
「【新智元导读】为了争夺有限的 GPU,OpenAI 内部一度打得不可开交。2024 年总算力投入 70 亿美元,但算力需求依旧是无底洞。恰恰,微软发布了全球首台 GB300 超算,专供 OpenAI 让万亿 LLM 数天训完。」
一图看透全球大模型!新智元十周年钜献,2025 ASI 前沿趋势报告 37 页首发
过去一年,OpenAI 在算力上斥资 70 亿美元。
其中,大模型研发占了最大头------50 亿美元,而推理计算仅用了 20 亿美元。
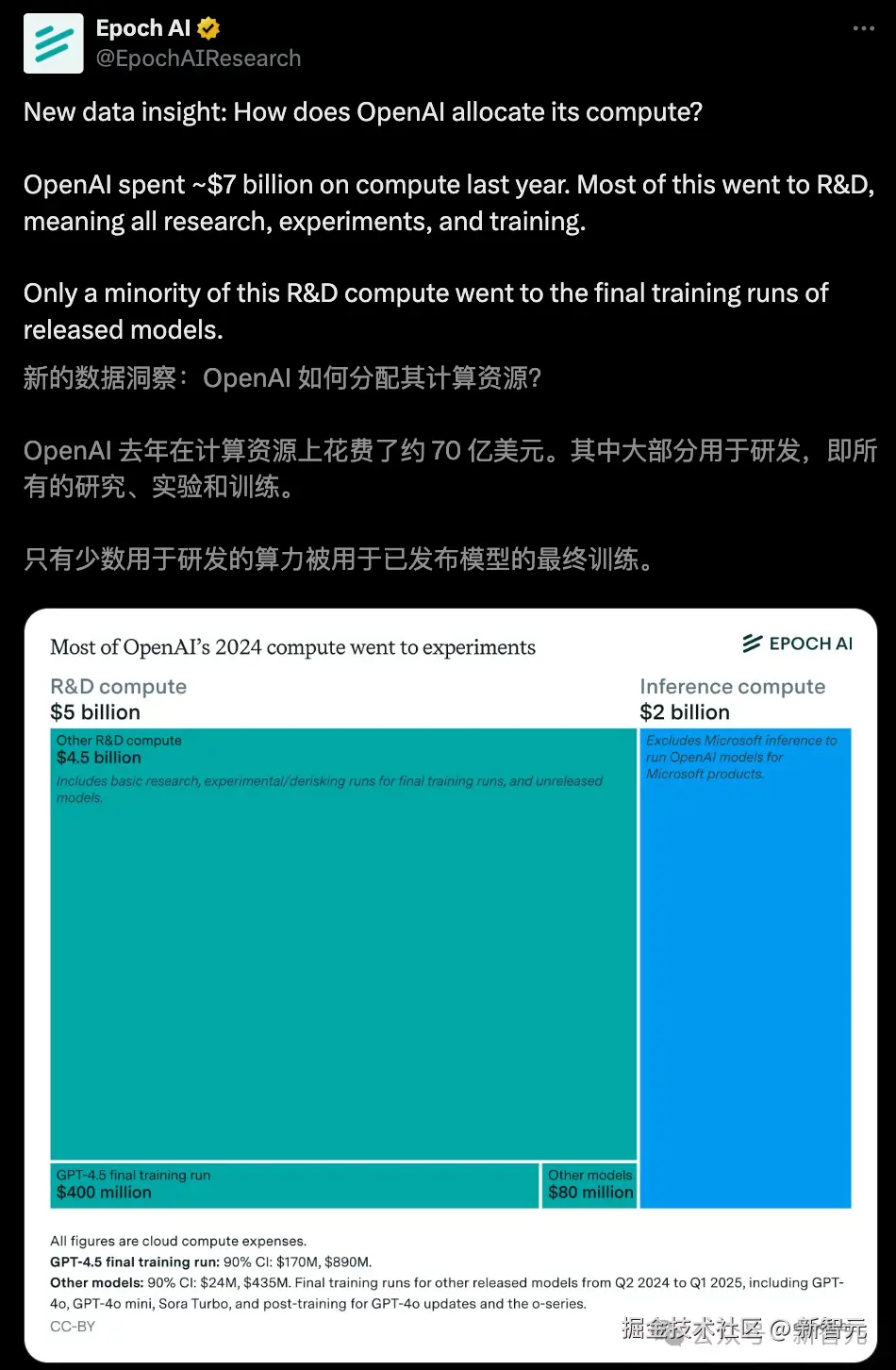
可见,LLM 训练正吞噬无尽的算力,这也是 OpenAI 最近一直在大举扩展超算建设与合作的重要原因。
采访中,OpenAI 总裁 Greg Brockman 坦言,「内部如何分配 GPU,简直就是一场痛苦与煎熬」。
OpenAI 各个团队争抢 GPU,那叫一个激烈。最头疼的是,如何去合理分配。

如今,甲骨文、英伟达、AMD 等芯片巨头 / 云服务巨头,纷纷与 OpenAI 联结,能够解其燃眉之急。
这不,就连曾经最大的「金主爸爸」微软也上阵了。
纳德拉官宣,全球首个配备 4600+ GB300 的超算率先上线,专攻 OpenAI。预计,未来将扩展到十万块 GPU。

英伟达称,这一算力巨兽,可以让 OpenAI 不用数周,仅在数天内训练万亿参数模型。


「全球首台 GB300 超算」
「数天训出万亿 LLM」
就在昨天,微软 Azure 宣布成功交付了,全球首个生产级超大规模 AI 集群。
它搭载了超 4600 个 GB300 NVL72,配备通过下一代 InfiniBand 网络互联的 Blackwell Ultra GPU。

今年早些时候,微软曾推出 GB200 v6 虚拟机(VM),通过大规模 GB200 NVL2 集群,已在 OpenAI 内部训练部署得到应用。
这一次,GB300 v6 虚拟机再次树立了行业标杆。
该系统基于机架级设计,每个机架包含 18 个虚拟机,共计 72 个 GPU:
- 72 个 Blackwell Ultra GPU,搭配 36 个 Grace CPU
- 通过下一代 Quantum-X800 InfiniBand,实现每 GPU 800 Gb/s 的跨机架横向扩展带宽(2x GB200 NVL72)
- 机架内 130 TB/s 的 NVLink 带宽
- 37TB 高速内存
- 高达 1,440 PFLOPS 的 FP4 Tensor Core 性能

「 」
」
「全新设计,为大规模 AI 超算而生」
为打造出最强超算,微软对计算、内存、网络、数据中心、散热和供电等技术栈的每一层,都进行了重新设计。
「机架层:低延迟高吞吐」
通过 NVLink 和 NVSwitch,GB300 v6 在机架层面实现了高达 130TB/s 的机架内数据传输速率,连接了总计 37TB 的高速内存,由此消除了内存和带宽瓶颈。
在大模型和长上下文场景下,推理吞吐量大幅提升,为 AI 智能体和多模态 AI 带来前所未有的响应速度和扩展性。
同时,Azure 部署了采用当今最快网络 fabric------Quantum-X800 Gbp/s InfiniBand------的全连接胖树(fat-tree)无阻塞架构,能够跨机架扩展数万个 GPU。
此外,Azure 散热系统采用独立的「散热器单元」和「设施级冷却方案」。
在为 GB300 NVL72 这类高密度、高性能集群保持热稳定性的同时,最大限度地减少了水资源消耗。
「软件层:全面优化」
不仅如此,微软为存储、编排和调度重构的软件栈也经过全面优化,能够在超算规模上充分利用计算、网络、存储和数据中心基础设施,提供前所未有的高性能和高效率。

「OpenAI GPU 争夺战」
「一场「痛苦与煎熬」」
在 OpenAI 内部,正上演一场 GPU 激烈争夺战。

上周四,Greg 在一期「Matthew Berman」播客节目中,自曝管理算力资源分配的过程,令人揪心且筋疲力尽。
这太难了,你总能看到各种绝妙的点子,然后又有人带着另一个绝妙的点子来找你,你心想,这个也太棒了。
在 OpenAI 内部,将算力资源主要分配给「研究」和「应用产品」两个方向。

为了应对算力分配的挑战,OpenAI 建立了一套相对清晰的资源分配机制:
- 高层决策:由奥特曼和 Fidji Simo 组成的领导团队,决定研究团队与应用团队之间的总体算力划分;
- 研究团队内部协调:首席科学家和研究负责人,决定研究团队资源分配;
- 运营层:由 Kevin Park 领导的小型内部团队负责 GPU 的具体分配和调动。
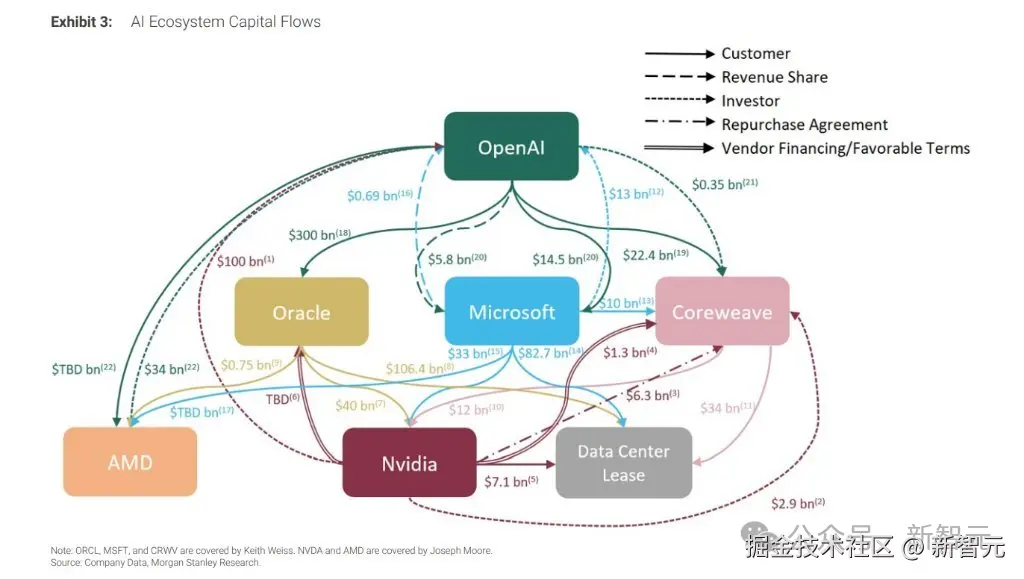
OpenAI 复杂算力关系网络图
Greg 提到,当一个项目接近尾声时,Kevin 会重新分配硬件资源,以支持新启动的项目。
算力驱动着整个团队的生产力,此事干系重大。
大家对此都非常在意。人们对「我能否分到算力」这件事所投入的精力与情感强度远超想象。
一直以来,OpenAI 多次公开表达其对算力永不满足的需求。
OpenAI 首席产品官 Kevin Weil 曾表示,「我们每次拿到新的 GPU,它们都会被立刻投入使用」。
OpenAI 对算力的需求逻辑很简单------
GPU 的数量直接决定了 AI 应用的能力上限。获得的 GPU 越多,所有人就能使用越多的 AI。
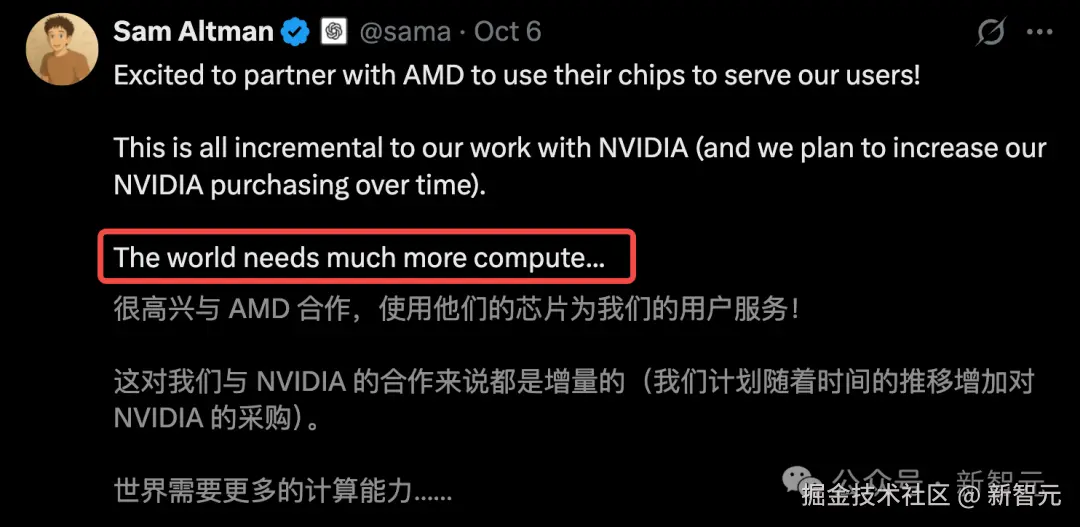
不仅 OpenAI,整个行业科技巨头也在加码算力投入。小扎透露,Meta 正将「人均算力」打造为核心竞争优势。

上个月,奥特曼称,OpenAI 正在推出「算力密集型服务」。
当我们以当前模型的成本,将海量算力投入到有趣的新想法上时,能创造出怎样的可能性?
这场算力争夺战中,谁手握最多的算力,将决定谁在 AI 竞赛中脱颖而出。
参考资料: