目录
- 深度学习核心网络模型梳理
- 神经网络核心组件
- 训练模型流程
-
-
- [1. 数据准备:](#1. 数据准备:)
- [2. 模型构建:打造一个"学习机器"](#2. 模型构建:打造一个“学习机器”)
- [3. 训练过程:学生开始学习](#3. 训练过程:学生开始学习)
- [4. 验证过程:定期进行模拟考试](#4. 验证过程:定期进行模拟考试)
- [5. 记录最优权重:保存学生的"巅峰状态"](#5. 记录最优权重:保存学生的“巅峰状态”)
- [6. 调参:根据考试结果调整学习方法](#6. 调参:根据考试结果调整学习方法)
-
深度学习核心网络模型梳理
简述
1)基础网络模型
- 多层感知机(MLP):全连接层堆叠,无空间结构保留
- 卷积神经网络(CNN):含卷积层+池化层,主打图像/空间数据
- 经典子型:LeNet、AlexNet、VGG、GoogLeNet、ResNet
- 循环神经网络(RNN):含循环层,主打序列数据
- 经典子型:LSTM、GRU
- Transformer:基于自注意力机制,适配序列/图像/多模态数据
- 经典子型:BERT、GPT、Vision Transformer(ViT)
2)模型核心设置(组件选择)
- 网络层:卷积层、全连接层、循环层、注意力层、池化层
- 激活函数:ReLU、Sigmoid、Tanh、GELU
- 优化器:SGD、Adam、RMSProp、AdamW
- 损失函数:交叉熵损失、MSE、MAE、Triplet Loss
- 正则化:Dropout、L1/L2正则、BatchNorm、LayerNorm
- 数据处理:归一化、增强、填充、截断、分词(NLP)、tokenize(多模态)
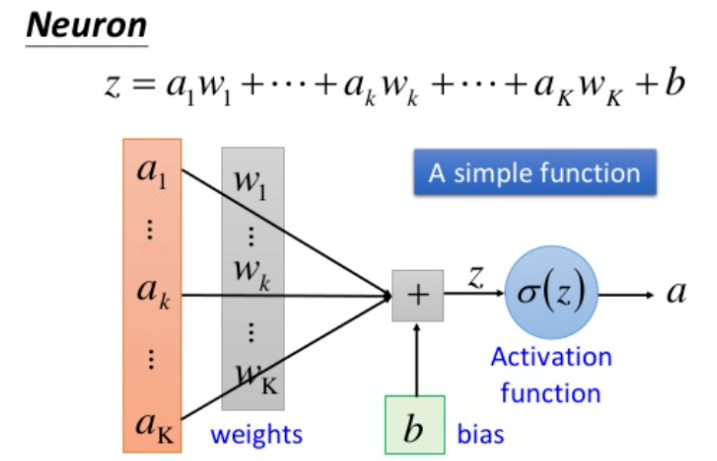
一、单个神经元
1)结构
- 输入:接收外部信号,用向量 ( x = x_1, x_2, ..., x_n ) 表示,每个输入对应一个权重。
- 权重与偏置 :
- 权重 w = w 1 , w 2 , . . . , w n w=w_1,w_2,...,w_n w=w1,w2,...,wn:衡量各输入的重要性(正数增强信号,负数抑制信号);
- 偏置 b b b:调整神经元的激活阈值,控制神经元响应灵敏度。
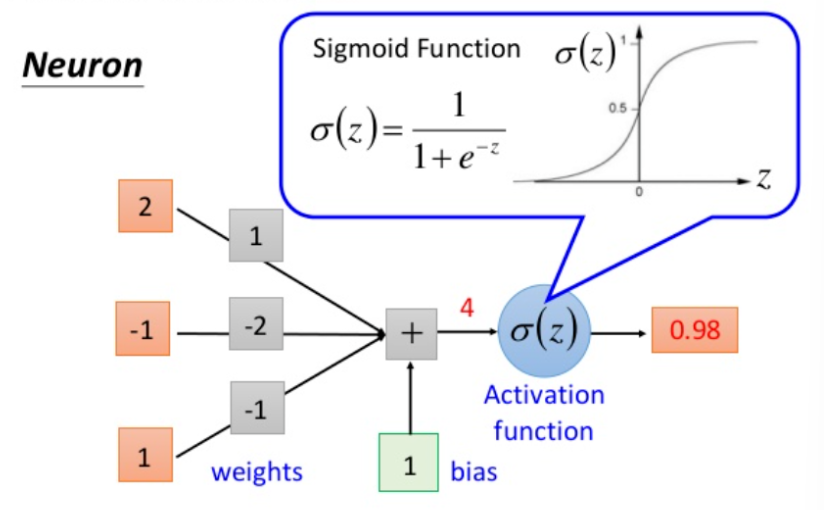
- 激活函数 :对加权和 z = ∑ ( w i x i ) + b z = \sum(w_i x_i) + b z=∑(wixi)+b做非线性转换,输出最终信号 ( a = f(z) )(如ReLU、Sigmoid)。
2)意义
- 基础计算单元:通过"加权求和+非线性转换",学习输入数据的简单特征(如边缘、关键词)。
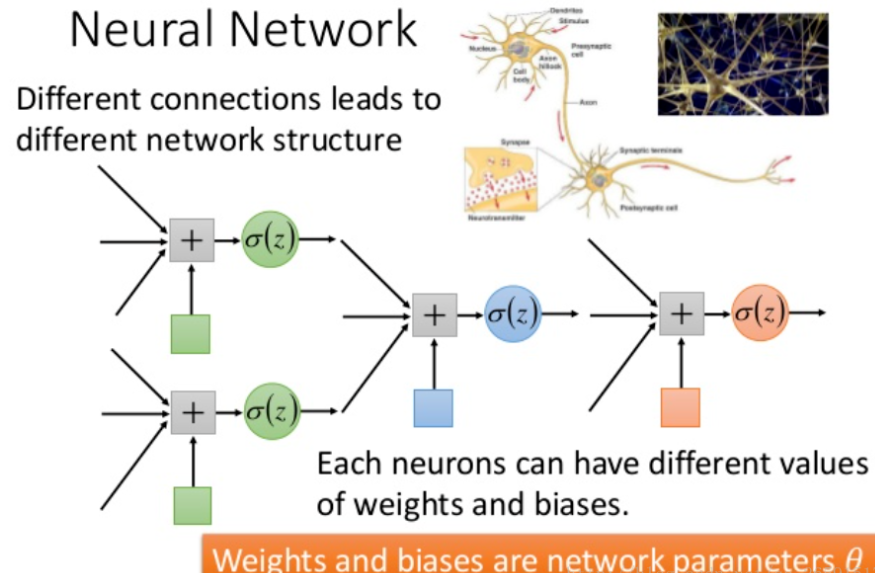
- 网络基石:单个神经元的能力有限(仅能拟合简单非线性关系),但当大量神经元按层堆叠(形成多层网络)后,可组合低阶特征形成高阶抽象特征(如"图像类别""文本语义"),为神经网络处理复杂任务提供基础。
下图转载自深度学习(3)之经典神经网络模型整理:神经网络、CNN、RNN、LSTM,对相关含义展示的比较清晰,供参考。
二、基础网络模型
1. 多层感知机(MLP)
- 核心特征:全连接层堆叠,输入为扁平化向量,不保留空间或序列结构。
- 经典子型:
- 自编码器(Autoencoder):编码器-解码器结构,用于无监督特征学习(降维、去噪)。
- 变分自编码器(VAE):引入概率分布假设的生成模型,可生成新样本。
- GAN基础结构:生成器与判别器均为MLP架构,通过对抗训练实现生成式任务。
2. 卷积神经网络(CNN)
-
核心特征:含卷积层(提取局部特征)和池化层(降维),专为图像/空间数据设计。
-
经典子型 :
模型 核心创新点 应用场景 LeNet 首次确立"卷积+池化+全连接"框架 手写数字识别 AlexNet 引入ReLU、Dropout,支持GPU并行 大规模图像分类 VGG 3×3卷积核堆叠,通过深度提升性能 图像特征提取 GoogLeNet Inception模块,多尺度特征并行提取 高效特征学习 ResNet 残差连接解决深层网络梯度消失问题 超深网络训练(如152层) DenseNet 密集连接强化特征复用,减少参数 轻量化场景 MobileNet 深度可分离卷积,适合移动端 移动端图像任务
3. 循环神经网络(RNN)
- 核心特征:含循环层,可处理序列数据(如文本、语音),保留时序依赖。
- 经典子型 :
- LSTM/GRU:解决长序列梯度消失问题,适合长文本、语音建模。
- 双向RNN(Bi-RNN):同时利用前向和后向序列信息,提升语义理解。
- Seq2Seq:编码器-解码器架构,用于机器翻译、文本摘要等序列转换任务。
4. Transformer
-
核心特征:基于自注意力机制,并行处理序列,突破RNN的时序依赖限制。
-
经典子型 :
模型 核心创新点 应用场景 BERT 双向Transformer预训练,适配NLP任务 文本分类、问答 GPT 自回归生成式Transformer,擅长续写 文本生成 ViT 将图像分割为"patch",用Transformer处理 图像分类 Swin Transformer 滑动窗口注意力,适配高分辨率图像 目标检测、语义分割 T5 统一NLP任务为"文本到文本"格式 通用NLP任务
三、扩展网络模型
1. 跨模态与融合模型
- 核心逻辑:处理文本、图像、语音等多类型数据的交互与融合。
- 代表模型 :
- CLIP:联合训练文本和图像编码器,实现跨模态检索。
- ViLBERT:双流Transformer分别处理图像和文本,通过跨模态注意力融合。
- Whisper:基于Transformer的多语言语音识别模型。
2. 图神经网络(GNN)
- 核心逻辑:处理图结构数据(如社交网络、分子结构),通过节点与邻接关系学习特征。
- 代表模型 :
- GCN:将卷积推广到图结构,通过邻接矩阵聚合节点特征。
- GAT:用注意力机制动态调整邻接节点权重,提升灵活性。
- 图Transformer:结合自注意力机制,突破GCN的固定邻接依赖。
3. 强化学习相关网络
- 核心逻辑:用于决策任务,通过与环境交互学习最优策略。
- 代表模型 :
- DQN:结合CNN与Q-learning,用于离散动作空间(如游戏AI)。
- Policy Gradient:直接优化策略函数,适合连续动作空间(如机器人控制)。
- Actor-Critic:结合策略网络(Actor)和价值网络(Critic),平衡探索与利用。
神经网络核心组件
一、网络层(基础构建模块)
-
核心层
- 卷积层 :通过滑动卷积核提取局部特征(如CNN中的
Conv2d/Conv3d,适用于图像/视频)。 - 全连接层 :输入输出全维度连接(
Linear),用于特征映射到输出空间(如分类结果)。 - 循环层 :处理序列数据(
RNN/LSTM/GRU),保留时序依赖。 - 注意力层:动态分配权重到输入序列(如自注意力、交叉注意力),适配Transformer。
- 池化层 :降低特征维度(
MaxPooling/AvgPooling),增强鲁棒性。
- 卷积层 :通过滑动卷积核提取局部特征(如CNN中的
-
扩展层
- 归一化层 :稳定训练(
BatchNorm/LayerNorm/InstanceNorm,分场景适配批量/层/单样本归一化)。 - dropout层 :随机失活神经元(
Dropout/DropPath,防止过拟合)。 - 嵌入层 :将离散值映射为低维向量(
Embedding,适用于NLP的词向量、推荐系统的ID映射)。 - 图卷积层 :处理图结构数据(
GCNConv/GATConv,聚合节点与邻接特征)。 - 转置卷积层 :上采样特征(
ConvTranspose2d,用于图像生成、语义分割的分辨率恢复)。
- 归一化层 :稳定训练(
二、激活函数(引入非线性能力)
-
核心函数
- ReLU : f ( x ) = max ( 0 , x ) f(x) = \max(0, x) f(x)=max(0,x),解决梯度消失,计算高效(应用最广)。
- Sigmoid : f ( x ) = 1 / ( 1 + e − x ) f(x) = 1/(1+e^{-x}) f(x)=1/(1+e−x),输出映射到(0,1),适用于二分类概率输出。
- Tanh : f ( x ) = ( e x − e − x ) / ( e x + e − x ) f(x) = (e^x - e^{-x})/(e^x + e^{-x}) f(x)=(ex−e−x)/(ex+e−x),输出映射到(-1,1),比Sigmoid对称。
- GELU : f ( x ) = x ⋅ Φ ( x ) f(x) = x \cdot \Phi(x) f(x)=x⋅Φ(x)(高斯误差线性单元),平滑非线性,适配Transformer。
-
扩展函数
- LeakyReLU : f ( x ) = max ( 0.01 x , x ) f(x) = \max(0.01x, x) f(x)=max(0.01x,x),解决ReLU的"死亡神经元"问题。
- Swish : f ( x ) = x ⋅ Sigmoid ( β x ) f(x) = x \cdot \text{Sigmoid}(\beta x) f(x)=x⋅Sigmoid(βx),自门控机制,在深层网络表现优异。
- Softmax : f ( x i ) = e x i / ∑ e x j f(x_i) = e^{x_i}/\sum e^{x_j} f(xi)=exi/∑exj,将输出归一化为概率分布,适用于多分类。
三、优化器(参数更新策略)
-
核心优化器
- SGD :随机梯度下降,基础优化器,可加动量(
momentum)加速收敛。 - Adam :结合动量和自适应学习率(
beta1/beta2控制动量和二阶矩),适用于多数场景。 - RMSProp:自适应调整学习率(衰减平方梯度),缓解Adam的震荡问题。
- AdamW:Adam+权重衰减,更稳定的正则化效果。
- SGD :随机梯度下降,基础优化器,可加动量(
-
扩展优化器
- Adagrad:为稀疏特征分配更大学习率,适用于文本等稀疏数据。
- Nadam:Adam+Nesterov动量,收敛更快。
- LAMB:适配大batch训练,支持自适应学习率缩放。
四、损失函数(衡量预测与真实值差异)
-
核心损失
- 交叉熵损失 :适用于分类任务(
CrossEntropyLoss,含Softmax+负对数似然)。 - MSE(均方误差) : Loss = ∑ ( y − y ^ ) 2 \text{Loss} = \sum (y-\hat{y})^2 Loss=∑(y−y^)2,适用于回归任务。
- MAE(平均绝对误差) : Loss = ∑ ∣ y − y ^ ∣ \text{Loss} = \sum |y-\hat{y}| Loss=∑∣y−y^∣,抗 outliers 能力强于MSE。
- Triplet Loss:通过"锚点-正例-负例"三元组优化,拉近同类、拉远异类(适用于人脸识别、embedding学习)。
- 交叉熵损失 :适用于分类任务(
-
扩展损失
- Huber Loss:MSE与MAE结合(小误差用MSE,大误差用MAE),平衡鲁棒性和梯度稳定性。
- Dice Loss:基于交并比(IoU),适用于样本不平衡任务(如医学图像分割)。
- KL散度:衡量两个概率分布的差异(适用于生成模型,如VAE的正则项)。
- CTC Loss:处理不定长序列对齐(如语音识别、OCR的输入输出长度不匹配问题)。
五、正则化(防止过拟合)
-
核心方法
- Dropout:训练时随机失活部分神经元,降低网络依赖。
- L1/L2正则:损失中加入权重绝对值(L1)或平方(L2)惩罚,限制权重大小。
- BatchNorm/LayerNorm:通过归一化稳定训练分布,间接增强泛化能力。
-
扩展方法
- 早停(Early Stopping):监控验证集性能,提前终止训练,避免过拟合。
- 数据增强:通过旋转、裁剪等生成多样样本(本质是扩大数据集,减少过拟合)。
- 权重衰减(Weight Decay):训练中按比例衰减权重(比L2正则更直接)。
- 知识蒸馏(Knowledge Distillation):用大模型指导小模型训练,提升泛化能力。
六、数据处理(输入预处理)
-
核心处理
- 归一化/标准化:将数据映射到固定范围(如0,1或均值0、方差1),加速收敛。
- 增强:图像(旋转、裁剪、加噪)、文本(同义词替换、回译)等,增加数据多样性。
- 填充/截断:统一序列长度(如文本padding到固定长度)。
- 分词/Tokenize :文本拆分为词/子词(如NLP的
word2vec、BPE;多模态的图像patch划分)。
-
扩展处理
- 特征选择:保留重要特征(如去除冗余维度,降低噪声)。
- 降维:用PCA、t-SNE等减少特征维度(适用于高维数据预处理)。
- 去噪:图像(高斯滤波)、语音(谱减法)等,提升输入数据质量。
- 格式转换:将原始数据转为模型可接收格式(如图像转Tensor、文本转ID序列)。
训练模型流程
1. 数据准备:
-
训练集 (Training Set):
- 类比 :学生的教材和课后作业。
- 作用:模型(学生)主要通过学习这部分数据来掌握知识(比如识别图像中的特征)。这是模型学习的主要依据。
-
验证集 (Validation Set):
- 类比 :模拟考试试卷。题目是学生没做过的,但题型和难度与教材(训练集)类似。
- 作用 :在训练过程中,定期用它来测试模型的学习效果。它的关键作用是防止学生"死记硬背"教材(即防止模型"过拟合")。如果学生考试分数高,但模拟考分数低,说明他可能只是背了答案,而没有真正理解。
-
测试集 (Test Set):
- 类比 :最终的高考。这是完全保密的,学生和老师都没见过。
- 作用 :当模型训练完成后,用它来进行最终的、公正的评估,衡量模型在真实世界中的泛化能力。注意:测试集只能在最后用一次,不能用来指导训练或调参。
2. 模型构建:打造一个"学习机器"
- 类比 :根据学生的情况(问题类型),制定一个学习方法或解题思路。
- 作用:这是你要训练的核心。对于图像识别,我们通常用CNN(卷积神经网络);对于自然语言处理,可能用RNN或Transformer。
- 怎么做:你不需要从零开始发明,可以使用PyTorch或TensorFlow等框架提供的"积木"(如卷积层、全连接层)来搭建一个适合你任务的模型结构。
3. 训练过程:学生开始学习
通常被称为训练循环 (Training Loop)。
- 喂数据:从训练集中拿出一批数据(比如128张图片),输入给模型。
- 模型预测:模型根据当前学到的"知识"(权重),对这128张图片进行预测。
- 计算误差 :通过损失函数 (Loss Function) 计算模型预测结果与真实标签(比如图片实际是数字"5")之间的差距。这个差距就是损失值 (Loss)。
- 反向传播与更新 :这是模型"学习"的关键一步。计算机会自动找出模型中哪些"权重"导致了错误,并根据优化器 (Optimizer) 的规则(比如梯度下降),微微调整这些权重,以期望下一次预测得更准。
- 重复 :不断重复步骤1-4,直到把训练集中的所有数据都学完一遍(这叫一个Epoch)。然后再从头开始,进行第二个、第三个... Epoch,直到模型收敛。
4. 验证过程:定期进行模拟考试
- 什么时候做 :通常在每个Epoch结束后,或者每训练一定步数后进行。
- 怎么做 :把验证集 的所有数据输入给模型,计算模型在验证集上的损失值 和准确率 (Accuracy) 等指标。
- 为什么重要 :
- 防止过拟合:如果模型在训练集上的准确率越来越高,但在验证集上的准确率反而开始下降,这说明模型开始"死记硬背"训练数据了(过拟合),对新数据的处理能力变差。
- 判断训练效果:验证集的指标是判断模型是否"学到位"的重要依据。
5. 记录最优权重:保存学生的"巅峰状态"
- 什么时候记录 :在每次验证后,如果发现模型在验证集上的某个关键指标(如准确率)达到了训练以来的最好成绩,就应该立刻保存此时模型的所有"权重"。
- 为什么要记录:训练过程是波动的,模型的状态并非一直变好。记录最优权重,可以确保在训练结束后,你手上有一个"巅峰状态"的模型,而不是最后一个可能已经开始过拟合或效果下降的模型。这就像在学生备考期间,我们拍下他状态最好的那一刻,作为最终参考。
6. 调参:根据考试结果调整学习方法
这是一个迭代优化的过程,也是区分新手和高手的关键。
- 什么时候调:当你发现训练和验证的效果不理想时。
- 调常见参数 :
- 学习率 (Learning Rate) :这是最重要的参数。
- 类比 :学生学习的步长。
- 调参策略:如果学习率太高,模型可能在最优解附近来回震荡,无法稳定;如果太低,模型学习速度会非常慢,需要训练极长的时间才能收敛。通常需要从小范围(如0.001)开始尝试。
- 模型结构 :
- 类比 :调整学习方法,比如从死记硬背改成理解记忆。
- 调参策略:如果模型太简单(比如层数太少),可能无法学到足够的知识(欠拟合),导致训练集和验证集准确率都很低。这时可以尝试增加网络层数或每层的神经元数量。反之,如果模型太复杂,就容易过拟合。
- 批大小 (Batch Size) :
- 类比 :学生每次学习的题量。
- 调参策略:批大小越大,训练越稳定,但对计算机内存/显存的要求越高。批大小越小,训练速度可能越快,但过程会有波动。
- 优化器 (Optimizer) :
- 类比 :不同的学习策略,如SGD(随机梯度下降)、Adam等。
- 调参策略:Adam通常是新手的首选,因为它收敛快且鲁棒性好。
- 学习率 (Learning Rate) :这是最重要的参数。