模型介绍:公式
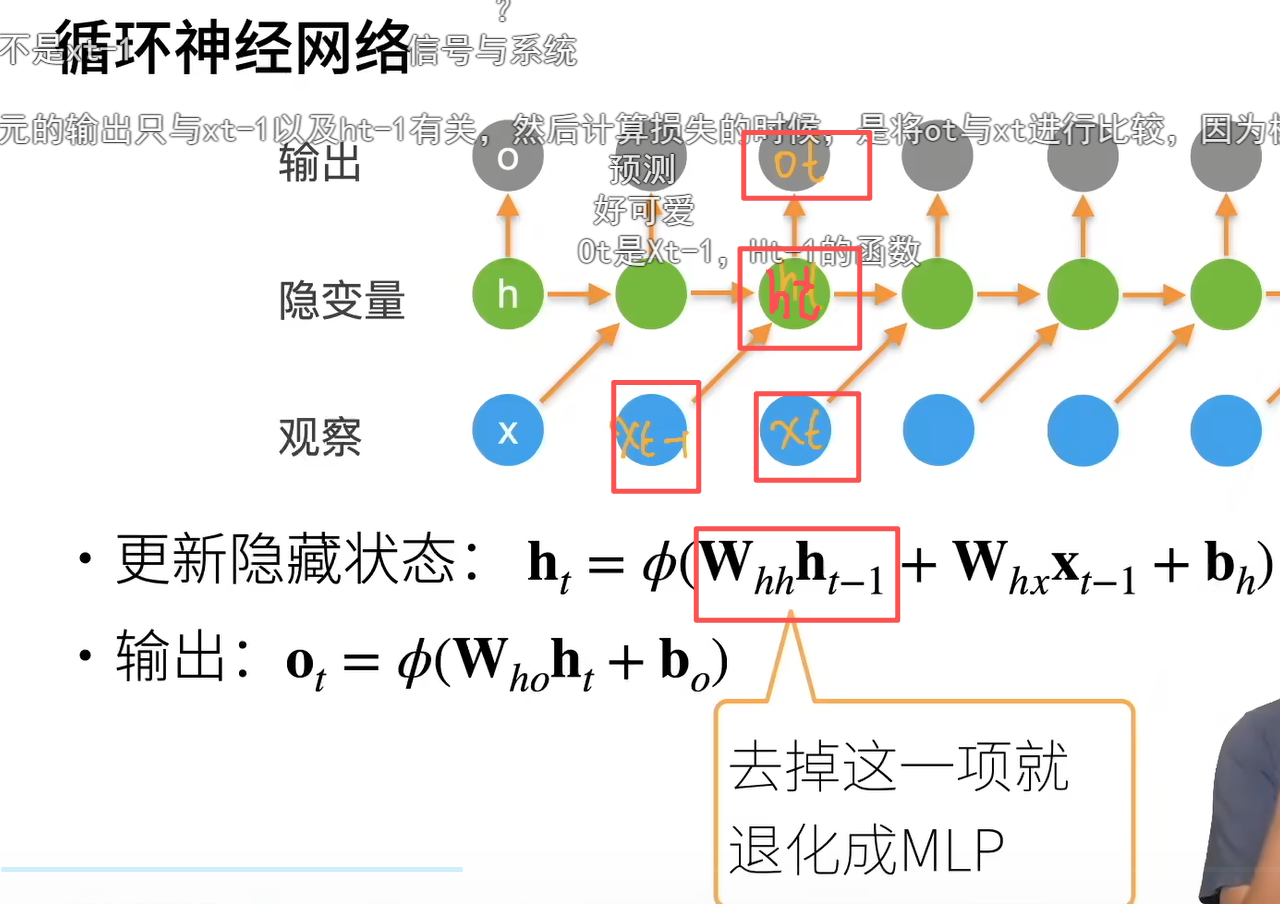
这里意思是 在循环卷积网络中当前神经元的输出只与xt-1以及ht-1有关,然后计算损失的时候,是将ot与xt进行比较,因为模型的下一个输出就是序列的下一个
不是n元语法,因为这里的因变量ht实际上包含了前面任意长序列的信息,不只是几元。
吴恩达老师那里课件的公式是:h_t = f(W_hh * h_t-1 + W_hx * x_t + b_h) (强推他的讲解)
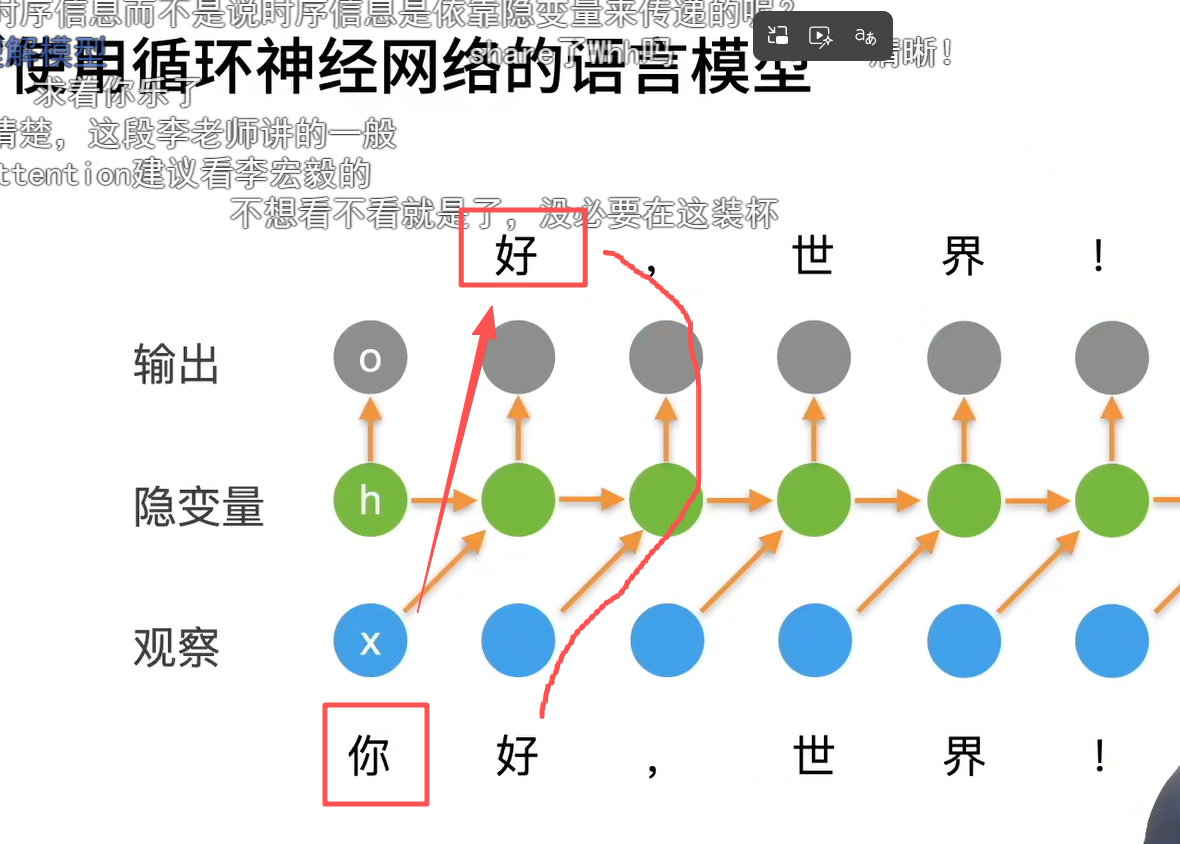
这里的t不要理解成下标,理解成时间,结合应用你要根据前面一个字(t-1),预测下一个字(t),下标不是重点,标的不同解释不同而已,重要的是结合老师前面那个例子来理解模型
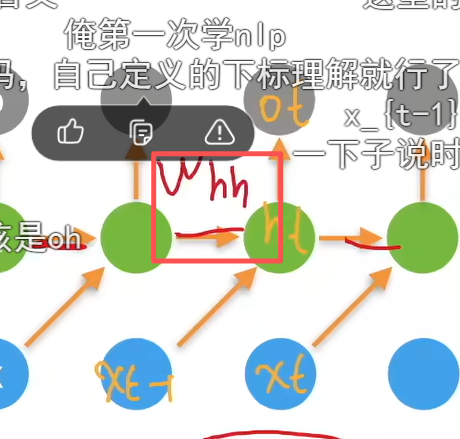
反正理解李沐老师想表达的意思就行,把最下面一行都往右边移动一步 就是和吴恩达老师一致的了

衡量好坏标准:困惑度

t是要预测的序列,i是一共有多少种词组分类选择的下标
-
困惑度 exp(π):这是对交叉熵取指数,目的是把"信息量(比特/纳特)"还原成"猜测的概率(分支数)",让指标更符合人类直觉。
-
1表示完美:当模型预测完全准确时,p=1,log(1)=0,exp(0)=1。
困惑度1表示完美,因为意味着平均交叉熵的值为0,log(p)=0, p=1
最好就是n个p都尽可能趋近于1,最差就是n个p全都趋近于0
exp就是取指数 这样数值比较大

什么是"长尾分布"(一句话)
在很多真实系统里:
-
头部:少数高频词/句式出现千万次("的/是/我/你...")
-
尾巴 :海量低频词/稀有实体/边缘情况各自只出现几次甚至一次("某化学名词""某地名拼写""罕见 bug 句子")
画出来就是一条很陡的曲线,然后拖着一条很长很长的尾巴------这就是长尾。

梯度爆炸->裁剪:重要

深度学习训练过程中的一种常见现象------梯度爆炸 ,以及对应的解决方法------梯度裁剪。为了让你更容易理解,我们可以跳过复杂的数学公式,用大白话来拆解这三个核心点:
- 为什么训练会出问题?
-
现象 :在处理长文本或长时间序列时(比如一句话有100个字),计算机需要一步步反向传播误差。这个过程就像是一个传话游戏,信息要传100遍。
-
后果 :在传递过程中,数字很容易像滚雪球一样越滚越大(即文字中提到的"数值不稳定"),导致下一次更新模型参数时用力过猛,模型直接"崩溃"或训练失败。这在学术上叫梯度爆炸。
- 怎么解决?(公式部分)
为了解决这个问题,人们想了一个非常直观的办法,就像图片里写的:"如果梯度长度超过 θ,那么拖影回长度 θ"。
-
梯度的物理意义 :你可以把"梯度"想象成一辆车的行驶速度。
-
限制速度 :θ就是一个设定的最高限速。
-
操作逻辑:如果车子开得太快(梯度太大),我们就强制踩刹车,把速度降到最高限速 θ(裁剪);如果车子开得慢(梯度正常),就不管它,照常行驶。
- 具体的数学动作
图片下方的公式 g←min(1,∥g∥θ)g就是在执行上面的逻辑:
-
它算出了当前的速度(∥g∥)和限速(θ)的比例。
-
如果比例大于1(超速了),就按比例缩小当前的速度,保证缩小后的最大速度刚好等于 θ。
-
这样既能保留前进的方向,又保证了不会因为速度太快而冲出跑道。
简单来说,这段话的核心意思是:为了防止电脑在更新模型时用力过猛,我们设定了一个速度上限,一旦超过这个上限就强行按比例缩小,从而保证训练过程平稳进行。
小结:

简洁实现:

dir(xx):查看该东西所有可用属性和方法
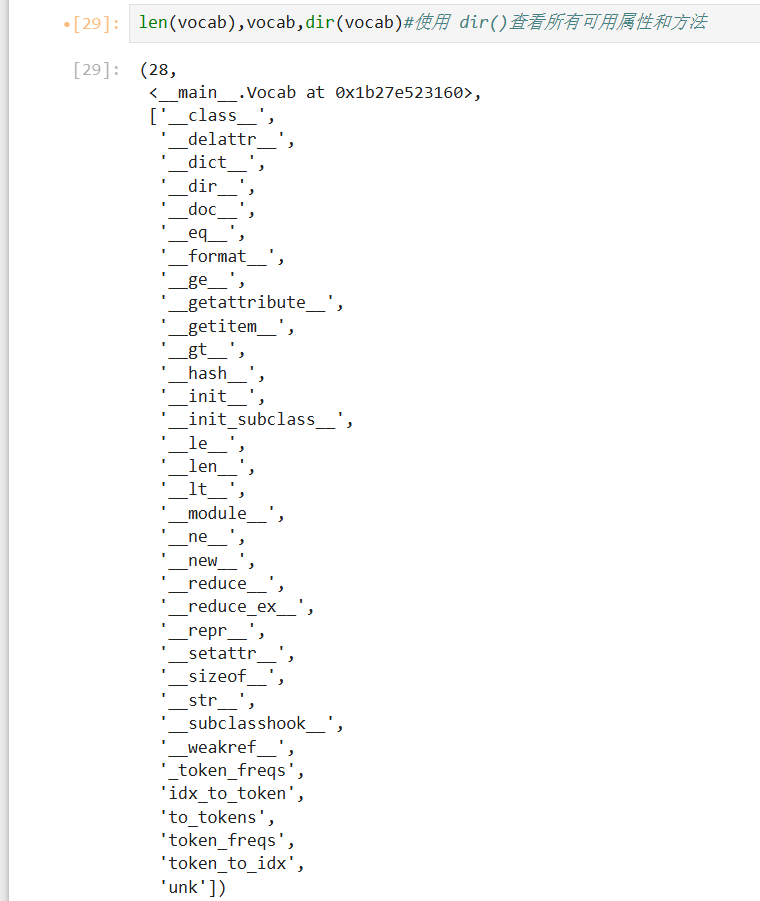
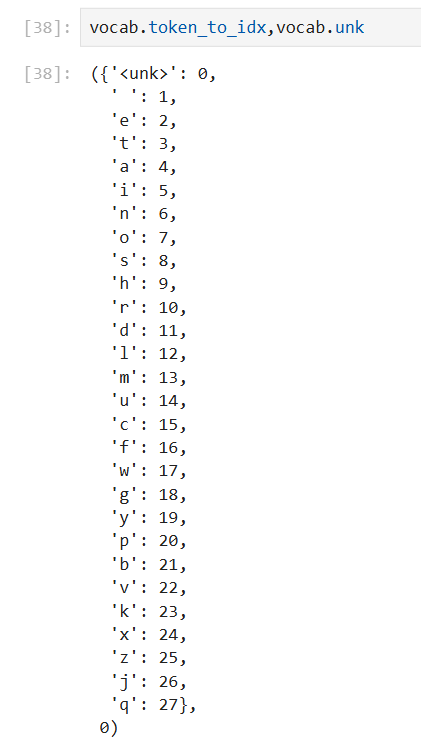

特殊方法(用来支持操作)这些是 Python 内部用来支持特定语法的"幕后功臣":
-
__len__:这就是你代码里len(vocab)背后调用的东西,返回词典的大小(不包含特殊符号如 padding 的话可能少几个)。 -
__getitem__:支持直接用方括号取词,比如vocab['hello']能直接返回 'hello' 对应的 id。
python
# 设置RNN隐藏单元数为256
num_hiddens = 256
# 创建一个单层RNN层,输入维度为词汇表大小(len(vocab)),隐藏层大小为256
rnn_layer = nn.RNN(len(vocab), num_hiddens)
"""nn.RNN是 PyTorch 内置的单层 RNN 模块。
输入维度 = 词汇表大小(len(vocab)),即每个字符用一个 one‑hot 向量表示。
隐藏单元数 = 256,控制记忆容量。
rnn_layer 结果RNN(28, 256)
"""
# 初始化隐状态:形状为 (1, batch_size, num_hiddens)
# 1表示只有一层RNN,batch_size是批大小,num_hiddens是隐藏单元数
state = torch.zeros((1, batch_size, num_hiddens))
state.shape # 输出形状,验证正确性
结果 torch.Size([1, 32, 256])
#初始化隐状态 state,形状 (层数, 批量大小, 隐藏单元数)。这里层数为1,所以第一个维度是1。
# 构造一个随机输入张量,模拟序列数据
# 形状:(num_steps, batch_size, len(vocab)) ------ 时间步数×批量大小×词表大小
X = torch.rand(size=(num_steps, batch_size, len(vocab)))
# 将输入X和初始状态state传入RNN层,得到输出Y和新状态state_new
Y, state_new = rnn_layer(X, state)
# 查看输出Y的形状:(num_steps, batch_size, num_hiddens)
# 新状态state_new的形状:(1, batch_size, num_hiddens) ------ 最后一层的最终隐状态
Y.shape, state_new.shape
结果(torch.Size([35, 32, 256]), torch.Size([1, 32, 256]))
"""这里Y并不是输出 而是最后一个隐藏层 所以这里的维度是256 而不是len(vocab)
Y是每个时间步的隐状态,这些隐状态可以用作后续输出层的输入 并不是输出
Y是所有h的集合,rnn循环了35次(时间步35),产生了35个h"""
"""模拟一个随机输入 X:时间步数 × 批量大小 × 词表大小。
经过 RNN 层后:
Y形状 (num_steps, batch_size, num_hiddens):每个时间步的输出(最后一个隐藏层的输出)。
state_new形状 (1, batch_size, num_hiddens):最后一个时间步的隐状态(可用于继续生成)
"""
# @save 标记表示这个类将被保存以便后续复用
class RNNModel(nn.Module):
"""循环神经网络模型"""
def __init__(self, rnn_layer, vocab_size, **kwargs):
super(RNNModel, self).__init__(**kwargs)
self.rnn = rnn_layer # 传入的RNN层(可以是普通RNN、GRU或LSTM)
self.vocab_size = vocab_size # 词汇表大小
self.num_hiddens = self.rnn.hidden_size # 获取RNN层的隐藏单元数
# 判断是否为双向RNN,决定输出线性层的输入维度
if not self.rnn.bidirectional:
self.num_directions = 1
# 单向:线性层输入维度 = 隐藏单元数
self.linear = nn.Linear(self.num_hiddens, self.vocab_size)
else:
self.num_directions = 2
# 双向:线性层输入维度 = 隐藏单元数 × 2(正向+反向)
self.linear = nn.Linear(self.num_hiddens * 2, self.vocab_size)
def forward(self, inputs, state):
# 将输入进行 one-hot 编码
# inputs形状:(batch_size, num_steps),T()转置为(num_steps, batch_size)
# 编码后形状:(num_steps, batch_size, vocab_size)
X = F.one_hot(inputs.T.long(), self.vocab_size)
X = X.to(torch.float32) # 转为float32类型,便于计算
# 通过RNN层,返回输出Y和新状态state
# Y形状:(num_steps, batch_size, num_hiddens)
Y, state = self.rnn(X, state)
#Y是所有时间步的隐藏层状态,state是最后一个时间步的
# 将Y重塑为二维矩阵:(时间步数×批量大小, 隐藏单元数)
# 然后通过全连接层映射到词汇表大小,得到每个时间步每个样本的预测分数
output = self.linear(Y.reshape((-1, Y.shape[-1])))
# output形状:(num_steps * batch_size, vocab_size)
return output, state
def begin_state(self, device, batch_size=1):
"""初始化隐状态(根据RNN类型返回不同结构)"""
if not isinstance(self.rnn, nn.LSTM):
# 对于普通RNN或GRU:隐状态是一个张量
# 形状:(num_directions * num_layers, batch_size, num_hiddens)
return torch.zeros((self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens),
device=device)
else:
# 对于LSTM:隐状态是一个包含两个张量的元组(h0, c0)
return (torch.zeros((
self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens), device=device),
torch.zeros((
self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens), device=device))
"""继承 nn.Module,封装整个模型。
__init__
接收外部创建的 rnn_layer(可以是普通 RNN、GRU 或 LSTM)。
self.rnn = rnn_layer
self.vocab_size = vocab_size
self.num_hiddens = self.rnn.hidden_size
判断是否双向:如果是双向,则线性层输入维度需乘以2(正向+反向);否则直接用 num_hiddens。
定义 self.linear = nn.Linear(...):将 RNN 输出映射回词汇表大小,得到每个字符的得分(logits)。
forward
输入 inputs:形状 (batch_size, num_steps),元素是字符索引(整数)。
先做 one‑hot 编码:F.one_hot(inputs.T.long(), self.vocab_size)
.T转置为 (num_steps, batch_size),方便 RNN 按时间步处理。
编码后形状 (num_steps, batch_size, vocab_size),并转成 float32。
送入 self.rnn(X, state),得到 Y(所有时间步输出)和 state(最终隐状态)。
将 Y重塑为二维:Y.reshape((-1, Y.shape[-1])),即 (num_steps * batch_size, num_hiddens)。
通过 self.linear得到 output,形状 (num_steps * batch_size, vocab_size)。
返回 output和 state。
begin_state
用于初始化隐状态,适配不同 RNN 类型:
普通 RNN / GRU:返回一个零张量,形状 (方向数×层数, batch_size, num_hiddens)。
LSTM:返回元组 (h0, c0),两个相同形状的张量。"""
# 尝试使用GPU(如果可用)
device = d2l.try_gpu()
# 创建RNN模型实例,传入之前定义的rnn_layer和词汇表大小
net = RNNModel(rnn_layer, vocab_size=len(vocab))
net = net.to(device) # 将模型移动到设备(GPU/CPU)
# 使用d2l库中的predict_ch8函数,用当前未训练的模型生成文本
# 给定前缀'time traveller',预测接下来的10个字符
d2l.predict_ch8('time traveller', 10, net, vocab, device)
"""用 GPU(若有)加速。
predict_ch8是 d2l 提供的辅助函数:给定前缀字符串,利用当前模型逐个预测后面10个字符。此时模型未训练,输出是随机的。"""
# 训练参数:迭代500轮,学习率1
num_epochs, lr = 500, 1
# 调用d2l的train_ch8函数进行训练
# train_iter:训练数据迭代器;vocab:词汇表对象;lr:学习率;num_epochs:轮数;device:设备
d2l.train_ch8(net, train_iter, vocab, lr, num_epochs, device)
"""train_iter:从文本数据构建的批量迭代器,每次返回一批 (X, y)字符序列。
训练过程(由 train_ch8内部实现):
在每个 epoch 中遍历所有批次。
初始化隐状态(调用 net.begin_state)。
前向传播得到 output,与目标字符索引计算交叉熵损失。
反向传播更新参数。
每若干步打印困惑度(perplexity)和生成样例。
训练完成后,模型能学会字符之间的统计规律,例如生成像 "time traveller" 风格的新文本。"""这段代码实现了一个基于RNN的字符级语言模型,用于预测文本中的下一个字符。主要步骤:
-
定义RNN层(
nn.RNN)并设置隐藏单元数。 -
封装为
RNNModel类,处理前向传播(包括one-hot编码、RNN计算、全连接输出)和隐状态初始化。 -
使用
d2l工具包中的predict_ch8测试未训练模型的生成效果(通常乱码)。 -
调用
train_ch8进行训练,优化模型参数,使其学会根据上下文预测下一个字符。
注意:代码中的vocab、train_iter、batch_size、num_steps等变量需要在前面定义(通常来自d2l的数据加载部分)。
时间步概念:
1. 什么是时间步?
核心定义:一次看多少字
num_steps代表模型在一次计算(一次前向传播)中,能够同时处理的连续字符(或单词)的数量。
你可以把它理解为模型的**"视野宽度"** 或**"时间窗口大小"**。
结合图片例子理解
图片中提到:"比如一次看 35 个字符来预测下一个字符"。
-
如果
num_steps = 5:模型一次只能看到 5 个字符。比如输入 "hello",模型看到的是
['h', 'e', 'l', 'l', 'o']。-
优点:计算快,显存占用少。
-
缺点:如果句子很长(比如 100 个字),模型只能看到前面 5 个字,看不到更远的上下文,可能会影响预测准确性。
-
-
如果
num_steps = 35(如图片所述):模型一次能看到 35 个字符。它能根据前面 35 个字的语境来猜下一个字。
-
优点:上下文信息更丰富,预测更准。
-
缺点:计算量大,需要更多显存。
-
在代码和公式中的体现
-
在输入数据
X中:X的形状通常是(num_steps, batch_size, vocab_size)。这意味着你把一长串文本切成了许多个长度为
num_steps的小片段(Segments)。 -
在 RNN 公式中:
num_steps决定了循环的次数。公式里的 xt会不断迭代,从 t=1一直到 t=num_steps。
时间步是序列数据中的"位置编号"。
-
在处理文本时,一个句子由多个字符组成,比如
"hello"有 5 个字符,每个字符就是一个时间步。 -
在代码中,
num_steps就是一次处理多少个连续的时间步(比如一次看 35 个字符来预测下一个字符?)。
形象理解:时间步就像电影胶片的一帧一帧画面,按顺序播放。
2. 什么是隐藏层?
隐藏层是神经网络中负责计算的"层级结构"。
-
在 RNN 中,隐藏层由一组带权重的神经元组成,每个时间步都共享同一套权重。
-
nn.RNN(len(vocab), num_hiddens)创建了一个单隐藏层 的 RNN,其中num_hiddens是该隐藏层的神经元数量(即隐藏单元数)。 -
如果是多层 RNN(比如
nn.RNN(..., num_layers=2)),就有两个隐藏层堆叠起来,上一层输出作为下一层输入。
形象理解:隐藏层就像一个加工车间,每个时间步送进来的原料(输入)都要经过这个车间加工,车间内部的机器(权重)是不变的,但车间的"工作台状态"(隐状态)会随着每个时间步更新。

整体流程:(重要)
输入: inputs (batch_size, num_steps) # 字符索引
↓ one-hot 编码
X: (num_steps, batch_size, vocab_size)
↓ RNN 层
Y: (num_steps, batch_size, num_hiddens)
↓ reshape 成 (-1, num_hiddens)
Y_flat: (num_steps * batch_size , num_hiddens)
↓ Linear 层
output: (num_steps * batch_size, vocab_size)
例子:(重要)
假设:
-
batch_size = 2(同时处理两个句子) -
num_steps = 3(每个句子只看前 3 个字符) -
vocab_size = 4(只有 4 种字符:a,b,c,d)
原始输入 inputs(形状 2×3):
句子1: 0, 1, 2 (a, b, c)
句子2: 1, 2, 3 (b, c, d)
转置后(3×2):
时间步0: 0, 1
时间步1: 1, 2
时间步2: 2, 3
one-hot 后(3×2×4):
时间步0: \[1,0,0,0, 0,1,0,0] # 句子1的第一个字是a,句子2的第一个字是b
时间步1: \[0,1,0,0, 0,0,1,0]
时间步2: \[0,0,1,0, 0,0,0,1]
经过 RNN 后,Y形状 (3,2,num_hiddens)(假设num_hiddens=5)。 激活过程在rnn_layer中实现了,用的tanh函数激活
reshape 成 (-1,5)→ 形状 (6,5)。这 6 行对应:
先取完所有批次(句子)的第 0 个时间步 -> 再取所有批次的第 1 个时间步 -> ...
所以,(6, 5)的这 6 行具体对应关系是:
-
第 0 行 :时间步 0,句子 1 (原
Y[0, 0]) -
第 1 行 :时间步 0,句子 2 (原
Y[0, 1]) -
第 2 行 :时间步 1,句子 1 (原
Y[1, 0]) -
第 3 行 :时间步 1,句子 2 (原
Y[1, 1]) -
第 4 行 :时间步 2,句子 1 (原
Y[2, 0]) -
第 5 行 :时间步 2,句子 2 (原
Y[2, 1])
线性层(5(因为之前形状是(6,5)→4)后,output形状 (6,4)。
5(输入维度 in_features):
-
这是 RNN 层输出的隐藏状态大小(
num_hiddens)。 -
意思是:模型内部在当前这一步,提取出了 5个特征 来描述当前的语境。
4(输出维度 out_features):
-
这是你想要预测的目标词汇表大小(
vocab_size)。 -
意思是:我们要把这 5 个抽象特征,翻译成给 4个具体字符 打分。
-
对应图中
output形状(6, 4)中的 4。
比如 output[0]就是模型根据句子1的前1个字符(a)预测的下一个字符的分数(对应 b,c,d,a 的可能性)。output 含义:把时间和批量合并成一个维度,每一行代表一个具体位置(哪个句子的哪个时间步)的预测结果,方便一次性计算损失和梯度。

代码细节:
super(RNNModel, self).init(**kwargs)这句怎么解读
- 为什么需要调用父类的
__init__?
RNNModel****继承自 nn.Module,而 nn.Module本身有自己的初始化方法,用于:
-
管理模型的参数(
parameters()) -
注册子模块(比如
self.rnn、self.linear) -
支持
model.to(device)、model.train()、model.eval()等功能
如果不调用 父类的 __init__,这些基础功能就会缺失,模型就无法正常使用。
super(RNNModel, self).__init__(**kwargs)的具体含义
-
super(RNNModel, self):找到RNNModel的父类(即nn.Module),并返回一个代理对象。 -
.__init__(**kwargs):调用父类的__init__方法,并将**kwargs中的所有关键字参数传递给父类。
**kwargs的作用:
RNNModel的 __init__签名是 def __init__(self, rnn_layer, vocab_size, **kwargs),其中 **kwargs收集了所有额外的关键字参数(比如 device='cuda'、dtype=torch.float32等)。将这些参数传给父类,可以让父类处理一些通用的配置。
1️⃣ nn.Linear(in_features, out_features)的两个参数
nn.Linear是 PyTorch 中的全连接层(也叫线性层),它做的事情就是:
output=input×WT+b
其中:
-
in_features:输入特征的数量(每个样本有多少个数字)。 -
out_features:输出特征的数量(希望输出的每个样本有多少个数字)。 -
W是形状为(out_features, in_features)的权重矩阵,b是偏置向量。
在代码中:
-
self.num_hiddens(比如 256)是 RNN 每个时间步输出的隐藏状态维度,也就是线性层的输入特征数。 -
self.vocab_size(比如 10000)是词汇表的大小,我们希望把 RNN 的输出映射到词汇表上,得到每个字符的"分数",所以输出特征数等于词汇表大小。
所以 nn.Linear(256, 10000)就代表:把一个 256 维的向量变成 10000 维的向量。
2️⃣ 为什么需要这个线性层?
RNN 的输出 Y的形状是 (num_steps, batch_size, num_hiddens),也就是说每个时间步、每个样本都有一个 256 维的向量。但这个向量还不是最终的预测结果------我们需要知道下一个字符是什么(从 10000 个候选字符里选一个)。
所以线性层的作用就是将 256 维的隐藏状态"翻译"成 10000 维的分数向量(logits),之后可以用 softmax 转换成概率,选择概率最高的字符作为预测。
3️⃣ 为什么要先 reshape 再送入 linear?
Y.reshape((-1, Y.shape[-1]))-
Y.shape是(num_steps, batch_size, num_hiddens)。 -
Y.shape[-1]就是num_hiddens(最后那个维度)。 -
reshape((-1, num_hiddens))会把前两个维度(num_steps和batch_size)合并成一个维度,结果形状变为(num_steps * batch_size, num_hiddens)。
为什么这么做?
因为 nn.Linear期望输入的形状是 (任意批量大小, in_features)。这里我们把所有时间步和所有样本拼在一起当成一个大的"批量",一次性完成所有映射,效率更高。
之后得到的 output形状就是 (num_steps * batch_size, vocab_size),每个"样本"对应原来某个时间步的某个样本的预测分数
one-hot作用:
X = F.one_hot(inputs.T.long(), self.vocab_size)
inputs的原始形状是 (batch_size, num_steps),即每行是一个样本序列,每列是一个时间步。
.T做了转置,变成 (num_steps, batch_size),即每行是一个时间步,每列是一个样本。
然后 F.one_hot会对每个元素(每个字符索引)转换为一个长度为 vocab_size的 one-hot 向量。
所以最终形状变成了 (num_steps, batch_size, vocab_size)。
为什么特意要转置?
因为 PyTorch 的 nn.RNN默认要求输入的第一维是时间步,第二维是批量大小。如果不转置,直接对 (batch_size, num_steps)做 one-hot 会得到 (batch_size, num_steps, vocab_size),不符合 RNN 的要求。所以代码先转置,让时间步在最前面。
output 形状 (num_steps * batch_size, vocab_size)是什么意思?
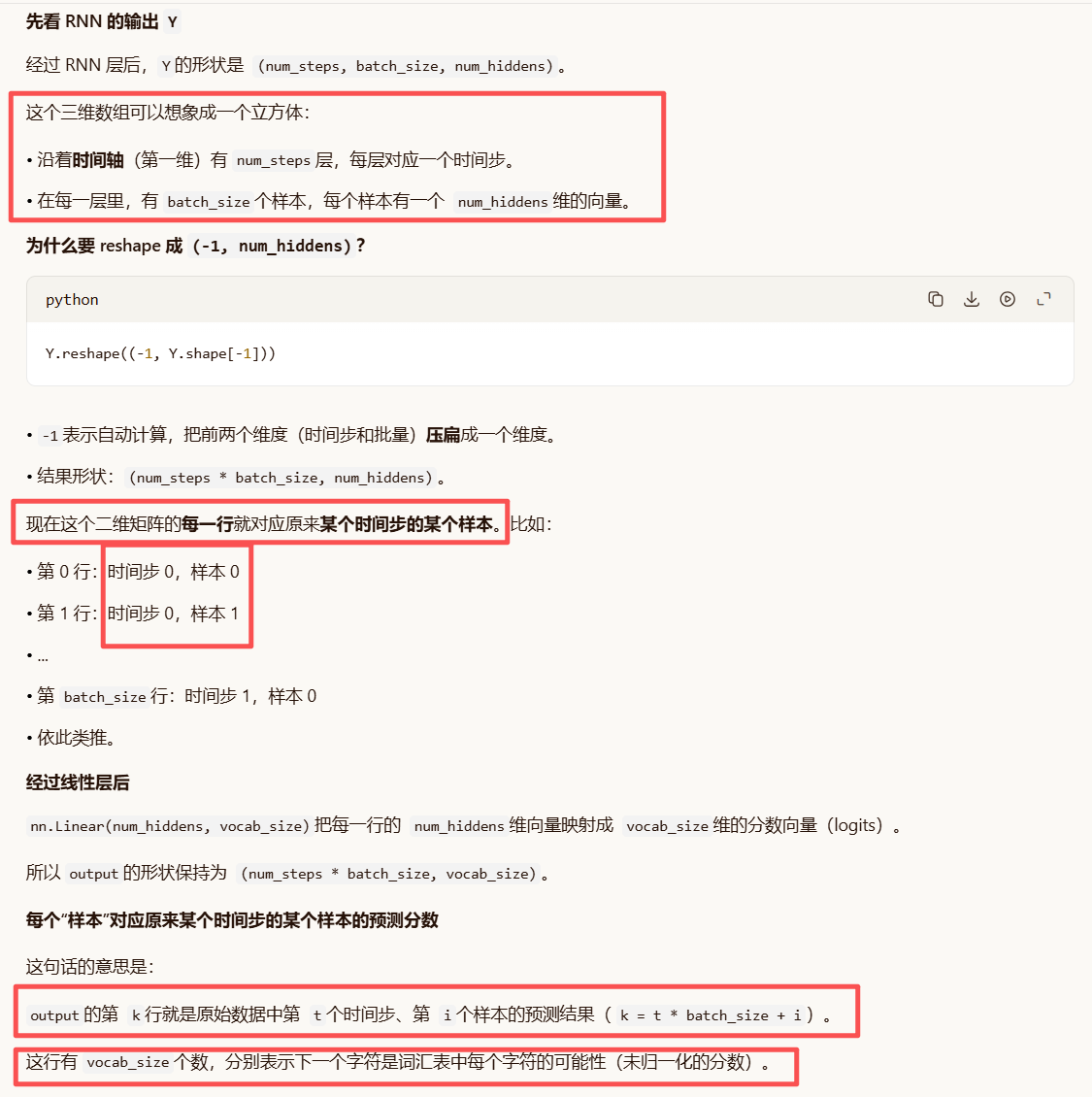
代码和最开始的公式对应关系
