#LangGraph实现自适应RAGAgent TOC
原理
基于论文: arxiv.org/abs/2403.14...
核心点: Web搜索工具:针对近期事件的搜索 自适应RAG工具:针对知识库相关问题 路由器:判断问题交由Web搜索还是RAG处理
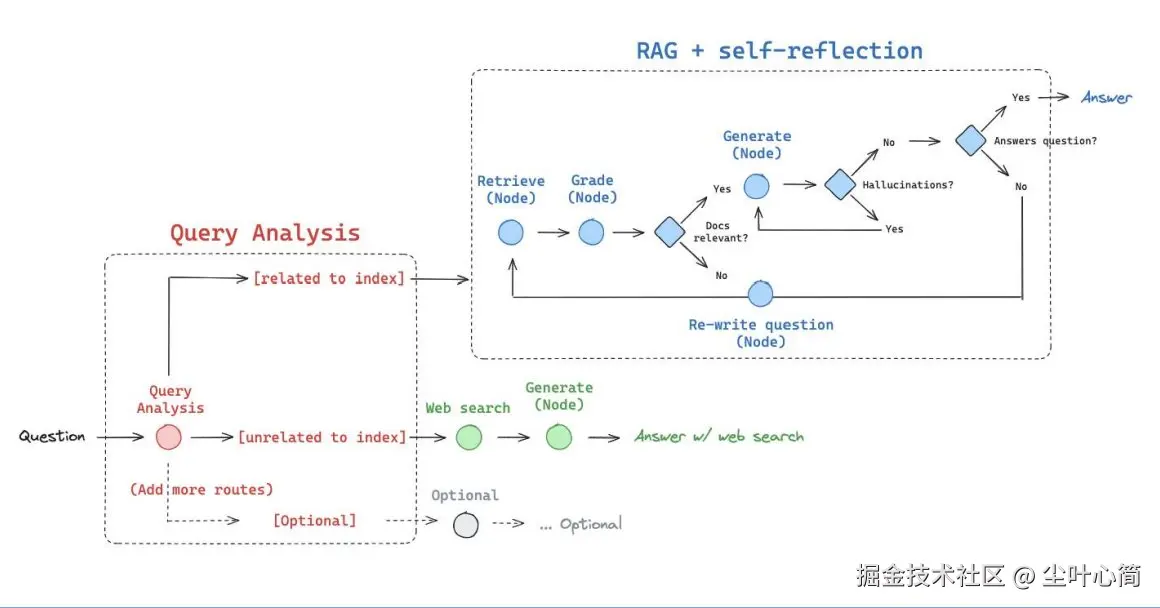
这幅图讲述了它的执行过程: 1.用户先提出一个问题。 2.路由器判断问题是要查最新事件还是知识库。 3.如果是最新事件,就走 Web 搜索工具。 4.如果是知识库问题,就走自适应 RAG 工具。 5.系统最后把结果整理好输出给用户。
Web搜索:Tavily

使用Tavily执行网络搜索,让LLM感知现实世界。
特点
快速响应:相比较搜索引擎能更快返回结果 良好摘要:无需加载页面的所有内容 结果优化:针对LLM优化的搜索结果,提高准确率 SaaS服务,需申请Key: app.tavily.com
这里我们创建AIOps的key,然后我们创建一个文件夹并创建一个
tavily.ipynb文件,然后安装相关依赖包。
bash
! pip install -U langgraph langchain-openai tavily-python langchain-community
下面在这段代码里,我主要是用 LangChain + LangGraph 搭建了一个最简单的智能体工作流。 核心思路是:先定义一个基于 GPT-4o 的模型,并给它绑定了 Tavily 搜索工具。然后通过一个路由函数来判断:如果模型生成的消息里包含工具调用,就跳转到工具节点执行,否则直接结束。整个流程被抽象成了一个 有条件的状态图(StateGraph),其中节点之间的关系用 add_node 和 add_edge 来描述。最后我把这个工作流编译运行,不仅可以流式输出查询结果(例如"2024 年深圳程序员平均薪酬"),还能绘制出整个流程图,直观地展示智能体在运行时的结构和逻辑。
python
import os
from langchain_openai import ChatOpenAI
from typing import Literal
from langchain_core.tools import tool
from IPython.display import Image, display
from langgraph.prebuilt import ToolNode
from langgraph.graph import StateGraph, MessagesState
from langchain_community.tools.tavily_search import TavilySearchResults
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGCHAIN_API_KEY"] = "你的Langchain的Key"
# LangSmith 项目名称,默认 default
os.environ["LANGCHAIN_PROJECT"] = "default"
# Tavily API Key
os.environ["TAVILY_API_KEY"] = "你的Tavily Key"
def call_model(state: MessagesState):
messages = state["messages"]
response = model_with_tools.invoke(messages)
return {"messages": [response]}
def should_continue(state: MessagesState) -> Literal["tools", "__end__"]:
messages = state["messages"]
last_message = messages[-1]
if last_message.tool_calls:
return "tools"
return "__end__"
tools = [TavilySearchResults(max_results=1)]
model_with_tools = ChatOpenAI(model="gpt-4o", temperature=0,
api_key="你的OpenAPI Key"
).bind_tools(tools)
tool_node = ToolNode(tools)
workflow = StateGraph(MessagesState)
workflow.add_node("agent", call_model)
workflow.add_node("tools", tool_node)
workflow.add_edge("__start__", "agent")
workflow.add_conditional_edges(
"agent",
should_continue,
)
workflow.add_edge("tools", "agent")
app = workflow.compile()
try:
display(Image(app.get_graph().draw_mermaid_png()))
except Exception:
pass
for chunk in app.stream(
{"messages": [("human", "2024年深圳程序员平均薪酬")]}, stream_mode="values"
):
chunk["messages"][-1].pretty_print()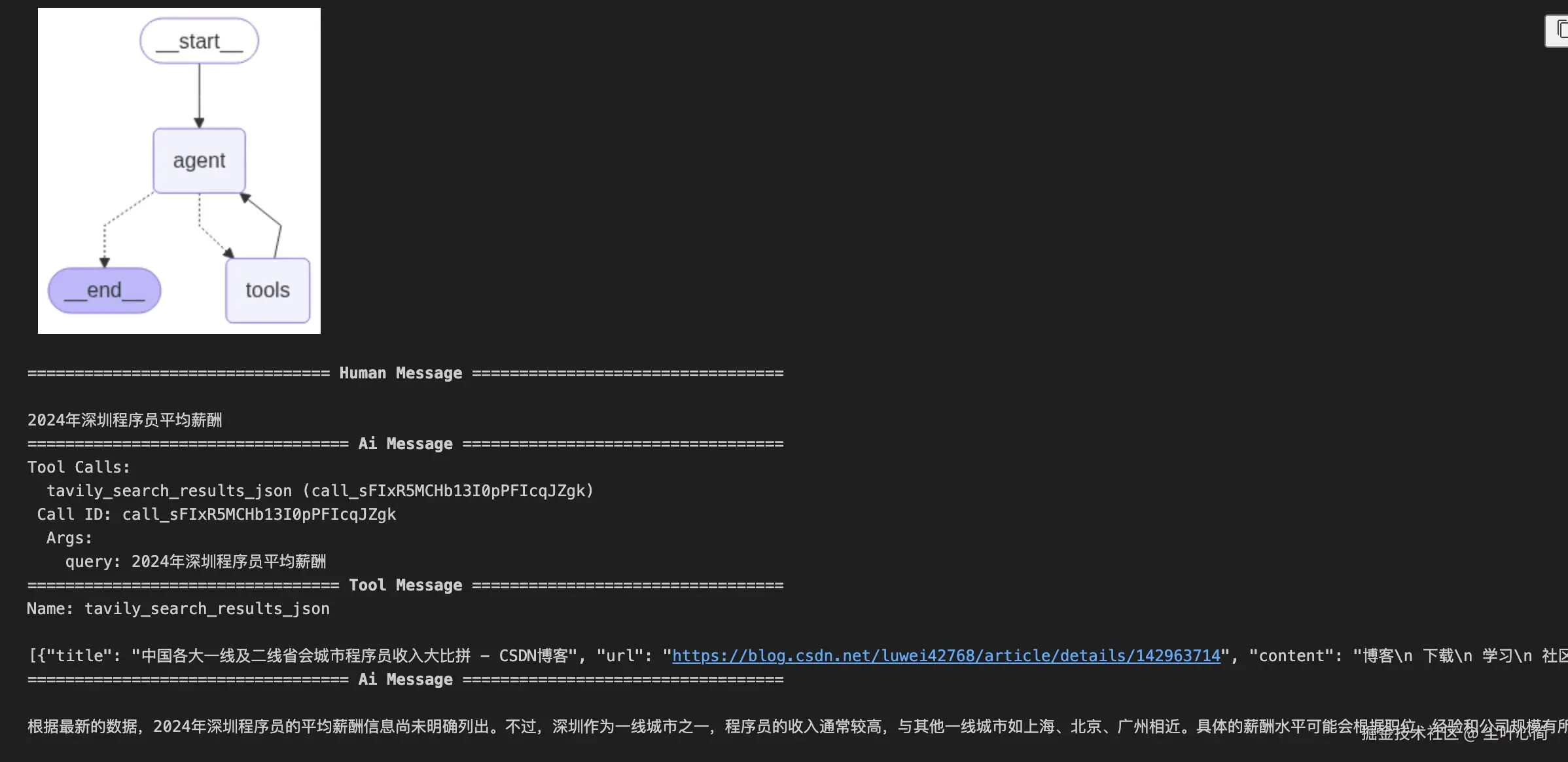
自适应RAG
基于论文: arxiv.org/abs/2310.11... 特点: ?对检索到的文档和生成的回答进行反思和评分,直到获得满意的回答 ?解决传统RAG粗暴检索固定数量段落以及回复准确性差的问题 ?显著提升长文本检索的准确性
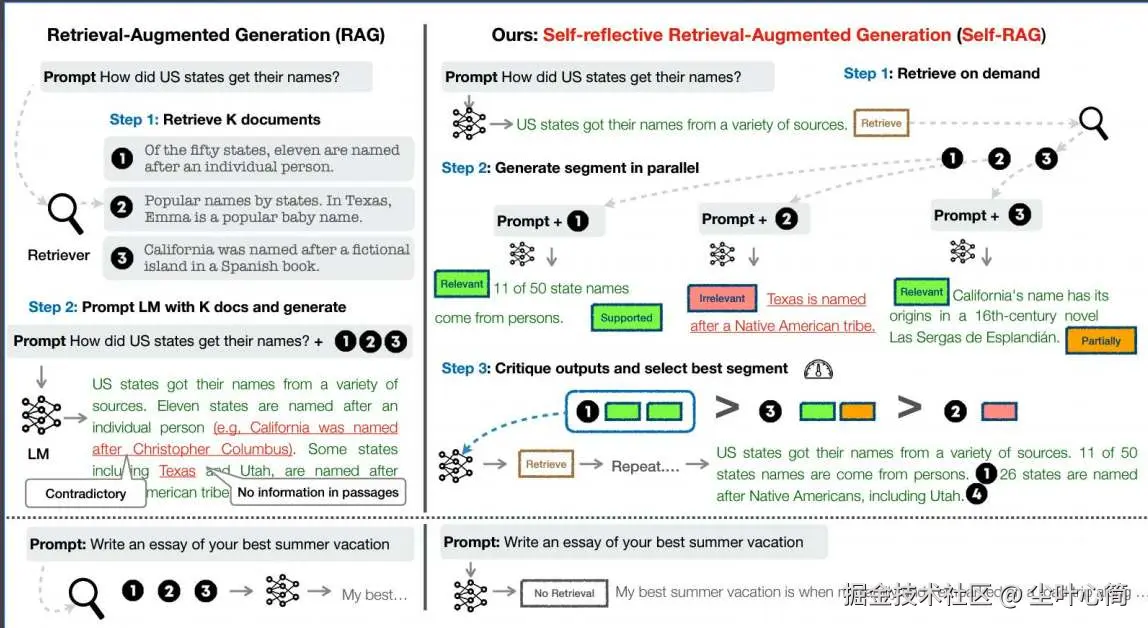
自适应RAG流程
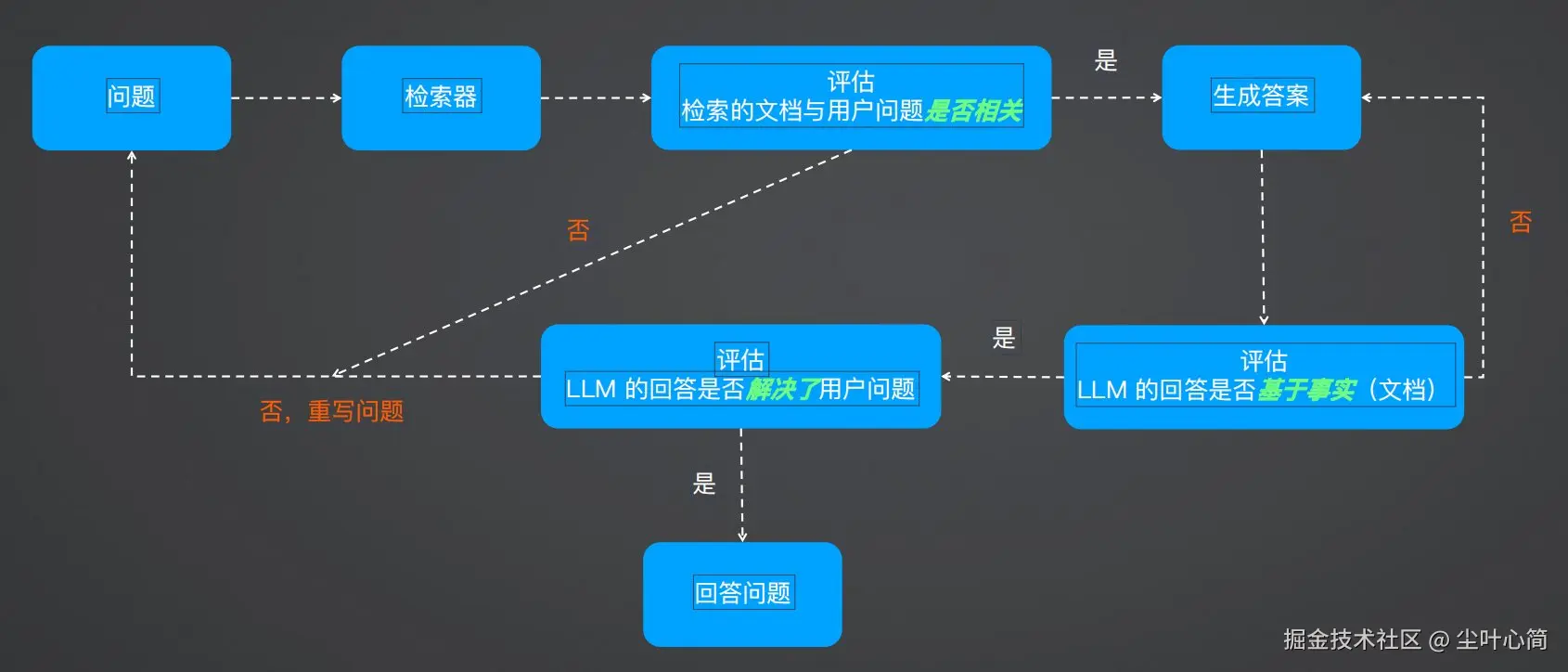
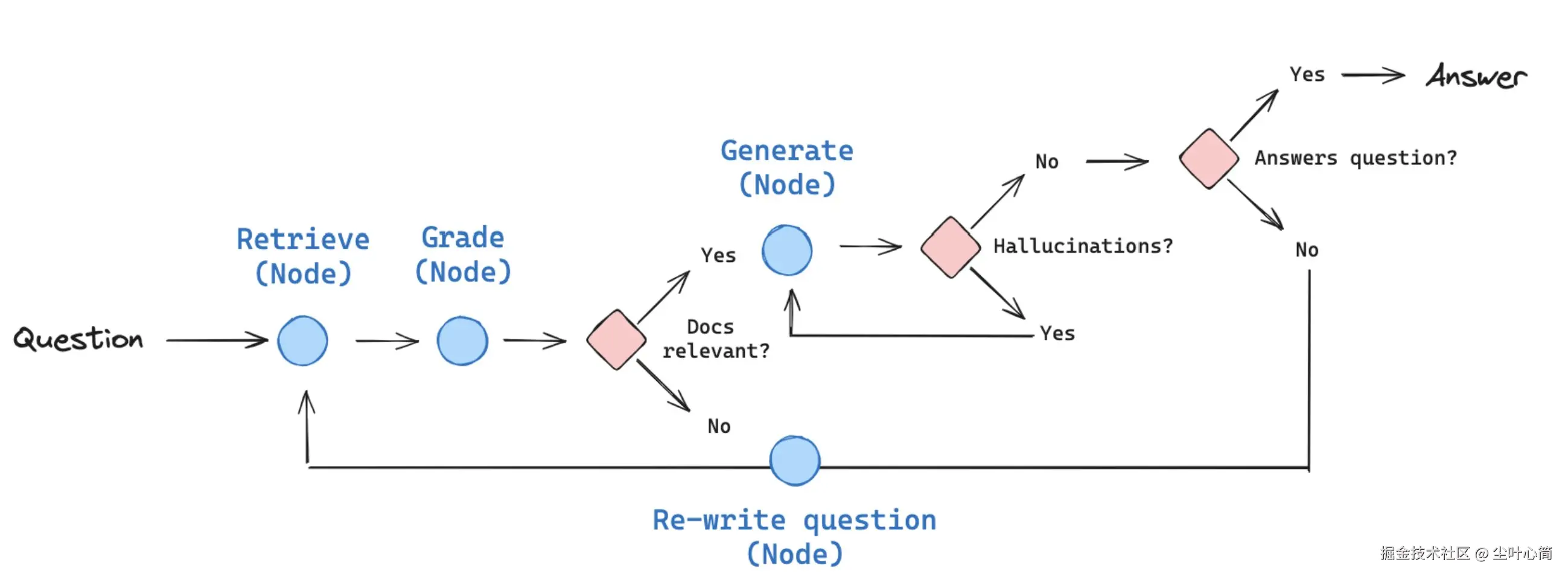
流程梳理
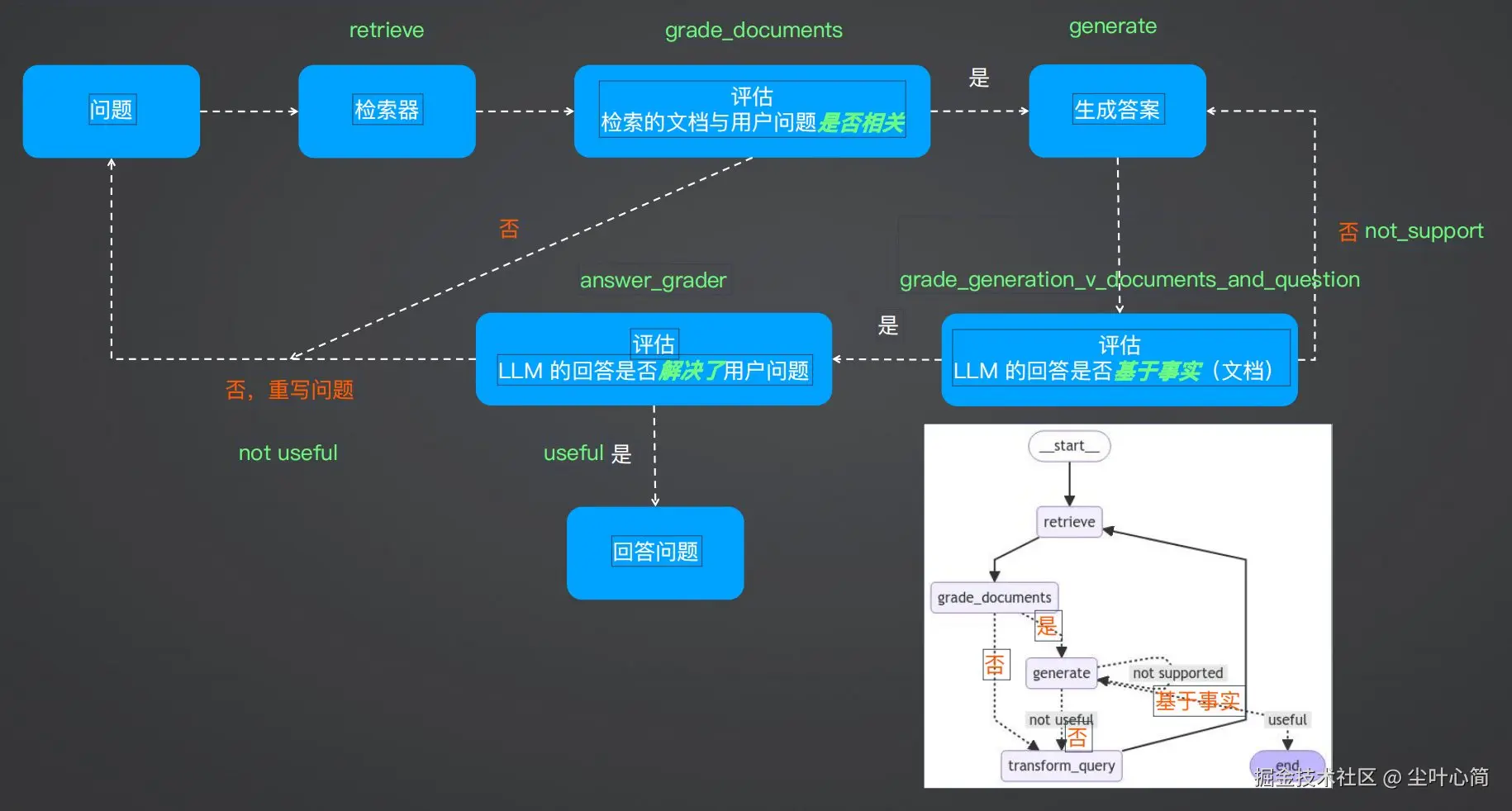
1.评估检索到的文档与用户问题是否相关 2.评估 LLM 回答的问题是否基于事实(检索到的文档) 3.评估 LLM 的回答是否解决了用户提出的问题 4.基于检索到的文档和用户问题,对用户问题进行优化
首先安装我们的包。
bash
! pip install -U langchain_community tiktoken langchain-openai langchainhub chromadb langchain langgraph
首先我们通过如下代码设置环境变量来配置 LangSmith 的追踪功能、接口地址、API Key 以及项目名称。
python
import os
from langchain_openai import ChatOpenAI
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGCHAIN_API_KEY"] = "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"
# LangSmith 项目名称,默认 default
os.environ["LANGCHAIN_PROJECT"] = "default"然后我们将我们的一个
data.md的文件放到data目录下面,按标题层级切分成小块后,用 OpenAI 向量模型生成向量,并存入 Chroma 向量数据库,最终构建出一个可用于检索的 retriever。
python
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain.text_splitter import MarkdownHeaderTextSplitter
import uuid
file_path = os.path.join('data', 'data.md')
with open(file_path, 'r', encoding='utf-8') as file:
docs_string = file.read()
# Split the document into chunks base on markdown headers.
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
text_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
doc_splits = text_splitter.split_text(docs_string)
# Add to vectorDB
random_directory = "./" + str(uuid.uuid4())
embedding = OpenAIEmbeddings(model="text-embedding-3-small",
openai_api_key="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"
)
vectorstore = Chroma.from_documents(documents=doc_splits, embedding=embedding, persist_directory=random_directory, collection_name="rag-chroma",)
retriever = vectorstore.as_retriever()接着通过定义 GradeDocuments 数据模型,把 LLM 封装成一个结构化输出的"文档评分器",然后针对用户问题逐个通过每个块评估检索到的文档是否相关,并返回 yes/no 的判定结果。
python
### 评估检索的文档与用户问题是否相关
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI
# Data model
class GradeDocuments(BaseModel):
"""Binary score for relevance check on retrieved documents."""
binary_score: str = Field(
description="Documents are relevant to the question, 'yes' or 'no'"
)
# LLM with function call
# 温度0,不需要输出多样性
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
structured_llm_grader = llm.with_structured_output(GradeDocuments)
# Prompt
system = """您是一名评分员,负责评估检索到的文档与用户问题的相关性。\n
测试不需要很严格。目标是过滤掉错误的检索。\n
如果文档包含与用户问题相关的关键字或语义含义,则将其评为相关。\n
给出二进制分数"yes"或"no",以指示文档是否与问题相关。"""
grade_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "Retrieved document: \n\n {document} \n\n User question: {question}"),
]
)
retrieval_grader = grade_prompt | structured_llm_grader
# 相关问题
question = "payment_backend 服务是谁维护的"
# 不相关问题
#question = "深圳天气"
docs = retriever.get_relevant_documents(question)
# 观察每一个文档块的相关性判断结果
for doc in docs:
print("doc: \n", doc.page_content, "\n")
print(retrieval_grader.invoke({"question": question, "document": doc.page_content}))
print("\n")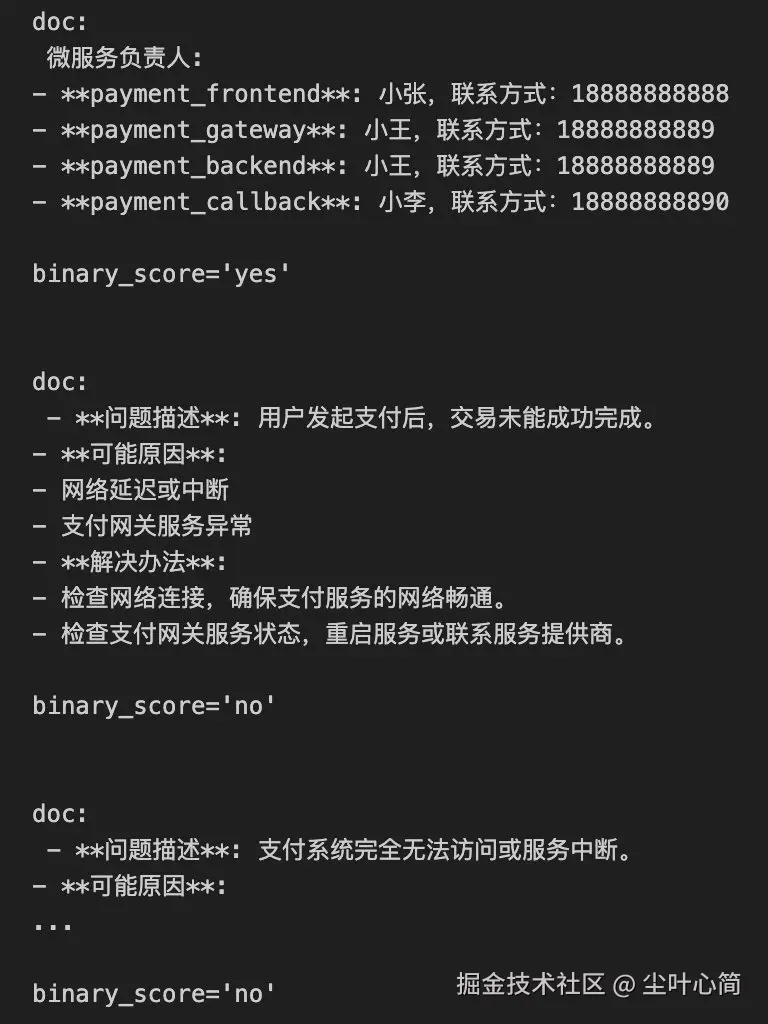
然后把 ChatOpenAI 包装成链,接收检索到的文档和用户问题作为输入,最后生成并输出结构化的回答字符串。
python
### 生成回复
from langchain import hub
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
# Prompt
prompt = hub.pull("rlm/rag-prompt")
# LLM
llm = ChatOpenAI(model_name="gpt-4o-mini",api_key="你的API Key",temperature=0)
# Post-processing
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# Chain
rag_chain = prompt | llm | StrOutputParser()
# Run
generation = rag_chain.invoke({"context": docs, "question": question})
print(generation)
下面代码通过定义 GradeHallucinations 数据模型,把 ChatOpenAI 封装成一个"事实校验器",用提示词让模型判断 生成的回答是否有依据于检索文档,并输出 yes/no 的结果。
python
# 评估LLM 的回答是否基于事实(文档)
# Data model
class GradeHallucinations(BaseModel):
"""Binary score for hallucination present in generation answer."""
binary_score: str = Field(
description="Answer is grounded in the facts, 'yes' or 'no'"
)
# LLM with function call
llm = ChatOpenAI(model="gpt-4o-mini",
api_key="你的Api Key",
temperature=0)
structured_llm_grader = llm.with_structured_output(GradeHallucinations)
# Prompt
system = """您是一名评分员,正在评估 LLM 生成是否基于一组检索到的事实/由一组检索到的事实支持。\n
给出二进制分数"yes"或"no"。 "yes"表示答案基于一组事实/由一组事实支持。"""
hallucination_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "Set of facts: \n\n {documents} \n\n LLM generation: {generation}"),
]
)
hallucination_grader = hallucination_prompt | structured_llm_grader
hallucination_grader.invoke({"documents": docs, "generation": generation})
运行结果为true,说明他是基于一个事实的回答。 接着使用代码定义了一个 GradeAnswer 数据模型,并结合 ChatOpenAI 和提示词,把 LLM 封装成一个"答案评审器",用于判断生成的回答是否真正解决了用户的问题,并返回 yes/no 的结果。
python
### 评估 LLM 的回答是否解决了用户问题
# Data model
class GradeAnswer(BaseModel):
"""Binary score to assess answer addresses question."""
binary_score: str = Field(
description="Answer addresses the question, 'yes' or 'no'"
)
# LLM with function call
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0,
api_key="你的api key",
)
structured_llm_grader = llm.with_structured_output(GradeAnswer)
# Prompt
system = """您是评分员,评估答案是否解决某个问题 \n
给出二进制分数"yes"或"no"。"yes"表示答案解决了问题。"""
answer_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "User question: \n\n {question} \n\n LLM generation: {generation}"),
]
)
answer_grader = answer_prompt | structured_llm_grader
answer_grader.invoke({"question": question, "generation": generation})
接下来代码利用 ChatOpenAI 搭配提示词,把用户原始问题重写成更适合 向量数据库检索 的优化版本,并保持和用户相同的语言输出。
python
### 结合知识库,重写问题(基于用户问题提出新的问题)
# LLM
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0,
api_key="你的api key",
)
# Prompt
system = """您有一个问题重写器,可将输入问题转换为针对 vectorstore 检索进行了优化的更好版本 \n
。查看输入并尝试推断底层语义意图/含义,使用用户语言回复。"""
re_write_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
(
"human",
"Here is the initial question: \n\n {question} \n Formulate an improved question.",
),
]
)
question_rewriter = re_write_prompt | llm | StrOutputParser()
question_rewriter.invoke({"question": question})
这样改写得更加合理。
完善节点相关代码
python
# 使用 LangGraph 构造 Agent
from typing import List
from typing_extensions import TypedDict
class GraphState(TypedDict):
"""
Represents the state of our graph.
Attributes:
question: question
generation: LLM generation
documents: list of documents
"""
question: str
generation: str
documents: List[str]
python
### Nodes 节点
# 检索文档
def retrieve(state):
"""
Retrieve documents
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, documents, that contains retrieved documents
"""
print("---RETRIEVE---")
question = state["question"]
# Retrieval
documents = retriever.get_relevant_documents(question)
return {"documents": documents, "question": question}
# 生成回复
def generate(state):
"""
Generate answer
Args:
state (dict): The current graph state
Returns:
state (dict): New key added to state, generation, that contains LLM generation
"""
print("---GENERATE---")
question = state["question"]
documents = state["documents"]
# RAG generation
generation = rag_chain.invoke({"context": documents, "question": question})
return {"documents": documents, "question": question, "generation": generation}
# 判断检索到的文档是否和问题相关
def grade_documents(state):
"""
Determines whether the retrieved documents are relevant to the question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with only filtered relevant documents
"""
print("----检查文档是否和问题相关----\n")
question = state["question"]
documents = state["documents"]
# Score each doc
filtered_docs = []
for d in documents:
score = retrieval_grader.invoke(
{"question": question, "document": d.page_content}
)
grade = score.binary_score
if grade == "yes":
print("文档和用户问题相关\n")
filtered_docs.append(d)
else:
print("文档和用户问题不相关\n")
continue
return {"documents": filtered_docs, "question": question}
# 改写问题,生成更好的问题
def transform_query(state):
"""
Transform the query to produce a better question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates question key with a re-phrased question
"""
print("改写问题\n")
question = state["question"]
documents = state["documents"]
# Re-write question
better_question = question_rewriter.invoke({"question": question})
print("LLM 改写优化后更好的提问:", better_question)
return {"documents": documents, "question": better_question}
### Edges
def decide_to_generate(state):
"""
Determines whether to generate an answer, or re-generate a question.
Args:
state (dict): The current graph state
Returns:
str: Binary decision for next node to call
"""
print("访问检索到的相关知识库\n")
state["question"]
filtered_documents = state["documents"]
if not filtered_documents:
# All documents have been filtered check_relevance
# We will re-generate a new query
print("所有的文档都不相关,重新生成问题\n")
return "transform_query"
else:
# We have relevant documents, so generate answer
print("文档和问题相关,生成回答")
return "generate"
# 评估生成的回复是否基于知识库事实(是否产生了幻觉)
def grade_generation_v_documents_and_question(state):
"""
Determines whether the generation is grounded in the document and answers question.
Args:
state (dict): The current graph state
Returns:
str: Decision for next node to call
"""
print("评估生成的回复是否基于知识库事实(是否产生了幻觉)\n")
question = state["question"]
documents = state["documents"]
generation = state["generation"]
score = hallucination_grader.invoke(
{"documents": documents, "generation": generation}
)
grade = score.binary_score
# Check hallucination
if grade == "yes":
print("生成的回复是基于知识库,没有幻觉\n")
# 评估LLM 的回答是否解决了用户问题
score = answer_grader.invoke({"question": question, "generation": generation})
grade = score.binary_score
if grade == "yes":
print("问题得到解决\n")
return "useful"
else:
print("问题没有得到解决\n")
return "not useful"
else:
print("生成的回复不是基于知识库,继续重试......\n")
return "not supported"
python
from langgraph.graph import END, StateGraph, START
from IPython.display import Image, display
workflow = StateGraph(GraphState)
# 添加 Nodes
workflow.add_node("retrieve", retrieve) # 检索文档
workflow.add_node("grade_documents", grade_documents) # 判断检索到的文档是否和问题相关
workflow.add_node("generate", generate) # 生成回复
workflow.add_node("transform_query", transform_query) # 改写问题,生成更好的问题
# 生成有向有环图
workflow.add_edge(START, "retrieve")
workflow.add_edge("retrieve", "grade_documents")
# 给 grade_documents 添加条件边,判断 decide_to_generate 函数返回的结果
# 如果函数返回 "transform_query",则跳转到 transform_query 节点
# 如果函数返回 "generate",则跳转到 generate 节点
workflow.add_conditional_edges(
"grade_documents",
# 条件:评估检索到的文档是否和问题相关,如果不相关则重新检索,如果相关则生成回复
decide_to_generate,
{
"transform_query": "transform_query",
"generate": "generate",
},
)
workflow.add_edge("transform_query", "retrieve")
# 给 generate 添加条件边,判断 grade_generation_v_documents_and_question 函数返回的结果
# 如果函数返回 "useful",则跳转到 END 节点
# 如果函数返回 "not useful",则跳转到 transform_query 节点
# 如果函数返回 "not supported",则跳转到 generate 节点
workflow.add_conditional_edges(
"generate",
# 条件:评估生成的回复是否基于知识库事实(是否产生了幻觉),是则评估答案准确性,否则重新生成问题
grade_generation_v_documents_and_question,
{
"not supported": "generate",
"useful": END,
"not useful": "transform_query",
},
)
# Compile
app = workflow.compile()
try:
display(Image(app.get_graph().draw_mermaid_png()))
except Exception:
pass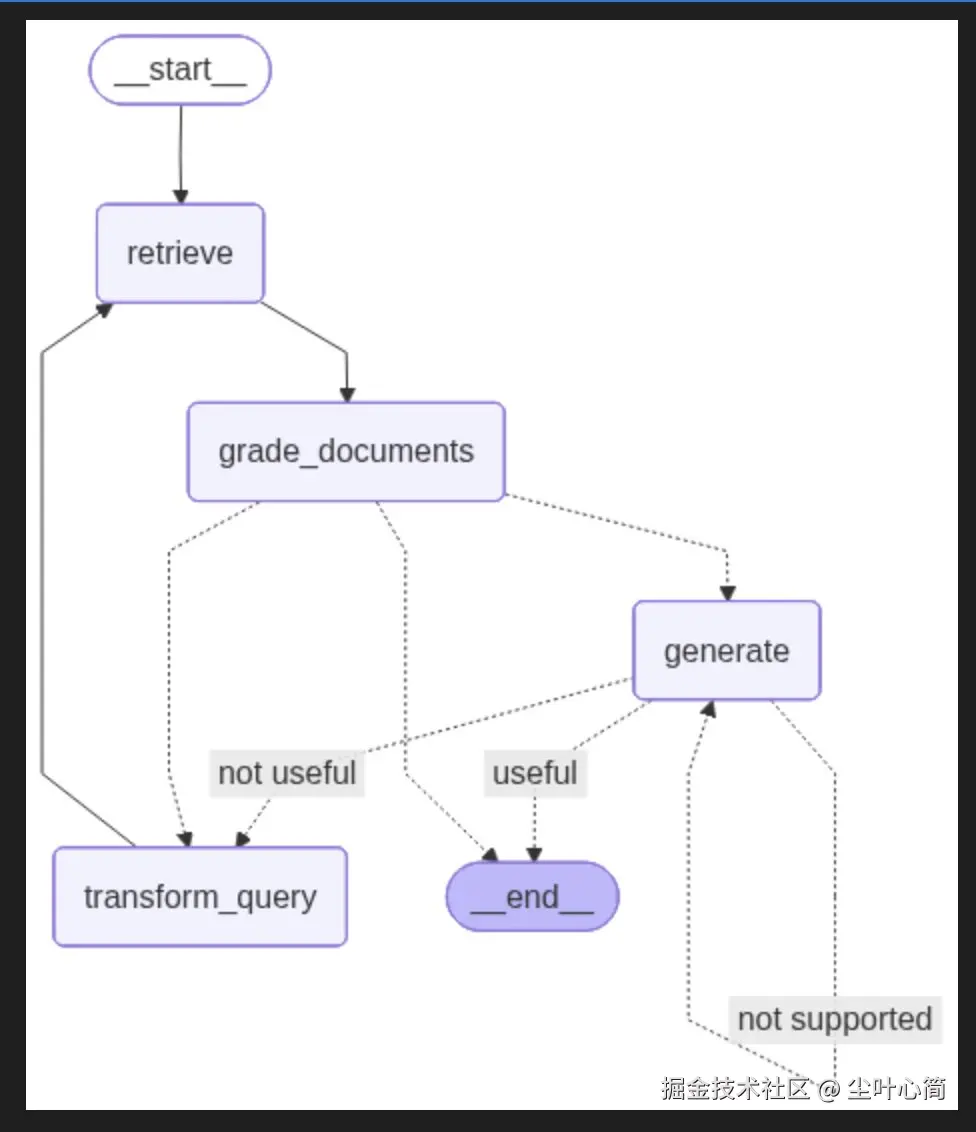
最后我们问一个问题运行测试一下试试看。
python
from pprint import pprint
# 简单问题
# inputs = {"question": "payment_backend 服务是谁维护的?"}
# 复杂问题
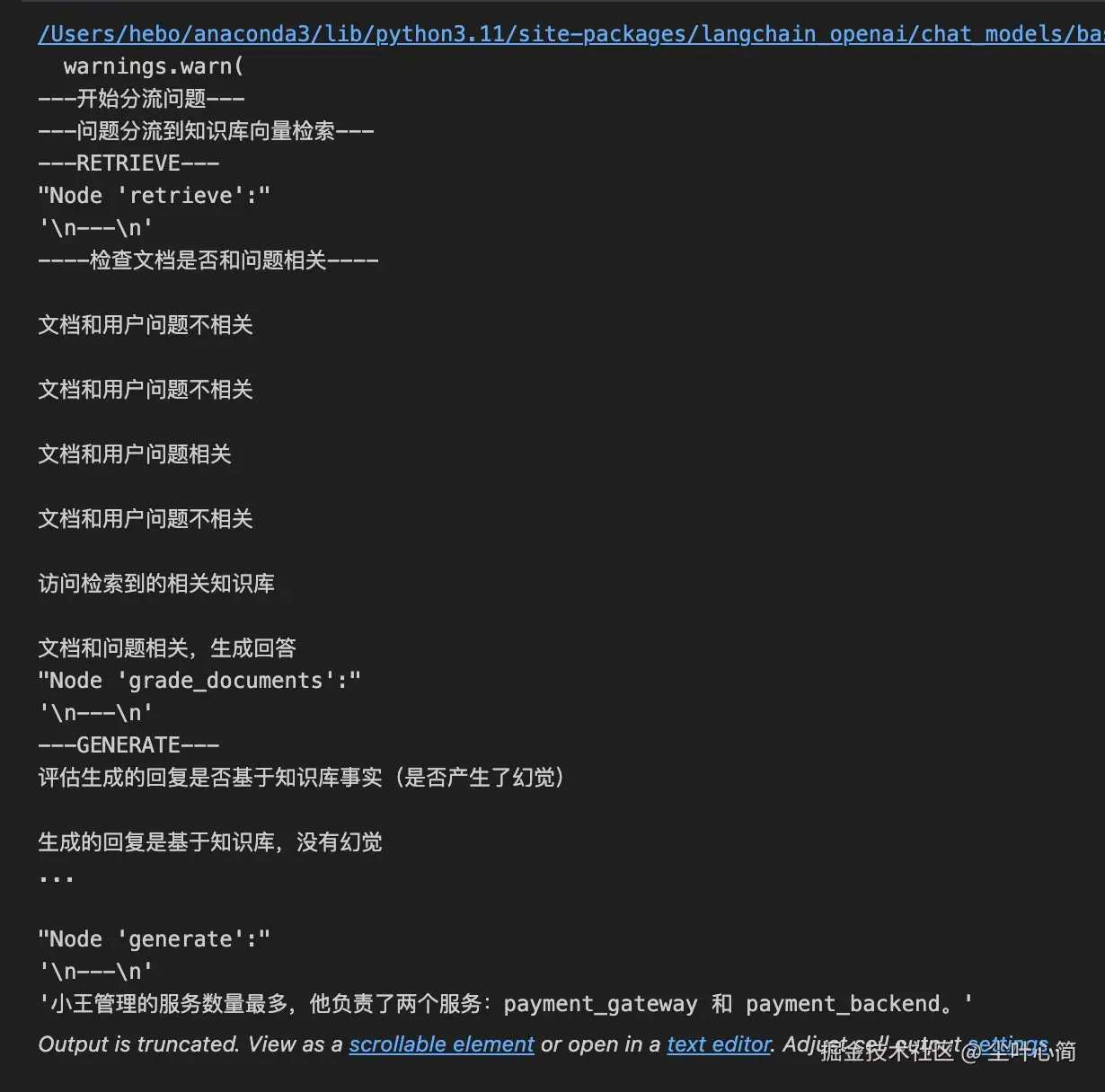
inputs = {"question": "谁管理的服务数量最多?"}
for output in app.stream(inputs):
for key, value in output.items():
# Node
pprint(f"Node '{key}':")
# Optional: print full state at each node
# pprint.pprint(value["keys"], indent=2, width=80, depth=None)
pprint("\n---\n")
# Final generation
pprint(value["generation"])
结合WebSearch和Self-RAG
添加如下代码:
python
# 问题分流路由器:将问题分流到 Self-RAG 或者搜索引擎
class RouteQuery(BaseModel):
"""Route a user query to the most relevant datasource."""
datasource: Literal["vectorstore", "web_search"] = Field(
...,
description="Given a user question choose to route it to web search or a vectorstore.",
)
def route_question(state):
"""
Route question to web search or RAG.
Args:
state (dict): The current graph state
Returns:
str: Next node to call
"""
llm = ChatOpenAI(model="gpt-4o-mini",api_key="你的API Key", temperature=0)
structured_llm_router = llm.with_structured_output(RouteQuery)
# Prompt
system = """您是将用户问题路由到 vectorstore 或 web_search 的专家。
vectorstore 包含运维、工单、微服务、网关、工作负载、日志等相关内容,使用 vectorstore 来回答有关这些主题的问题。
否则,请使用 web_search"""
route_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
question_router = route_prompt | structured_llm_router
print("---开始分流问题---")
question = state["question"]
source = question_router.invoke({"question": question})
if source.datasource == "web_search":
print("---问题分流到网络搜索---")
return "web_search"
elif source.datasource == "vectorstore":
print("---问题分流到知识库向量检索---")
return "vectorstore"
### Search
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain.schema import Document
web_search_tool = TavilySearchResults(k=3)
# 网络搜索
def web_search(state):
"""
Web search based on the re-phrased question.
Args:
state (dict): The current graph state
Returns:
state (dict): Updates documents key with appended web results
"""
print("---进行网络搜索---")
question = state["question"]
# Web search
docs = web_search_tool.invoke({"query": question})
web_results = "\n".join([d["content"] for d in docs])
web_results = Document(page_content=web_results)
return {"documents": web_results, "question": question}
python
from langgraph.graph import END, StateGraph, START
from IPython.display import Image, display
workflow = StateGraph(GraphState)
# 添加 Nodes
workflow.add_node("web_search", web_search) # web search
workflow.add_node("retrieve", retrieve) # 检索文档
workflow.add_node("grade_documents", grade_documents) # 判断检索到的文档是否和问题相关
workflow.add_node("generate", generate) # 生成回复
workflow.add_node("transform_query", transform_query) # 改写问题,生成更好的问题
# 定义有向有环图
workflow.add_conditional_edges(
START,
route_question,
{
"web_search": "web_search",
"vectorstore": "retrieve",
},
)
workflow.add_edge("web_search", "generate")
workflow.add_edge("retrieve", "grade_documents")
# 给 grade_documents 添加条件边,判断 decide_to_generate 函数返回的结果
# 如果函数返回 "transform_query",则跳转到 transform_query 节点
# 如果函数返回 "generate",则跳转到 generate 节点
workflow.add_conditional_edges(
"grade_documents",
# 条件:评估检索到的文档是否和问题相关,如果不相关则重新检索,如果相关则生成回复
decide_to_generate,
{
"transform_query": "transform_query",
"generate": "generate",
},
)
workflow.add_edge("transform_query", "retrieve")
# 给 generate 添加条件边,判断 grade_generation_v_documents_and_question 函数返回的结果
# 如果函数返回 "useful",则跳转到 END 节点
# 如果函数返回 "not useful",则跳转到 transform_query 节点
# 如果函数返回 "not supported",则跳转到 generate 节点
workflow.add_conditional_edges(
"generate",
# 条件:评估生成的回复是否基于知识库事实(是否产生了幻觉),是则评估答案准确性,否则重新生成问题
grade_generation_v_documents_and_question,
{
"not supported": "generate",
"useful": END,
"not useful": "transform_query",
},
)
# Compile
app = workflow.compile()
try:
display(Image(app.get_graph().draw_mermaid_png()))
except Exception:
pass然后我们进行测试两个问题,一个会进行从知识库回答,一个会从网络中搜索回答。
python
from pprint import pprint
# 向量匹配问题
#inputs = {"question": "谁管理的服务数量最多?"}
# 搜索问题
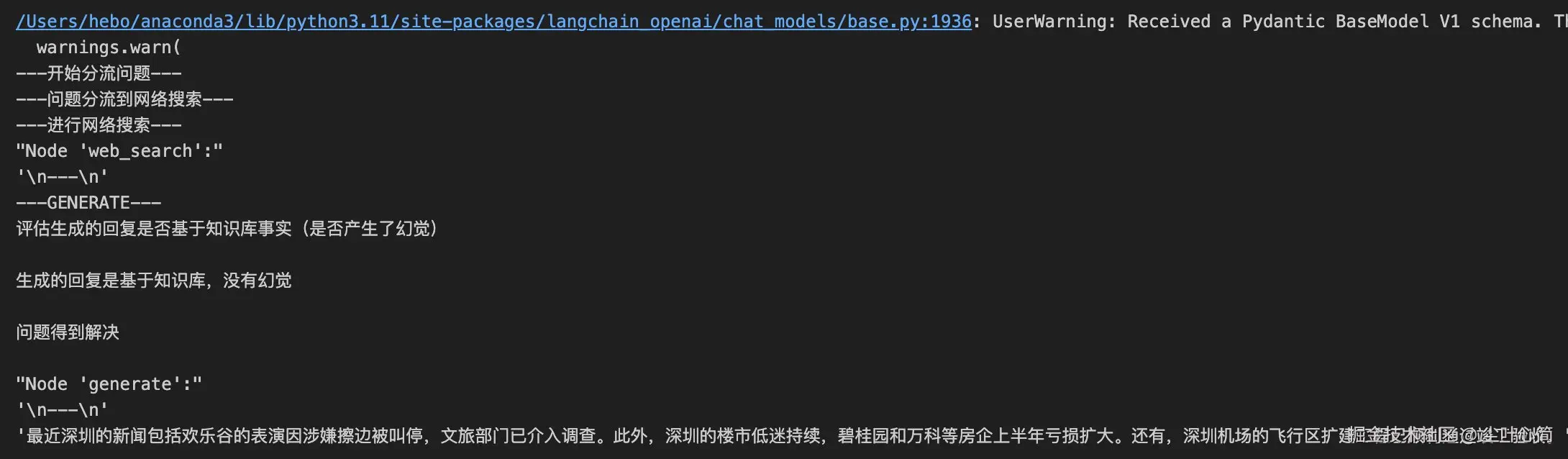
inputs = {"question": "深圳最近的新闻"}
for output in app.stream(inputs):
for key, value in output.items():
# Node
pprint(f"Node '{key}':")
# Optional: print full state at each node
# pprint.pprint(value["keys"], indent=2, width=80, depth=None)
pprint("\n---\n")
# Final generation
pprint(value["generation"])