前言
风风火火的写了写AVL树和红黑树的实现,其实都是铺垫,早在map和set使用的学习的时候,我就提库里的map和set底层封装个红黑树实现。
为了能够自己模拟实现map和set的一些功能:
我们先学了AVL树,重点关注了保证平衡方式和平衡调整,也就是四种旋转,这为后续写红黑树实现又做铺垫;
有了AVL树的铺垫,在学习红黑树时重点学习红黑树如何保证平衡,另外的重点就是调整用到旋转的时候就不用另起炉灶,直接复用AVL树中实现的就行了。
那么怎么用红黑树实现map和set的功能呢?
我们大致分为:
1.阅读源码,了解库里面大致怎么实现的
2.模仿源码实现功能
一、阅读源码(1)

<set.h>和<map.h>就这么点内容,其实重点还是里面包的头文件,库里面代码经常就是包来包去,可能考虑到解耦和使用的原因吧。
所以重点还是转到<stl_set.h>和<stl_map.h>
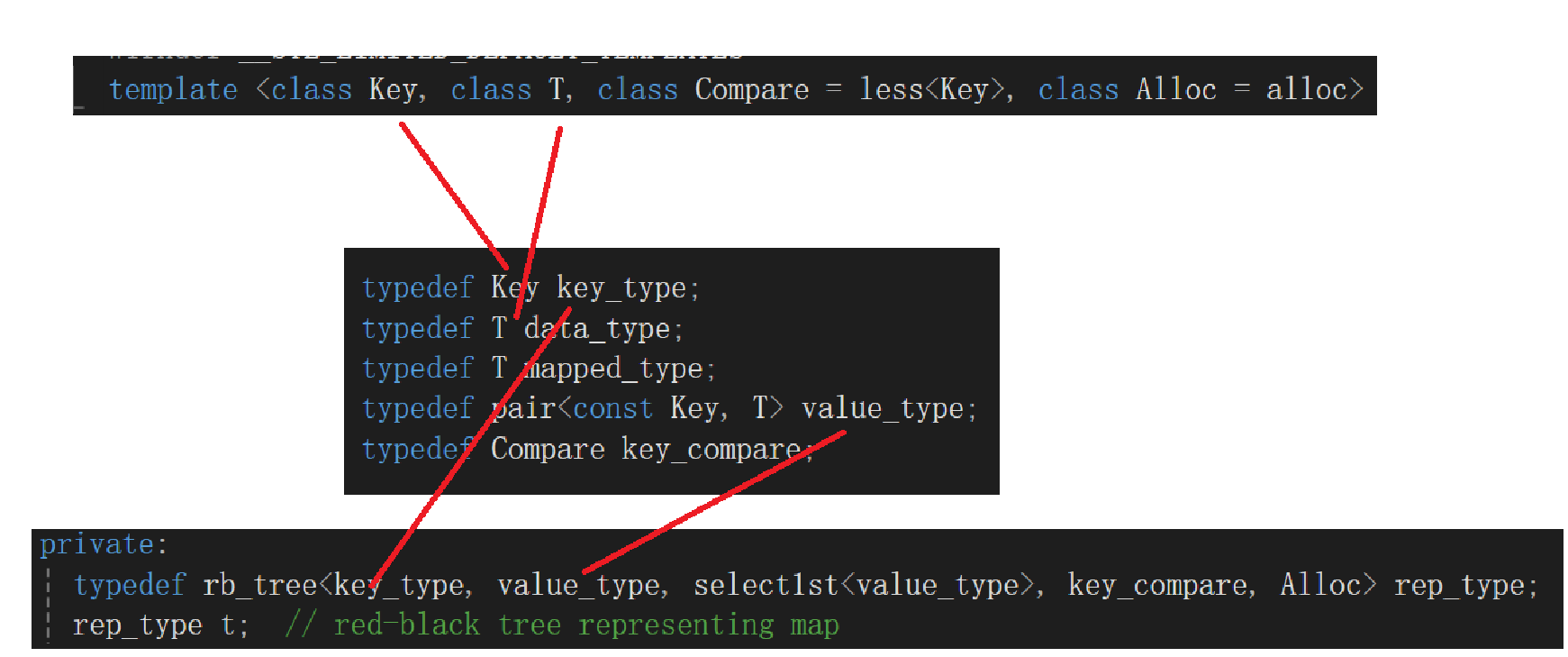
模板和成员变量
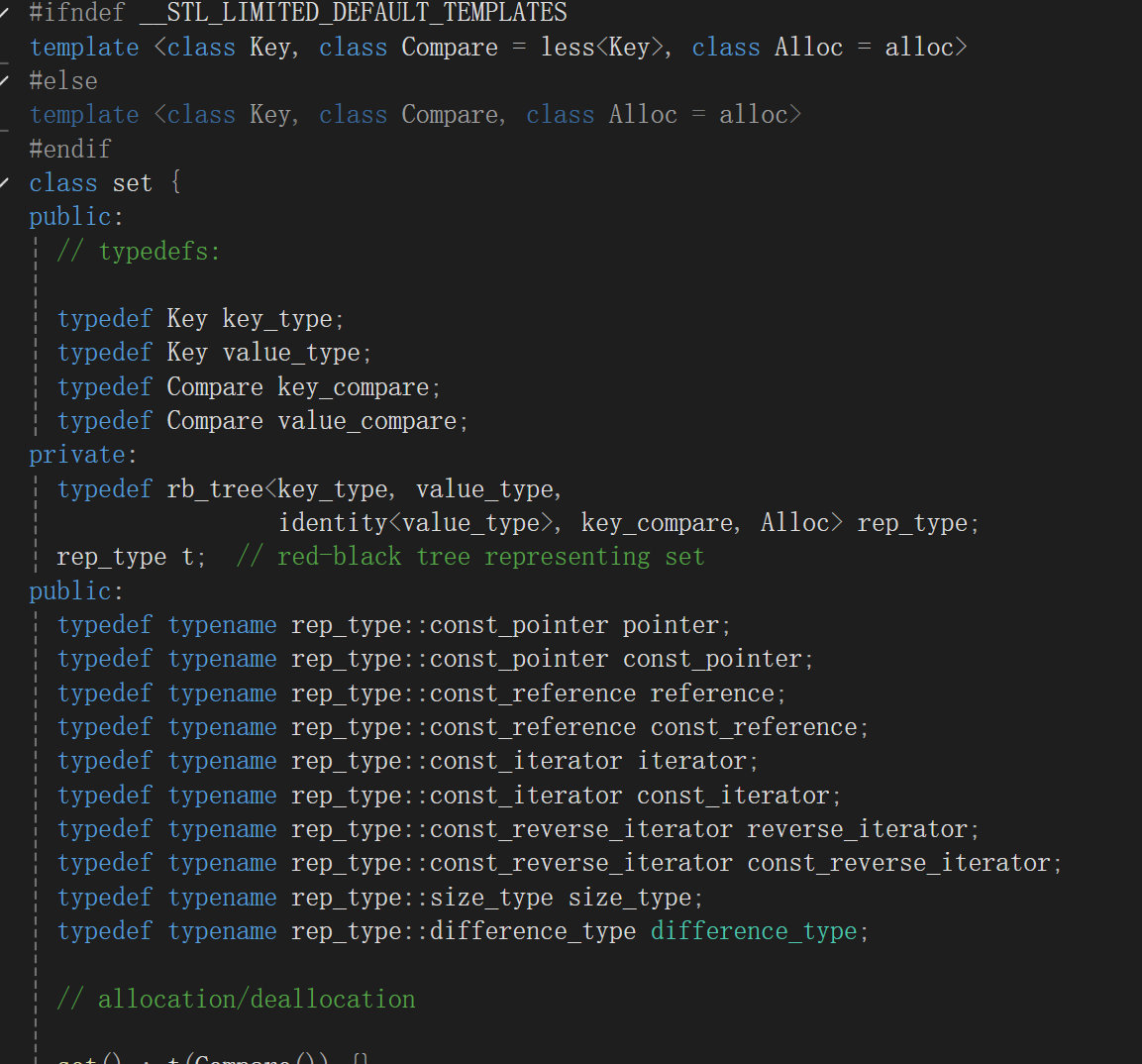
set类的模板是Key、仿函数、内存池,意料之中昂。
内存池就不多说了,STL里的容器都用这玩意,原因也说了,频繁从堆申请释放内存这个事很不好,大致就是内存碎片化的问题,因此干脆划出来一部分内存专门让容器用。
set类底层每个结点存的就是key;
至于仿函数模板参数:底层用的数据结构是红黑树,不管是插入、查找、删除,你随便想想,其实最先干的事就是查找,查找就得比较大小;就包括set迭代器,就现在空想大致也得比较大小,留着仿函数接口就是给你自定义比较大小逻辑用的。
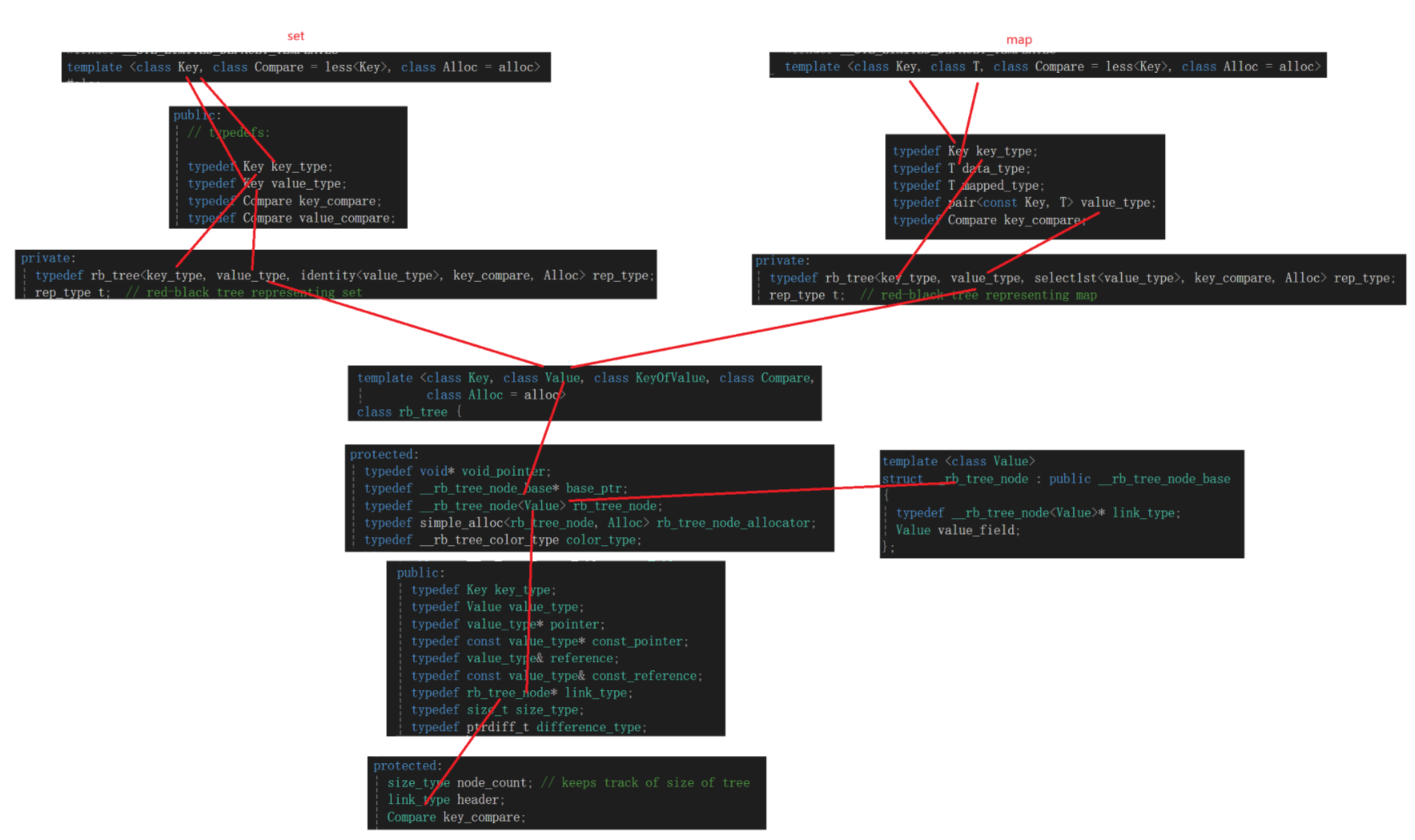
然后就是找成员变量昂,这也真是个技术活,考眼力的,因为它里面经常搞typedef,写一大堆,我是盯着访问限定符找到的:

人家不管是注释还是说命名,都告诉你了,用的数据结构就是红黑树。
但是实际上这玩意有点小抽,因为你如果一个一个对着看:
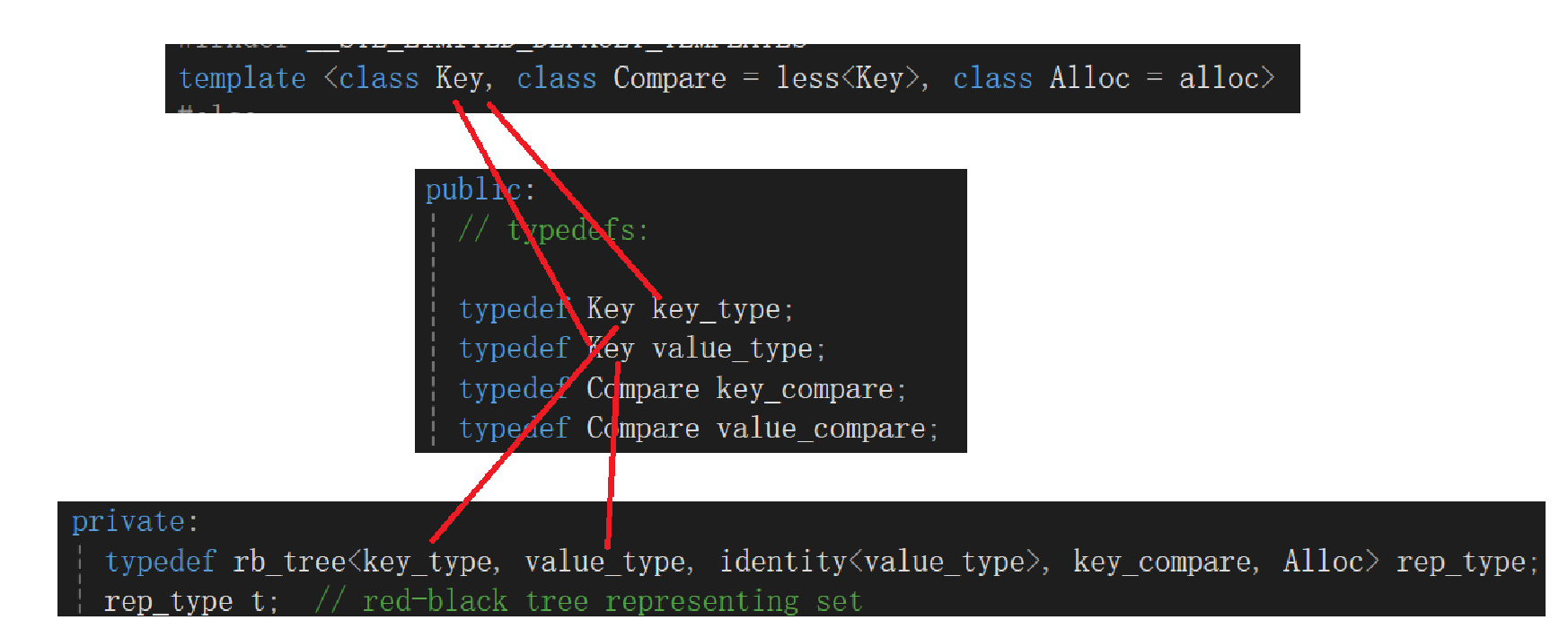
找着找着发现不对劲了,这个数实例化的时候传参咋传个key_type又传个value_type,我研究的是set啊,咋不是存个key呢?后面的仨也有不认识的identity又是干啥的,看着又是一个模板实例化。
上面研究了研究也看不出来个啥,那瞅瞅map看看:
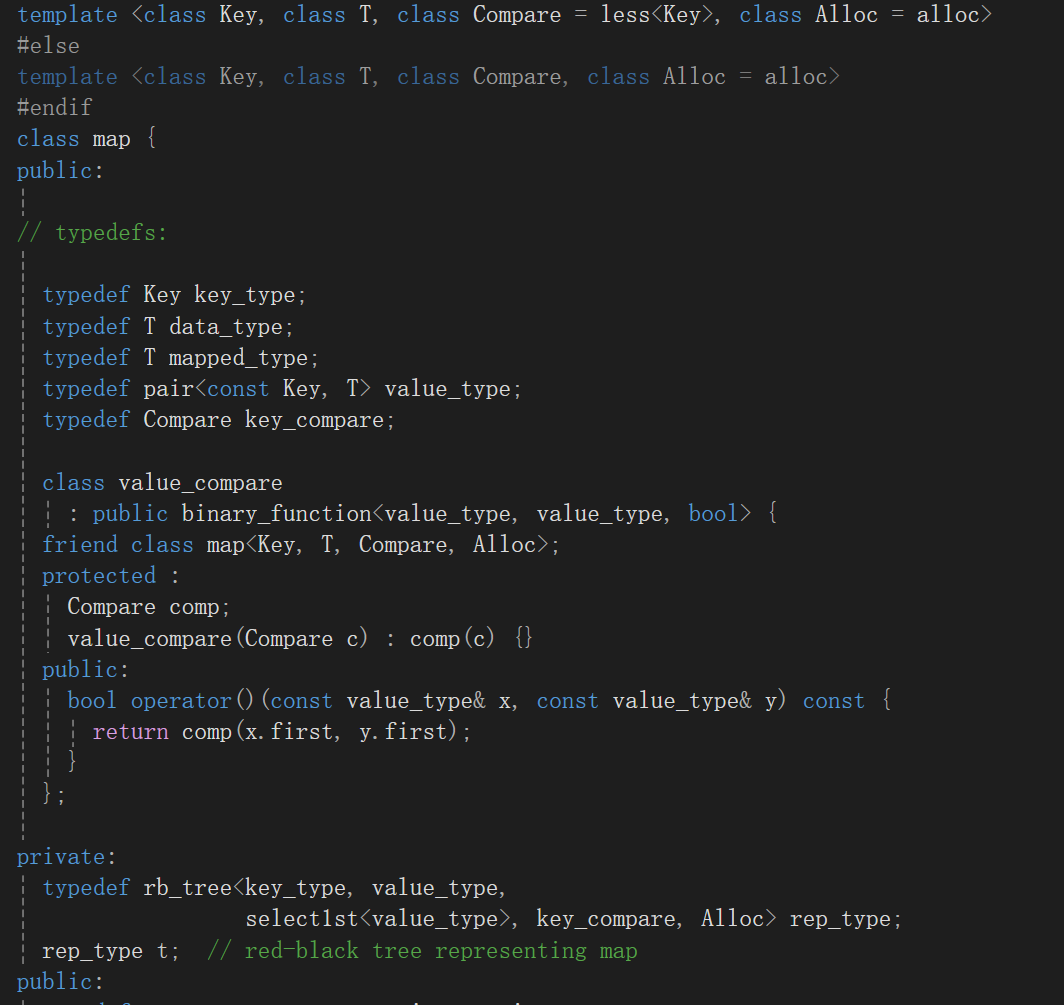
模仿set一样去一点一点看成员变量昂:
c,咋又是这样,按道理来说红黑树存个pair就行了,咋滴还存一个key存一个pair,感觉这么冗余呢?
再来就是微微吐槽一下,这个版本比较早了九几年的版本,说句实话,给value的类型命名个T真别扭,弄一个K一个T多好。
①弄清楚value是什么
疑问:为什么封装红黑树传参时,key的类型传一下,再传一下存储在红黑树结点里的value的类型?
这个疑问只能从红黑树里找答案了:
结果又是包来包去的,还得再找,我这里已经找到了:
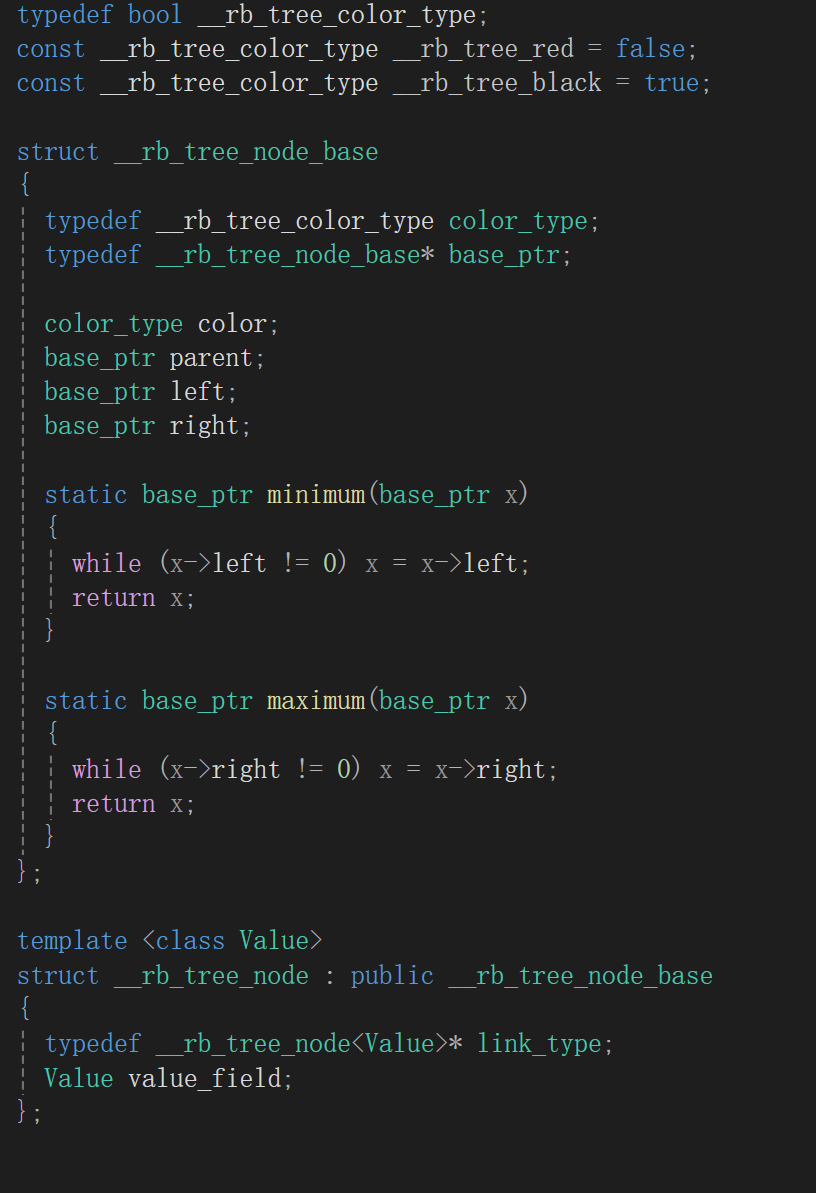
一上来就是定义颜色,当然,人家设计的时候没用枚举类型,用的布尔值,不过也没毛病,红黑树结点不是红就是黑,找个值只有两种可能的bool类型也没啥毛病,这个不多纠结。
接着就看见了个struct tree_node_base,但是其实我看的时候没意识到看的是基类,看了看大概也就是红黑树结点的样子,有颜色、左右孩子和父亲指针,但是没有存储的值,我就继续往下看。
有看见个tree_node而且明显有继承,我才看出来原来上面是基类,这里说句题外话,看源码看的少真是不敏感,base甩脸上都没反应。
这个tree_node类是个模板类,模板参数只有一个,value,大概猜测昂,其实就是上面实例化参数给的那个value_type,不然结点存啥,但是猜归猜,还是看看红黑树到底咋定义的:

翻翻找找瞅见了模板了,但是具体还得去里面找细节,于是我找来找去:

就这玩意像成员变量,而且排除法昂,compare是仿函数逻辑,size_type有注释而且看名字不像结点,像记录树里面结点的变量。
所以这个link_type header大概率就是结点,看这名字,库里面大概率用了个头结点哨兵结点,就跟双链表的头结点一样。
之后就是找找typedef:
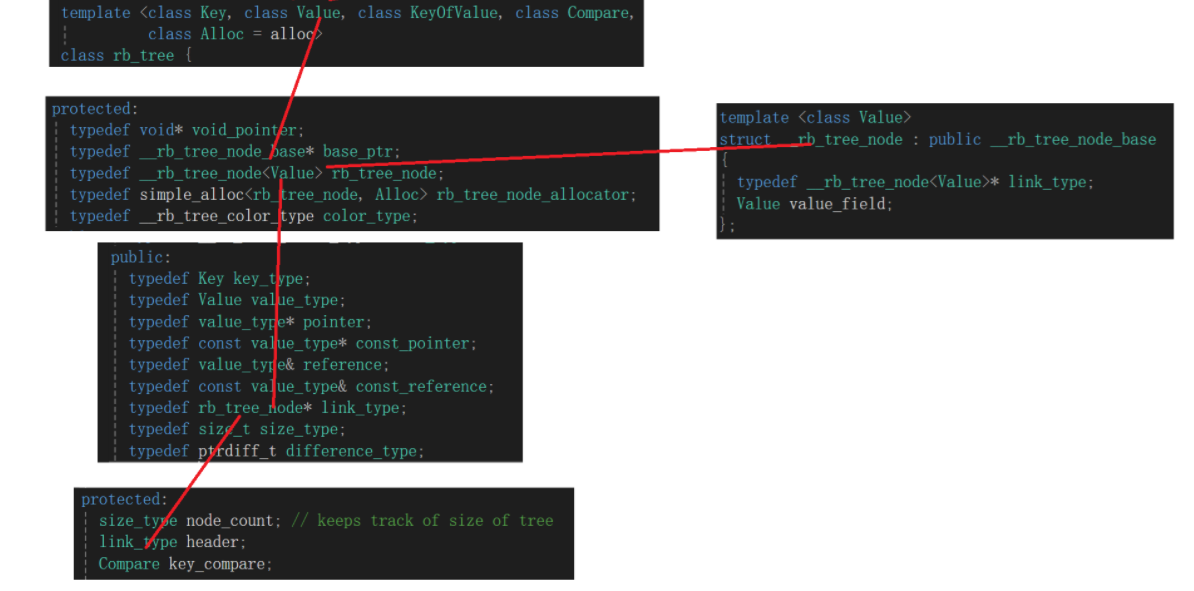
顺着一大堆typedef就找到了,其实就是个node*,跟我们自己写红黑树其实一样,只不过我们不写头结点,直接Node* _root,不过该说不说,这么多typedef给我看的都快不认识typedef了。
所以红黑树结点存储的值的类型就是第二个模板参数value了,因为它直接把结点搞成node<value>了,当然,如果不放心的话还有个:

这里我就不再翻内存池了,但是也能看出来create_node函数创建结点的时候用的也是link_type。
这个时候结合着上面我们分析的看:
最关键的就是:
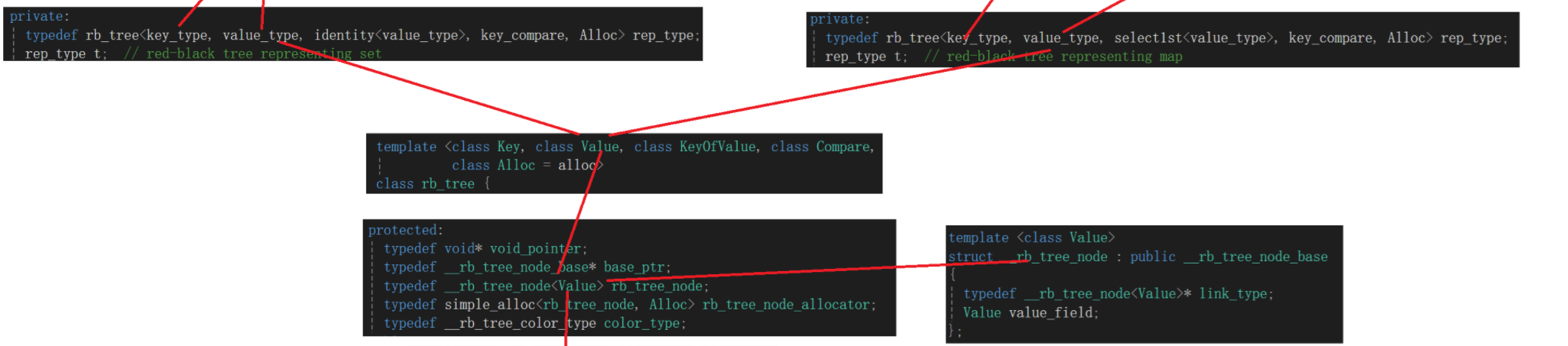
由这个图可以看出来,set底层红黑树结点存储的是key,map底层红黑树结点存储的是pair<key,value>,等于红黑树结点其实还是我们学过的红黑树的实现方式,但是其实担心红黑树结点存储值问题是解决了,不过为啥还要传这里的第一个模板参数key呢?
光看这里真没啥可扒了,毕竟所有的typedef都找完了,这里能找到的内容都完了。
②弄清楚KeyOfValue是啥
其实我们忽略了第三个模板参数,第三个模板参数我们都不知道干啥的,往上走的话,第三个模板参数分别为:
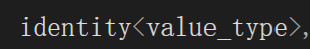
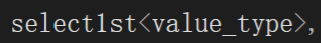
在红黑树里:
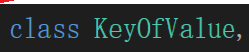
大概看名字能猜个value的key,等于是value里存的key的类型呗,不过其实这还是我们的猜测,于是顺着继续往下走;
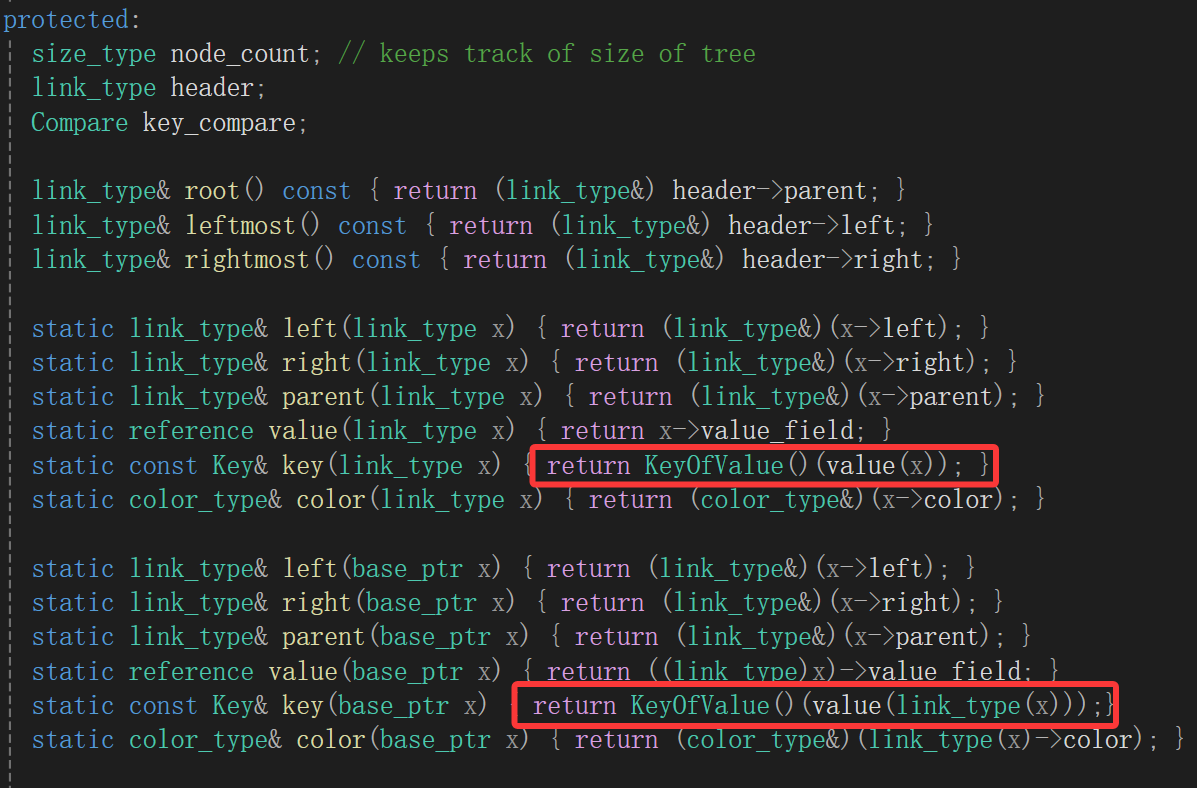
就这里看见了keyofvalue,而且你仔细看,其实这根本不是单纯的我们认为的数据类型,它这样子明显是仿函数类型,问题还是没啥眉目啊,知道它是仿函数类型那有啥用呢?
既然protected修饰,我就看看谁调它了吧,不知道这个函数干嘛的我咋可能知道函数逻辑里面一个语句啥意思,有点寻宝那感觉,在小小的花园里面挖呀挖呀挖。
之后的寻找大致过程是这样的:
我挨着一个一个去找哪里有这个keyofvalue,结果刚开始是个operator==啥的,还有operator=、sawp,说句实话,我想了想,这些函数对于我理解这个类型没屁用,因为你想吧,判断是不是基于对类型了解才能写,至于赋值重载和swap也是这个道理,了解类型是啥才知道深拷贝浅拷贝。
最后找到了insert函数:
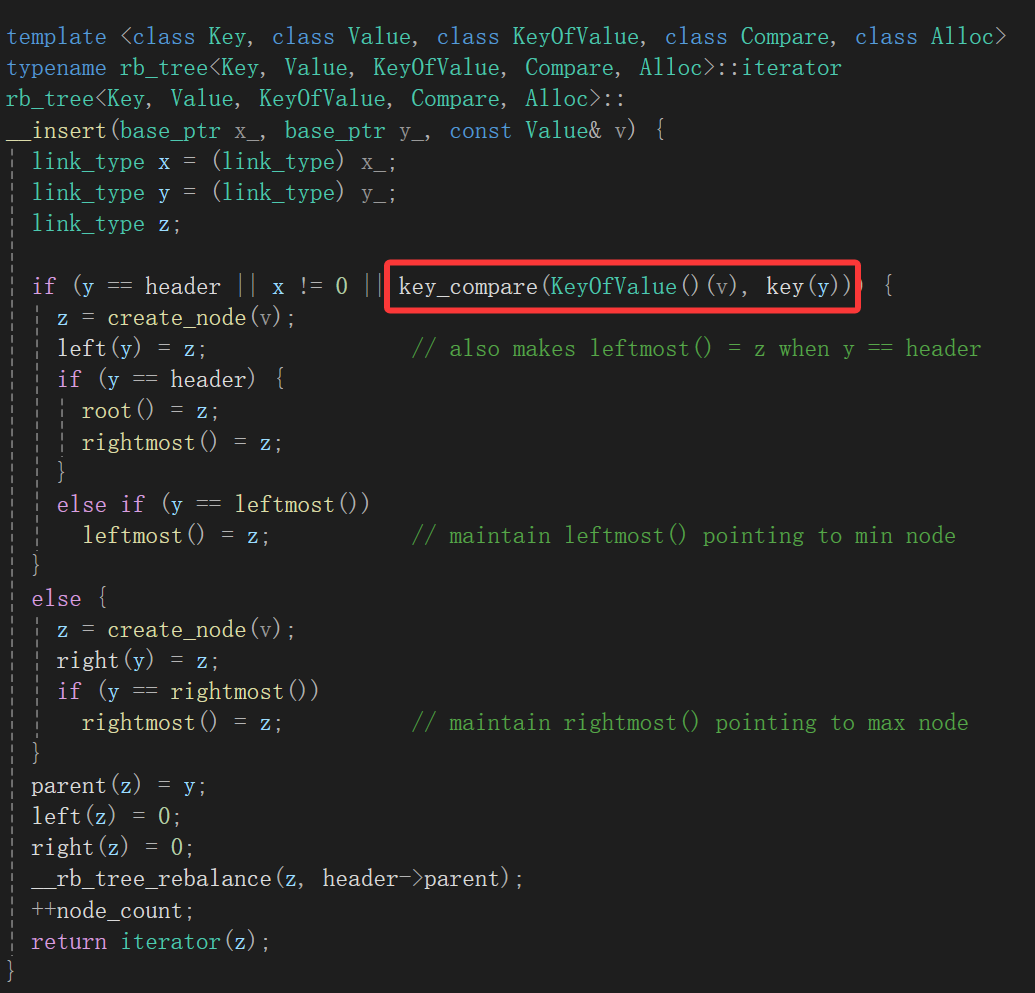
这里不仅有keyofvalue这个仿函数类型的使用,还有key这个函数的调用,反正总归找到点眉目,不过不多,因为这函数前面__insert,又是哪个函数套一层,我光看这个函数会我也不知道干啥的,看看哪里调这个函数:
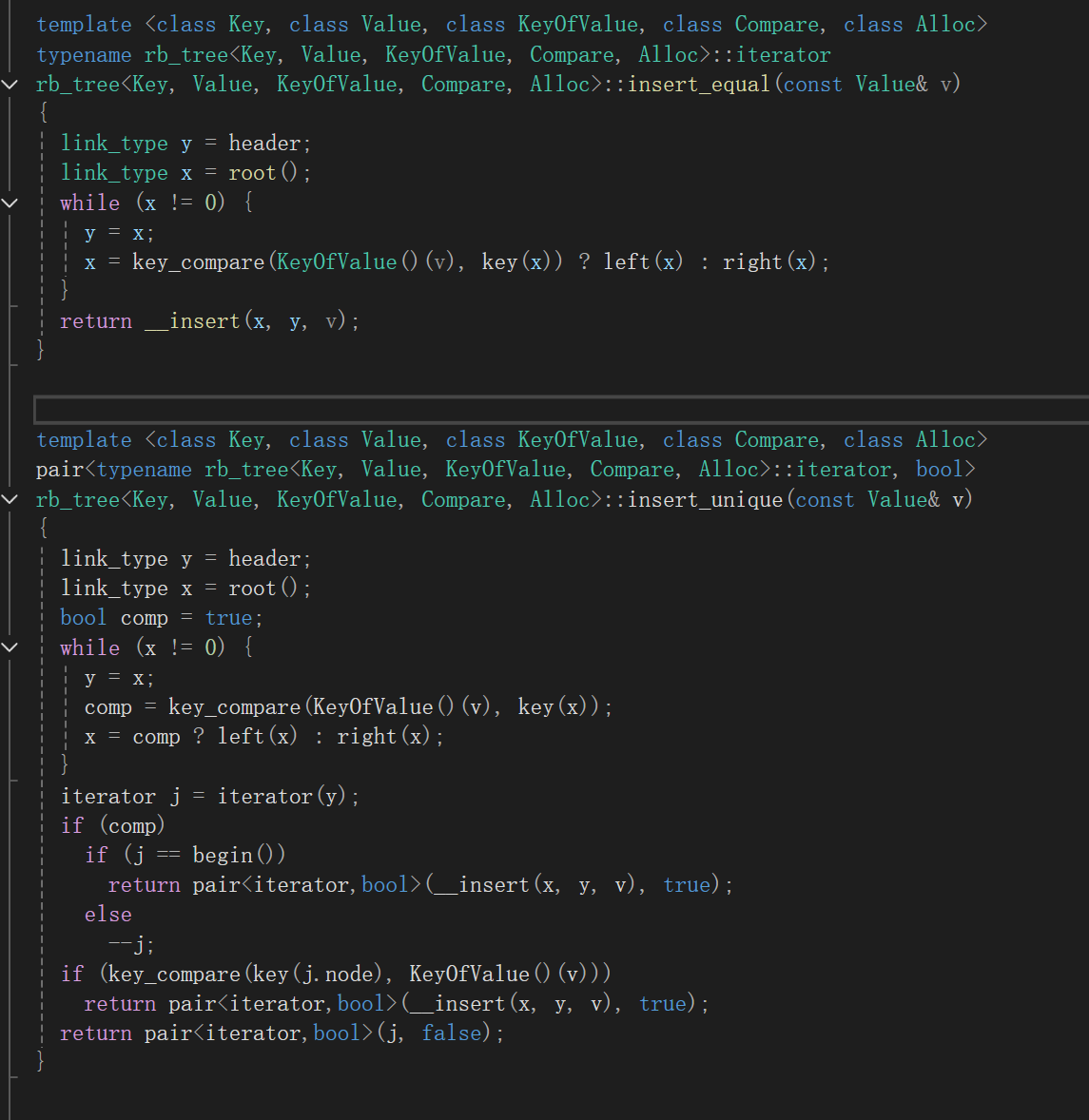
这俩函数都调了,看了看名字,一个叫equal一个叫unique,大概我猜昂,上面那个是用于插入相同数据,下面那个插入不同数据。因为我们学的set和map不是不允许冗余key的存在,multi版本的允许嘛,我们只实现普通的,所以就看那个unique版本吧。
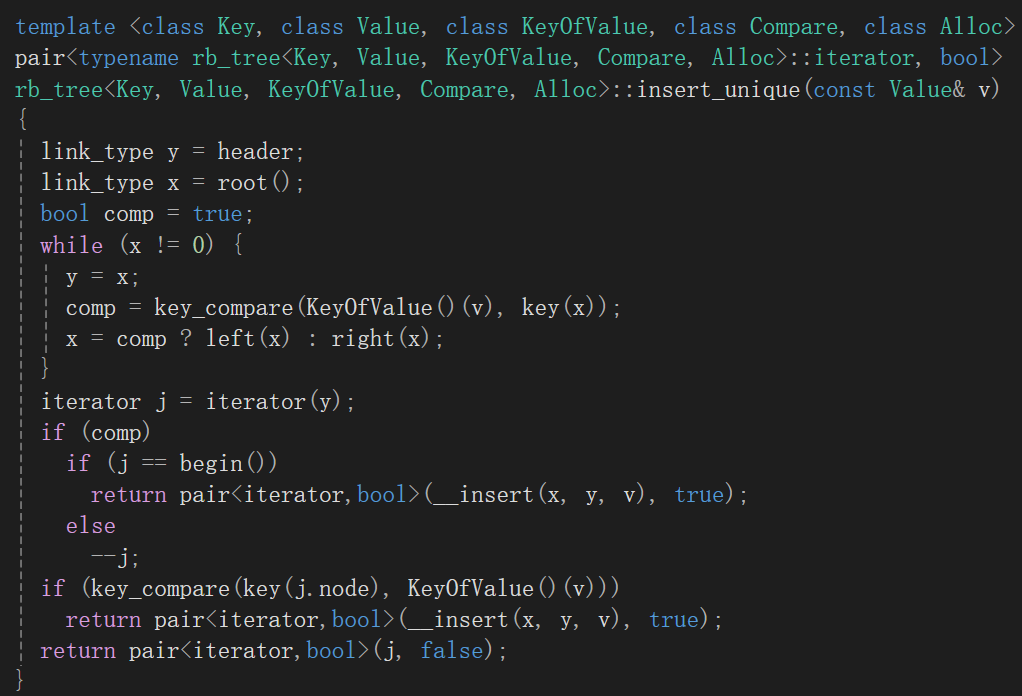
这个insert函数看着真吓人昂,我真是吓死了,不说内部逻辑,它的头都大的不行,但是仔细看看其实就不害怕了:
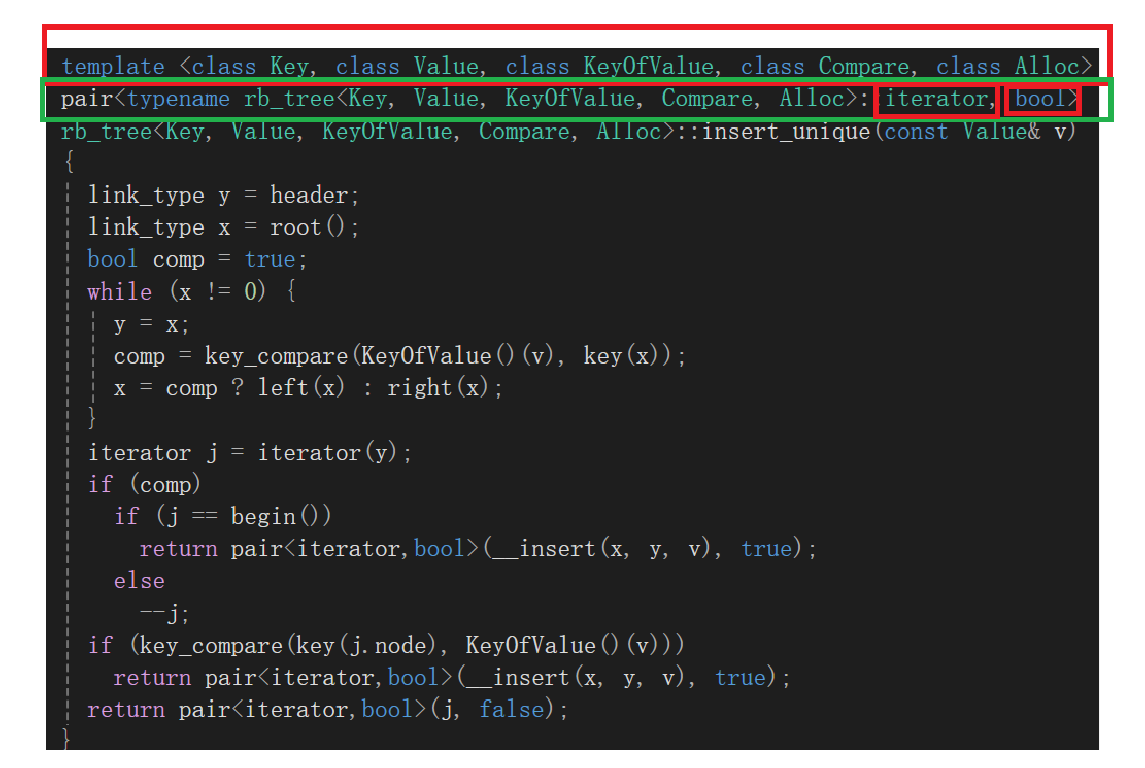
最上面是个模板,等于这里的是个函数模板;
第二行其实我真吓死了,但是吧,重点就是它弄了个作用域限定符::前面跟的rb_tree这个类名,落脚到iterator了,后面是个bool,这个不就是我们学习使用的时候insert接口的标准返回值嘛,就算不记得了,我现在给你拉过来:

那就不用太害怕了,直接研究函数内部逻辑就行,外面一大堆不用管,就当成普通insert函数看待就行。

最关键的就是这,真是抽象死了,给我看傻了都,y初始是头结点,x弄了个root(),那真都不是猜了,一个红黑树能用root的是啥,所以进入循环前y是头结点,x是二叉树的根结点。
进去以后x!=0干啥的,因为这个代码够老了,之前我们讲过一个:
#if C
typedef (void*)0 NULL;
#if C++
typedef 0 NULL;
当然,库里面咋写的我真忘了,反正在nullptr出来之前就是这两句,所以其实等于这个是个
while(x != nullptr)
往里看,上来给我弄个y = x,不知道啥意思,反正第一次进循环嘛x = y = _root了,继续看,搞了个什么key_compare,传的值是v和x,啥意思?
还是画图:
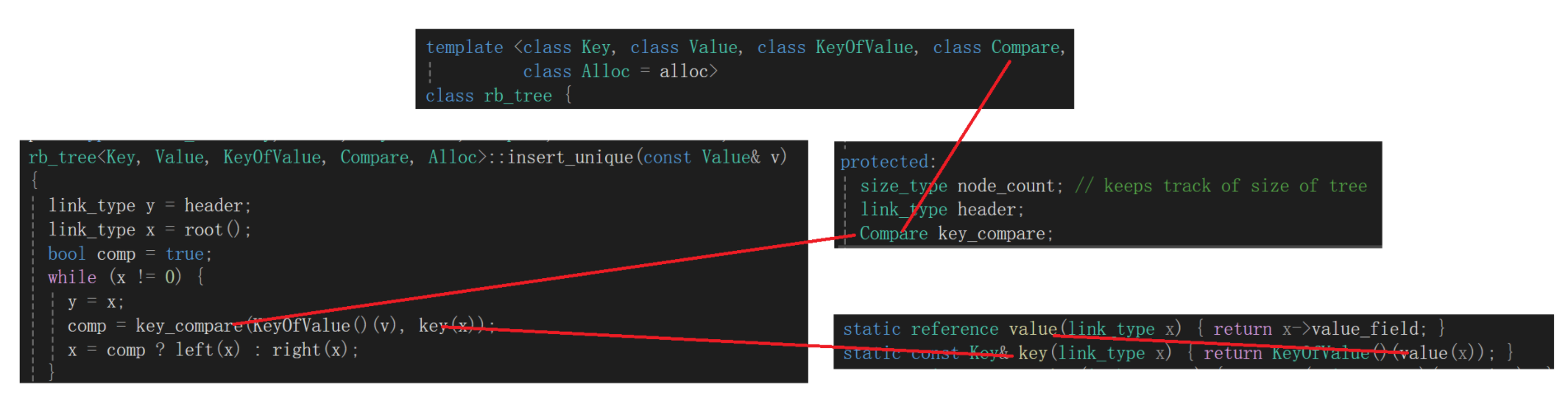
看到这里我就知道这个keyofvalue干啥的了,啥叫key_compare,不就是传过来的比较大小的仿函数类型有名对象的opeartor(),红黑树的比较大小不就是key跟key比,新插入的v的key跟当前遍历到的x的key比较,熟悉不熟悉这个操作,搞这么麻烦其实还是那套逻辑。
所以keyofvalue这个仿函数类型我就知道干啥的了:

x先进到key(),这个函数内部又调用value()得到的是value_field,等于拿着set里的key或者map里的pair<K,V> kv,那这个keyofvalue对象还用说吗,如果是set,直接把key拿出来就行了,如果是map那就取一下key。
真是不容易昂,但是总算弄清楚了所有的模板参数和成员变量了,唯一的遗憾就是不知道额外传个key干啥,不过你说影响吗?
用不上不用就行了,写的时候咱们先模仿着写,不用纠结太多。
有的地方确实整的真麻烦,比如这里弄个key(x),你知道它是Node*,取出来个value很麻烦吗,非得再搞个value函数,但是万一人家有啥考量呢,我只不过是看源码看抓狂了在这无能狂怒。不过它确实有为了省代码让人抓狂的点,就比如下一句:

咱们看懂上面的了,那么这句肯定是小往左走,大往右走,为了缩短代码长度真是,给我搞个这,不过这确实也合理吧,就比如我们写算法题弄个if-else,写完发现重复的代码就把重复的代码提取出来放最后面让它不管什么情况都执行。
但是该说不说昂,看源码真是个体力活,我这轻飘飘的说最后线索找到了insert,硬是看了三四百行才看到这,而且还是基于我对C++语法的发展(NULL和nullptr),以及红黑树insert底层逻辑的理解才弄懂。
总结经验
虽然二三十年前,九几年的源码了,但是吧,还是有参考价值的,比如看一个类看不懂咋办,先看模板参数,看名字去连蒙带猜,猜了后就看成员变量,再看不懂就找找函数,当然别去找逻辑运算符、赋值重载、swap啥的,这玩意看了也是个没营养,这个类干啥也还是看不懂,有insert这种就奔着insert去吧,总归能有点头绪。
当然,如果存在类与类之间的缠绕,就跟我一样追本溯源画画图理清关系,不然开着VS光拿眼看我真要瞎了。
二、实现map和set已知内容
1.基本结构设计
红黑树结点泛型设计
cpp
enum Color
{
RED,
BLACK
};
template <class K,class V>
struct RBTreeNode
{
//V可能是set的K,也可能是map的pair<K,V>
RBTreeNode(const V& data)
:_data(data)
,_left(nullptr)
,_right(nullptr)
,_parent(nullptr)
{}
V _data;
struct RBTreeNode* _left;
struct RBTreeNode* _right;
struct RBTreeNode* _parent;
Color _color;
};库里面使用V单独作为存储的数据,可能是key,也可能是pair<key,value>,我们不管,直接泛型编程就行了。
map和set基本结构(成员变量)
cpp
//set
namespace xx
{
template <class K>
struct SetKOV
{
const K& operator()(const K& key)
{
return key;
}
};
template <class K>
class set
{
private:
RBTree<K, K, SetKOV<K>> _t;
};
}
cpp
//map
namespace xx
{
template <class K,class V>
struct MapKOV
{
const K& operator()(const pair<K,V>& kv)
{
return kv.first;
}
};
template <class K,class V>
class map
{
private:
RBTree<K, pair<K, V>, MapKOV<K, V>> _t;
};
}我们不搞仿函数那一套,也不搞内存池,重心就放在模拟实现结构和操作。
那么不管怎么说,因为红黑树只有一个,所以红黑树得搞泛型编程,模仿着库里面:
第一个类型就传K
第二个类型set就弄成K,map就弄成pair<K,V>,存啥数据第二个模板参数传啥
第三个类型必须弄个KOV,当然,对于set肯定直接拿到的就是key,直接return就完了;对于map还得从pair里取出来first
cpp
template <class K,class V,class KeyOfValue>
class RBTree
{
typedef RBTreeNode<K, V> Node;红黑树就得跟上,那边传你这边不接那不扯嘛。
2.insert函数
insert函数我们读源码读出来了,就实现:
对于set和map来说,直接调用红黑树的就行了:
cpp
//set
public:
bool insert(const K& key)
{
return _t.Insert(key);
}
//map
public:
bool insert(const pair<K, V>& kv)
{
return _t.Insert(kv);
}所以重难点还是回到了,红黑树内部Insert函数的逻辑:
为了能够保证取出来key,所以干脆直接学着库里面:
cpp
private:
Node* _root = nullptr;
KeyOfValue kov;
};需要修改的有:
cpp
bool Insert(const V& data)
{
if (_root == nullptr)
{
_root = new Node(data);
_root->_color = BLACK;
return true;
}
Node* cur = _root;
Node* parent = nullptr;
while (cur)
{
if (kov(data) < kov(cur->_data))
{
parent = cur;
cur = cur->_left;
}
else if (kov(data) > kov(cur->_data))
{
parent = cur;
cur = cur->_right;
}
else
return false;
}
cur = new Node(data);
//新插入的结点颜色必定为红
cur->_color = RED;
if (kov(cur->_data) < kov(parent->_data))
parent->_left = cur;
else
parent->_right = cur;
cur->_parent = parent;一旦插入叶子结点,查找一定得拿到key,所以每句判断都得搞个kov(value);确定新插入结点是左还是右同理。
cpp
private:
void RotateR(Node* parent)
{
Node* subL = parent->_left;
Node* subLR = subL->_right;
//parent subL subLR
//child
parent->_left = subLR;
subL->_right = parent;
//parent
subL->_parent = parent->_parent;
if (subLR)
subLR->_parent = parent;
parent->_parent = subL;
//_root?
if (subL->_parent == nullptr)
_root = subL;
//left or right?
else if (kov(subL->_data) < kov(subL->_parent->_data))
subL->_parent->_left = subL;
else
subL->_parent->_right = subL;
}
void RotateL(Node* parent)
{
Node* subR = parent->_right;
Node* subRL = subR->_left;
//child
parent->_right = subRL;
subR->_left = parent;
//parent
subR->_parent = parent->_parent;
if (subRL)
subRL->_parent = parent;
parent->_parent = subR;
if (_root == parent)
_root = subR;
else if (kov(subR->_data) < kov(subR->_parent->_data))
subR->_parent->_left = subR;
else
subR->_parent->_right = subR;
}左单旋右单旋,最后如果subL/subR是叶子结点,那么就得判断它跟父亲啥关系,到底左还是右,不然更新不了父亲的左孩子/右孩子。
双旋纯是套单旋,保证单旋就行了。
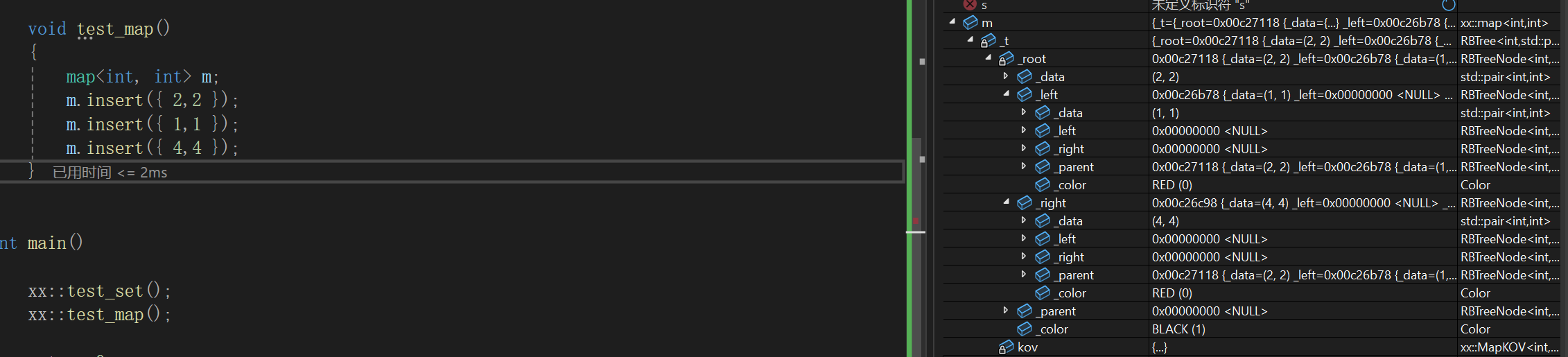
测试set:
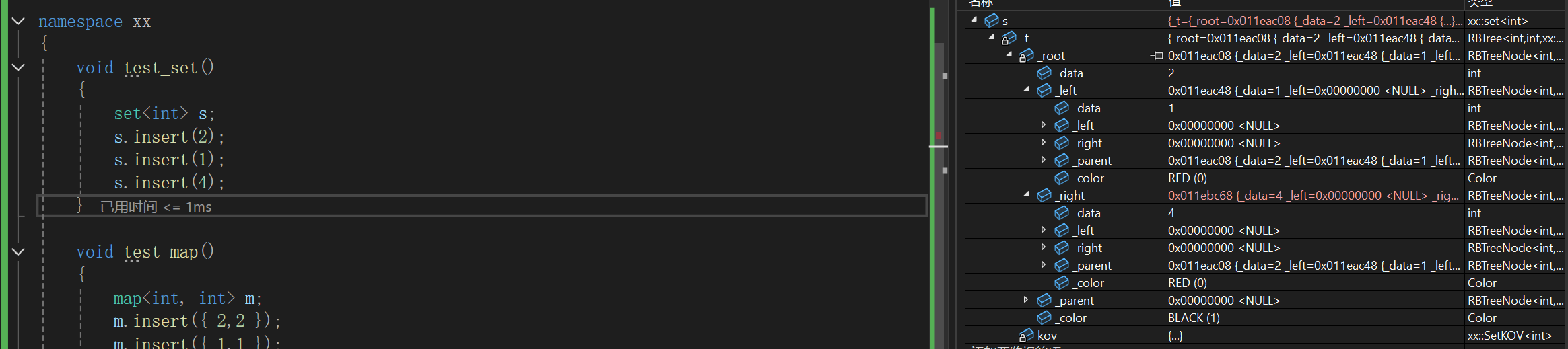
测试map:
三、阅读源码(2)
设计完insert函数最后搞的测试说句实话,真是硬逼着自己看的,所以如果想要测试的直观一点,我们还是得设计迭代器,不然自己遍历肯定不方便。
1.迭代器成员变量设计
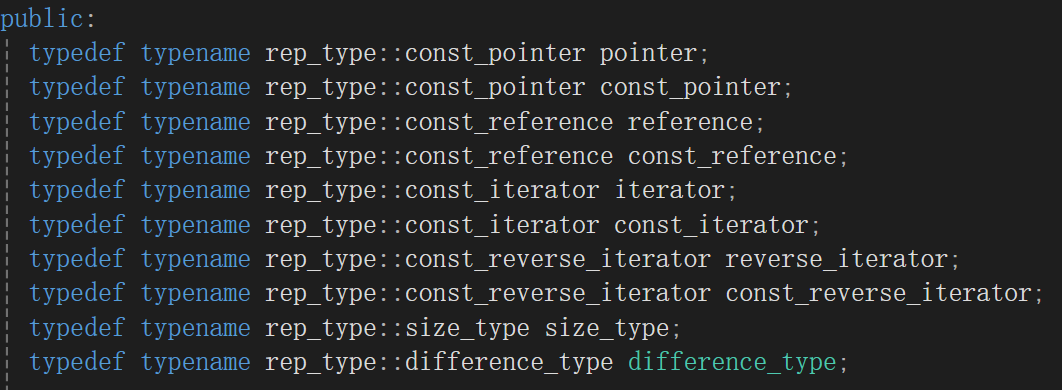
这是set里呈现的代码,我翻来又翻去,根本没找到一点iterator定义的迹象,结果就看见了这段,等于set还是啥都没干,不对,也不能说人家啥也不干,这不是typedef了嘛,具体细节还是红黑树的迭代器搞的。
并且比较奇特的一点是:
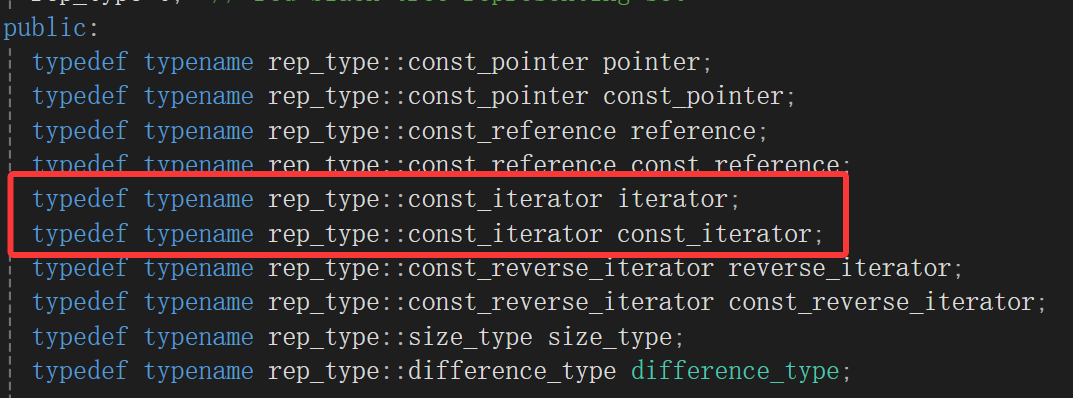
它只用红黑树的const_iterator,我想大概率是因为set只存key,而iterator只能取出来key,二叉树的key绝对不能改变,所以不管是普通迭代器还是const迭代器都用const_iterator。当然,这些还都是猜测,具体还得看红黑树咋实现的。
既然如此再观察观察map底层的迭代器:
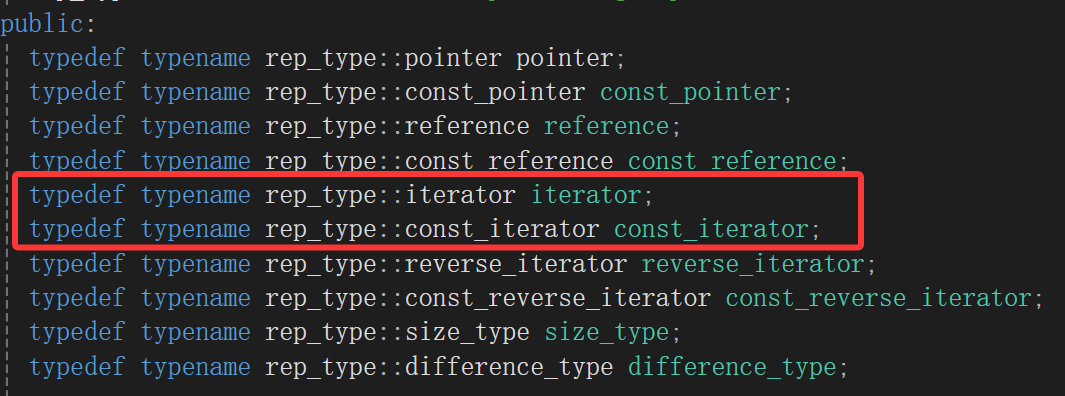
确实也不自己实现,而是封装一层红黑树的迭代器,但是这里的迭代器就是普通复用普通,const迭代器复用const迭代器,难道不管key了吗?
还是保留问题到红黑树底层找。
红黑树底层细节

在红黑树类里面有typedef的两种iterator,这种做法类似于我们list里的模拟实现,因为它的iterator并不能说仅仅依靠typedef Node*来实现,而是有特别的行为封装,list当时是++和--需要用指针往前或者往后找;红黑树大概率迭代器需要封装在树里面遍历结点的逻辑,所以具体细节还得去这个类里找:
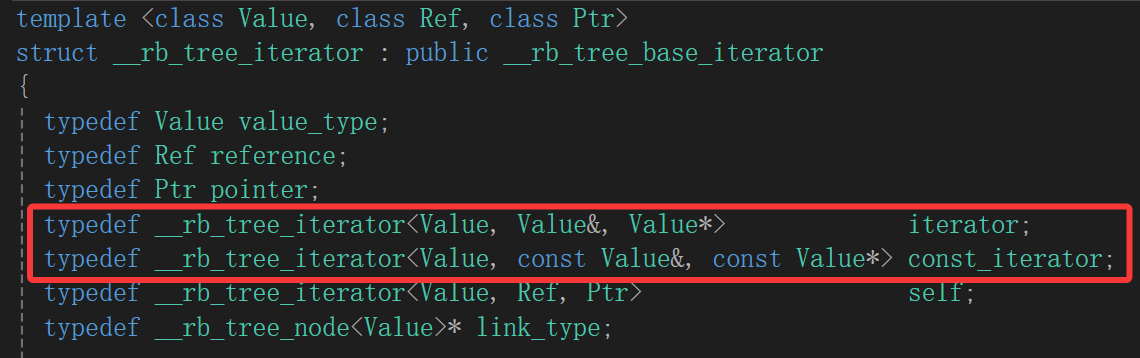
找到了噢,但是这个类是继承下来的,这个类里面根本没有成员变量,根据我们写list的经验,总得拿到Node*才能做事吧,不然有再多操作,巧妇也难为无米之炊。
但是一往上找就遇到问题了:
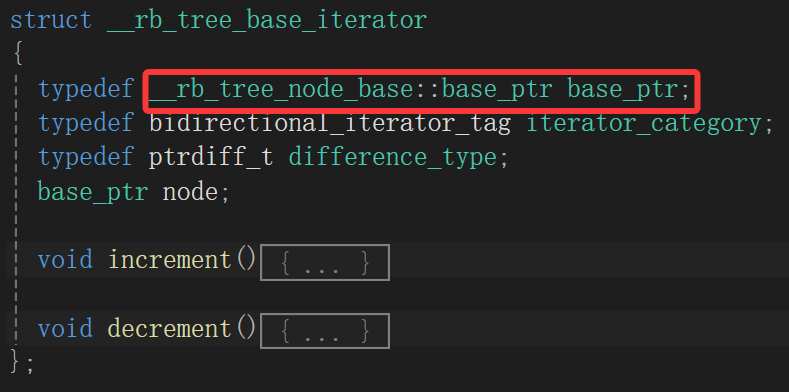
下面那俩函数不管干啥的,我们现在重点是去找成员变量,但是我标出来的地方就麻烦的很,因为在node_base的类里面:
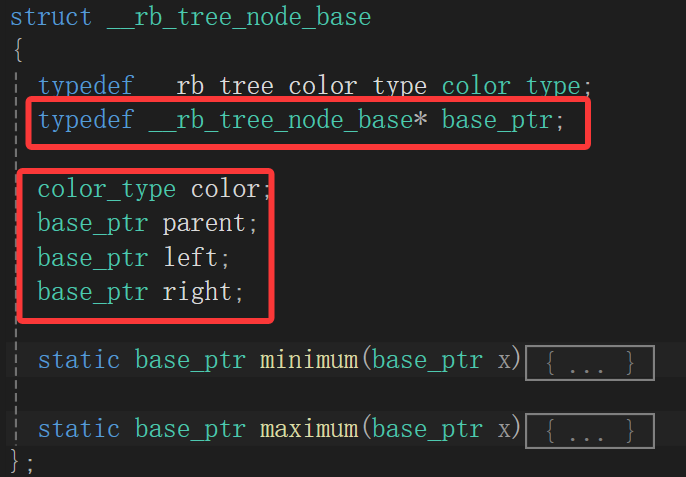
之前我们就看过了,说node_base不含结点存的值,有的只是维持树平衡维持树结构的那几个成员,这可坏了,设计这个迭代器的人难道是想让我们用基类指针访问派生类成员吗,这可能吗?
问题就出现了:
为什么用的基类node*的指针,却能访问派生类对象?
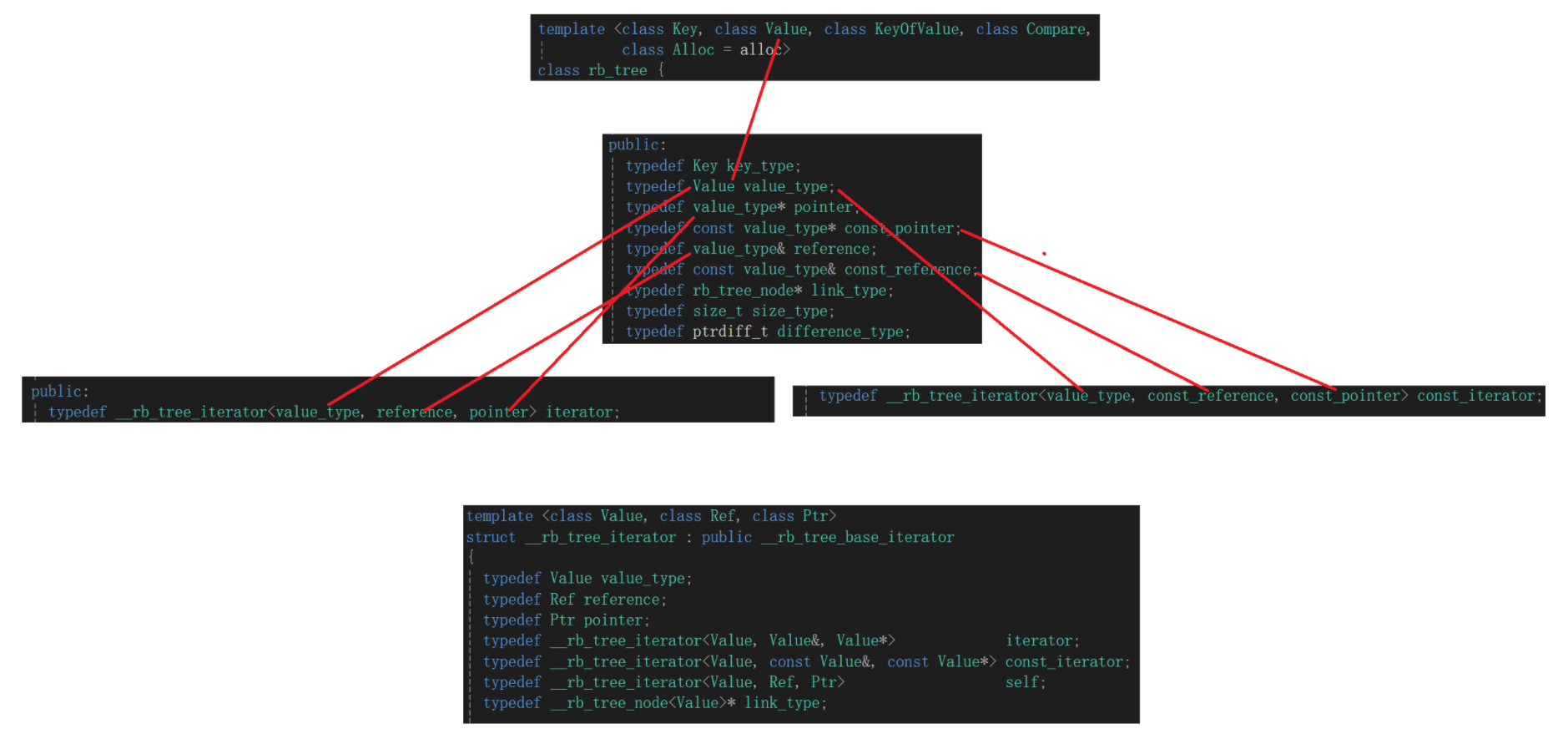
这张图对比下我们得知,红黑树类内部的迭代器跟iterator自己的迭代器完全一样,所以想要研究清楚红黑树内部迭代器,直接看iterator内部即可:
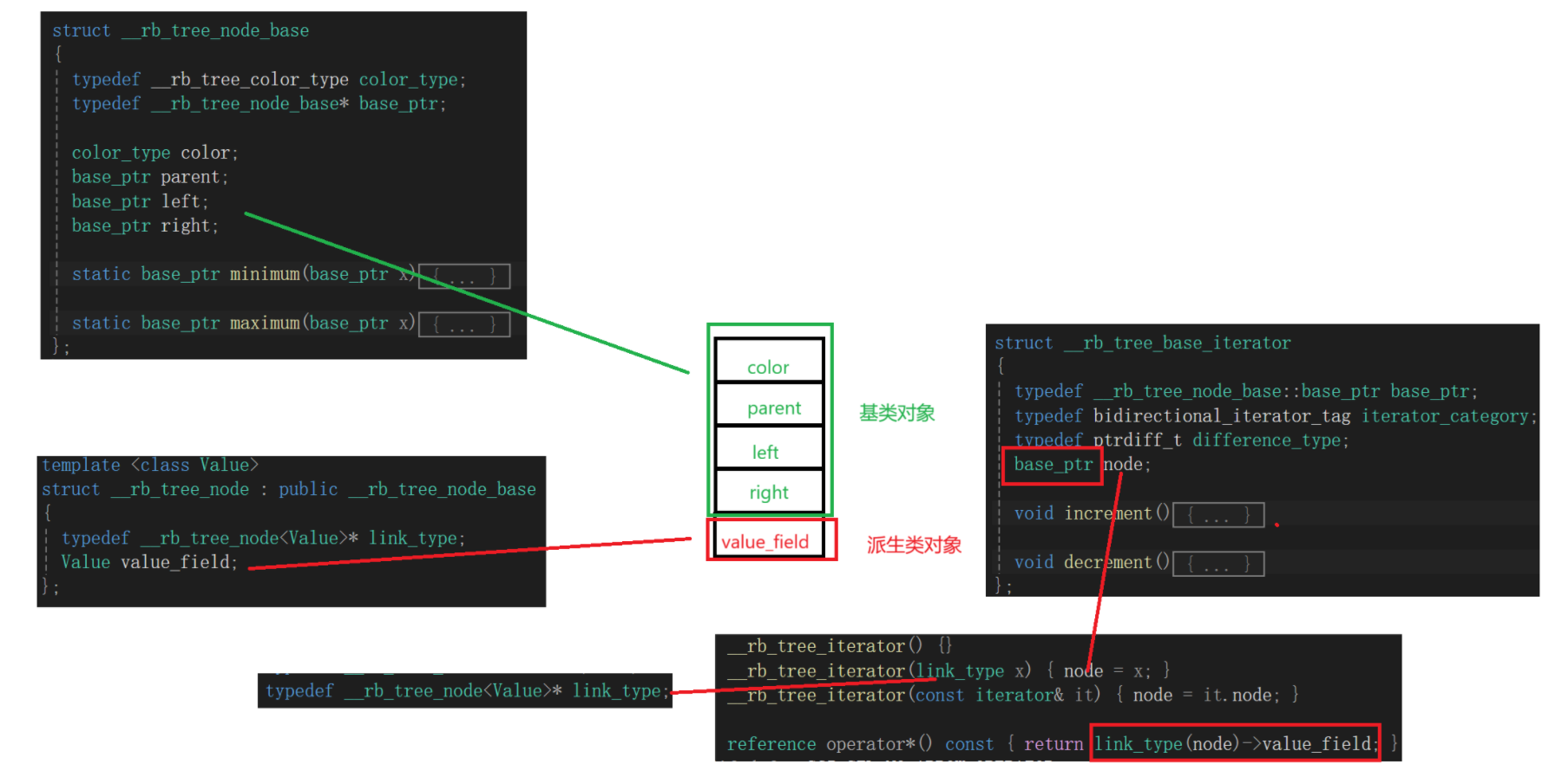
研究来研究去我发现几个特点:
迭代器将base_node* 的node成员初始化时走的是link_type赋值,我找了找,其实是node*,派生类指针,等于迭代器存的是基类指针初始化用的是派生类指针,等到operator*的时候又强转成派生类指针,这样又能访问到派生类成员了。
这里一切前提就是传过来的指针必须是派生类对象的指针,这样这几次操作就没毛病。
我倒是找到间接的证据了:

红黑树内部创建结点的时候,用的全都是node而不是node_base,创建出来的结点都是理想的结点,到时候存的指针一定指向的是派生类对象,只不过由于结点类继承关系,又把派生类指针塞到基类指针变量里:
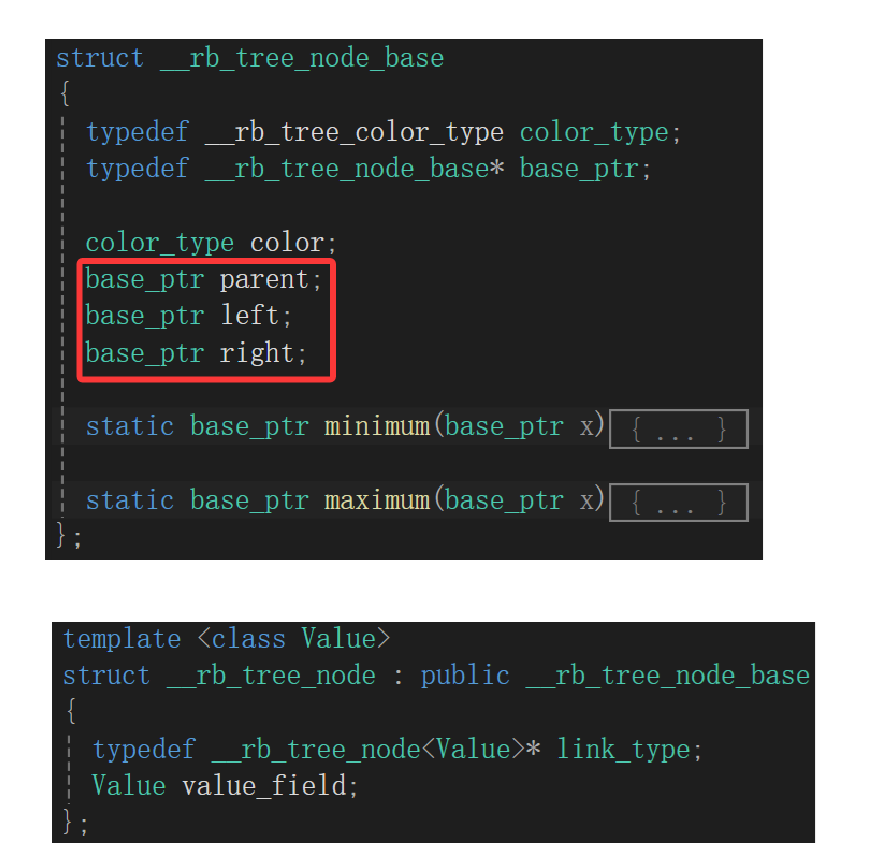
当然,如果是下面这种一个指向基类对象的指针强转成派生类就危险了,基类指针转派生类指针必须确定基类指针指向的内容,一定谨慎使用!!!
cpp
__rb_tree_node_base base_node;
__rb_tree_node<int>* derived_ptr = (__rb_tree_node<int>*)&base_node;
int value = derived_ptr->value_field; 2.迭代器成员函数设计
不废话昂,直接说结论:
迭代器的operator*、operator==之类的不用多说。
需要特别学习的就是operator++和operator--,因为要求迭代器遍历的顺序必须是按照底层红黑树的中序遍历的顺序。
对于operator++和operator--,库里面是把中序遍历的行为封装成:
看代码没啥用,所以怎么实现迭代器按照中序遍历顺序就不看了,找个图自己捋清逻辑。
四、设计map和set的迭代器
1.外壳
库里面设计map和set的迭代器,就那一个初始化给我看的头晕转向的,继承来继承去,还搞强转,实在是以我目前水平真看不出来有什么优势,不过我设计的红黑树结点就那一个类,也没搞继承,所以设计迭代器也不用套来套去的,直接:
cpp
//set
namespace xx
{
template <class K>
struct SetKOV
{
const K& operator()(const K& key)
{
return key;
}
};
template <class K>
class set
{
typedef RBTree<K, K, SetKOV<K>> rbt_type;
public:
typedef rbt_type::const_Iterator iterator;
typedef rbt_type::const_Iterator const_iterator;
bool insert(const K& key)
{
return _t.Insert(key);
}
private:
rbt_type _t;
};
}
cpp
//map
namespace xx
{
template <class K,class V>
struct MapKOV
{
const K& operator()(const pair<K,V>& kv)
{
return kv.first;
}
};
template <class K,class V>
class map
{
typedef RBTree<K, pair<K, V>, MapKOV<K, V>> rbt_type;
public:
typedef rbt_type::Iterator iterator;
typedef rbt_type::const_Iterator const_iterator;
bool insert(const pair<K, V>& kv)
{
return _t.Insert(kv);
}
private:
RBTree<K, pair<K, V>, MapKOV<K, V>> _t;
};
}外面套个typedef,实际上调用的红黑树的迭代器。
2.内涵
写迭代器内容还是一头雾水,猛一下也不知道写啥,那就想想我们用迭代器的时候需要用到什么:
cpp
set::iterator it = s.begin();
while (it != s.end())
{
cout << *it << " ";
++it;
}
cout << endl;①简单方法的实现
cpp
template <class K,class V>
struct RBTreeIterator
{
typedef RBTreeNode<K, V> Node;
typedef struct RBTreeIterator<K, V> Iterator;
Node* _node;
RBTreeIterator(Node* node)
:_node(node)
{}
V& operator*()
{
return _node->_data;
}
bool operator!=(const Iterator& it)
{
return _node != it._node;
}
};其他方法暂且不说,搞个这几个还是没问题的。
②begin和end设计思路
考虑考虑begin和end方法咋实现:
根据中序遍历顺序左根右。
第一个遍历到的结点一定是整棵树最左结点,因为只要一个结点有左子树,一定优先遍历左子树,因此begin方法应当是找整棵子树最左结点:
cpp
public:
typedef RBTreeIterator<K, V> Iterator;
typedef RBTreeIterator<const K,const V> const_Iterator;
Iterator begin()
{
Node* cur = _root;
while (cur && cur->_left)
cur = cur->_left;
return cur;
}
const_Iterator begin()const
{
Node* cur = _root;
while (cur && cur->_left)
cur = cur->_left;
return cur;
}如果容器为空,也考虑到了,容器为空循环进不去,cur = nullptr,直接返回nullptr,空容器的迭代器本身就不能解引用,如果此时解引用相当于给空指针解引用,到时候直接报错;
如果容器不为空,cur绝对是树的最左结点。
至于end方法,我暂时不知道怎么弄,理论上应该是整个二叉树遍历完后的下一个位置,谁遍历二叉树遍历完了还继续,也就现在写代码才考虑。
③operator++和operator--
++
研究如何实现operaotr++和operator--,其实也就是在树中遍历感受,到底如何设计,并且遍历完以后我也知道怎么设计end方法了:
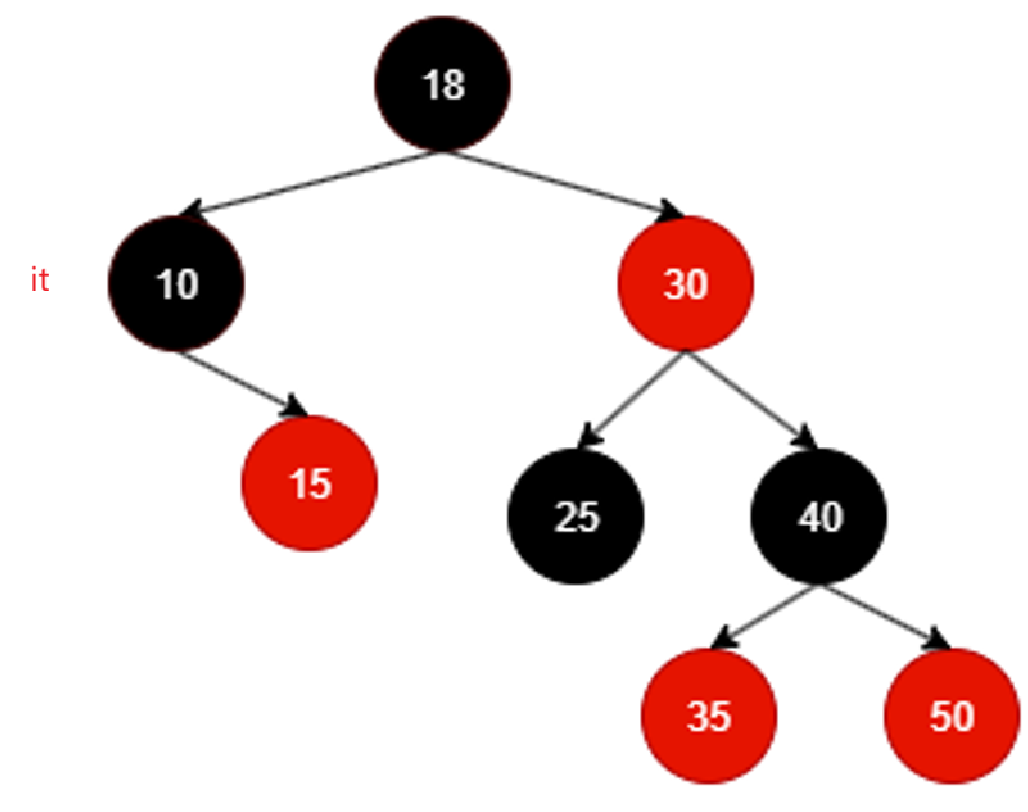
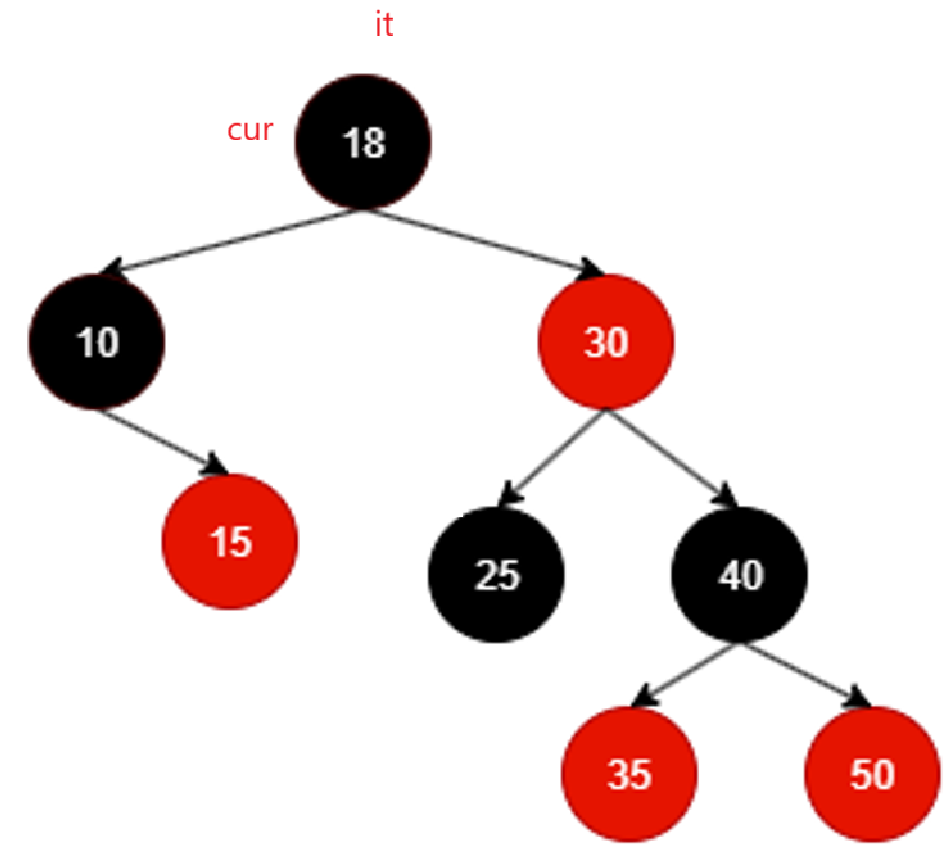
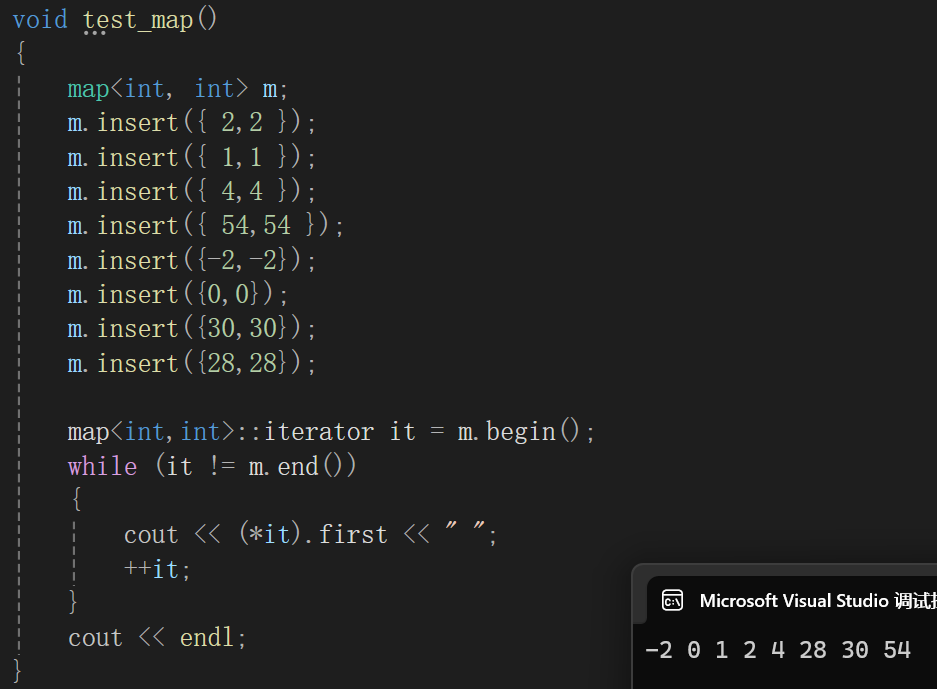
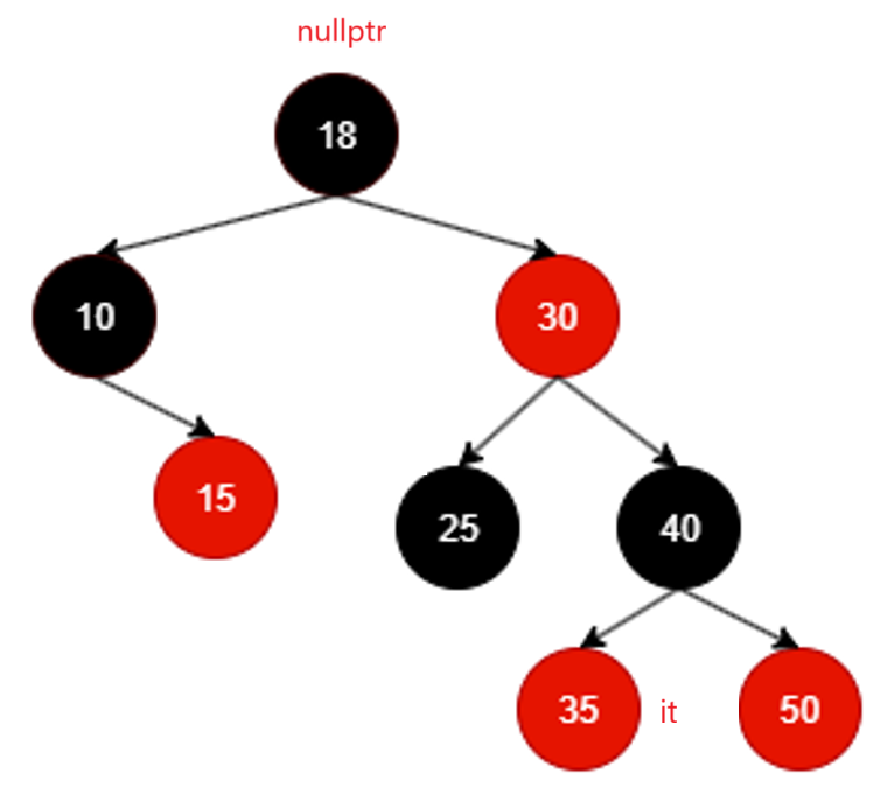
比如在这一棵红黑树里面,++it该何去何从?
10其实就是树的最左结点,由begin可以得到,那么由它往下走,左根右,它自己就是整棵树最左,迭代器指向10,所以现在相当于10为根的树的左子树和根遍历完毕,++就该遍历10的右子树,而且遍历10的右子树时候必须也遵循左根右,也就是当前遍历过的结点++应该去10的右子树找,而且情况允许应该也是找最左结点,不过右子树刚好没有左,所以还是直接遍历根:
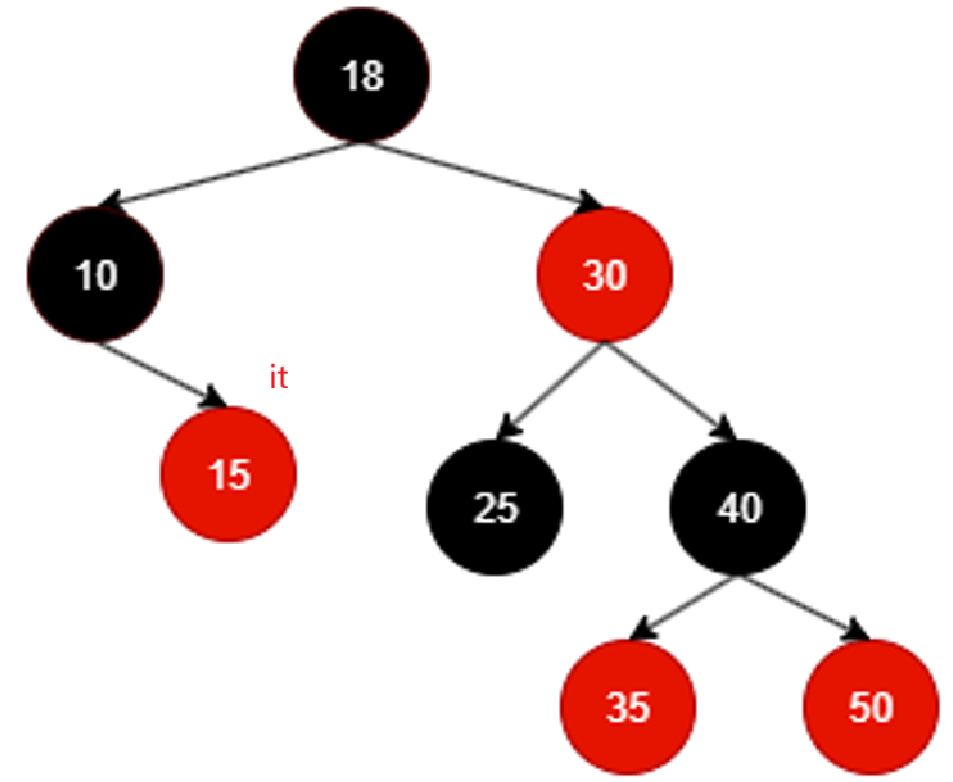
还按照刚才的去右子树里找就行不通了,因为15这个结点根本没有右子树,其实也合理,毕竟就算15有右子树,按照左根右左根右,早晚得遍历到底。这里相当于以15为根的子树遍历完毕。
那这个时候就应该回溯:
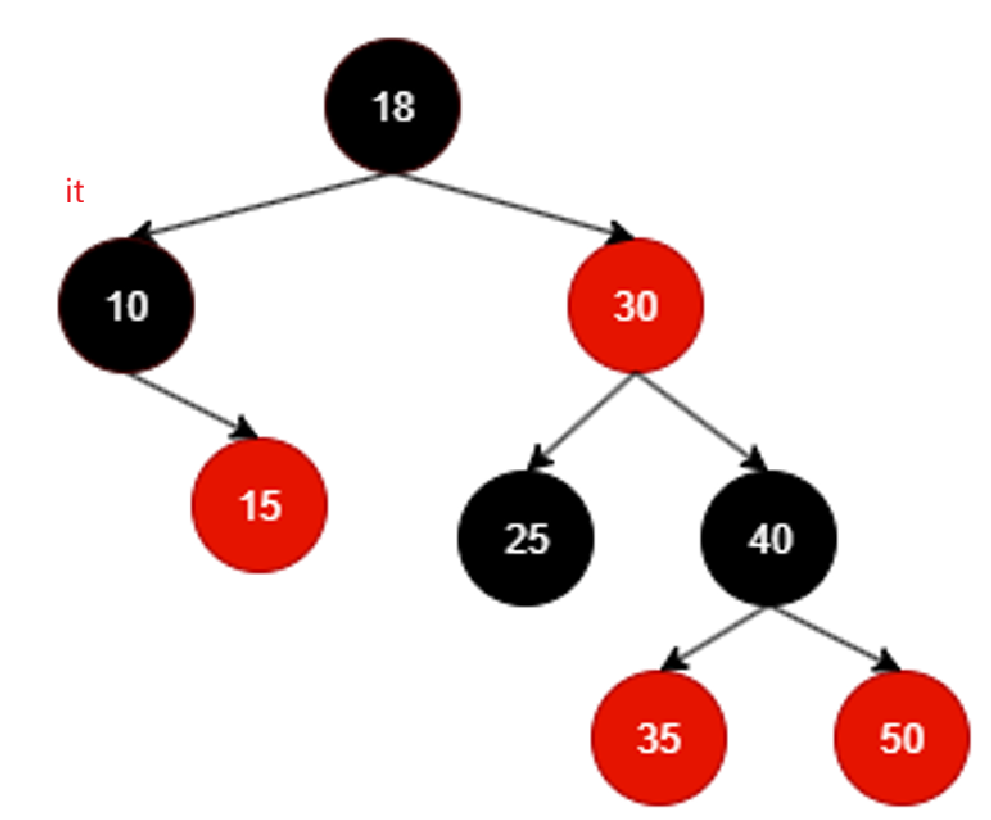
it回溯到10,10是18的左子树,根据左根右,以18为根结点的树左根右的左遍历完了,那就++该遍历根18:
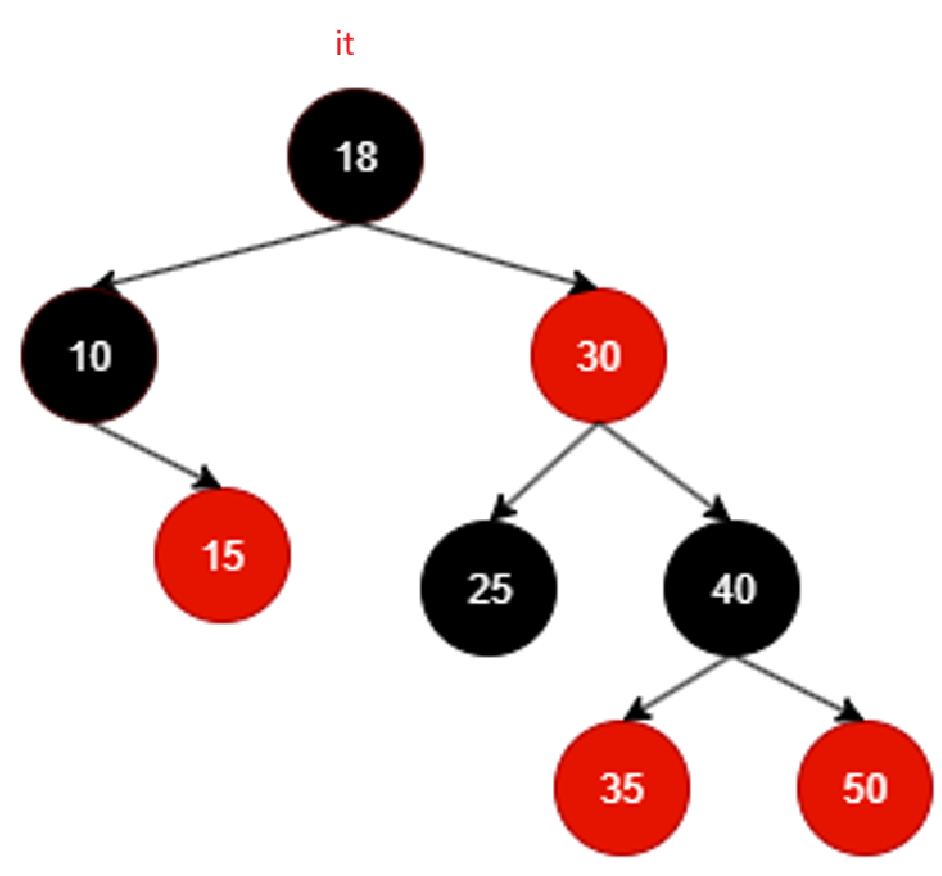
以18为根的树左根右的左根遍历完毕,继续++遍历那就该右了,同理,还是得去找18的右子树,但是对于18的右子树,我们也必须遵循左跟右的原则,所以相当于找的还是右子树的最左:
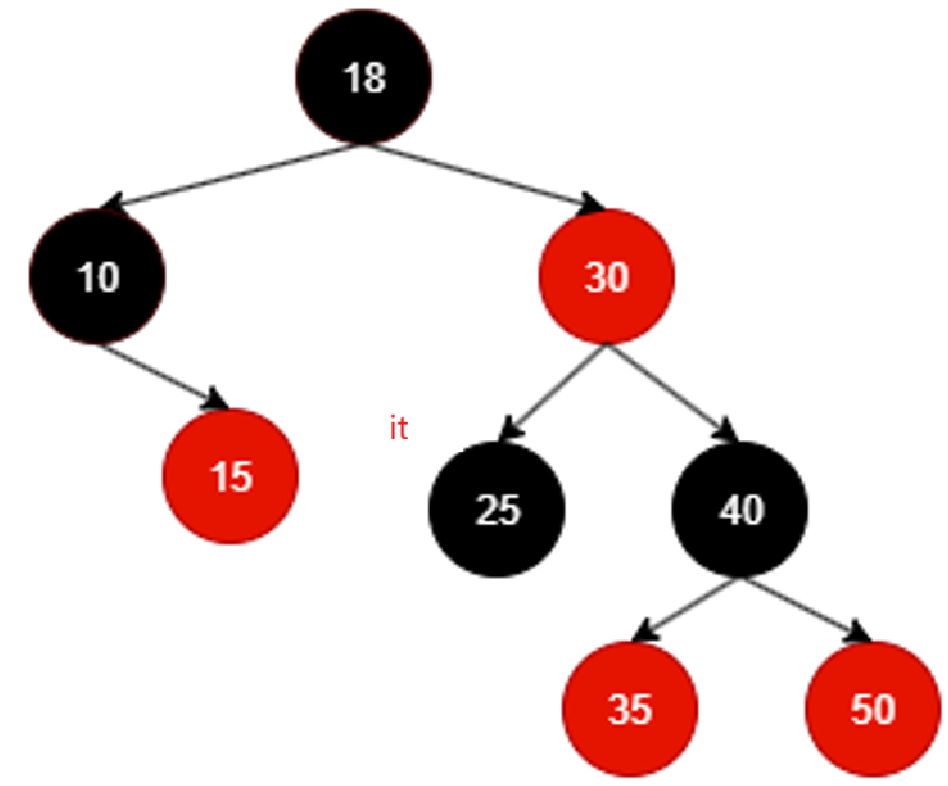
继续++遍历,那就是找25的右子树,又不存在,还判断出来25是30左子树,根据左根右,相当于30为根的子树的左子树遍历完成,该回溯到根了:
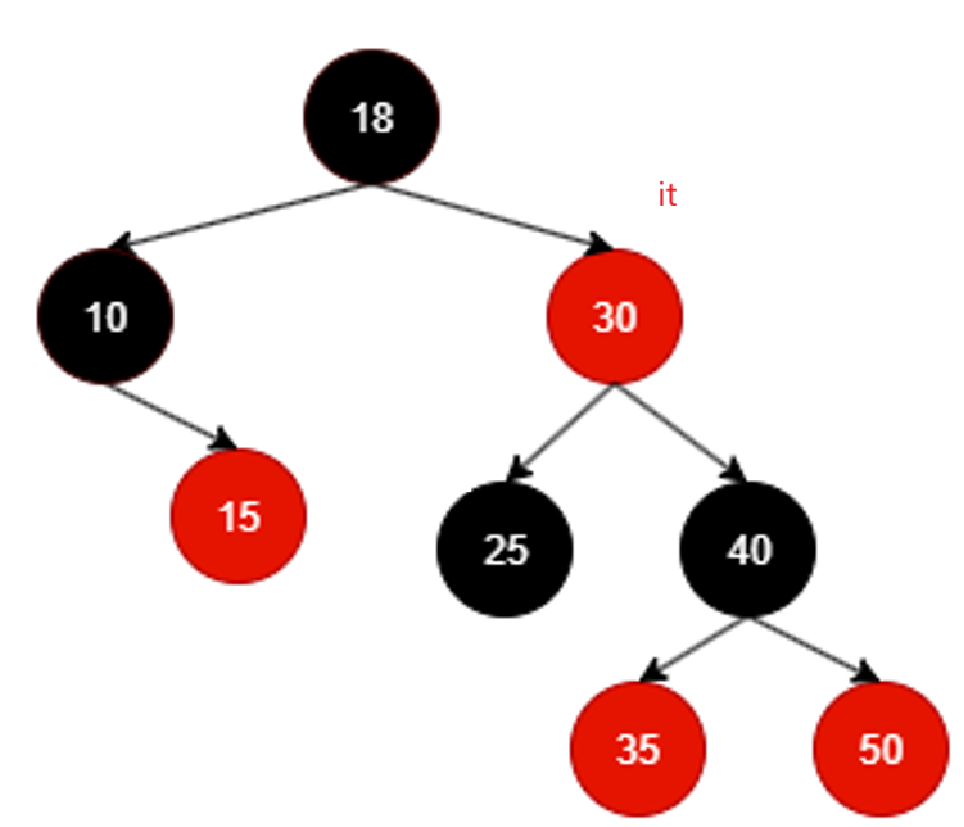
中间就不咋看了,直接看最后一个遍历到的有效结点:
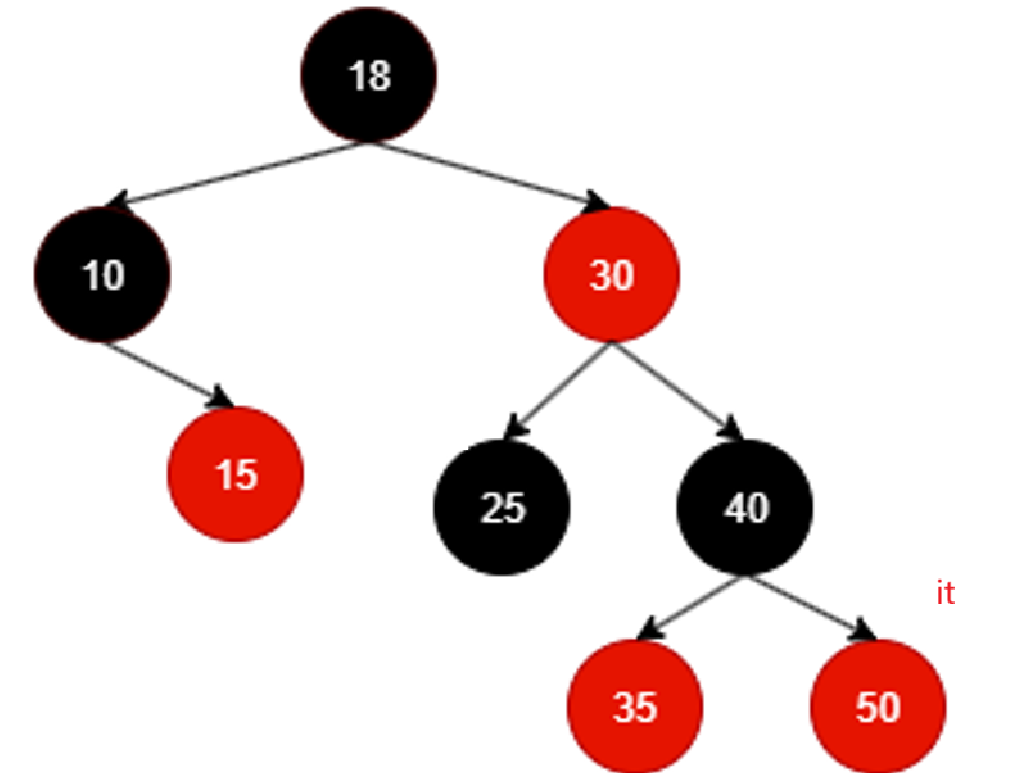
50没有右子树,而且不断回溯不断回溯,发现回溯到的结点都是别人的右子树,直至:
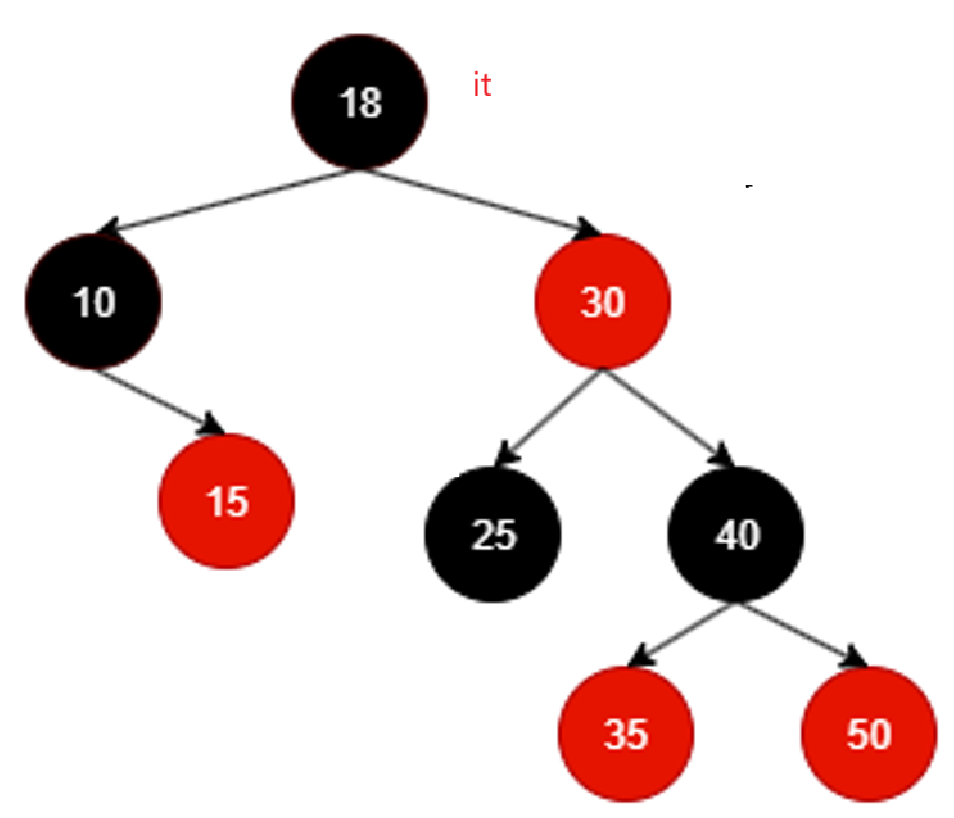
这里再回溯it == nullptr,其实代表整棵树遍历完毕了。
end
所以end就能写出来了:
cpp
Iterator end()
{
return nullptr;
}
const_Iterator end()const
{
return nullptr;
}话说回来昂,继续完善++逻辑:
迭代器所站位置的左子树必然遍历完毕,因为左根右的顺序,根位置同理。
++情况有两种:
如果右子树为空,回溯:
当前迭代器指向结点是父亲结点的右,那就再回溯(因为说明以这个父亲结点为根的这棵子树左根右也遍历完了);直至找到某个祖先是某个结点的左子树,那这个祖先的父亲就是我们要找的++的下一个;
如果右子树存在,进入到右子树以后找右子树的最左
尝试写写代码昂:
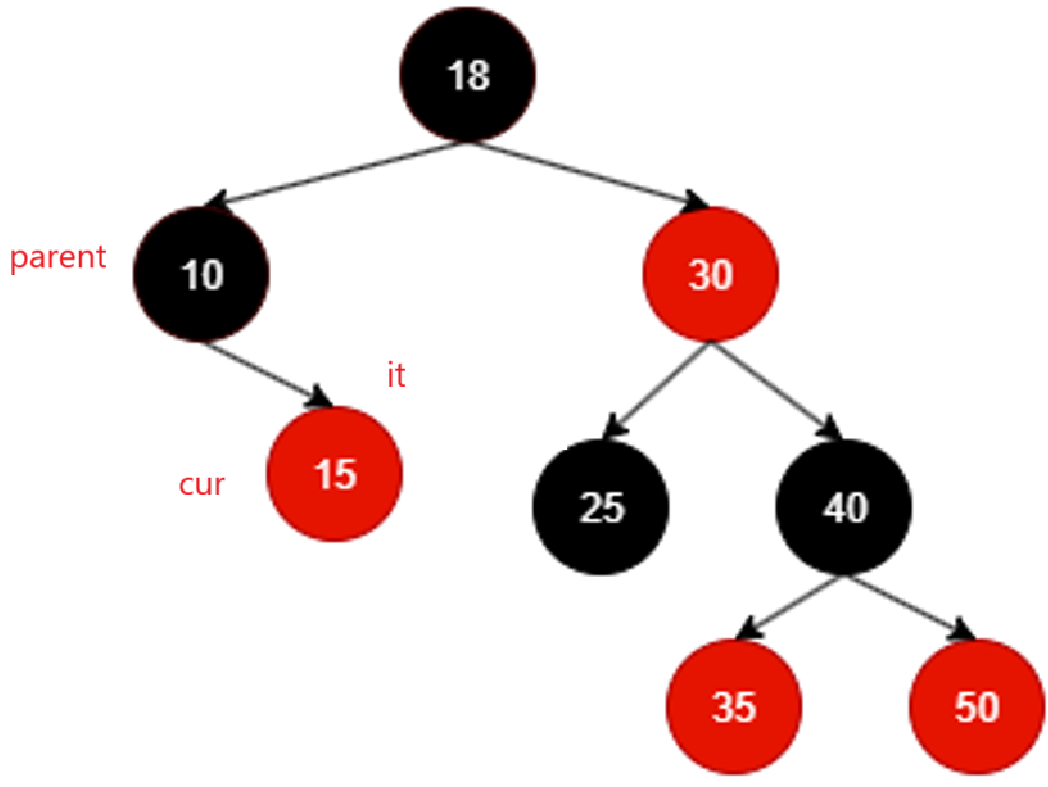
我写代码的时候看的就是这两张图。
cpp
Iterator operator++()
{
//cur只要在[begin,end)范围不可能为nullptr,除非逻辑错误或者使用者越界使用
Node* cur = _node;
Node* parent = cur->_parent;
if (cur->_right == nullptr)
{
while (parent)
{
if (parent->_right == cur)
{
cur = parent;
parent = parent->_parent;
}
else
return parent;
}
return parent;
}
else//cur->_right != nullptr
{
cur = cur->_right;
//一开始cur不可能为nullptr
//之后循环都是cur的left不为空才赋值
while (cur->_left)
cur = cur->_left;
return cur;
}
}当然,if回溯的代码如果进去,正常情况没问题,但极端情况,从最后一个有效结点++的话,那么会while内部的return无法捕捉,所以一旦while结束都没有return,说明parent == end() == nullptr,直接return parent就行。
弄完我突然想到,好像能改良:
cpp
Iterator operator++()
{
//cur只要在[begin,end)范围不可能为nullptr,除非逻辑错误或者使用者越界使用
Node* cur = _node;
Node* parent = cur->_parent;
if (cur->_right == nullptr)
{
while (parent&&parent->_right == cur)
{
cur = parent;
parent = parent->_parent;
}
return parent;
}
else//cur->_right != nullptr
{
cur = cur->_right;
//一开始cur不可能为nullptr
//之后循环都是cur的left不为空才赋值
while (cur->_left)
cur = cur->_left;
return cur;
}
}结果不能运行,我找了半天,没找到,最后问的ai:
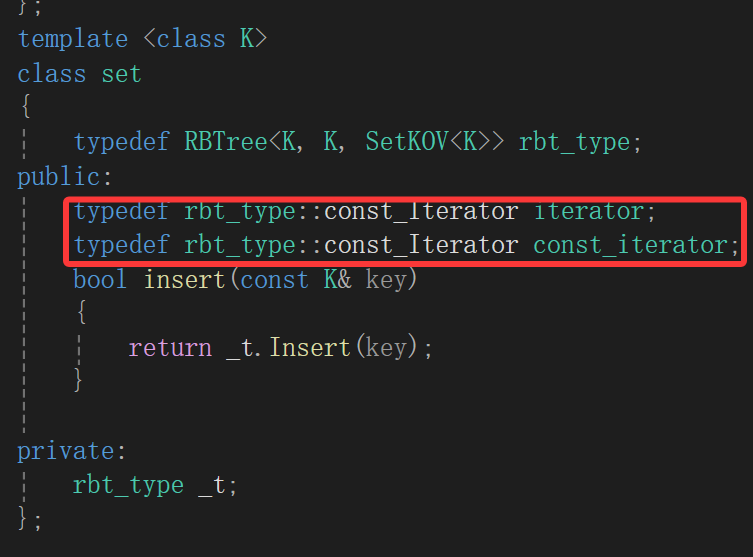
能用类域+类访问限定符::的可能是类型,可能是静态成员变量,编译器编译的时候自动认为是静态成员变量,静态成员变量哪能允许你typedef,这就是之前讲的typename的用法,注明就是类型。
第二个bug就是,我提前搞了个const_iterator给set,但是如果这么搞接口有问题:
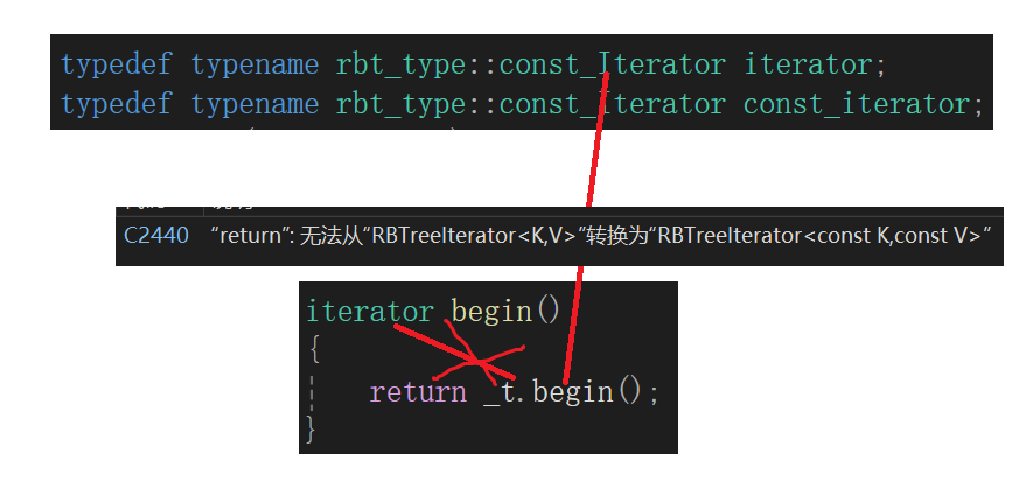
底层肯定调的非const_Iterator的接口,到这你又让它变成const_Iterator,没办法转换,所以这里我们直接这么设计:

传参传个const,这样从根就限制死了,不需要通过接口设计。
另外一测试发现:
cpp
Iterator& operator++()
{
//cur只要在[begin,end)范围不可能为nullptr,除非逻辑错误或者使用者越界使用
Node* cur = _node;
Node* parent = cur->_parent;
if (cur->_right == nullptr)
{
while (parent&&parent->_right == cur)
{
cur = parent;
parent = parent->_parent;
}
_node = parent;
}
else//cur->_right != nullptr
{
cur = cur->_right;
//一开始cur不可能为nullptr
//之后循环都是cur的left不为空才赋值
while (cur->_left)
cur = cur->_left;
_node = cur;
}
return *this;
}我每个地方都是返回的临时变量的值,并没有说修改并返回++后的值,再修改一下。
测试:
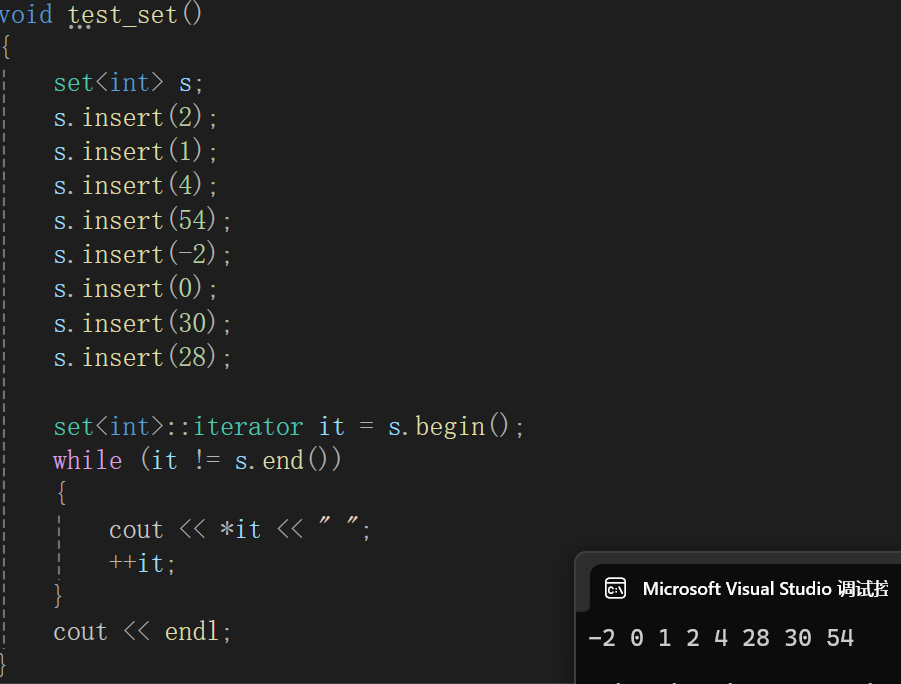
忘了operator->,看见这个就想起来了,没需求代码真是不知道干啥。
cpp
V* operator->()
{
return &(_node->_data);
}没毛病嗷,顺手搞个后置++:
cpp
RBTreeIterator(const Iterator& it)
{
_node = it._node;
}
Iterator operator++(int)
{
Iterator temp(*this);
++(*this);
return temp;
}后置++得先保留初始值,再++,所以又搞了个拷贝构造。
--
还是拿着那图研究--:
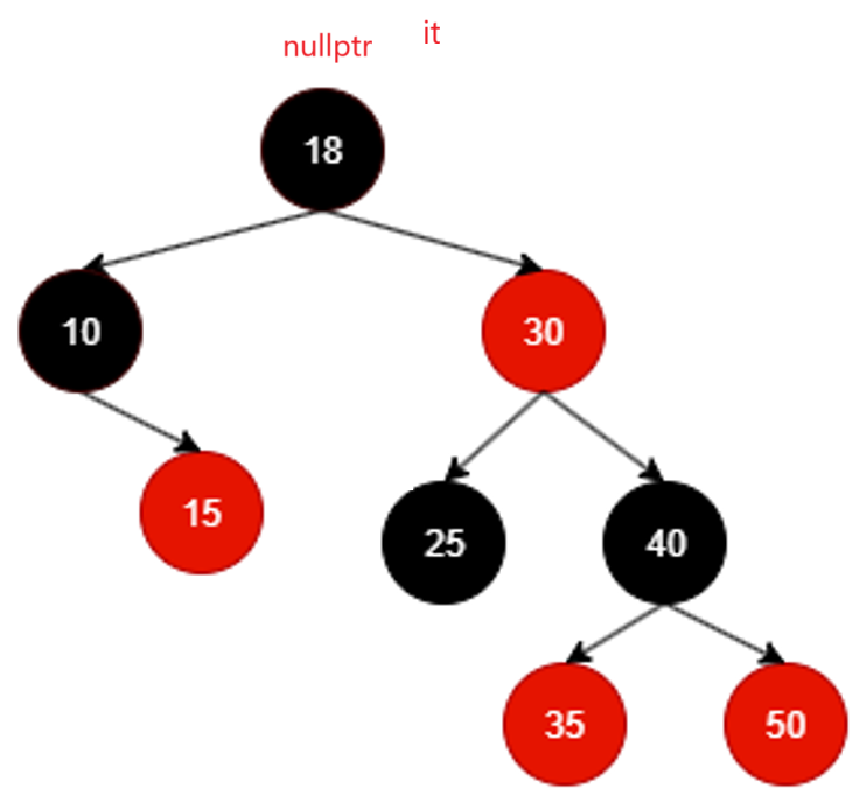
如果从end开始_node肯定是nullptr,这个时候也不用管_node,直接根据左根右,去找整棵树最右节点。
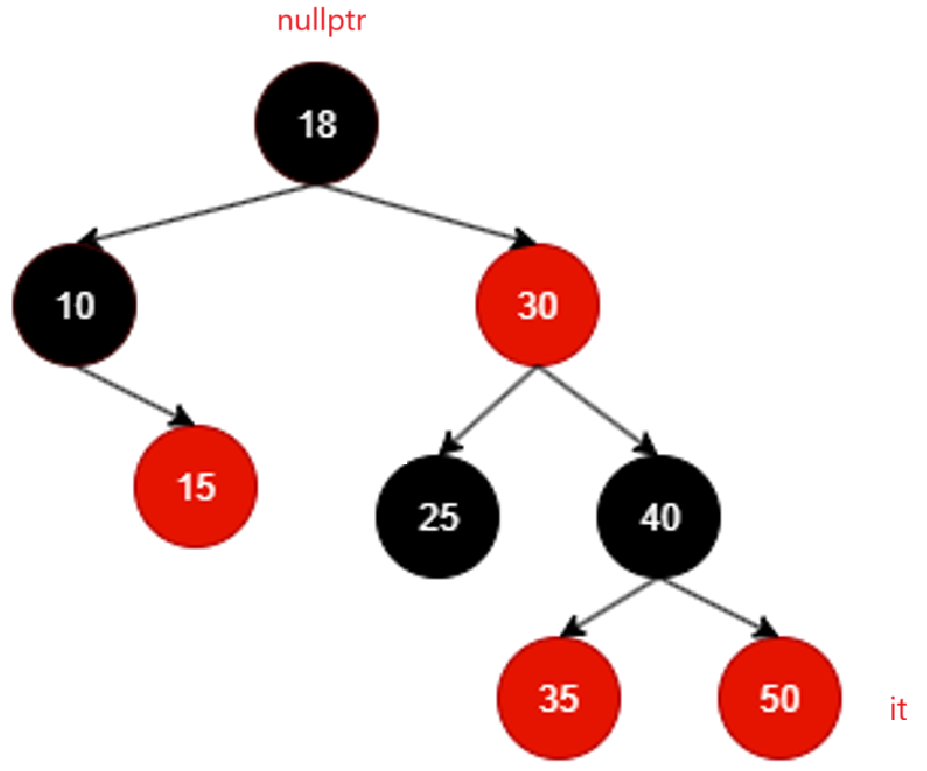
如果是没有左子树且是右子树的话,左根右反过来就是右根左,直接找根去。
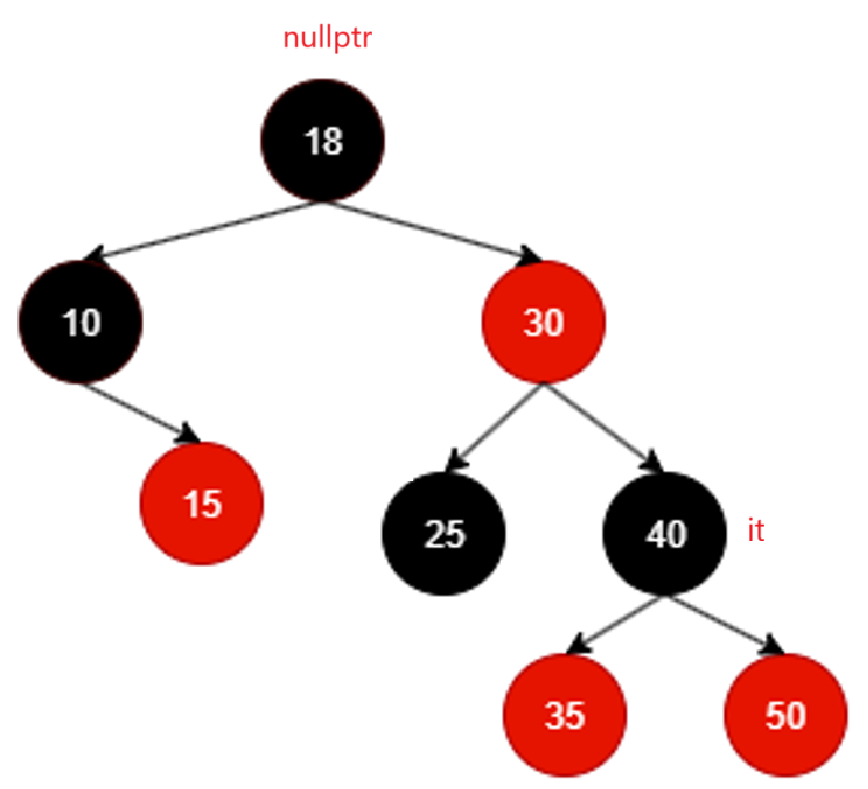
但是到这就发现,如果有左子树的话优先进入左子树,而且不难想到,一定得走到左子树的最右:
继续遍历,如果没有左子树且是左子树的话,得找到某个祖先是其父亲结点的右子树为止。
其实就是反过来了逻辑。
代码表达:
cpp
Iterator& operator--()
{
Node* cur = _node;
if (_node == nullptr)
{
cur = _root;
while (cur && cur->_right)
cur = cur->_right;
_node = cur;
}
if (cur->_left == nullptr)
{
Node* parent = cur->_parent;
while (parent && parent->_left == cur)
{
cur = parent;
parent = parent->_parent;
}
_node = parent;
}
else//cur->_left != nullptr
{
cur = cur->_left;
while (cur->_right)
cur = cur->_right;
_node = cur;
}
return *this;
}设计出来倒不是啥难事,问题就在于--这个方法需要拿到红黑树的root,经过我不怎么聪明的脑袋瓜思考,在类外访问class里的private成员根本就是痴人说梦;get方法可以拿,但是这个方法怎么能设置成只有iterator类可以用呢,我就想不到了。
除了get方法我想到的就是给iterator多搞个成员变量_root,专门存储,但是这么搞我们所有的return语句,只要是跟迭代器有关的都得多加个_root,太麻烦了。
最后我又想到了,继承,能不能搞一个类专门存_root,让iterator类继承再专门给iterator类用呢?
但是想了想还是得构造函数初始化跟多搞个_root一个效果。
我问了问ai,这个问题大致解决问题就是存_root,或者搞个header,头结点,只不过二叉树如果加头结点的话是这么加的:
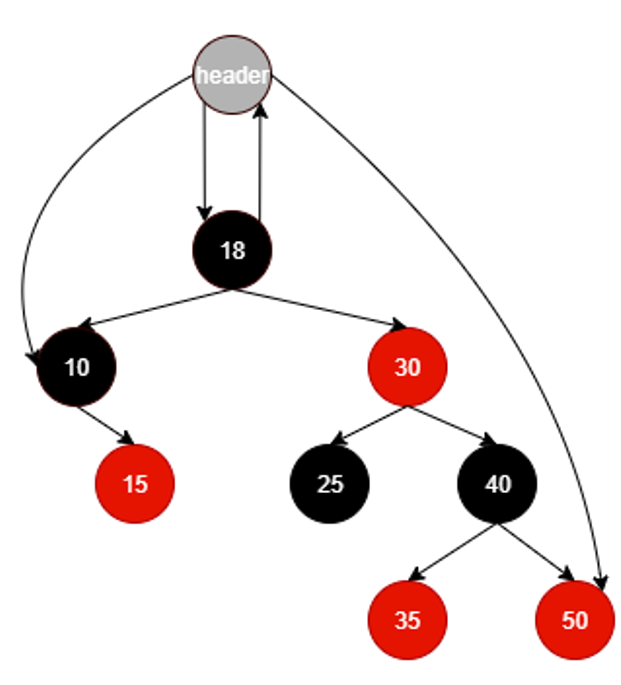
头结点左孩子是中序遍历第一个结点;右孩子是中序遍历最后一个结点;与二叉树的_root构成共轭父子,有这玩意找_root方便的很。
但是要加头结点,我们之前写的好多代码就都得缝缝补补,为了不用缝缝补补又三年的代码,我做出了一个违背祖宗的决定,那就是--不实现了,因为最重要的思想我们都有了,并且确实上手实现了,没必要浪费时间了,这可不是避重就轻,你吃西瓜不吃中间最甜的,去啃西瓜皮干啥。
五、设计map的operator\[\]
本来可能是个难事,但是库里面给咱弄的明明白白的:
cpp
V& operator[]()
{
return (*((this->insert(make_pair(k, mapped_type()))).first)).second);
}当然,如果真要搞这个还得改改insert的返回值和实现细节,毕竟这里面俩pair,一个是map存的pair<K,V>,一个是pair<bool,iterator>,细节真不再说了,分析好几次了。
经典用法,不多bb了。
六、设计find方法
红黑树底层细节:
cpp
Iterator Find(const K& key)
{
Node* cur = _root;
while (cur)
{
if (key < kov(cur->_data))
cur = cur->_left;
else if (key > kov(cur->_data))
cur = cur->_right;
else
return cur;
}
return nullptr;
}道理还是那个道理,只不过key得用kov取,并且返回值套个Iterator。
从Find方法中可以知道,我们还是用的到模板的第一个参数K的,毕竟Find方法看的就是key,也包括erase方法,其实也是只看key,所以可不能说人家库里面设计都是瞎设计,可能你写的少没碰见用的情况,但是吧,也不能把库里的当信条,设计的时候有整体架构,说不定哪里设计的时候就欠考虑。
set和map套个壳就行了。
小结
稍微再说几句昂,map和set的实现主要是学设计思想,比如多个kov就可以用key-value树同时封装k和pair<k,v>结构,或者说学习迭代器迭代思路,怎么去找。
除了操作,学会读代码也是非常重要的训练。