本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。
在当今AI浪潮中,大模型(LLM)无疑是技术前沿的明星。然而,如何让大模型更好地理解我们的私有数据,并提供更准确、更可信的回答,RAG(检索增强生成)技术给出了一个绝佳的答案。但市面上关于RAG的教程,往往止步于理论或简单的原型,距离真正的"生产级"系统总有一段距离。
今天,我们要介绍的这个开源项目,正是为了解决这一痛点而来。它不是简单的代码堆砌,而是一个为期6周、以学习者为中心 的生产级RAG系统实战教程 ------《The Mother of AI Project》的第一阶段:arXiv论文策展人 (arXiv Paper Curator) 。
这个项目将手把手带你构建一个完整的AI研究助手。它能自动抓取学术论文,深入理解其内容,并运用先进的RAG技术,精准回答你的研究疑问。更重要的是,它将教会你如何按照行业最佳实践,从零开始搭建一个生产级的RAG系统。
它与众不同之处在于:强调先打好关键词搜索的基础,再结合向量搜索进行混合检索。这正是许多成功企业构建搜索系统所遵循的专业路径------以扎实的搜索基础为核心,再辅以AI增强,而非一味追求AI优先而忽视了搜索的根本。
通过这个项目,你不仅能拥有一个强大的AI研究助手,更能掌握构建任何领域生产级RAG系统的深厚技术。
你将构建什么?
这个项目以周为单位,循序渐进地构建一个复杂而强大的RAG系统:
- 第1周: 搭建Docker、FastAPI、PostgreSQL、OpenSearch和Airflow构成的完整基础设施。
- 第2周: 实现自动获取和解析arXiv学术论文的数据管道。
- 第3周: 学习生产级BM25关键词搜索,包括过滤和相关性评分。
- 第4周: 掌握智能分块技术,并结合关键词与语义理解实现混合搜索。
- 第5周: 构建完整的RAG管道,集成本地LLM、流式响应和Gradio界面。
- 第6周: 实现生产级监控(Langfuse追踪)和Redis缓存,以优化性能。
下面,让我们逐周深入,看看这6周的旅程将带你探索哪些精彩内容。
第1周:奠定基石------基础设施
万丈高楼平地起,一个稳定的基础设施是任何生产级AI系统的基石。在第一周,你将学会如何利用Docker Compose,搭建起包括FastAPI、PostgreSQL、OpenSearch、Apache Airflow和Ollama(本地LLM服务)在内的核心服务。这将为你后续的所有开发提供坚实的环境支持。
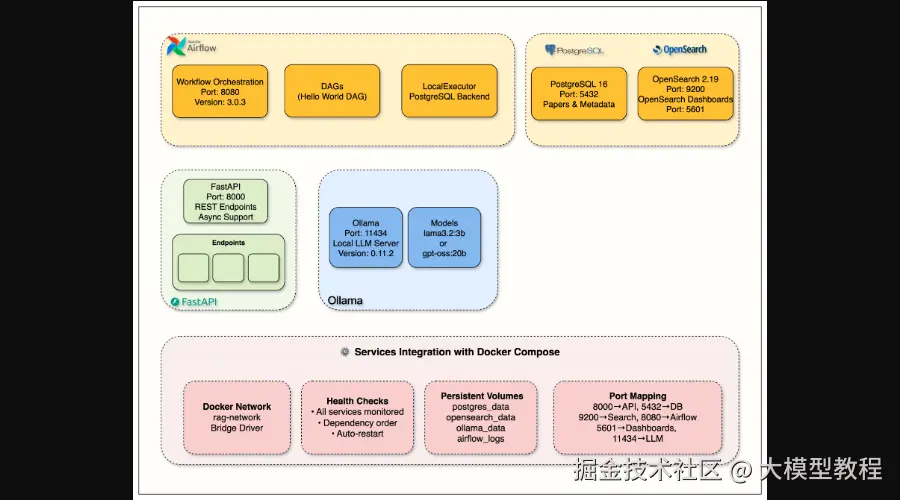 图1:第1周基础设施概览,涵盖API、数据库、搜索、工作流和本地LLM
图1:第1周基础设施概览,涵盖API、数据库、搜索、工作流和本地LLM
本周目标:
- 使用Docker Compose完成基础设施搭建。
- FastAPI开发,实现自动文档和健康检查。
- 配置和管理PostgreSQL数据库。
- 设置OpenSearch混合搜索引擎。
- 配置Ollama本地LLM服务。
- 服务编排和健康监控。
第2周:数据喂养------自动化论文摄取
有了基础设施,RAG系统的"燃料"------数据就成了核心。第二周,你将构建一个自动化的数据摄取管道。它能从arXiv API批量抓取论文元数据和PDF文档,并利用Docling等工具进行科学PDF解析,提取结构化内容。通过Apache Airflow,整个过程将实现自动化调度,确保系统拥有源源不断且处理完善的最新学术资料。
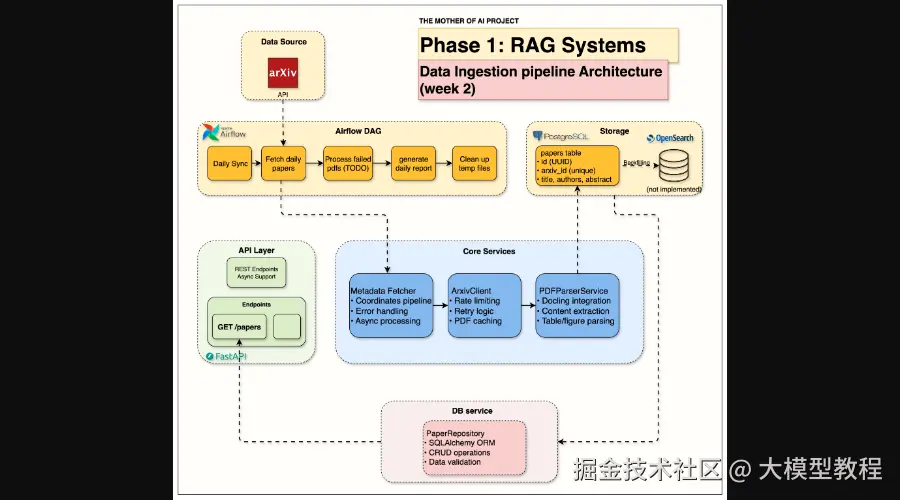
Week 2 Data Ingestion Architecture
图2:第2周数据摄取架构,展示了从arXiv到PostgreSQL的数据流
本周目标:
- 集成arXiv API,实现限速和重试逻辑。
- 使用Docling解析科学PDF文档。
- 通过Apache Airflow构建自动化数据摄取管道。
- 提取和存储论文元数据。
- 实现从API到数据库的完整论文处理。
第3周:搜索之本------关键词先行
很多RAG系统一上来就直奔向量搜索,但这往往会忽略一个重要的基础:关键词搜索。本项目强调先打好BM25关键词搜索的扎实基础。因为在实际生产中,精确匹配、术语识别和效率,关键词搜索往往表现卓越。你将利用OpenSearch,实现高效的关键词检索、过滤和相关性评分,为后续的混合搜索打下坚实的基础。
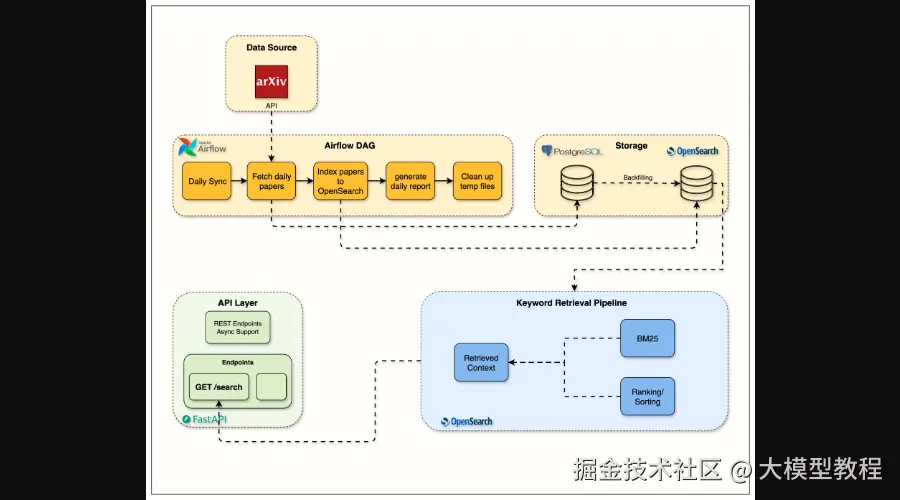
Week 3 OpenSearch Flow Architecture
图3:第3周OpenSearch集成流程架构,专注于关键词搜索
本周目标:
- 理解关键词搜索对RAG系统的重要性。
- 掌握OpenSearch的索引管理、映射和搜索优化。
- 深入理解BM25算法背后的原理。
- 利用Query DSL构建复杂的搜索查询。
- 学习搜索相关性分析和性能测量。
第4周:智能跃迁------分块与混合搜索
在关键词搜索的基础之上,第四周将为系统增加语义理解能力。你将学习如何进行智能分块 ,将长文档切分成有意义的片段,并利用Jina AI等工具生成向量嵌入。随后,通过RRF(Reciprocal Rank Fusion)融合算法,将关键词搜索的精确性和向量搜索的语义召回能力相结合,实现混合搜索,让检索结果既精准又全面。
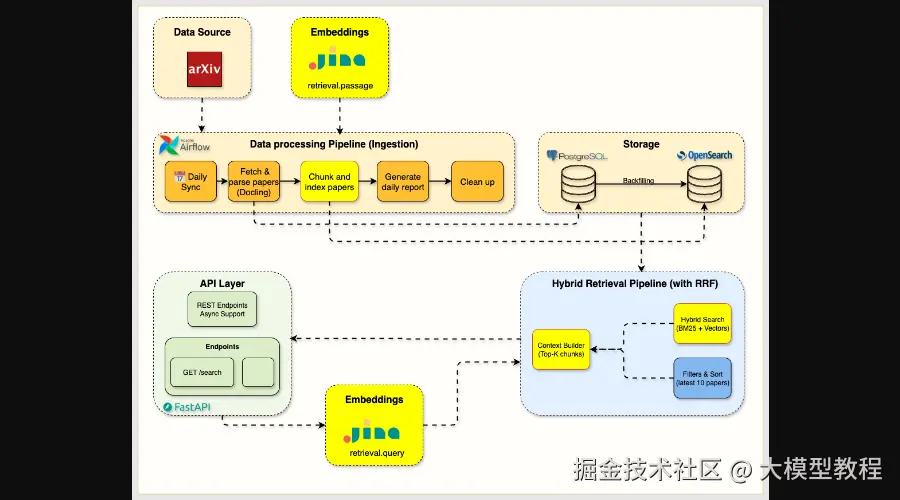
Week 4 Hybrid Search Architecture
图4:第4周混合搜索架构,展示了分块、嵌入和RRF融合
本周目标:
- 掌握基于章节的智能文档分块策略。
- 集成Jina AI等生产级嵌入服务。
- 通过RRF融合实现关键词与语义检索的混合搜索。
- 设计统一的API,支持多种搜索模式。
- 分析不同搜索方法的性能权衡。
第5周:核心智能------完整的RAG管道
至此,RAG系统的检索部分已趋于完善。第五周,我们将集成大模型,完成整个RAG管道的核心。你将把Ollama部署为本地LLM服务,确保数据隐私。通过精心的提示工程,系统响应速度将提升6倍 (从120秒优化到15-20秒)。同时,实现流式响应(SSE) 提供实时用户反馈,并构建一个友好的Gradio交互式Web界面,让非技术用户也能轻松使用。
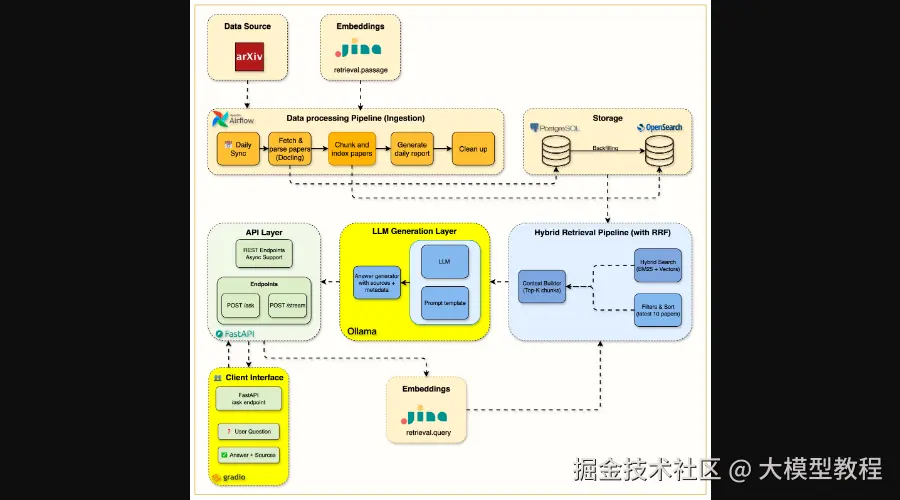
Week 5 Complete RAG System Architecture
图5:第5周完整的RAG系统架构,包括LLM生成层和Gradio界面
本周目标:
- 掌握本地LLM服务(Ollama)集成。
- 通过提示工程实现6倍性能优化和80%的Prompt压缩。
- 实现流式响应(Server-Sent Events)。
- 设计支持标准和流式查询的API。
- 构建带有高级参数控制的Gradio交互式界面。
性能飞跃:
| 指标 | 优化前 | 优化后 (第5周) | 提升幅度 |
|---|---|---|---|
| 响应时间 | 120+ 秒 | 15-20 秒 | 快6倍 |
| 首次出字时间 | 不适用 | 2-3 秒 | 流式启用 |
| Prompt效率 | ~10KB | ~2KB | 80%缩减 |
| 用户体验 | 仅API | Web界面+流式 | 生产就绪 |
第6周:生产就绪------监控与缓存
一个功能完善的RAG系统还不足以称为"生产级"。在最后一周,你将为系统加上至关重要的可观测性和性能优化层。通过集成Langfuse 进行端到端的RAG管道追踪,你可以清晰地看到每个请求从查询到回答的完整路径,分析性能瓶颈。同时,引入Redis缓存 ,针对重复查询可将响应速度从15-20秒提升到惊人的50毫秒 ,实现150-400倍 的加速,并有效降低LLM调用成本达60% 。
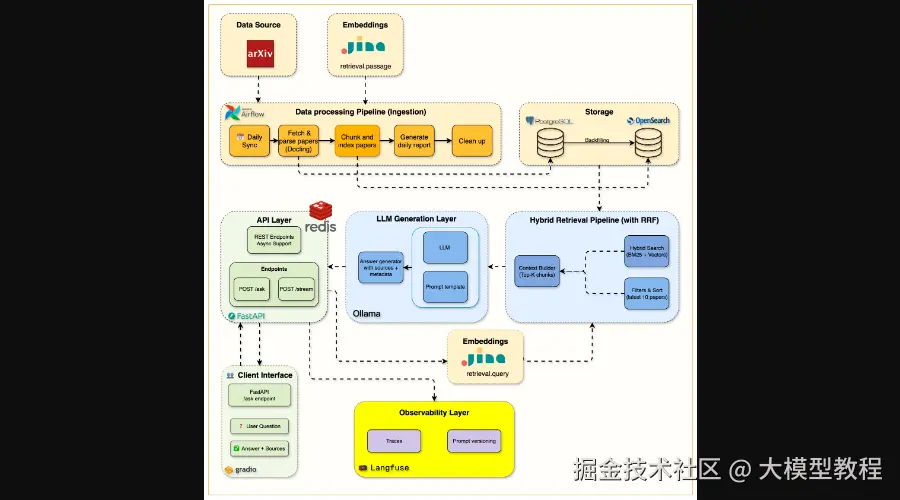
Week 6 Monitoring & Caching Architecture
图6:第6周监控与缓存架构,添加了Langfuse追踪和Redis缓存层
本周目标:
- 集成Langfuse,实现端到端RAG管道追踪和性能分析。
- 制定Redis缓存策略,包括智能缓存键和TTL管理。
- 构建实时性能监控仪表盘,显示延迟、成本和缓存命中率。
- 掌握行业标准的观测和优化技术。
- 分析和优化LLM使用及基础设施成本。
性能与成本显著提升:
| 指标 | 优化前 | 优化后 (第6周) | 提升幅度 |
|---|---|---|---|
| 平均响应时间 | 15-20秒 | 3-5秒 (混合负载) | 快3-4倍 |
| 缓存命中响应 | 不适用 | 50-100毫秒 | 快150-400倍 |
| LLM Token用量 | 100% | 40% (60%缓存) | 减少60% |
| 日常成本 | $12 | $4.50 | 节省63% |
| 系统可观测性 | 无 | 完整追踪 | 全面可见 |
快速开始
这个项目非常适合那些想深入了解RAG系统、提升AI工程实践能力的开发者。所有内容都可以在本地运行,无需额外费用。
先决条件:
- Docker Desktop (含 Docker Compose)
- Python 3.12+
- UV Package Manager
- 8GB+ RAM 和 20GB+ 空闲磁盘空间
开始构建:
- 克隆项目仓库:
bash
git clone <repository-url>
cd arxiv-paper-curator-
配置环境变量:
cpenv
go
(根据需要修改 `.env` 文件,例如第4周需要添加 `JINA_API_KEY`)- 安装依赖:
bash
uv sync- 启动所有服务:
css
docker compose up --build -d- 验证服务:
bash
curl http://localhost:8000/health写在最后
《The Mother of AI Project: arXiv Paper Curator》不仅仅是一个开源项目,更是一门系统而实用的AI工程课程。它将带领你亲历一个生产级RAG系统从无到有的全过程,从基础设施搭建到数据管道,从关键词搜索到混合检索,再到大模型集成、性能优化和生产监控。
如果你是一名AI/ML工程师、软件工程师或数据科学家,渴望将理论知识转化为解决实际问题的能力,那么这个项目绝对是你不容错过的实战宝典。它将帮你填补理论与实践之间的鸿沟,让你真正掌握构建现代AI应用所需的核心技能。
项目地址:
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。