Python 3.14 来了。它有多快?
2024 年 11 月,我写了一篇博客文章,题为 "Python 真的那么慢吗?" ,其中我测试了 Python 的几个版本,并注意到该语言在性能方面取得了稳步的进步。
今天是 2025 年 10 月 8 日,距离 Python 3.14 正式发布仅剩一天。让我们重新运行基准测试,看看新版本的 Python 到底有多快!
注意:如果您不关心带有结果的表格和图表,而只想阅读我的结论, 请单击此处转到文章末尾 。
简单说说基准测试的误导性
虽然我打算分享我的基准测试结果,但我觉得还是要再次提醒大家,就像我在上一篇文章中说过的那样,像这样的通用基准测试其实没什么用。运行这些基准测试很有趣,这也是我这样做的原因,但仅仅通过运行几个简单的小脚本,就无法对像 Python 解释器这样复杂的系统构建准确的性能分析。
我设计的测试只运行纯 Python 代码 ,避免使用任何依赖项,尤其是任何用 C 代码编写的函数。原生(Native )代码(Python 解释器本身除外)不太可能在 Python 版本之间变得更快,因此我认为没有必要将其纳入基准测试。但现实世界中的应用程序确实经常混合使用纯 Python 代码和原生代码(无论是 C、C++ 还是 Rust),因此虽然我的测试脚本非常适合评估纯 Python 代码的性能,但我认为它们并不能代表我们通常使用的应用程序。
简而言之,看看我的基准,但将其视为一个数据点,而不是 Python 性能的最终结论!
测试矩阵
这是我使用的测试矩阵,有五个维度:
- 6 个 Python 版本,以及 Pypy、Node.js 和 Rust 的最新版本:
- 3 个 Python 解释器
- Standard 标准
- Just-In-Time (JIT): only for CPython 3.13+
- Free-threading (FT): only for CPython 3.13+
- 2个测试脚本
- 2 种线程模式
- 单线程(Single-threaded)
- 4个线程运行独立计算(4 threads running independent calculations)
- 2台电脑
- Framework laptop running Ubuntu Linux 24.04 (Intel Core i5 CPU)
- Mac laptop running macOS Sequoia (M2 CPU)
你可能觉得在我的基准测试中包含 Node.js 和 Rust 是一个奇怪的选择。或许确实如此,但同样地,我将这两个 Python 测试应用程序移植到了 JavaScript 和 Rust 上,这样我就可以获得一些来自 Python 生态系统之外的参考数据,以便更好地理解情况。
测试脚本
下面您可以看到 fibo.py 中的主要逻辑:
python
def fibo(n):
if n <= 1:
return n else:
return fibo(n-1) + fibo(n-2)经过一些实验后,我确定使用此函数在我的两台笔记本电脑上计算第 40 个斐波那契数需要几秒钟,因此这就是我在下面分享的所有测试结果所使用的。
这是 bubble.py 中的排序函数:
python
def bubble(arr):
n = len(arr)
for i in range(n):
for j in range(0, n-i-1):
if arr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
return arr对于这个脚本,我还仔细观察了要使用的数组大小,以便脚本运行几秒钟。我决定使用一个包含 10,000 个随机生成的数字的列表。
请不要认为这些例子很棒,因为它们并非如此。如果目标是让这些函数运行得尽可能快,那么有更高效的方法来编写它们。但这里的目标不是编写快速的函数,而是比较不同的 Python 解释器如何运行代码。我选择这些函数主要是因为其中一个是递归的,另一个不是,所以在测试集中我有两种不同的编码风格。
我为运行此基准测试而构建的框架会执行每个测试函数三次,并报告三次运行的平均时间。完整的测试脚本以及基准测试脚本可在 GitHub 仓库中找到。
Benchmark #1: Fibonacci single-threaded
好的,让我们看一下第一个测试。在这个测试中,我测量了运行 fibo(40) 所需的时间(以秒为单位)。如上所述,对于每个数据点,我运行了三次代码并取平均值。
以下是表格形式的数字:
| fibo 1 thread | Linux | macOS | vs. 3.14 |
|---|---|---|---|
| 3.9 | 15.21 | 13.81 | 0.45x |
| 3.10 | 16.24 | 14.97 | 0.42x |
| 3.11 | 9.11 | 9.23 | 0.71x |
| 3.12 | 8.01 | 8.54 | 0.78x |
| 3.13 | 8.26 | 8.24 | 0.79x |
| 3.14 | 6.59 | 6.39 | -- |
| Pypy 3.11 | 1.39 | 1.24 | 4.93x |
| Node 24 | 1.38 | 1.28 | 4.88x |
| Rust 1.90 | 0.08 | 0.10 | 69.82x |
最右边一列显示的是与 3.14 的速度比,因此此列中小于 1 的数字表示相应的测试比 3.14 慢,大于 1 的数字表示更快。为了计算这些比率,我使用了 Linux 和 macOS 结果的平均值。
有时以图形方式查看数据也会有所帮助,因此这里有一个包含上述数字的图表:
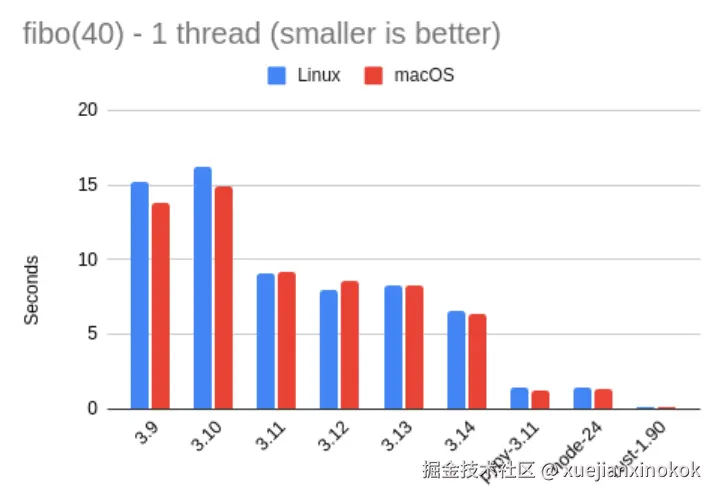
从这些结果中我们能看出什么?我们可以看到,3.14 比 3.13 有了显著的速度提升。它的运行速度提高了近 27%,换句话说,3.13 的运行速度大约是 3.14 的 79%。这些结果还表明,3.11 版本是 Python 版本从"非常慢"走向"不那么慢"的转折点。
还有一个与 Python 3.14 无关的细节是,Pypy 继续让我惊叹不已。在这次测试中,它比 Node.js 快了一点点,比 3.14 快了近 5 倍。这令人印象深刻,尽管它与 Rust 的差距仍然很大,但 Rust 不出所料地遥遥领先于其他所有语言。
Just-In-Time and Free-Threading Variants
从 Python 3.13 开始,CPython 解释器有三种版本 :标准(standard)、自由线程 (FT,free-threading) 和即时编译 (JIT, just-in-time)。自由线程解释器 禁用了全局解释器锁 (GIL),这一改变有望大幅提升多线程应用程序的速度。JIT 解释器包含一个即时编译器,可编译为本机代码,理论上,它可以通过仅编译一次本机代码,帮助多次运行的代码部分提高运行速度。
我上面分享的 3.13 和 3.14 版本的结果使用的是 标准解释器,但我还想具体看看其他两个解释器版本在我的测试中的表现。在下面的表格和图表中,您可以看到在 3.13 和 3.14 下三个解释器上运行相同测试的比较:
| fibo 1 thread | Linux | macOS | vs. 3.14 |
|---|---|---|---|
| 3.13 | 8.26 | 8.24 | 0.79x |
| 3.13 JIT | 8.26 | 8.28 | 0.78x |
| 3.13 FT | 12.40 | 12.40 | 0.52x |
| 3.14 | 6.59 | 6.39 | -- |
| 3.14 JIT | 6.59 | 6.37 | 1.00x |
| 3.14 FT | 7.05 | 7.27 | 0.91x |
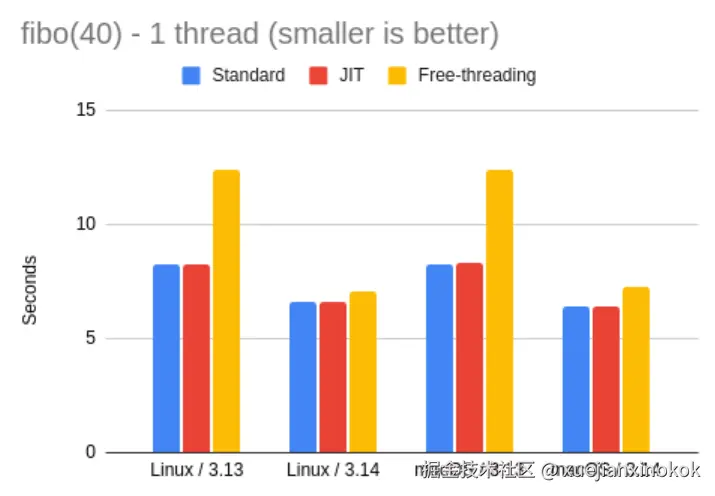
这有点令人失望。至少在这次测试中,JIT 解释器并没有带来任何显著的性能提升,以至于我不得不反复检查我使用的解释器是否正确构建并启用了此功能。我对新 JIT 编译器的内部机制不太了解,但我想知道它是否无法处理这个高度递归的函数。
至于自由线程,我去年就发现解释器在运行单线程代码时速度很慢。在 3.14 中,这个解释器似乎仍然比标准解释器慢,但差距已经小得多,自由线程的运行速度仅为标准解释器速度的 91%。
Benchmark #2: Bubble sort single-threaded
以下结果是针对冒泡排序基准测试,对 10,000 个随机数的数组进行排序:
| bubble 1 thread | Linux | macOS | vs. 3.14 |
|---|---|---|---|
| 3.9 | 3.77 | 3.29 | 0.60x |
| 3.10 | 4.01 | 3.38 | 0.57x |
| 3.11 | 2.48 | 2.15 | 0.91x |
| 3.12 | 2.69 | 2.46 | 0.82x |
| 3.13 | 2.82 | 2.61 | 0.78x |
| 3.14 | 2.18 | 2.05 | -- |
| Pypy 3.11 | 0.10 | 0.14 | 18.14x |
| Node 24 | 0.43 | 0.21 | 6.64x |
| Rust 1.90 | 0.04 | 0.07 | 36.15x |
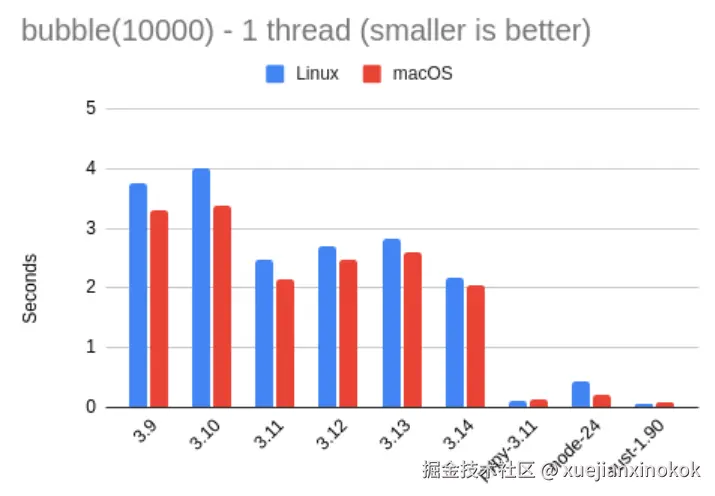
本次测试显示,我的 Linux 和 macOS 笔记本电脑之间的差异较大,但两台机器上不同版本之间的比率大致相同。这种差异只是表明 Mac 上的 Python 能够稍微快一点地运行此测试。
3.14 解释器在 Fibonacci 测试中是 CPython 中速度更快的,但两者之间的差距比之前的基准测试要小,Python 3.11 的速度仅为 3.14 的 91%。此外,在 3.12 和 3.13 中的测试运行速度也比 3.11 慢,这是我在去年的基准测试中也观察到的一个有趣的现象。
Pypy 这次比 3.14 快了 18 倍,甚至比 Node 快了 3 倍。我真的需要花点时间评估一下 Pypy,因为它看起来棒极了。
Just-In-Time and Free-Threading Variants
让我们看看 3.13 和 3.14 版本的专用解释器在冒泡排序测试中的表现。以下是结果表格和图表:
| bubble 1 thread | Linux | macOS | vs. 3.14 |
|---|---|---|---|
| 3.13 | 2.82 | 2.61 | 0.78x |
| 3.13 JIT | 2.59 | 2.44 | 0.84x |
| 3.13 FT | 4.13 | 3.75 | 0.54x |
| 3.14 | 2.18 | 2.05 | -- |
| 3.14 JIT | 2.03 | 2.32 | 0.97x |
| 3.14 FT | 2.66 | 2.28 | 0.86x |
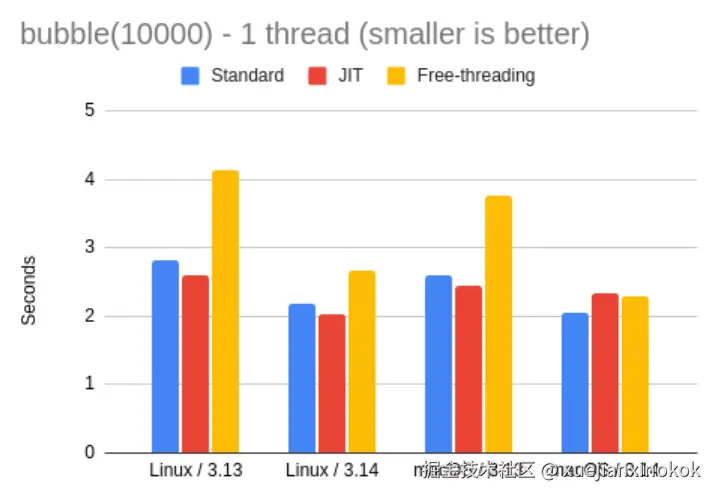
JIT 解释器在这里似乎稍微快一点,但仅限于 Linux 版 Python。在 Mac 上,3.13 版本的速度稍快一些,但 3.14 版本的速度较慢。速度差异也很小,所以总的来说,我觉得 JIT 解释器需要更多时间才能成熟。我使用的代码似乎无法从 JIT 编译中获益太多。
自由线程解释器的运行速度也较慢,但 3.14 中的差异比 3.13 中的差异要小得多,因此这两个基准测试的结果一致。目前看来,对于常规工作负载切换到自由线程解释器似乎不太合理,但当 GIL 确实造成阻碍时,这可能是一个有趣的选择,这种情况只适用于 CPU 需求较大的多线程情况。
Benchmark #3: Fibonacci multi-threaded
今年我决定推出这两个测试程序的多线程版本,主要是为了给自由线程解释器一个大放异彩的机会。
我在多线程斐波那契测试中的做法是启动四个线程,运行相同的第 40 个斐波那契数列的计算。这四个线程彼此独立运行,我使用的两台笔记本电脑都拥有超过四个核心的处理器,因此它们应该能够很好地并行执行此测试。我使用的测量时间是从启动第一个线程到所有四个线程结束的时间。
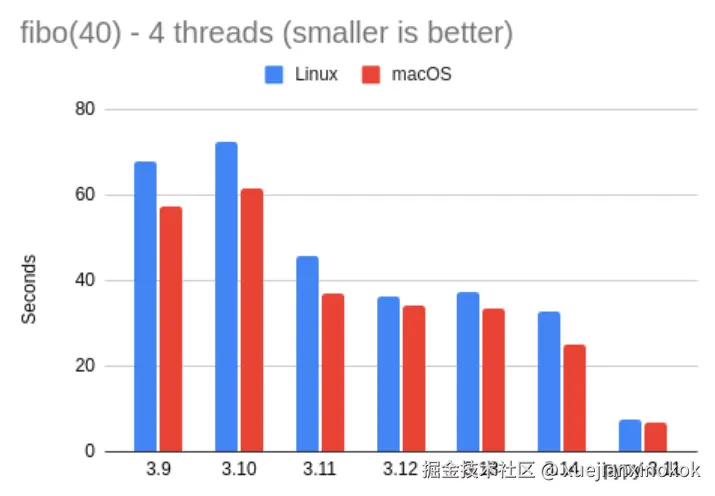
以下是在标准解释器上运行 4 个线程的 fibo.py 的结果:
| fibo 4 threads | Linux | macOS | vs. 3.14 |
|---|---|---|---|
| 3.9 | 67.87 | 57.51 | 0.46x |
| 3.10 | 72.42 | 61.57 | 0.43x |
| 3.11 | 45.83 | 36.98 | 0.70x |
| 3.12 | 36.22 | 34.13 | 0.82x |
| 3.13 | 37.20 | 33.53 | 0.81x |
| 3.14 | 32.60 | 24.96 | -- |
| Pypy 3.11 | 7.49 | 6.84 | 4.02x |
注意,我没有在这里运行 Node 和 Rust 版本的测试,因为这是一个非常具体的测试,仅适用于 Python 的 GIL。
当然,这些结果并不能说明太多问题。我们可以再次看到,我的 Mac 似乎比我的 Linux 机器快一点,但除此之外,速度或多或少是呈线性增长的。例如,单线程斐波那契测试运行了 7 秒,在 Mac 上花了 25 秒,在 Linux 上花了 32 秒,也就是大约 4 倍。这是预料之中的,因为 GIL 不允许 Python 代码并行化。
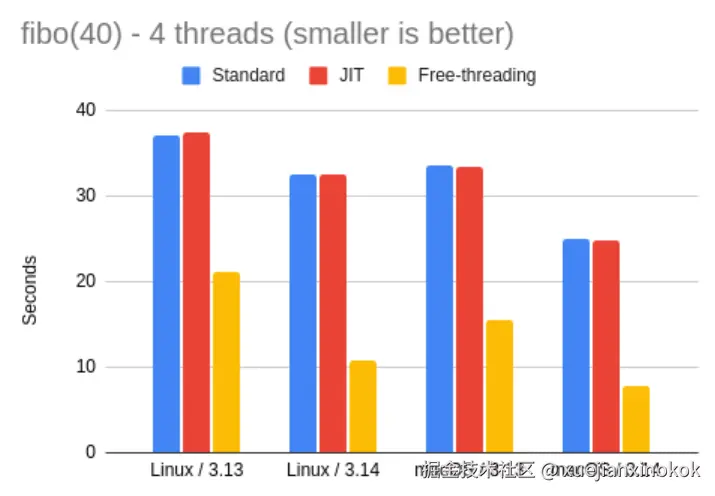
让我们看看 3.13 和 3.14 解释器的详细结果:
| fibo 4 threads | Linux | macOS | vs. 3.14 |
|---|---|---|---|
| 3.13 | 37.20 | 33.53 | 0.81x |
| 3.13 JIT | 37.48 | 33.36 | 0.81x |
| 3.13 FT | 21.14 | 15.47 | 1.57x |
| 3.14 | 32.60 | 24.96 | -- |
| 3.14 JIT | 32.58 | 24.90 | 1.00x |
| 3.14 FT | 10.80 | 7.81 | 3.09x |
太好了!
由于我们预计 JIT 解释器在本次测试中不会有任何显著表现,因此可以忽略这些结果。不过,自由线程解释器向我们展示了移除 GIL 如何有助于运行耗费 CPU 的多个线程。
在 Python 3.13 中,自由线程解释器的运行速度比标准解释器快约 2.2 倍。在 3.14 中,性能提升了约 3.1 倍。这是一个令人兴奋的结果!
Benchmark #4: Bubble sort multi-threaded
为了完成这项基准测试,您可以在下面看到在 4 个线程上运行的冒泡排序测试的结果。在这次测试中,我让每个线程对 10,000 个随机数进行排序。四个线程都收到了相同的随机生成数组的副本。
首先让我们看一下标准解释器:
| bubble 4 threads | Linux | macOS | vs. 3.14 |
|---|---|---|---|
| 3.9 | 16.14 | 12.58 | 0.66x |
| 3.10 | 16.12 | 12.95 | 0.65x |
| 3.11 | 11.43 | 7.89 | 0.97x |
| 3.12 | 11.39 | 9.01 | 0.92x |
| 3.13 | 11.54 | 9.78 | 0.88x |
| 3.14 | 10.55 | 8.27 | -- |
| Pypy 3.11 | 0.54 | 0.59 | 16.65x |
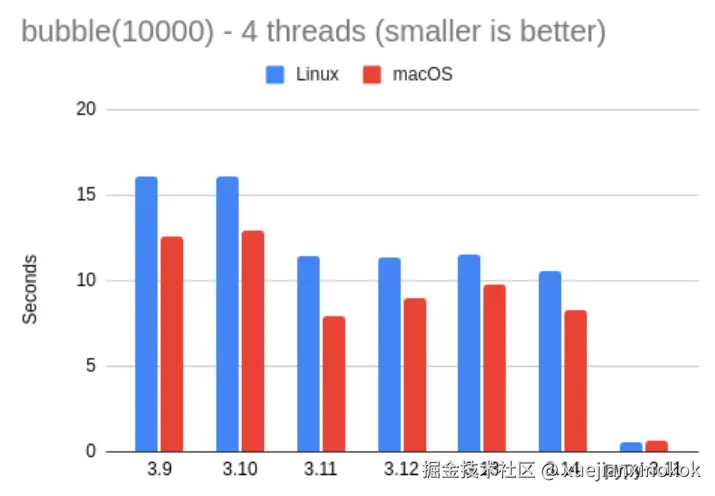
这些结果也没什么特别出乎意料的地方。这项测试的单线程版本在 3.14 版本上执行时间约为 2 秒,在 Linux 上执行时间为 10 秒,在 Mac 上执行时间为 8 秒。有趣的是,在 Linux 机器上,这项测试的耗时比单线程时间长 4 倍多一点。
以下是 3.13 和 3.14 中新解释器的结果:
| bubble 4 threads | Linux | macOS | vs. 3.14 |
|---|---|---|---|
| 3.13 | 11.54 | 9.78 | 0.88x |
| 3.13 JIT | 10.90 | 9.19 | 0.94x |
| 3.13 FT | 9.83 | 5.05 | 1.17x |
| 3.14 | 10.55 | 8.27 | -- |
| 3.14 JIT | 10.03 | 9.26 | 0.98x |
| 3.14 FT | 6.23 | 3.02 | 2.03x |
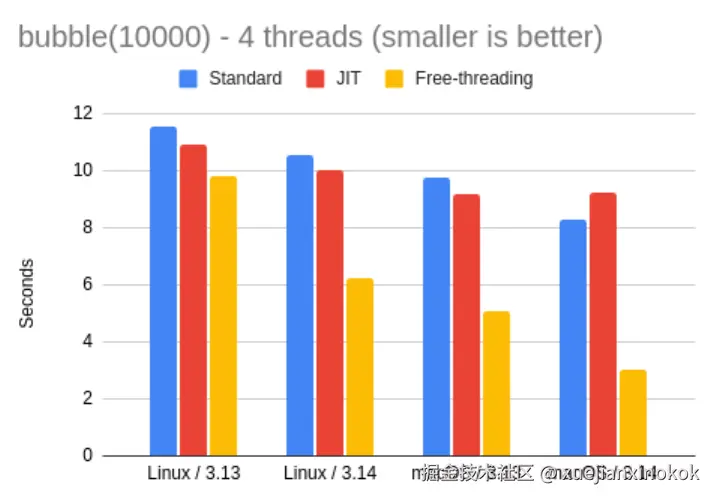
这里我们再次看到了自由线程解释器的良好用例。在本次测试中,Mac 的自由线程性能优于 Linux,但在 3.14 以上版本上,FT 的运行速度比标准 3.14 版本快了大约两倍。如果您有一个 CPU 占用率较高的多线程应用程序,那么切换到自由线程解释器可能是个好主意。
我们在单线程冒泡排序测试中看到的 JIT 解释器在 3.14 Mac 解释器上速度较慢的奇怪结果在这里再次出现,所以我猜这不是偶然的,但无论如何,在我看来,差异并不大,不值得关注。我们只需要等待 JIT 解释器在未来版本中继续发展。
Conclusions 结论
希望您觉得我的基准测试结果有趣。总结一下,以下是我根据这些结果得出的结论:
- CPython 3.14 似乎是所有 CPython 中最快的。
- 如果您还不能升级到 3.14,请考虑使用 3.11 之后的版本,因为它们比 3.10 及更早版本快得多。
- 3.14 JIT 解释器似乎并没有提供任何显著的速度提升,至少对于我的测试脚本来说是这样。
- 对于 CPU 密集型多线程应用程序,3.14 版自由线程解释器比标准解释器更快,因此如果您的应用程序符合此用例,值得一试。我不建议将此解释器用于其他工作负载,因为对于未直接受 GIL 拖慢的代码,它仍然较慢。
- Pypy 速度非常快!