9 月 29 日,DeepSeek 最新发布的 DeepSeek-V3.2-Exp 模型引入了自主研发的 DeepSeek Sparse Attention(DSA)稀疏注意力机制,在几乎不影响模型性能的前提下,实现了长文本训练和推理效率的大幅提升。本文旨在深入解析 DSA 的技术原理,并重点探讨中昊芯英「刹那®」TPU 平台如何凭借其片上缓存与高度并行矩阵计算单元,在 Lightning Indexer 键缓存管理、突破「内存墙」瓶颈、提升长文本处理效率及降低推理成本等方面取得的显著收益与适配成果。
1.DSA稀疏注意力机制的技术突破
1.1 背景:如何突破传统注意力机制的瓶颈
标准自注意力(Self-Attention)机制是 Transformer 架构的核心,但其计算和内存复杂度均与序列长度 L 的平方 O(L²) 成正比。当处理长文本时,这种二次方增长的复杂度会迅速成为性能瓶颈,导致显存耗尽和计算延迟过高,限制了模型处理长序列的能力。为克服这一限制,学术界与工业界提出了多种稀疏注意力方案(即仅对部分 token 进行注意力计算),如滑动窗口注意力、块稀疏注意力、可学习稀疏模式、低秩近似等。稀疏注意力可以显著减少计算、内存开销,并提升吞吐或降低成本。DeepSeek-V3.2-Exp的核心武器DeepSeek 稀疏注意力(DSA),首次实现了细粒度稀疏注意力机制,在几乎不影响模型输出效果的前提下,实现了长文本训练和推理效率的大幅提升。
论文地址:github.com/deepseek-ai...
1.2 DeepSeek稀疏注意力(DSA)核心架构
DeepSeek-V3.2-Exp 与上一版本DeepSeek-V3.1-Terminus相比,核心创新在于引入了DeepSeek 稀疏注意力(DSA)。DSA 通过筛选与当前任务高度相关的文本,而非对全部历史 token 进行全量注意力计算,从而显著提升运算效率。
DSA 主要包含两项关键技术:闪电索引器(Lightning Indexer)和细粒度稀疏注意力(Fine-grained Sparse Attention)。整体实现基于 MLA 架构,主要流程可参考 Fig.1:
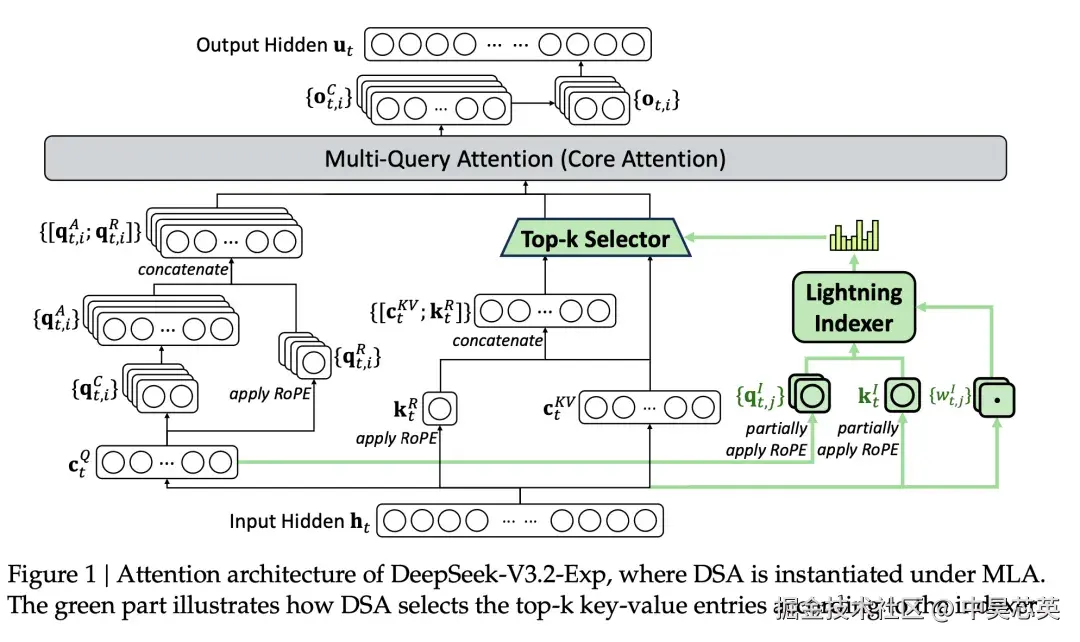
Fig.1 DeepSeek-V3.2-Exp 基于MLA的注意力架构图,其中绿色部分显示了DSA如何根据索引器选择top-k键值条目
1.3 DSA两大核心组件
1.闪电索引器(Lightning Indexer)
闪电索引器负责快速、高效地为每个查询(Query)从海量候选的键(Key)中,识别出最可能相关的 Top-k 个键。闪电索引器的核心目标是以极低的计算开销完成相关键的「海选」。其实现方式如下:
- 低维投影:将原始高维度的 Query 和 Key 向量,通过一个独立的、可学习的线性层投影到极低的维度(例如128维)。这使得后续的相似度计算变得异常高效。
- 高效相似度计算:使用低维投影后的向量 qI 和 kI 计算索引分数,这也是索引器的核心作用,也即为每个查询 token(query token)计算「与前文每个 token 的相关性得分」,即索引得分 Iₜ,ₛ,公式如下:

论文指出:选择 ReLU 激活函数的主要考量是其计算上的高吞吐量(throughput),因为与 Softmax 等需要全局归一化的函数相比,ReLU 仅需进行一次简单的阈值操作,计算成本低。
2.细粒度稀疏注意力(Fine-grained Sparse Attention)
基于索引器输出的分数,token选择机制仅保留 Top-k 索引分数对应的键值对(KV),再通过注意力机制计算最终输出 uₜ(仅基于这些筛选后的「关键键值对」计算注意力)。具体工作流程为:
1). 为每个查询token ht计算索引分数{𝐼𝑡,𝑠}
2). 选择 Top-k 索引分数对应的键值条目{𝑐𝑠}
3). 在稀疏选择的键值条目上应用注意力机制,公式如下:
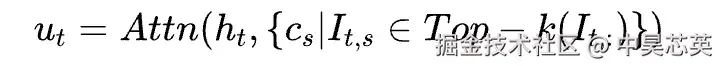
复杂度降低:通过这一机制,核心注意力的计算复杂度从 O(L²) 成功降至 O(L*k)(其中 k 远小于 L),实现了计算量和内存访问的巨大节省。在 DeepSeek-V3.2-Exp 的训练中,k 值设为 2048;也就是说即使处理 128K 长度的文本,每个查询 token 也只需与 2048 个最相似的 token 计算注意力。
这种两阶段设计,既保证了筛选过程的高效率,又确保了最终注意力计算的高精度。
1.4 在MLA架构下的工程实现
DSA架构与DeepSeek-V3.1-Terminus 兼容,DSA 采用 MLA(多头潜在注意力)框架的 MQA(多查询注意力)模式(而非 MHA 模式)实现。MQA 模式下每个 KV 条目可被多个查询共享,这种设计的关键优势在于:
- 计算共享:每个潜在向量在所有查询头之间共享
- 内存效率:显著减少键值缓存的内存占用
- 训练稳定性:支持从已有检查点的平滑继续训练
2.「刹那®」TPU平台上的DSA效能优势
中昊芯英「刹那®」TPU 的硬件架构与 DSA(DeepSeek Sparse Attention)稀疏计算模式的两阶段设计(即 Lightning Indexer 的筛选阶段与稀疏 Attention 的计算阶段)形成了高度协同,具体表现为以下两个层面:
2.1 在Lightning Indexer计算阶段的高效协同
-
片上缓存与数据局部性:Lightning Indexer 需要为每个 token 维护一个小维度(如 128 维)的键缓存。这个缓存尺寸能够被完全存放在「刹那®」TPU 的高速片上静态随机存取存储器(SRAM)中。这使得索引器所需的核心计算(查询与键的点积运算)可完全在芯片内部完成,实现极高的数据局部性,大幅减少向高延迟、高功耗的 DRAM 的数据搬运,成为提升能效的关键。
-
并行矩阵计算单元:「刹那®」TPU 内部集成了大规模、高度并行的矩阵计算单元(类似于 GPU 中的 Tensor Core)。这些计算单元能够以流水线方式,对海量的查询-键对进行并行点积运算,在极短时间内完成对所有候选键的评分和 Top-k 筛选(如前 2048 个 token)。为后续的精确注意力计算完成了高效的「粗筛」。
2.2 在稀疏Attention计算阶段的高效协同
- 计算效率的革新: DSA 将核心计算复杂度从 O(L²) 降至 O(L*k),直接减少了「刹那®」TPU 计算单元处理的总运算量,这使得 TPU 能够以极短的时间完成超长序列的注意力计算。
- 确保计算单元高利用率:更关键的是,DSA 将计算任务从密集全注意力,转化为一次数据量可控的稀疏 Gather 操作和一次规模显著减小的密集矩阵乘法。这种规则化的计算模式使得 TPU 的指令调度与数据预取单元能够高效工作,确保核心计算单元持续处于饱和状态,避免「空转」,从而在处理长序列时获得数倍的性能提升。
- 极致降低访存开销:传统注意力机制在处理每个新生成的 token 时,都需要将整个序列的 Key-Value 缓存从 DRAM 频繁加载至片上缓存。随着序列长度(L)的增加,这种操作对显存带宽的需求呈平方级增长,形成严重的「内存墙」瓶颈。DSA 的稀疏计算模式从根本上改变了这一数据访问范式。它不再处理所有历史 token,而是通过 Lightning Indexer 等组件,智能地筛选出少量最关键 token(如Top-2048)。这意味着,每次计算只需从 DRAM 中选择性加载一小部分 KV 缓存,而非全部,从而将访存量从 O(L²) 降 O(L*k),其中 k 为常数且 k≪L。
3.「刹那®」TPU平台上的DSA适配实践
DeepSeek Sparse Attention(DSA) 推理流程包含两大核心组件:Lightning Indexer 和 Sparse Multi-Latent Attention (MLA)。
- Lightning Indexer:对每个 query token,首先通过低秩投影得到 128 维的稀疏 key 表示(而 MLA 的 KV 通常为更高维,如 512),并对所有历史 token 的 key 进行重要性打分。随后,为每个 query 选出最相关的 Top-2048 个 key token(即 Top-k 稀疏选择)。
- Sparse MLA:仅对被 Indexer 选中的 Top-2048 个 key token 执行稀疏注意力计算,这可极大降低计算和访存压力。
基于上述架构和 vLLM 社区提供的流程图(Fig. 2),DSA 稀疏注意力的推理(prefill + decode)流程可分为以下四个核心步骤:

Fig. 2 Illustration of DeepSeek Sparse Attention (DSA) Mechanism.(图片来源:vLLM)
Step 1:低秩投影与特征预处理(projection for query, key, and query_head_weights)
核心实现 :MLA.init 、MLA.forward、Indexer.init
实现要点:
- 输入 hidden_states 先经低秩线性变换(wq_a、wq_b),得到压缩后的 query(q_compressed)。
- query 经过 RMSNorm 归一化(q_norm)。
- query 拆分为带/不带 RoPE 的两部分,带位置信息部分用 apply_rotary_emb 加入旋转位置编码。
- 生成 query_head_weights(weights_proj),为后续稀疏选择提供打分依据。
Step 2:稀疏打分计算(compute mqa logits)
核心实现: Indexer.forward
实现要点:
- 用压缩后的query、key及query_head_weights计算稀疏打分。
- 该打分仅用于重要性筛选,不直接参与最终注意力输出。
Step 3:Top-k 关键token筛选(select Top-k)
核心实现: Indexer.forward
实现要点:
- 若context_len≤2048,保留所有token连接
- 若 context_len > 2048,每个 query 仅保留 Top-k(如 2048)个最重要的 key,其余跳过计算。
Step 4:稀疏注意力计算与KV缓存访问(run sparse MLA)
核心实现: MLA.forward
实现要点:
- flash_mla_sparse_*(TPU原生指令优化)。
- 仅对上一步筛选出的 Top-k token 对执行注意力运算(通过 index_mask 控制)。
- 结合 KV cache 实现高效推理,支持 prefill 与 decode 两种模式,decode 阶段不会全量加载 KV cache,而是只访问 Top-k 相关的 KV。
关键收获
- 算法核心:轻量预打分 → Top-k 稀疏选择 → Sparse MLA 高效运算
- 复杂度变化:理论上从 O(L²) 降至 O(L*k)
- 实际收益:显著降低运算量、访存量与推理成本,在长上下文场景下性价比提升可达 50% 以上。
在「刹那®」TPU 芯片上的测试显示,DeepSeek-V3.2 与 DSA 结合带来了以下实质性收益:
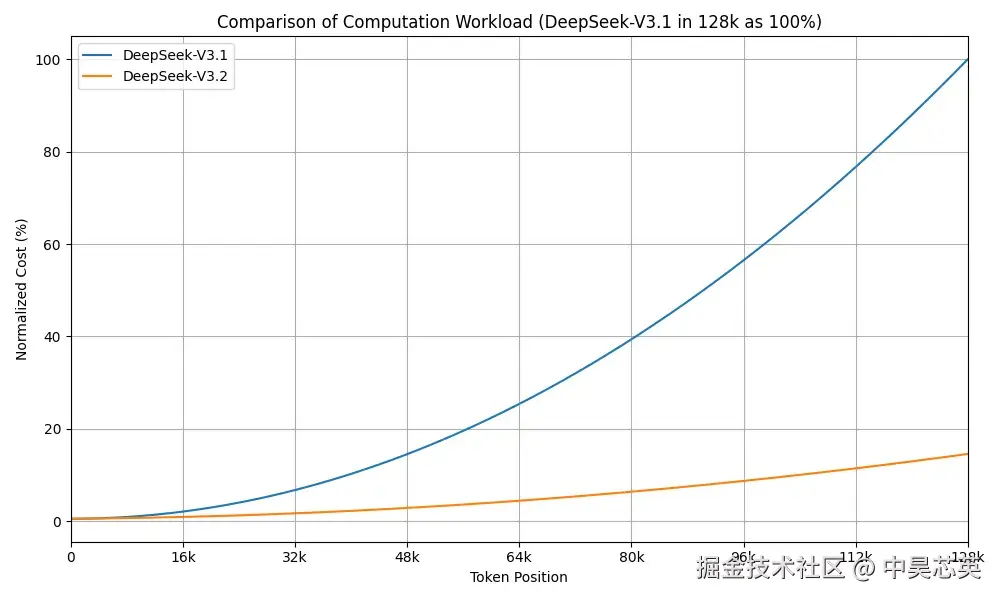
prefill阶段
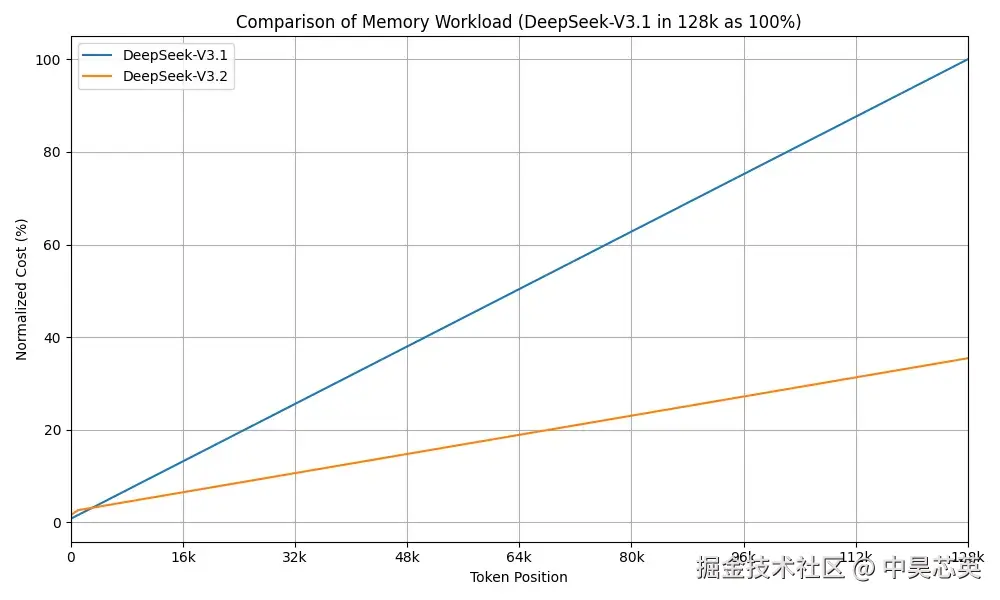
decode阶段
4. 总结与展望
DeepSeek-V3.2-Exp 的 DSA 架构,在保持模型性能的基础上,通过「闪电索引器+Top-k 筛选」的稀疏注意力机制,极大提升了长上下文的计算效率,将长文本推理成本降低至原来的 50% 以下,有效解决了「长文本处理贵」的核心痛点。基于这一技术突破,DSA 架构在以下场景中展现出重要的应用价值:
- 长文档处理:针对法律合同分析、学术论文解析及大型代码库审查等需处理长上下文的场景,DSA 机制通过细粒度 token 选择策略,显著降低内存占用与计算开销。
- 代码编程:对于大型代码库的理解和生成任务,DSA 能够高效捕捉代码中的长距离依赖关系,提升代码任务中对跨文件函数调用和复杂逻辑链的解析能力。
- 多轮对话系统:在需要维护长对话历史的智能助手应用中,DSA 能有效管理不断增长的上下文长度和保持响应质量,并同时控制推理延迟。
在大型语言模型(LLM)向「更长上下文、更准确、更便宜」演进的技术浪潮中,稀疏注意力机制通过算法与硬件协同优化,正成为突破传统 Transformer 计算瓶颈的关键路径。DeepSeek-V3.2-Exp 的实践表明,其采用的 DSA 机制将注意力计算复杂度从 O(L²) 降至 O(L*k) 级别,在长序列任务中实现显著加速,同时保持模型性能。中昊芯英「刹那®」TPU 芯片的硬件特性------片上缓存结构、高度并行的矩阵计算单元等对稀疏计算的天然亲和性及架构级支持,展现出其在承载 DeepSeek-V3.2-Exp 等前沿稀疏注意力模型方面的潜在优势,也为未来实现更高效、低成本的长文本推理提供了可行的技术路径。