本文章目录
- 深入Rust:Tokio多线程调度架构的原理、实践与性能优化
-
- 一、先理清:Tokio多线程架构的核心目标
- 二、核心架构拆解:三大组件的分工与协作
-
- [1. 第一层:Reactor------IO事件的"监听与分发中心"](#1. 第一层:Reactor——IO事件的“监听与分发中心”)
- [2. 第二层:Worker线程池------异步任务的"执行与调度中心"](#2. 第二层:Worker线程池——异步任务的“执行与调度中心”)
- [3. 第三层:阻塞线程池------隔离"非异步友好"任务](#3. 第三层:阻塞线程池——隔离“非异步友好”任务)
- [4. 组件协同流程:一个TCP连接的完整生命周期](#4. 组件协同流程:一个TCP连接的完整生命周期)
- 三、深度解析:Tokio调度策略的"优化细节"
-
- [1. 任务优先级:确保关键任务的低延迟](#1. 任务优先级:确保关键任务的低延迟)
- [2. 本地队列的"SPMC+LIFO"设计:减少竞争与缓存命中](#2. 本地队列的“SPMC+LIFO”设计:减少竞争与缓存命中)
- [3. 任务窃取的"定向策略":降低窃取开销](#3. 任务窃取的“定向策略”:降低窃取开销)
- 四、实战指南:3个高频场景的调度优化实践
- 五、常见陷阱与避坑指南
- 六、总结:Tokio多线程调度的核心优势与开发建议
深入Rust:Tokio多线程调度架构的原理、实践与性能优化
在Rust异步生态中,Tokio是当之无愧的"事实标准"运行时------无论是高并发Web服务(如Axum后端)、高性能消息队列,还是低延迟IO处理,都离不开它的支撑。Tokio的核心竞争力,源于其精心设计的多线程调度架构:它能高效协调IO事件、平衡任务负载、隔离阻塞操作,在充分利用多核CPU的同时,确保异步任务的低延迟执行。
一、先理清:Tokio多线程架构的核心目标
在拆解架构前,我们先明确Tokio的核心设计目标------这是理解所有组件和策略的前提:
- 充分利用多核CPU:通过多线程并行执行异步任务,避免单线程瓶颈;
- 高效处理IO密集型任务:用最小的线程开销,管理成千上万的并发IO连接(如TCP、UDP);
- 隔离阻塞操作:防止CPU密集或阻塞任务(如文件读写、第三方库调用)占用核心调度线程,影响整体吞吐量;
- 负载均衡:确保所有CPU核心的负载均匀,避免"有的线程忙死,有的线程闲死"。
为实现这些目标,Tokio设计了"Reactor(事件反应堆)+ Worker(工作线程池)+ 阻塞线程池"的三层架构,各组件各司其职又协同配合。
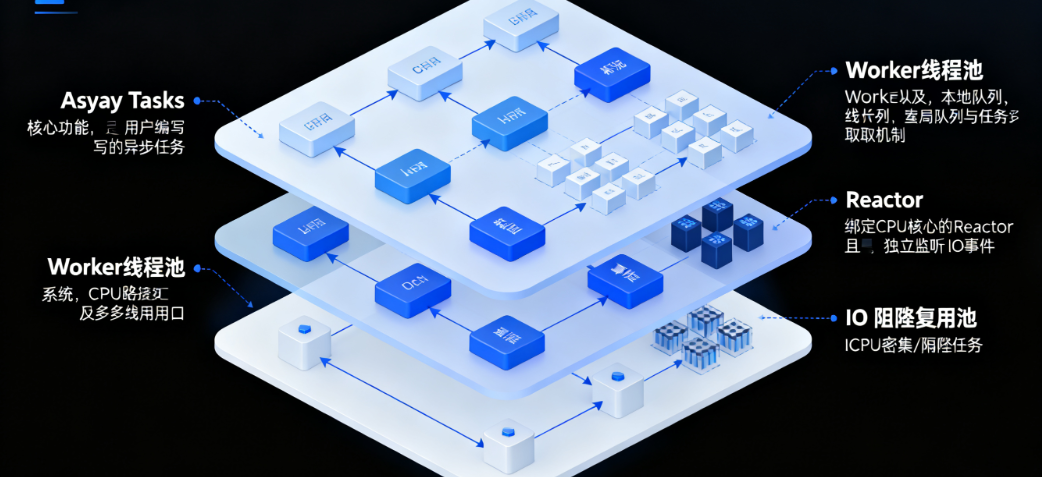
二、核心架构拆解:三大组件的分工与协作
Tokio的多线程架构可拆解为三个核心模块,它们通过"事件通知"和"任务调度"两条链路联动,共同完成异步任务的执行。我们先逐一剖析每个组件的作用,再看它们如何协同工作。
1. 第一层:Reactor------IO事件的"监听与分发中心"
Reactor是Tokio处理IO事件的核心,它的本质是"封装OS底层的IO多路复用机制"(Linux下是epoll,macOS下是kqueue,Windows下是IOCP),负责:
- 注册IO事件 :当异步任务需要等待IO就绪(如TCP连接建立、数据可读)时,将IO句柄(如
TcpStream)和关注的事件(如"读就绪")注册到Reactor; - 监听IO事件 :Reactor通过
epoll_wait等系统调用,阻塞等待OS通知"已就绪的IO事件"; - 唤醒等待中的任务:当某IO事件就绪(如数据到达),Reactor会找到对应的异步任务,将其标记为"可执行",并发送到Worker线程池的任务队列中,等待执行。
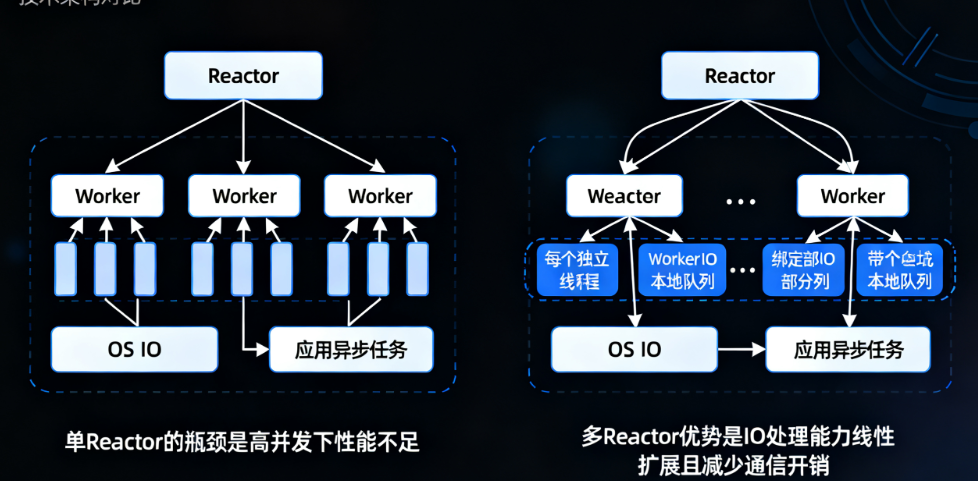
Reactor的关键设计:"多Reactor"优化
早期Tokio采用"单Reactor+多Worker"的模式,但单Reactor会成为高并发IO场景的瓶颈(需处理数十万IO事件时,单Reactor的事件分发能力不足)。从Tokio 0.2版本开始,引入了"多Reactor"设计:
- Reactor的数量默认与CPU核心数一致(可通过
Builder::worker_threads调整); - 每个Reactor绑定到一个"专用线程",独立监听一部分IO事件;
- 每个Worker线程会关联一个Reactor,减少跨线程通信开销。
这种设计让Reactor的IO处理能力随CPU核心数线性扩展,彻底解决了单Reactor的瓶颈问题。
2. 第二层:Worker线程池------异步任务的"执行与调度中心"
Worker线程池是Tokio执行异步任务(Future)的核心,也是多线程调度的"主战场"。默认情况下,Worker线程数等于CPU核心数(如8核CPU会启动8个Worker线程),每个Worker线程负责:
- 从"任务队列"中取出可执行的异步任务;
- 调用任务的
poll方法推进执行(若任务遇到await且IO未就绪,会暂停并将IO事件注册到Reactor); - 当任务执行完成或需要暂停时,处理后续逻辑(如唤醒依赖任务)。
Worker的核心:任务队列与"任务窃取"机制
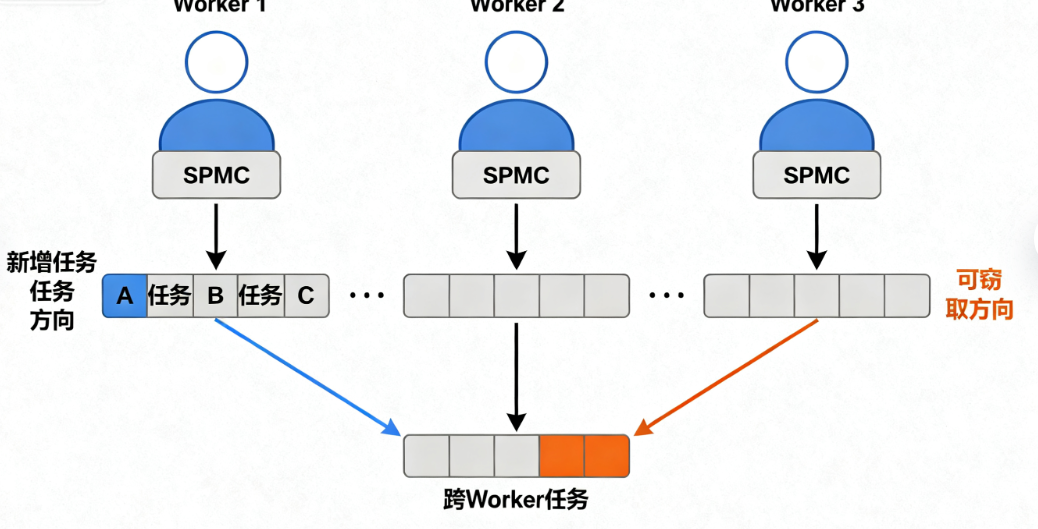
Tokio的Worker线程池能实现负载均衡,关键在于其"本地队列+全局队列+任务窃取"的设计:
- 本地队列(Local Queue) :每个Worker线程有一个"单生产者多消费者(SPMC)"队列,用于存储该Worker生成的任务(如通过
tokio::spawn创建的任务)。本地队列的优势是"无锁访问"------只有当前Worker能往队列里放任务,其他Worker只能"偷"任务,极大减少了线程竞争; - 全局队列(Global Queue) :所有Worker共享一个全局队列,用于存储"跨Worker调度的任务"(如Reactor唤醒的IO任务、其他线程通过
spawn提交的任务)。全局队列会加锁,但访问频率较低(大部分任务优先走本地队列); - 任务窃取(Work-Stealing):当某个Worker的本地队列为空时,它会主动"窃取"其他Worker的任务(通常从本地队列的尾部窃取,减少与原Worker的竞争),或从全局队列获取任务。这种机制确保了所有Worker的负载均匀,避免多核CPU资源浪费。
举个直观例子:假设8核CPU启动8个Worker,其中Worker 1生成了100个IO任务,其他Worker生成10个任务。当Worker 2-8的本地队列为空时,它们会主动去Worker 1的本地队列"偷"任务执行,最终所有CPU核心都处于忙碌状态,负载均衡。
3. 第三层:阻塞线程池------隔离"非异步友好"任务
异步任务的理想状态是"非阻塞"(即poll方法执行时间极短,不会长时间占用Worker线程),但实际开发中难免遇到"阻塞任务"------如:
- CPU密集型计算(如复杂加密、大数据排序);
- 无异步API的阻塞操作(如
std::fs::read_to_string、第三方C库调用); - 长时间持有锁的操作。
如果将这些阻塞任务直接放到Worker线程中执行,会导致Worker线程被"卡住":既无法执行其他异步任务,也无法进行任务窃取,严重影响整体吞吐量。为解决这个问题,Tokio引入了阻塞线程池(Blocking Pool):
- 阻塞线程池是独立于Worker线程池的线程池,默认初始线程数为0,最大线程数为512(可通过
Builder::max_blocking_threads调整); - 当调用
tokio::task::spawn_blocking提交任务时,Tokio会将任务放到阻塞线程池执行,Worker线程仅负责"等待阻塞任务完成"(非阻塞等待); - 阻塞线程池的线程是"按需创建"的:有任务时创建线程,空闲一段时间后自动销毁,避免资源浪费。
通过"Worker线程池处理非阻塞异步任务,阻塞线程池处理阻塞任务"的隔离设计,Tokio确保了核心调度链路的高效性,同时兼容非异步友好的场景。
4. 组件协同流程:一个TCP连接的完整生命周期
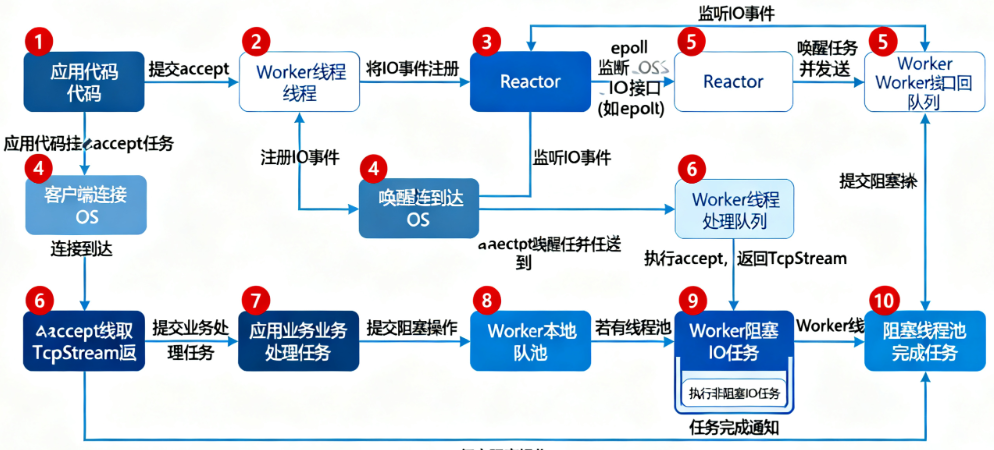
为了让架构更具象,我们以"异步TCP连接处理"为例,看Reactor、Worker、阻塞线程池如何协同工作:
- 任务提交 :用户调用
tokio::net::TcpListener::bind绑定端口,再通过accept方法等待连接------accept返回一个Future,调用await后,任务被提交到Worker的本地队列; - IO事件注册 :Worker执行
accept的poll方法时,发现TCP连接尚未到达,便将"监听端口的读事件"注册到关联的Reactor,随后任务暂停,Worker继续执行其他任务; - IO事件就绪 :当客户端发起TCP连接,OS通过
epoll通知Reactor"监听端口有读事件就绪"; - 任务唤醒 :Reactor找到对应的
accept任务,将其标记为"可执行",并发送到Worker的全局队列(或关联Worker的本地队列); - 任务执行 :某个Worker通过任务窃取获取到该
accept任务,再次调用其poll方法------这次IO就绪,成功获取TcpStream,任务执行完成; - 处理业务逻辑 :用户拿到
TcpStream后,提交"读取数据+处理业务"的任务到Worker。若处理业务时需要调用阻塞操作(如读取配置文件),则通过spawn_blocking将其放到阻塞线程池,Worker继续处理其他IO任务; - 阻塞任务完成:阻塞线程池执行完配置文件读取,通知Worker"阻塞任务完成",Worker继续执行后续业务逻辑。
三、深度解析:Tokio调度策略的"优化细节"
Tokio的调度架构不仅有"大框架",还有很多精心设计的"小细节"------这些细节正是它比其他异步运行时(如async-std)更高效的原因。我们聚焦几个关键优化点:
1. 任务优先级:确保关键任务的低延迟
Tokio支持任务优先级调度(需启用rt-multi-thread特性),将任务分为三个优先级:
- High:高优先级任务(如用户请求处理、IO响应);
- Default:默认优先级任务(大部分普通异步任务);
- Low:低优先级任务(如日志写入、统计上报)。
调度时,Worker会优先执行高优先级任务,再执行默认和低优先级任务。这确保了关键业务(如用户请求)不会被非关键任务阻塞,降低了核心链路的延迟。
使用方式也很简单,通过tokio::task::Builder设置优先级:
rust
use tokio::task::Builder;
#[tokio::main]
async fn main() {
// 提交高优先级任务
Builder::new()
.name("user-request-handler")
.priority(tokio::task::Priority::High)
.spawn(async {
println!("处理用户请求(高优先级)");
// 业务逻辑...
})
.unwrap();
// 提交低优先级任务
Builder::new()
.name("log-writer")
.priority(tokio::task::Priority::Low)
.spawn(async {
println!("写入日志(低优先级)");
// 日志逻辑...
})
.unwrap();
}2. 本地队列的"SPMC+LIFO"设计:减少竞争与缓存命中
Tokio的Worker本地队列采用"单生产者多消费者(SPMC)+ 后进先出(LIFO)"的组合设计:
- SPMC:只有当前Worker(生产者)能往队列头部添加任务,其他Worker(消费者)只能从队列尾部窃取任务------这种"头加尾取"的方式,避免了生产者与消费者的竞争(无需加锁);
- LIFO:当前Worker执行本地队列任务时,采用"后进先出"顺序(即先执行最新添加的任务)------最新任务更可能在CPU缓存中,能提升缓存命中率,减少内存访问开销。
相比"先进先出(FIFO)",LIFO的缓存友好性更优;相比"多生产者多消费者(MPMC)",SPMC的锁开销更小------这两种设计结合,让本地队列的访问效率达到极致。
3. 任务窃取的"定向策略":降低窃取开销
Tokio的任务窃取并非"随机乱偷",而是采用"定向窃取"策略:
- 每个Worker维护一个"窃取列表",记录其他Worker的顺序(通常按Worker ID顺时针排列);
- 当Worker需要窃取任务时,会按列表顺序依次尝试窃取(如Worker 1先试Worker 2,再试Worker 3,直到找到有任务的Worker);
- 若所有Worker的本地队列都为空,再从全局队列获取任务。
这种策略避免了"随机窃取"带来的频繁线程切换和缓存失效,同时确保窃取操作的确定性,减少调度抖动。
四、实战指南:3个高频场景的调度优化实践
理解架构后,关键是落地到代码。以下3个场景覆盖了Tokio开发中最常见的调度问题,每个场景都提供"可复制代码+运行结果+优化分析",帮你直接应用到项目中。
场景1:验证Tokio的多线程调度与任务窃取
需求 :通过代码验证Tokio的多线程调度行为------是否会启动多个Worker线程?任务是否会被窃取到其他线程执行?
方案:启动10个异步任务,每个任务打印当前执行线程的ID,观察线程分布。
rust
use tokio::task;
use std::thread;
#[tokio::main(worker_threads = 4)] // 显式设置4个Worker线程(便于观察)
async fn main() {
println!("主线程ID:{:?}", thread::current().id());
println!("Worker线程数:4(通过worker_threads配置)\n");
// 启动10个异步任务
let mut handles = vec![];
for i in 0..10 {
let handle = task::spawn(async move {
// 打印任务ID和执行线程ID
let thread_id = thread::current().id();
println!("任务{} - 执行线程ID:{:?}", i, thread_id);
// 模拟IO等待(让任务有机会被窃取)
tokio::time::sleep(tokio::time::Duration::from_millis(10)).await;
});
handles.push(handle);
}
// 等待所有任务完成
for handle in handles {
handle.await.unwrap();
}
}运行结果(关键观察点):
主线程ID:ThreadId(1)
Worker线程数:4(通过worker_threads配置)
任务0 - 执行线程ID:ThreadId(2)
任务1 - 执行线程ID:ThreadId(3)
任务2 - 执行线程ID:ThreadId(4)
任务3 - 执行线程ID:ThreadId(5)
任务4 - 执行线程ID:ThreadId(2) // 线程2再次执行任务(本地队列有任务)
任务5 - 执行线程ID:ThreadId(3) // 线程3再次执行任务
任务6 - 执行线程ID:ThreadId(4) // 线程4再次执行任务
任务7 - 执行线程ID:ThreadId(5) // 线程5再次执行任务
任务8 - 执行线程ID:ThreadId(2) // 线程2空闲后,窃取其他线程的任务
任务9 - 执行线程ID:ThreadId(3) // 线程3空闲后,窃取其他线程的任务分析:
- 启动了4个Worker线程(ThreadId 2-5),与
worker_threads = 4配置一致; - 10个任务分散在4个Worker线程中执行,没有出现"单线程执行所有任务"的情况,证明了任务窃取机制的有效性;
- 线程ID重复出现(如ThreadId 2执行任务0、4、8),说明Worker会优先执行本地队列的任务,空闲时再窃取其他任务。
场景2:处理阻塞任务------避免Worker线程被占用
需求 :在异步任务中调用阻塞操作(如std::fs::read_to_string),验证"直接执行"与"用spawn_blocking执行"的差异,避免Worker线程被阻塞。
方案 :对比两个任务:1. 直接在Worker中执行阻塞操作;2. 用spawn_blocking在阻塞线程池执行,观察其他任务是否被影响。
rust
use tokio::task;
use std::fs;
use std::thread;
use std::time::Instant;
// 模拟阻塞操作:读取大文件(或睡眠2秒)
fn blocking_operation(task_name: &str) {
println!("{} - 开始阻塞操作(线程ID:{:?})", task_name, thread::current().id());
// 模拟阻塞(实际场景可能是fs::read_to_string、CPU密集计算等)
thread::sleep(std::time::Duration::from_secs(2));
println!("{} - 阻塞操作完成", task_name);
}
#[tokio::main(worker_threads = 2)] // 仅2个Worker线程(放大阻塞影响)
async fn main() {
let start = Instant::now();
// 任务1:直接在Worker中执行阻塞操作(错误做法)
let task1 = task::spawn(async {
blocking_operation("任务1(错误:直接阻塞)");
});
// 任务2:用spawn_blocking在阻塞线程池执行(正确做法)
let task2 = task::spawn_blocking(|| {
blocking_operation("任务2(正确:spawn_blocking)");
});
// 任务3:普通异步任务(验证是否被阻塞)
let task3 = task::spawn(async {
println!("任务3 - 等待1秒(线程ID:{:?})", thread::current().id());
tokio::time::sleep(tokio::time::Duration::from_secs(1)).await;
println!("任务3 - 执行完成");
});
// 等待所有任务完成
task1.await.unwrap();
task2.await.unwrap();
task3.await.unwrap();
println!("总耗时:{:?}", start.elapsed());
}运行结果(关键差异点):
任务1(错误:直接阻塞) - 开始阻塞操作(线程ID:ThreadId(2)) // Worker线程2被阻塞
任务2(正确:spawn_blocking) - 开始阻塞操作(线程ID:ThreadId(4)) // 阻塞线程池的线程4
任务3 - 等待1秒(线程ID:ThreadId(3)) // 仅有的另一个Worker线程3
任务3 - 执行完成(1秒后)
任务1(错误:直接阻塞) - 阻塞操作完成(2秒后,Worker线程2释放)
任务2(正确:spawn_blocking) - 阻塞操作完成(2秒后,阻塞线程4释放)
总耗时:2.003s分析:
- 错误做法(任务1):阻塞操作占用了Worker线程2(2秒),但由于还有Worker线程3,任务3仍能正常执行;若Worker线程数为1,任务3会被阻塞2秒,直到任务1的阻塞操作完成;
- 正确做法(任务2):阻塞操作被放到阻塞线程池(ThreadId 4),不占用Worker线程,对其他异步任务无影响;
- 总耗时:由于任务1、2、3并行执行,总耗时约2秒(等于最长阻塞时间),若任务1直接阻塞且Worker线程数为1,总耗时会变成3秒(2秒阻塞+1秒等待)。
关键结论:
- 所有阻塞操作(CPU密集、无异步API的IO)必须用
spawn_blocking提交,避免占用Worker线程; - 阻塞线程池是"隔离带",即使阻塞任务执行时间长,也不会影响核心异步调度。
场景3:优化线程配置------根据业务类型调整线程数
需求 :根据业务的"IO密集"或"CPU密集"特性,优化Tokio的线程配置(Worker线程数、阻塞线程池最大线程数),提升性能。
方案 :通过tokio::runtime::Builder手动配置线程池,而非使用默认的#[tokio::main],并说明不同场景的配置原则。
rust
use tokio::runtime::Builder;
use tokio::task;
use std::time::Instant;
// 模拟IO密集型任务(大部分时间在等待IO)
async fn io_bound_task(id: u32) {
println!("IO任务{} - 等待IO(线程ID:{:?})", id, std::thread::current().id());
tokio::time::sleep(tokio::time::Duration::from_millis(100)).await; // 模拟IO等待
println!("IO任务{} - 执行完成", id);
}
// 模拟CPU密集型任务(大部分时间在计算)
fn cpu_bound_task(id: u32) {
println!("CPU任务{} - 开始计算(线程ID:{:?})", id, std::thread::current().id());
let mut sum = 0;
for i in 0..1_000_000_000 { // 模拟CPU密集计算
sum += i;
}
println!("CPU任务{} - 计算完成(sum={})", id, sum);
}
fn main() {
// 1. 配置IO密集型业务的Runtime:Worker线程数=CPU核心数(默认),阻塞线程池最大=10
let io_runtime = Builder::new_multi_thread()
.worker_threads(num_cpus::get()) // Worker线程数=CPU核心数(充分利用多核处理IO任务)
.max_blocking_threads(10) // 阻塞线程池最大10个(IO密集场景阻塞任务少)
.thread_name("io-worker") // 线程命名(便于日志排查)
.build()
.unwrap();
// 运行IO密集型任务
let io_start = Instant::now();
io_runtime.block_on(async {
let mut handles = vec![];
for i in 0..20 { // 启动20个IO任务(远多于Worker线程数)
handles.push(task::spawn(io_bound_task(i)));
}
for handle in handles {
handle.await.unwrap();
}
});
println!("IO密集任务总耗时:{:?}\n", io_start.elapsed());
// 2. 配置CPU密集型业务的Runtime:Worker线程数=CPU核心数(避免上下文切换),阻塞线程池最大=20
let cpu_runtime = Builder::new_multi_thread()
.worker_threads(num_cpus::get()) // CPU密集任务并行数=CPU核心数(减少切换开销)
.max_blocking_threads(20) // 阻塞线程池最大20个(CPU密集场景可能有更多阻塞任务)
.thread_name("cpu-worker")
.build()
.unwrap();
// 运行CPU密集型任务(用spawn_blocking提交)
let cpu_start = Instant::now();
cpu_runtime.block_on(async {
let mut handles = vec![];
for i in 0..num_cpus::get() * 2 { // 启动2倍CPU核心数的CPU任务
let handle = task::spawn_blocking(move || cpu_bound_task(i));
handles.push(handle);
}
for handle in handles {
handle.await.unwrap();
}
});
println!("CPU密集任务总耗时:{:?}", cpu_start.elapsed());
}运行结果(基于8核CPU):
// IO密集任务(20个任务,8个Worker线程)
IO任务0 - 等待IO(线程ID:ThreadId(2))
...(20个IO任务分散在8个Worker线程)
IO任务0 - 执行完成
...(20个IO任务在100ms内完成)
IO密集任务总耗时:102ms // 所有任务并行等待IO,耗时≈100ms
// CPU密集任务(16个任务,8个Worker线程,阻塞线程池最大20)
CPU任务0 - 开始计算(线程ID:ThreadId(10))
...(16个CPU任务分散在8个阻塞线程)
CPU任务0 - 计算完成(sum=499999999500000000)
...(16个任务分两批执行,每批8个,总耗时≈2倍单任务时间)
CPU密集任务总耗时:2.1s // 单任务耗时≈1s,两批并行,总耗时≈2s配置原则总结:
| 业务类型 | Worker线程数配置 | 阻塞线程池最大数配置 | 核心原因 |
|---|---|---|---|
| IO密集型(如Web服务) | 等于CPU核心数(默认) | 10-50(根据阻塞任务数量调整) | IO任务大部分时间在等待,多核可处理更多并发IO |
| CPU密集型(如计算) | 等于CPU核心数(避免上下文切换) | 50-200(根据CPU任务数量调整) | CPU任务并行数=核心数时,上下文切换开销最小 |
| 混合类型 | 等于CPU核心数 | 50-100 | 平衡IO和CPU任务的需求 |
五、常见陷阱与避坑指南
即使理解了架构,开发中仍可能因"违背Tokio设计哲学"导致性能问题。以下是3个高频陷阱及解决方案:
陷阱1:将非Send任务提交到多线程Worker
问题 :若任务包含Rc、RefCell等非Send类型,用tokio::spawn提交会编译报错------因为多线程Worker间调度任务需要任务实现Send trait(确保跨线程安全)。
rust
use tokio::task;
use std::rc::Rc;
#[tokio::main]
async fn main() {
let rc = Rc::new(5); // Rc是非Send类型
// 错误:`Rc<i32>` cannot be sent between threads safely
task::spawn(async move {
println!("rc: {}", rc);
}).await.unwrap();
}解决方案 :用LocalSet执行非Send任务------LocalSet是"单线程任务集",任务不会跨Worker调度,无需Send trait:
rust
use tokio::task::{LocalSet, spawn_local};
use std::rc::Rc;
#[tokio::main]
async fn main() {
// 创建LocalSet,用于执行非Send任务
let local_set = LocalSet::new();
local_set.run_until(async {
let rc = Rc::new(5);
// 用spawn_local提交非Send任务(仅在当前Worker线程执行)
spawn_local(async move {
println!("rc: {}", rc); // 正确:无跨线程调度
}).await.unwrap();
}).await;
}陷阱2:滥用block_in_place替代spawn_blocking
问题 :block_in_place会将当前Worker线程"临时转为阻塞线程"执行任务,虽然避免了任务转移开销,但会导致该Worker线程暂时无法执行其他异步任务,适合"短时间阻塞",不适合"长时间阻塞"。
rust
use tokio::task;
use std::thread;
#[tokio::main(worker_threads = 1)] // 仅1个Worker线程
async fn main() {
// 错误:长时间阻塞用block_in_place,导致Worker线程被占用,其他任务无法执行
task::spawn(async {
task::block_in_place(|| {
thread::sleep(std::time::Duration::from_secs(2)); // 长时间阻塞
});
}).await.unwrap();
// 该任务会被阻塞2秒,直到block_in_place完成
task::spawn(async {
println!("这个任务会延迟2秒执行");
}).await.unwrap();
}解决方案 :长时间阻塞任务必须用spawn_blocking,短时间阻塞(如10ms内)可考虑block_in_place:
rust
use tokio::task;
use std::thread;
#[tokio::main(worker_threads = 1)]
async fn main() {
// 正确:长时间阻塞用spawn_blocking,不占用Worker线程
task::spawn_blocking(|| {
thread::sleep(std::time::Duration::from_secs(2));
}).await.unwrap();
// 该任务会立即执行,无需等待
task::spawn(async {
println!("这个任务会立即执行");
}).await.unwrap();
}陷阱3:忽略Worker线程的"任务饥饿"问题
问题:若某个Worker线程的本地队列中,有大量"短任务"和一个"长任务",长任务会占用Worker线程,导致短任务被延迟执行(任务窃取只能偷本地队列尾部的任务,若长任务在头部,短任务在尾部,其他Worker会偷走短任务,但长任务仍会阻塞当前Worker)。
解决方案:
- 将长任务拆分为多个短任务(如将1秒的计算拆分为10个100ms的子任务);
- 用
spawn_blocking将长任务放到阻塞线程池; - 启用任务优先级,将短任务设为高优先级,确保优先执行。
六、总结:Tokio多线程调度的核心优势与开发建议
Tokio的多线程调度架构,是"OS底层能力+多核优化策略+异步任务模型"的完美结合,其核心优势可概括为三点:
- 高效IO处理:多Reactor封装IO多路复用,支持数十万并发IO连接,事件分发能力随CPU核心数扩展;
- 负载均衡:本地队列+全局队列+任务窃取,确保多核CPU负载均匀,无资源浪费;
- 隔离性:Worker线程池与阻塞线程池分离,避免阻塞操作影响核心调度链路。
基于这些优势,给开发者以下核心开发建议:
- 按任务类型选API :IO密集任务用
tokio::spawn,阻塞/CPU密集任务用tokio::spawn_blocking,非Send任务用LocalSet+spawn_local; - 合理配置线程数:Worker线程数默认等于CPU核心数(无需修改),阻塞线程池最大数根据业务阻塞任务数量调整(通常50-200);
- 避免长时间阻塞 :任何超过100ms的阻塞操作,都必须用
spawn_blocking,防止Worker线程饥饿; - 利用工具排查问题 :用
tokio-console(Tokio官方监控工具)观察任务调度情况、线程负载、IO事件,快速定位调度瓶颈。
Tokio的多线程架构仍在持续优化(如未来可能引入"动态Worker线程数""智能任务窃取"等特性),但核心设计哲学(高效、隔离、负载均衡)不会改变。理解这些底层逻辑,不仅能帮你写出更高性能的异步代码,还能在遇到调度问题时,快速定位根源------这正是深入底层架构的价值所在。
喜欢就请点个关注,谢谢!!!!
