08 软件设计的方法论:软件为什么要建模?
我们开发的绝大多数软件都是用来解决现实问题的。通过计算机软件,可以用高效、自动化的方式去解决现实中低效的、手工的业务过程。
因此软件开发的本质就是在计算机的虚拟空间中根据现实需求创建一个新世界。阿里的工程师在创造一个"500平方公里"的交易市场,百度的工程师在创造一个"一万层楼"的图书馆,新浪微博的工程师在创造"两亿份报纸",腾讯的工程师在创造"数10亿个聊天茶室和棋牌室"。
现实世界纷繁复杂,庞大的软件系统也需要很多人合作,开发出众多的模块和代码。如何使软件系统准确反映现实世界的业务逻辑和需求?庞大的软件系统如何能在开发之初就使各个相关方对未来的软件蓝图有清晰的认知和认可,以便在开发过程中使不同工程师们能够有效合作,能够让软件的各个模块边界清晰、易于维护和部署?
这个由软件工程师创造出来的虚拟世界,是一个恢弘大气的罗马都城,还是一片垃圾遍地的棚户区,就看软件工程师如何设计它了,而软件设计的主要过程就是软件建模。
软件建模
所谓软件建模,就是为要开发的软件建造模型。模型是对客观存在的抽象,我们常说的数学建模,就是用数学公式作为模型,抽象表达事务的本质规律,比如著名的(E=mc^2),就是质量能量转换的物理规律的数学模型。除了数学公式是模型,还有一些东西也是模型,比如地图,就是对地理空间的建模。各种图纸,机械装置的图纸、电子电路的图纸、建筑设计的图纸,也是对物理实体的建模。而软件,也可以通过各种图进行建模。
通过建模,我们可以把握事物的本质规律和主要特征,正确建造模型和使用模型,以防在各种细节中迷失方向。软件系统庞大复杂,通过软件建模,我们可以抽象软件系统的主要特征和组成部分,梳理这些关键组成部分的关系,在软件开发过程中依照模型的约束开发,系统整体的格局和关系就会可控,相关人员从始至终都能清晰了解软件的蓝图和当前的进展,不同的开发工程师会很清晰自己开发的模块和其他同事工作内容的关系与依赖,并按照这些模型开发代码。
在软件开发中,有两个客观存在,一个是我们要解决的领域问题,比如我们要开发一个电子商务网站,那么客观的领域问题就是如何做生意,卖家如何管理商品、管理订单、服务用户,买家如何挑选商品,如何下订单,如何支付等等。对这些客观领域问题的抽象就是各种功能及其关系、各种模型对象及其关系、各种业务处理流程。
另一个客观存在就是最终开发出来的软件系统,这个软件系统也是客观存在的,软件由哪些主要类组成,这些类如何组织构成一个个的组件,这些类和组件之间的依赖关系如何,运行期如何调用,需要部署多少台服务器,服务器之间如何通信等。
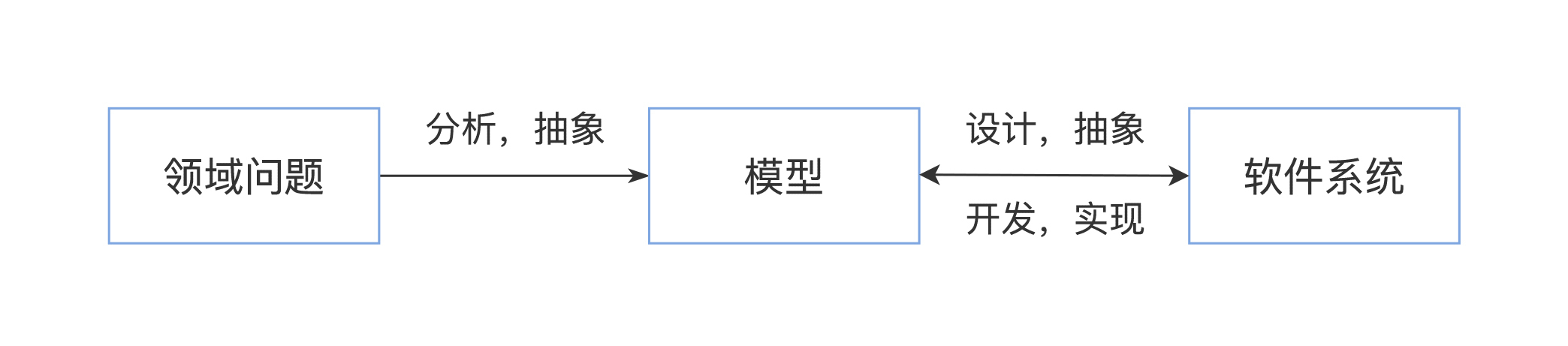
所有这两个方面客观存在的抽象,就是我们的软件模型,一方面我们要对领域问题和软件系统进行分析、设计、抽象,另一方面,我们根据抽象出来的模型开发,实现出最终的软件系统。这就是软件开发的主要过程。而对领域问题和软件系统进行分析、设计和抽象的这个过程,我们专门划分出来,就是软件建模与设计。
4+1视图模型
软件建模比较知名的是4+1视图模型,准确地说,4+1模型不是一种软件建模工具和方法,而是一种软件建模方法的方法,即建模方法论。
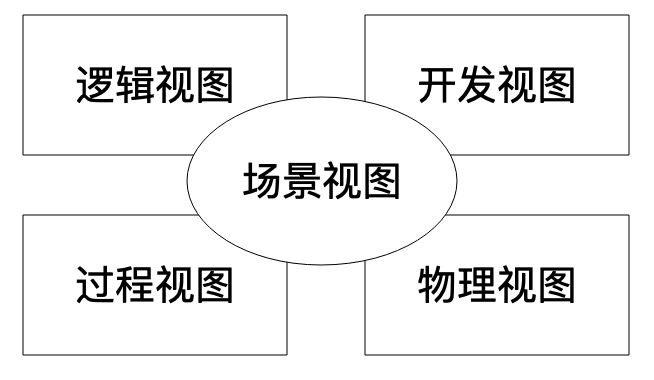
4+1视图模型认为,一个完整的软件设计模型,应该包括5部分的内容:
- 逻辑视图:描述软件的功能逻辑,由哪些模块组成,模块中包含哪些类,其依赖关系如何。
- 开发视图:包括系统架构层面的层次划分,包的管理,依赖的系统与第三方的程序包。开发视图某些方面和逻辑视图有一定重复性,不同视角看到的可能是同一个东西,开发视图中一个程序包,可能正好对应逻辑视图中的一个功能模块。
- 过程视图:描述程序运行期的进程、线程、对象实例,以及与此相关的并发、同步、通信等问题。
- 物理视图:描述软件如何安装并部署到物理的服务上,以及不同的服务器之间如何关联、通信。
- 场景视图:针对具体的用例场景,将上述4个视图关联起来,一方面从业务角度描述,功能流程如何完成,一方面从软件角度描述,相关组成部分如何互相依赖、调用。
在机械制图领域,一个立体的零件进行制图设计,必须要画三视图,即正视图、侧视图、俯视图,每张图都平面的,但是组合起来就完整地描述了一个立体的机械零件。4+1视图模型也是通过多个角度描述软件系统的某个方面的抽象模型,最终组合起来构成一个软件完整的模型。
三视图中,有些部分是重复的,而正是这些重复的部分将机械零件不同视角的细节关联起来,使看图者准确了解一个机械零件的完整结构。软件建模的时候也是如此,作为设计者,也许你觉得用多个视图描述软件模型会重复,但是阅读你的设计文档的人,正是通过这些重复,才将软件的各个部分关联起来,对软件整体形成完整的认识。
我在前面说4+1视图模型是一种方法论的原因,就在于这5种视图模型主要指导我们应该从哪些方面去对我们的业务和软件建模。而具体如何去建模,如何画模型,则可以使用各种建模工具去完成,重要的是这些模型能够构成一个整体,从多个视角完整抽象软件系统的各个方面。
在实践中,通常用来进行软件建模画图的工具是UML,建模的时候,也不一定要把5种视图都画出来。因为不同的软件类型其特点和设计关注点各不相同,只要能向相关人员准确传递出自己的设计意图就可以了。
UML建模
UML,即统一建模语言,是目前最常用的建模工具,使用UML可以实现4+1视图模型。这个名字的叫法也很有意思。
所谓统一,指的是在UML之前,软件建模工具和方法有很多种,最后业界达成共识,用UML统一软件建模工具。
所谓建模,前面已经说过,就是用UML对领域业务问题和软件系统进行设计抽象,一个工具完成软件开发过程中的两个客观存在的建模。
所谓语言,这个比较有意思,为什么一个建模工具被称为语言?我们先看下语言的特点,语言一则用以沟通,通过语言人们得以交流;二则用以思考,即使我们不需要和别人交流,仅仅一个人进行思考的时候,其实我们头脑中还是默默在使用语言,有时候甚至不知不觉说出来。
UML也符合语言的这两个特点,一方面满足设计阶段和各个相关方沟通的目的;一方面可以用来思考,即使软件开发过程不需要跟其他人沟通,或者还没到沟通的时候,依然可以使用UML建模画图,帮助自己进行设计思考。
此外,语言还有个特点,就是有方言,而对于UML,就我观察,不同公司,不同团队使用UML都有自己的特点,并不需要拘泥于UML的规范和语法,只要不引起歧义,在使用UML过程中对UML语法元素适当变通正是UML的最佳实践,这正是UML的"方言"。
具体如何使用UML画图建模,如何在不同的软件设计阶段用最合适的UML图形进行软件设计与建模,以及如何将这些模型图整合起来构成一个完整的软件设计文档,我会在下一篇文章中为你讲述。
小结
很多做软件开发同学的职业规划都是架构师,那么设想这样一个场景,如果公司安排你做架构师,要你在项目开发前期进行软件架构设计,你该如何开展你的工作,你该如何输出你的工作成果,你如何确定你的设计是否满足用户需求,你是否有把握最后交付的软件是满足要求的,是否有把握让团队每个工程师清晰了解自己的职责范围并有效地完成开发工作?
架构师的核心工作就是做好软件设计,软件设计是软件开发过程中的一个重要环节。如何进行软件设计,软件设计的输出是什么?软件设计过程中,如何和各个相关方沟通,使软件设计既能满足用户的功能需求,又能满足用户的非功能需求,也能满足用户的成本要求?此外,还要使开发工程师、测试工程师、运维工程师能够理解软件的整体架构、主要模块划分、关键技术实现、核心领域模型,使他们能做好自己的工作,使得软件在开发之初就对软件未来蓝图有个清晰的认识,从而使整个软件开发过程处于可控的范围之内?
以上这些诉求可以说是软件开发管理与技术的核心诉求,这些问题搞定了,软件的开发过程和结果也就都得到了保证。而要实现这些诉求,主要的手段就是软件建模,以及将这些软件模型组织成一篇有价值的设计文档。
思考题
回到我们上面描述的场景,如果公司安排你做架构师,你该如何开展你的工作,你向客户或者上司呈现的第一份工作成果是什么?你如何向团队开发人员呈现你的设计方案?
如果你暂时没有思路也不要紧,下一节我会为你完整描述一个解决思路。
09 软件设计实践:如何使用UML完成一个设计文档?
在上一篇文章中,我们讨论了为什么要建模,以及建模的4+1视图模型,4+1视图模型很好地向我们展示了如何对一个软件的不同方面用不同的模型图进行建模与设计,以完整描述一个软件的业务场景与技术实现。但是软件开发是有阶段性的,在不同的开发阶段用不同的模型图描述业务场景与设计思路,在不同阶段输出不同的设计文档,对于现实的开发更有实践意义。
软件建模与设计过程可以拆分成需求分析、概要设计和详细设计三个阶段。UML规范包含了十多种模型图,常用的有7种:类图、序列图、组件图、部署图、用例图、状态图和活动图。下面我们讨论如何画这7种模型图,以及如何在需求分析、概要设计、详细设计三个阶段使用这7种模型输出合适的设计文档。
类图
类图是最常见的UML图形,用来描述类的特性和类之间的静态关系。
一个类包含三个部分:类的名字、类的属性列表和类的方法列表。类之间有6种静态关系:关联、依赖、组合、聚合、继承、泛化。把相关的一组类及其关系用一张图画出来,就是类图。
类图主要是在详细设计阶段画,如果类图已经设计出来了,那么开发工程师只需要按照类图实现代码就可以了,只要类方法的逻辑不是太复杂,不同的工程师实现出来的代码几乎是一样的,这样可以保证软件的规范、统一。在实践中,我们通常不需要把一个软件所有的类都画出来,把核心的、有代表性的、有一定技术难度的类图画出来,一般就可以了。
 除了在详细设计阶段画类图,在需求分析阶段,也可以将关键的领域模型对象用类图画出来,在这个阶段中,我们需要关注的是领域对象的识别及其关系,所以用简化的类图来描述,只画出类的名字及关系就可以了。
除了在详细设计阶段画类图,在需求分析阶段,也可以将关键的领域模型对象用类图画出来,在这个阶段中,我们需要关注的是领域对象的识别及其关系,所以用简化的类图来描述,只画出类的名字及关系就可以了。
序列图
类图之外,另一种常用的图是序列图,类图描述类之间的静态关系,序列图则用来描述参与者之间的动态调用关系。
每个参与者有一条垂直向下的生命线,这条线用虚线表示,而参与者之间的消息也从上到下表示其调用的前后顺序关系,这正是序列图这个词的由来。每个生命线都有一个激活条,只有在参与者活动的时候才是激活的。
序列图通常用于表示对象之间的交互,这个对象可以是类对象,也可以是更大粒度的参与者,比如组件、服务器、子系统等,总之,只要是描述不同参与者之间交互的,都可以使用序列图,也就是说,在软件设计的不同阶段,都可以画序列图。
组件图
组件是比类粒度更大的设计元素,一个组件中通常包含很多个类。组件图有的时候和包图的用途比较接近,组件图通常用来描述物理上的组件,比如一个JAR,一个DLL等等。在实践中,我们进行模块设计的时候更多的是用组件图。
 组件图描述组件之间的静态关系,主要是依赖关系,如果想要描述组件之间的动态调用关系,可以使用组件序列图,以组件作为参与者,描述组件之间的消息调用关系。
组件图描述组件之间的静态关系,主要是依赖关系,如果想要描述组件之间的动态调用关系,可以使用组件序列图,以组件作为参与者,描述组件之间的消息调用关系。
因为组件的粒度比较粗,通常用以描述和设计软件的模块及其之间的关系,需要在设计早期阶段就画出来,因此组件图一般用在概要设计阶段。
部署图
部署图描述软件系统的最终部署情况,比如需要部署多少服务器,关键组件都部署在哪些服务器上。
部署图是软件系统最终物理呈现的蓝图,根据部署图,所有相关者,诸如客户、老板、工程师都能清晰地了解到最终运行的系统在物理上是什么样子,和现有的系统服务器的关系,和第三方服务器的关系。根据部署图,还可以估算服务器和第三方软件的采购成本。
因此部署图是整个软件设计模型中,比较宏观的一种图,是在设计早期就需要画的一种模型图。根据部署图,各方可以讨论对这个方案是否认可。只有对部署图达成共识,才能继续后面的细节设计。部署图主要用在概要设计阶段。
用例图
用例图主要用在需求分析阶段,通过反映用户和软件系统的交互,描述系统的功能需求。
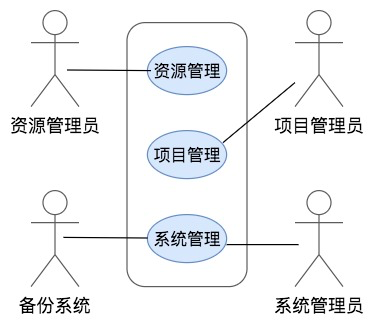
图中小人形象的元素,被称为角色,角色可以是人,也可以是其他的系统。系统的功能可能会很复杂,所以一张用例图可能只包含其中一小部分功能,这些功能被一个矩形框框起来,这个矩形框被称为用例的边界。框里的椭圆表示一个一个的功能,功能之间可以调用依赖,也可以进行功能扩展。
因为用例图中功能描述比较简单,通常还需要对用例图配以文字说明,形成需求文档。
状态图
状态图用来展示单个对象生命周期的状态变迁。
业务系统中,很多重要的领域对象都有比较复杂的状态变迁,比如账号,有创建状态、激活状态、冻结状态、欠费状态等等各种状态。此外,用户、订单、商品、红包这些常见的领域模型都有多种状态。
这些状态的变迁描述可以在用例图中用文字描述,随着角色的各种操作而改变,但是用这种方式描述,状态散乱在各处,不要说开发的时候容易搞错,就是产品经理自己在设计的时候,也容易搞错对象的状态变迁。
UML的状态图可以很好地解决这一问题,一张状态图描述一个对象生命周期的各种状态,及其变迁的关系。如图所示,门的状态有开opened、关closed和锁locked三种,状态与变迁关系用一张状态图就可以搞定。
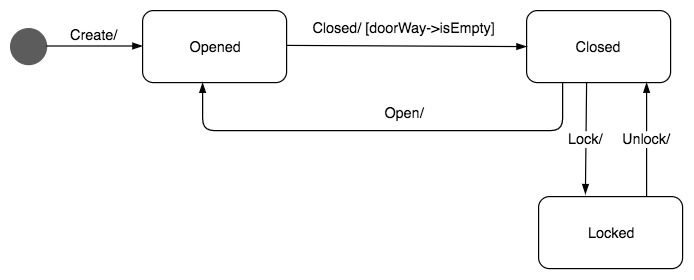
状态图要在需求分析阶段 画,描述状态变迁的逻辑关系,在详细设计阶段也要画,这个时候,状态要用枚举值表示,以指导具体的开发。
活动图
活动图主要用来描述过程逻辑和业务流程。UML中没有流程图,很多时候,人们用活动图代替流程图。
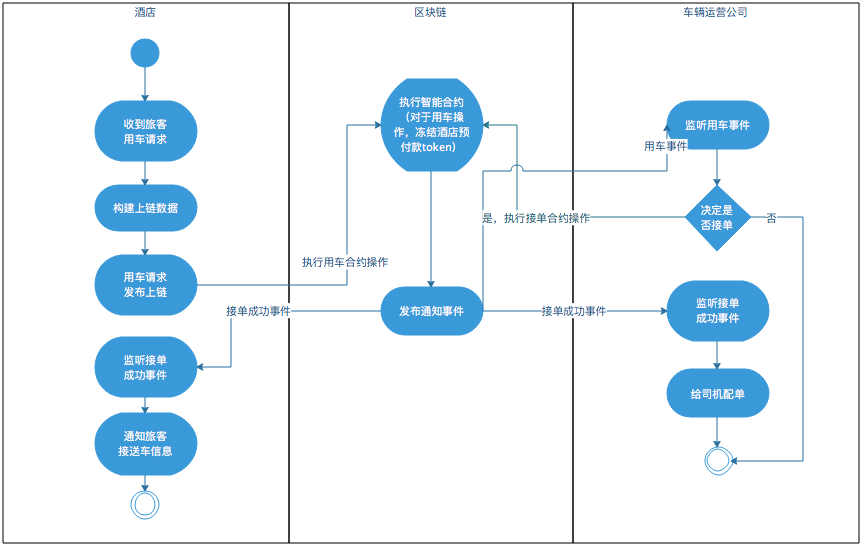
活动图和早期流程图的图形元素也很接近,实心圆代表流程开始,空心圆代表流程结束,圆角矩形表示活动,菱形表示分支判断。
此外,活动图引入了一个重要的概念------泳道。活动图可以根据活动的范围,将活动根据领域、系统和角色等划分到不同的泳道中,使流程边界更加清晰。
活动图也比较有普适性,可以在需求分析阶段 描述业务流程,也可以在概要设计阶段 描述子系统和组件的交互,还可以在详细设计阶段描述一个类方法内部的计算流程。
使用合适的UML模型构建一个设计文档
UML模型图本身并不复杂,几分钟的时间就可以学习一个模型图的画法。但难的是如何在合适的场合下用正确的UML模型表达自己的设计意图,形成一套完整的软件模型,进而组织成一个言之有物,层次分明,既可以指导开发,又可以在团队内外达成共识的设计文档。
下面我们就从软件设计的不同阶段这一维度,重新梳理下如何使用正确的模型进行软件建模。
在需求分析阶段,主要是通过用例图来描述系统的功能与使用场景;对于关键的业务流程,可以通过活动图描述;如果在需求阶段就提出要和现有的某些子系统整合,那么可以通过时序图描述新系统和原来的子系统的调用关系;可以通过简化的类图进行领域模型抽象,并描述核心领域对象之间的关系;如果某些对象内部会有复杂的状态变化,比如用户、订单这些,可以用状态图进行描述。
在概要设计阶段,通过部署图描述系统最终的物理蓝图;通过组件图以及组件时序图设计软件主要模块及其关系;还可以通过组件活动图描述组件间的流程逻辑。
在详细设计阶段,主要输出的就是类图和类的时序图,指导最终的代码开发,如果某个类方法内部有比较复杂的逻辑,那么可以用画方法的活动图进行描述。
下一篇文章我会通过一个示例模板为你展示设计文档的写法和UML模型在文档中的应用。
小结
UML建模可以很复杂,也可以很简单,简单掌握类图、时序图、组件图、部署图、用例图、状态图、活动图这7种模型图,根据场景的不同,灵活在需求分析、概要设计和详细设计阶段绘制对应的模型图,可以实实在在地做好软件建模,搞好系统设计,做一个掌控局面、引领技术团队的架构师。
画UML的工具,可以是很复杂的,用像EA这样的大型软件设计工具,不过是收费的,也可以是draw.io这样在线、免费的工具,一般来说,都建议先从简单的用起。
思考题
你现在开发的软件是否会用到UML建模呢?如果没有,你觉得应该画哪些UML模型?又该如何画呢?
10 软件设计的目的:糟糕的程序员比优秀的程序员差在哪里?
有人说,在软件开发中,优秀的程序员比糟糕的程序员的工作产出高100倍。这听起来有点夸张,实际上,我可能更悲观一点,就我看来,有时候,后者的工作成果可能是负向的,也就是说,因为他的工作,项目会变得更加困难,代码变得更加晦涩,难以维护,工期因此推延,各种莫名其妙改来改去的bug一再出现,而且这种局面还会蔓延扩散,连那些本来还好的代码模块也逐渐腐坏变烂,最后项目难以为继,以失败告终。
如果仅仅是看过程,糟糕的程序员和优秀的程序员之间,差别并没有那么明显。但是从结果看,如果最后的结果是失败的,那么产出就是负的,和成功的项目比,差别不是100倍,而是无穷倍。
程序员的好坏,一方面体现在编程能力上,比如并不是每个程序员都有编写一个编译器程序的能力;另一方面,体现在程序设计方面,即使在没有太多编程技能要求的领域下,比如开发一个订单管理模块,只要需求明确,具有一定的编程经验,大家都能开发出这样一个程序,但优秀的程序员和糟糕的程序员之间,依然有巨大的差别。
在软件设计开发这个领域,好的设计和坏的设计最大的差别就体现在应对需求变更的能力上。而好的程序员和差的程序员的一个重要区别,就是对待需求变更的态度。差的程序员害怕需求变更,因为每次针对需求变更而开发的代码都会导致无尽的bug;好的程序员则欢迎需求变更,因为他们一开始就针对需求变更进行了软件设计,如果没有需求变更,他们优秀的设计就没有了用武之地,产生一拳落空的感觉。这两种不同态度的背后,是设计能力的差异。
一个优秀的程序员一旦习惯设计、编写能够灵活应对需求变更的代码,他就再也不会去编写那些僵化的、脆弱的、晦涩的代码了,甚至仅仅是看这样的代码,也会产生强烈的不舒服的感觉。记得一天下午,一个技术不错的同事突然跟我请假,说身体不舒服,需要回去休息一下,我看他脸色惨白,有气无力,就问他怎么了。他回答:刚才给另一个组的同事review代码,代码太恶心了,看到中途去厕所吐了,现在浑身难受,需要休息。
惊讶吗?但实际上,糟糕的代码就是能产生这么大的威力,这些代码在运行过程中使系统崩溃;测试过程中使bug无法收敛,越改越多;开发过程使开发者陷入迷宫,掉到一个又一个坑里;而仅仅是看这些代码,都会使阅读者头晕眼花。
糟糕的设计
糟糕的设计和代码有如下一些特点,这些特点共同铸造了糟糕的软件。
僵化性
软件代码之间耦合严重,难以改动,任何微小的改动都会引起更大范围的改动。一个看似微小的需求变更,却发现需要在很多地方修改代码。
脆弱性
比僵化性更糟糕的是脆弱性,僵化导致任何一个微小的改动都能引起更大范围的改动,而脆弱则是微小的改动容易引起莫名其妙的崩溃或者bug,出现bug的地方看似与改动的地方毫无关联,或者软件进行了一个看似简单的改动,重新启动,然后就莫名其妙地崩溃了。
如果说僵化性容易导致原本只用3个小时的工作,变成了需要三天,让程序员加班加点工作,于是开始吐槽工作的话,那么脆弱性导致的突然崩溃,则让程序员开始抓狂,怀疑人生。
牢固性
牢固性是指软件无法进行快速、有效地拆分。想要复用软件的一部分功能,却无法容易地将这部分功能从其他部分中分离出来。
目前微服务架构大行其道,但是,一些项目在没有解决软件牢固性的前提下,就硬着头皮进行微服务改造,结果可想而知。要知道,微服务是低耦合模块的服务化,首先需要的,就是低耦合的模块,然后才是微服务的架构。如果单体系统都做不到模块的低耦合,那么由此改造出来的微服务系统只会将问题加倍放大,最后就怪微服务了。
粘滞性
需求变更导致软件变更的时候,如果糟糕的代码变更方案比优秀的方案更容易实施,那么软件就会向糟糕的方向发展。
很多软件在设计之初有着良好的设计,但是随着一次一次的需求变更,最后变得千疮百孔,趋向腐坏。
晦涩性
代码首先是给人看的,其次是给计算机执行的。如果代码晦涩难懂,必然会导致代码的维护者以设计者不期望的方式对代码进行修改,导致系统腐坏变质。如果软件设计者期望自己的设计在软件开发和维护过程中一直都能被良好执行,那么在软件最开始的模块中就应该保证代码清晰易懂,后继者参与开发维护的时候才有章法可循。
一个设计腐坏的例子
软件如果是一次性的,只运行一次就被永远丢弃,那么无所谓设计,能实现功能就可以了。然而现实中的软件,大多数在其漫长的生命周期中都会被不断修改、迭代、演化和发展。淘宝从最初的小网站,发展到今天有上万名程序员维护的大系统;Facebook从扎克伯格一个人开发的小软件,成为如今服务全球数十亿人的巨无霸,无不经历过并将继续经历演化发展的过程。
接下来,我们就来看一个软件在需求变更过程中,不断腐坏的例子。
假设,你需要开发一个程序,将键盘输入的字符,输出到打印机上。任务看起来很简单,几行代码就能搞定:
c
void copy()
{
int c;
while ((c = readKeyBoard()) != EOF)
writePrinter(c);
}你将程序开发出来,测试没有问题,很开心得发布了,其他程序员在他们的项目中依赖你的代码。过了几个月,老板忽然过来说,这个程序需要支持从纸带机读取数据,于是你不得不修改代码:
c
bool ptFlag = false;
//使用前请重置这个flag
void copy()
{
int c;
while ((c = (ptFlag ? readPt() : readKeyBoard())) != EOF)
writePrinter(c);
}为了支持从纸带机输入数据,你不得不增加了一个布尔变量,为了让其他程序员依赖你的代码的时候能正确使用这个方法,你还添加一句注释。即便如此,还是有人忘记了重设这个布尔值,还有人搞错了这个布尔值的代表的意思,运行时出来bug。
虽然没有人责怪你,但是这些问题还是让你很沮丧。这个时候,老板又来找你,说程序需要支持输出到纸带机上,你只好硬着头皮继续修改代码:
c
bool ptFlag = false;
bool ptFlag2 = false;
//使用前请重置这些flag
void copy()
{
int c;
while ((c = (ptFlag? readPt() : readKeyBoard())) != EOF)
ptFlag2? writePt(c) : writePrinter(c);
}虽然你很贴心地把注释里的"这个flag"改成了"这些flag",但还是有更多的程序员忘记要重设这些奇怪的flag,或者搞错了布尔值的意思,因为依赖你的代码而导致的bug越来越多,你开始犹豫是不是需要跑路了。
解决之道
从这个例子我们可以看到,一段看起来还比较简单、清晰的代码,只需要经过两次需求变更,就有可能变得僵化、脆弱、粘滞、晦涩。
这样的问题场景,在各种各样的软件开发场景中,随处可见。人们为了改善软件开发中的这些问题,使程序更加灵活、强壮、易于使用、阅读和维护,总结了很多设计原则和设计模式,遵循这些设计原则,灵活应用各种设计模式,就可以避免程序腐坏,开发出更强大灵活的软件。
比如针对上面这个例子,更加灵活,对需求更加有弹性的设计、编程方式可以是下面这样的:
cpp
public interface Reader {
int read();
}
public interface Writer {
void write(int c);
}
public class KeyBoardReader implements Reader {
public int read() {
return readKeyBoard();
}
}
public class Printer implements Writer {
public void write(int c) {
writePrinter(c);
}
}
Reader reader = new KeyBoardReader();
Writer writer = new Printer():
void copy() {
int c;
while(c = reader.read() != EOF)
writer(c);
}我们通过接口将输入和输出抽象出来,copy程序只负责读取输入并进行输出,具体输入和输出实现则由接口提供,这样copy程序就不会因为要支持更多的输入和输出设备而不停修改,导致代码复杂,使用困难。
所以你能看到,应对需求变更最好的办法就是一开始的设计就是针对需求变更的,并在开发过程中根据真实的需求变更不断重构代码,保持代码对需求变更的灵活性。
小结
我们在开始设计的时候就需要考虑程序如何应对需求变更,并因此指导自己进行软件设计,在开发过程中,需要敏锐地察觉到哪些地方正在变得腐坏,然后用设计原则去判断问题是什么,再用设计模式去重构代码解决问题。
我在面试过程中,考察候选人编程能力和编程技巧的主要方式就是问关于设计原则与设计模式的问题。
我将在"软件的设计原理"这一模块,主要讲如何用设计原则和设计模式去设计强壮、灵活、易复用、易维护的程序。希望这部分内容能够帮你掌握如何进行良好的程序设计。
思考题
你在软件开发实践中,是否曾经看到过一些糟糕的代码?这些糟糕的代码是否符合僵化、脆弱、牢固、粘滞、晦涩这些特点?这些代码给工作带来了怎样的问题呢?
11 软件设计的开闭原则:如何不修改代码却能实现需求变更?
我在上篇文章讲到,软件设计应该为需求变更而设计,应该能够灵活、快速地满足需求变更的要求。优秀的程序员也应该欢迎需求变更,因为持续的需求变更意味着自己开发的软件保持活力,同时也意味着自己为需求变更而进行的设计有了用武之地,这样的话,技术和业务都进入了良性循环。
但是需求变更就意味着原来开发的功能需要改变,也意味着程序需要改变。如果是通过修改程序代码实现需求变更,那么代码一定会在不断修改的过程中变得面目全非,这也意味着代码的腐坏。
有没有办法不修改代码却能实现需求变更呢?
这个要求听起来有点玄幻,事实上却是软件设计需要遵循的最基本的原则:开闭原则。
开闭原则
开闭原则说:软件实体(模块、类、函数等等)应该对扩展是开放的,对修改是关闭的。
对扩展是开放的,意味着软件实体的行为是可扩展的,当需求变更的时候,可以对模块进行扩展,使其满足需求变更的要求。
对修改是关闭的,意味着当对软件实体进行扩展的时候,不需要改动当前的软件实体;不需要修改代码;对于已经完成的类文件不需要重新编辑;对于已经编译打包好的模块,不需要再重新编译。
通俗的说就是,软件功能可以扩展,但是软件实体不可以被修改。
功能要扩展,软件又不能修改,似乎是自相矛盾的,怎样才能做到不修改代码和模块,却能实现需求变更呢?
一个违反开闭原则的例子
在开始讨论前,让我们先看一个反面的例子。
假设我们需要设计一个可以通过按钮拨号的电话,核心对象是按钮和拨号器。那么简单的设计可能是这样的:

按钮类关联一个拨号器类,当按钮按下的时候,调用拨号器相关的方法。代码是这样的:
cpp
public class Button {
public final static int SEND_BUTTON = -99;
private Dialer dialer;
private int token;
public Button(int token, Dialer dialer) {
this.token = token;
this.dialer = dialer;
}
public void press() {
switch (token) {
case 0:
case 1:
case 2:
case 3:
case 4:
case 5:
case 6:
case 7:
case 8:
case 9:
dialer.enterDigit(token);
break;
case SEND_BUTTON:
dialer.dial();
break;
default:
throw new UnsupportedOperationException("unknown button pressed: token=" + token);
}
}
}
public class Dialer {
public void enterDigit(int digit) {
System.out.println("enter digit: " + digit);
}
public void dial() {
System.out.println("dialing...");
}
}按钮在创建的时候可以创建数字按钮或者发送按钮,执行按钮的press()方法的时候,会调用拨号器Dialer的相关方法。这个代码能够正常运行,完成需求,设计似乎也没什么问题。
这样的代码我们司空见惯,但是它的设计违反了开闭原则:当我们想要增加按钮类型的时候,比如,当我们需要按钮支持星号(*)和井号(#)的时候,我们必须修改Button类代码;当我们想要用这个按钮控制一个密码锁而不是拨号器的时候,因为按钮关联了拨号器,所以依然要修改Button类代码;当我们想要按钮控制多个设备的时候,还是要修改Button类代码。
似乎对Button类做任何的功能扩展,都要修改Button类,这显然违反了开闭原则:对功能扩展是开放的,对代码修改是关闭的。
违反开闭原则的后果是,这个Button类非常僵硬,当我们想要进行任何需求变更的时候,都必须要修改代码。同时我们需要注意,大段的switch/case语句是非常脆弱的,当需要增加新的按钮类型的时候,需要非常谨慎地在这段代码中找到合适的位置,稍不小心就可能出现bug。粗暴一点说,当我们在代码中看到else或者switch/case关键字的时候,基本可以判断违反开闭原则了。
而且,这个Button类也是难以复用的,Button类强耦合了一个Dialer类,在脆弱的switch/case代码段耦合调用了Dialer的方法,即使Button类自身也将各种按钮类型耦合在一起,当我想复用这个Button类的时候,不管我需不需要一个Send按钮,Button类都自带了这个功能。
所以,这样的设计不要说不修改代码就能实现功能扩展,即使我们想修改代码进行功能扩展,里面也很脆弱,稍不留心就掉到坑里了。这个时候你再回头审视Button的设计,是不是就感觉到了代码里面腐坏的味道,如果让你接手维护这些代码实现需求变更,是不是头疼难受?
很多设计开始看并没有什么问题,如果软件开发出来永远也不需要修改,也许怎么设计都可以,但是当需求变更来的时候,就会发现各种僵硬、脆弱。所以设计的优劣需要放入需求变更的场景中考察。当需求变更时发现当前设计的腐坏,就要及时进行重构,保持设计的强壮和代码的干净。
使用策略模式实现开闭原则
设计模式中很多模式其实都是用来解决软件的扩展性问题的,也是符合开闭原则的。我们用策略模式对上面的例子重新进行设计。
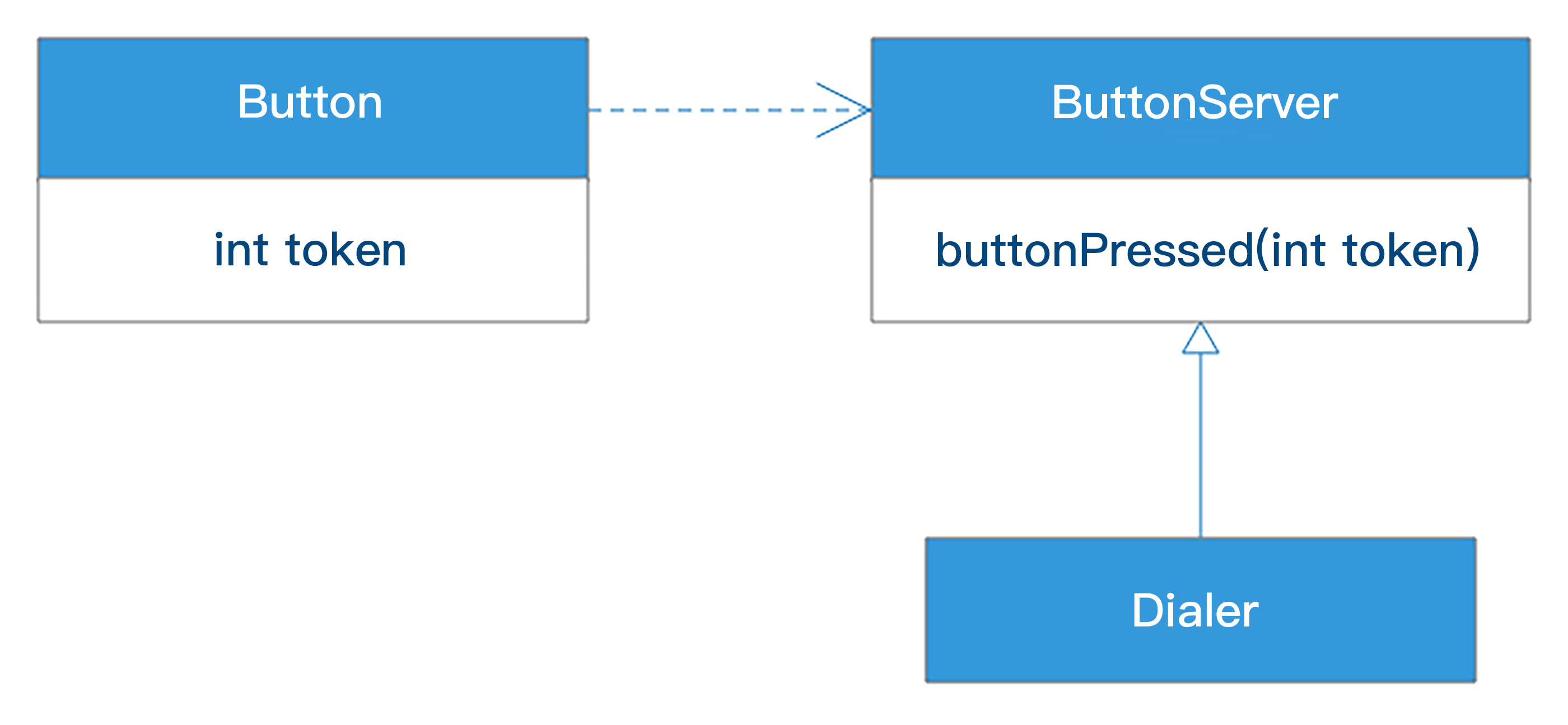
我们在Button和Dialer之间增加了一个抽象接口ButtonServer,Button依赖ButtonServer,而Dialer实现ButtonServer。
当Button按下的时候,就调用ButtonServer的buttonPressed方法,事实上是调用Dialer实现的buttonPressed方法,这样既完成了Button按下的时候执行Dialer方法的需求,又不会使Button依赖Dialer。Button可以扩展复用到其他需要使用Button的场景,任何实现ButtonServer的类,比如密码锁,都可以使用Button,而不需要对Button代码进行任何修改。
而且Button也不需要switch/case代码段去判断当前按钮类型,只需要将按钮类型token传递给ButtonServer就可以了,这样增加新的按钮类型的时候就不需要修改Button代码了。
策略模式是一种行为模式,多个策略实现同一个策略接口,编程的时候client程序依赖策略接口,运行期根据不同上下文向client程序传入不同的策略实现。
在我们这个场景中,client程序就是Button,策略就是需要用Button控制的目标设备,拨号器、密码锁等等,ButtonServer就是策略接口。通过使用策略模式,我们使Button类实现了开闭原则。
使用适配器模式实现开闭原则
Button符合开闭原则了,但是Dialer又不符合开闭原则了,因为Dialer要实现ButtonServer接口,根据参数token决定执行enterDigit方法还是dial方法,又需要if/else或者switch/case,不符合开闭原则。
那怎么办?
这种情况可以使用适配器模式进行设计。适配器模式是一种结构模式,用于将两个不匹配的接口适配起来,使其能够正常工作。
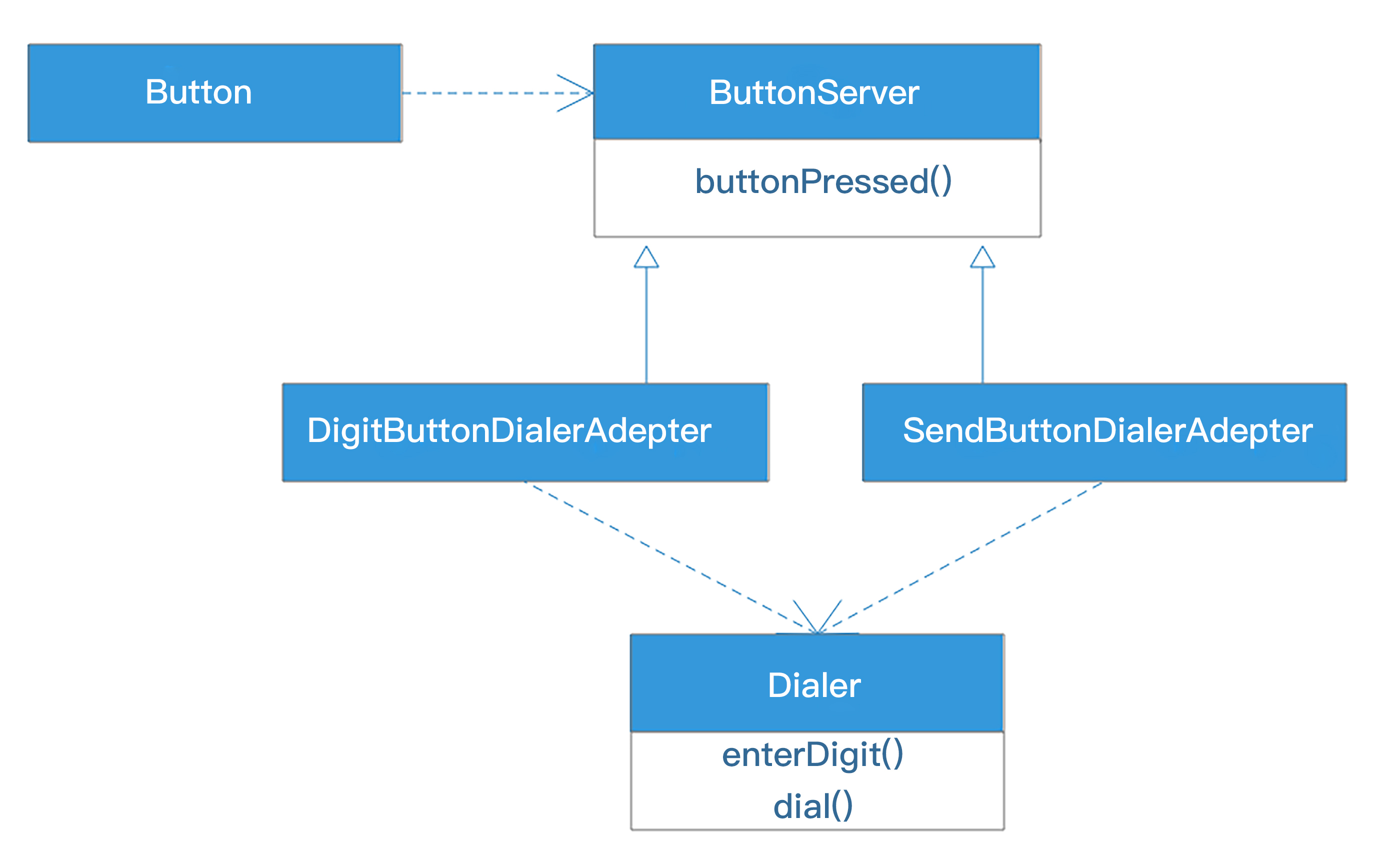
不要由Dialer类直接实现ButtonServer接口,而是增加两个适配器DigitButtonDialerAdapter、SendButtonDialerAdapter,由适配器实现ButtonServer接口,在适配器的buttonPressed方法中调用Dialer的enterDigit方法和dial方法,而Dialer类保持不变,Dialer类实现开闭原则。
在我们这个场景中,Button需要调用的接口是buttonPressed,和Dialer的方法不匹配,如何在不修改Dialer代码的前提下,使Button能够调用Dialer代码?就是靠适配器,适配器DigitButtonDialerAdapter和SendButtonDialerAdapter实现了ButtonServer接口,使Button能够调用自己,并在自己的buttonPressed方法中调用Dialer的方法,适配了Dialer。
使用观察者模式实现开闭原则
通过策略模式和适配器模式,我们使Button和Dialer都符合了开闭原则。但是如果要求能够用一个按钮控制多个设备,比如按钮按下进行拨号的同时,还需要扬声器根据不同按钮发出不同声音,将来还需要根据不同按钮点亮不同颜色的灯。按照当前设计,可能需要在适配器中调用多个设备,增加设备要修改适配器代码,又不符合开闭原则了。
怎么办?
这种情况可以用观察者模式进行设计:
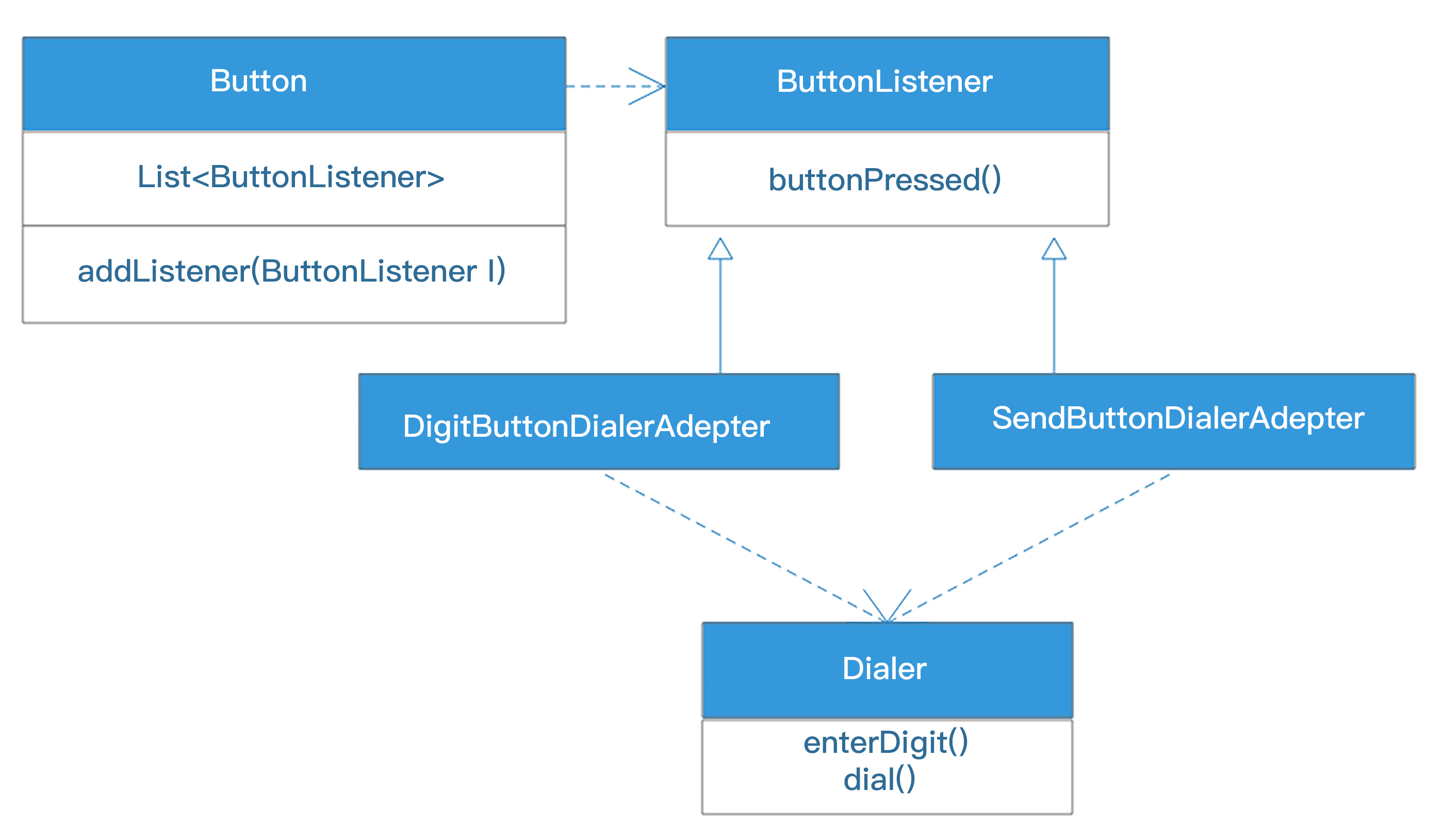
这里,ButtonServer被改名为ButtonListener,表示这是一个监听者接口,其实这个改名不重要,仅仅是为了便于识别。因为接口方法buttonPressed不变,ButtonListener和ButtonServer本质上是一样的。
重要的是在Button类里增加了成员变量List和成员方法addListener。通过addListener,我们可以添加多个需要观察按钮按下事件的监听者实现,当按钮需要控制新设备的时候,只需要将实现了ButtonListener的设备实现添加到Button的List列表就可以了。
Button代码:
csharp
public class Button {
private List<ButtonListener> listeners;
public Button() {
this.listeners = new LinkedList<ButtonListener>();
}
public void addListener(ButtonListener listener) {
assert listener != null;
listeners.add(listener);
}
public void press() {
for (ButtonListener listener : listeners) {
listener.buttonPressed();
}
}
}Dialer代码和原始设计一样,如果我们需要将Button和Dialer组合成一个电话,Phone代码如下:
csharp
public class Phone {
private Dialer dialer;
private Button[] digitButtons;
private Button sendButton;
public Phone() {
dialer = new Dialer();
digitButtons = new Button[10];
for (int i = 0; i < digitButtons.length; i++) {
digitButtons[i] = new Button();
final int digit = i;
digitButtons[i].addListener(new ButtonListener() {
public void buttonPressed() {
dialer.enterDigit(digit);
}
});
}
sendButton = new Button();
sendButton.addListener(new ButtonListener() {
public void buttonPressed() {
dialer.dial();
}
});
}
public static void main(String[] args) {
Phone phone = new Phone();
phone.digitButtons[9].press();
phone.digitButtons[1].press();
phone.digitButtons[1].press();
phone.sendButton.press();
}
}观察者模式是一种行为模式,解决一对多的对象依赖关系,将被观察者对象的行为通知到多个观察者,也就是监听者对象。
在我们这个场景中,Button是被观察者,目标设备拨号器、密码锁等是观察者。被观察者和观察者通过Listener接口解耦合,观察者(的适配器)通过调用被观察者的addListener方法将自己添加到观察列表,当观察行为发生时,被观察者会逐个遍历Listener List,通知观察者。
使用模板方法模式实现开闭原则
如果业务要求按下按钮的时候,除了控制设备,按钮本身还需要执行一些操作,完成一些成员变量的状态更改,不同按钮类型进行的操作和记录状态各不相同。按照当前设计可能又要在Button的press方法中增加switch/case了。
怎么办?
这种情况可以用模板方法模式进行设计:
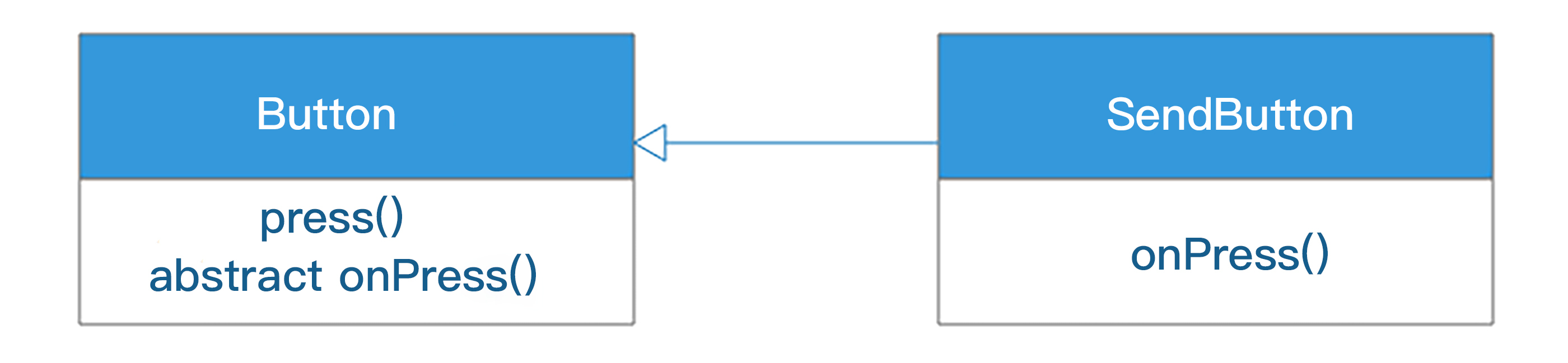
在Button类中定义抽象方法onPress,具体类型的按钮,比如SendButton实现这个方法。Button类中增加抽象方法onPress,并在press方法中调用onPress方法:
csharp
abstract void onPress();
public void press() {
onPress();
for (ButtonListener listener : listeners) {
listener.buttonPressed();
}
}所谓模板方法模式,就是在父类中用抽象方法定义计算的骨架和过程,而抽象方法的实现则留在子类中。
在我们这个例子中,press方法就是模板,press方法除了调用抽象方法onPress,还执行通知监听者列表的操作,这些抽象方法和具体操作共同构成了模板。而在子类SendButton中实现这个抽象方法,在这个方法中修改状态,完成自己类型特有的操作,这就是模板方法模式。
通过模板方法模式,每个子类可以定义自己在press执行时的状态操作,无需修改Button类,实现了开闭原则。
小结
实现开闭原则的关键是抽象。当一个模块依赖的是一个抽象接口的时候,就可以随意对这个抽象接口进行扩展,这个时候,不需要对现有代码进行任何修改,利用接口的多态性,通过增加一个新实现该接口的实现类,就能完成需求变更。不同场景进行扩展的方式是不同的,这时候就会产生不同的设计模式,大部分的设计模式都是用来解决扩展的灵活性问题的。
开闭原则可以说是软件设计原则的原则,是软件设计的核心原则,其他的设计原则更偏向技术性,具有技术性的指导意义,而开闭原则是方向性的,在软件设计的过程中,应该时刻以开闭原则指导、审视自己的设计:当需求变更的时候,现在的设计能否不修改代码就可以实现功能的扩展?如果不是,那么就应该进一步使用其他的设计原则和设计模式去重新设计。
更多的设计原则和设计模式,我将在后面陆续讲解。
思考题
我在观察者模式小节展示的Phone代码示例中,并没有显式定义DigitButtonDialerAdapter和SendButtonDialerAdapter这两个适配器类,但它们是存在的。在哪里呢?
12 软件设计的依赖倒置原则:如何不依赖代码却可以复用它的功能?
在软件开发过程中,我们经常会使用各种编程框架。如果你使用的是Java,那么你会比较熟悉Spring、MyBatis等。事实上,Tomcat、Jetty这类Web容器也可以归类为框架。框架的一个特点是,当开发者使用框架开发一个应用程序时,无需在程序中调用框架的代码,就可以使用框架的功能特性。比如程序不需要调用Spring的代码,就可以使用Spring的依赖注入,MVC这些特性,开发出低耦合、高内聚的应用代码。我们的程序更不需要调用Tomcat的代码,就可以监听HTTP协议端口,处理HTTP请求。
这些框架我们每天都在使用,已经司空见惯,所以觉得这种实现理所当然,但是我们停下好好想一想,难道不觉得这很神奇吗?我们自己也写代码,能够做到让其他工程师不调用我们的代码就可以使用我们的代码的功能特性吗?就我观察,大多数开发者是做不到的。那么Spring、Tomcat这些框架是如何做到的呢?
依赖倒置原则
我们看下Spring、Tomcat这些框架设计的核心关键点,也就是面向对象的基本设计原则之一:依赖倒置原则。
依赖倒置原则是这样的:
- 高层模块不应该依赖低层模块,二者都应该依赖抽象。
- 抽象不应该依赖具体实现,具体实现应该依赖抽象。
软件分层设计已经是软件开发者的共识。事实上,最早引入软件分层设计,正是为了建立清晰的软件分层关系,便于高层模块依赖低层模块。一般的应用程序中,策略层会依赖方法层,业务逻辑层会依赖数据存储层。这正是我们日常软件设计开发的常规方式。
那么这种高层模块依赖低层模块的分层依赖方式有什么缺点呢?
一是维护困难,高层模块通常是业务逻辑和策略模型,是一个软件的核心所在。正是高层模块使一个软件区别于其他软件,而低层模块则更多的是技术细节。如果高层模块依赖低层模块,那么就是业务逻辑依赖技术细节,技术细节的改变将影响到业务逻辑,使业务逻辑也不得不做出改变。因为技术细节的改变而影响业务代码的改变,这是不合理的。
二是复用困难,通常越是高层模块,复用的价值越高。但如果高层模块依赖低层模块,那么对高层模块的依赖将会导致对底层模块的连带依赖,使复用变得困难。
事实上,在我们软件开发中,很多地方都使用了依赖倒置原则。我们在Java开发中访问数据库,代码并不直接依赖数据库的驱动,而是依赖JDBC。各种数据库的驱动都实现了JDBC,当应用程序需要更换数据库的时候,不需要修改任何代码。这正是因为应用代码,高层模块,不依赖数据库驱动,而是依赖抽象JDBC,而数据库驱动,作为低层模块,也依赖JDBC。
同样的,Java开发的Web应用也不需要依赖Tomcat这样的Web容器,只需要依赖J2EE规范,Web应用实现J2EE规范的Servlet接口,然后把应用程序打包通过Web容器启动就可以处理HTTP请求了。这个Web容器可以是Tomcat,也可以是Jetty,任何实现了J2EE规范的Web容器都可以。同样,高层模块不依赖低层模块,大家都依赖J2EE规范。
其他我们熟悉的MVC框架,ORM框架,也都遵循依赖倒置原则。
依赖倒置的关键是接口所有权的倒置
下面,我们进一步了解下依赖倒置原则的设计原理,看看如何在我们的程序设计开发中也能利用依赖倒置原则,开发出更少依赖、更低耦合、更可复用的代码。
这是我们习惯上的层次依赖示例,策略层依赖方法层,方法层依赖工具层。
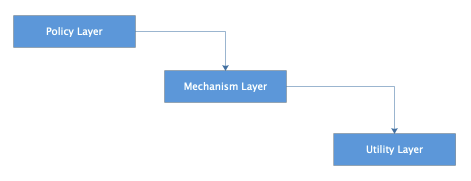
这样分层依赖的一个潜在问题是,策略层对方法层和工具层是传递依赖的,下面两层的任何改动都会导致策略层的改动,这种传递依赖导致的级联改动可能会导致软件维护过程非常糟糕。
解决办法是利用依赖倒置的设计原则,每个高层模块都为它所需要的服务声明一个抽象接口,而低层模块则实现这些抽象接口,高层模块通过抽象接口使用低层模块。
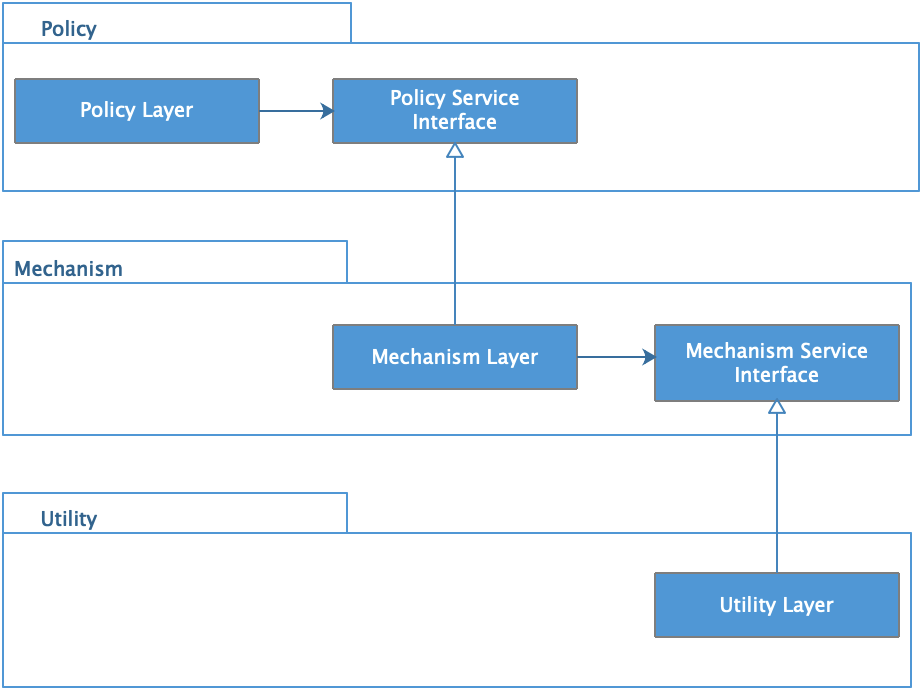
这样,高层模块就不需要直接依赖低层模块,而变成了低层模块依赖高层模块定义的抽象接口,从而实现了依赖倒置,解决了策略层、方法层、工具层的传递依赖问题。
我们日常的开发通常也要依赖抽象接口,而不是依赖具体实现。比如Web开发中,Service层依赖DAO层,并不是直接依赖DAO的具体实现,而是依赖DAO提供的抽象接口。那么这种依赖是否是依赖倒置呢?其实并不是,依赖倒置原则中,除了具体实现要依赖抽象,最重要的是,抽象是属于谁的抽象。
通常的编程习惯中,低层模块拥有自己的接口,高层模块依赖低层模块提供的接口,比如方法层有自己的接口,策略层依赖方法层的接口;DAO层定义自己的接口,Service层依赖DAO层定义的接口。
但是按照依赖倒置原则,接口的所有权是被倒置的,也就是说,接口被高层模块定义,高层模块拥有接口,低层模块实现接口。不是高层模块依赖底层模块的接口,而是低层模块依赖高层模块的接口,从而实现依赖关系的倒置。
在上面的依赖层次中,每一层的接口都被高层模块定义,由低层模块实现,高层模块完全不依赖低层模块,即使是低层模块的接口。这样,低层模块的改动不会影响高层模块,高层模块的复用也不会依赖低层模块。对于Service和DAO这个例子来说,就是Service定义接口,DAO实现接口,这样才符合依赖倒置原则。
使用依赖倒置实现高层模块复用
依赖倒置原则适用于一个类向另一个类发送消息的场景。我们再看一个例子。
Button按钮控制Lamp灯泡,按钮按下的时候,灯泡点亮或者关闭。按照常规的设计思路,我们可能会设计出如下的类图关系,Button类直接依赖Lamp类。
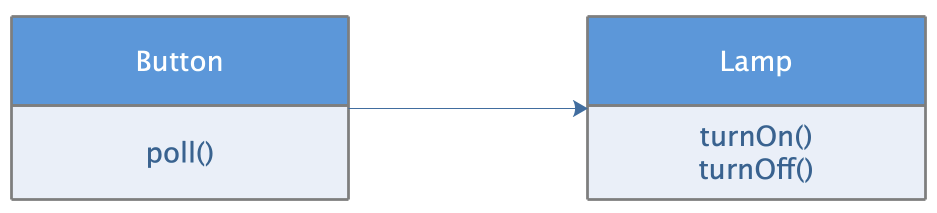
这样设计的问题在于,Button依赖Lamp,那么对Lamp的任何改动,都可能会使Button受到牵连,做出联动的改变。同时,我们也无法重用Button类,比如,我们期望通过Button控制一个电机的启动或者停止,这种设计显然难以重用Button,因为我们的Button还依赖着Lamp呢。
解决之道就是将这个设计中的依赖于实现,重构为依赖于抽象。这里的抽象就是:打开关闭目标对象。至于具体的实现细节,比如开关指令如何产生,目标对象是什么,都不重要。这是重构后的设计。
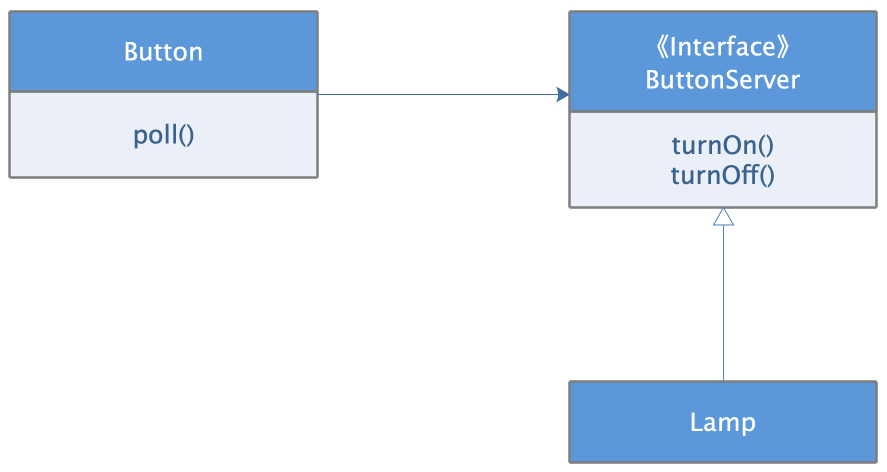
由Button定义一个抽象接口ButtonServer;在ButtonServer中描述抽象:打开、关闭目标对象。由具体的目标对象,比如Lamp实现这个接口,从而完成Button控制Lamp这一功能需求。
通过这样一种依赖倒置,Button不再依赖Lamp,而是依赖抽象ButtonServer,而Lamp也依赖ButtonServer,高层模块和低层模块都依赖抽象。Lamp的改动不会再影响Button,而Button 可以复用控制其他目标对象,比如电机,或者任何由按钮控制的设备,只要这些设备实现ButtonServer接口就可以了。
这里再强调一次,抽象接口ButtonServer的所有权是倒置的,它不属于底层模块Lamp,而是属于高层模块Button。我们从命名上也能看的出来,这正是依赖倒置原则的精髓所在。
这也正好回答了开头提出的问题:如何使其他工程师不调用我们的代码,就能使用我们代码的功能特性?如果我们是Button的开发者,那么只要其他工程师的代码实现了我们定义的ButtonServer接口,Button就可以调用他们开发的Lamp或者其他任何由按钮控制的设备,使设备代码拥有了按钮功能。设备的代码开发者不需要调用Button的代码,就拥有了Button的功能,而我们,也不需要关心Button会在什么样的设备代码中使用,所有实现ButtonServer的设备都可以使用Button功能。
所以依赖倒置原则也被称为好莱坞原则:Don't call me,I will call you. 即不要来调用我,我会调用你。Tomcat、Spring都是基于这一原则设计出来的,应用程序不需要调用Tomcat或者Spring这样的框架,而是框架调用应用程序。而实现这一特性的前提就是应用程序必须实现框架的接口规范,比如实现Servlet接口。
小结
依赖倒置原则通俗说就是,高层模块不依赖低层模块,而是都依赖抽象接口,这个抽象接口通常是由高层模块定义,低层模块实现。
遵循依赖倒置原则有这样几个编码守则:
- 应用代码中多使用抽象接口,尽量避免使用那些多变的具体实现类。
- 不要继承具体类,如果一个类在设计之初不是抽象类,那么尽量不要去继承它。对具体类的继承是一种强依赖关系,维护的时候难以改变。
- 不要重写(override)包含具体实现的函数。
依赖倒置原则最典型的使用场景就是框架的设计。框架提供框架核心功能,比如HTTP处理,MVC等,并提供一组接口规范,应用程序只需要遵循接口规范编程,就可以被框架调用。程序使用框架的功能,但是不调用框架的代码,而是实现框架的接口,被框架调用,从而框架有更高的可复用性,被应用于各种软件开发中。
我们的代码开发也可以按照依赖倒置原则,参考框架的设计理念,开发出灵活、低耦合、可复用的软件代码。
软件开发有时候像变魔术一样,常常表现出违反常识的特性,让人目眩神晕,而这正是软件编程这门艺术的魅力所在,感受到这种魅力,在自己的软件设计开发中体现出这种魅力,你就迈进了软件高手的大门。
思考题
除了文中的例子,还有哪些软件设计遵循了依赖倒置原则?这些软件中,底层模块和高层模块共同依赖的抽象是什么?
13 软件设计的里氏替换原则:正方形可以继承长方形吗?
我们都知道,面向对象编程语言有三大特性:封装、继承、多态。这几个特性也许可以很快就学会,但是如果想要用好,可能要花非常多的时间。
通俗地说,接口(抽象类)的多个实现就是多态。多态可以让程序在编程时面向接口进行编程,在运行期绑定具体类,从而使得类之间不需要直接耦合,就可以关联组合,构成一个更强大的整体对外服务。绝大多数设计模式其实都是利用多态的特性玩的把戏,前面两篇学习的开闭原则和依赖倒置原则也是利用多态的特性。正是多态使得编程有时候像变魔术,如果能用好多态,可以说掌握了大多数的面向对象编程技巧。
封装是面向对象语言提供的特性,将属性和方法封装在类里面。用好封装的关键是,知道应该将哪些属性和方法封装在某个类里。一个方法应该封装进A类里,还是B类里?这个问题其实就是如何进行对象的设计。深入研究进去,里面也有大量的学问。
继承似乎比多态和封装要简单一些,但实践中,继承的误用也很常见。
里氏替换原则
关于如何设计类的继承关系,怎样使继承不违反开闭原则,实际上有一个关于继承的设计原则,叫里氏替换原则。这个原则说:若对每个类型T1的对象o1,都存在一个类型T2的对象o2,使得在所有针对T2编写的程序P中,用o1替换o2后,程序P的行为功能不变,则T1是T2的子类型。
上面这句话比较学术,通俗地说就是:子类型必须能够替换掉它们的基类型。
再稍微详细点说,就是:程序中,所有使用基类的地方,都应该可以用子类代替。
语法上,任何类都可以被继承。但是一个继承是否合理,从继承关系本身是看不出来的,需要把继承放在应用场景的上下文中去判断,使用基类的地方,是否可以用子类代替?
这里有一个马的继承设计:
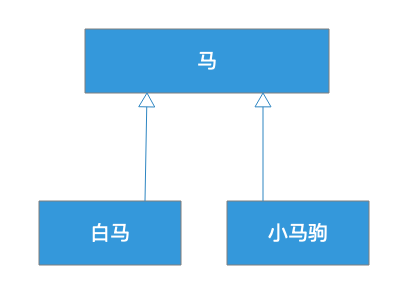
白马和小马驹都是马,所以都继承了马。这样的继承是不是合理呢?我们需要放到应用场景中:
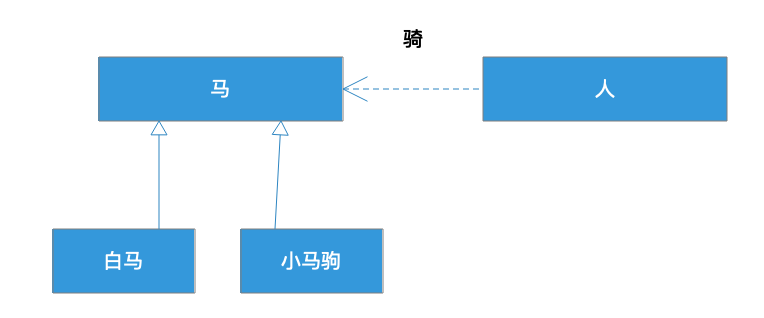
在这个场景中,是人骑马。根据这里的关系,继承了马的白马和小马驹,应该都可以代替马。白马代替马当然没有问题,人可以骑白马,但是小马驹代替马可能就不合适了,因为小马驹还没长好,无法被人骑。
那么很显然,作为子类的白马可以替换掉基类马,但是小马不能替换马,因此小马继承马就不太合适了,违反了里氏替换原则。
一个违反里氏替换规则的例子
我们再看这样一段代码:
java
void drawShape(Shape shape) {
if (shape.type == Shape.Circle ) {
drawCircle((Circle) shape);
} else if (shape.type == Shape.Square) {
drawSquare((Square) shape);
} else {
...
}
}这里Circle和Square继承了基类Shape,然后在应用的方法中,根据输入Shape对象类型进行判断,根据对象类型选择不同的绘图函数将图形画出来。这种写法的代码既常见又糟糕,它同时违反了开闭原则和里氏替换原则。
首先看到这样的if/else代码,就可以判断违反了开闭原则:当增加新的Shape类型的时候,必须修改这个方法,增加else if代码。
其次也因为同样的原因违反了里氏替换原则:当增加新的Shape类型的时候,如果没有修改这个方法,没有增加else if代码,那么这个新类型就无法替换基类Shape。
要解决这个问题其实也很简单,只需要在基类Shape中定义draw方法,所有Shape的子类,Circle、Square都实现这个方法就可以了:
java
public abstract Shape{
public abstract void draw();
}上面那段drawShape()代码也就可以变得更简单:
java
void drawShape(Shape shape) {
shape.draw();
}这段代码既满足开闭原则:增加新的类型不需要修改任何代码。也满足里氏替换原则:在使用基类的这个方法中,可以用子类替换,程序正常运行。
正方形可以继承长方形吗?
一个继承设计是否违反里氏替换原则,需要在具体场景中考察。我们再看一个例子,假设我们现在有一个长方形的类,类定义如下:
java
public class Rectangle {
private double width;
private double height;
public void setWidth(double w) { width = w; }
public void setHeight(double h) { height = h; }
public double getWidth() { return width; }
public double getHeight() { return height; }
public double calculateArea() {return width * height;}
}这个类满足我们的应用场景,在程序中多个地方被使用,一切良好。但是现在,我们有个新需求,我们还需要一个正方形。
通常,我们判断一个继承是否合理,会使用"IS A"进行判断,类B可以继承类A,我们就说类B IS A 类A,比如白马IS A 马,轿车 IS A 车。
那正方形是不是IS A长方形呢?通常我们会说,正方形是一种特殊的长方形,是长和宽相等的长方形,从这个角度讲,那么正方形IS A长方形,也就是可以继承长方形。
具体实现上,我们只需要在设置长方形的长或宽的时候,同时设置长和宽就可以了,如下:
java
public class Square extends Rectangle {
public void setWidth(double w) {
width = height = w;
}
public void setHeight(double h) {
height = width = w;
}
}这个正方形类设计看起来很正常,用起来似乎也没有问题。但是,真的没有问题吗?
继承是否合理我们需要用里氏替换原则来判断。之前也说过,是否合理并不是从继承的设计本身看,而是从应用场景的角度看。如果在应用场景中,也就是在程序中,子类可以替换父类,那么继承就是合理的,如果不能替换,那么继承就是不合理的。
这个长方形的使用场景是什么样的呢,我们看使用代码:
java
void testArea(Rectangle rect) {
rect.setWidth(3);
rect.setHeight(4);
assert 12 == rect.calculateArea();
}显然,在这个场景中,如果用子类Square替换父类Rectangle,计算面积calculateArea将返回16,而不是12,程序是不能正确运行的,这样的继承不满足里氏替换原则,是不合适的继承。
子类不能比父类更严格
类的公有方法其实是对使用者的一个契约,使用者按照这个契约使用类,并期望类按照契约运行,返回合理的值。
当子类继承父类的时候,根据里氏替换原则,使用者可以在使用父类的地方使用子类替换,那么从契约的角度,子类的契约就不能比父类更严格,否则使用者在用子类替换父类的时候,就会因为更严格的契约而失败。
在上面这个例子中,正方形继承了长方形,但是正方形有比长方形更严格的契约,即正方形要求长和宽是一样的。因为正方形有比长方形更严格的契约,那么在使用长方形的地方,正方形因为更严格的契约而无法替换长方形。
我们开头小马继承马的例子也是如此,小马比马有更严格的要求,即不能骑,那么小马继承马就是不合适的。
在类的继承中,如果父类方法的访问控制是protected,那么子类override这个方法的时候,可以改成是public,但是不能改成private。因为private的访问控制比protected更严格,能使用父类protected方法的地方,不能用子类的private方法替换,否则就是违反里氏替换原则的。相反,如果子类方法的访问控制改成public就没问题,即子类可以有比父类更宽松的契约。同样,子类override父类方法的时候,不能将父类的public方法改成protected,否则会出现编译错误。
通常说来,子类比父类的契约更严格,都是违反里氏替换原则的。
子类不应该比父类更严格,这个原则看起来既合理又简单,但是在实际中,如果你不严谨地审视自己的设计,是很可能违背里氏替换原则的。
在JDK中,类Properties继承自类Hashtable,类Stack继承自Vector。
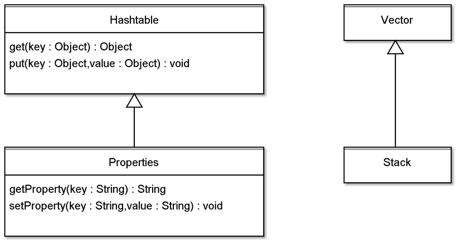
这样的设计,其实是违反里氏替换原则的。Properties要求处理的数据类型是String,而它的父类Hashtable要求处理的数据类型是Object,子类比父类的契约更严格;Stack是一个栈数据结构,数据只能后进先出,而它的父类Vector是一个线性表,子类比父类的契约更严格。
这两个类都是从JDK1就已经存在的,我想,如果能够重新再来,JDK的工程师一定不会这样设计。这也从另一个方面说明,不恰当的继承是很容易就发生的,设计继承的时候,需要更严谨的审视。
小结
实践中,当你继承一个父类仅仅是为了复用父类中的方法的时候,那么很有可能你离错误的继承已经不远了。一个类如果不是为了被继承而设计,那么最好就不要继承它。粗暴一点地说,如果不是抽象类或者接口,最好不要继承它。
如果你确实需要使用一个类的方法,最好的办法是组合这个类而不是继承这个类,这就是人们通常说的组合优于继承。比如这样:
java
Class A {
public Element query(int id){...}
public void modify(Element e){...}
}
Class B {
private A a;
public Element select(int id){
a.query(id);
}
public void modify(Element e){
a.modify(e);
}
}如果类B需要使用类A的方法,这时候不要去继承类A,而是去组合类A,也能达到使用类A方法的效果。这其实就是对象适配器模式了,使用这个模式的话,类B不需要继承类A,一样可以拥有类A的方法,同时还有更大的灵活性,比如可以改变方法的名称以适应应用接口的需要。
当然,继承接口或者抽象类也并不保证你的继承设计就是正确的,最好的方法还是用里氏替换原则检查一下你的设计:使用父类的地方是不是可以用子类替换?
违反里氏替换原则不仅仅发生在设计继承的地方,也可能发生在使用父类和子类的地方,错误的使用方法,也可能导致程序违反里氏替换原则,使子类无法替换父类。
思考题
下面给你留一道思考题吧。
父类中有抽象方法f,抛出异常AException:
java
public abstract void f() throws AException;子类override父类这个方法后,想要将抛出的异常改为BException,那么BException应该是AException的父类还是子类?
14 软件设计的单一职责原则:为什么说一个类文件打开最好不要超过一屏?
我在Intel工作期间,曾经接手过一个大数据SQL引擎的开发工作(如何自己开发一个大数据SQL引擎?)。我接手的时候,这个项目已经完成了早期的技术验证和架构设计,能够处理较为简单的标准SQL语句。后续公司打算成立一个专门的小组,开发支持完整的标准SQL语法的大数据引擎,然后进一步将这个产品商业化。
我接手后打开项目一看,吓出一身冷汗,这个项目只有几个类组成,其中最大的一个类,负责SQL语法的处理,有近万行代码。代码中充斥着大量的switch/case,if/else代码,而且方法之间互相调用,各种全局变量传递。
只有输入测试SQL语句的时候,在debug状态下才能理解每一行代码的意思。而这样的代码有1万行,现在只实现了不到10%的SQL语法特性。如果将SQL的全部语法特性都实现了,那么这个类该有多么大!逻辑有多么复杂!维护有多么困难!而且还要准备一个团队来合作开发!想想看,几个人在这样一个大文件里提交代码,想想都酸爽。
这是当时这个SQL语法处理类中的一个方法,而这样的方法有上百个。
java
/**
* Digest all Not Op and merge into subq or normal filter semantics
* After this process there should not be any NOT FB in the FB tree.
*/
private void digestNotOp(FilterBlockBase fb, FBPrepContext ctx) {
// recursively digest the not op in a top down manner
if (fb.getType() == FilterBlockBase.Type.LOGIC_NOT) {
FilterBlockBase child = fb.getOnlyChild();
FilterBlockBase newOp = null;
switch (child.getType()) {
case LOGIC_AND:
case LOGIC_OR: {
// not (a and b) -> (not a) or (not b)
newOp = (child.getType() == Type.LOGIC_AND) ? new OpORFilterBlock()
: new OpANDFilterBlock();
FilterBlockBase lhsNot = new OpNOTFilterBlock();
FilterBlockBase rhsNot = new OpNOTFilterBlock();
lhsNot.setOnlyChild(child.getLeftChild());
rhsNot.setOnlyChild(child.getRightChild());
newOp.setLeftChild(lhsNot);
newOp.setRightChild(rhsNot);
break;
}
case LOGIC_NOT:
newOp = child.getOnlyChild();
break;
case SUBQ: {
switch (((SubQFilterBlock) child).getOpType()) {
case ALL: {
((SubQFilterBlock) child).setOpType(OPType.SOMEANY);
SqlASTNode op = ((SubQFilterBlock) child).getOp();
// Note: here we directly change the original SqlASTNode
revertRelationalOp(op);
break;
}
case SOMEANY: {
((SubQFilterBlock) child).setOpType(OPType.ALL);
SqlASTNode op = ((SubQFilterBlock) child).getOp();
// Note: here we directly change the original SqlASTNode
revertRelationalOp(op);
break;
}
case RELATIONAL: {
SqlASTNode op = ((SubQFilterBlock) child).getOp();
// Note: here we directly change the original SqlASTNode
revertRelationalOp(op);
break;
}
case EXISTS:
((SubQFilterBlock) child).setOpType(OPType.NOTEXISTS);
break;
case NOTEXISTS:
((SubQFilterBlock) child).setOpType(OPType.EXISTS);
break;
case IN:
((SubQFilterBlock) child).setOpType(OPType.NOTIN);
break;
case NOTIN:
((SubQFilterBlock) child).setOpType(OPType.IN);
break;
case ISNULL:
((SubQFilterBlock) child).setOpType(OPType.ISNOTNULL);
break;
case ISNOTNULL:
((SubQFilterBlock) child).setOpType(OPType.ISNULL);
break;
default:
// should not come here
assert (false);
}
newOp = child;
break;
}
case NORMAL:
// we know all normal filters are either UnCorrelated or
// correlated, don't have both case at present
NormalFilterBlock nf = (NormalFilterBlock) child;
assert (nf.getCorrelatedFilter() == null || nf.getUnCorrelatedFilter() == null);
CorrelatedFilter cf = nf.getCorrelatedFilter();
UnCorrelatedFilter ucf = nf.getUnCorrelatedFilter();
// It's not likely to result in chaining SqlASTNode
// as any chaining NOT FB has been collapsed from top down
if (cf != null) {
cf.setRawFilterExpr(
SqlXlateUtil.revertFilter(cf.getRawFilterExpr(), false));
}
if (ucf != null) {
ucf.setRawFilterExpr(
SqlXlateUtil.revertFilter(ucf.getRawFilterExpr(), false));
}
newOp = child;
break;
default:
}
fb.getParent().replaceChildTree(fb, newOp);
}
if (fb.hasLeftChild()) {
digestNotOp(fb.getLeftChild(), ctx);
}
if (fb.hasRightChild()) {
digestNotOp(fb.getRightChild(), ctx);
}
}我当时就觉得,我太难了。
单一职责原则
软件设计有两个基本准则:低耦合和高内聚。我在前面讲到过的设计原则和后面将要讲的设计模式大多数都是关于如何进行低耦合设计的。而内聚性主要研究组成一个模块或者类的内部元素的功能相关性。
设计类的时候,我们应该把强相关的元素放在一个类里,而弱相关性的元素放在类的外边。保持类的高内聚性。具体设计时应该遵循这样一个设计原则:
一个类,应该只有一个引起它变化的原因。
这就是软件设计的单一职责原则。如果一个类承担的职责太多,就等于把这些职责都耦合在一起。这种耦合会导致类很脆弱:当变化发生的时候,会引起类不必要的修改,进而导致bug出现。
职责太多,还会导致类的代码太多。一个类太大,它就很难保证满足开闭原则,如果不得不打开类文件进行修改,大堆大堆的代码呈现在屏幕上,一不小心就会引出不必要的错误。
所以关于编程有这样一个最佳实践:一个类文件打开后,最好不要超过屏幕的一屏。这样做的好处是,一方面代码少,职责单一,可以更容易地进行复用和扩展,更符合开闭原则。另一方面,阅读简单,维护方便。
一个违反单一职责原则的例子
如何判断一个类的职责是否单一,就是看这个类是否只有一个引起它变化的原因。
我们看这样一个设计:
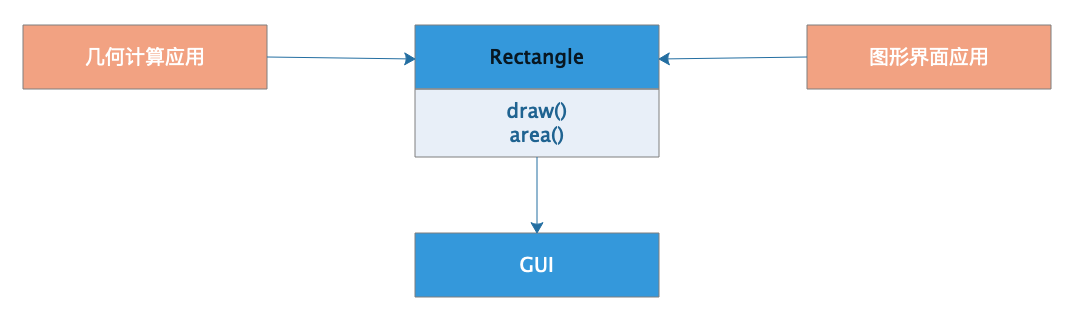
正方形类Rectangle有两个方法,一个是绘图方法draw(),一个是计算面积方法area()。有两个应用需要依赖这个Rectangle类,一个是几何计算应用,一个是图形界面应用。
绘图的时候,程序需要计算面积,但是计算面积的时候呢,程序又不需要绘图。而在计算机屏幕上绘图又是一件非常麻烦的事情,所以需要依赖一个专门的GUI组件包。
这样就会出现一个尴尬的情形:当我需要开发一个几何计算应用程序的时候,我需要依赖Rectangle类,而Rectangle类又依赖了GUI包,一个GUI包可能有几十M甚至数百M。本来几何计算程序作为一个纯科学计算程序,主要是一些数学计算代码,现在程序打包完,却不得不把一个不相关的GUI包也打包进来。本来程序包可能只有几百K,现在变成了几百M。
Rectangle类的设计就违反了单一职责原则。Rectangle承担了两个职责,一个是几何形状的计算,一个是在屏幕上绘制图形。也就是说,Rectangle类有两个引起它变化的原因,这种不必要的耦合不仅会导致科学计算应用程序庞大,而且当图形界面应用程序不得不修改Rectangle类的时候,还得重新编译几何计算应用程序。
比较好的设计是将这两个职责分离开来,将Rectangle类拆分成两个类:
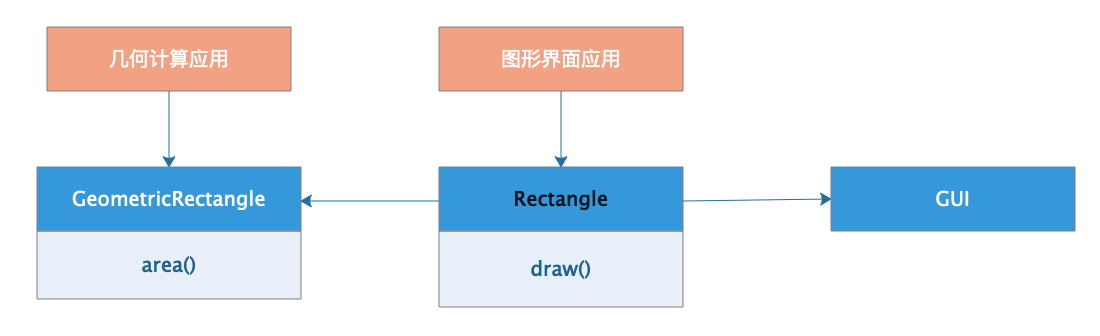
将几何面积计算方法拆分到一个独立的类GeometricRectangle,这个类负责图形面积计算area()。Rectangle只保留单一绘图职责draw(),现在绘制长方形的时候可以使用计算面积的方法,而几何计算应用程序则不需要依赖一个不相关的绘图方法以及一大堆的GUI组件。
从Web应用架构演进看单一职责原则
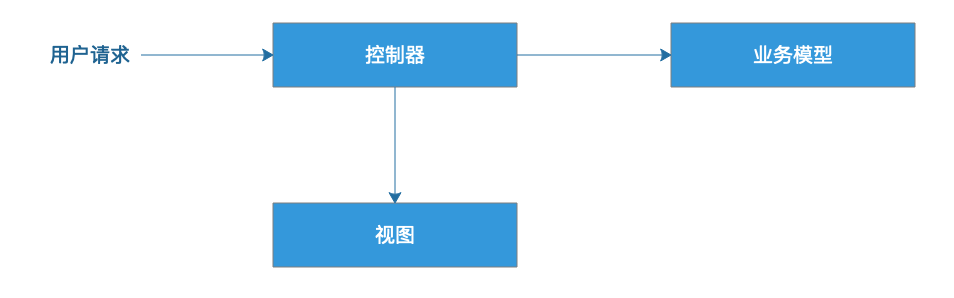
事实上,Web应用技术的发展、演化过程,也是一个不断进行职责分离,实现单一职责原则的过程。在十几年前,互联网应用早期的时候,业务简单,技术落后,通常是一个类负责处理一个请求处理。
以Java为例,就是一个Servlet完成一个请求处理。

这种技术方案有一个比较大的问题是,请求处理以及响应的全部操作都在Servlet里,Servlet获取请求数据,进行逻辑处理,访问数据库,得到处理结果,根据处理结果构造返回的HTML。这些职责全部都在一个类里完成,特别是输出HTML,需要在Servlet中一行一行输出HTML字符串,类似这样:
java
response.getWriter().println("<html> <head> <title>servlet程序</title> </head>");这就比较痛苦了,一个HMTL文件可能会很大,在代码中一点一点拼字符串,编程困难、维护困难,总之就是各种困难。
于是后来就有了JSP,如果说Servlet是在程序中输出HTML,那么JSP就是在HTML调用程序。使用JSP开发Web程序大概是这样的:

用户请求提交给JSP,而JSP会依赖业务模型进行逻辑处理,并将模型的处理结果包装在HTML里面,构造成一个动态页面返回给用户。
使用JSP技术比Servlet更容易开发一点,至少不用再痛苦地进行HTML字符串拼接了,通常基于JSP开发的Web程序在职责上也会进行了一些最基本的分离:构造页面的JSP和处理逻辑的业务模型分离。但是这种分离藕断丝连,JSP中依然存在大量的业务逻辑代码,代码和HTML标签耦合在一起,职责分离得并不彻底。
真正将视图和模型分离的是后来出现的各种MVC框架,MVC框架通过控制器将视图与模型彻底分离。视图中只包含HTML标签和模板引擎的占位符,业务模型则专门负责进行业务处理。正是这种分离,使得前后端开发成为两个不同的工种,前端工程师只做视图模板开发,后端工程师只做业务开发,彼此之间没有直接的依赖和耦合,各自独立开发、维护自己的代码。
有了MVC,就可以顺理成章地将复杂的业务模型进行分层了。通过分层方式,将业务模型分为业务层、服务层、数据持久层,使各层职责进一步分离,更符合单一职责原则。
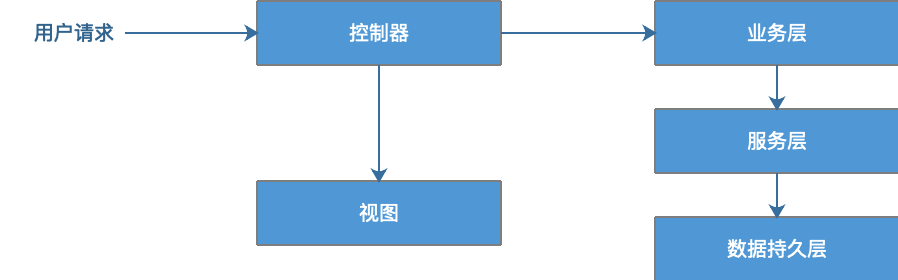
小结
让我们回到文章的标题,类的职责应该是单一的,也就是引起类变化的原因应该只有一个,这样类的代码通常也是比较少的。在开发实践中,一个类文件在IDE打开,最好不要超过一屏。
文章开头那个大数据SQL引擎的例子中,SQL语法处理类的主要问题是,太多功能职责被放在一个类里了。我在研读了原型代码,并和开发原型的同事讨论后,把这个类的职责从两个维度进行切分。一个维度是处理过程,整个处理过程可以分为语法定义、语法变形和语法生成这三个环节,每个SQL语句都需要依赖这三个环节。此外,我在第一个模块的第6篇文章中讲到,每个SQL语句在处理的时候都要生成一个SQL语法树,而树是由很多节点组成的。从这个角度讲,每个语法树节点都应该由一个单一职责的类处理。
我从这两个维度将原来有着近万行代码的类进行职责拆分,拆分出几百个类,每个类的职责都比较单一,只负责一个语法树节点的一个处理过程。很多小的类只有几行代码,打开后只占IDE中一小部分,在显示器上一目了然,阅读、维护都很轻松。类之间没有耦合,而是在运行期,根据SQL语法树将将这些代表语法节点的类构造成一颗树,然后用设计模式中的组合模式进行遍历即可。
后续参与进来开发的同事,只需要针对还不支持的SQL语法功能点,开发相对应的语法转换器Transformer和语法树生成器Generator就可以了,不需要对原来的类再进行修改,甚至不需要调用原来的类。程序运行期,在语法处理的时候遇到对应的语法节点,交给相关的类处理就好了。
重构后虽然类的数量扩展了几百倍,但是代码总行数却少了很多,这是重构后的部分代码截图:
思考题
你在软件开发中有哪些可以用单一职责原则改进的设计呢?
15 软件设计的接口隔离原则:如何对类的调用者隐藏类的公有方法?
我在阿里巴巴工作期间,曾经负责开发一个统一缓存服务。这个服务要求能够根据远程配置中心的配置信息,在运行期动态更改缓存的配置,可能是将本地缓存更改为远程缓存,也可能是更改远程缓存服务器集群的IP地址列表,进而改变应用程序使用的缓存服务。
这就要求缓存服务的客户端SDK必须支持运行期配置更新,而配置更新又会直接影响缓存数据的操作,于是就设计出这样一个缓存服务Client类。

这个缓存服务Client类的方法主要包含两个部分:一部分是缓存服务方法,get()、put()、delete()这些,这些方法是面向调用者的;另一部分是配置更新方法reBuild(),这个方法主要是给远程配置中心调用的。
但是问题是,Cache类的调用者如果看到reBuild()方法,并错误地调用了该方法,就可能导致Cache连接被错误重置,导致无法正常使用Cache服务。所以必须要将reBuild()方法向缓存服务的调用者隐藏,而只对远程配置中心的本地代理开放这个方法。
但是reBuild()方法是一个public方法,如何对类的调用者隐藏类的公有方法?
接口隔离原则
我们可以使用接口隔离原则解决这个问题。接口隔离原则说:不应该强迫用户依赖他们不需要的方法。
那么如果强迫用户依赖他们不需要的方法,会导致什么后果呢?
一来,用户可以看到这些他们不需要,也不理解的方法,这样无疑会增加他们使用的难度,如果错误地调用了这些方法,就会产生bug。二来,当这些方法如果因为某种原因需要更改的时候,虽然不需要但是依赖这些方法的用户程序也必须做出更改,这是一种不必要的耦合。
但是如果一个类的几个方法之间本来就是互相关联的,就像我开头举的那个缓存Client SDK的例子,reBuild()方法必须要在Cache类里,这种情况下, 如何做到不强迫用户依赖他们不需要的方法呢?
我们先看一个简单的例子,Modem类定义了4个主要方法,拨号dail(),挂断hangup(),发送send()和接受recv()。这四个方法互相存在关联,需要定义在一个类里。
java
class Modem {
void dial(String pno);
void hangup();
void send(char c);
void recv();
}但是对调用者而言,某些方法可能完全不需要,也不应该看到。比如拨号dail()和挂断hangup(),这两个方式是属于专门的网络连接程序的,通过网络连接程序进行拨号上网或者挂断网络。而一般的使用网络的程序,比如网络游戏或者上网浏览器,只需要调用send()和recv()发送和接收数据就可以了。
强迫只需要上网的程序依赖他们不需要的拨号与挂断方法,只会导致不必要的耦合,带来潜在的系统异常。比如在上网浏览器中不小心调用hangup()方法,就会导致整个机器断网,其他程序都不能连接网络。这显然不是系统想要的。
这种问题的解决方法就是通过接口进行方法隔离,Modem类实现两个接口,DataChannel接口和Connection接口。
DataChannel接口对外暴露send()和recv()方法,这个接口只负责网络数据的发送和接收,网络游戏或者网络浏览器只依赖这个接口进行网络数据传输。这些应用程序不需要依赖它们不需要的dail()和hangup()方法,对应用开发者更加友好,也不会导致因错误的调用而引发的程序bug。
而网络管理程序则可以依赖Connection接口,提供显式的UI让用户拨号上网或者挂断网络,进行网络连接管理。
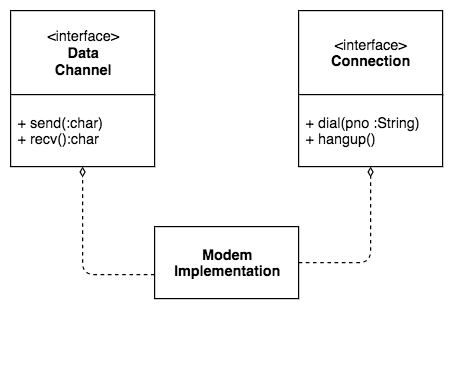
通过使用接口隔离原则,我们可以将一个实现类的不同方法包装在不同的接口中对外暴露。应用程序只需要依赖它们需要的方法,而不会看到不需要的方法。
一个使用接口隔离原则优化的例子
我们再看一个使用接口隔离原则优化设计的例子。假设我们有个门Door对象,这个Door对象可以锁上,可以解锁,还可以判断门是否打开。
java
class Door {
void lock();
void unlock();
boolean isDoorOpen();
}现在我们需要一个TimedDoor,一个有定时功能的门,如果门开着的时间超过预定时间,就会自动锁门。
我们已经有一个类Timer,和一个接口TimerClient:
java
class Timer {
void register(int timeout, TimerClient client);
}
interface TimerClient {
void timeout();
}TimerClient可以向Timer注册,调用register()方法,设置超时时间。当超时时间到,就会调用TimerClient的timeout()方法。
那么,我们如何利用现有的Timer和TimerClient将Door改造成一个具有超时自动锁门的TimedDoor?
比较容易,且直观的办法就是,修改Door类,Door实现TimerClient接口,这样Door就有了timeout()方法,直接将Door注册给Timer,当超时的时候,Timer调用Door的timeout()方法,在Door的timeout()方法里调用lock()方法,就可以实现超时自动锁门的操作。
java
class Door implements TimerClient {
void lock();
void unlock();
boolean isDoorOpen();
void timeout(){
lock();
}
}这个方法简单直接,也能实现需求,但是问题在于使Door多了一个timeout()方法。如果这个Door类想要复用到其他地方,那么所有使用Door的程序都不得不依赖一个它们可能根本用不着的方法。同时,Door的职责也变得复杂,违反了单一职责原则,维护会变得更加困难。这样的设计显然是有问题的。
要想解决这些问题,就应该遵循接口隔离原则。事实上,这里有两个互相独立的接口,一个接口是TimerClient,用来供Timer进行超时控制;一个接口是Door,用来控制门的操作。虽然超时锁门的操作是一个完整的动作,但是我们依然可以使用接口使其隔离。
一种方法是通过委托进行接口隔离,具体方式就是增加一个适配器DoorTimerAdapter,这个适配器继承TimerClient接口实现timeout()方法,并将自己注册给Timer。适配器在自己的timeout()方法中,调用Door的方法实现超时锁门的操作。
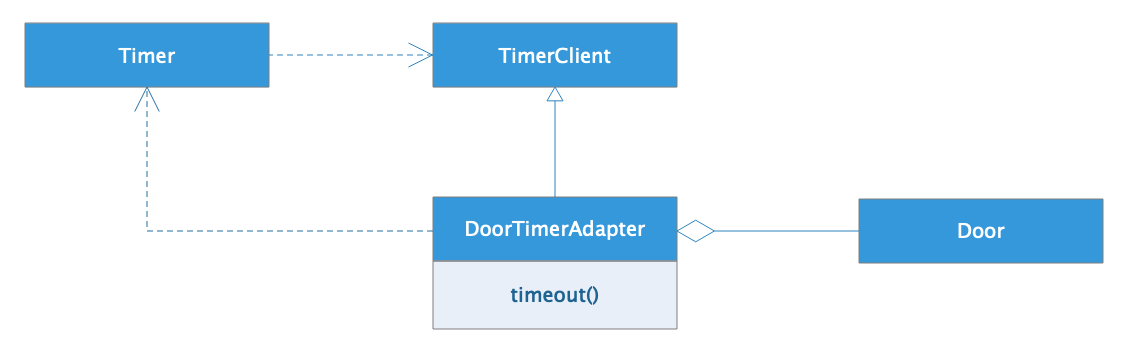
这种场合使用的适配器可能会比较重,业务逻辑比较多,如果超时的时候需要执行较多的逻辑操作,那么适配器的timeout()方法就会包含很多业务逻辑,超出了适配器的职责范围。而如果这些逻辑操作还需要使用Door的内部状态,可能还需要迫使Door做出一些修改。
接口隔离更典型的做法是使用多重继承,跟前面Modem的例子一样,TimedDoor同时实现TimerClient接口和继承Door类,在TimedDoor中实现timeout()方法,并注册到Timer定时器中。
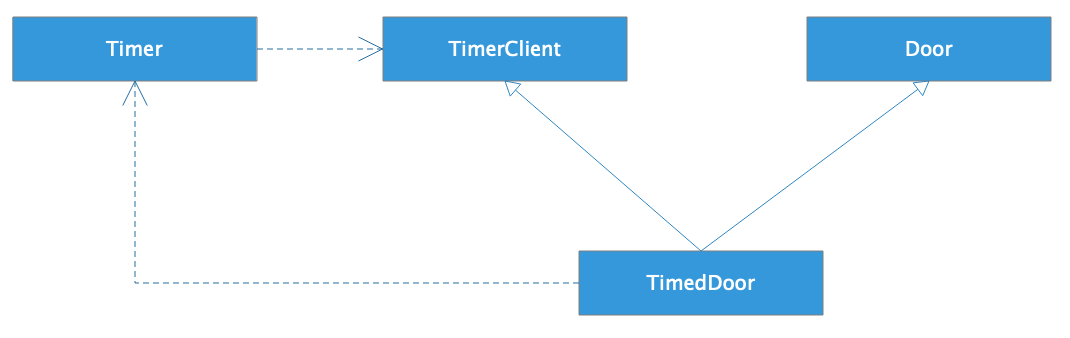
这样,使用Door的程序就不需要被迫依赖timeout()方法,Timer也不会看到Door的方法,程序更加整洁,易于复用。
接口隔离原则在迭代器设计模式中的应用
Java的数据结构容器类可以通过for循环直接进行遍历,比如:
java
List<String> ls = new ArrayList<String>();
ls.add("a");
ls.add("b");
for(String s: ls) {
System.out.println(s);
}事实上,这种for语法结构并不是标准的Java for语法,标准的for语法在实现上述遍历时应该是这样的:
java
for(Iterator<String> itr=ls.iterator();itr.hasNext();) {
System.out.println(itr.next());
}之所以可以写成上面那种简单的形式,就是因为Java提供的语法糖。Java5以后版本对所有实现了Iterable接口的类都可以使用这种简化的for循环进行遍历。而我们上面例子的ArrayList也实现了这个接口。
Iterable接口定义如下,主要就是构造Iterator迭代器。
java
public interface Iterable<T> {
Iterator<T> iterator();
}在Java5以前,每种容器的遍历方法都不相同,在Java5以后,可以统一使用这种简化的遍历语法实现对容器的遍历。而实现这一特性,主要就在于Java5通过Iterable接口,将容器的遍历访问从容器的其他操作中隔离出来,使Java可以针对这个接口进行优化,提供更加便利、简洁、统一的语法。
小结
我们再回到开头那个例子,如何让缓存类的使用者看不到缓存重构的方法,以避免不必要的依赖和方法的误用。答案就是使用接口隔离原则,通过多重继承的方式进行接口隔离。
Cache实现类BazaCache(Baza是当时开发的统一缓存服务的产品名)同时实现Cache接口和CacheManageable接口,其中Cache接口提供标准的Cache服务方法,应用程序只需要依赖该接口。而CacheManageable接口则对外暴露reBuild()方法,使远程配置服务可以通过自己的本地代理调用这个方法,在运行期远程调整缓存服务的配置,使系统无需重新部署就可以热更新。
最后的缓存服务SDK核心类设计如下:
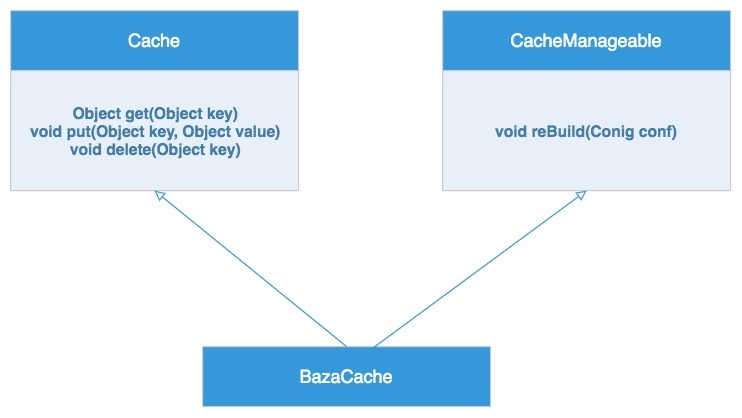
当一个类比较大的时候,如果该类的不同调用者被迫依赖类的所有方法,就可能产生不必要的耦合。对这个类的改动也可能会影响到它的不同调用者,引起误用,导致对象被破坏,引发bug。
使用接口隔离原则,就是定义多个接口,不同调用者依赖不同的接口,只看到自己需要的方法。而实现类则实现这些接口,通过多个接口将类内部不同的方法隔离开来。
思考题
在你的开发实践中,你看到过哪些地方使用了接口隔离原则?你自己开发的代码,哪些地方可以用接口隔离原则优化?
16 设计模式基础:不会灵活应用设计模式,你就没有掌握面向对象编程
我在面试的时候,喜欢问一个问题:"你比较熟悉哪些设计模式?"得到的回答很多时候是"单例"和"工厂"。老实说,这个回答不能让人满意。因为在我看来,单例和工厂固然是两种经典的设计模式,但是,这些创建类的设计模式并不能代表设计模式的精髓。
设计模式的精髓在于对面向对象编程特性之一------多态的灵活应用,而多态正是面向对象编程的本质所在。
面向对象编程的本质是多态
我在面试时,有时候会问"什么是对象",得到的回答各种各样:"对象是数据与方法的组合。""对象是领域的抽象。""一切都是对象。""对象的特性就是封装、继承、多态。"
这是一个比较开放的问题,这些回答可以说都是对的,都描述了对象的某个方面。那么,面向对象的本质是什么?面向对象编程和此前的面向过程编程的核心区别是什么?
我们常说,面向对象编程的主要特性是封装、继承和多态。那么这三个特性是否是面向对象编程区别于其他编程技术的关键呢?
我们先看封装,面向对象编程语言都提供了类的定义。通过类,我们可以将类的成员变量和成员方法封装起来,还可以通过访问控制符,private、protected、public控制成员变量和成员方法的可见性。
面向对象设计最基本的设计粒度就是类。类通过封装数据和方法,构成一个相对独立的实体。类之间通过访问控制的约束互相调用,这样就完成了面向对象的编程。但是,封装并不是面向对象编程语言独有的。面向过程的编程语言,比如C语言,也可以实现封装特性,在头文件.h里面定义方法,而在实现文件.c文件里定义具体的结构体和方法实现,从而使依赖.h头文件的外部程序只能够访问头文件里定义过的方法,这样同样实现了变量和函数的封装,以及访问权限的控制。
继承似乎是面向对象编程语言才有的特性,事实上,C语言也可以实现继承。如果A结构体包含B结构体的定义,那么就可以理解成A继承了B,定义在B结构上的方法可以直接(通过强制类型转换)执行A结构体的数据。
作为一种编程技巧,这种通过定义结构体从而实现继承特性的方法,在面向对象编程语言出现以前就已经经常被开发者使用了。
我们再来看多态,因为有指向函数的指针,多态事实上在C语言中也可以实现。但是使用指向函数的指针实现多态是非常危险的,因为这种多态没有语法和编译方面的约束,只能靠程序员之间约定,一旦出现bug,调试非常痛苦。因此在面向过程语言的开发中,这种多态并不能频繁使用。
而在面向对象的编程语言中,多态非常简单:子类实现父类或者接口的抽象方法,程序使用抽象父类或者接口编程,运行期注入不同的子类,程序就表现出不同的形态,是为多态。
这样做最大的好处就是软件编程时的实现无关性,程序针对接口和抽象类编程,而不需要关心具体实现是什么。你应该还记得我在第10篇中讲到的案例:对于一个从输入设备拷贝字符到输出设备的程序,如果具体的设备实现和拷贝程序是耦合在一起的,那么当我们想要增加任何输入设备或者输出设备的时候,都必须要修改程序代码,最后这个拷贝程序将会变得越来越复杂、难于使用和理解。
而通过使用接口,我们定义了Reader和Writer两个接口,分别描述输入设备和输出设备,拷贝程序只需要针对这两个接口编程,而无需关心具体设备是什么,程序可以保持稳定,并且易于复用。具体设备在程序运行期创建,然后传给拷贝程序,传入什么具体设备,就在什么具体设备上操作拷贝逻辑,具体设备可以像插件一样,灵活插拔,使程序呈现多态的特性。
多态还颠覆了程序模块间的依赖关系。在习惯的编程思维中,如果A模块调用B模块,那么A模块必须依赖B模块,也就是说,在A模块的代码中必须import或者using B模块的代码。但是通过使用多态的特性,我们可以将这个依赖关系倒置,也就是:A模块调用B模块,A模块却可以不依赖B模块,反而是B模块依赖A模块。
这就是我在第12篇中提到的依赖倒置原则。准确地说,B模块也没有依赖A模块,而是依赖A模块定义的抽象接口。A模块针对抽象接口编程,调用抽象接口,B模块实现抽象接口。在程序运行期将B模块注入A模块,就使得A模块调用B模块,却没有依赖B模块。
多态常常使面向对象编程表现出神奇的特性,而多态正是面向对象编程的本质所在。正是多态,使得面向对象编程和以往的编程方式有了巨大的不同。
设计模式的精髓是对多态的使用
但是就算知道了面向对象编程的多态特性,也很难利用好多态的特性,开发出强大的面向对象程序。到底如何利用好多态特性呢?人们通过不断的编程实践,总结了一系列的设计原则和设计模式。
我们前面几篇文章都是讨论设计原则的:
- 开闭原则:软件类、模块应该是对修改关闭的,而对扩展是开放的。通俗地说,就是要不修改代码就是实现需求的变更。
- 依赖倒置原则:高层模块不应该依赖低层模块,低层模块也不应该依赖高层模块,他们应该都依赖抽象,而这个抽象是高层定义的,逻辑上属于高层。
- 里氏替换原则:所有能够使用父类的地方,应该都可以用它的子类替换。但要注意的是,能不能替换是要看应用场景的,所以在设计继承的时候就要考虑运行期的场景,而不是仅仅考虑父类和子类的静态关系。
- 单一职责原则:一个类应该只有一个引起它变化的原因。实践中,就是类文件尽量不要太大,最好不要超过一屏。
- 接口隔离原则:不要强迫调用者依赖他们不需要的方法。方法主要是通过对接口的多重继承,一个类实现多个接口,不同接口服务不同调用者,不同调用者看到不同方法。
这些设计原则大部分都是和多态有关的,不过这些设计原则更多时候是具有指导性,编程的时候还需要依赖更具体的编程设计方法,这些方法就是设计模式。
模式是可重复的解决方案 ,人们在编程实践中发现,有些问题是重复出现的,虽然场景各有不同,但是问题的本质是一样的,而解决这些问题的方法也是可以重复使用的。人们把这些可以重复使用的编程方法称为设计模式。设计模式的精髓就是对多态的灵活应用。
我们以装饰模式为例,看一下如何灵活应用多态特性。我们先定义一个接口AnyThing,包含一个exe方法。
java
public interface AnyThing {
void exe();
}然后多个类实现这个接口,装饰模式最大的特点是,通过类的构造函数传入一个同类对象,也就是每个类实现的接口和构造函数传入的对象是同一个接口。我们创建了三个类,如下:
java
public class Moon implements AnyThing {
private AnyThing a;
public Moon(AnyThing a) {
this.a = a;
}
public void exe() {
System.out.print("明月装饰了");
a.exe();
}
}
public class Dream implements AnyThing {
private AnyThing a;
public Dream(AnyThing a) {
this.a=a;
}
public void exe() {
System.out.print("梦装饰了");
a.exe();
}
}
public class You implements AnyThing {
private AnyThing a;
public You(AnyThing a) {
this.a = a;
}
public void exe() {
System.out.print("你");
}
}设计这个几个类的时候,它们之间没有任何耦合,但是在创建对象的时候,我们通过构造函数的不同次序,可以使这几个类互相调用,从而呈现不同的装饰结果。
java
AnyThing t = new Moon(new Dream(new You(null)));
t.exe();
// 输出:明月装饰了梦装饰了你
AnyThing t = new Dream(new Moon(new You(null)));
t.exe();
// 输出:梦装饰了明月装饰了你多态的迷人之处就在于,你单独看类的代码的时候,这些代码似乎平淡无奇,但是一旦运行起来,就会表现出纷繁复杂的特性。所以多态有时候也会带来一些代码阅读方面的困扰,让面向对象编程的新手望而却步,这也正是设计模式的作用,这时候你仅仅通过类的名字,比如Observer、Adapter,你就能知道设计者在使用什么模式,从而更快速理解代码。
小结
如果你只是使用面向对象编程语言进行编程,其实并不能说明你就掌握了面向对象编程。只有灵活应用设计模式,使程序呈现多态的特性,进而使程序健壮、灵活、清晰、易于维护和复用,这才是真正掌握了面向对象编程。
所以,下次再有面试官让你"聊聊设计模式",也许你可以这样回答:"除了单例和工厂,我更喜欢适配器和观察者,还有,组合模式在处理树形结构的时候也非常有用。"适配器和观察者模式我在前面已经讲到。
设计模式是一个非常注重实践的编程技能,通过学习设计模式,我们可以体会到面向对象编程的种种精妙。真正掌握设计模式,需要在实践中不断使用它,让自己的程序更加健壮、灵活、清晰、易于复用和扩展。这个时候,面试聊设计模式更好的回答是:"我在工作中比较喜欢用模板模式和策略模式,上个项目中,为了解决不同用户使用不同推荐算法的问题,我......"
事实上,设计模式不仅仅包括《设计模式》这本书里讲到的23种设计模式,只要可重复用于解决某个问题场景的设计方案都可以被称为设计模式。关于设计模式还有一句很著名的话"精通设计模式,就是忘了设计模式",有点像张无忌学太极。如果真正对设计模式融会贯通,你的程序中无处不是设计模式,也许你在三五行代码里,就用了两三个设计模式。你自己就是设计模式的大师,甚至还可以创建一些自己的设计模式。这个时候,再去面试的时候,面试官也不会再问你设计模式的问题了,如果问了,那么你说什么都是对的。
思考题
我在第2篇文章和本篇中都提到了可以使用组合模式遍历树,那么如何用组合模式遍历树呢?
17 设计模式应用:编程框架中的设计模式
在绝大多数情况下,我们开发应用程序的时候,并不是从头开发的。比如,我们用Java开发一个Web应用,并不需要自己写代码监听HTTP 80端口;不需要处理网络传输的二进制HTTP数据包(参考第4篇网络编程原理);不需要亲自为每个用户请求分配一个处理线程(参考01篇操作系统原理),而是直接编写一个Servlet,得到一个HttpRequest对象进行处理就可以了。我们甚至不需要从这个HttpRequest对象中获取请求参数,通过Controller就可以直接得到一个由请求参数构造的对象。
我们写代码的时候,只需要关注自己的业务逻辑就可以了。那些通用的功能,比如监听HTTP端口,从HTTP请求中构造参数对象,是由一些通用的框架来完成的,比如Tomcat或者Spring这些。
什么是框架
框架是对某一类架构方案可复用的设计与实现。所有的Web应用都需要监听HTTP端口,也需要处理请求参数,这些功能不应该在每个Web应用中都被重复开发,而是应该以通用组件的形式被复用。
但并不是所有可被复用的组件都被称作框架,框架通常规定了一个软件的主体结构,可以支撑起软件的整体或者局部的架构形式。比如说,Tomcat完成了Web应用请求响应的主体流程,我们只需要开发Servlet,完成请求处理逻辑,构造响应对象就可以了,所以Tomcat是一个框架。
还有一类可复用的组件不控制软件的主体流程,也不支撑软件的整体架构,比如Log4J提供了一个可复用的日志输出功能,但是,日志输出功能不是软件的主体结构,所以我们通常不称Log4J为框架,而称其为工具。
一般说来,我们使用框架编程的时候,需要遵循框架的规范编写代码。比如Tomcat、Spring、Mybatis、Junit等,这些框架会调用我们编写的代码,而我们编写的代码则会调用工具完成某些特定的功能,比如输出日志,进行正则表达式匹配等。
我在这里强调框架与工具的不同,并不是在咬文嚼字。我见过一些有进取心的工程师宣称自己设计开发了一个新框架,但是这个框架并没有提供一些架构性的规范,也没有支撑软件的主体结构,仅仅只是提供了一些功能接口供开发者调用,实际上,这跟我们对框架的期待相去甚远。
根据我们上面对框架的描述,当你设计一个框架的时候,你实际上是在设计一类软件的通用架构,并通过代码的方式实现出来。如果仅仅是提供功能接口供程序调用,是无法支撑起软件的架构的,也无法规范软件的结构。
那么如何设计、开发一个编程框架?
我在前面讲过开闭原则。框架应该满足开闭原则,即面对不同应用场景,框架本身是不需要修改的,需要对修改关闭。但是各种应用功能却是可以扩展的,即对扩展开放,应用程序可以在框架的基础上扩展出各种业务功能。
同时框架还应该满足依赖倒置原则,即框架不应该依赖应用程序,因为开发框架的时候,应用程序还没有呢。应用程序也不应该依赖框架,这样应用程序可以灵活更换框架。框架和应用程序应该都依赖抽象,比如Tomcat提供的编程接口就是Servlet,应用程序只需要实现Servlet接口,就可以在Tomcat框架下运行,不需要依赖Tomcat,可以随时切换到Jetty等其他Web容器。
要知道,虽然设计原则可以指导框架开发,但是并没有给出具体的设计方法。事实上,框架正是利用各种设计模式开发出来的。编程框架与应用程序、设计模式、设计原则之间的关系如下图所示。

面向对象的设计目标是低耦合、高内聚。为了实现这个目标,人们提出了一些设计原则,主要有开闭原则、依赖倒置原则、里氏替换原则、单一职责原则、接口隔离原则。在这些原则之上,人们总结了若干设计模式,最著名的就是GoF23种设计模式,还有Web开发同学非常熟悉的MVC模式等等。依照这些设计模式,人们开发了各种编程框架。使用这些编程框架,开发者可以简单、快速地开发各种应用程序。
Web容器中的设计模式
前面我们一再提到Tomcat是一个框架,那么Tomcat与其他同类的Web容器是用什么设计模式实现的?代码如何被Web容器执行?程序中的请求对象HttpServletRequest是从哪里来的?
Web容器主要使用了策略模式,多个策略实现同一个策略接口。编程的时候Tomcat依赖策略接口,而在运行期根据不同上下文,Tomcat装载不同的策略实现。
这里的策略接口就是Servlet接口,而我们开发的代码就是实现这个Servlet接口,处理HTTP请求。J2EE规范定义了Servlet接口,接口中主要有三个方法:
java
public interface Servlet {
public void init(ServletConfig config) throws ServletException;
public void service(ServletRequest req, ServletResponse res)
throws ServletException, IOException;
public void destroy();
}Web容器Container在装载我们开发的Servlet具体类的时候,会调用这个类的init方法进行初始化。当有HTTP请求到达容器的时候,容器会对HTTP请求中的二进制编码进行反序列化,封装成ServletRequest对象,然后调用Servlet的service方法进行处理。当容器关闭的时候,会调用destroy方法做善后处理。
当我们开发Web应用的时候,只需要实现这个Servlet接口,开发自己的Servlet就可以了,容器会监听HTTP端口,并将收到的HTTP数据包封装成ServletRequest对象,调用我们的Servlet代码。代码只需要从ServletRequest中获取请求数据进行处理计算就可以了,处理结果可以通过ServletResponse返回给客户端。
这里Tomcat就是策略模式中的Client程序,Servlet接口是策略接口。我们自己开发的具体Servlet类就是策略的实现。通过使用策略模式,Tomcat这样的Web容器可以调用各种Servlet应用程序代码,而各种Servlet应用程序代码也可以运行在Jetty等其他的Web容器里,只要这些Web容器都支持Servlet接口就可以了。
Web容器完成了HTTP请求处理的主要流程,指定了Servlet接口规范,实现了Web开发的主要架构,开发者只要在这个架构下开发具体Servlet就可以了。因此我们可以称Tomcat、Jetty这类Web容器为框架。
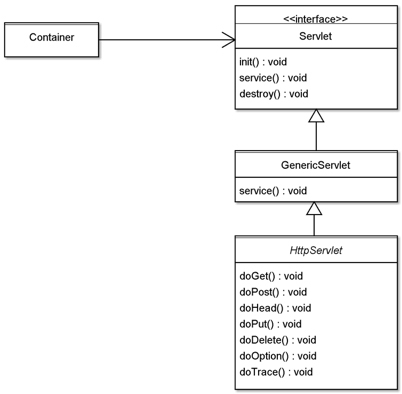
事实上,我们开发具体的Servlet应用程序的时候,并不会直接实现Servlet接口,而是继承HttpServlet类,HttpServlet类实现了Servlet接口。HttpServlet还用到了模板方法模式,所谓模板方法模式,就是在父类中用抽象方法定义计算的骨架和过程,而抽象方法的实现则留在子类中。
这里,父类是HttpServlet,HttpServlet通过继承GenericServlet实现了Servlet接口,并在自己的service方法中,针对不同的HTTP请求类型调用相应的方法,HttpServlet的service方法就是一个模板方法。
java
protected void service(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
String method = req.getMethod();
if (method.equals(METHOD_GET)) {
doGet(req, resp);
} else if (method.equals(METHOD_HEAD)) {
long lastModified = getLastModified(req);
maybeSetLastModified(resp, lastModified);
doHead(req, resp);
} else if ...由于HTTP请求有get、post等7种请求类型,为了便于编程,HttpServlet提供了这7种HTTP请求类型对应的执行方法doGet、doPost等等。service模板方法会判断HTTP请求类型,根据不同请求类型,执行不同方法。开发者只需要继承HttpServlet,重写doGet、doPost等对应的HTTP请求类型方法就可以了,不需要自己判断HTTP请求类型。Servlet相关的类关系如下:
JUnit中的设计模式
JUnit是一个Java单元测试框架,开发者只需要继承JUnit的TestCase,开发自己的测试用例类,通过JUnit框架执行测试,就得到测试结果。
开发测试用例如下:
java
public class MyTest extends TestCase {
protected void setUp() {
...
}
public void testSome() {
...
}
protected void tearDown() {
...
}
}每个测试用例继承TestCase,在setUp方法里做一些测试初始化的工作,比如装载测试数据什么的;然后编写多个以test为前缀的方法,这些方法就是测试用例方法;还有一个tearDown方法,在测试结束后,进行一些收尾的工作,比如删除数据库中的测试数据等。
那么,我们写的这些测试用例如何被JUnit执行呢?如何保证测试用例中这几个方法的执行顺序呢?JUnit在这里也使用了模板方法模式,测试用例的方法执行顺序被固定在JUnit框架的模板方法里。如下:
java
public void runBare() throws Throwable {
setUp();
try{
runTest();
}
finally {
tearDown();
}
}runBare是TestCase基类里的方法,测试用例执行时实际上只执行runBare模板方法,这个方法里,先执行setUp方法,然后执行各种test前缀的方法,最后执行tearDown方法。保证每个测试用例都进行初始化及必要的收尾。而我们的测试类只需要继承TestCase基类,实现setUp、tearDown以及其他测试方法就可以了。
此外,一个软件的测试用例会有很多,你可能希望执行全部这些用例,也可能希望执行一部分用例,JUnit提供了一个测试套件TestSuit管理、组织测试用例。
java
public static Test suite() {
TestSuite suite = new TestSuite("all");
suite.addTest(MyTest.class);//加入一个TestCase
suite.addTest(otherTestSuite);//加入一个TestSuite
return suite;
}TestSuite可以通过addTest方法将多个TestCase类加入一个测试套件suite,还可以将另一个TestSuite加入这个测试套件。当执行这个TestSuite的时候,加入的测试类TestCase会被执行,加入的其他测试套件TestSuite里面的测试类也会被执行,如果其他的测试套件里包含了另外一些测试套件,也都会被执行。
这也就意味着TestSuite是可以递归的,事实上,TestSuite是一个树状的结构,如下:
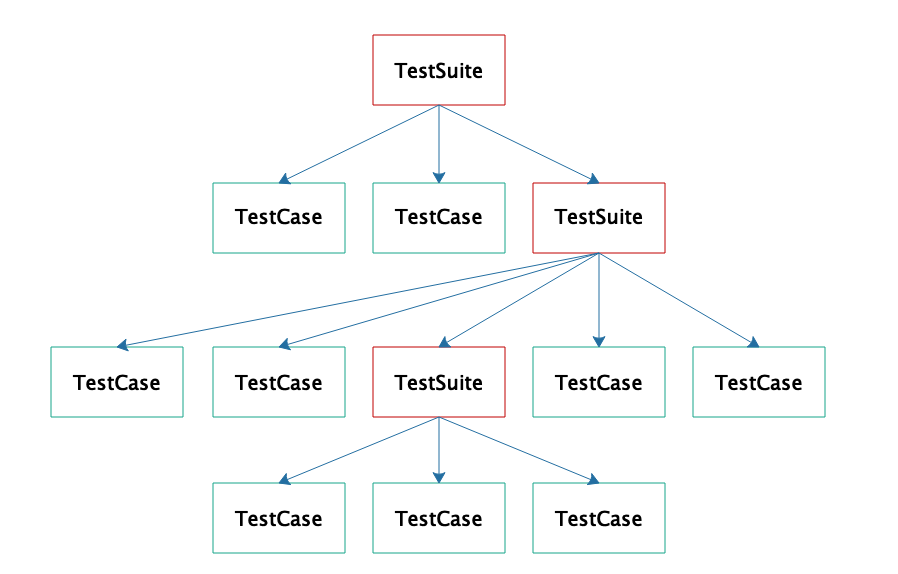
当我们从树的根节点遍历树,就可以执行所有这些测试用例。传统上进行树的遍历需要递归编程的,而使用组合模式,无需递归也可以遍历树。
首先,TestSuite和TestCase都实现了接口Test:
java
public interface Test {
public abstract void run(TestResult result);
}当我们调用TestSuite的addTest方法时,TestSuite会将输入的对象放入一个数组:
java
private Vector<Test> fTests= new Vector<Test>(10);
public void addTest(Test test) {
fTests.add(test);
}由于TestCase和TestSuite都实现了Test接口,所以addTest的时候,既可以传入TestCase,也可以传入TestSuite。执行TestSuite的run方法时,会取出这个数组的每个对象,分别执行他们的run方法:
java
public void run(TestResult result) {
for (Test each : fTests) {
test.run(result);
}
}如果这个test对象是TestCase,就执行测试;如果这个test对象是一个TestSuite,那么就会继续调用这个TestSuite对象的run方法,遍历执行数组的每个Test的run方法,从而实现了树的递归遍历。
小结
人们对架构师的工作有一种常见的误解,认为架构师做架构设计就可以了,架构师不需要写代码。事实上,架构师如果只是画画架构图,写写设计文档,那么如何保证自己的架构设计能被整个开发团队遵守、落到实处?
架构师应该通过代码落实自己的架构设计,也就是通过开发编程框架,约定软件开发的规范。开发团队依照框架的接口开发程序,最终被框架调用执行。架构师不需要拿着架构图一遍一遍讲软件架构是什么,只需要基于框架写个Demo,大家就都清楚架构是什么了,自己应该如何做了。
所以每个想成为架构师的程序员都应该学习如何开发框架。
思考题
在Tomcat和JUnit中,还使用了其他一些设计模式,在哪些地方使用什么设计模式,解决什么问题?你了解吗?
18 反应式编程框架设计:如何使程序调用不阻塞等待,立即响应?
我们在专栏第1篇就讨论了为什么在高并发的情况下,程序会崩溃。主要原因是,在高并发的情况下,有大量用户请求需要程序计算处理,而目前的处理方式是,为每个用户请求分配一个线程,当程序内部因为访问数据库等原因造成线程阻塞时,线程无法释放去处理其他请求,这样就会造成请求堆积,不断消耗资源,最终导致程序崩溃。

这是传统的Web应用程序运行期的线程特性。对于一个高并发的应用系统来说,总是同时有很多个用户请求到达系统的Web容器。Web容器为每个请求分配一个线程进行处理,线程在处理过程中,如果遇到访问数据库或者远程服务等操作,就会进入阻塞状态,这个时候,如果数据库或者远程服务响应延迟,就会出现程序内的线程无法释放的情况,而外部的请求不断进来,导致计算机资源被快速消耗,最终程序崩溃。
那么有没有不阻塞线程的编程方法呢?
反应式编程
答案就是反应式编程。反应式编程本质上是一种异步编程方案,在多线程(协程)、异步方法调用、异步I/O访问等技术基础之上,提供了一整套与异步调用相匹配的编程模型,从而实现程序调用非阻塞、即时响应等特性,即开发出一个反应式的系统,以应对编程领域越来越高的并发处理需求。
人们还提出了一个反应式宣言,认为反应式系统应该具备如下特质:
即时响应,应用的调用者可以即时得到响应,无需等到整个应用程序执行完毕。也就是说应用调用是非阻塞的。
回弹性,当应用程序部分功能失效的时候,应用系统本身能够进行自我修复,保证正常运行,保证响应,不会出现系统崩溃和宕机的情况。
弹性,系统能够对应用负载压力做出响应,能够自动伸缩以适应应用负载压力,根据压力自动调整自身的处理能力,或者根据自身的处理能力,调整进入系统中的访问请求数量。
消息驱动,功能模块之间,服务之间,通过消息进行驱动,完成服务的流程。
目前主流的反应式编程框架有RxJava、Reactor等,它们的主要特点是基于观察者设计模式的异步编程方案,编程模型采用函数式编程。
观察者模式和函数式编程有自己的优势,但是反应式编程并不是必须用观察者模式和函数式编程。Flower就是一个纯消息驱动,完全异步,支持命令式编程的反应式编程框架。
下面我们就看看Flower如何实现异步无阻塞的调用,以及Flower这个框架设计使用了什么样的设计原则与模式。
反应式编程框架Flower的基本原理
一个使用Flower框架开发的典型Web应用的线程特性如下图所示:
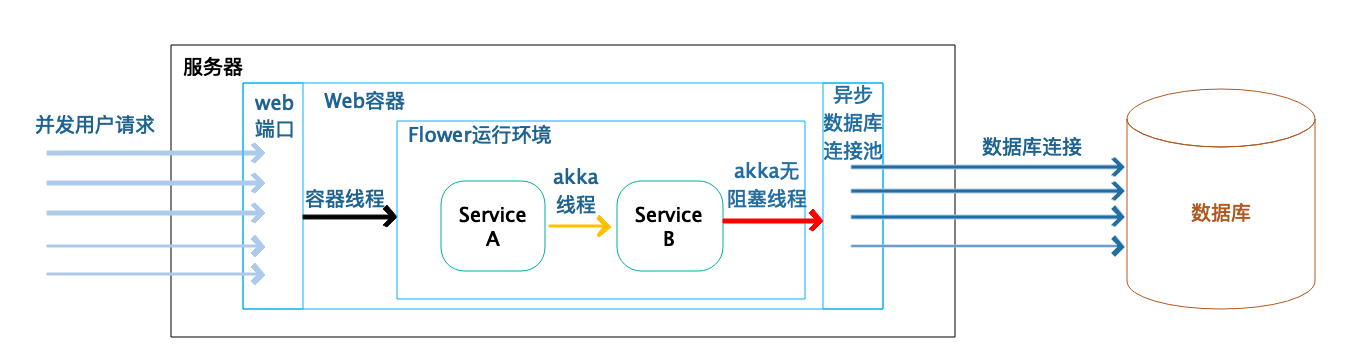
当并发用户到达应用服务器的时候,Web容器线程不需要执行应用程序代码,它只是将用户的HTTP请求变为请求对象,将请求对象异步交给Flower框架的Service去处理,自身立刻就返回。因为容器线程不做太多的工作,所以只需极少的容器线程就可以满足高并发的用户请求,用户的请求不会被阻塞,不会因为容器线程不够而无法处理。相比传统的阻塞式编程,Web容器线程要完成全部的请求处理操作,直到返回响应结果才能释放线程;使用Flower框架只需要极少的容器线程就可以处理较多的并发用户请求,而且容器线程不会阻塞。
用户请求交给基于Flower框架开发的业务Service对象以后,Service之间依然是使用异步消息通讯的方式进行调用,不会直接进行阻塞式的调用。一个Service完成业务逻辑处理计算以后,会返回一个处理结果,这个结果以消息的方式异步发送给它的下一个Service。
传统编程模型的Service之间如果进行调用,如我们在专栏第一篇讨论的那样,被调用的Service在返回之前,调用的Service方法只能阻塞等待。而Flower的Service之间使用了AKKA Actor进行消息通信,调用者的Service发送调用消息后,不需要等待被调用者返回结果,就可以处理自己的下一个消息了。事实上,这些Service可以复用同一个线程去处理自己的消息,也就是说,只需要有限的几个线程就可以完成大量的Service处理和消息传输,这些线程不会阻塞等待。
我们刚才提到,通常Web应用主要的线程阻塞,是因为数据库的访问导致的线程阻塞。Flower支持异步数据库驱动,用户请求数据库的时候,将请求提交给异步数据库驱动,立刻就返回,不会阻塞当前线程,异步数据库访问连接远程的数据库,进行真正的数据库操作,得到结果以后,将结果以异步回调的方式发送给Flower的Service进行进一步的处理,这个时候依然不会有线程被阻塞。
也就是说,使用Flower开发的系统,在一个典型的Web应用中,几乎没有任何地方会被阻塞,所有的线程都可以被不断地复用,有限的线程就可以完成大量的并发用户请求,从而大大地提高了系统的吞吐能力和响应时间 ,同时,由于线程不会被阻塞,应用就不会因为并发量太大或者数据库处理缓慢而宕机,从而提高了系统的可用性。
Flower框架实现异步无阻塞,一方面是利用了Web容器的异步特性,主要是Servlet3.0以后提供的AsyncContext,快速释放容器线程;另一方面是利用了异步的数据库驱动以及异步的网络通信,主要是HttpAsyncClient等异步通信组件。而Flower框架内,核心的应用代码之间的异步无阻塞调用,则是利用了Akka 的Actor模型实现。
Akka Actor的异步消息驱动实现如下:
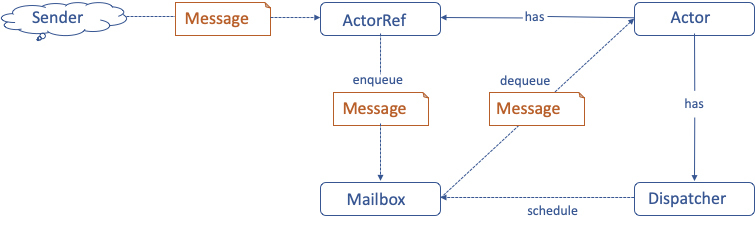
一个Actor向另一个Actor进行通讯的时候,当前Actor就是一个消息的发送者sender,当它想要向另一个Actor进行通讯的时候,就需要获得另一个Actor的ActorRef,也就是一个引用,通过引用进行消息通信。而ActorRef收到消息以后,会将这个消息放入到目标Actor的Mailbox里面去,然后就立即返回了。
也就是说一个Actor向另一个Actor发送消息的时候,不需要另一个Actor去真正地处理这个消息,只需要将消息发送到目标Actor的Mailbox里面就可以了。自己不会被阻塞,可以继续执行自己的操作,而目标Actor检查自己的Mailbox中是否有消息,如果有消息,Actor则会在从Mailbox里面去获取消息,对消息进行异步的处理,而所有的Actor会共享线程,这些线程不会有任何的阻塞。
反应式编程框架Flower的设计方法
但是直接使用Actor进行编程有很多不便,Flower框架对Actor进行了封装,开发者只需要编写一些细粒度的Service,这些Service会被包装在Actor里面,进行异步通信。
Flower Service例子如下:
java
public class ServiceA implements Service<Message2> {
@Override
public Object process(Message2 message) {
return message.getAge() + 1;
}
}每个Service都需要实现框架的Service接口的process方法,process方法的输入参数就是前一个Service process方法的返回值,这样只需要将Service编排成一个流程,Service的返回值就会变成Actor的一个消息,被发送给下一个Service,从而实现Service的异步通信。
Service的流程编排有两种方式,一种方式是编程实现,如下:
java
getServiceFlow().buildFlow("ServiceA", "ServiceB");表示ServiceA的返回值将作为消息发送给ServiceB,成为ServiceB的输入值,这样两个Service就可以合作完成一些更复杂的业务逻辑。
Flower还支持可视化的Service流程编排,像下面这张图一样编辑流程定义文件,就可以开发一个异步业务处理流程。

那么这个Flower框架是如何实现的呢?
Flower框架的设计也是基于前面专栏讨论过的依赖倒置原则。所有应用开发者实现的Service类都需要包装在Actor里面进行异步调用,但是Actor不会依赖开发者实现的Service类,开发者也不会依赖Actor类,他们共同依赖一个Service接口,这个接口是框架提供的,如上面例子所示。
Actor与Service的依赖倒置关系如下图所示:
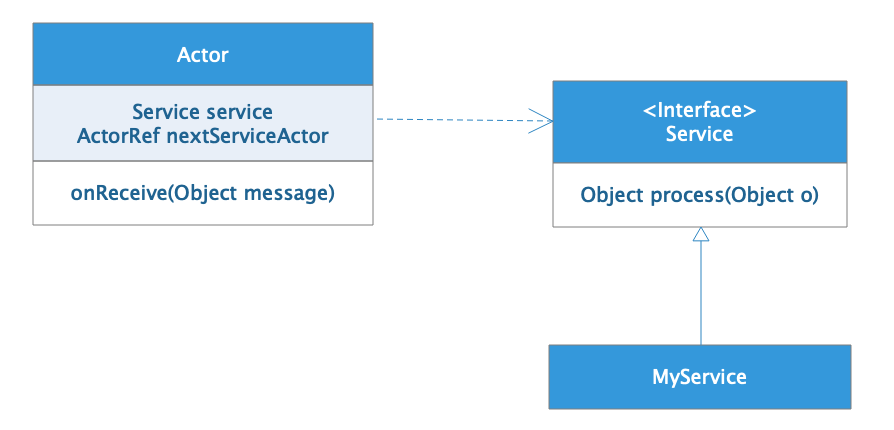
每个Actor都依赖一个Service接口,而具体的Service实现类,比如MyService,则实现这个Service接口。在运行期实例化Actor的时候,这个接口被注入具体的Service实现类,比如MyService。在Flower中,调用MyService对象,其实就是给包装MyService对象的Actor发消息,Actor收到消息,执行自己的onReceive方法,在这个方法里,Actor调用MyService的process方法,并将onReceive收到的Message对象当做process的输入参数传入。
process处理完成后,返回一个Object对象。Actor会根据编排好的流程,获取MyService在流程中的下一个Service对应的Actor,即nextServiceActor,将process返回的Object对象当做消息发送给这个nextServiceActor。这样,Service之间就根据编排好的流程,异步、无阻塞地调用执行起来了。
反应式编程框架Flower的落地效果
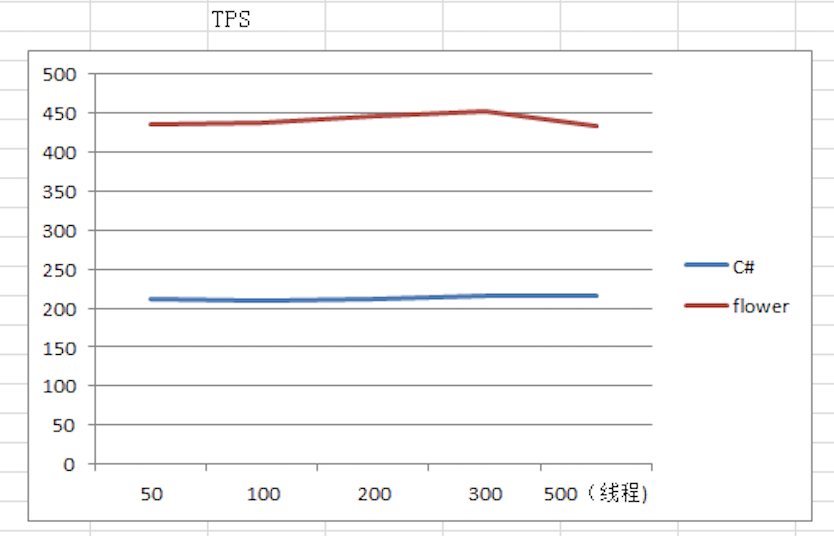
Flower框架在部分项目中落地应用,应用效果较为显著,一方面,Flower可以显著提高系统的性能。这是某个C#开发的系统使用Flower重构后的TPS性能比较,使用Flower开发的系统TPS差不多是原来C#系统的两倍。
另一方面,Flower对系统可用性也有较大提升,目前常见互联网应用架构如下图:
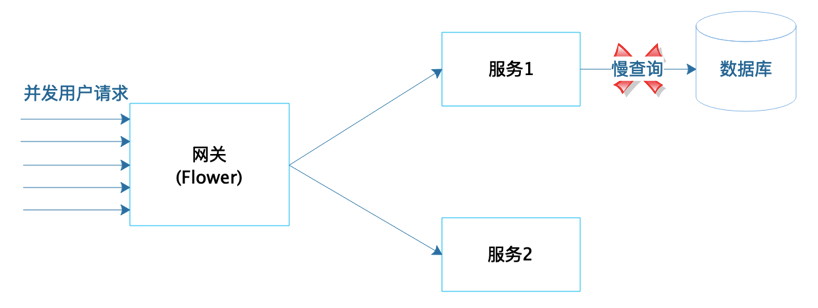
用户请求通过网关服务器调用微服务完成处理,那么当有某个微服务连接的数据库查询执行较慢时,如图中服务1,那么按照传统的线程阻塞模型,就会导致服务1的线程都被阻塞在这个慢查询的数据库操作上。同样的,网关线程也会阻塞在调用这个延迟比较厉害的服务1上。
最终的效果就是,网关所有的线程都被阻塞,即使是不调用服务1的用户请求也无法处理,最后整个系统失去响应,应用宕机。使用阻塞式编程,实际的压测效果如下,当服务1响应延迟,出错率大幅飙升的时候,通过网关调用正常的服务2的出错率也非常高。

使用Flower开发的网关,实际压测效果如下,同样服务1响应延迟,出错率极高的情况下,通过Flower网关调用服务2完全不受影响。

小结
事实上,Flower不仅是一个反应式Web编程框架,还是反应式的微服务框架。也就是说,Flower的Service可以远程部署到一个Service容器里面,就像我们现在常用的微服务架构一样。Flower会提供一个独立的Flower容器,用于启动一些Service,这些Service在启动了以后,会向注册中心进行注册,而且应用程序可以将这些分布式的Service进行流程编排,得到一个分布式非阻塞的微服务系统。整体架构和主流的微服务架构很像,主要的区别就是Flower的服务是异步的,通过流程编排的方式进行服务调用,而不是通过接口依赖的方式进行调用。
你可以点击这里进入Flower框架的源代码地址,欢迎你参与Flower开发,也欢迎将Flower应用到你的系统开发中。你对Flower有什么疑问,也欢迎与我交流。
思考题
反应式编程虽然能带来性能和可用性方面的提升,但是也带来一些问题,你觉得反应式编程可能存在的问题有哪些?应该如何应对?你是否愿意在工作实践中尝试反应式编程?
19 组件设计原则:组件的边界在哪里?
软件的复杂度和它的规模成指数关系,一个复杂度为100的软件系统,如果能拆分成两个互不相关、同等规模的子系统,那么每个子系统的复杂度应该是25,而不是50。软件开发这个行业很久之前就形成了一个共识,应该将复杂的软件系统进行拆分,拆成多个更低复杂度的子系统,子系统还可以继续拆分成更小粒度的组件。也就是说,软件需要进行模块化、组件化设计。
事实上,早在打孔纸带编程时代,程序员们就开始尝试进行软件的组件化设计。那些相对独立,可以被复用的程序被打在纸带卡片上,放在一个盒子里。当某个程序需要复用这个程序组件的时候,就把这一摞纸带卡片从盒子里拿出来,放在要运行的其他纸带的前面或者后面,被光电读卡器一起扫描,一起执行。
其实我们现在的组件开发与复用跟这个也差不多。比如我们用Java开发,会把独立的组件编译成一个一个的jar包,相当于这些组件被封装在一个一个的盒子里。需要复用的时候,程序只需要依赖这些jar包,运行的时候,只需要把这些依赖的jar包放在classpath路径下,最后被JVM统一装载,一起执行。
现在,稍有规模的软件系统一定被拆分成很多组件。正是因为组件化设计,我们才能开发出复杂的系统。
那么如何进行组件的设计呢?组件的粒度应该多大?如何对组件的功能进行划分?组件的边界又在哪里?
我们之前说过,软件设计的核心目标就是高内聚、低耦合。那么今天我们从这两个维度,看组件的设计原则。
组件内聚原则
组件内聚原则主要讨论哪些类应该聚合在同一个组件中,以便组件既能提供相对完整的功能,又不至于太过庞大。在具体设计中,可以遵循以下三个原则。
复用发布等同原则
复用发布等同原则是说,软件复用的最小粒度应该等同于其发布的最小粒度。也就是说,如果你希望别人以怎样的粒度复用你的软件,你就应该以怎样的粒度发布你的软件。这其实就是组件的定义了,组件是软件复用和发布的最小粒度软件单元。这个粒度既是复用的粒度,也是发布的粒度。
同时,如果你发布的组件会不断变更,那么你就应该用版本号做好组件的版本管理,以使组件的使用者能够知道自己是否需要升级组件版本,以及是否会出现组件不兼容的情况。因此,组件的版本号应该遵循一些大家都接受的约定。
这里有一个版本号约定建议供你参考,版本号格式:主版本号.次版本号.修订号。比如1.3.12,在这个版本号中,主版本号是1,次版本号是3,修订号是12。主版本号升级,表示组件发生了不向前兼容的重大修订;次版本号升级,表示组件进行了重要的功能修订或者bug修复,但是组件是向前兼容的;修订号升级,表示组件进行了不重要的功能修订或者bug修复。
共同封闭原则
共同封闭原则是说,我们应该将那些会同时修改,并且为了相同目的而修改的类放到同一个组件中。而将不会同时修改,并且不会为了相同目的而修改的类放到不同的组件中。
组件的目的虽然是为了复用,然而开发中常常引发问题的,恰恰在于组件本身的可维护性。如果组件在自己的生命周期中必须经历各种变更,那么最好不要涉及其他组件,相关的变更都在同一个组件中。这样,当变更发生的时候,只需要重新发布这个组件就可以了,而不是一大堆组件都受到牵连。
也许将某些类放入这个组件中对于复用是便利的、合理的,但如果组件的复用与维护发生冲突,比如这些类将来的变更和整个组件将来的变更是不同步的,不会由于相同的原因发生变更,那么为了可维护性,应该谨慎考虑,是不是应该将这些类和组件放在一起。
共同复用原则
共同复用原则是说,不要强迫一个组件的用户依赖他们不需要的东西。
这个原则一方面是说,我们应该将互相依赖,共同复用的类放在一个组件中。比如说,一个数据结构容器组件,提供数组、Hash表等各种数据结构容器,那么对数据结构遍历的类、排序的类也应该放在这个组件中,以使这个组件中的类共同对外提供服务。
另一方面,这个原则也说明,如果不是被共同依赖的类,就不应该放在同一个组件中。如果不被依赖的类发生变更,就会引起组件变更,进而引起使用组件的程序发生变更。这样就会导致组件的使用者产生不必要的困扰,甚至讨厌使用这样的组件,也造成了组件复用的困难。
其实,以上三个组件内聚原则相互之间也存在一些冲突,比如共同复用原则和共同闭包原则,一个强调易复用,一个强调易维护,而这两者是有冲突的。因此这些原则可以用来指导组件设计时的考量,但要想真正做出正确的设计决策,还需要架构师自己的经验和对场景的理解,对这些原则进行权衡。
组件耦合原则
组件内聚原则讨论的是组件应该包含哪些功能和类,而组件耦合原则讨论组件之间的耦合关系应该如何设计。组件耦合关系设计也应该遵循三个原则。
无循环依赖原则
无循环依赖原则说,组件依赖关系中不应该出现环。如果组件A依赖组件B,组件B依赖组件C,组件C又依赖组件A,就形成了循环依赖。
很多时候,循环依赖是在组件的变更过程中逐渐形成的,组件A版本1.0依赖组件B版本1.0,后来组件B升级到1.1,升级的某个功能依赖组件A的1.0版本,于是形成了循环依赖。如果组件设计的边界不清晰,组件开发设计缺乏评审,开发者只关注自己开发的组件,整个项目对组件依赖管理没有统一的规则,很有可能出现循环依赖。
而一旦系统内出现组件循环依赖,系统就会变得非常不稳定。一个微小的bug都可能导致连锁反应,在其他地方出现莫名其妙的问题,有时候甚至什么都没做,头一天还好好的系统,第二天就启动不了了。
在有严重循环依赖的系统内开发代码,整个技术团队就好像在焦油坑里编程,什么也不敢动,也动不了,只有焦躁和沮丧。
稳定依赖原则
稳定依赖原则说,组件依赖关系必须指向更稳定的方向。很少有变更的组件是稳定的,也就是说,经常变更的组件是不稳定的。根据稳定依赖原则,不稳定的组件应该依赖稳定的组件,而不是反过来。
反过来说,如果一个组件被更多组件依赖,那么它需要相对是稳定的,因为想要变更一个被很多组件依赖的组件,本身就是一件困难的事。相对应的,如果一个组件依赖了很多的组件,那么它相对也是不稳定的,因为它依赖的任何组件变更,都可能导致自己的变更。
稳定依赖原则通俗地说就是,组件不应该依赖一个比自己还不稳定的组件。
稳定抽象原则
稳定抽象原则说,一个组件的抽象化程度应该与其稳定性程度一致。也就是说,一个稳定的组件应该是抽象的,而不稳定的组件应该是具体的。
这个原则对具体开发的指导意义就是:如果你设计的组件是具体的、不稳定的,那么可以为这个组件对外提供服务的类设计一组接口,并把这组接口封装在一个专门的组件中,那么这个组件相对就比较抽象、稳定。
在具体实践中,这个抽象接口的组件设计,也应该遵循前面专栏讲到的依赖倒置原则。也就是说,抽象的接口组件不应该由低层具体实现组件定义,而应该由高层使用组件定义。高层使用组件依赖接口组件进行编程,而低层实现组件实现接口组件。
Java中的JDBC就是这样一个例子,在JDK中定义JDBC接口组件,这个接口组件位于java.sql包,我们开发应用程序的时候只需要使用JDBC的接口编程就可以了。而发布应用的时候,我们指定具体的实现组件,可以是MySQL实现的JDBC组件,也可以是Oracle实现的JDBC组件。
小结
组件的边界与依赖关系划分,不仅需要考虑技术问题,也要考虑业务场景问题。易变与稳定,依赖与被依赖,都需要放在业务场景中去考察。有的时候,甚至不只是技术和业务的问题,还需要考虑人的问题,在一个复杂的组织中,组件的依赖与设计需要考虑人的因素,如果组件的功能划分涉及到部门的职责边界,甚至会和公司内的政治关联起来。
因此,公司的技术沉淀与实力,公司的业务情况,部门与团队的人情世故,甚至公司的过往历史,都可能会对组件的设计产生影响。而能够深刻了解这些情况的,通常都是公司的一些"老人"。所以,年龄大的程序员并不一定要和年轻程序员拼技术甚至拼体力,应该发挥自己的所长,去做一些对自己、对公司更有价值的事。
思考题
在稳定抽象原则里,类似JDBC的例子还有很多,你能举几个吗?
20 领域驱动设计:35岁的程序员应该写什么样的代码?
我在阿里巴巴工作的头一年,坐在我对面的同事负责开发一个公司统一的运维系统。他对这个系统经过谨慎的调研和认真的思考,花费了半年多的时间开发,终于开发完了。然后邀请各个部门的相关同事做发布评审,如果大家没什么意见就发布上线,全公司范围统一推广使用。
结果在这个发布会上,几乎所有部门的同事都提出了不同的意见:虽然这个功能是我们需要的,但是那个特性却是不能接受的,我们以往不是这样的......
最糟糕的是,不同部门的这个功能和那个特性又几乎不相同。最终讨论的结果是,这个系统不发布推广,需要重新设计。
这个同事又花了几个月的时间尝试满足所有部门的不同的需求,最终发现无法统一这些功能需求,于是辞职了......
他离职后,有次会上我们又讨论起这个项目为什么会失败,其中有个同事的话让我印象深刻,他的话的大意是:如果你对自己要开发的业务领域没有清晰的定义和边界,没有设计系统的领域模型,而仅仅跟着所谓的需求不断开发功能,一旦需求来自多个方面,就可能发生需求冲突,或者随着时间的推移,前后功能也会发生冲突,这时你越是试图弥补这些冲突,就越是陷入更大的冲突之中。
回想一下我经历的各种项目,似乎确实如此。用户或者产品经理的需求零零散散,不断变更。工程师在各处代码中寻找可以实现这些需求变更的代码,修修补补。软件只有需求分析,并没有真正的设计,系统没有一个统一的领域模型维持其内在的逻辑一致性。功能特性并不是按照领域模型内在的逻辑设计,而是按照各色人等自己的主观想象设计。项目时间一长,各种困难重重,需求不断延期,线上bug不断,管理者考虑是不是要推到重来,而程序员则考虑是不是要跑路。
领域模型模式
目前企业级应用开发中,业务逻辑的组织方式主要是事务脚本模式。事务脚本按照业务处理的过程组织业务逻辑,每个过程处理来自客户端的单个请求。客户端的每次请求都包含了一定的业务处理逻辑,而程序则按照每次请求的业务逻辑进行划分。
事务脚本模式典型的就是Controller→Service→Dao这样的程序设计模式。Controller封装用户请求,根据请求参数构造一些数据对象调用Service,Service里面包含大量的业务逻辑代码,完成对数据的处理,期间可能需要通过Dao从数据库中获取数据,或者将数据写入数据库中。
比如这样一个业务场景:每个销售合同都包含一个产品,根据销售的不同产品类型计算收入,当用户支付的时候,需要计算合同收入。
按照事务脚本模式,也就是我们目前习惯的方法,程序设计可能是这样的:
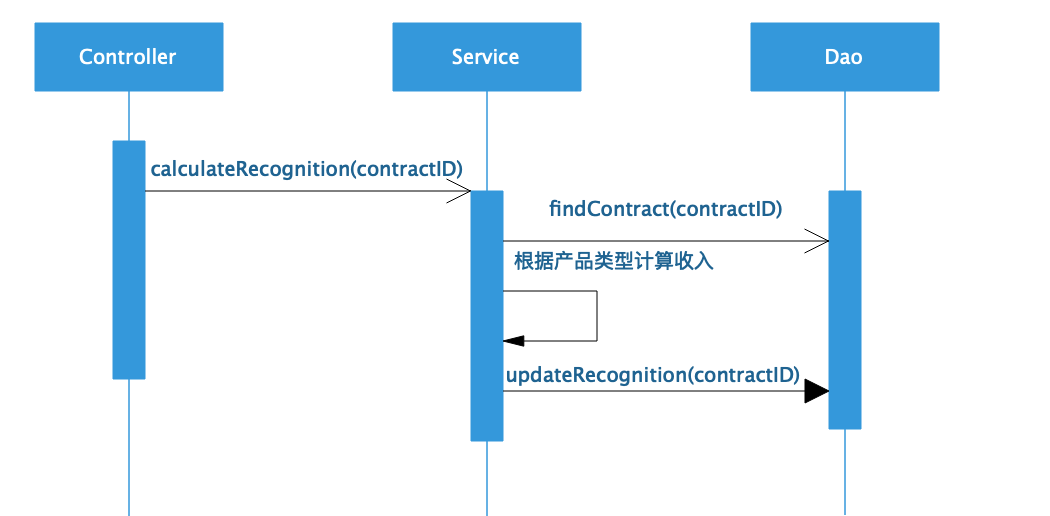
用户发起请求到Controller,Controller调用Service的calculateRecognition方法,并将合同ID传递过去计算确认收入。Service根据合同ID调用Dao查找合同信息,根据合同获得产品类型,再根据产品类型计算收入,然后把确认收入保存到数据库。
这里一个很大的问题在于,不同产品类型收入的计算方法不同,如果修改计算方法,或者增加新的产品类型,都需要修改这个Service类,随着业务不断复杂,这个类会变得越来越难以维护。
在这里,Service只是用来放收入计算方法的一个类,并没有什么设计的约束。如果有一天,另一个客户端需要计算另一种产品类型收入,很大可能会重新写一个Service。于是,相同的业务在不同的地方维护,事情变得更加复杂。
由于事务脚本模式中,Service、Dao这些对象只有方法,没有数值成员变量,而方法调用时传递的数值对象没有方法(或者只有一些getter、setter方法),因此事务脚本又被称作贫血模型。
领域模型模式和事务脚本模式不同。在领域模型模式下,业务逻辑围绕领域模型设计。比如收入确认是和合同强相关的,是合同对象的一个职责,那么合同对象就应该提供一个calculateRecognition方法计算收入。
领域模型中的对象和事务脚本中的对象有很大的不同,比如事务脚本中也有合同Contract这个对象,但是这个Contract只包含合同的数据信息,不包含和合同有关的计算逻辑,计算逻辑在Service类里。
而领域模型的对象则包含了对象的数据和计算逻辑,比如合同对象,既包含合同数据,也包含合同相关的计算。因此从面向对象的角度看,领域模型才是真正的面向对象。如果用领域模型设计上面的合同收入确认,是这样的:
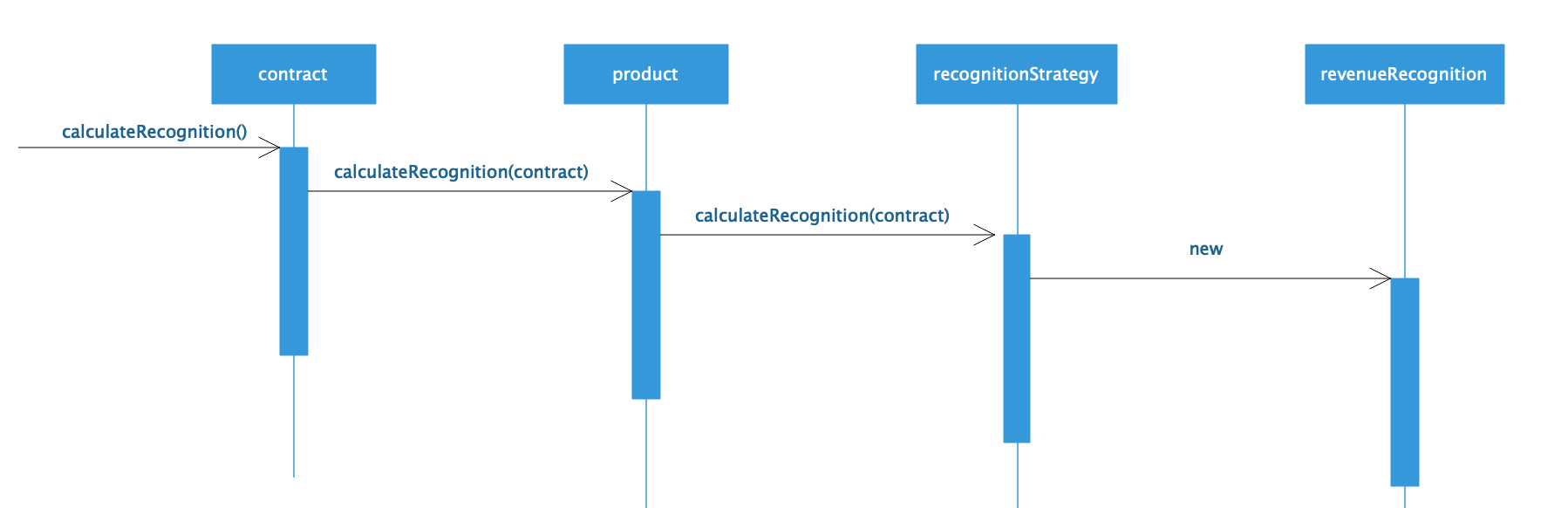
计算收入的请求直接提交给合同对象Contract,这个时候,就无需传递合同ID,因为请求的合同对象就是这个ID的对象。合同对象聚合了一个产品对Product,并调用这个product的calculateRecognition方法,把合同对象传递过去。不同产品关联不同的收入确认策略recognitionStrategy,调用recognitionStrategy的calculateRecognition,完成收入对象revenueRecognition的创建,也就完成了收入计算。
这里Contract和Product都是领域模型对象,领域模型是合并了行为和数据的领域的对象模型。通过领域模型对象的交互完成业务逻辑的实现,也就是说,设计好了领域模型对象,也就设计好了业务逻辑实现。和事务脚本被称作贫血模型相对应的,领域模型也被称为充血模型。
对于复杂的业务逻辑实现来说,用领域模型模式更有优势。特别是在持续的需求变更和业务迭代过程中,把握好领域模型,对业务逻辑本身也会有更清晰的认识。使用领域模型增加新的产品类型的时候,就不需要修改现有的代码,只需要扩展新的产品类和收入策略类就可以了。
在需求变更过程中,如果一个需求和领域模型有冲突,和模型的定义以及模型间的交互逻辑不一致,那么很有可能这个需求本身就是伪需求。很多看似合理的需求其实和业务的内在逻辑是有冲突的,这样的需求也不会带来业务的价值,通过领域模型分析,可以识别出这样的伪需求,使系统更好地保持一致性,也可以使开发资源投入到更有价值的地方去。
领域驱动设计(DDD)
前面我讲到领域模型模式,那么如何用领域模型模式设计一个完整而复杂的系统,有没有完整的方法和过程指导整个系统的设计?领域驱动设计,即DDD就是用来解决这一问题的。
领域 是一个组织所做的事情以及其包含的一切,通俗地说,就是组织的业务范围和做事方式,也是软件开发的目标范围。比如对于淘宝这样一个以电子商务为主要业务的组织,C2C电子商务就是它的领域。领域驱动设计就是从领域出发,分析领域内模型及其关系,进而设计软件系统的方法。
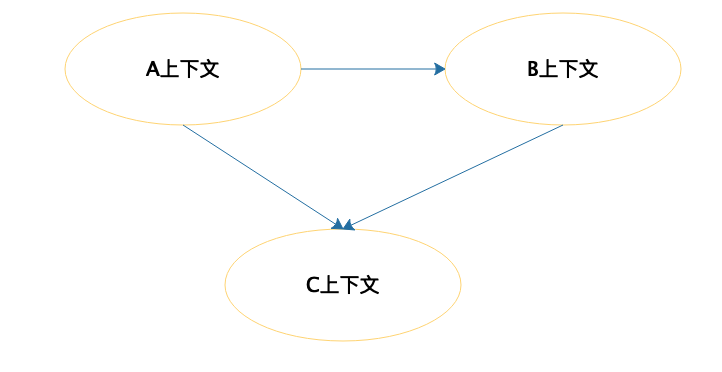
但是如果我们说要对C2C电子商务这个领域进行建模设计,那么这个范围就太大了,不知道该如何下手。所以通常的做法是把整个领域拆分成多个子域 ,比如用户、商品、订单、库存、物流、发票等。强相关的多个子域组成一个限界上下文,限界上下文是对业务领域范围的描述,对于系统实现而言,可以想象成相当于是一个子系统或者是一个模块。限界上下文和子域共同组成组织的领域,如下:
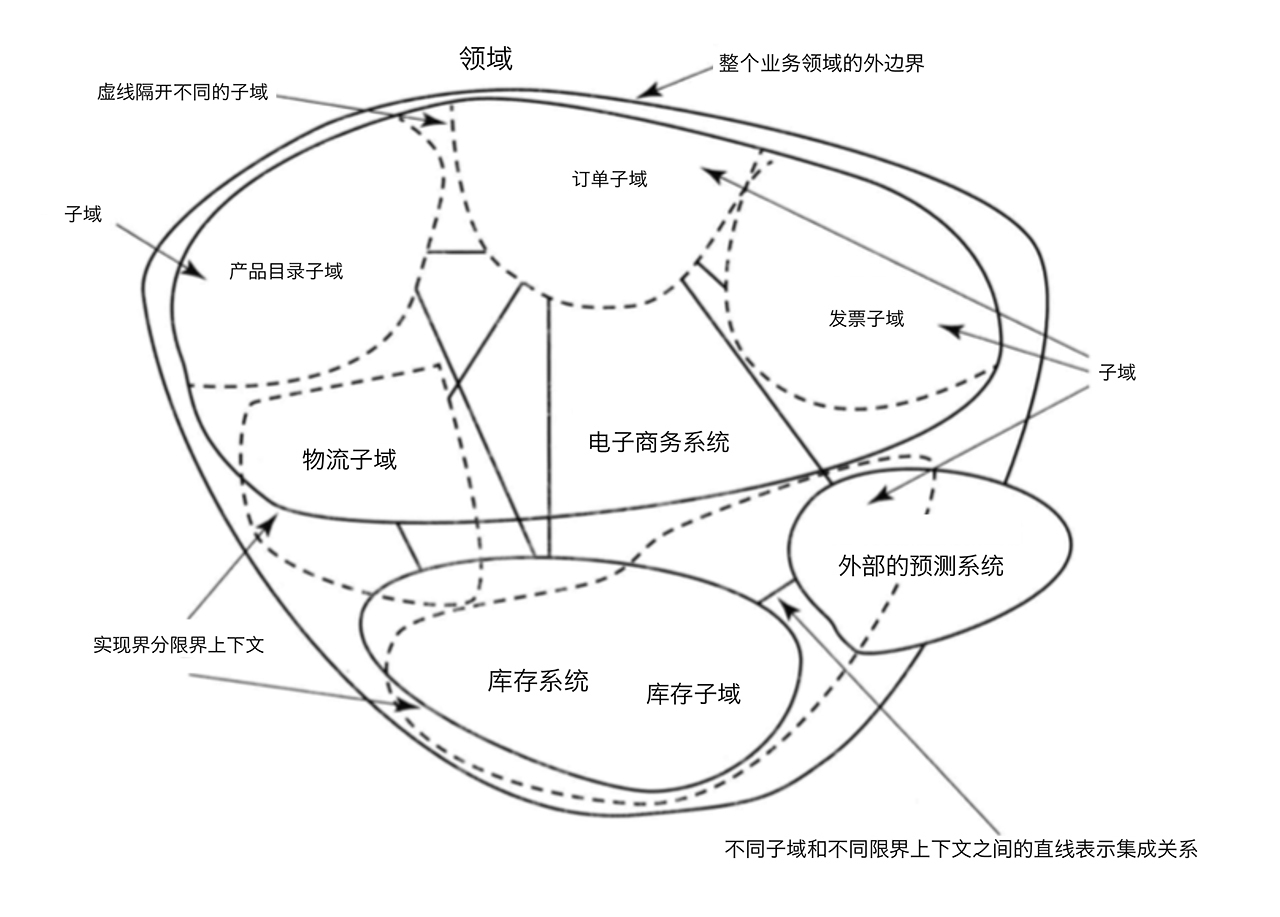
不同的限界上下文,也就是不同的子系统或者模块之间会有各种的交互合作。如何设计这些交互合作呢?DDD使用上下文映射图来完成,如下:
在DDD中,领域模型对象也被称为实体,每个实体都是唯一的,具有一个唯一标识,一个订单对象是一个实体,一个产品对象也是一个实体,订单ID或者产品ID是它们的唯一标识。实体可能会发生变化,比如订单的状态会变化,但是它们的唯一标识不会变化。
实体设计是DDD的核心所在,首先通过业务分析,识别出实体对象,然后通过相关的业务逻辑设计实体的属性和方法。这里最重要的,是要把握住实体的特征是什么,实体应该承担什么职责,不应该承担什么职责,分析的时候要放在业务场景和限界上下文中,而不是想当然地认为这样的实体就应该承担这样的角色。
事实上,并不是领域内的对象都应该被设计为实体,DDD推荐尽可能将对象设计为值对象。比如像住址这样的对象就是典型的值对象,也许建在住址上的房子可以被当做一个实体,但是住址仅仅是对房子的一个描述,像这样仅仅用来做度量或描述的对象应该被设计为值对象。
值对象的一个特点是不变性,一个值对象创建以后就不能再改变了。如果地址改变了,那就是一个新地址,而一个订单实体则可能会经历创建、待支付、已支付、代发货、已发货、待签收、待评价等各种变化。
领域实体和限界上下文包含了业务的主要逻辑,但是最终如何构建一个系统,如何将领域实体对外暴露,开发出一个完整的系统。事实上,DDD支持各种架构方案,比如典型的分层架构:
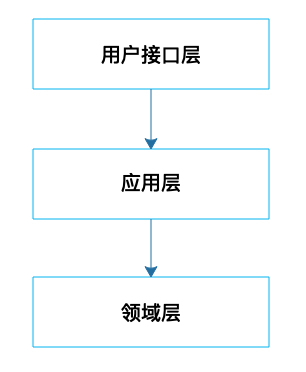
领域实体被放置在领域层,通过应用层对领域实体进行包装,最终提供一组访问接口,通过接口层对外开放。
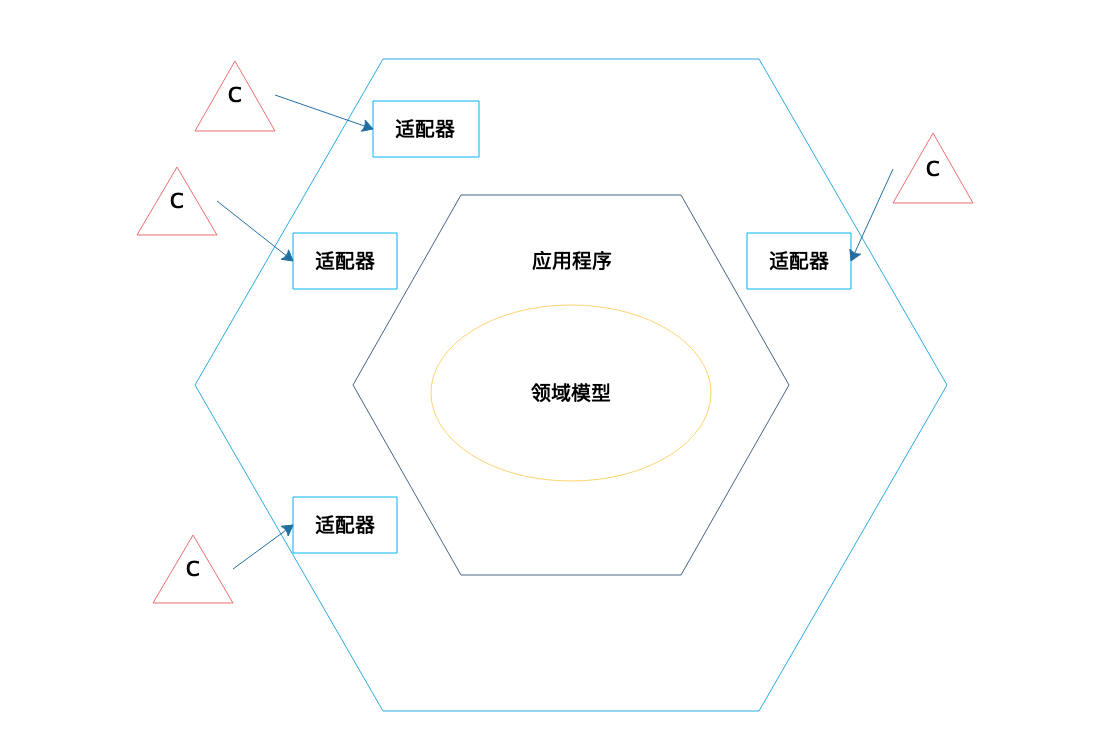
六边形架构是DDD中比较知名的一种架构方式,领域模型通过应用程序封装成一个相对比较独立的模块,而不同的外部系统则通过不同的适配器和领域模型交互,比如可以通过HTTP接口访问领域模型,也可以通过Web Service或者消息队列访问领域模型,只需要为这些不同的访问接口提供不同的适配器就可以了。
领域驱动设计的技术体系内还有其他一些方法和概念,但是最核心的还是领域模型本身,通过领域实体及其交互完成业务逻辑处理才是DDD的核心目标。至于是不是用了CQRS,是不是事件驱动,有没有事件溯源,并不是DDD的核心。
小结
回到我们的题目,一个35岁的程序员应该写什么样的代码?如果一个工作十多年的程序员,还是仅仅写一些跟他工作第一年差不多的CRUD代码。那么他迟早会遇到自己的职业危机。公司必然愿意用更年轻、更努力,当然也更低薪水的程序员来代替他。至于学习新技术的能力,其实多年工作经验也并没有太多帮助,有时候也许还是劣势。
在我看来,35岁的程序员真正有优势的是他在一个业务领域的多年积淀,对业务领域有更深刻的理解和认知。
那么如何将这些业务沉淀和理解反映到工作中,体现在代码中呢?也许可以尝试探索领域驱动设计。如果一个人有多年的领域经验,那么必然对领域模型设计有更深刻的认识,把握好领域模型在不断的需求变更中的演进,使系统维持更好的活力,并因此体现自己真正的价值。
思考题
你觉得大龄程序员的优势是什么?如何在公司保持自己的优势和地位?
答疑 对于设计模式而言,场景到底有多重要?
今天是第二模块的最后一讲。在这一讲中,我们主要讲了软件的设计原理,今天,我将会针对这一模块中大家提出的普遍问题进行总结和答疑。并且,我在最后列了一个书单,这个书单里涉及到的书,可能会对你学习设计模式有一些帮助。让我们整理一下,再接着学习下一个模块的内容。
问题答疑
我们先来看一个同学提出的问题。
@山猫
如果项目初始就对Button按钮进行这么复杂的设计,那么这么项目后期的维护成本也是相当之高。
答:
我们这个模块是讲设计的,这些设计原则都是用来解决需求变更的问题的。如果你为需求变更而进行了设计,但是预期中的需求变更却从来没有发生过,那么你的设计就属于设计过度;如果已经发生了需求变更,但是你却没有用灵活的设计方法去应对,而是通过硬编码的方式在既有代码上打补丁,那么这就是设计不足。
因此,是否要使用各种设计原则和设计模式去设计一个非常灵活的程序,主要是看你的需求场景。如果你的场景就是需要灵活,就是要各种复用,应对各种变更,那么一开始就应该这样设计。如果你的场景根本不需要一个可复用的Button,那么就不需要这样设计。
所以关键还是看场景。
但是场景也会变化,一开始不需要复用,但是后来又需要复用了,那么就需要在复用的第一个场景去重构代码,而不是等将来困难局面hold不住了再重构。
同时,设计原则和设计模式只是让代码看起来复杂了,毕竟一个接口好几个实现,看起来不如if-else来得直接。但是如果习惯了这种灵活的设计,你会觉得这种设计并不复杂。对于软件开发而言,复杂的永远是业务逻辑,而不是设计模式。设计模式是可重复的,可重复的东西即使看起来复杂,熟悉了就会觉得很简单。
看起来复杂的设计模式就是用来解决维护困难这种问题的。因此正确使用设计模式,看起来复杂了,其实维护简单了,因为关系和边界更清晰了,你不需要在一堆强耦合的代码里搅来搅去。真正维护成本高的,其实是那些所谓的简单设计,牵一发动全身,稍不注意就是各种bug。
最终,一切都要看场景,只有合适的设计,不存在好的设计。分析场景,根据场景进行相应的设计。当然,你要先知道有哪些设计原则和设计模式可以用在这样的场景,这就是我们这个专栏模块的目的。
关于依赖倒置原则,评论区有一个精彩留言,分享给你。
留言回复则解释得更加直白:
另外,我在第13篇留了一道思考题:

很多人都回答正确了,但也有一些回答错误的。我这里说明一下。
正确答案为,BException是AException的子类。因为只有异常是子类,使用父类的地方catch异常的时候,才能catch到子类异常,也就是才满足里氏替换原则,能用子类替换父类。
最近几年,分布式架构、大数据、区块链、物联网、AI技术广泛流行。当我们说起软件开发的时候,提到的常常是这些宏大的技术架构。但是再宏大的技术也要落实到代码上,再厉害的技术终究要解决我们的业务问题。如果不能写出清晰、简单的代码,软件之间的耦合关系梳理不清楚,即使用了一些很炫酷的技术,软件开发可能还是会陷入混乱之中。
这些年,我也曾在一些知名的企业做过各种分布式系统、大数据平台开发,这些系统本身的架构也许有很大创新之处,但是真正使这些系统成功的,依然是低层那些干净、清晰的代码。这些年,我也见过一些知名的架构师、布道师,有些人也曾引领技术潮流,成为风口浪尖上的技术红人,但是真正能够一直走下去,走得远的,不是那些能给自己安了各种厉害头衔的人,而是那些能踏踏实实写出漂亮代码的人。
这个专栏的第二模块就是想传递这些信息,我们为什么要写好的代码,而不仅仅写能用的代码;以及什么叫好的代码,如何写出好的代码。
书籍推荐
人类编程的历史超过半个多世纪了,关于什么叫好的代码,如何写出好的代码也有很多研究,有许多的经典案例和著作。专栏中的内容主要都是来自这些经典的作品。
专栏第9篇文章,如何使用UML建模的内容主要来自《UML精粹》这本书。
其实UML本身非常简单,简单到我都觉得不值得专门阅读一本书去学习UML。UML真正需要学习的,是如何灵活使用UML去完成软件设计,如何用UML表述出自己的设计意图,以及在什么样的场景下用什么样的模型图去表述自己的设计意图。
马丁·福勒这本书也是偏重UML的实践应用,而不是讲UML语法本身如何。我的专栏文章内容则更多来自自己的一些最佳实践:如何用UML完成设计文档。应该说,我在十几年前,得以最早抓住机会跳出开发CRUD代码,去做一些大型系统的架构和框架开发工作,正是因为我用UML比较清晰地表述了系统当时的状况和设计目标,打动了项目的领导,放手让我一个资历尚浅的新人去做系统的架构设计,也因此而改变了自己的职业发展路径。我也期望UML能帮助你找到自己的职业跳跃之路。
专栏11~15篇文章,主要讲述软件设计的基本原则,这些内容主要来自《敏捷软件开发: 原则、模式与实践》。
作者罗伯特·C ·马丁,更知名的昵称是Bob大叔。这本书的名字叫《敏捷软件开发》,但是全书主要讲的是设计原则与设计模式。作者认为,我们能够进行敏捷开发,能够快速响应需求变更,不在于什么敏捷开发过程和敏捷项目管理,而在于敏捷的软件设计。如果代码一团糟,各种耦合,各种腐化,任你用什么项目管理手段都无济于事。
但如果你的代码灵活、强壮、易于维护和变更,可以轻松应对各种需求变更,那么敏捷的项目过程管理才能带来真正敏捷的效果。
应该说,我第一次读这本书的时候,它给我的震撼相当大。人们在软件开发中遇到困难,本能地想寻找一种轻松又强大的解决办法,什么管理方法啦,外部咨询啦,购买商业解决方案啦。但是,软件终究还是存在于工程师编写的一行行代码里,如果不把这些代码搞清楚,搞好,再好的外部支持只怕也帮不上什么忙。
第19篇内容也是来自罗伯特·C·马丁的一本比较新的书,叫《架构整洁之道》。
这本书算是Bob大叔架构思想的一本书,讲述关于架构的过往与现在,关于架构的各种思想原理。
第20篇的内容又是来自马丁·福勒的另一本经典著作《企业应用架构模式》。
这本书是讲述企业架构模式的集大成者,我们日常使用的各种开发技术,各种解决方案,都可以在这本书里找到来源。很多业界广泛使用的技术产品,Spring,MyBatis这些,只不过是这本书里很多架构模式的一种,而同类的模式还有很多,这些模式有的被淘汰,有的在进化。
看这本书里的各种架构模式,然后再想想这些模式背后的技术在这些年中的起起落落,感觉很是沧桑。
这就是第二模块中遗留的一些问题,无论是架构,还是软件开发,终归要落到人身上,落到人编写的一行行代码身上。我希望这个模块可以对你写代码有一些好的启发与提示。