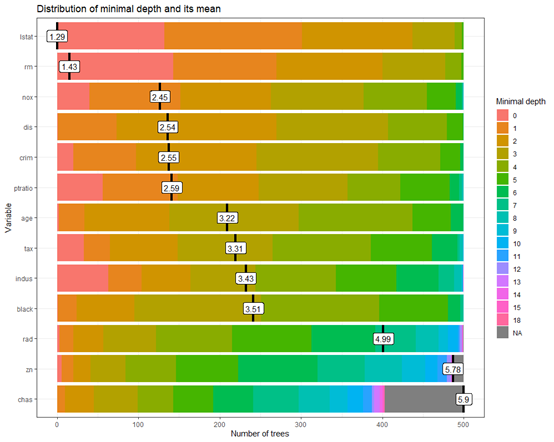
随机森林(Breiman 2001a)(RF)是一种非参数统计方法,需要没有关于响应的协变关系的分布假设。RF是一种强大的、非线性的技术,通过拟合一组树来稳定预测精度模型估计。
什么是shiny?Shiny是一个R包,可让您轻松地直接从 R 构建交互式 Web 应用程序(应用程序)。那随机森林和Shiny这两者有什么关系呢?
举个例子:比如你开发了一个很好的,预测能力很强的机器学习模型,随机森林或者其他模型。但是投稿后审稿人说,你的模型既然这么好,能力预测能力这么强,那么为什么不进一步开发个预测模型的软件或者页面?服务大众呢?因此shiny就可以上场了,它主要的功能是把你的模型生成交互式界面,可视化图形可以及时得到结果。
比如下面这篇文章就是开发了一个shiny的预测模型,估计就是根据编辑或审稿人的要求

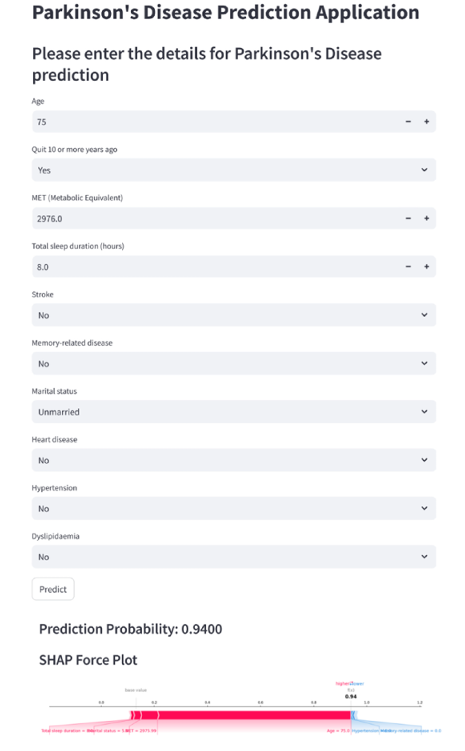
今天给大家介绍一下我自己编写的sciml包的shiny.randomForest函数,可以轻易生成随机森林模型的交互页面,再也不怕被审稿人刁难了,哈哈。
先导入R包和函数
r
library(sciml)
library(scitable)
bc<-read.csv("E:/r/test/demo.csv",sep=',',header=TRUE)
bc <- na.omit(bc)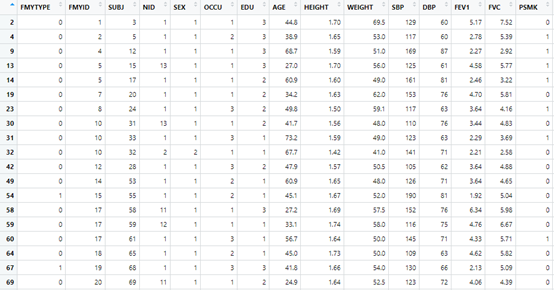
数据变量很多,我解释几个我等下要用的,HBP:是否发生高血压,结局指标,AGE:年龄,是我们的协变量,BMI肥胖指数,FEV1肺活量指标,WEIGHT体重,"SBP","DBP":收缩压和舒张压。公众号回复:体检数据,可以获得数据。
精简一下数据,方便演示,没有什么特殊意义
r
bc<-bc[,c("HBP","SEX","AGE","FEV1","OCCU","COUGH","EDU")]整理数据,主要是对数据检查,把分类变量转成因子,你手动转也是一样的
r
out2<-organizedata2(data = bc,username=username,token=token,explore = T)提取整理好的数据
r
data<-out2[["data"]]
allVars<-out2[["allVars"]]
fvars<-out2[["factorvarout"]]对数据3:7划分
r
set.seed(123)
tr1<- sample(nrow(data),0.7*nrow(data))##随机无放抽取
data_train <- data[tr1,]#70%数据集
data_test<- data[-tr1,]#30%数据集生成随机森林模型,我这里用scirandomForest函数,你用常规方法也是可以的
r
out<-scirandomForest(data=data_train,y="HBP",username=username,token=token,onlygetfit = T,username=username,token=token)
fit<-out[["fit"]]生成随机森林模型之前,这些步骤都是常规,生成森林随林后,生成随机森林预测模型交互式 Web 应用程序(应用程序)非常简单,就是一句话代码
r
shiny.randomForest(model=fit, data=data_train, app_title ="随机森林分类预测器")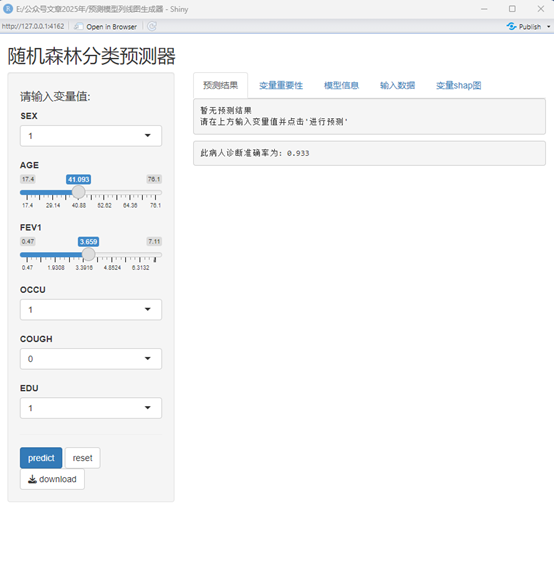
点击预测按钮就可以预测了,
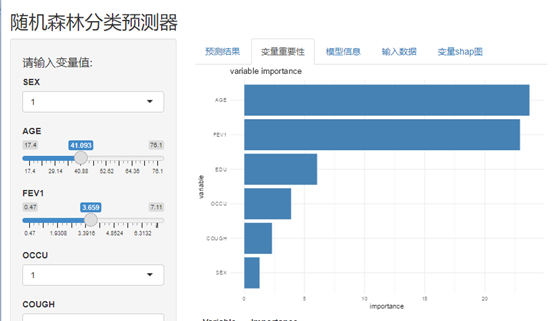
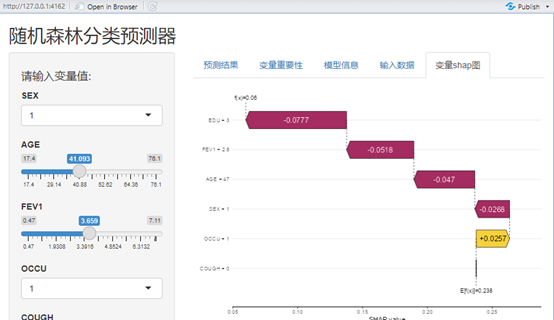
这样简单的一句话代码,交互是应用程序就生成了,拖动按钮,更改参数可以得到不同患者的发病率。
如果你想发英文,也可以简单更改一下,看下函数参数

修改一下
r
shiny.randomForest(model=fit, data=data_train, app_title ="随机森林分类预测器",username=username,token=token,
tabPanel1 = "predct")可以看到已经改成英文了
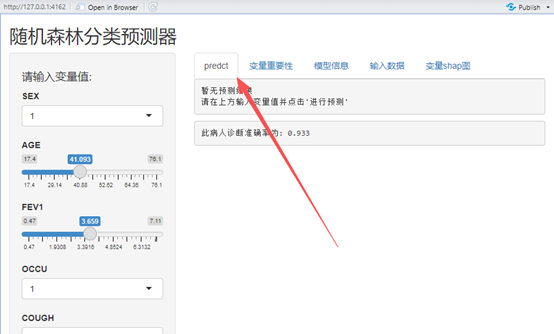
这是我第一次写交互式应用函数,难免有些不足,后面应该会越写越好,除了机器学习,咱们的生存分析,列线图等都能做,后面我再写写,有什么意见和建议可以私信给我。
R语言基于shiny开发随机森林预测模型交互式 Web 应用程序(应用程序)