Model I/O-介绍
Model I/O模块是与语言模型(LLMs)进行交互的核心组件,再整个框架中有着很重要的地位。
所谓的Model I/O,包括输入提示(Format)、调用模型(Predict)、输出解析(Parse)。分别对应着Prompt Template,Model和Output Parser。
简单来说,就是输入,模型处理,输出这三个步骤
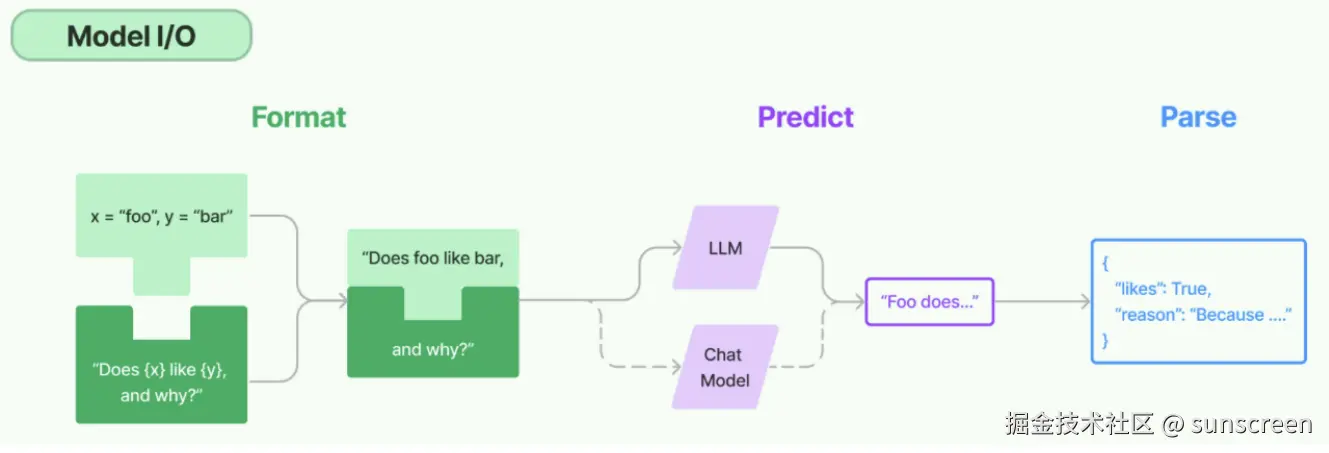
针对每个环节,LangChain都提供了模板和工具,可以快捷的调用各种语言模型的接口。
Model I/O-调用模型
LangChain作为一个"工具",不提供任何 LLMs,而是依赖于第三方集成各种大模型。比如,将OpenAI、Anthropic、Hugging Face 、LlaMA、阿里Qwen、ChatGLM等平台的模型无缝接入到你的应用。
关于对话模型的Message(消息)
聊天模型,除了将字符串作为输入外,还可以使用聊天消息作为输入,并返回聊天消息作为输出。
LangChain有一些内置的消息类型:
SystemMessage:设定AI行为规则或背景信息。比如设定AI的初始状态、行为模式或对话的总体目标。比如"作为一个代码专家",或者"返回JSON格式"。通常作为输入消息序列中的第一个传递HumanMessage:表示来自用户输入。比如"实现一个快速排序方法"AIMessage:存储AI恢复的内容。可以是文本,也可以是调用工具的请求ChatMessage:可以自定义角色的通用消息类型FunctionMessage/ToolMessage:函数调用/工具消息,用于函数调用结果的消息类型
举例1:
python
from langchain_core.message import HumanMessage,SystemMessage
message = [
SystemMessage(content="你是一位AI助手"),
HumanMessage(content="你好,请介绍一下你自己")
]
print(message)举例2:
python
from langchain_core.messages import HumanMessage, AIMessage, SystemMessage
messages = [
SystemMessage(content=["你是一个数学家,只会回答数学问题","每次你都能给出详细的方案"]),
HumanMessage(content="1 + 2 * 3 = ?"),
AIMessage(content="1 + 2 * 3 的结果是7"),
]
print(messages)举例3:
python
#1.导入相关包
from langchain_core.messages import SystemMessage, HumanMessage, AIMessage
# 2.直接创建不同类型消息
systemMessage = SystemMessage(
content="你是一个AI开发工程师",
additional_kwargs={"tool": "invoke_tool()"}
)
humanMessage = HumanMessage(
content="你能开发哪些AI应用?"
)
aiMessage = AIMessage(
content="我能开发很多AI应用, 比如聊天机器人, 图像识别, 自然语言处理等"
)
# 3.打印消息列表
messages = [systemMessage,humanMessage,aiMessage]
print(messages)举例4:
python
from langchain_core.messages import (
AIMessage,
HumanMessage,
SystemMessage,
ChatMessage
)
# 创建不同类型的消息
system_message = SystemMessage(content="你是一个专业的数据科学家")
human_message = HumanMessage(content="解释一下随机森林算法")
ai_message = AIMessage(content="随机森林是一种集成学习方法...")
custom_message = ChatMessage(role="analyst", content="补充一点关于超参数调优的信息")
print(system_message.content)
print(human_message.content)
print(ai_message.content)
print(custom_message.content)举例5:结合大模型使用
python
import os
from langchain_core.messages import SystemMessage,HumanMessage
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
chat_model = ChatOpenAI(
model="gpt-4o-mini",
)
# 组成消息列表
messages = [
SystemMessage(content="你是一个擅长人工智能相关学科的专家"),
HumanMessage(content="请解释一下什么是机器学习?")
]
response = chat_model.invoke(messages)
print(response.content)
print(type(response)) #<class 'langchain_core.messages.ai.AIMessage'>关于多轮对话与上下文记忆
前提:获取大模型
python
import os
from langchain_core.messages import SystemMessage,HumanMessage
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
chat_model = ChatOpenAI(
model="gpt-4o-mini",
)测试1:
python
from langchain_core.messages import SystemMessage, HumanMessage
sys_message = SystemMessage(
content="我是一个人工智能的助手,我的名字叫小智",
)
human_message = HumanMessage(content="猫王是一只猫吗?")
messages = [sys_message, human_message]
#调用大模型,传入messages
response = chat_model.invoke(messages)
print(response.content)
response1 = chat_model.invoke("你叫什么名字?")
print(response1.content)关于模型调用的方法
为了尽可能简化自定义链的创建,我们实现了一个"Runnable"协议。许多LangChain组件实现了Runnable协议,包括聊天模型、提示词模板、输出解释器、检索器、代理(智能体)等。
Runnable定义的公共调用方法如下:
invoke:处理单条输入,等待LLM完全推理完成后再调用结果stream:流式相应,逐字输出LLM的相应结果batch:处理批量输入
这些也有相应的异步方法,应该与 asyncio 的await语法一起使用以实现并发:
astream:异步流式处理ainvoke:异步处理单条输入abatch:异步处理批量输入astream_log:异步流式返回中间步骤,以及最终响应
流式输出与非流式输出
以下是两个场景:
- 非流式输出:这是LangChain与LLM交互时的默认行为 ,是最简单、最稳定的语言模型调用方式。当用户发出请求后,系统再后台等待模型
生成完整响应,然后一次性将全部结果返回。
-
- 举例:用户提问写一首诗,系统在静默数秒后
突然弹出了完整的诗歌。 - 在大多数问答、摘要、信息抽取类任务中,非流式输出提供了结构清晰、逻辑完整的结果,适合快速集成和部署。
- 举例:用户提问写一首诗,系统在静默数秒后
- 流式输出:一种更具交互感的模型输出方式,用户不需要再等待完整答案,而是能看到模型
逐个token地实时返内容。
-
- 举例:用户提问写一首诗,当问题刚刚发送,系统就开始
一字一句(逐个token)进行恢复,感觉是一边思考一边输出 - 更像是"实时对话",更贴近人类交互的习惯,更有吸引力
- 适合构建强调"实时反馈"的应用,如聊天机器人,写作助手等。
- LangChain中通过设置
stream=True并配合回调机制来启用流式输出
- 举例:用户提问写一首诗,当问题刚刚发送,系统就开始
非流式输出:
python
import os
import dotenv
from langchain_core.messages import HumanMessage
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY1")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
#初始化大模型
chat_model = ChatOpenAI(model="gpt-4o-mini")
# 创建消息
messages = [HumanMessage(content="你好,请介绍一下自己")]
# 非流式调用LLM获取响应
response = chat_model.invoke(messages)
# 打印响应内容
print(response)结果是全部输出的
流式输出:
python
import os
import dotenv
from langchain_core.messages import HumanMessage
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
# 初始化大模型
chat_model = ChatOpenAI(model="gpt-4o-mini",
streaming=True # 启用流式输出
)
# 创建消息
messages = [HumanMessage(content="你好,请介绍一下自己")]
# 流式调用LLM获取响应
print("开始流式输出:")
for chunk in chat_model.stream(messages):
# 逐个打印内容块
print(chunk.content, end="", flush=True) # 刷新缓冲区 (无换行符,缓冲区未刷新,内容可能不会
立即显示)
print("\n流式输出结束")文字逐个输出
批量调用
python
import os
import dotenv
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
# 初始化大模型
chat_model = ChatOpenAI(model="gpt-4o-mini")
messages1 = [SystemMessage(content="你是一位乐于助人的智能小助手"),
HumanMessage(content="请帮我介绍一下什么是机器学习"), ]
messages2 = [SystemMessage(content="你是一位乐于助人的智能小助手"),
HumanMessage(content="请帮我介绍一下什么是AIGC"), ]
messages3 = [SystemMessage(content="你是一位乐于助人的智能小助手"),
HumanMessage(content="请帮我介绍一下什么是大模型技术"), ]
messages = [messages1, messages2, messages3]
# 调用batch
response = chat_model.batch(messages)
print(response)Model I/O-Prompt Template
Prompt Template,通过模板管理大模型的输入。
介绍与分类
Prompt Template是LangChain中的一个概念,接收用户输入,返回一个传递给LLM的信息(即提示词prompt)。
在应用开发中,固定的提示词限制了模型的灵活性和适用范围。所以,prompt template是一个模板化的字符串,你可以将变量插入到模板中,从而创建出不同的提示。调用时:
- 以
字典作为输入,其中每个键代表要填充的提示模板中的变量。 - 输出一个
PormptValue。这个PromptValue可以传递给LLM或ChatModel,并且还可以转换为字符串或消息列表
有几种不同类型的提示词模板:
PromptTemplate:LLM提示模板,用于生成字符串提示。它使用Python的字符串来模板提示ChatPromptTemplate:聊天提示模板,用于组合各种角色的消息模板,传入聊天模型XxxMessagePromptTemplate:消息模板词模板,包括SystemMessagePromptTemplate、HumanMessagePromptTemplate、AIMessagePromptTemplate、ChatMessagePromptTemplate等FewShotPromptTemplate:样本提示词模板,通过实例来教模型如何回答PipelinePrompt:管道提示词模板,用于把几个提示词组合在一起使用自定义模板:允许基类其他模板类来指定自己的提示词模板
模板导入
python
from langchain.prompts.prompt import PromptTemplate
from langchain.prompts import ChatPromptTemplate
from langchain.prompts import FewShotPromptTemplate
from langchain.prompts.pipeline import PipelinePromptTemplate
from langchain.prompts import (
ChatMessagePromptTemplate,
SystemMessagePromptTemplate,
AIMessagePromptTemplate,
HumanMessagePromptTemplate,
)str.format()
Python中的str.format()方法是一种字符串的格式化的手段,允许在字符串中插入变量。使用这种方法,可以创建包含占位符的字符串模板,占位符由花括号 {} 标识。
- 调用format()方法时,可以传入一个或者多个参数,这些参数将被顺序替换进占位符中。
- str.format()提供了灵活的方式来构造字符串,支持多种格式化的选项。
在LangChain的默认设置下,PromptTemplate使用Python的str.format()方法进行模板化。这样在模型接入输入前,可以根据需要对数据进行预处理和结构化。
带有位置参数的用法
python
# 使用位置参数
info = "Name:{0},Age{1}".format("Jone",21)
pirnt(info)
#结果:Name:Jone,Age:21带有关键字参数的用法
python
# 使用关键字参数
info = "Name:{name},Age:{age}".format(name="Tom",age=23)
print(info)
#结果:Name:Tom,Age:25使用字典包的方式
python
# 使用字典解包
person = {"name":"David","age":30}
info = "Name:{name},Age:{age}".format(**preson)
print(info)
#结果:Name: David, Age: 30使用-PromptTemplate
说明
PromptTemplate类,用于快速构建包含变量的提示词模板,并通过传入不同的参数值生成自定义的提示词
主要参数介绍
template:定义提示词模板的字符串,其中包含文本 和变量占位符(如{name})input_variables:列表,指定了模板中使用的变量名称,在调用模板时被替换partial_variables:字典,用于定义模板中一些固定的变量名。这些值不需要再每次调用时被替换
函数介绍
format():给input_variables变量赋值,并返回提示词。利用format()进行格式化时就一定要赋值,否则会报错。当在template中国未设置input_variables,则会自动忽略
两种实例化方式
方式1:使用构造方法
例1:
python
from langchain_core.prompts import PromptTemplate
# 定义模板:描述主题的应用
template=PromptTemplate(
template="请简要描述{topic}的应用。",
input_variables=["topic"],
)
print(template)
# 使用模板生成提示词
prompt_1 = template.format(topic = "机器学习")
prompt_2 = template.format(topic = "自然语言处理")
print("提示词1:", prompt_1)
print("提示词2:", prompt_2)例2:定义多变量模板
python
from langchain_core.prompts import PromptTemplate
# 定义多变量模板
template=PromptTemplate(
template="请评价{product}的优缺点,包括{aspect1}和{aspect2}。",
input_variables=["product", "aspect1", "aspect2"],
)
# 使用模板生成提示词
prompt_1 = template.format(
product = "智能手机",
aspect1 = "电池续航",
aspect2 = "便携性",
)
prompt_2 = template.format(
product = "笔记本电脑",
aspect1 = "电池续航",
aspect2 = "处理速度",
)
print("提示词1:", prompt_1)
print("提示词2:", prompt_2)例1:
python
from langchain.prompts import PromptTemplate
prompt_template = PromptTemplate.from_template(
"请给我一个关于{topic}的{type}解释。"
)
# 传入模板中变量的名字
prompt = prompt_template.format(
type = "粗略",
topic = "量子力学"
)
print(prompt)举例2:模板支持任意数量的变量,包括不含变量:
python
from langchain_core.prompts import PromptTemplate
# 定义提示词模板
text = """
讲一个笑话
"""
prompt_template = PromptTemplate.from_template(text)
prompt = prompt_template.format()
print(prompt)两种新的结构形式
形式1:部分提示词模板
在生成prompt前就已经提前初始化部分的提示词,实际进一步导入模板的时候只导入除已初始化的变量即可。
举例1:
方式1:实例化过程中使用partial_variables变量
python
from langchain.prompts import PromptTemplate
template = PromptTemplate(
template = "{foo}{bar}",
input_variables=["foo", "bar"],
partial_variables={"foo":"hello"}
)
prompt = template.format(bar="world")
print(prompt)方式2:使用PromptTemplate.partial()方法创建部分提示模板
python
from langchain.prompts import PromptTemplate
template = PromptTemplate(
template = "{foo}{bar}",
input_variables=["foo", "bar"],
)
partial_template = template.partial(foo="hello")
prompt = partial_template.format(bar="world")
print(prompt)形式2:组合提示词
举例:
python
from langchain_core.prompts import PromptTemplate
template = (
PromptTemplate.from_template("讲一个关于{topic}笑话")
+ ",很搞笑的"
+ "\n\n用{language}语言"
)
prompt = template.format(topic = "运动", language = "中文")
print(prompt)format()与invoke()
只要对象是RunnableSerializable类型的接口,都可以使用invoke(),替换前面使用format()的调用方法。
format(),返回值为字符串类型
invoke(),返回值为PromptValue类型,接着调用to_string()返回字符串
结合LLM调用
提供大模型:(非对话模型)
python
import os
import dotenv
from langchain_openai import OpenAI
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
llm = OpenAI(model="gpt-4o-mini")
prompt_template = PromptTemplate.from_template(
template="请评价{product}的优缺点,包括{aspect1}和{aspect2}。"
)
prompt = prompt_template.format(
product = "电脑",
aspect1 = "性能",
aspect2 = "电池续航",
)
print(llm.invoke(prompt))提供大模型:(对话大模型)
python
import os
import dotenv
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
llm = ChatOpenAI(model="gpt-4o-mini")
prompt_template = PromptTemplate.from_template(
template="请评价{product}的优缺点,包括{aspect1}和{aspect2}。"
)
prompt = prompt_template.format(
product = "电脑",
aspect1 = "性能",
aspect2 = "电池续航",
)
print(llm.invoke(prompt))使用-ChatPromptTemplate
说明
ChatPromptTemplate是创建聊天信息列表的提示词模板。它比普通PromptTemplate更适合处理多角色、多轮次的对话场景。
特点
- 支持
System/Human/AI等不同角色的消息模板 - 支持历史维护
参数类型 :列表参数格式tuple类型(role:str ,content:str 组合最常用)
元组的格式为:(role: str | type, content: str | list[dict] | list[object])
其中role是:字符串(如"system"、"human"、"ai")
两种实例化方式
方式1:使用构造方法
举例:
python
from langchain_core.prompts import ChatPromptTemplate
#这里参数类型使用的是tuple构成的list
prompt_template = ChatPromptTemplate([
#字符串role+字符串content
("system","你是一个AI开发工程师,你的名字是{name}."),
("human","你能开发哪些AI应用."),
("ai","我能开发很多AI应用, 比如聊天机器人, 图像识别, 自然语言处理等."),
("human","{user_input}")
])
#调用invoke()方法,返回字符串
prompt = prompt_template.invoke(
input = {
"name" : "小智AI",
"user_input" : "你能帮我做什么?"
}
)
print(type(prompt))
print(prompt)方式2:调用from_message()
举例:
python
from langchain_core.prompts import ChatPromptTemplate
#定义聊天提示词模板
prompt_template = ChatPromptTemplate.from_messages([
("system","你是一个AI机器人,你的名字叫{name}"),
("human","你好,最近怎么样?"),
("ai","我很好,你呢?"),
("human","{user_input}")
])
#格式化聊天提示模板中的变量
messages = prompt_template.invoke(
input = {
"name":"小明",
"user_input":"你叫什么名字?"
}
)
#打印格式化后的聊天提示词模板内容
print(messages)模板调用的几种方式
对比:invoke()、format()、format_messages()、format_prompt()
invoke() :
同方式一中的示例
python
from langchain_core.prompts import ChatPromptTemplate
#这里参数类型使用的是tuple构成的list
prompt_template = ChatPromptTemplate([
#字符串role+字符串content
("system","你是一个AI开发工程师,你的名字是{name}."),
("human","你能开发哪些AI应用."),
("ai","我能开发很多AI应用, 比如聊天机器人, 图像识别, 自然语言处理等."),
("human","{user_input}")
])
#调用invoke()方法,返回字符串
prompt = prompt_template.invoke(
input = {
"name" : "小智AI",
"user_input" : "你能帮我做什么?"
}
)
print(type(prompt))
print(prompt)<class 'langchain_core.prompt_values.ChatPromptValue'>
format() :
python
from langchain_core.prompts import ChatPromptTemplate
#这里参数类型使用的是tuple构成的list
prompt_template = ChatPromptTemplate([
#字符串role+字符串content
("system","你是一个AI开发工程师,你的名字是{name}."),
("human","你能开发哪些AI应用."),
("ai","我能开发很多AI应用, 比如聊天机器人, 图像识别, 自然语言处理等."),
("human","{user_input}")
])
#调用format()方法,返回字符串
prompt = prompt_template.format(
name="小智AI",
user_input="你能帮我做什么?"
)
print(type(prompt))
print(prompt)<class 'str'>
System: 你是一个AI开发工程师,你的名字是小智AI.
Human: 你能开发哪些AI应用.
AI: 我能开发很多AI应用, 比如聊天机器人, 图像识别, 自然语言处理等.
Human: 你能帮我做什么?
format_messages():
python
from langchain_core.prompts import ChatPromptTemplate
prompt_template = ChatPromptTemplate([
#字符串role+字符串content
("system","你是一个AI开发工程师,你的名字是{name}."),
("human","你能开发哪些AI应用."),
("ai","我能开发很多AI应用, 比如聊天机器人, 图像识别, 自然语言处理等."),
("human","{user_input}")
])
#调用format_messages()方法,返回字符串
prompt = prompt_template.format_messages(
name="小智AI",
user_input="你能帮我做什么?"
)
print(type(prompt))
print(prompt)format_prompt() :
python
from langchain_core.prompts import ChatPromptTemplate
#这里参数类型使用的是tuple构成的list
prompt_template = ChatPromptTemplate([
#字符串role+字符串content
("system","你是一个AI开发工程师,你的名字是{name}."),
("human","你能开发哪些AI应用."),
("ai","我能开发很多AI应用, 比如聊天机器人, 图像识别, 自然语言处理等."),
("human","{user_input}")
])
#调用format_prompt()方法,返回字符串
prompt = prompt_template.format_prompt(
name="小智AI",
user_input="你能帮我做什么?"
)
print(type(prompt))
print(prompt)结论 :invoke()、format()、format_messages()、format_prompt()返回的消息类型分别是ChatPromptValue、str、list、ChatPromptValue。给占位符赋值,针对于ChatPromptTemplate,推荐使用format_message()方法,返回消息列表
更丰富的实例化参数类型
前面ChatPromptTemplate的两种创建方式,不管使用构造方法还是使用from_message(),参数都是列表类型。列表中的元素可以是多种类型,如字符串、字典、字符串构成的元组、消息类型、提示词模板类型、消息提示词模板类型等。
类型1:str类型
python
chat_template = ChatPromptTemplate.from_messages(
"hello","{name}"
)
messages = chat_template.format_messages(name="小智AI")类型2:dict类型
python
chat_template = ChatPromptTemplate.form_message([
{"role":"system","content":"你是一个{role}."},
{"role":"human","content":["复杂内容",{"type":"text"}]}
])
messages = chat_template.format_messages(role="老师")类型3:Message类型
python
chat_template = ChatPromptTemplate.form_message([
SystemMessage(content="我是一个AI智能助手"),
HumanMessage(content="问题:人工智能的英语是什么?")
])
messages = chat_template.format_messages()类型4:BaesChatPromptTemplate
使用了BaseChatPromptTemplate,可以理解为ChatPromptTemplate里嵌套了ChatPromptTemplate。
例1:不带参数
python
chat_prompt1=ChatPromptTemplate.from_messages(
[("system","我是一个人工智能助手")]
)
chat_prompt2=ChatPromptTemplate.from_messages(
[("human","很高兴认识你")]
)
chat_prompt=ChatPromptTemplate.from_messages(
[chat_prompt1,chat_prompt2]
)
chat_prompt.format_messages()例2:带参数
python
chat_prompt1=ChatPromptTemplate.from_messages(
[("system","我是一个人工智能助手,我叫{name}")]
)
chat_prompt2=ChatPromptTemplate.from_messages(
[("human","很高兴认识你,我的问题是{question}")]
)
chat_prompt=ChatPromptTemplate.from_messages(
[chat_prompt1,chat_prompt2]
)
chat_prompt.format_messages(
name="小智",
question="你叫什么名字"
)类型5:BaseMessagePromptTemplate类型
LangChain提供不同类型的MessagePromptTemplate。最常用的是SystemMessagePromptTemplate、HumanMessagePromptTemplate和AIMessagePromptTemplate,分别创建系统消息、人工消息和AI消息,他们是ChatMessagePromptTemplate的特定角色子类。
基本概念:
HumanMessagePromptTemplate ,专用于生成用户消息(HumanMessage)的模板类,是ChatMessagePromptTemplate的特定角色子类。
本质:预定义了role = "human"的MessagePromptTemplate,且无序手动创建角色模板化:支持使用变量占位符,可以再运行时填充具体指格式化:能够将模板与输入变量结合生成最终的聊天消息输出类型:生成HumanMessage对象(content + role = human)设计目的:简化用户输入消息的模板化构造,避免重复定义角色
SystemMessagePromptTemplate 、AIMessagePromptTemplate:类似于上面,不再赘述
ChatMessagePromptTemplate,用于构建聊天消息的模板。它允许你创建可宠用的消息模板,这些模板可以动态地插入变量值来生成最终的聊天消息
角色指定:可以为每条消息指定角色(如"system"、"human"、"ai")等,角色灵活。模板化:支持使用变量占位符,可以再运行时填充具体值格式化:能够将模板与输入变量结合生成最终的聊天消息
例1:
python
# 导入聊天消息类模板
from langchain_core.prompts import (ChatPromptTemplate,
HumanMessagePromptTemplate,
SystemMessagePromptTemplate)
# 创建消息模板
system_template = "你是一个专家{role}"
system_message_prompt = SystemMessagePromptTemplate.from_template(system_template)
human_template = "给我解释{concept},用浅显易懂的语言"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
# 组合成聊天提示模板
chat_prompt = ChatPromptTemplate.from_messages([
system_message_prompt,
human_message_prompt
])
# 格式化提示
formatted_messages = chat_prompt.format_messages(
role="物理学家",
concept="相对论"
)
print(formatted_messages)例2:ChatMessagePromptTemplate的理解
python
from langchain_core.prompts import ChatMessagePromptTemplate
#定义模板
prompt = "今天我们要上的课是{subject}"
#创建自定义角色聊天消息提示词模板
chat_message_prompt=ChatMessagePromptTemplate.from_template(
role="teacher",
template=prompt
)
#格式聊天消息提示词
resp = chat_message_prompt.format(
subject="如何在3000分对局中压力对面"
)
print(type(resp))
print(resp)结合LLM调用
例1:
python
from langchain.prompts.chat import ChatPromptTemplate
import os
import dotenv
from langchain_openai import ChatOpenAI
chat_prompt = ChatPromptTemplate.from_messages([
("system","你是一个小作家,你特别喜欢《龙族》的作者江南"),
("human","我的要求:{request}"),
])
messages = chat_prompt.format_messages(
request = "模仿江南的文笔写一段路明非和绘梨衣在一起的结局"
)
dotenv.load_dotenv()
os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
os.environ["OPENAI_BASE_URL"] = os.getenv("OPENAI_BASE_URL")
chat_model = ChatOpenAI(
model = "gpt-4o-mini"
)
output = chat_model.invoke(messages)
print(output.content)夕阳的余晖透过密林,洒落在青翠的草地上,洒下斑驳的金色光影。路明非静静坐在溪边,手中捧着那本已经翻旧的书,然而他的眼神却飘向远方的那片天际。
此时的绘梨衣,正蹲在一旁的水边,细致地捡起一朵绽放的白色野花,微风轻轻吹拂她的长发,宛如洒落的花瓣,柔柔地摇曳。她的笑容在阳光下格外明媚,仿佛是一道光,照亮了路明非心中那片曾经险峻的阴霾。
"明非。"绘梨衣转过头,目光如水波荡漾,"你觉得未来会怎样?"
他微微一愣,缓缓合上书本,目光坚定而温和地看着她:"未来是什么,或许我们无法预知,但我希望无论发生什么,我都能与你并肩走下去。"
绘梨衣的心跳在瞬间加速,似乎有什么情感在她心底悄然升腾。她轻轻放下手中的花,走向他,握住他的手,彼此的温度在这个平静的黄昏中交融。
不远处,溪水潺潺,映着两人的剪影,仿佛那一刻的永恒。明知前方的路充满荆棘,他们却愿意携手共进,因为彼此的心,是彼此最坚实的依靠。
"来吧,我们继续走,"路明非微笑着说,眼中闪烁着坚定的光芒。
随着他的话音,绘梨衣轻轻点头,决然与他一同迈出了下一步,仿佛那条未知的路,正因他们的选择而变得鲜活无畏。
夕阳西下,余晖洒在他们身上,像是为这段旅程赋予了神圣的光辉。在这无尽的岁月里,只愿有你,便是晴天。
(个人感觉AI感还是太强了,没有江南老贼的感觉~)
插入消息列表:MessagePlaceholder
当你不确定消息模板使用什么角色,或者希望在格式化过程中插入消息列表时,就需要使用MessagesPlaceholde,负责在特定位置添加消息列表
使用场景:多轮对话系统存储历史消息以及Agent的中间步骤处理此功能非常有用。
例1:
python
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.messages import HumanMessage
prompt_template = ChatPromptTemplate.from_messages([
("system","你是一个智能体"),
MessagesPlaceholder("msgs")
])
prompt_template.format_messages(
msgs = [HumanMessage(content = "你好")]
)这将生成两条消息,第一条时系统信息,第二条时我们传入的HumanMessage。如果我们传入了5条消息,那么总共会生成6条消息(系统消息再加上传入的5条消息)。这对于将一系列消息插入到特定位置非常有用。
例2:存储对话历史内容
python
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.messages import AIMessage
prompt = ChatPromptTemplate.from_messages([
("system","你是一个数学大师"),
MessagesPlaceholder("history"),
("human","{question}")
])
prompt.format_messages(
history=[
HumanMessage(content = "1+2=?"),
AIMessage(content="1+2=3")
],
question="我刚才问的是什么?"
)使用-少量样本示例的提示词模板
说明
在构建prompt时,可以通过构造一个少量示例列表去进一步格式化prompt,这是一种简单但强大的指导生成方式,在某些情况下可以显著提高模型性能
少量示例提示模板可以由一组示例或一个负责从定义的结合中选择一部分示例的示例选择器构建
- 前者:使用FewShotPromptTemplate 或FewShotChatMessagePromptTemplate
- 后者:使用Example Selectors(示例选择器)
每个示例的结构都是一个字典,其中键是输入变量,值是输入变量的值
FewShotPromptTemplate的使用
例1:
python
from langchain.prompts import PromptTemplate
from langchain.prompts.few_shot import FewShotPromptTemplate
#创建示例集合
example = [
{"input":"长沙天气怎么样","output":"长沙市"},
{"input":"南京热吗","output":"南京市"},
{"input":"武汉樱花开了吗","output":"武汉市"}
]
#创建PromptTemplate实例
example_prompt = PromptTemplate.from_template(
template = "Input:{input}\nOutput:{output}"
)
#创建FewShotPromptTemplate实例
prompt = FewShotPromptTemplate(
examples = example,
example_prompt = example_prompt,
suffix = "Input:{input}\nOutput:", #要放在示例后面的提示模板字符串
input_variables = ["input"] #传入的变量
)
#调用
final_prompt = prompt.invoke({"input":"北京多少度"})
print(final_prompt)结合大模型调用:
python
from langchain_openai import ChatOpenAI
import os
import dotenv
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
chat_model = ChatOpenAI(model = "gpt-4o-mini")
chat_model.invoke(few_shot_template.invoke({"input":"天津会下雪吗"})).contentFewShotChatMessagePromptTemplate的使用
除了FewShotChatMessagePromptTemplate的之外,FewShotChatMessagePromptTemplate是专门为聊天对话 场景设计的少量样本(few-shot)提示模板,它继承自FewShotPromptTemplate,但针对聊天消息的格式进行了优化
特点:
- 自动将示例格式化为聊天消息(HumanMesssage /AIMessage等)
- 输出结构化聊天消息(ListBaseMessage )
例1:基本结构
python
from langchain.prompts import(
FewShotChatMessagePromptTemplate,
ChatPromptTemplate,
)
#示例消息格式
examples = [
{"input":"1+1等于几?","output":"1+1等于2"},
{"input":"法国的首都是?","output":"巴黎"}
]
#定义示例的消息格式提示词模板
msg_example_prompt = ChatPromptTemplate.from_messages([
("human","{input}"),
("ai","{output}")
])
#定义FewShotChatMessagePromptTemplate对象
few_shot_prompt = FewShotChatMessagePromptTemplate(
examples = examples,
example_prompt = msg_example_prompt,
)
print(few_shot_prompt.format())Example Selector(示例选择器)
前面FewShotPromptTemplate的特点是,无论输入什么问题,都会包含全部示例。在实际开发中,我们可以根据当前输入,使用示例选择器,从大量候选示例中选取最相关的示例子集
使用的好处:避免盲目传递所有实例,减少token消耗的同时,还可以提升输出效果
示例选择策略:语义相似选择,长度选择,最大边际相关示例选择等
语义相似选择:通过余弦相似度等度量方式评估语义相关性,选择与输入问题最相似的k个示例长度选择:根据输入文本的长度,从候选示例中筛选出长度最匹配的示例。增强模型对文本结构的理解。比语义相似度计算更轻量,适合对响应速度要求高的场景最大边际化示例选择:优先选择输入问题语义相似的示例;同时,通过惩罚机制避免返回同质化的内容
例1:
python
from langchain_community.vectorstores import Chroma
from langchain_core.example_selectors import SemanticSimilarityExampleSelector
import os
import dotenv
from langchain_openai import OpenAIEmbeddings
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
embeddings_model = OpenAIEmbeddings(
model="text-embedding-ada-002"
)
examples = [
{
"question": "谁活得更久,穆罕默德·阿里还是艾伦·图灵?",
"answer": """
接下来还需要问什么问题吗?
追问:穆罕默德·阿里去世时多大年纪?
中间答案:穆罕默德·阿里去世时享年74岁。
""",
},
{
"question": "craigslist的创始人是什么时候出生的?",
"answer": """
接下来还需要问什么问题吗?
追问:谁是craigslist的创始人?
中级答案:Craigslist是由克雷格·纽马克创立的。
""",
},
{
"question": "谁是乔治·华盛顿的外祖父?",
"answer": """
接下来还需要问什么问题吗?
追问:谁是乔治·华盛顿的母亲?
中间答案:乔治·华盛顿的母亲是玛丽·鲍尔·华盛顿。
""",
},
{
"question": "《大白鲨》和《皇家赌场》的导演都来自同一个国家吗?",
"answer": """
接下来还需要问什么问题吗?
追问:《大白鲨》的导演是谁?
中级答案:《大白鲨》的导演是史蒂文·斯皮尔伯格。
""",
},
]
# 定义示例选择器
example_selector = SemanticSimilarityExampleSelector.from_examples(
# 这是可供选择的示例列表
examples,
# 这是用于生成嵌入的嵌入类,用于衡量语义相似性
embeddings_model,
# 这是用于存储嵌入并进行相似性搜索的 VectorStore 类
Chroma,
# 这是要生成的示例数量
k=1,
)
# 选择与输入最相似的示例
question = "玛丽·鲍尔·华盛顿的父亲是谁?"
selected_examples = example_selector.select_examples({"question": question})
print(f"与输入最相似的示例:{selected_examples}")例2:结合FewShotPromptTemplate使用
python
from langchain_community.vectorstores import FAISS
from langchain_core.example_selectors import SemanticSimilarityExampleSelector
from langchain_core.prompts import FewShotPromptTemplate, PromptTemplate
from langchain_openai import OpenAIEmbeddings
# 定义示例提示词模版
example_prompt = PromptTemplate.from_template(
template="Input: {input}\nOutput: {output}",
)
# 创建一个示例提示词模版
examples = [
{"input": "高兴", "output": "悲伤"},
{"input": "高", "output": "矮"},
{"input": "长", "output": "短"},
{"input": "精力充沛", "output": "无精打采"},
{"input": "阳光", "output": "阴暗"},
{"input": "粗糙", "output": "光滑"},
{"input": "干燥", "output": "潮湿"},
{"input": "富裕", "output": "贫穷"},
]
# 定义嵌入模型
embeddings = OpenAIEmbeddings(
model="text-embedding-ada-002"
)
# 创建语义相似性示例选择器
example_selector = SemanticSimilarityExampleSelector.from_examples(
examples,
embeddings,
FAISS,
k=2,
)
# 定义小样本提示词模版
similar_prompt = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=example_prompt,
prefix="给出每个词组的反义词",
suffix="Input: {word}\nOutput:",
input_variables=["word"],
)
response = similar_prompt.invoke({"word":"忧郁"})
print(response.text)Model I/O-Output Parsers
语言模型返回的内容通常都是字符串的格式(文本格式),但在实际AI应用开发过程中,往往希望model可以返回更直观,更格式化的内容 ,以确保应用能够顺利进行后续的逻辑处理。此时,LangChain提供的输出解释器就派上用场了
输出解释器(Output Parser)负责获取LLM的输出并将其转换为更合适的格式。这在开发中及其重要
输出解析器的分类
LangChain有许多不同类型的输出解析器
StrOutputParser:字符串解析器JsonOutputParser:JSON解释器,确保输出符合特定JSON对象格式XMLOutputParser:XML解析器,允许以流行的XML格式从LLM获取结果CommaSeparatedListOutputParser:CSV解析器,模型的输出以逗号分割,以列表形式返回输出DatatimeOutputParser:日期时间解析器,可用于将LLM输出解析为日期时间格式
除了上述常用的输出解释器之外,还有:
EnmuOutputParser:枚举解析器,将LLM的输出,解析为预定义的枚举值StructuredOutputParser:将非结构化文本 转换为预定义格式的结构化数据(如字典)OutputFixingParser:输出修复解析器,用于自动修复格式错误的解析器,比如将返回的不符合预期的格式输出尝试修正为正确的结构化数据(如JSON)RetryOutputParser:重试解释器,当主解释器(如JSONOutputParser)因格式错误无法解析LLM输出时,通过调用另一个LLM自动修正错误,并重新尝试解析
具体解析器的使用
字符串解析器StrOutputParser
StrOutputParser简单地将任何输入转换为字符串。它是一个简单的解析器,从结果中提取content字段
例:将一个对话模型的输出结果,解析为字符串输出
python
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_core.output_parsers import StrOutputParser
import os
import dotenv
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
chat_model = ChatOpenAI(model="gpt-4o-mini")
messages = [
SystemMessage(content="将以下内容从英语翻译成中文"),
HumanMessage(content="It's a nice day today"),
]
result = chat_model.invoke(messages)
print(type(result))
print(result)
parser = StrOutputParser()
#使用parser处理model返回的结果
response = parser.invoke(result)
print(type(response))
print(response)JSON解析器JsonOutputParser
JsonOutputParser,即JSON输出解析器,是一种用于大模型的自由文本输出转换为结构化JSON数据的工具
使用场景:特别适用于需要严格结构化输出的场景,比如API调用、数据存储或下游任务处理
实现方式
- 方式1:用户自己通过提示词指明返回JSON格式
- 方式2:借助JsonOutputParser的
get_format_instructions(),生成格式说明,指导模型输出JSON结构
例1:
python
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import JsonOutputParser
import os
import dotenv
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
chat_model = ChatOpenAI(model="gpt-4o-mini")
chat_prompt_template = ChatPromptTemplate.from_messages([
("system","你是一个靠谱的{role}"),
("human","{question}")
])
parser = JsonOutputParser()
result = chat_model.invoke(
chat_prompt_template.format_messages(
role="人工智能专家",
question="人工智能用英文怎么说?问题用q表示,答案用a表示,返回一个JSON格式"
)
)
print(result)
print(type(result))
parser.invoke(result)XML解析器XMLOutputParser
XMLOutputParser,将模型的自由文本输出转换为可编程处理的XML数据
如何实现 :在PromptTemplate中指定XML格式要求,让模型返回<tag>content</tag>形式的数据
注意 :XMLOutputParser不会直接将模型的输出保持为原始XML字符串,而是会解析XML并转换成为Python字典(或类似结构化的数据)。目的是为了方便程序后续处理数据,而不是单纯保留XML格式
例1:不使用XMLOutputParser,通过大模型的能力,返回xml格式数据
python
import os
import dotenv
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
chat_model = ChatOpenAI(model="gpt-4o-mini")
actor_query = "生成周星驰的简短电影记录"
output = chat_model.invoke(f"""{actor_query}请将影片附在<movie></movie>标签中""")
print(type(output))
print(output.content)例2:体会XMLOutputParser的格式
python
from langchain_core.output_parsers import XMLOutputParser
import os
import dotenv
from langchain_openai import ChatOpenAI
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
chat_model = ChatOpenAI(model="gpt-4o-mini")
output_parser = XMLOutputParser()
format_instructions = output_parser.get_format_instructions()
print(format_instructions)例3:XMLOutputParser 的使用
python
from langchain_openai import ChatOpenAI
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import XMLOutputParser
model = ChatOpenAI(model="gpt-4o-mini")
actor_query = "生成周星驰的简化电影作品列表,按照最新的时间降序,必要时使用中文"
# 设置解析器 + 将指令注入提示模板。
parser = XMLOutputParser()
prompt = PromptTemplate(
template="回答用户的查询。\n{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
chain = prompt | model | parser
output = chain.invoke({"query": actor_query})
print(output)列表解释器CommaSeparatedListOutputParser
列表解释器:利用此解释器可以将模型的文本响应转换为一个用逗号分割的列表(List[str])
例:
python
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
from langchain.output_parsers import CommaSeparatedListOutputParser
chat_model = ChatOpenAI(model="gpt-4o-mini")
output_parser = CommaSeparatedListOutputParser()
chat_prompt = PromptTemplate.from_template(
"生成5个关于{text}的列表\n\n{format_instructions}",
partial_variables={"format_instructions": output_parser.get_format_instructions()}
)
chain = chat_prompt | chat_model | output_parser
res = chain.invoke({"text":"电影"})
print(res)
print(type(res))日期解析器DatatimeOutputParser
利用此解析器可以直接将LLM输出解析为日期时间格式
- get_format_instructions() :获取日期解析的格式化指令
-
- 举例:1206-08-16T17:39:06.176399Z
例:
python
from langchain_openai import ChatOpenAI
from langchain.prompts.chat import HumanMessagePromptTemplate
from langchain_core.prompts import ChatPromptTemplate
from langchain.output_parsers import DatetimeOutputParser
chat_model = ChatOpenAI(model="gpt-4o-mini")
chat_prompt = ChatPromptTemplate.from_messages([
("system","{format_instructions}"),
("human", "{request}")
])
output_parser = DatetimeOutputParser()
chain = chat_prompt | chat_model | output_parser
resp = chain.invoke({"request":"中华人民共和国是什么时候成立的",
"format_instructions":output_parser.get_format_instructions()})
print(resp)
print(type(resp))