1. 如何查找CPU故障  编辑
编辑
在Linux系统中,可以通过以下方法排查CPU故障:
-
查看系统日志 :使用
dmesg命令查看内核日志,检查是否有与CPU相关的硬件错误消息。例如,日志中可能会出现类似于"CPU bug"或者"hardware error"的信息,指示CPU故障。 编辑
编辑bash dmesg | grep -i "cpu" -
监控CPU负载 :使用
top或htop命令监控系统的CPU负载,观察是否有不正常的CPU占用率,可能表示某个进程或硬件故障。bash top htop -
硬件测试 :使用如
stress或stress-ng等工具进行CPU负载测试,观察是否能复现CPU的异常或故障。
bash sudo apt install stress stress --cpu 4 --timeout 60
- 查看CPU温度 :过高的CPU温度也会导致性能问题或硬件故障。可以使用
sensors命令查看当前CPU的温度。
bash sensors 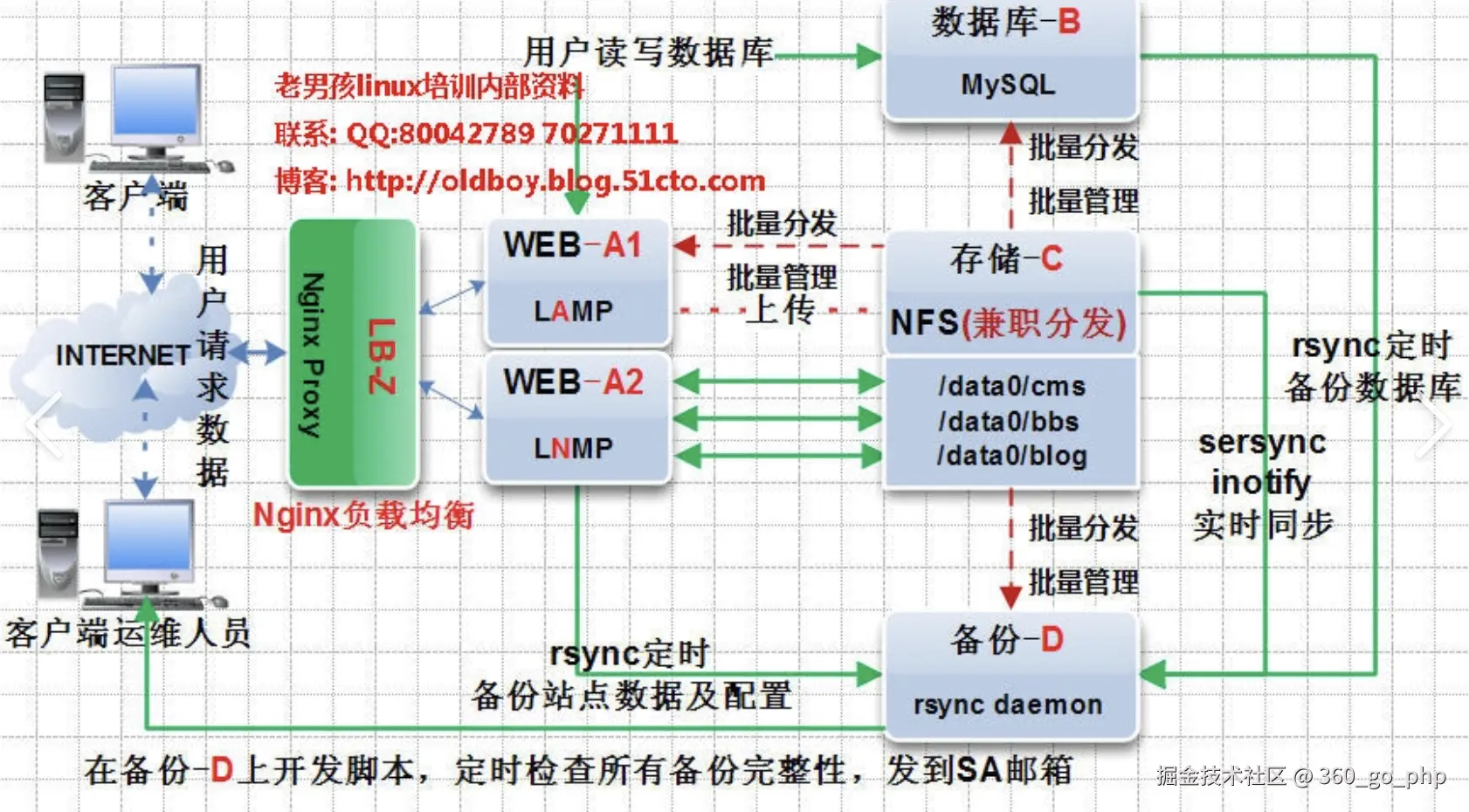 编辑
编辑
- 检查CPU内核和硬件错误 :有些处理器提供了硬件错误报告机制(如Intel的MCE)。可以通过
mcelog或edac工具查看详细的硬件错误日志。
2. 如何检查内存故障
内存故障通常表现为程序崩溃、系统重启或不稳定。以下是几种检测内存故障的方法: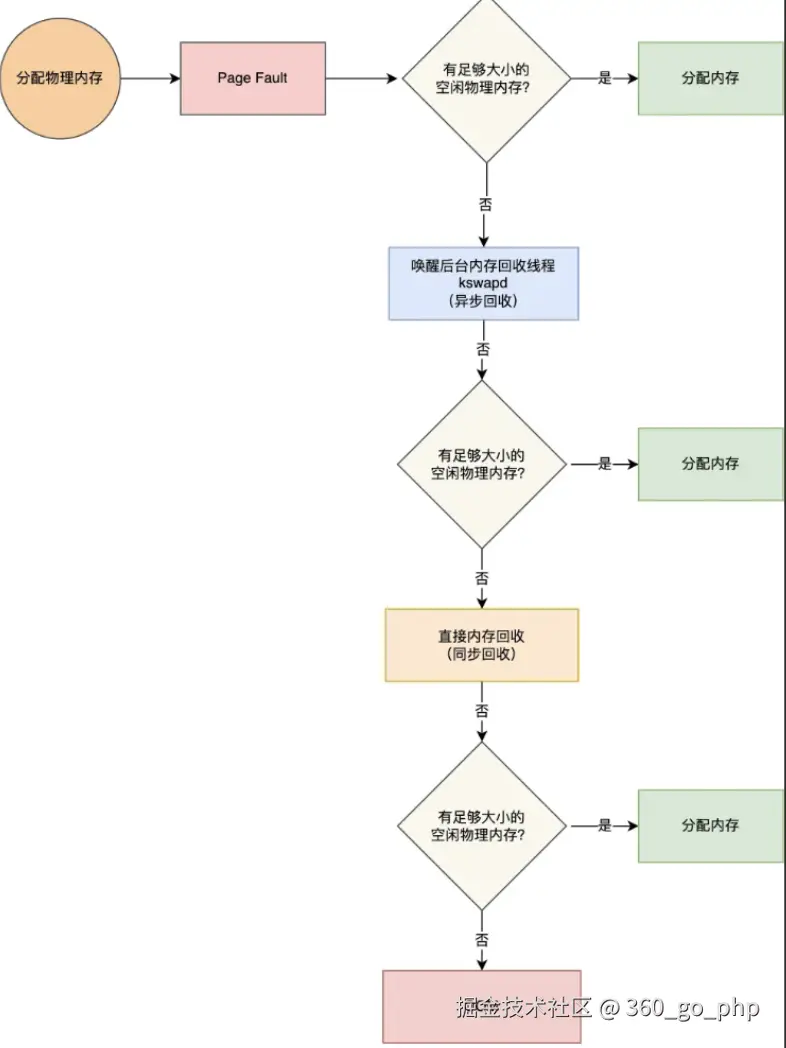 编辑
编辑
- dmesg日志:查看系统日志中的内存错误信息。
bash dmesg | grep -i "memory"
- 使用Memtest86+进行内存检测:Memtest86+是一个广泛使用的内存测试工具,可以检测内存故障。它在启动时会运行,并进行多轮内存测试,帮助发现内存条的问题。
- 可以通过
apt-get安装 Memtest86+ 或者在引导时选择Memtest选项进行测试。 编辑
编辑
bash sudo apt-get install memtest86+
- 检查系统负载 :使用
top或htop命令查看内存的使用情况,观察是否存在内存泄漏或不正常的内存占用。
bash top htop free -h
3. Linux进程和线程的区别
-
进程:进程是操作系统资源分配的基本单位,是程序的一个执行实例。每个进程拥有自己独立的地址空间、代码、数据和其他资源。
-
线程:线程是进程中的一个执行单元,同一个进程的多个线程共享进程的资源(如内存、文件描述符等)。线程间的切换比进程间切换开销小,因此线程通常用于提高程序的并发性能。
进程的特点:
- 拥有独立的地址空间。
- 系统资源独立,进程之间不会共享内存,除非使用IPC(进程间通信)机制。
- 创建和销毁开销较大。
线程的特点:
- 同一进程中的多个线程共享资源。
- 线程间的切换比进程切换更高效。
- 多线程编程可以提高程序的并发性,适用于IO密集型或计算密集型任务。
4. Linux如何实现进程间通信(IPC)
Linux提供了多种IPC机制,让不同的进程之间可以共享数据或同步操作。常见的IPC机制有:
- 管道(Pipe):允许一个进程将数据写入管道,另一个进程从管道中读取数据。管道是单向的,数据流动方向从写入端到读取端。
bash $ ls | grep "test"
- 消息队列(Message Queue):用于发送和接收消息,支持异步传输。消息队列可以跨进程发送数据,非常适合大规模通信。
bash ipcs -q # 查看系统中的消息队列
-
共享内存(Shared Memory):多个进程可以将数据存储在同一块内存区域中。共享内存是最快的IPC形式,但需要额外的同步机制来避免数据冲突。
-
信号量(Semaphore):用于同步进程之间的操作,避免多个进程同时访问共享资源。信号量通常用于保证互斥。
-
套接字(Socket):不仅用于同一台机器的进程间通信,也适用于网络中不同主机之间的通信。Socket可用于基于TCP/IP协议的通信。
-
文件锁(File Locking) :使用
flock等文件锁机制,可以控制对文件的并发访问。它可以用于进程间的同步。
5. Linux中的线程模型
在Linux中,线程是由进程创建的,每个线程都由pthread(POSIX线程)库管理。线程可以通过pthread_create函数创建,通过pthread_join进行等待和同步。每个线程共享同一个进程的资源,包括内存、文件描述符等。
Linux使用了1:1线程模型,即每个用户级线程对应一个内核级线程。这意味着Linux内核直接调度每个线程,并在多个核心上进行并行执行。
- 线程的创建 :通过
pthread_create函数创建新线程。 - 线程同步 :可以使用
mutex(互斥锁)、cond_variable(条件变量)、semaphore(信号量)等进行线程同步。 - 线程调度:Linux使用调度策略(如CFS - Completely Fair Scheduler)来调度线程。
6. Linux下的文件系统
Linux支持多种文件系统,常见的有:
-
ext4 :目前Linux中使用最广泛的文件系统,具有较好的性能、稳定性和兼容性。它是
ext3的继任者,支持更大的文件系统和更好的数据恢复功能。 -
XFS:主要用于高性能存储的场景,支持大文件和大容量存储,尤其适合数据库等高IO负载场景。
-
Btrfs:支持复制、压缩、快照等高级特性,适合用于大规模的存储管理,但相对较新,稳定性不如ext4。
-
F2FS:为Flash存储设备设计的文件系统,针对NAND闪存优化,适合SSD和eMMC存储设备。
-
NTFS :主要用于Windows系统,但Linux通过
ntfs-3g等工具支持读写NTFS格式的分区。 -
FAT32/exFAT:常用于USB闪存盘、SD卡等存储介质,广泛支持,但在处理大文件时有一些限制(如FAT32最大文件大小为4GB)。
7. Linux内存管理
Linux内存管理通过虚拟内存技术来管理系统内存。关键概念包括:
-
虚拟内存:每个进程都有一个独立的虚拟地址空间。通过内存映射(Memory Mapping)技术,Linux将虚拟地址转换为物理地址,提供了内存隔离和保护。
-
页面:内存被分割为固定大小的块,称为页面。通常页面大小为4KB,但也可以是其他大小(例如2MB或1GB)。
-
页面交换(Swap):当系统内存不足时,Linux会将不常用的页面交换到磁盘上的交换空间(Swap)中,以释放内存给活跃的进程。
-
内存池:内核使用内存池来管理内存分配,池中有不同大小的块来满足不同进程的需求。
-
OOM Killer:当系统内存不足时,Linux会启动OOM Killer(Out of Memory Killer)来终止一些进程,优先杀死内存占用较高的进程,以避免整个系统崩溃。
8. Linux文件权限与管理
Linux系统通过文件权限控制对文件的访问。文件权限可以通过ls -l命令查看,每个文件都有以下权限设置:
- 读(r):允许读取文件内容。
- 写(w):允许修改文件内容。
- 执行(x):允许执行文件(如果是脚本或程序)。
文件权限可以使用chmod命令进行修改,chown命令修改文件的所有者,chgrp命令修改文件的所属组。
1. RocketMQ的组件
RocketMQ 是一款分布式消息中间件,主要用于处理大规模消息的可靠传输。RocketMQ 主要包括以下几个核心组件:
-
Broker :Broker 是 RocketMQ 的核心组件,负责消息的存储和投递。一个 Broker 集群由多个 Broker 节点组成。每个 Broker 节点负责处理特定主题的消息。
-
NameServer:NameServer 是 RocketMQ 中的路由组件,类似于 DNS,它负责存储并维护 Broker 的路由信息。当生产者或消费者需要获取消息的路由信息时,会向 NameServer 请求。一个 NameServer 集群通常包含多个 NameServer 节点,保证高可用性。
-
Producer:Producer 是消息的生产者,它负责创建消息并将消息发送到指定的 Topic 中。Producer 会根据 NameServer 提供的路由信息找到正确的 Broker,将消息发送给 Broker。
-
Consumer:Consumer 是消息的消费者,负责从指定的 Topic 中消费消息。Consumer 可以是广播模式(一个消费者接收所有消息)或集群模式(多个消费者共同消费消息)。
-
Message:消息是 RocketMQ 中传输的数据单元,通常包含主题(Topic)、消息体、消息标签等信息。
-
Client:RocketMQ 提供了多种客户端 API,支持 Java、C++、Python 等语言,通过这些客户端 API,Producer 和 Consumer 可以与 Broker 和 NameServer 进行交互。
-
Admin:Admin 是 RocketMQ 提供的管理工具,用于管理 Topic、Producer、Consumer 等资源,常用于集群的监控和管理。
-
RocketMQ Console:RocketMQ Console 是一个 Web 控制台,用于管理 RocketMQ 的集群、查看消息队列的状态、监控消息的消费情况等。
2. Mybatis的缓存
MyBatis 提供了一级缓存和二级缓存,用于提高数据库查询的性能。
-
一级缓存 :
-
一级缓存是 MyBatis 默认启用的缓存机制,它的作用范围仅限于当前的
SqlSession。每次在同一个SqlSession中执行相同的查询时,MyBatis 会直接从缓存中获取数据,而不是重新查询数据库。 -
一级缓存是本地缓存 ,在
SqlSession会话级别有效。如果SqlSession被关闭或者提交,则缓存会被清空。 -
一级缓存是启用的默认行为,无需额外配置。
-
-
二级缓存 :
-
二级缓存是跨
SqlSession的缓存,可以在不同的会话之间共享缓存数据。它可以大大减少数据库的查询负担,提高性能。 -
二级缓存通常会绑定到 Mapper 上,因此每个 Mapper 都有独立的缓存。
-
二级缓存需要手动启用,并且需要配置缓存策略(例如启用缓存、选择缓存实现等)。
-
缓存的实现可以使用内存中的
HashMap或者通过第三方缓存框架(如 Ehcache、Redis)实现。
-
如何启用二级缓存:
- 在
mybatis-config.xml配置文件中启用二级缓存:
xml <configuration> <settings> <setting name="cacheEnabled" value="true"/> </settings> </configuration> - 在 Mapper 接口中启用二级缓存:
xml <mapper namespace="com.example.mapper"> <cache/> <!-- SQL语句 --> </mapper>
注意事项:
- 二级缓存默认是不开启的,必须手动配置。
- 二级缓存的清理策略通常依赖于 MyBatis 提供的缓存清理机制(如
flushCache等)。
3. JMeter压测时为什么会丢包
在使用 JMeter 进行压测时,丢包是一个常见问题,可能由以下几个原因导致:
-
网络带宽不足 :
- JMeter 发送的请求数量过多,超过了网络带宽的承载能力,导致某些请求未能成功发送或接收响应。解决方法包括增加带宽或者分布式压测,使用多个 JMeter 节点。
-
服务器承载能力不足 :
- 被压测的服务器无法承载大量的并发请求,导致部分请求丢失或超时。可以检查服务器性能瓶颈,如 CPU、内存、磁盘IO等资源,进行优化。
-
JMeter配置不当 :
-
如果 JMeter 中的线程数设置过高,可能会导致机器资源(如内存、CPU)不足,进而丢失请求。建议逐步增加并发线程数,观察资源占用情况。
-
适当配置 JMeter 的采样器、定时器等,以避免请求过于集中。
-
-
JMeter客户端性能瓶颈 :
- 如果 JMeter 运行的机器性能不足(CPU、内存等),可能导致请求丢失。可以考虑使用分布式压测,分散负载到多个机器上。
-
HTTP连接池设置问题 :
-
默认情况下,JMeter 的 HTTP 请求可能会使用有限的连接池,尤其是在高并发场景下,连接池中的连接可能会被用完,导致部分请求无法正常发送。
-
可以通过增加连接池的大小或设置
HTTP Request Defaults中的最大连接数来优化。
-
-
代理或防火墙问题 :
- 在进行大规模压测时,代理服务器或防火墙可能会限制请求的数量,或者由于流量过大,阻止了某些请求的到达。可以检查是否有代理、负载均衡或防火墙的配置限制。
-
超时设置问题 :
- 在 JMeter 中设置了不合理的请求超时时间,可能导致超时错误和丢包。调整合理的超时设置以确保请求能成功完成。
-
JMeter服务器端响应慢 :
- 被压测的服务器端响应时间较长,当响应时间超出客户端的超时设置时,JMeter 会认为请求丢失并记录为失败。可以增加 JMeter 中的超时设置,或优化被测系统的性能。
这些是常见的Linux相关面试问题及其解答,涵盖了Linux的核心概念和一些高级主题。