精炼回答
Few-shot Learning是指模型仅需少量样本就能完成新任务的学习范式。对于大语言模型来说,你在prompt里给几个输入-输出的示例,模型就能理解任务模式并处理新的输入。
模型能快速学会的核心原因在于预训练阶段已经学到了丰富的模式识别能力 。比如GPT在海量文本上训练时,见过各种格式转换、分类、抽取等任务的隐含模式。当你给出"将这句话改成礼貌的表达:你错了→您可能理解有偏差"这样两个例子后,模型会在其嵌入空间中激活相关的语义转换模式,通过上下文注意力机制将这些示例作为任务说明来调整后续token的生成概率分布。
本质上说,few-shot不是真正的"学习"新知识,而是利用已有知识进行模式匹配和任务推理。模型参数并未更新,只是通过prompt中的示例构建了一个临时的任务规范。这就像你已经精通编程语法,看到几行代码风格示例就能写出符合规范的新代码,而不需要重新学编程。这也解释了为什么few-shot效果依赖模型规模------更大的模型在预训练时能学到更抽象、更通用的模式表示,从而能更好地从少量示例中提取任务本质。实际应用中,像文本分类、命名实体识别、格式转换等任务都能通过3-5个示例获得不错的效果。
扩展分析
从传统方法到大模型时代的范式转变
面试时回答这道题,最关键的是在开场就让面试官看到你真的理解了Few-shot Learning的本质。传统机器学习需要成百上千条标注数据来训练模型参数,而Few-shot不更新任何参数,直接通过几个示例就能工作。这个区别背后是整个技术范式的转变。
首先是要把Few-shot的概念边界划清楚,它和Zero-shot、One-shot其实是一个连续的光谱。Zero-shot就是完全不给例子,直接用自然语言描述任务让模型去做,比如直接说"把下面这段话翻译成英文"。One-shot是给一个例子作为示范,Few-shot通常是3到5个例子。但这些概念在传统机器学习时代和大模型时代的含义有很大变化,这是很多人容易混淆的地方。
传统Few-shot Learning的语境下,我们说的是真正用几个样本去训练或微调模型。早期做Few-shot主要有三条技术路线:元学习learn to learn的思路、基于度量学习的方法,还有迁移学习。Prototypical Networks是个特别直观的例子,它的核心思想是用少量样本为每个类别构建一个原型向量,新样本就看它离哪个原型最近。比如要做图片分类,每个类别只有5张图,模型会把这5张图的特征向量求个平均作为这个类的原型,测试时就计算新图片和各个原型的距离。这种方法的问题是需要专门设计训练策略,而且泛化能力受限。
MAML是元学习的代表算法,它的思想是训练一个好的初始化参数,这个参数能够在见到新任务的少量样本后快速适应。具体做法是模拟大量的Few-shot任务,每个任务用几个样本做内循环梯度更新,然后在外循环优化初始参数。这个解释够清楚了,核心是你理解它在做什么,而不是背公式。
大模型时代的Few-shot完全不同了,它不需要任何参数更新,甚至不需要梯度计算。你只是把例子放在prompt里,模型通过注意力机制理解这些例子,然后生成符合模式的输出。关键在于预训练阶段的规模够大。GPT-3用了45TB的文本数据训练,这个过程中它见过无数种任务的隐含表达。比如文本中自然出现"问:xxx 答:xxx"这种格式,或者"错误的说法→正确的说法"这种对比,模型的参数就编码了这些模式。当你在prompt里构造类似结构时,注意力机制会把这些例子作为上下文,调整后续token生成的概率分布。
你可以把预训练模型想象成一个见过世面的人,他读过大量书籍文章。当你给他看几个例子时,他不是在学新知识,而是在回忆"哦,这个任务我见过类似的,应该是这样处理"。模型的参数矩阵就像人的记忆,prompt中的例子激活了相关的记忆区域。
在Transformer架构中,注意力机制会计算prompt中所有token之间的关联。当模型看到你给的几个输入-输出例子,它会在生成新输出时,给这些例子中的输出部分更高的注意力权重。这些高权重的token会影响最后的输出概率分布,使得生成的结果在语义和格式上都接近你给的例子。这也解释了为什么模型越大效果越好------小模型的参数容量有限,预训练时学到的模式比较浅层,可能只是记住了表面的词汇共现。大模型能学到更抽象的语义转换规则,比如"礼貌化表达"这种高层概念,所以从几个例子中提取任务本质的能力更强。
面试官很可能问"那为什么不直接Fine-tuning"。Fine-tuning需要收集大量标注数据,更新模型参数,计算成本高而且有过拟合风险 。Few-shot的优势是即插即用,换个任务只需要改prompt。但劣势是性能上限通常不如充分Fine-tuning,而且对prompt的措辞很敏感。比如电商平台要做商品评论的情感分类,如果是高频核心任务,值得收集一万条数据去Fine-tuning一个专用模型。但如果是临时需求,比如分析某个新品类的评论倾向,用Few-shot给几个例子就能快速上线,不需要等数据积累和训练周期。
Zero-shot和Few-shot的对比也很有意思。Zero-shot更灵活,不需要构造例子,但对模型的理解能力要求更高,而且效果不稳定。Few-shot通过例子明确了输入输出的格式和风格,能显著提升准确性。实践中我们会先试Zero-shot,如果效果不理想再加几个Few-shot例子,这是个渐进的优化过程。
In-Context Learning是大模型Few-shot的核心机制,值得多说几句。GPT这类模型的In-Context Learning能力其实是个涌现现象,小模型几乎没有,大模型突然就表现出来了。研究发现当模型参数量超过某个临界点,比如GPT-3的1750亿参数,它就能从prompt中的例子归纳出任务规则。有研究分析了模型内部的注意力模式,发现在处理Few-shot prompt时,后面层的注意力头会重点关注例子中的输入-输出对应关系。模型像是在做模式匹配,找到"当输入是A类特征时,输出应该是B类特征"这种映射规律。
In-Context Learning不改变参数,这意味着它不会"忘记"预训练知识,也不会过拟合到你给的几个例子上。但这也是局限------它只能利用已有知识重组,真正全新的知识学不会。所以如果任务和预训练数据分布差异太大,Few-shot效果会很差,这时候就需要Fine-tuning了。
实践应用中的工程经验
Few-shot特别适合那种需要快速验证想法的场景,典型的像文本分类任务。产品经理突然要分析用户反馈的情感倾向,如果走传统方法,可能要标注几千条数据训练模型,等上线都过了一周。但用Few-shot,你只需要挑选五六条有代表性的评论作为示例,直接调用模型,跑一下 Prompt 就能得到初步结果,半小时就能跑通流程。
类似的,客服机器人要处理新的业务类型,比如售后退换货,传统做法是收集大量对话记录训练意图识别模型。但实际上这类对话有很强的模式性,你在prompt里写三个"用户问XX,客服答YY"的例子,模型就能理解这个场景的应答风格。这种方式特别适合长尾场景,那些频次不高但又必须支持的业务。
设计Prompt最重要的是让模型明确理解输入输出的映射关系 。通常用三段式结构:第一段是任务描述,用一句话说清楚要做什么 ;第二段是示例,每个示例包含明确的输入标记和输出标记 ;第三段是待处理的新输入。假设要分类用户评论的情感,可以这样构造Prompt:先写"请判断以下评论的情感倾向,输出正面、负面或中性",然后给三个示例,格式统一成"评论:这个商品质量真好 → 情感:正面"。注意这里的箭头符号和冒号都要保持一致,因为模型会把这些格式当作模式的一部分来学习。示例的顺序也有影响,一般会把最典型的放在前面,边界情况放在后面,这样模型更容易抓住核心模式。
实现上很直接,核心就是拼接好Prompt字符串然后调API:
python
prompt = """请判断以下评论的情感倾向,输出正面、负面或中性。
评论:这个商品质量真好,超出预期
情感:正面
评论:物流太慢了,等了一周才到
情感:负面
评论:还行吧,没什么特别的
情感:中性
评论:{}
情感:""".format(new_comment)
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": prompt}],
temperature=0.3
)
result = response.choices[0].message.content.strip()这里temperature设成0.3而不是默认的1.0,因为分类任务需要稳定的输出,不需要太多创造性。拿到响应后要做一些后处理,因为模型有时会输出多余的解释文字,需要提取关键的分类标签。
Few-shot的效果很依赖示例质量。不要随机选样本,而要刻意覆盖不同的典型模式。比如情感分类,正面评论里要包含明确褒奖的和委婉称赞的,负面里要有直接批评的和隐晦抱怨的,这样模型才能学到完整的模式空间。示例数量也是个平衡问题,不是越多越好,因为Prompt长度有限制,而且例子太多模型反而容易混淆。一般先从三个例子开始测试,如果效果不稳定就加到五个,很少超过十个。有个技巧是用对比学习的方式,比如分类任务里每个类别至少给两个例子,让模型看到类内差异。
最常见的问题是模型对措辞敏感,同样的任务换个表达方式效果可能差很多。比如做命名实体识别,开始用"找出文本中的人名"作为指令,效果一般,后来改成"识别以下句子中提到的人物姓名",准确率就上去了。这种情况下需要准备几个语义相近的Prompt版本,跑小规模测试集找最优的。另一个实战问题是输出格式不稳定,模型有时会多输出解释文字,有时格式不对。做法是在示例里严格统一格式,而且在指令部分明确说"仅输出分类结果,不要解释"。如果还不行,就用后处理做规则提取,比如正则匹配提取第一个出现的类别标签。
可以从三个维度评估什么时候用Few-shot,什么时候该用Fine-tuning:数据量、任务频次和性能要求。如果手上只有几十条标注数据,或者是临时性需求,Few-shot是首选。但如果是核心业务,有几千条以上的高质量数据,而且对准确率要求很高,那Fine-tuning的投入是值得的。拿内容审核来说,如果要识别常见的违规类型比如色情暴力,这是高频任务而且有大量标注数据,肯定要Fine-tuning一个专用模型,追求高召回率。但如果是识别新出现的违规模式,比如某种新型诈骗话术,刚开始可能只有十几个样本,这时候用Few-shot快速上线拦截,等积累了几百个案例再考虑Fine-tuning。
Few-shot的成本主要在API调用费用,每次推理都要把示例传给模型,token消耗大。Fine-tuning是一次性投入训练成本,但后续推理便宜。所以如果是低频但长期存在的需求,比如季度报告生成,Few-shot更划算。如果是高并发的在线服务,Fine-tuning后部署自己的模型更经济。
技术选择的系统思维
当面试官抛出Few-shot Learning这个问题时,他真正想看的不是你能背出定义,而是想判断你对AI前沿技术的理解深度,以及能否把理论和实际问题连接起来。真正能让面试官眼前一亮的,是你能自然地把Few-shot放在整个AI系统演进的脉络里讨论,说出它解决了什么问题、适用边界在哪里、跟其他技术如何配合。
如果Few-shot效果不好怎么办?别急着说Fine-tuning ,而是先展现诊断思路。先看示例选择是否合理,是不是覆盖了不同的典型模式,然后检查prompt措辞是否清晰,最后才考虑是不是任务本身超出了模型的预训练知识边界。这种分层排查的思路体现了工程成熟度。如何选择Few-shot的示例也是个高频追问,这里要强调多样性和代表性的平衡------既要覆盖不同子模式,又不能引入噪声干扰模型判断。
Few-shot和RAG的关系是个展现架构视野的机会。RAG是检索外部知识库提供上下文,Few-shot是通过示例定义任务格式,两者可以结合使用。比如先用RAG找到相关案例,再把这些案例作为Few-shot示例传给模型。这种组合在电商场景特别有用,比如客服回复用户问题时,先检索历史对话记录找到类似案例,然后把这些案例作为Few-shot示例让模型生成符合公司话术风格的回复。
电商场景特别适合讨论冷启动问题。新上线的品类没有历史数据,传统分类模型训练不起来,这时候用Few-shot给几个商品描述和类别的对应例子就能快速搭建初版系统。新品推荐也是类似场景,新商品缺少用户行为数据,可以用Few-shot根据商品属性相似性生成初始推荐策略。这些例子不需要展开技术细节,点到即止,关键是让面试官看到你思考过如何把技术落地到具体业务问题上。
体现技术判断力的关键在于主动谈适用边界和局限性。Few-shot在任务和预训练数据分布相近时效果好,但遇到真正的新知识就无能为力,这时候需要收集数据做Fine-tuning或者重新预训练。Few-shot对prompt的敏感性是个实际问题,同样的任务换个说法效果可能相差很多,这就需要做prompt工程和AB测试。这种讨论显得你思考问题很全面,既看到技术的价值也清楚它的局限。
在实际系统里,Few-shot、Fine-tuning、RAG这些技术不是非此即彼,而是根据任务特点组合使用。Few-shot适合快速验证和长尾场景,Fine-tuning适合核心高频任务,RAG补充实时更新的知识。面试时如果能主动画出这样一个技术选型的决策树,面试官会觉得你不只是学了一堆技术概念,而是真正理解了如何构建可落地的AI系统。
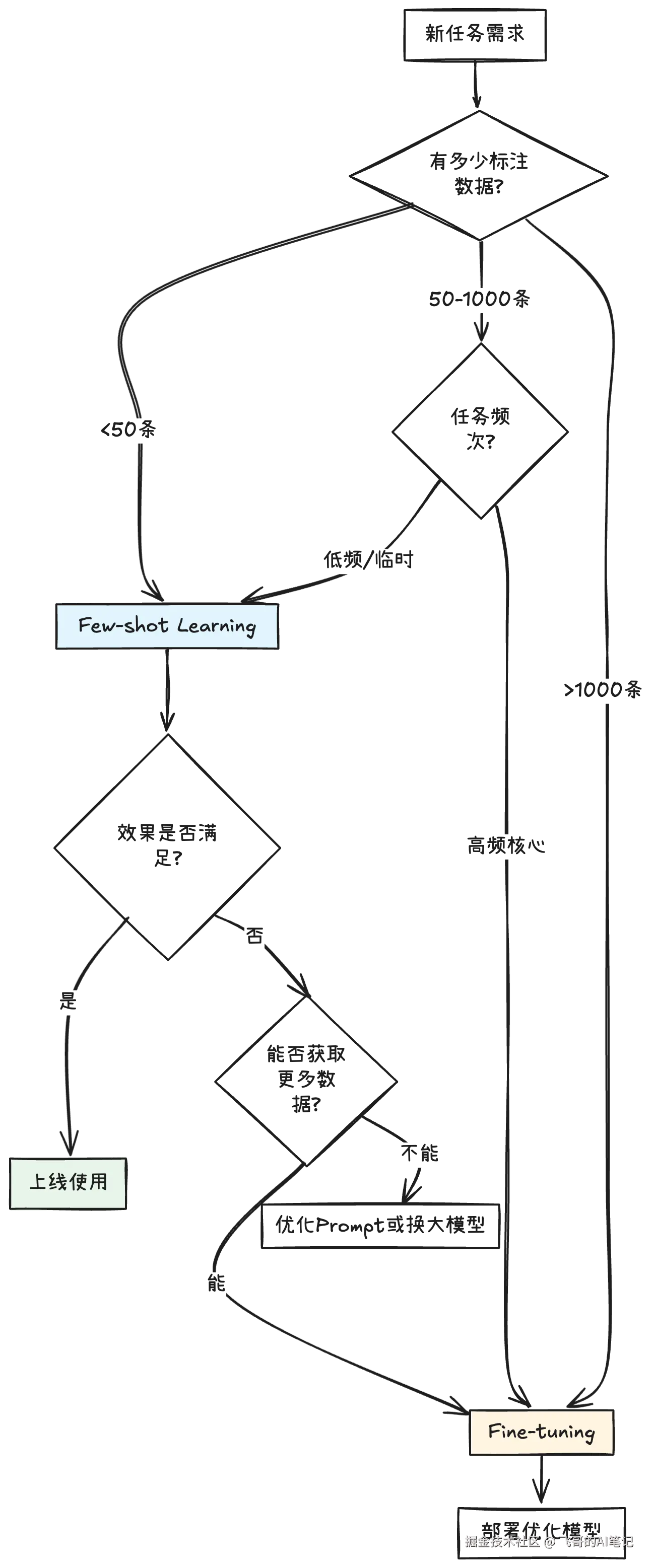
这个决策流程图清晰地展示了在不同数据量和业务场景下如何选择技术方案,体现了系统化的工程思维。