制的时效性更好。
局限性:相比 Input 模式,资源消耗较高(需要额外的查找操作)。
CREATE TABLE products_lookup ( product_id STRING, product_name STRING, price DECIMAL(10, 2), PRIMARY KEY (product_id) NOT ENFORCED) WITH ( 'changelog-producer' = 'lookup');
INSERT INTO products_lookup (product_id, product_name, price) VALUES ('P001', 'iPhone', 1000.00);INSERT INTO products_lookup (product_id, product_name, price) VALUES ('P001', 'iPhone', 6000.00);另起一个客户端进行流读,插入2条数据,可以看到变更前和变更后的数据。
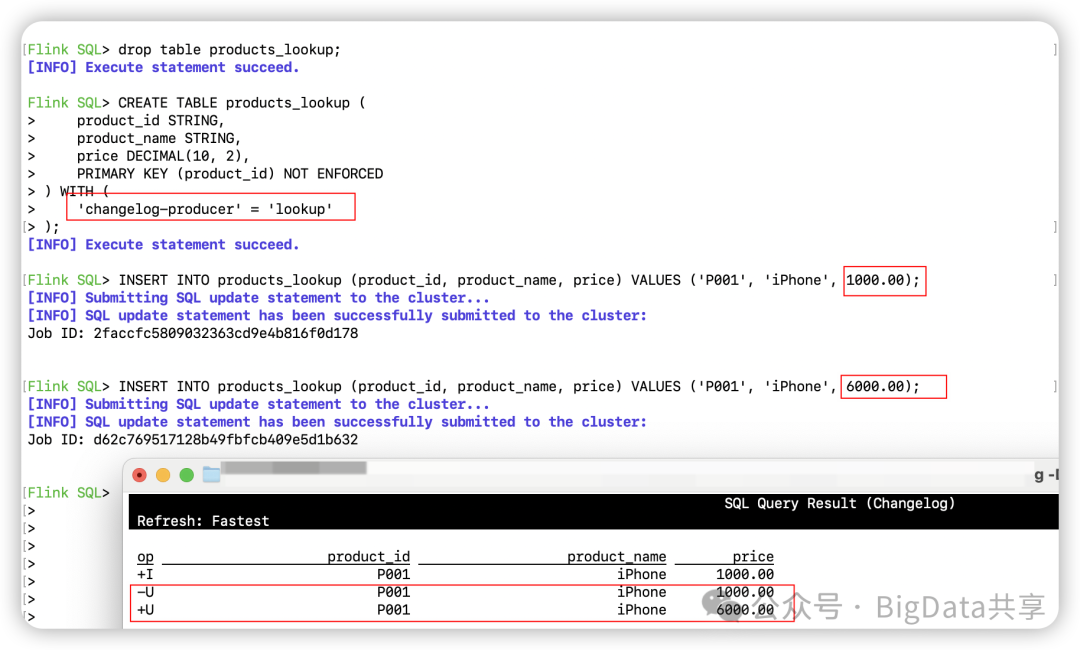
会有额外的 changelog 日志生成

四. Full Compaction
**功能:**设置 'changelog-producer' = 'full-compaction',Paimon 通过全量压缩(full compaction)比较前后数据,生成变更日志;可通过 full-compaction.delta-commits 属性设置触发全量压缩的频率(默认值为 1,即每次 checkpoint 触发一次全量压缩)。
使用场景:输入数据不包含完整变更日志,但需要生成完整变更日志的场景。
局限性:全量压缩的成本和资源消耗较高,可能会影响性能,同时变更日志的延迟受全量压缩频率影响。
CREATE TABLE products_compaction ( product_id STRING, product_name STRING, price DECIMAL(10, 2), PRIMARY KEY (product_id) NOT ENFORCED) WITH ( 'changelog-producer' = 'full-compaction');INSERT INTO products_compaction (product_id, product_name, price) VALUES ('P001', 'iPhone', 1000.00);INSERT INTO products_compaction (product_id, product_name, price) VALUES ('P001', 'iPhone', 6000.00);另起一个客户端进行流读,插入2条数据,可以看到变更前和变更后的数据。
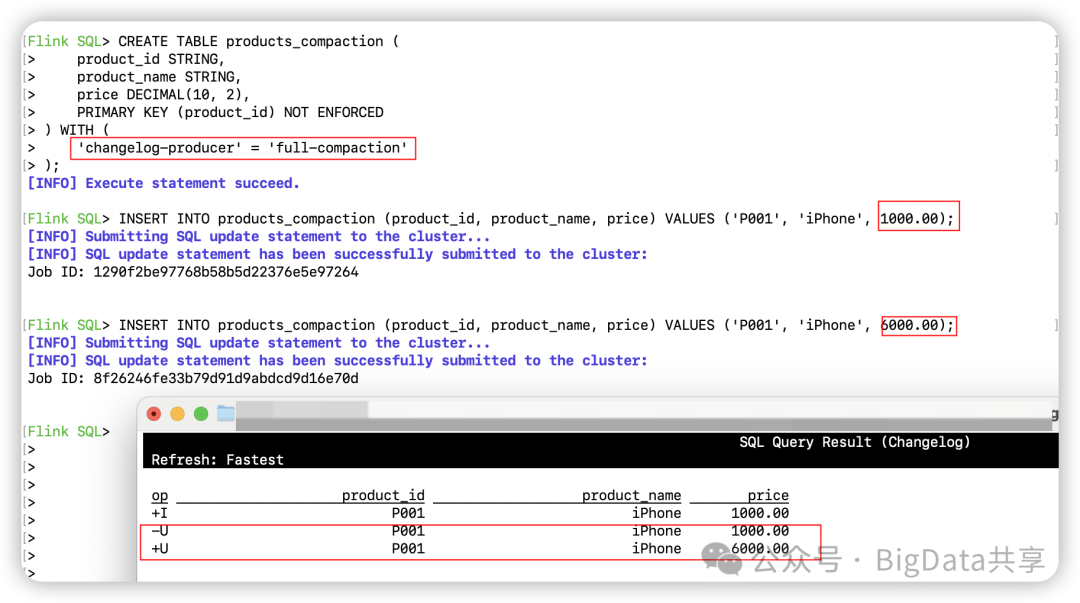
会有额外的 changelog 日志生成

总结
Paimon 的 Changelog Producer 是其流式读写功能的核心组件,通过 None、Input、Lookup 和 Full-Compaction 四种模式支持不同的变更日志生成需求。用户可以根据输入数据的特性、延迟要求和性能需求选择合适的模式。推荐优先使用 Lookup 或 Input 模式以获得更好的性能,而 Full-Compaction 模式适合对延迟要求较低的场景。
后面的文章会深入分析 Paimon 是如何基于 LSM 进行高效的流式更新。
更多大数据干货,欢迎关注我的微信公众号---BigData共享