作者介绍:简历上没有一个精通的运维工程师。请点击上方的蓝色《运维小路》关注我,下面的思维导图也是预计更新的内容和当前进度(不定时更新)。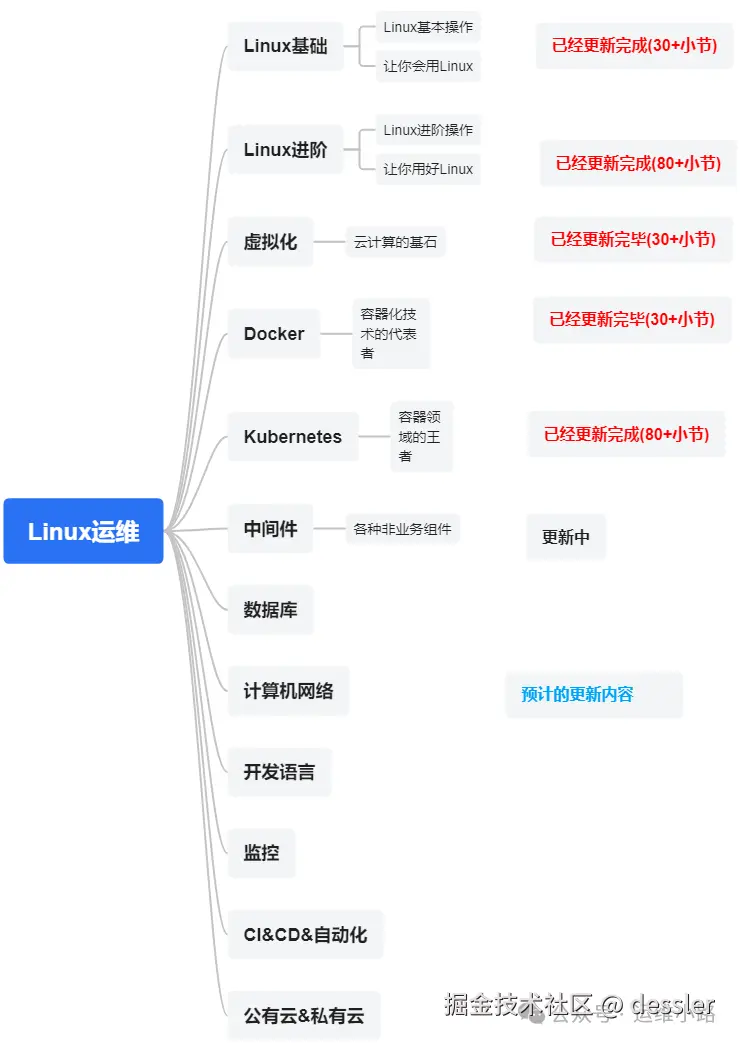
中间件,我给它的定义就是为了实现某系业务功能依赖的软件,包括如下部分:
Web服务器
代理服务器
ZooKeeper
Kafka
RabbitMQ
Hadoop HDFS
Elasticsearch ES (本章节)
我们在上一个章节介绍大数据领域一个很重要软件:HDFS,但是这里存储的文件主要普通文件。在实际环境里面会存在大量的类似日志文件(一条一条的记录),这样的数据我们还需要进行分析,从而获取我们需要的信息。这样的数据适合存储在我们的今天的主角:Elasticsearch,简称ES。
一、 Elasticsearch 的本质:分布式、RESTful 的搜索与分析引擎
分布式: ES 天生为处理大规模数据而设计。它能将数据自动分片 (Shard) 并分布到集群 (Cluster) 中的多个节点 (Node) 上存储和处理。这不仅突破了单机存储限制,还通过并行处理极大提升了性能和吞吐量。节点可以动态加入或离开集群,系统具有高可用性和可扩展性。
近实时 (NRT - Near Real-Time): 数据从被索引到可搜索,通常只需要1秒的延迟。这使得 ES 非常适用于需要快速反馈的场景(如日志监控、应用搜索)。
RESTful API: ES 提供简单、清晰、基于 HTTP 的 RESTful API (JSON 格式) 进行所有操作,包括数据索引、搜索、聚合和管理。这使得任何能发送 HTTP 请求的客户端(如 curl, Kibana Dev Tools, 各种编程语言的客户端库)都能轻松与其交互。
文档导向: ES 存储和操作的基本单位是 文档 (Document) 。文档是结构化的 JSON 对象,代表一个实体(如一篇商品信息、一条日志记录、一个用户资料)。文档被存储在 索引 (Index) 中。
基于 Apache Lucene: ES 的核心搜索与分析能力建立在强大的 Apache Lucene 库之上。Lucene 提供了顶级的全文索引和搜索功能,ES 则在 Lucene 基础上构建了分布式架构、REST API 和高级特性。
二、 核心概念:理解 ES 的骨架
文档 (Document):ES 中的****基本数据单元,类似数据库中的一行记录。
-
以 JSON 格式表示。例如:
{"id": 1, "title": "深入理解Elasticsearch", "author": "张三", "content": "...", "publish_date": "2023-10-27", "price": 59.9} -
每个文档属于一个类型(在 ES 7.x 后,一个索引通常只建议一种类型
_doc)并有一个唯一 ID。
索引 (Index):文档的集合,类似数据库中的表。
-
索引名必须小写。
-
定义了文档的结构(映射 Mapping)和设置(如分片数、副本数)。
-
示例:
books(存储所有书籍信息)、logs-2023-10(存储2023年10月的日志)。
类型 (Type):
(在 ES 7.x 中逐渐弱化,ES 8.x 中已移除)
在 ES 6.x 及之前,一个索引可以包含多种类型(如 books 索引下有 novel 和 tech 类型)。
-
ES 7.x 开始,一个索引只允许包含一种类型,默认为
_doc。 -
ES 8.x 完全移除了类型概念。现在更推荐将不同"类型"的数据放入不同的索引。
分片 (Shard) 与 副本 (Replica)
高可用性:主分片故障时,副本可接管。
提升读取性能:搜索请求可以在所有副本上并行执行。
横向扩展数据量:数据分散存储。
并行化操作:查询/聚合可并行在多个分片上执行,提升性能和吞吐量。
分片: 索引可以被水平拆分成多个分片。每个分片本身就是一个功能完整的独立"索引"。分片允许:
副本: 每个分片可以有零个或多个副本。副本是分片的精确拷贝。副本提供:
创建索引时指定 :主分片数 (number_of_shards) 通常在索引创建时设定且不能修改 (除非 reindex)。副本数 (number_of_replicas) 可以动态调整。
节点 (Node)
主节点 (Master-eligible node): 负责集群管理(创建/删除索引、跟踪节点状态、决定分片分配)。生产环境通常需要配置多个专用主节点保证稳定性。
数据节点 (Data node): 存储分片数据、执行数据相关的操作(CRUD、搜索、聚合)。是资源(CPU、内存、磁盘)消耗大户。
协调节点 (Coordinating node): (默认所有节点都是)接收客户端请求,将请求路由到相关数据节点,汇总结果返回给客户端。大型集群可设置专用协调节点。
摄取节点 (Ingest node): 在索引文档前执行预处理管道(Pipeline)。
一个运行中的 ES 实例。本质上是一个 Java 进程。
集群 (Cluster)
由一个或多个具有相同 cluster.name 的节点组成。集群拥有完整的数据集(所有索引的所有分片)并提供跨节点的联合索引与搜索能力。
运维小路
一个不会开发的运维!一个要学开发的运维!一个学不会开发的运维!欢迎大家骚扰的运维!
关注微信公众号《运维小路》获取更多内容。