本镜像基于 ComfyUI 进行部署,已经下载了Wan2.2-Animate-14B动作模仿和人物替换模型,下面将带您快速了解本模型的基本使用:
1.基本操作
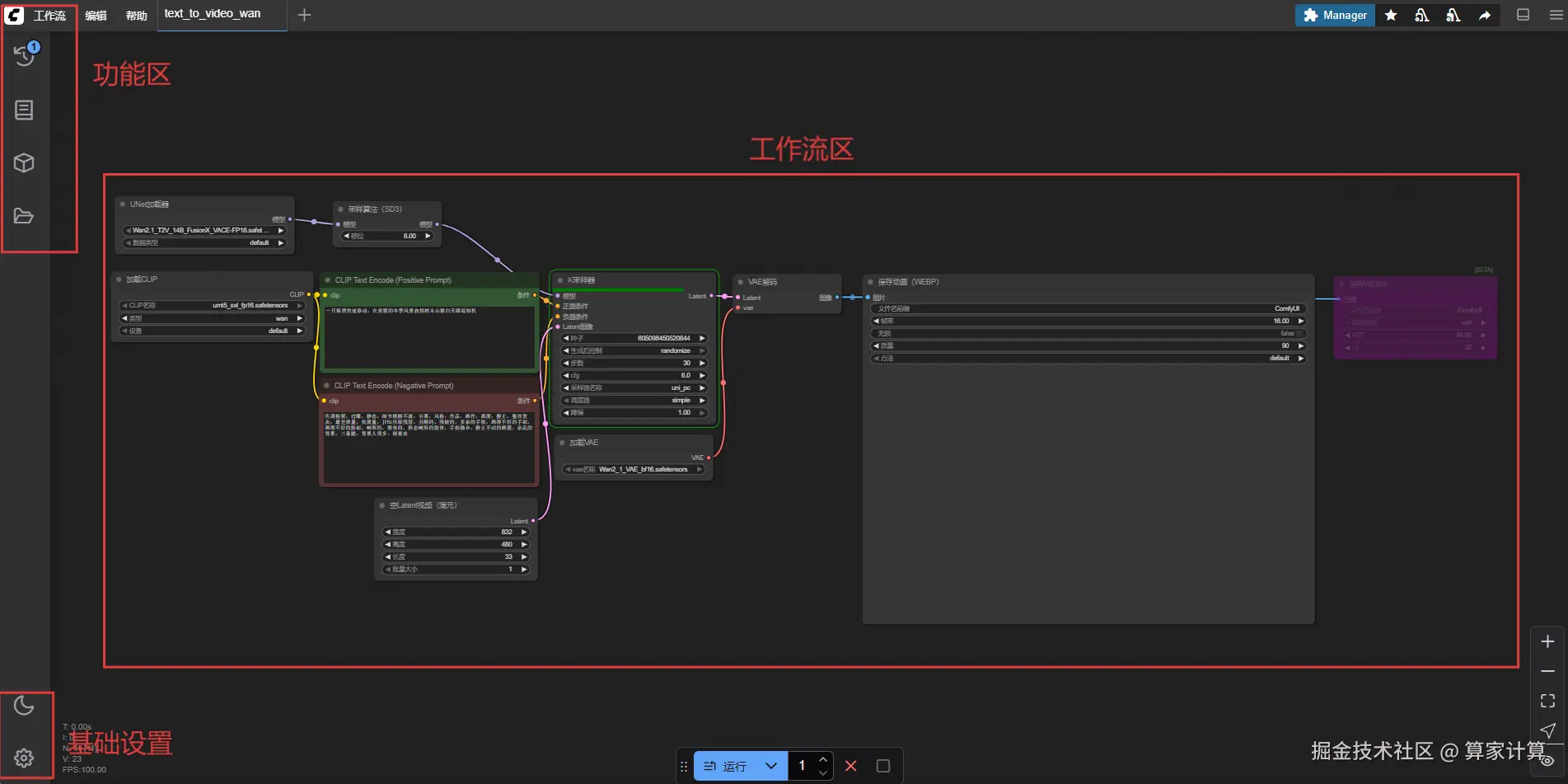
初识界面
刚进操作界面时如下:
快捷方式
2.快速上手
我们已经预设了一个工作流供您使用,您也可以选择案例中的其他工作流或者自己搭建,选择其他工作流可能会缺少模型,需要您自行下载。如果想深度使用还需自行探索,教程仅供初学者快速上手。由于模型本身的问题,生成的视频比原输入视频长或短1-2秒都是正常的
这里我们还提供了另一个官方的工作流,建议使用该工作流:复制全部内容,保存为json文件,导入ComfyUI即可
点击 docs.comfy.org/zh-CN/tutor...获取工作流
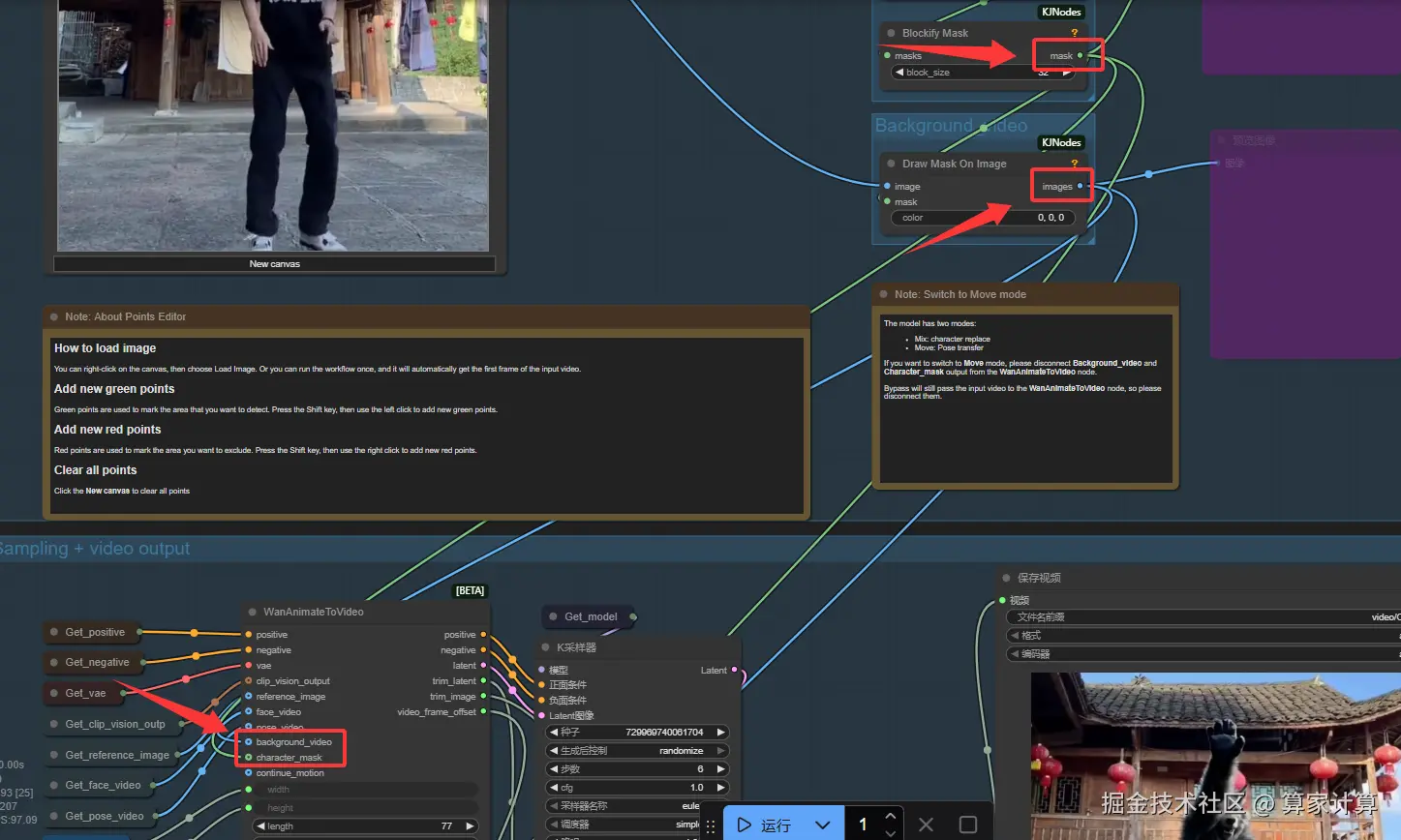
图片角色替换视频角色
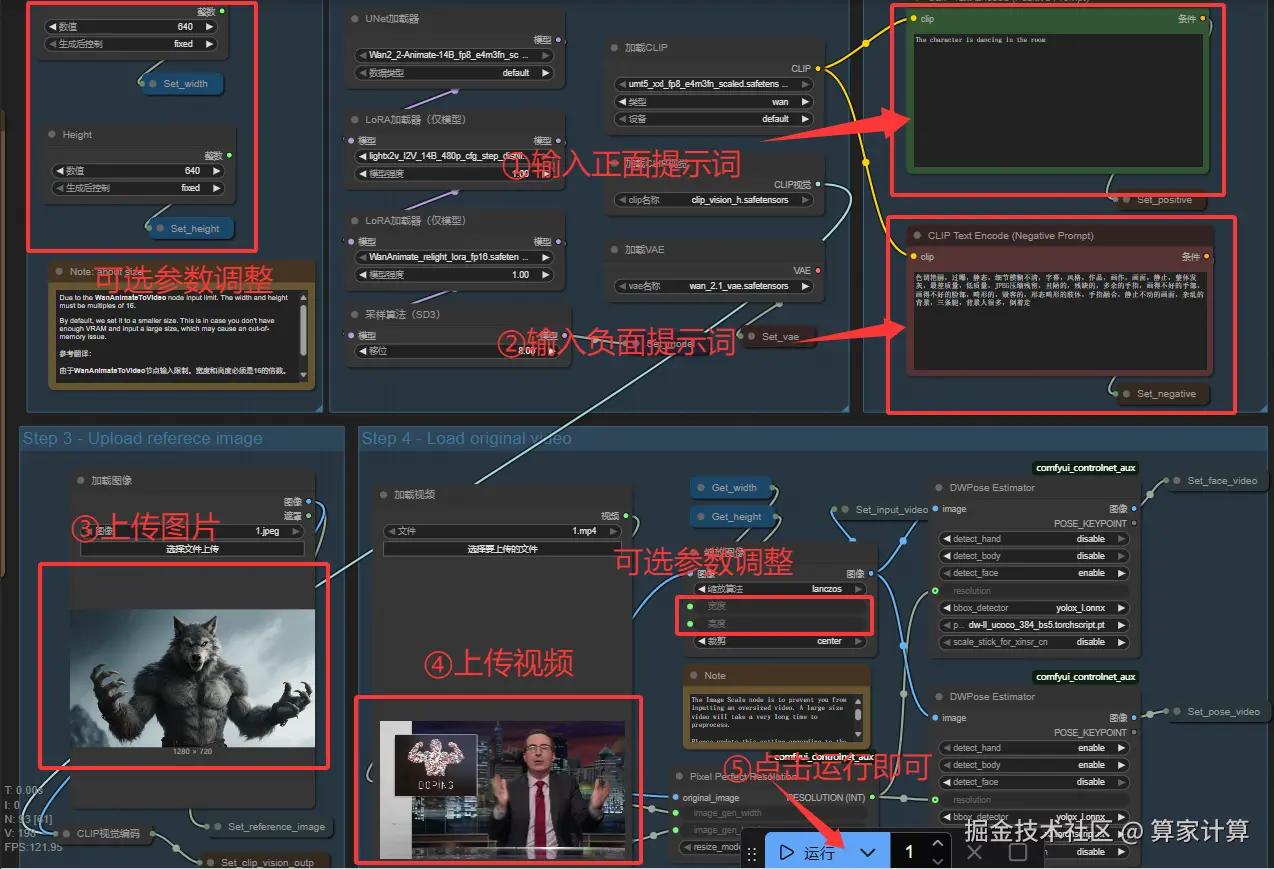
图片角色模仿视频角色动作
操作大致相同,但是需要断开如图两个节点,同时提示词可以适当进行更改,比如提示词:图中角色模仿视频角色动作。(不保证奏效,根据生成情况调整)
长视频的生成
一般我们不建议输入视频的时长超过10秒。
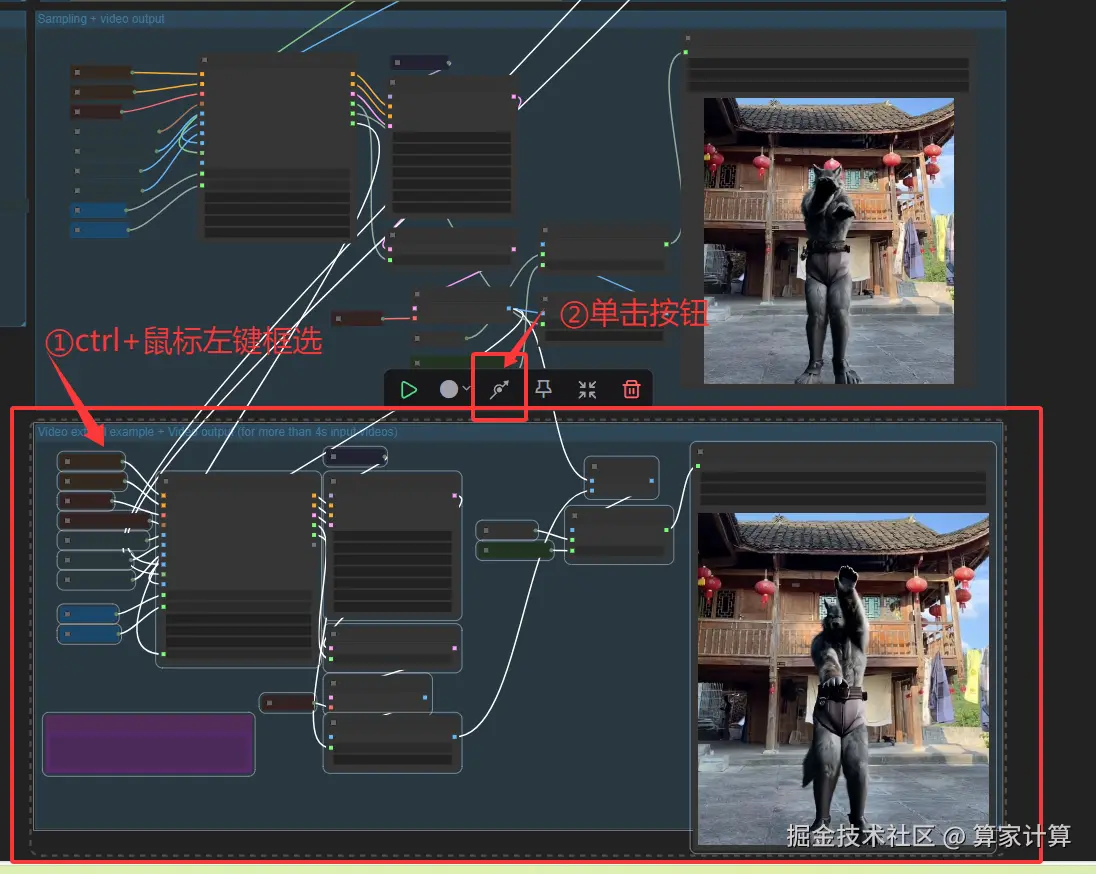
默认情况下生成的视频长度不会超过4秒,如果你希望生成更长的视频,可以进行如下图中的操作。如果希望更长那么就多复制粘贴几次节点,连接方式参考视频扩展示例即可。
ComfyUI界面是通用的,只要有工作流、模型、节点等即可使用。下面是下载其他基础模型的命令,如有其他模型需求,请在终端(小黑屏)处粘贴以下命令。缺少模型时您也可以选择直接在ComfyUI页面下载,或者复制链接,在终端下载完毕后重启ComfyUI。
基本命令:
shell
pip install modelscope #安装modelscope库
conda activate comfyenv #激活虚拟环境
modelscope download --model 您要下载的模型仓库链接 需要下载的模型名称 --loacl_dir 指定下载路径
#下载示例
conda activate comfyenv
cd /ComfyUI/models/diffusion_models
modelscope download QuantStack/Wan2.1_T2V_14B_FusionX_VACE Wan2.1_T2V_14B_FusionX_VACE-FP16.safetensors --local-dir ./
#不同模型下载位置不同,请根据仓库描述选择,以下列出了几个常见路径
#/ComfyUI/models/chechpoints/
#/ComfyUI/models/vae/
#/ComfyUI/models/loras/
#/ComfyUI/models/diffusion_models
#ComfyUI/models/text_encoders3.节点介绍
(1)基础节点介绍
Load chekpoint:基础大模型加载器,用于加载模型。
Load CLIP:作用是将输入的内容与生成式大模型结合,从而引导图片生成。
Load ControNet Model:用于加载 contronet 各功能的节点
KSampler:K 采样器。
VAE :变分自编码器,类似滤镜。现在很多模型都自带 VAE,VAE 分为 Decode(解码)和 Encode(编码)。其中 编码器将输入数据压缩成一个潜在向量,解码器则根据这个潜在向量重构原始输入。
(2)自定义节点介绍
Manager(管理器)提供了 对 ComfyUI 各种自定义节点的安装、删除、禁用、启用 等管理功能。同时还提供了中心功能和便利功能,用来访问 ComfyUI 中各种信息

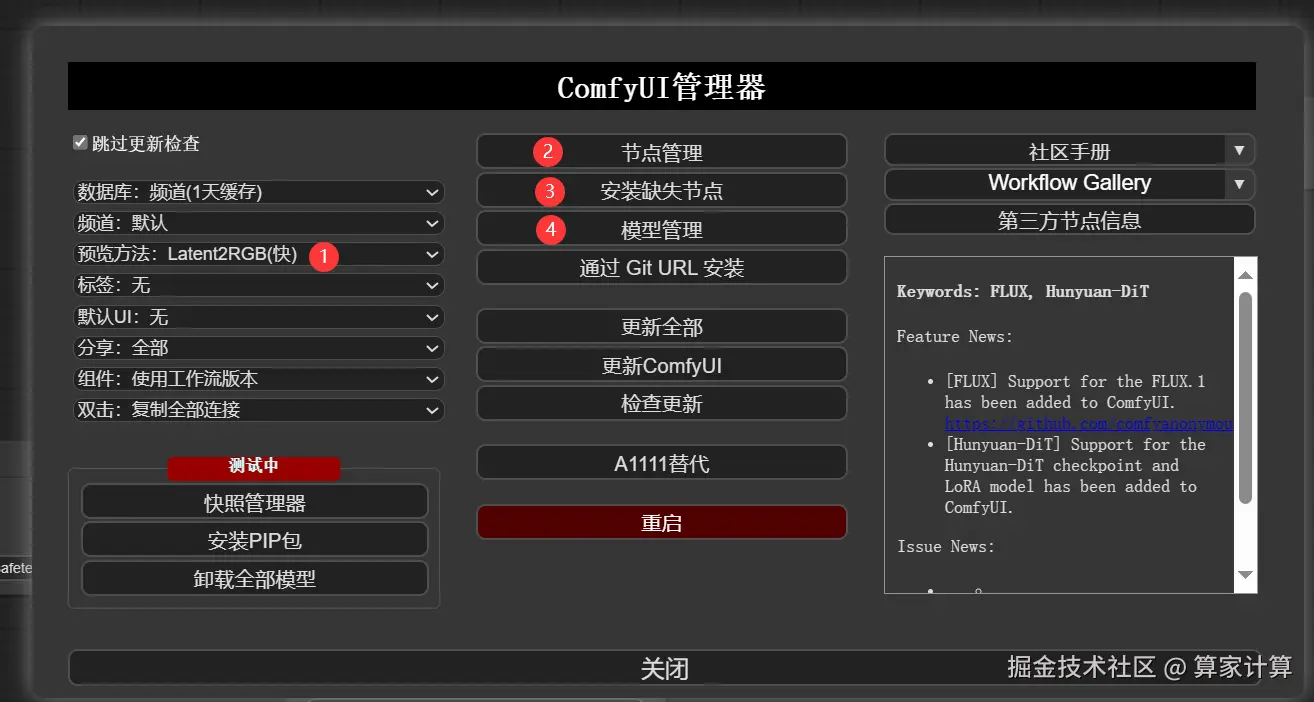
① 打开后能够实时预览图片生成过程
② 提供了一千多个拓展节点的下载,只需点击"install"即可安装(会通过 github 下载,安装失败就多试几次)
③ 导入别人的工作流时可能会缺失本分节点,管理器能检索出来,点击"install"快速安装
④ 提供许多模型
注:使用 Manager 安装某些节点后,该节点会从 hugging face 下载自己需要的模型,但是由于 hugging face 被墙,因此可到该节点下换
huggingface 的国内镜像(hf-mirror)重新下载。网址:hf-mirror.com
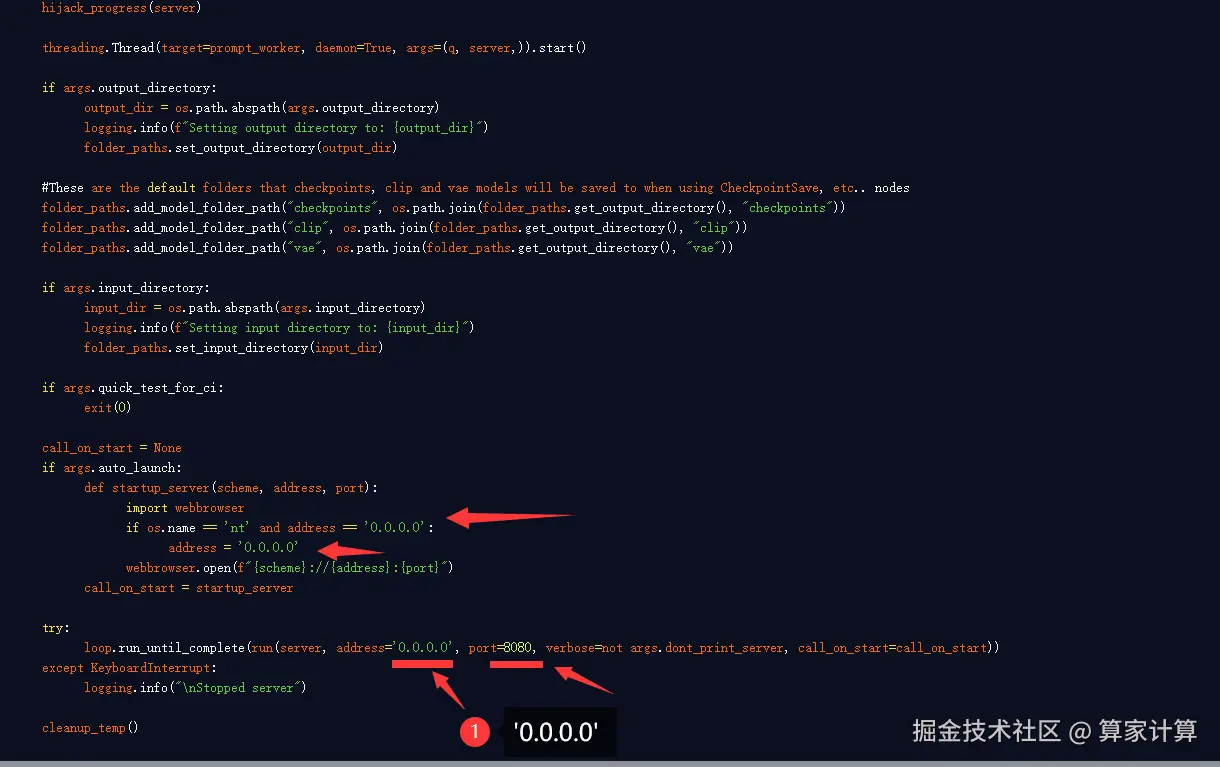
🚀️ 🚀️ 注意:使用 manager 更新 comfyui 之后如果需要通过外部访问,那么需修改/ComfyUI/main.py 中的 ip 和端口号,修改为如下图: