
😊你好,我是小航,一个正在变秃、变强的文艺倾年。
🔔本专栏《八股消消乐》旨在记录个人所背的八股文,包括
Java/Go开发、Vue开发、系统架构、大模型开发、具身智能、机器学习、深度学习、力扣算法等相关知识点,期待与你一同探索、学习、进步,一起卷起来叭!
目录
近期事情太多了,一直再赶别的事情,所以《八股消消乐》停更了一段时间,接下来会继续更新,助大家早日拿到自己的offer,冲冲冲!
题目
💬技术栈:分布式协议和算法
🔍简历内容:熟悉常见的分布式协议和算法,Paxos、Raft、Gossip、一致性哈希等理论。
🚩面试问:
- 为什么要学这些呢?
我希望我们都是分布式系统的架构师、开发者,而不仅仅是开源软件的使用者。

💡建议暂停思考10s,你有答案了嘛?如果你有不同题解,欢迎评论区留言、打卡。
答案
基础理论
拜占庭将军问题
拜占庭将军问题是分布式系统中的一个经典问题,主要研究在存在叛徒的情况下,如何通过消息传递达成共识。
故事来源:拜占庭罗马帝国国土辽阔,为了达到防御目的,每个军队都分隔很远,将军与将军之间只能靠信差传消息。在战争的时候,拜占庭军队内所有将军和副官必须达成一致的共识,决定是否有赢的机会才去攻打敌人的阵营。
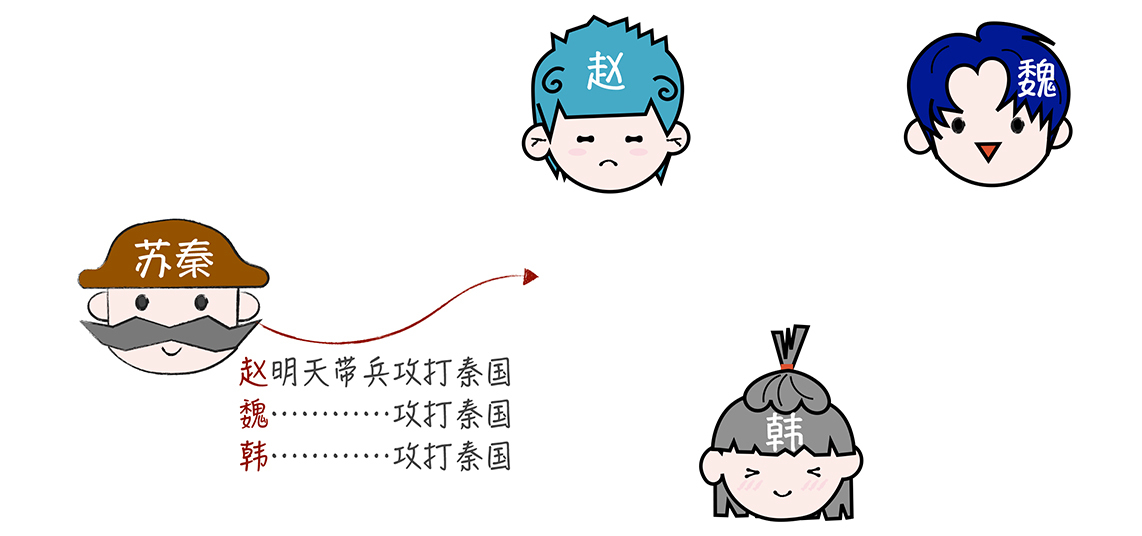
为了便于理解,后续的内容铺垫都为:战国时期,齐、楚、燕、韩、赵、魏、秦七雄并立,后来秦国的势力不断强大起来,成了东方六国的共同威胁。于是,这六个国家决定联合,全力抗秦,免得被秦国各个击破。一天,苏秦作为合纵长,挂六国相印,带着六国的军队叩关函谷,驻军在了秦国边境,为围攻秦国作准备。但是,因为各国军队分别驻扎在秦国边境的不同地方,所以军队之间只能通过信使互相联系,这时,苏秦面临了一个很严峻的问题:如何统一大家的作战计划?
解决方案:
(1)口信消息型拜占庭问题之解:
首先,三位将军都分拨一部分军队,由苏秦率领,苏秦参与作战计划讨论并执行作战指令。这样,3位将军的作战讨论,就变为了4位将军的作战讨论,这能够增加讨论中忠诚将军的数量。
然后呢,4位将军还约定了,如果没有收到命令,就执行预设的默认命令,比如"撤退"。除此之外,还约定一些流程来发送作战信息、执行作战指令,比如,进行两轮作战信息协商。
(2)签名消息型拜占庭问题之解:
苏秦要通过印章、虎符等信物,实现这样几个特性:
- 忠诚将军的签名无法伪造,而且对他签名消息的内容进行任何更改都会被发现;
- 任何人都能验证将军签名的真伪。
这时,如果忠诚的将军,比如齐先发起作战信息协商,一旦叛将小楚修改或伪造收到的作战信息,那么燕在接收到楚的作战信息的时候,会发现齐的作战信息被修改,楚已叛变,这时他将忽略来自楚的作战信息,最终执行齐发送的作战信息。
如果叛变将军楚先发送误导的作战信息,那么,齐和燕将按照一定规则(比如取中间的指令)在排序后的所有已接收到的指令中(比如撤退、进攻)中选取一个指令,进行执行,最终执行一致的作战计划。
CAP
CAP理论对分布式系统的特性做了高度抽象,形成了三个指标:
- 一致性(Consistency):客户端的每次读操作,不管访问哪个节点,要么读到的都是同一份最新写入的数据,要么读取失败。【
数据正确】 - 可用性(Availability):任何来自客户端的请求,不管访问哪个非故障节点,都能得到响应数据,但不保证是同一份最新数据。【
服务可用,但不保证数据正确】 - 分区容错性(Partition Tolerance):当节点间出现任意数量的消息丢失或高延迟的时候,系统仍然在继续工作。【
集群对分区故障的容错能力】
不过一致性(Consistency)、可用性(Availability)、分区容错性(Partition Tolerance)3个指标不可兼得,只能在3个指标中选择2个。
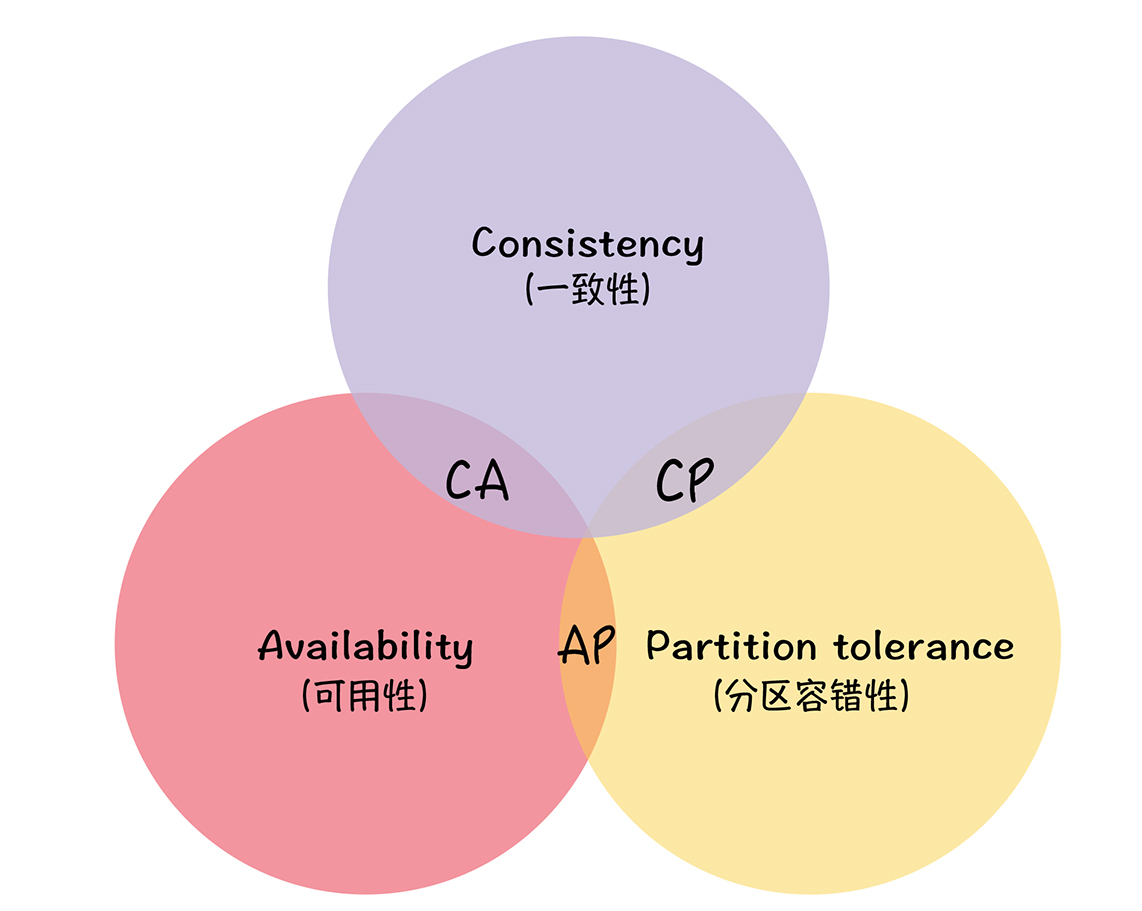
在分布式系统中,一定会涉及到网络交互,只要有网络交互就一定会有延迟和数据丢失,而这种状况我们必须接受,还必须保证系统不能挂掉。所以就像我上面提到的,节点间的分区故障是必然发生的。也就是说,在分布式系统中,分区容错性(P)是前提,是必须要保证的。
- CA模型:在分布式系统中不存在。因为舍弃P,意味着舍弃分布式系统,就比如单机版关系型数据库MySQL。
- CP模型:采用CP模型的分布式系统,舍弃了可用性,
一定会读到最新数据,不会读到旧数据。一旦因为消息丢失、延迟过高发生了网络分区,就影响用户的体验和业务的可用性(比如基于Raft的强一致性系统,此时可能无法执行读操作和写操作)。典型的应用是Etcd,Consul和Hbase。 - AP模型:采用AP模型的分布式系统,舍弃了一致性,实现了服务的高可用。
用户访问系统的时候,都能得到响应数据,不会出现响应错误,但会读到旧数据。典型应用就比如Cassandra和DynamoDB。
二阶段提交协议
二阶段提交协议:通过二阶段的协商来完成一个提交操作。二阶段提交在达成提交操作共识的算法中应用广泛,比如XA协议【这个协议是X/Open国际联盟基于二阶段提交协议提出的,也叫作X/Open Distributed Transaction Processing(DTP)模型,比如MySQL就是通过MySQL XA实现了分布式事务。】、TCC、Paxos、Raft等。
举例:
(1) 苏秦发消息给赵,赵接收到消息后就扮演协调者(Coordinator)的身份
(2) 赵进入 提交请求阶段(又称投票阶段)
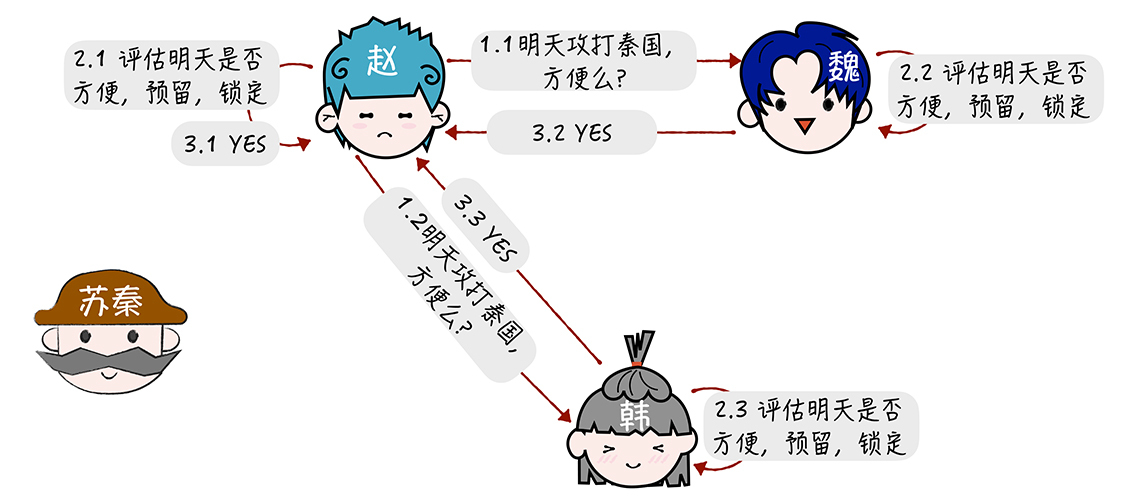
(3) 赵收到所有回复后,进入 提交执行阶段(又称完成阶段):
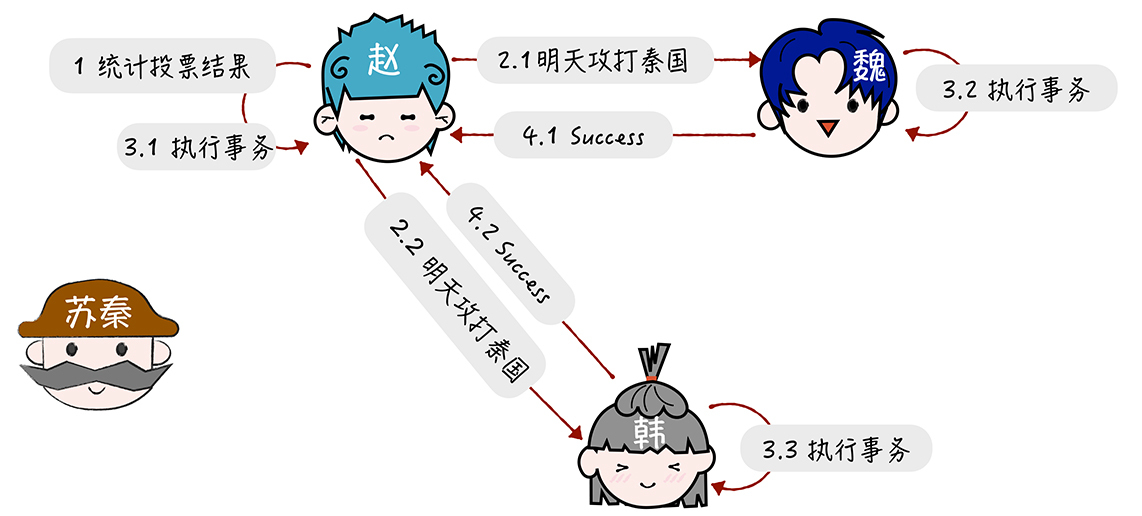
需要注意的是在第一个阶段,每个参与者投票表决事务是放弃还是提交。一旦参与者投票要求提交事务,那么就不允许放弃事务。也就是说, 在一个参与者投票要求提交事务之前,它必须保证能够执行提交协议中它自己那一部分,即使参与者出现故障或者中途被替换掉。
存在的问题:
- 在提交请求阶段,需要预留资源,在资源预留期间,其他人不能操作(比如,XA在第一阶段会将相关资源锁定);
- 数据库是独立的系统。
解决方案:TCC(Try-Confirm-Cancel)
TCC
TCC是Try(预留)、Confirm(确认)、Cancel(撤销) 3个操作的简称,它包含了预留、确认或撤销这2个阶段。
(1)进入到预留阶段:
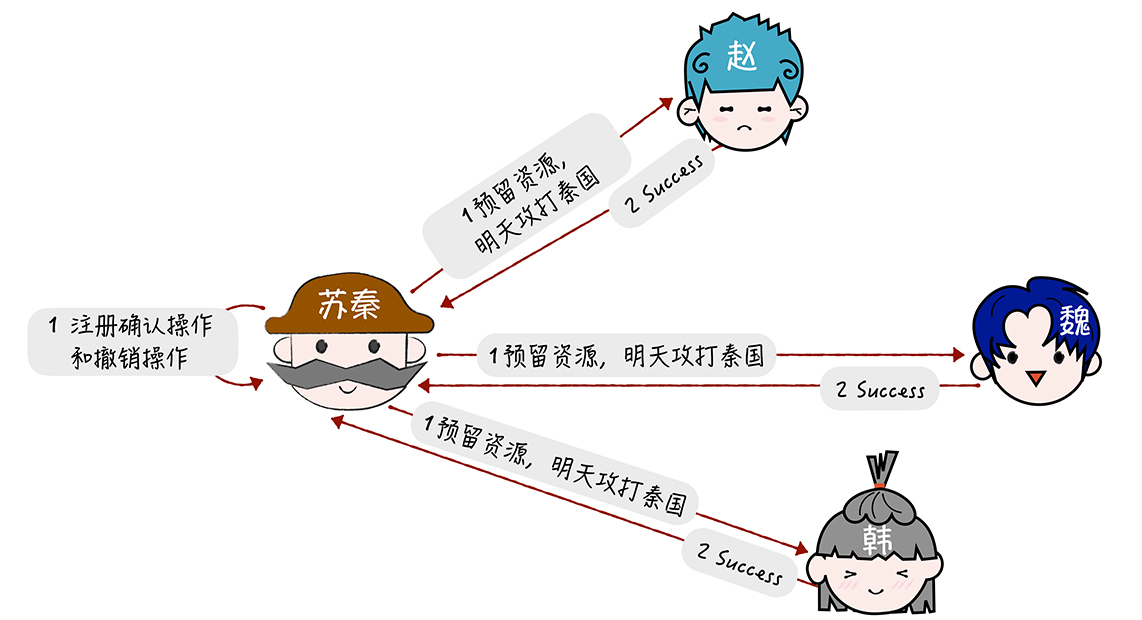
(2)确认阶段:
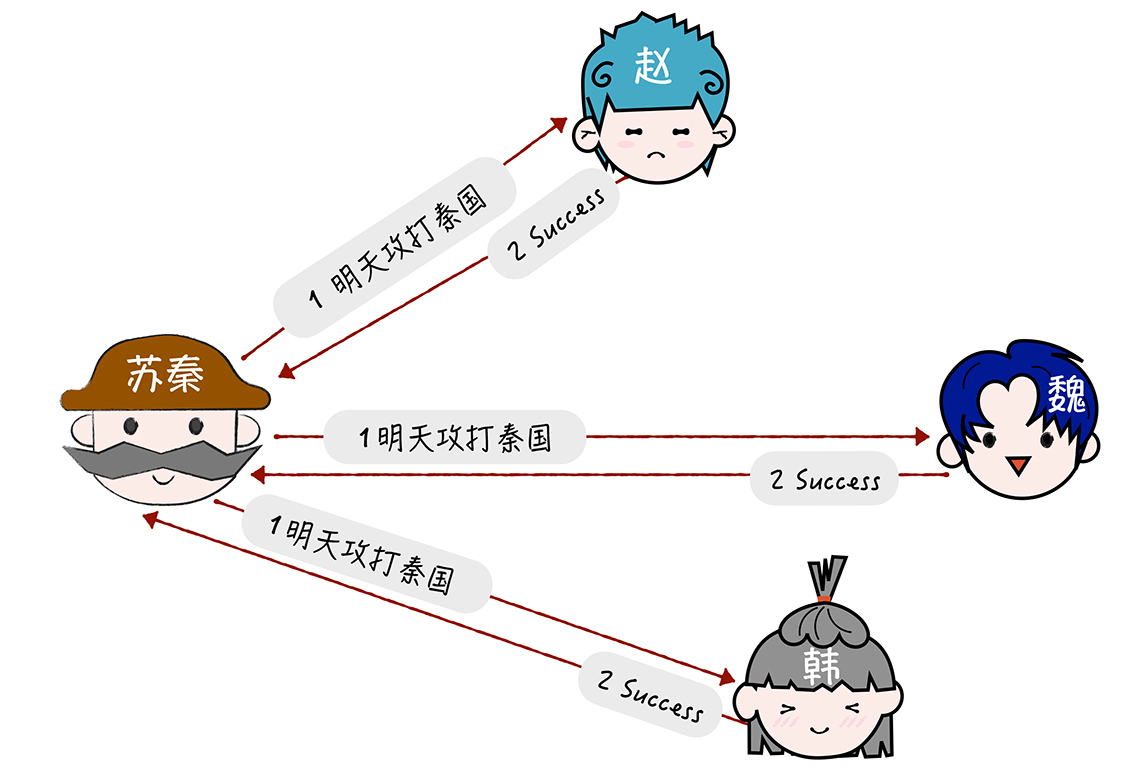
(3)如果预留阶段执行出错,那么就进入撤销 阶段:
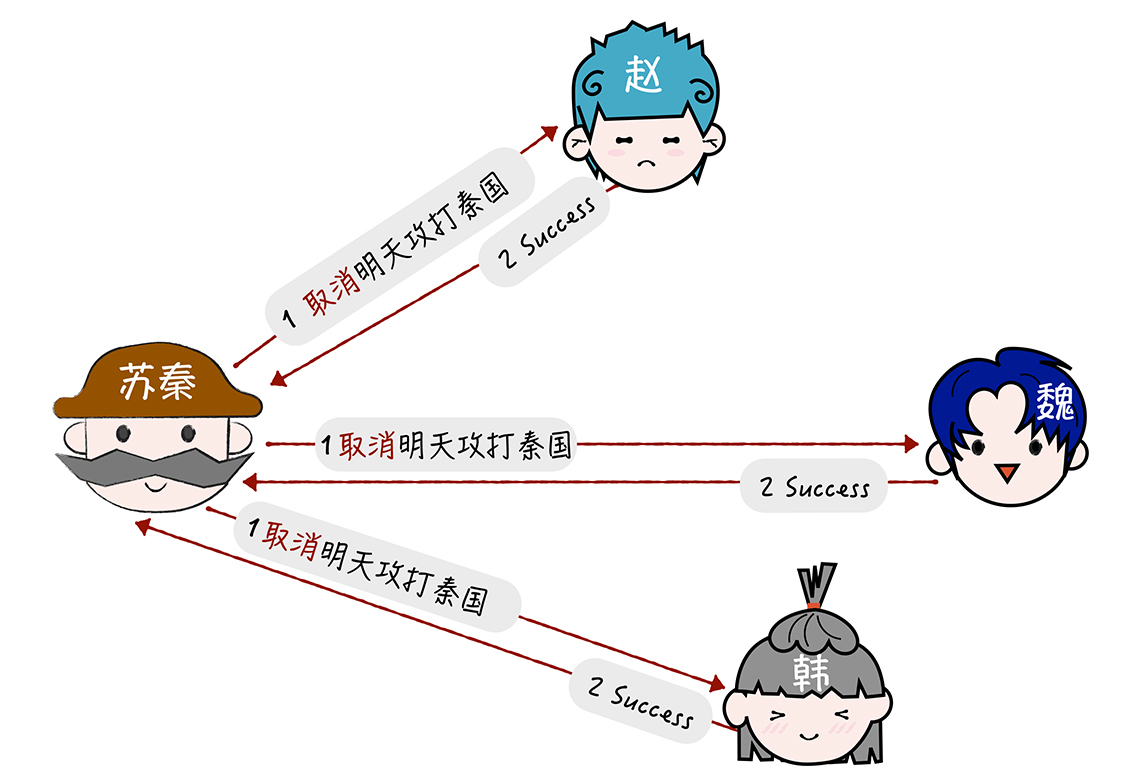
TCC本质上是补偿事务, 它的核心思想是针对每个操作都要注册一个与其对应的确认操作和补偿操作(也就是撤销操作)。
二阶段提交协议存在的问题:协调者故障,参与者长期锁定资源
三阶段提交协议:通过引入了询问阶段和超时机制,来减少资源被长时间锁定的情况。不过这会导致集群各节点在正常运行的情况下,
使用更多的消息进行协商,增加系统负载和响应延迟。
幂等
幂等性:同一操作对同一系统的任意多次执行,所产生的影响均与一次执行的影响相同,不会因为多次执行而产生副作用。常见的实现方法有Token、索引等。它的本质是通过唯一标识,标记同一操作的方式,来消除多次执行的副作用。
BASE
BASE理论:
- BASE理论是对CAP中一致性和可用性权衡的结果,它来源于对大规模互联网分布式系统实践的总结,是基于CAP定理逐步演化而来的。它的核心思想是,
如果不是必须的话,不推荐实现事务或强一致性,鼓励可用性和性能优先,根据业务的场景特点,来实现非常弹性的基本可用,以及实现数据的最终一致性。 - BASE理论主张
通过牺牲部分功能的可用性,实现整体的基本可用,也就是说,通过服务降级的方式,努力保障极端情况下的系统可用性。 - ACID理论是
传统数据库常用的设计理念,追求强一致性模型。BASE理论支持的是大型分布式系统,通过牺牲强一致性获得高可用性。BASE理论在很大程度上,解决了事务型系统在性能、容错、可用性等方面痛点。BASE理论在NoSQL中应用广泛,是NoSQL系统设计的事实上的理论支撑。
协议和算法
Paxos算法
Basic Paxos算法:描述的是多节点之间如何就某个值(提案Value)达成共识;
Multi-Paxos思想:描述的是执行多个Basic Paxos实例,就一系列值达成共识。
Basic Paxos
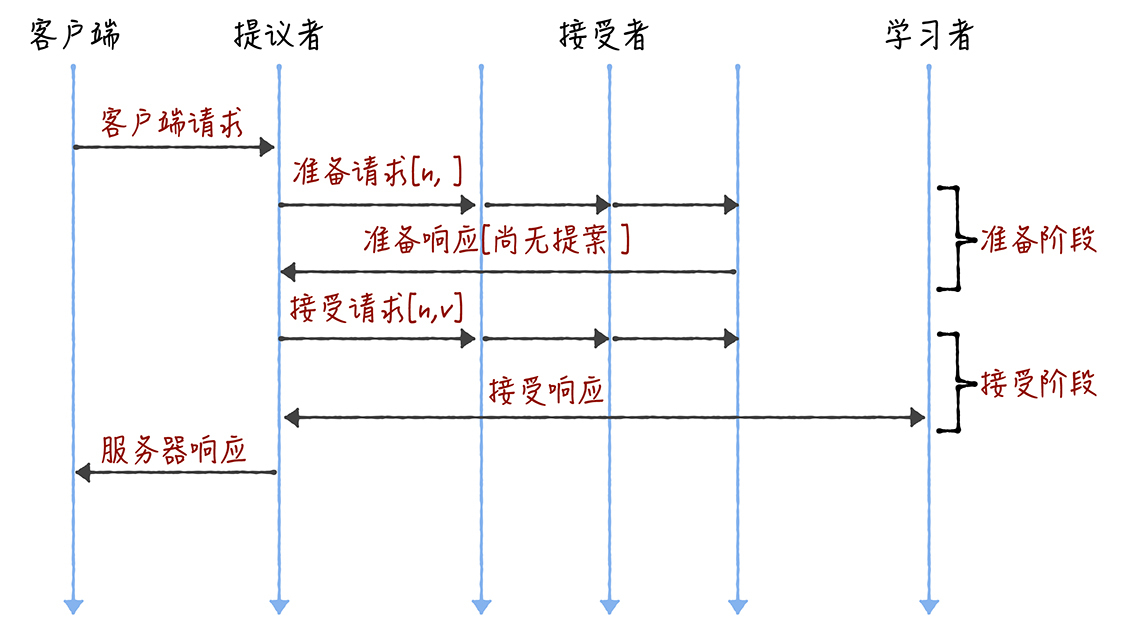
在Basic Paxos中,有提议者(Proposer)、接受者(Acceptor)、学习者(Learner)三种角色,他们之间的关系如下:
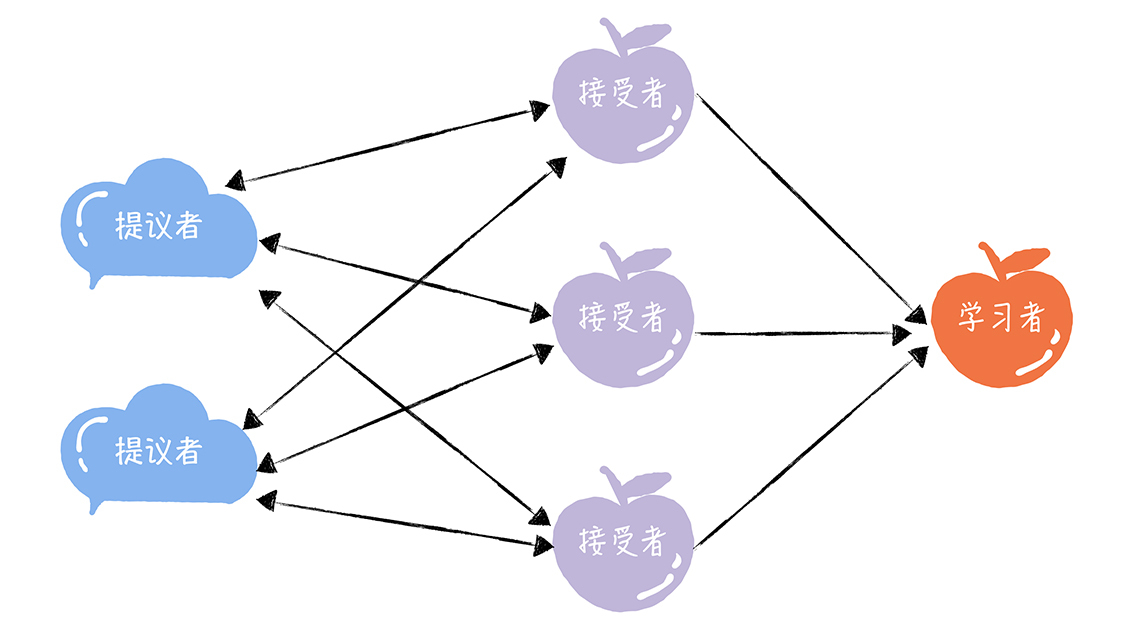
- 提议者(Proposer):
提议一个值,用于投票表决。提议者代表的是接入和协调功能,收到客户端请求后,发起二阶段提交,进行共识协商; - 接受者(Acceptor):
对每个提议的值进行投票,并存储接受的值。 一般来说,集群中的所有节点都在扮演接受者的角色,参与共识协商,并接受和存储数据。 - 学习者(Learner):被告知投票的结果,接受达成共识的值,存储保存,不参与投票的过程。
一般来说,学习者是数据备份节点,比如"Master-Slave"模型中的Slave,被动地接受数据,容灾备份。
达成共识的过程:
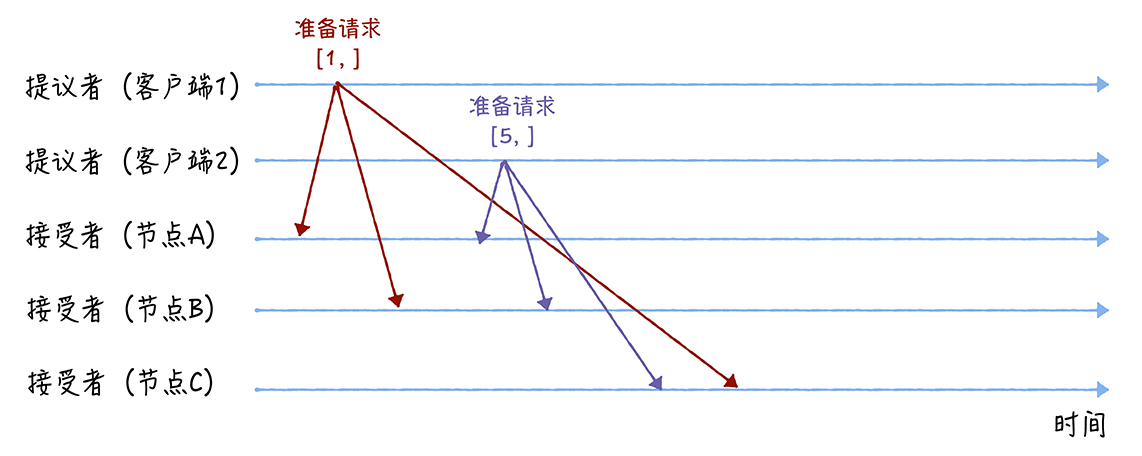
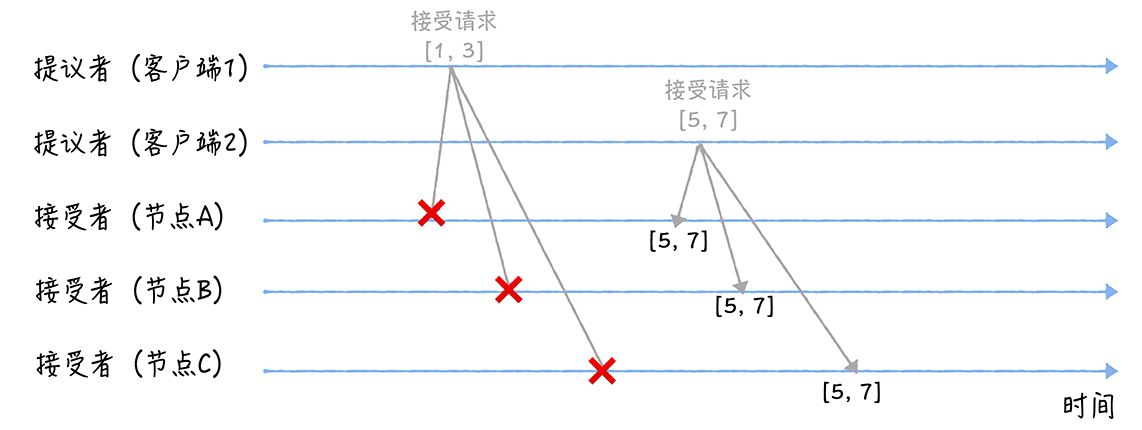
(1)准备阶段(Prepare):
客户端1、2作为提议者,分别向所有接受者发送包含提案编号的准备请求:
由于之前没有通过任何提案,所以节点返回一个 "尚无提案"的响应。
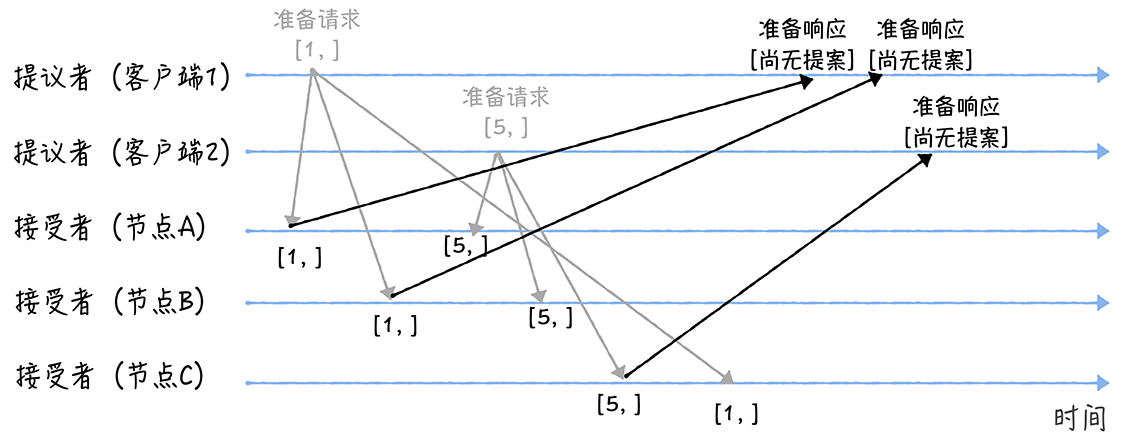
节点C收到提案编号为1的准备请求的时候,由于提案编号1小于它之前响应的准备请求的提案编号5,所以丢弃该准备请求,不做响应。
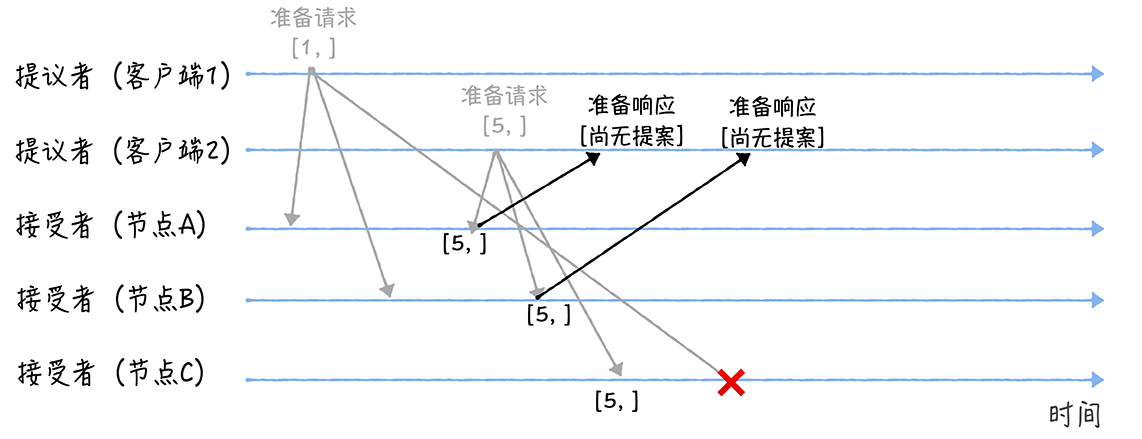
(2)接受阶段(Accept):
客户端1、2在收到大多数节点的准备响应之后,会分别发送接受请求:
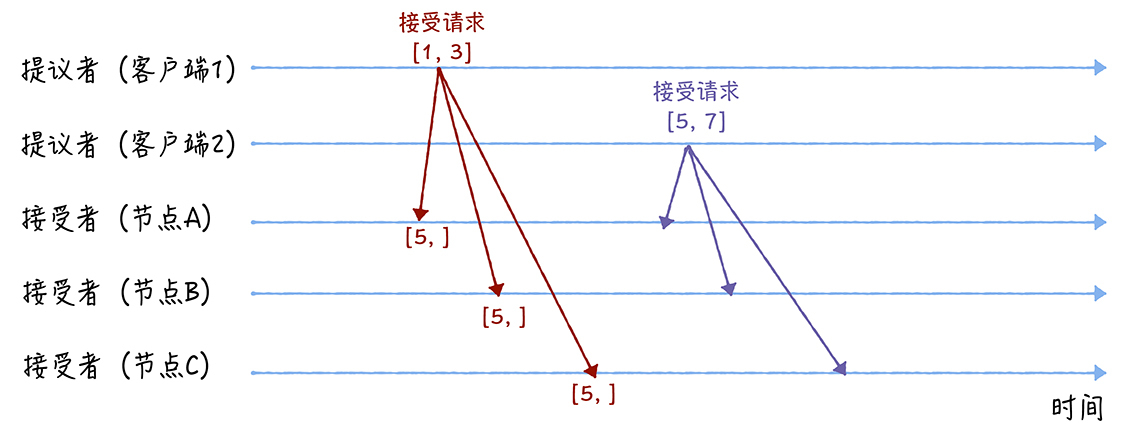
当三个节点收到2个客户端的接受请求时,会进行这样的处理:
如果集群中有学习者,当接受者通过了一个提案时,就通知给所有的学习者。当学习者发现大多数的接受者都通过了某个提案,那么它也通过该提案,接受该提案的值。
除了共识,Basic Paxos还实现了容错,在少于一半的节点出现故障时,集群也能工作。它不像分布式事务算法那样,必须要所有节点都同意后才提交操作,因为"所有节点都同意"这个原则,在出现节点故障的时候会导致整个集群不可用。也就是说,"大多数节点都同意"的原则,赋予了Basic Paxos容错的能力,让它能够容忍少于一半的节点的故障。
本质上而言,提案编号的大小代表着优先级,你可以这么理解,根据提案编号的大小,接受者保证 三个承诺,具体来说:
- 如果
准备请求的提案编号, 小于等于 接受者已经响应的准备请求的提案编号,那么接受者将承诺不响应这个准备请求; - 如果
接受请求中的提案的提案编号, 小于 接受者已经响应的准备请求的提案编号,那么接受者将承诺不通过这个提案; - 如果
接受者之前有通过提案,那么接受者将承诺,会在准备请求的响应中,包含 已经通过的最大编号的提案信息。
存在的问题:Basic Paxos只能就单个值(Value)达成共识,一旦遇到为一系列的值实现共识的时候,它就不管用了。虽然兰伯特提到可以通过多次执行Basic Paxos实例(比如每接收到一个值时,就执行一次Basic Paxos算法)实现一系列值的共识。
Multi-Paxos
如果我们直接通过多次执行Basic Paxos实例,来实现一系列值的共识,就会存在这样几个问题:
-
如果多个提议者同时提交提案,可能出现因为提案编号冲突,在准备阶段没有提议者接收到大多数准备响应,协商失败,需要重新协商。你想象一下,
一个5节点的集群,如果3个节点作为提议者同时提案,就可能发生因为没有提议者接收大多数响应(比如1个提议者接收到1个准备响应,另外2个提议者分别接收到2个准备响应)而准备失败,需要重新协商。 -
2轮RPC通讯(准备阶段和接受阶段)
往返消息多、耗性能、延迟大。你要知道,分布式系统的运行是建立在RPC通讯的基础之上的。
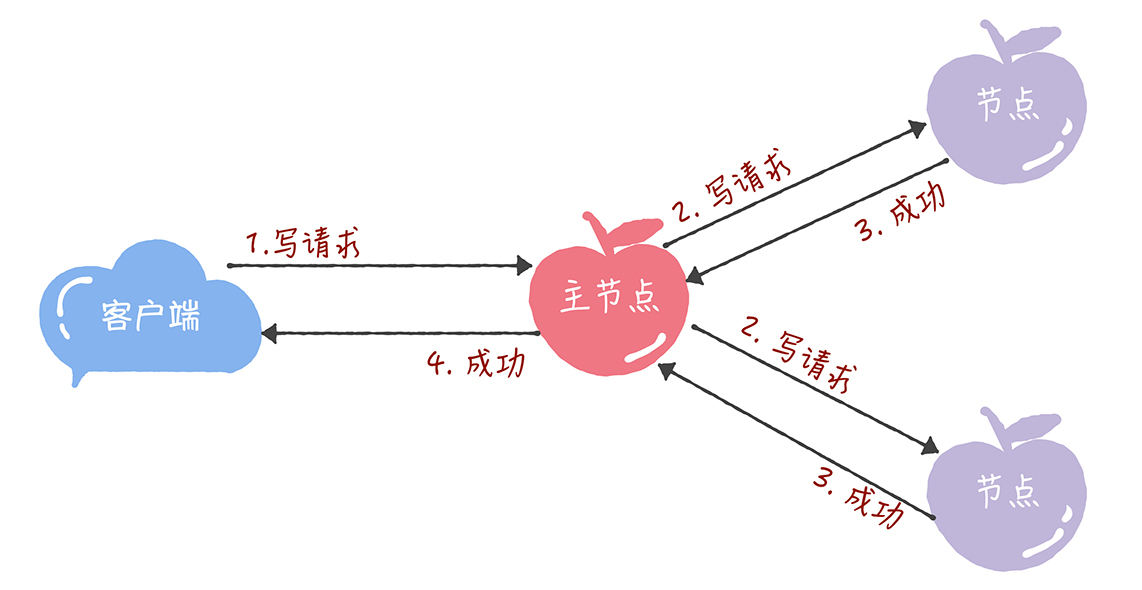
解决方案:实现主节点(也就是兰伯特提到的领导者),也实现了兰伯特提到的 "当领导者处于稳定状态时,省掉准备阶段,直接进入接受阶段" 这个优化机制,省掉Basic Paxos的准备阶段,提升了数据的提交效率,但是所有写请求都在主节点处理,限制了集群处理写请求的并发能力,约等于单机。
(1)写请求:
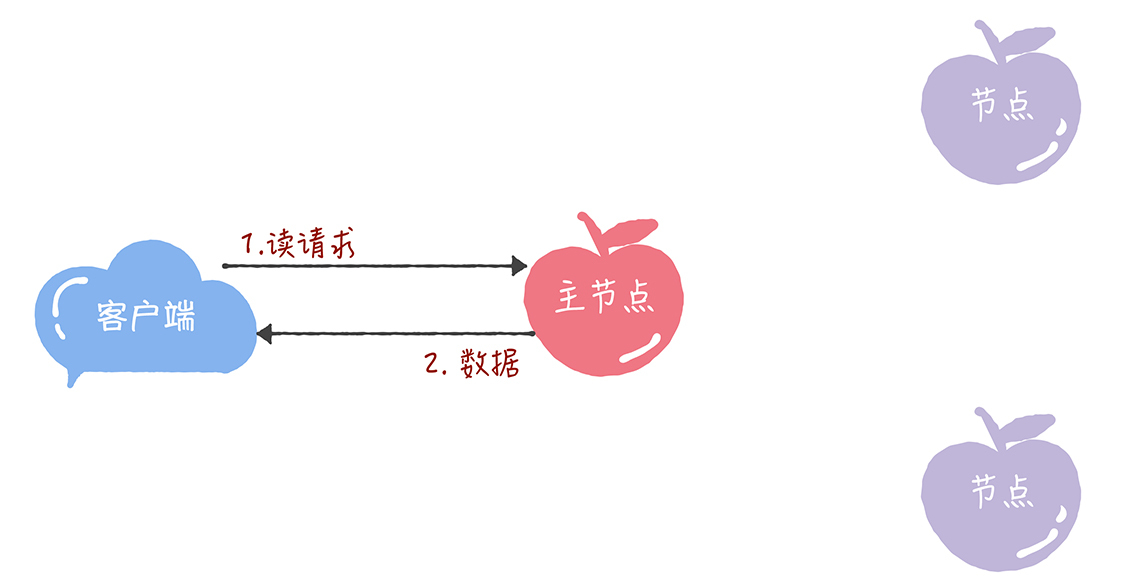
(2)读请求:
Raft算法
Raft算法:通过一切以领导者为准的方式,实现一系列值的共识和各节点日志的一致。 Raft算法支持领导者(Leader)、跟随者(Follower)和候选人(Candidate) 3种状态。

- 跟随者:就相当于
普通群众,默默地接收和处理来自领导者的消息,当等待领导者心跳信息超时的时候,就主动站出来,推荐自己当候选人。 - 候选人:
候选人将向其他节点发送请求投票(RequestVote)RPC消息,通知其他节点来投票,如果赢得了大多数选票,就晋升当领导者。 - 领导者:蛮不讲理的霸道总裁,
一切以我为准,平常的主要工作内容就是3部分,处理写请求、管理日志复制和不断地发送心跳信息,通知其他节点"我是领导者,我还活着,你们现在不要发起新的选举,找个新领导者来替代我。"
领导者选举
在初始状态下,集群中所有的节点都是跟随者的状态。
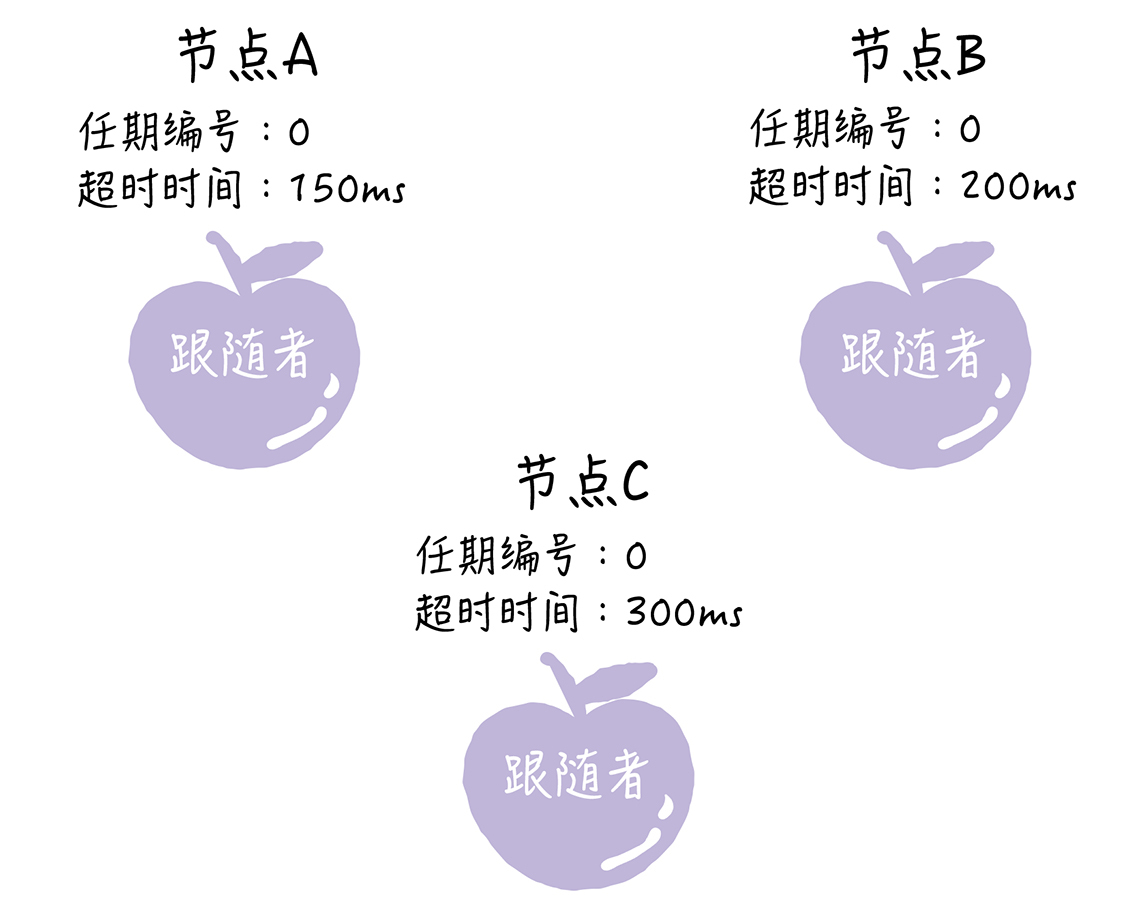
节点A增加自己的任期编号,并推举自己为候选人,先给自己投上一张选票,然后向其他节点发送请求投票RPC消息,请它们选举自己为领导者。
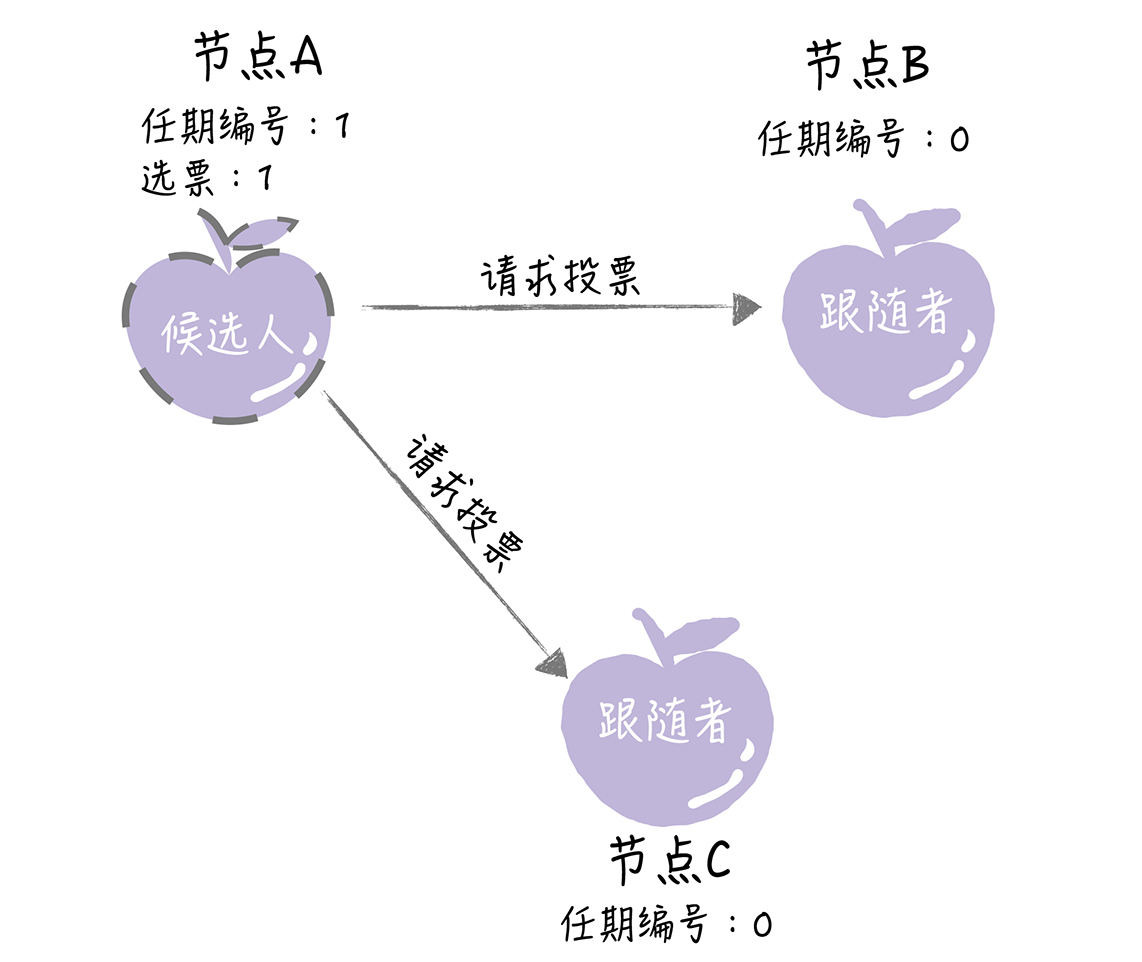
如果其他节点接收到候选人A的请求投票RPC消息,在编号为1的这届任期内,也还没有进行过投票,那么它将把选票投给节点A,并增加自己的任期编号。
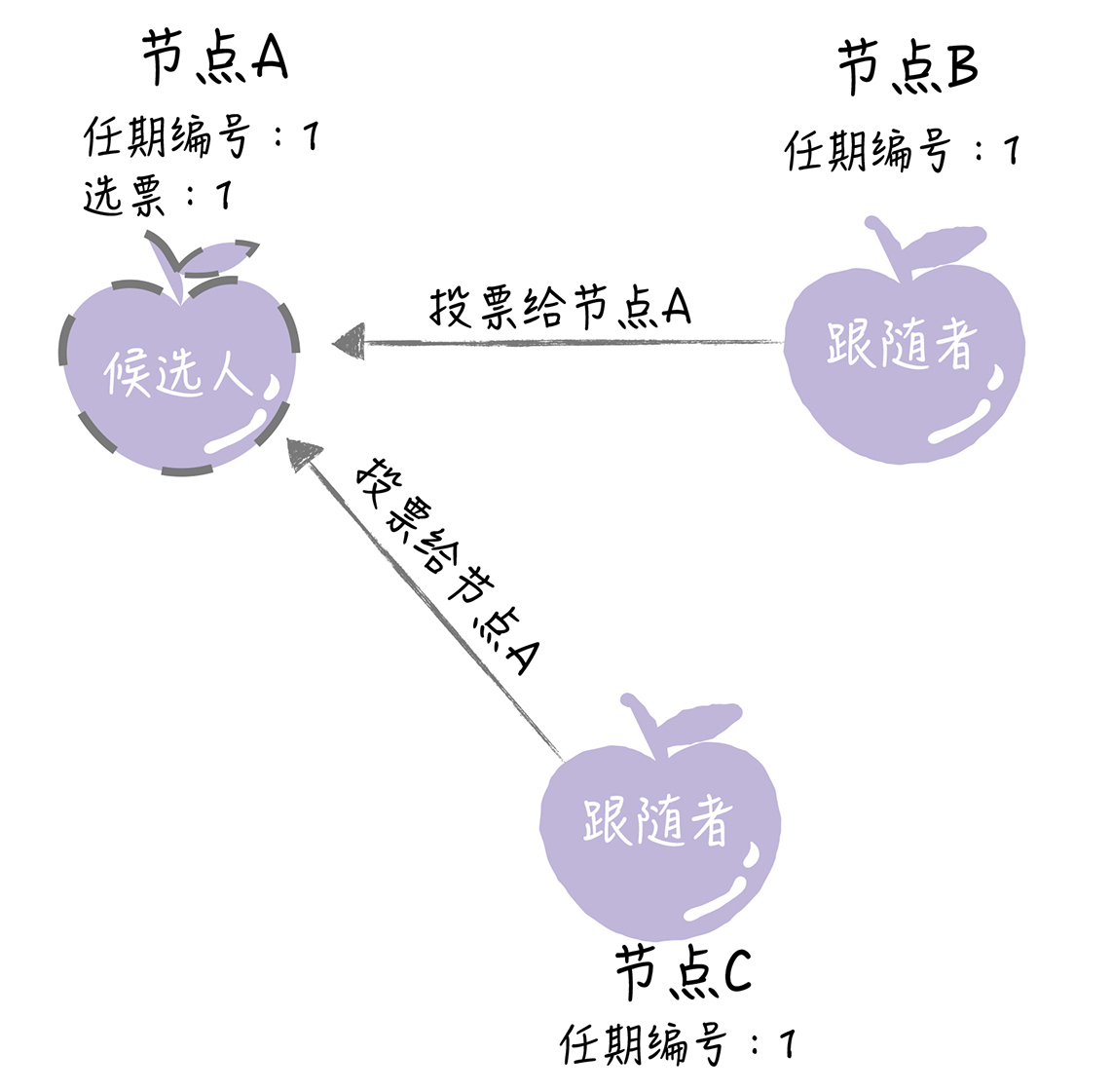
如果候选人在选举超时时间内赢得了大多数的选票,那么它就会成为本届任期内新的领导者。
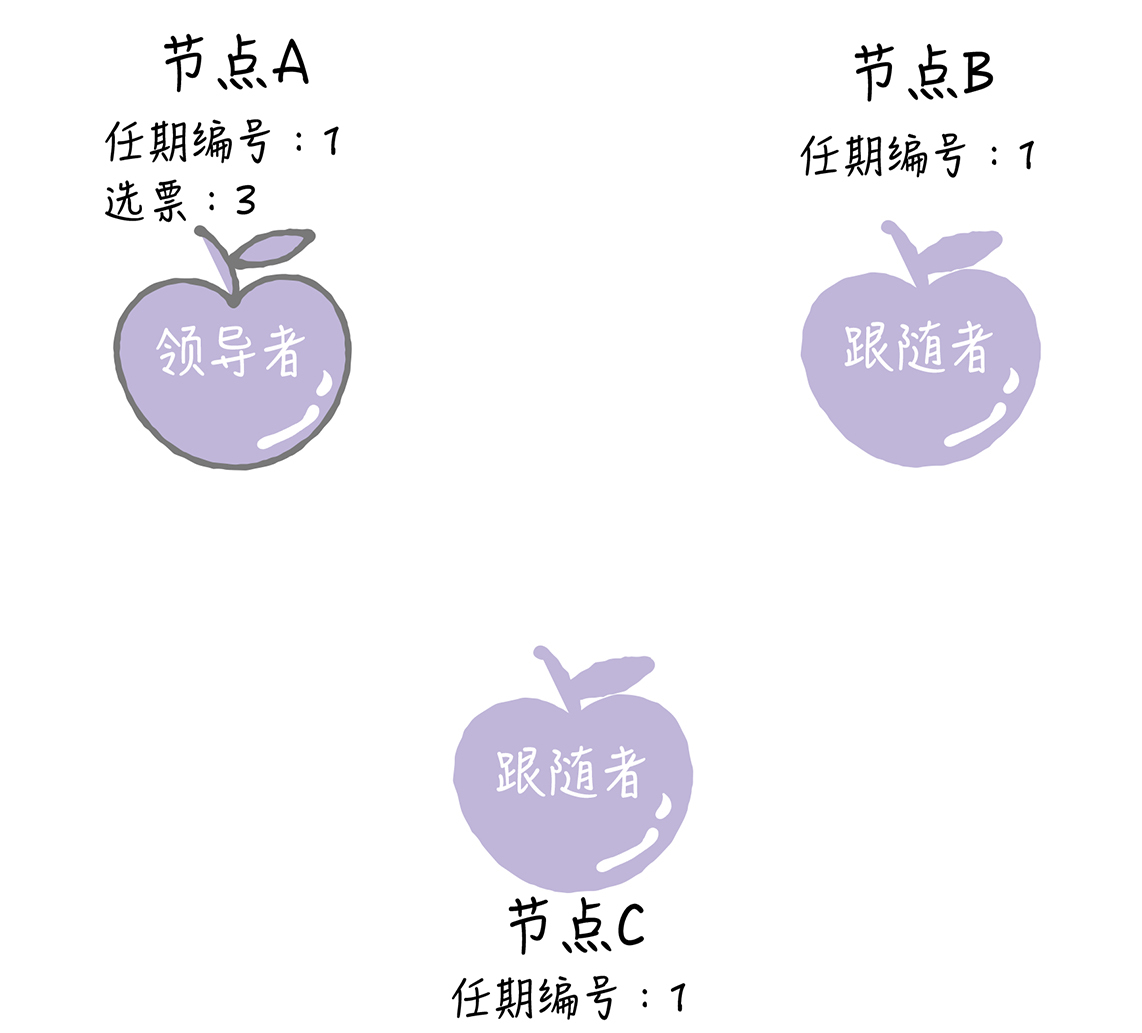
节点A当选领导者后,他将周期性地发送心跳消息,通知其他服务器我是领导者,阻止跟随者发起新的选举,篡权。
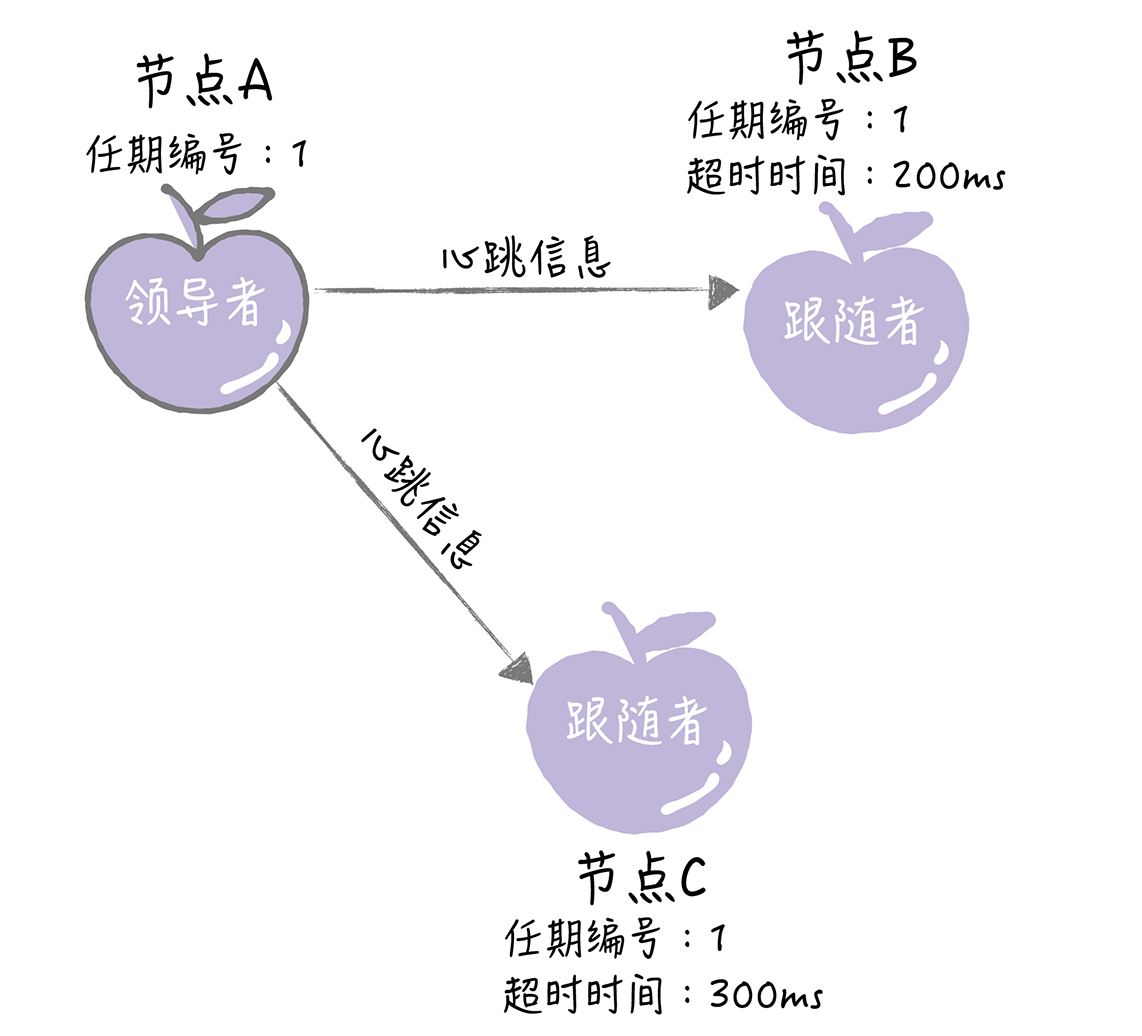
常见问题:
(1)节点间是如何通讯的呢?
在Raft算法中,服务器节点间的沟通联络采用的是远程过程调用(RPC),在领导者选举中,需要用到这样两类的RPC:
- 请求投票(RequestVote)RPC,是由候选人在选举期间发起,通知各节点进行投票;
- 日志复制(AppendEntries)RPC,是由领导者发起,用来复制日志和提供心跳消息。
日志复制
在Raft算法中,副本数据是以日志的形式存在的,日志是由日志项组成。领导者接收到来自客户端写请求后,处理写请求的过程就是一个复制和应用(Apply)日志项到状态机的过程。
日志项:一种数据格式,它主要包含用户指定的数据,也就是指令(Command),还包含一些附加信息,比如索引值(Log index)、任期编号(Term)。
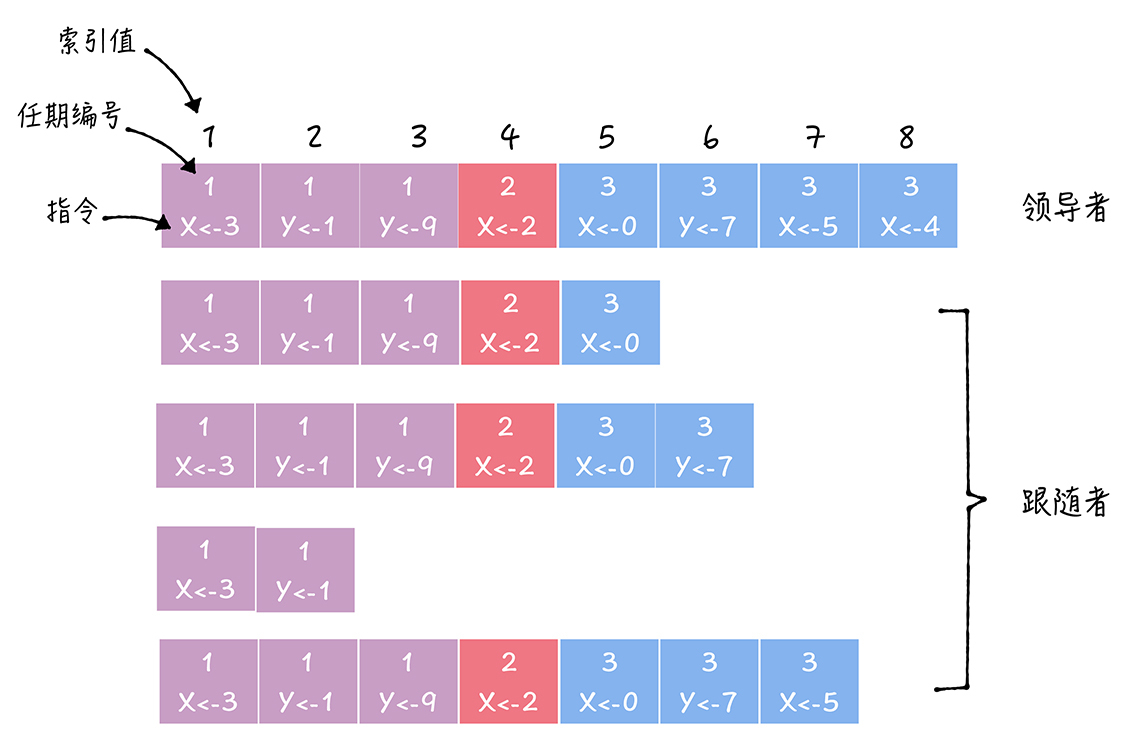
- 指令:一条由客户端请求指定的、状态机需要执行的指令。你可以将指令理解成客户端指定的数据。
- 索引值:日志项对应的整数索引值。它其实就是用来标识日志项的,是一个连续的、单调递增的整数号码。
- 任期编号:创建这条日志项的领导者的任期编号。
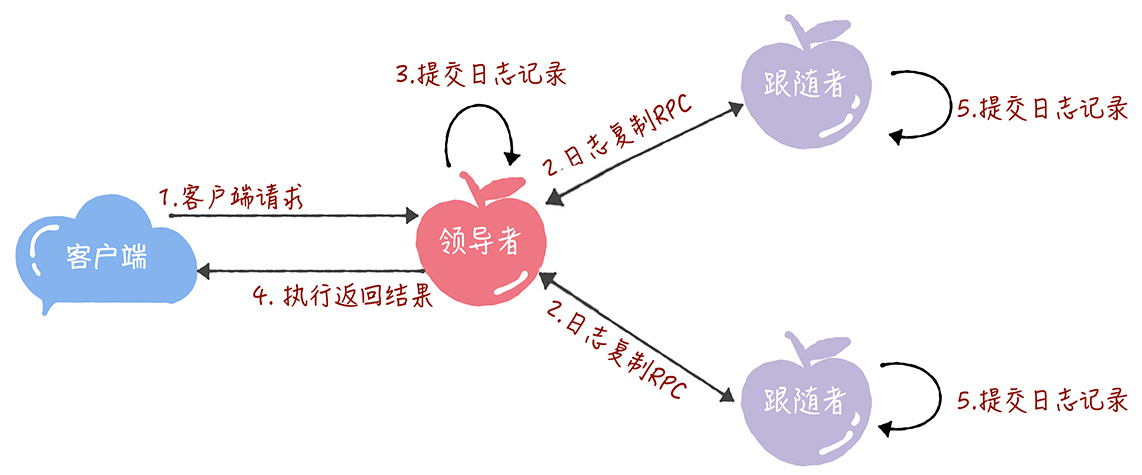
-
接收到客户端请求后,领导者基于客户端请求中的指令,创建一个新日志项,并附加到本地日志中。
-
领导者通过日志复制RPC,将新的日志项复制到其他的服务器。
-
当领导者将日志项,
成功复制到大多数的服务器上的时候,领导者会将这条日志项应用到它的状态机中。 -
领导者
将执行的结果返回给客户端。 -
当跟随者接收到心跳信息,或者新的日志复制RPC消息后,
如果跟随者发现领导者已经提交了某条日志项,而它还没应用,那么跟随者就将这条日志项应用到本地的状态机中。
可能会遇到的问题:复制日志的时候,可能会遇到进程崩溃、服务器宕机等问题,这些问题会导致日志不一致。
解决方案:
在Raft算法中,领导者通过强制跟随者直接复制自己的日志项,处理不一致日志。也就是说,Raft是通过以领导者的日志为准,来实现各节点日志的一致的。具体有2个步骤。
(1)领导者通过日志复制RPC的一致性检查,找到跟随者节点上,与自己相同日志项的最大索引值。也就是说,这个索引值之前的日志,领导者和跟随者是一致的,之后的日志是不一致的了。
(2)领导者强制跟随者更新覆盖的不一致日志项,实现日志的一致。
下面详细地走一遍这个过程(为了方便演示,我们引入2个新变量)。
- PrevLogEntry:表示当前要复制的日志项,前面一条日志项的索引值。比如在图中,如果领导者将索引值为8的日志项发送给跟随者,那么此时PrevLogEntry值为7。
- PrevLogTerm:表示当前要复制的日志项,前面一条日志项的任期编号,比如在图中,如果领导者将索引值为8的日志项发送给跟随者,那么此时PrevLogTerm值为4。
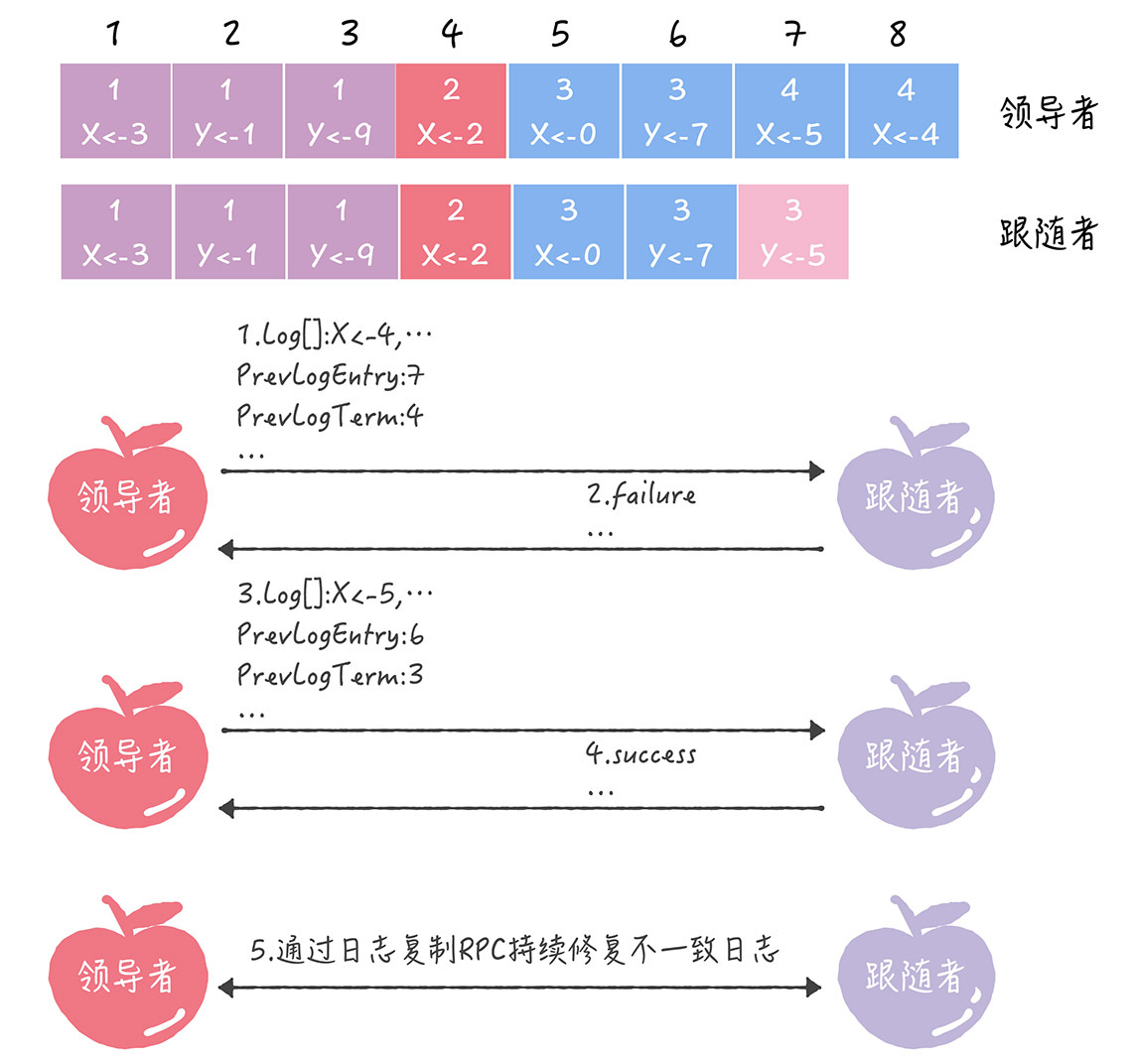
-
领导者通过日志复制RPC消息,发送当前最新日志项到跟随者(为了演示方便,假设当前需要复制的日志项是最新的),这个消息的PrevLogEntry值为7,PrevLogTerm值为4。
-
如果跟随者在它的日志中,找不到与PrevLogEntry值为7、PrevLogTerm值为4的日志项,也就是说它的日志和领导者的不一致了,那么跟随者就会拒绝接收新的日志项,并返回失败信息给领导者。
-
这时,领导者会递减要复制的日志项的索引值,并发送新的日志项到跟随者,这个消息的PrevLogEntry值为6,PrevLogTerm值为3。
-
如果跟随者在它的日志中,找到了PrevLogEntry值为6、PrevLogTerm值为3的日志项,那么日志复制RPC返回成功,这样一来,领导者就知道在PrevLogEntry值为6、PrevLogTerm值为3的位置,跟随者的日志项与自己相同。
-
领导者通过日志复制RPC,复制并更新覆盖该索引值之后的日志项(也就是不一致的日志项),最终实现了集群各节点日志的一致。
成员变更
存在的问题:Raft是共识算法,对集群成员进行变更时(比如增加2台服务器),会不会因为集群分裂,出现2个领导者呢?
假设我们有一个由节点A、B、C组成的Raft集群,现在我们需要增加数据副本数,增加2个副本(也就是增加2台服务器),扩展为由节点A、B、C、D、E, 5个节点组成的新集群:
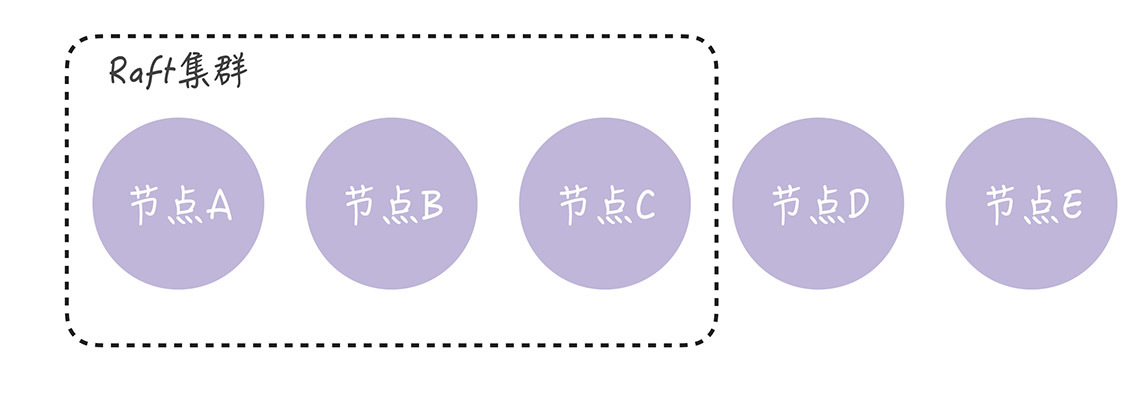
在进行成员变更时,出现了2个领导者,违背了"领导者的唯一性"的原则,进而影响到集群的稳定运行。
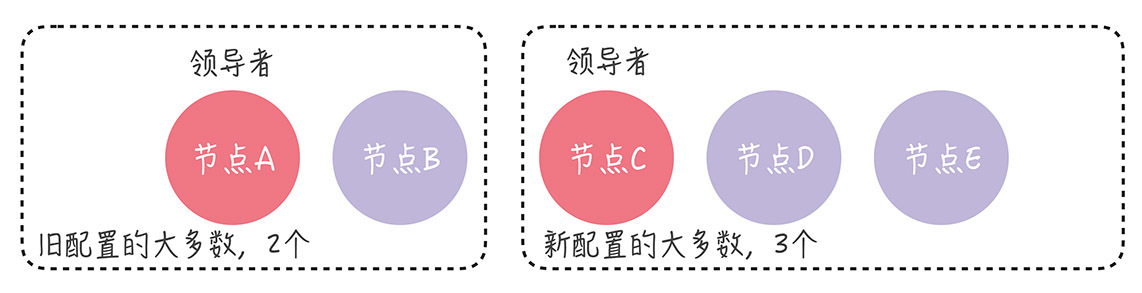
(1)节点A、B和C之间发生了分区错误,节点A、B组成旧配置中的"大多数",也就是变更前的3节点集群中的"大多数",那么这时的领导者(节点A)依旧是领导者。
(2)节点C和新节点D、E组成了新配置的"大多数",也就是变更后的5节点集群中的"大多数",它们可能会选举出新的领导者(比如节点C)。
错误的解决方案:先将集群关闭再启动新集群啊。也就是先把节点A、B、C组成的集群关闭,然后再启动节点A、B、C、D、E组成的新集群。但这种方案是不可行的,因为你每次变更都要重启集群,意味着在集群变更期间服务不可用,肯定不行啊,太影响用户体验了。想象一下,你正在玩王者荣耀,时不时弹出一个对话框通知你:系统升级,游戏暂停3分钟。这体验糟糕不糟糕?
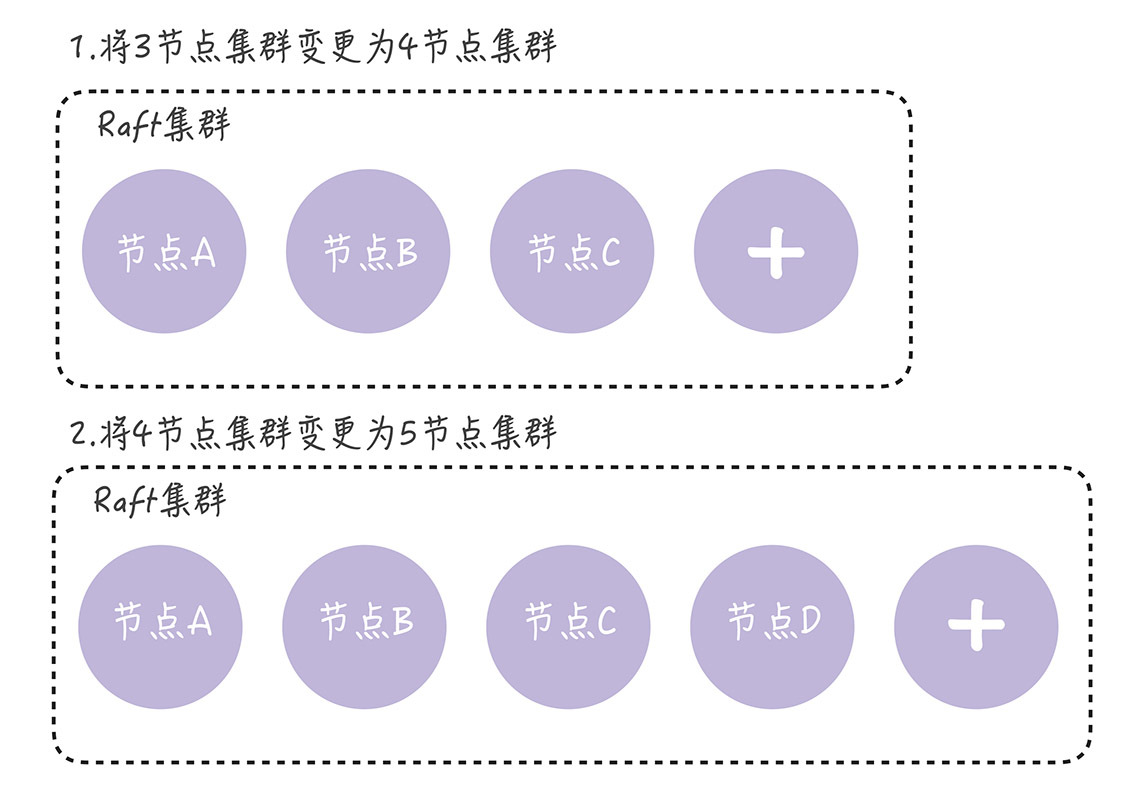
正确的解决方案:单节点变更(通过一次变更一个节点实现成员变更)。
如果需要变更多个节点,那你需要执行多次单节点变更。比如将3节点集群扩容为5节点集群,这时你需要执行2次单节点变更,先将3节点集群变更为4节点集群,然后再将4节点集群变更为5节点集群,就像下图的样子。
不过,在正常情况下, 不管旧的集群配置是怎么组成的,旧配置的"大多数"和新配置的"大多数"都会有一个节点是重叠的。 也就是说,不会同时存在旧配置和新配置2个"大多数":
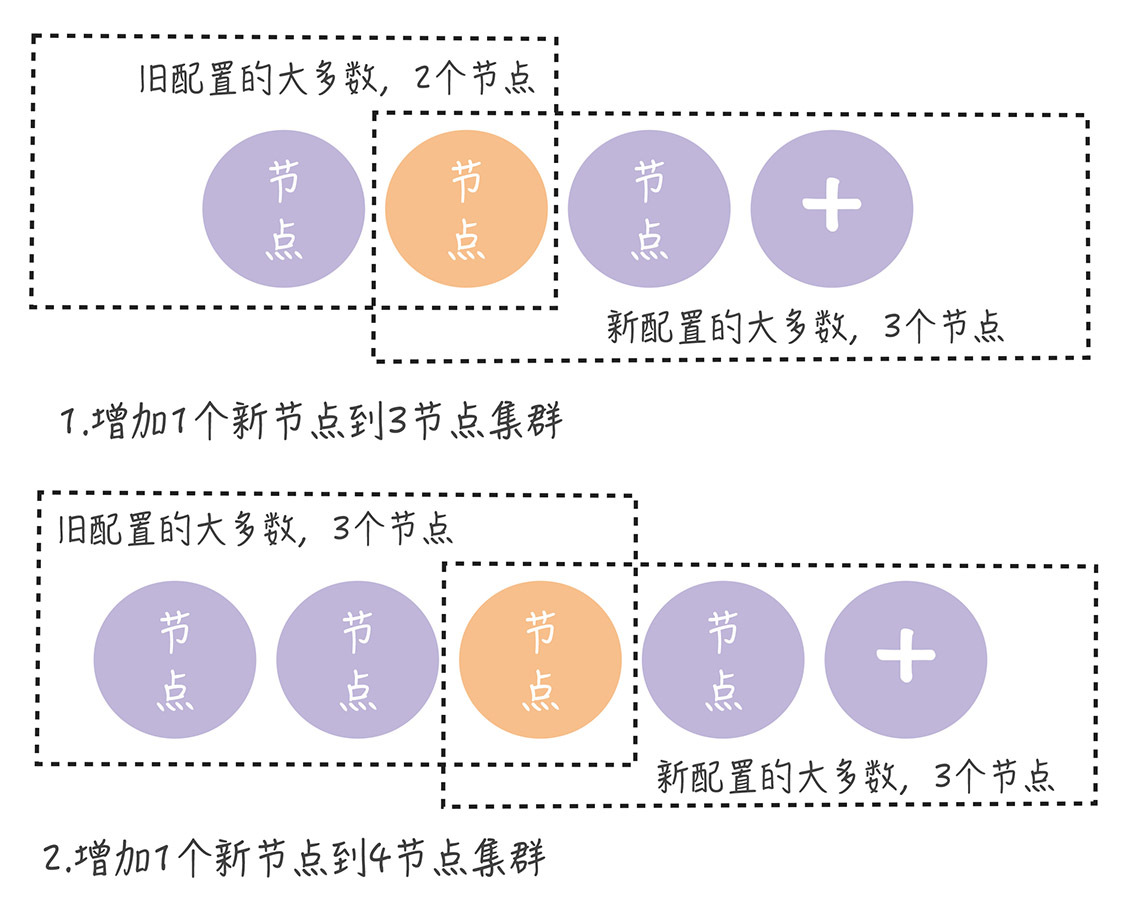
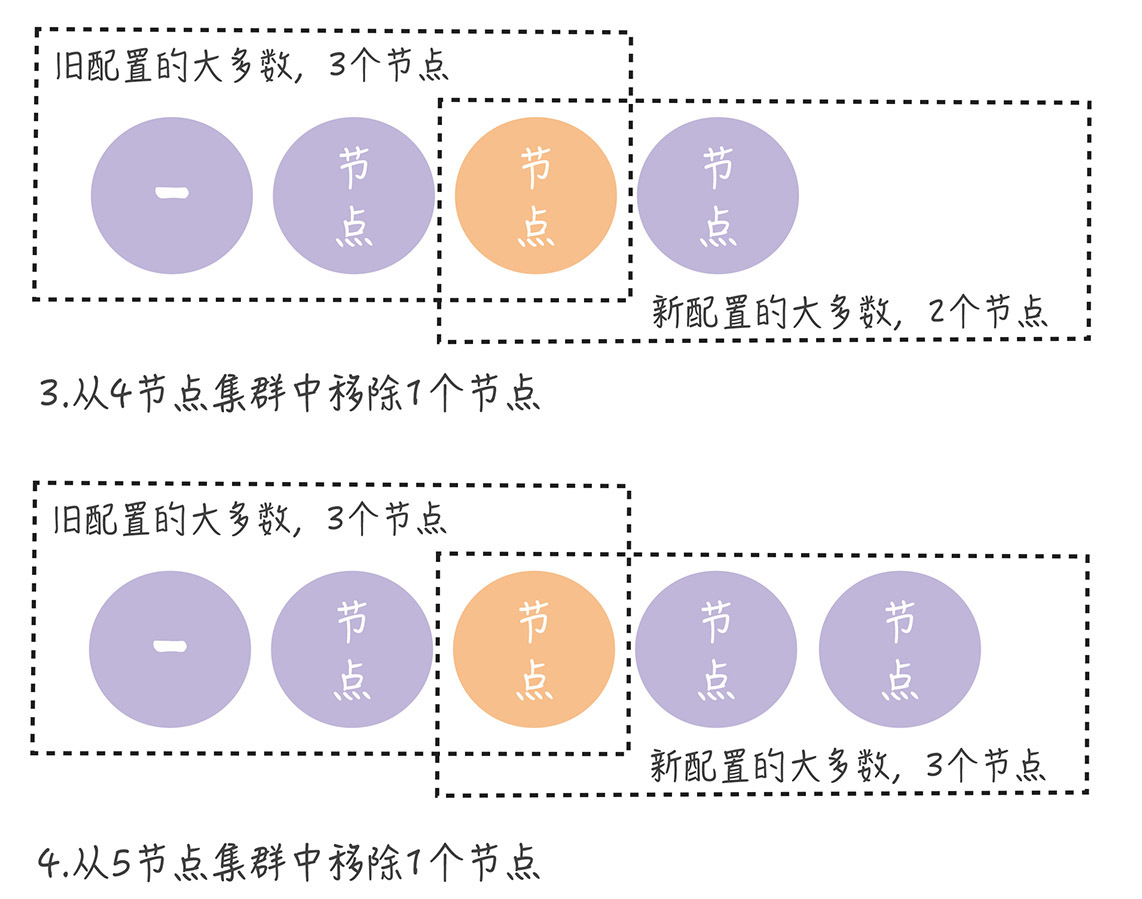
从上图中你可以看到,不管集群是偶数节点,还是奇数节点,不管是增加节点,还是移除节点,新旧配置的"大多数"都会存在重叠(图中的橙色节点)。
需要你注意的是,在分区错误、节点故障等情况下,如果我们并发执行单节点变更,那么就可能出现一次单节点变更尚未完成,新的单节点变更又在执行,导致集群出现2个领导者的情况。
如果你遇到这种情况,可以在领导者启动时,创建一个NO_OP日志项(也就是空日志项),只有当领导者将NO_OP日志项应用后,再执行成员变更请求。这个解决办法,你记住就可以了。具体的实现,可参考Hashicorp Raft的源码,也就是runLeader()函数中:
noop := &logFuture{
log: Log{
Type: LogNoop,
},
}
r.dispatchLogs([]*logFuture{noop})一致性哈希
Raft存在的潜在问题:领导者模型简化了算法实现和共识协商,但写请求只能限制在领导者节点上处理,导致了集群的接入性能约等于单机。
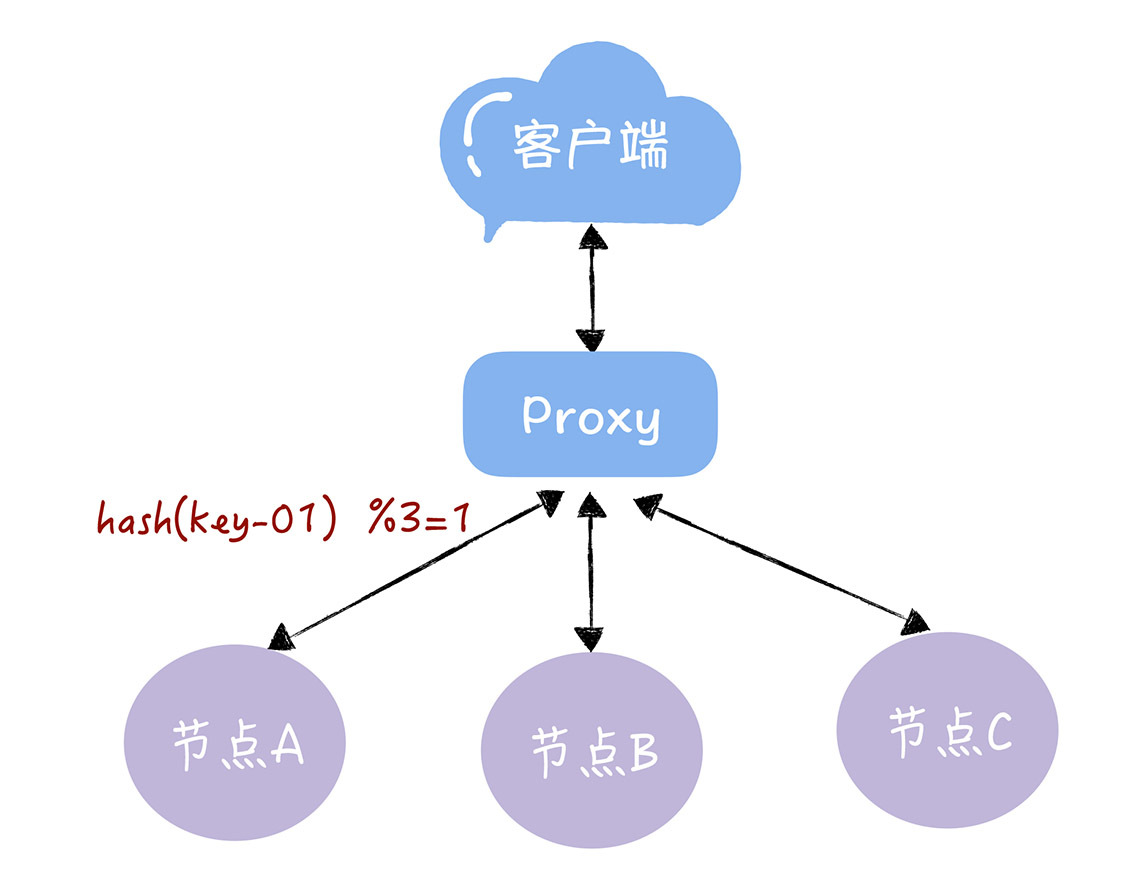
解决方案:通过分集群,加个Proxy层,然后由Proxy层处理来自客户端的读写请求,接收到读写请求后,通过对Key做哈希找到对应的集群就可以。
又遇到的问题:当需要变更集群数时(比如从2个集群扩展为3个集群),这时大部分的数据都需要迁移,重新映射,数据的迁移成本是非常高。
解决方案:一致哈希(Consistent Hashing)。
示例:查询key是key-01,计算公式为hash(key-01) % 3 ,经过计算寻址到了编号为1的服务器节点A。
假如3个节点不能满足业务需要了,这时我们增加了一个节点,节点的数量从3变化为4,那么之前的hash(key-01) % 3 = 1,就变成了hash(key-01) % 4 = X。
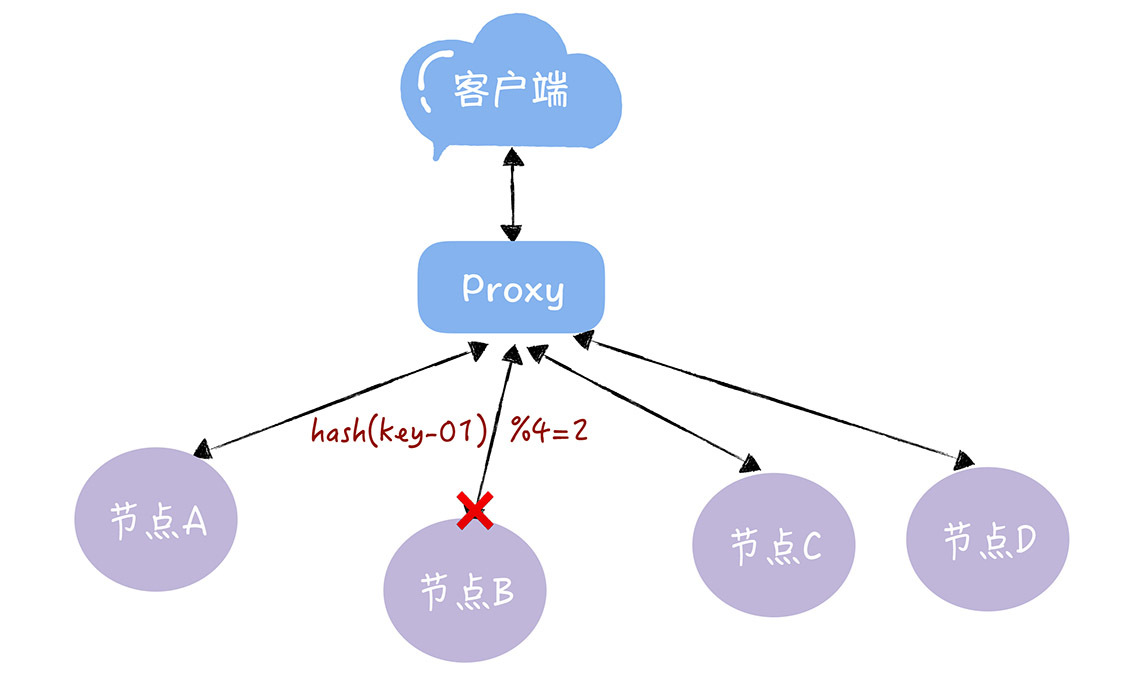
这个时候,我们需要迁移数据,基于新的计算公式hash(key-01) % 4 ,来重新对数据和节点做映射。需要注意的是,数据的迁移成本是非常高的。
再看看一致哈希实现哈希寻址。
与哈希算法不同的是,哈希算法是对节点的数量进行取模运算,而一致哈希算法是对2^32进行取模运算。一致哈希算法,将整个哈希值空间组织成一个虚拟的圆环,也就是哈希环:
当需要对指定key的值进行读写的时候,通过下面2步进行寻址:
- 将key作为参数执行c-hash()计算哈希值,并
确定此key在环上的位置; - 从这个位置沿着哈希环顺时针"行走",
遇到的第一节点就是key对应的节点。
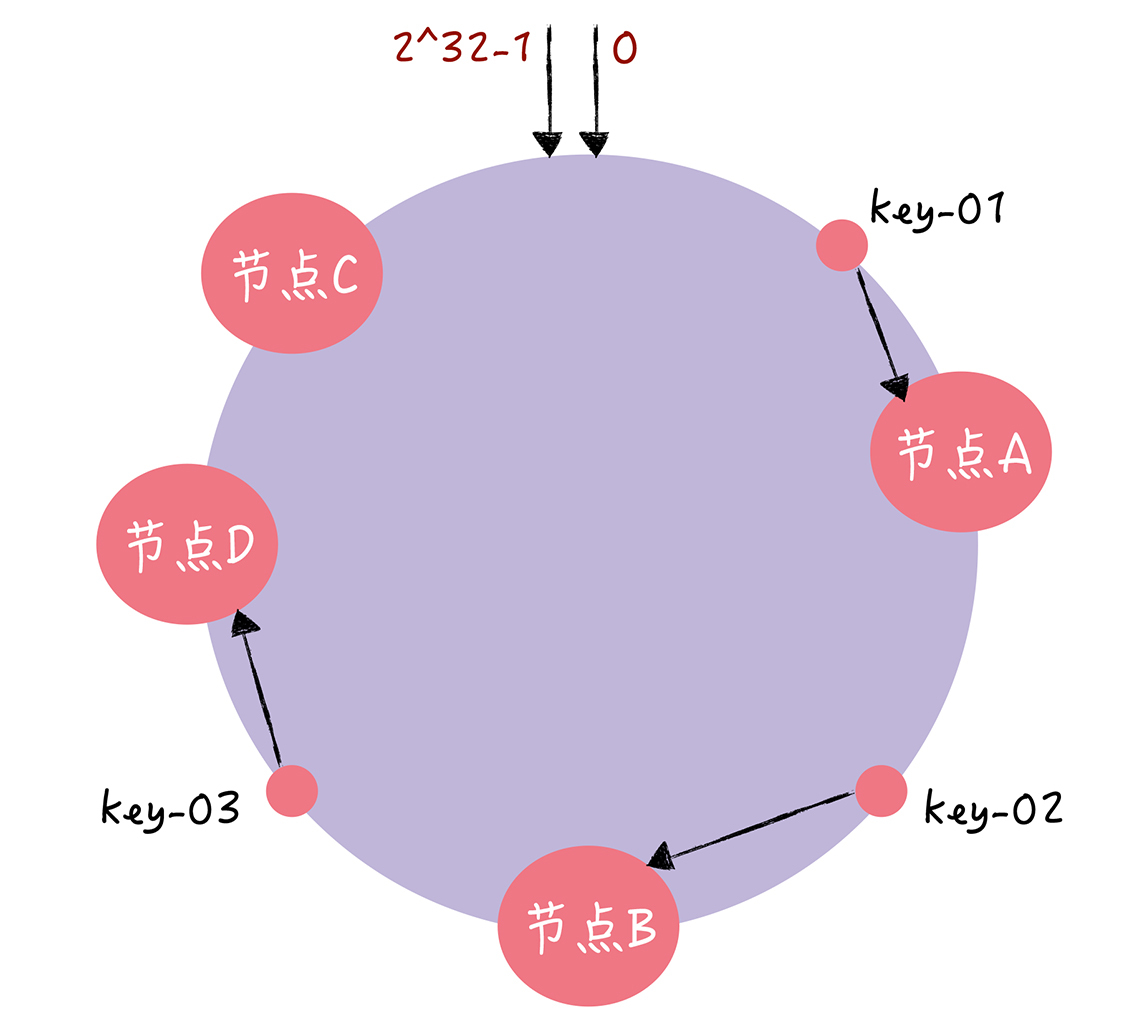
!在这里插入图片描述(https://i-blog.csdnimg.cn/direct/96bd133e03fc4828987bff43c8d4f6c7.png# pic_center)
假设有一个节点key-03故障,key-01和key-02不会受到影响,只有key-03的寻址被重定位到A。 => 在一致哈希算法中,如果某个节点宕机不可用了,那么受影响的数据仅仅是,会寻址到此节点和前一节点之间的数据。
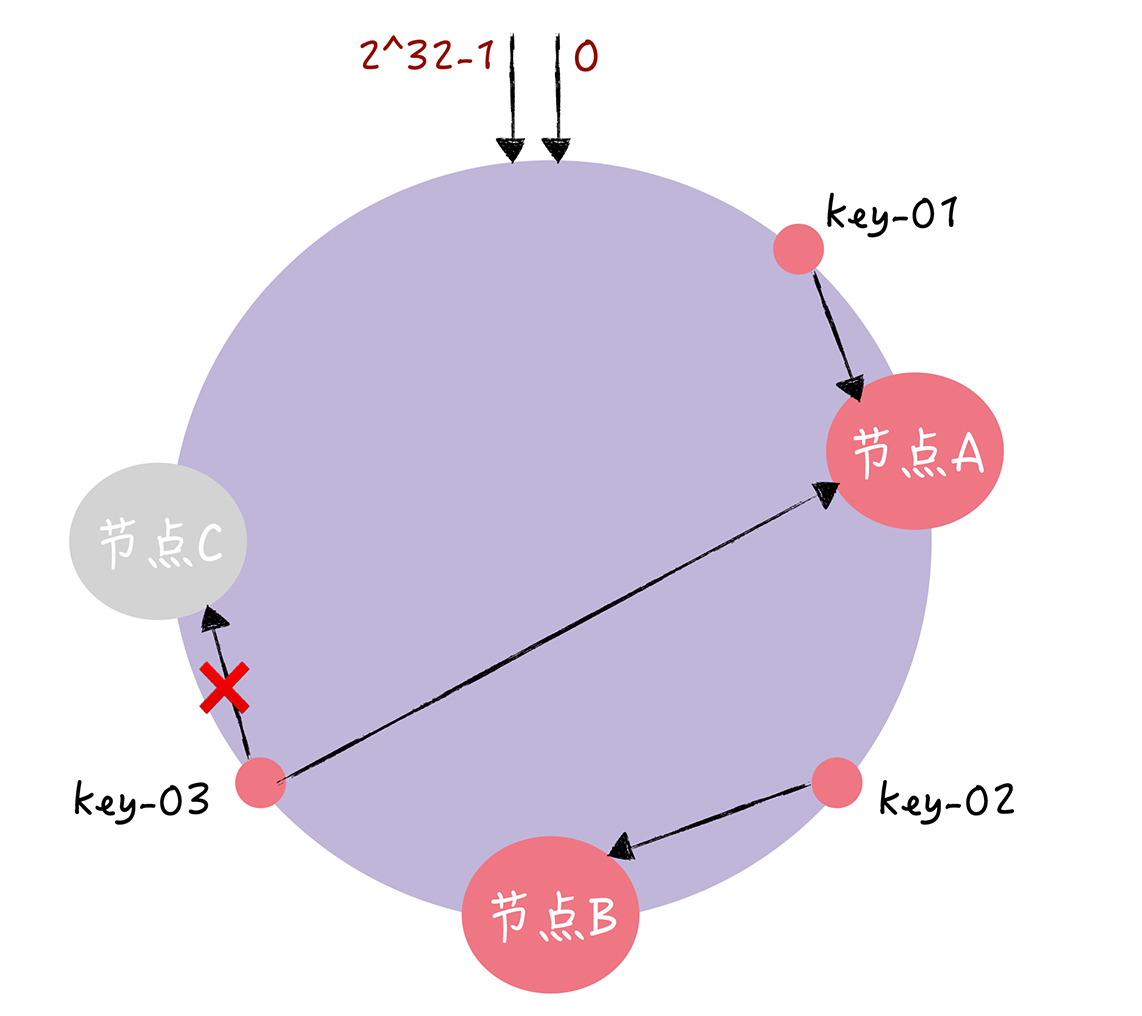
需要扩容一个节点(也就是增加一个节点,比如D),key-01、key-02不受影响,只有key-03的寻址被重定位到新节点D。 => 在一致哈希算法中,如果增加一个节点,受影响的数据仅仅是,会寻址到新节点和前一节点之间的数据,其它数据也不会受到影响。
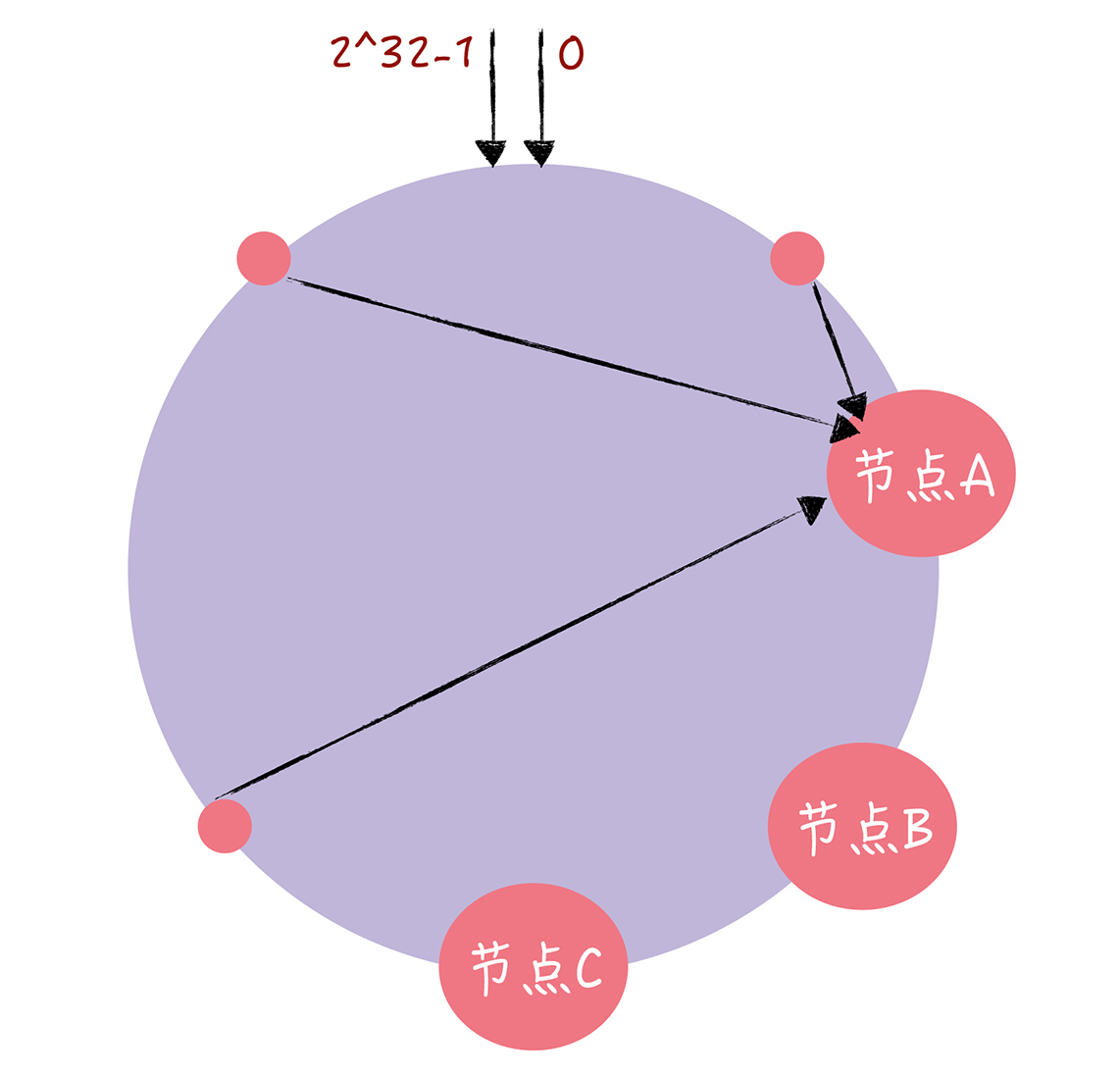
还可能存在的问题: 客户端访问请求集中在少数的节点上,出现了有些机器高负载,有些机器低负载的情况,需要让数据访问分布的比较均匀。
解决方案:虚拟节点。
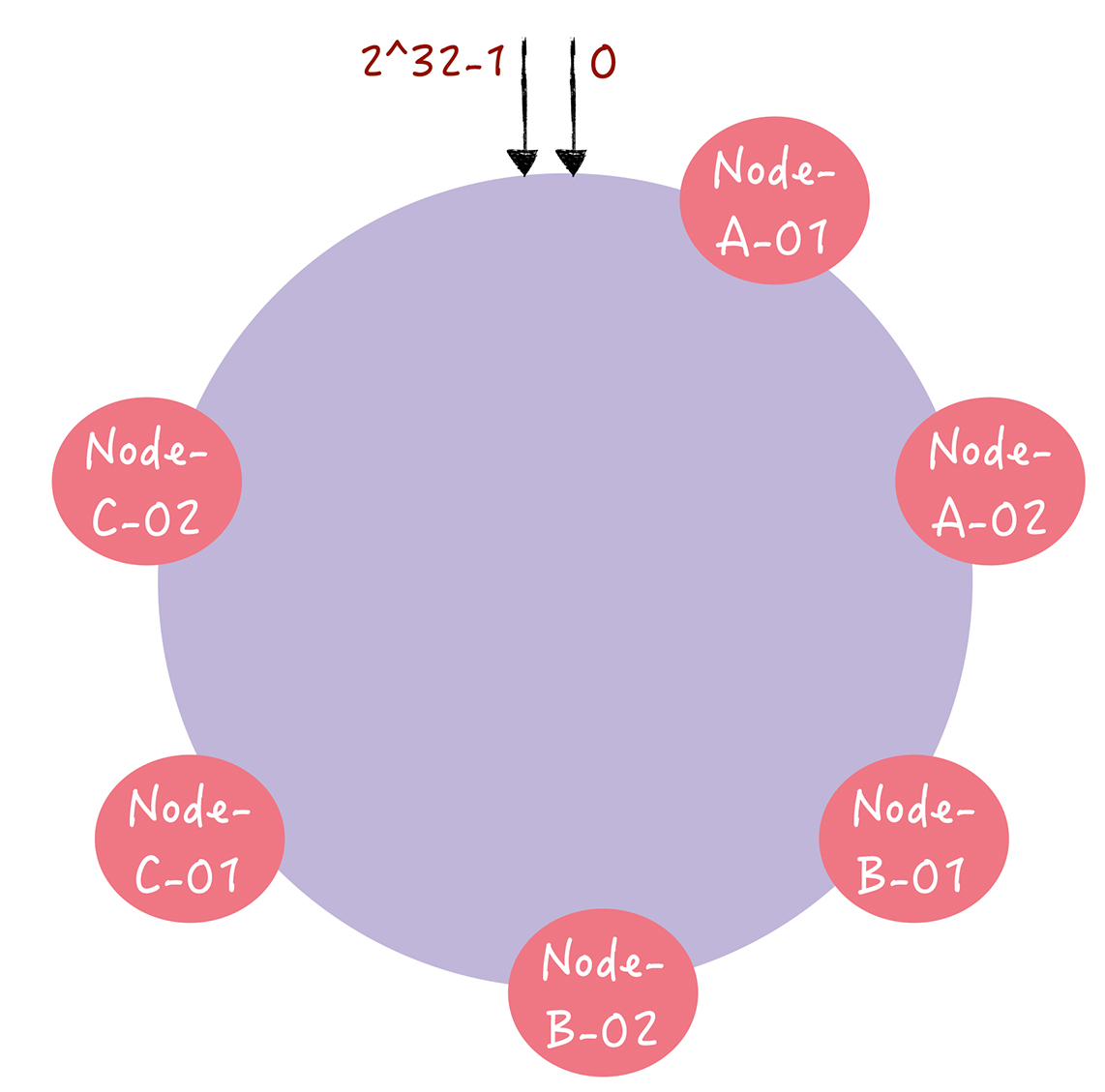
Gossip协议
Gossip协议,顾名思义,就像流言蜚语一样,利用一种随机、带有传染性的方式,将信息传播到整个网络中,并在一定时间内,使得系统内的所有节点数据一致。
Gossip的三板斧分别是:直接邮寄(Direct Mail)、反熵(Anti-entropy)和谣言传播(Rumor mongering)。
- 直接邮寄:就是
直接发送更新数据,当数据发送失败时,将数据缓存下来,然后重传。不过直接邮寄虽然实现起来比较容易,数据同步也很及时,但可能会因为缓存队列满了而丢数据。也就是说,只采用直接邮寄是无法实现最终一致性的。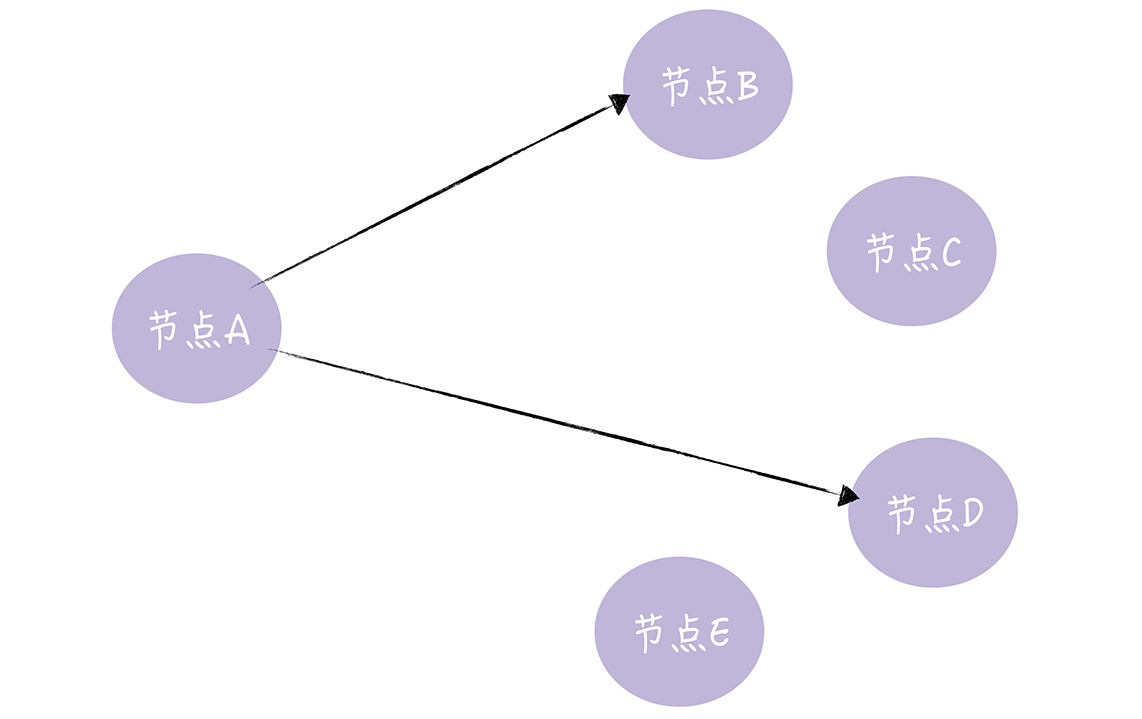
- 反熵:反熵中的熵是指混乱程度,反熵就是指消除不同节点中数据的差异,提升节点间数据的相似度,降低熵值。也就是说,集群中的节点,
每隔段时间就随机选择某个其他节点,然后通过互相交换自己的所有数据来消除两者之间的差异,实现数据的最终一致性。它其实是一种通过异步修复实现最终一致性的方法。节点A通过反熵的方式,修复了节点D中缺失的数据。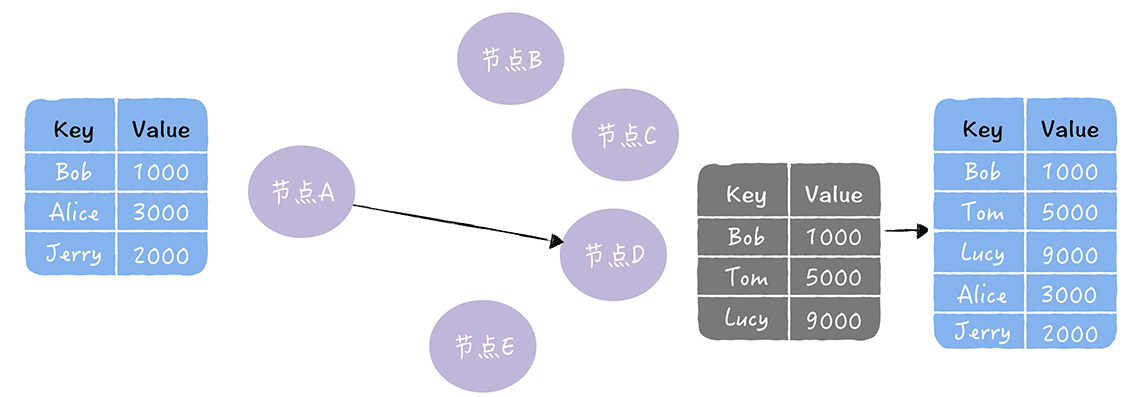
- 存在的问题:反熵
需要节点两两交换和比对自己所有的数据,执行反熵时通讯成本会很高。执行反熵时,相关的节点都是已知的,而且节点数量不能太多,如果是一个动态变化或节点数比较多的分布式环境(比如在DevOps环境中检测节点故障,并动态维护集群节点状态),这时反熵就不适用了。 - 推:将自己的所有副本数据,推给对方,修复对方副本中的熵。
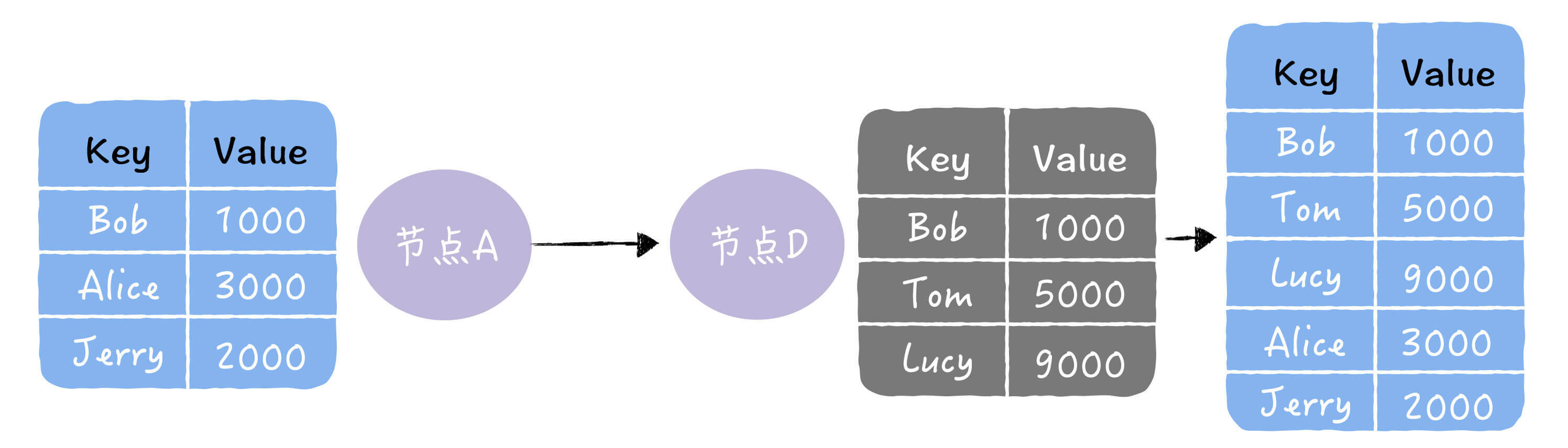
- 拉:拉取对方的所有副本数据,修复自己副本中的熵。
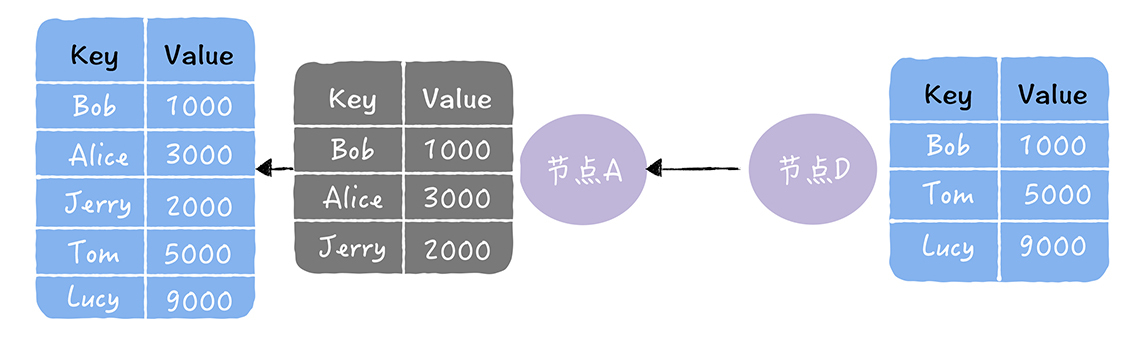
- 存在的问题:反熵
- 谣言传播:
广泛地散播谣言,它指的是当一个节点有了新数据后,这个节点变成活跃状态,并周期性地联系其他节点向其发送新数据,直到所有的节点都存储了该新数据。如图:节点A向节点B、D发送新数据,节点B收到新数据后,变成活跃节点,然后节点B向节点C、D发送新数据。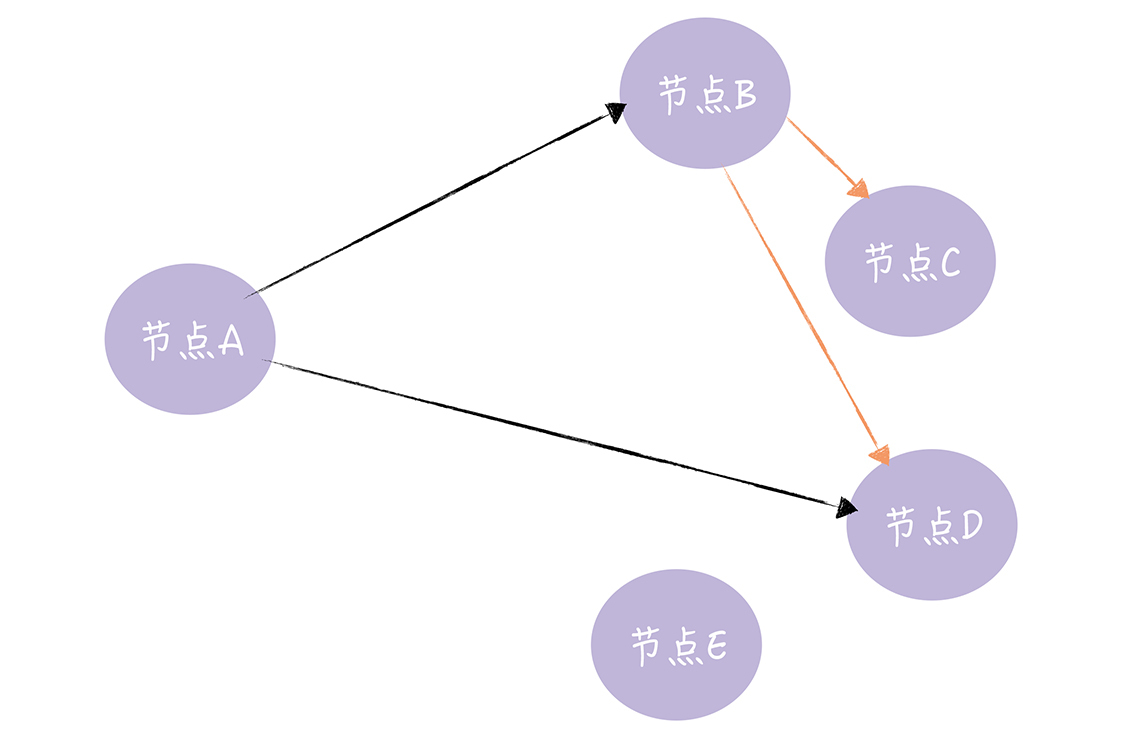
案例:使用Anti-entropy实现最终一致。
在分布式存储系统中,实现数据副本最终一致性,最常用的方法就是反熵了。我们在自研的InfluxDB中通过反熵实现数据副本最终一致性。
在自研InfluxDB中,一份数据副本是由多个分片组成的,也就是实现了数据分片,三节点三副本的集群,就像下图的样子:
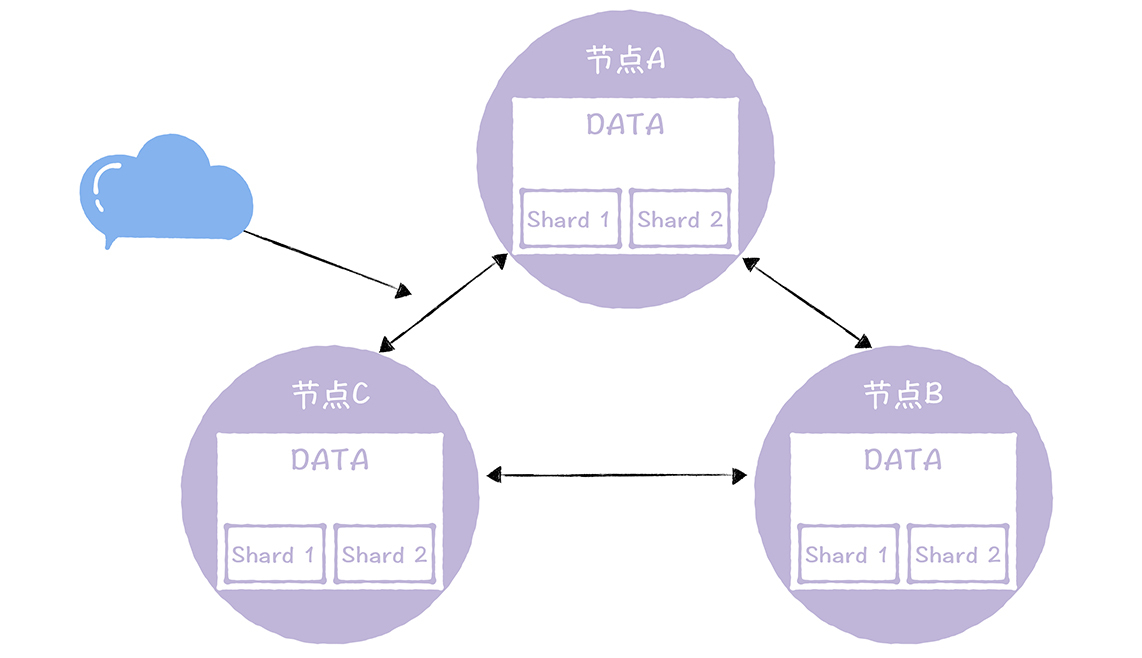
反熵的目标是确保每个DATA节点拥有元信息指定的分片,而且不同节点上,同一分片组中的分片都没有差异。比如说,节点A要拥有分片Shard1和Shard2,而且,节点A的Shard1和Shard2,与节点B、C中的Shard1和Shard2,是一样的。
我们将数据缺失,分为这样2种情况。
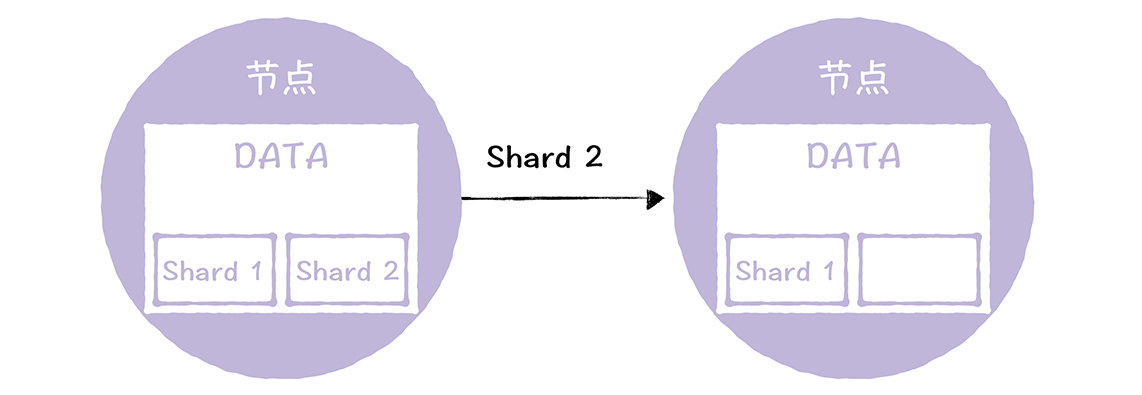
- 缺失分片:也就是说,在某个节点上整个分片都丢失了。解决方案就是将分片数据,通过RPC通讯,从其他节点上拷贝过来就可以了。
- 节点之间的分片不一致:也就是说,节点上分片都存在,但里面的数据不一样,有数据丢失的情况发生。解决方案就是需要设计一个闭环的流程,按照一个顺序修复,执行完流程后,也就是实现了一致性了。具体:
按照一定顺序来修复节点的数据差异,先随机选择一个节点,然后循环修复,每个节点生成自己节点有、下一个节点没有的差异数据,发送给下一个节点,进行修复(为了方便演示,假设Shard1、Shard2在各节点上是不一致的)。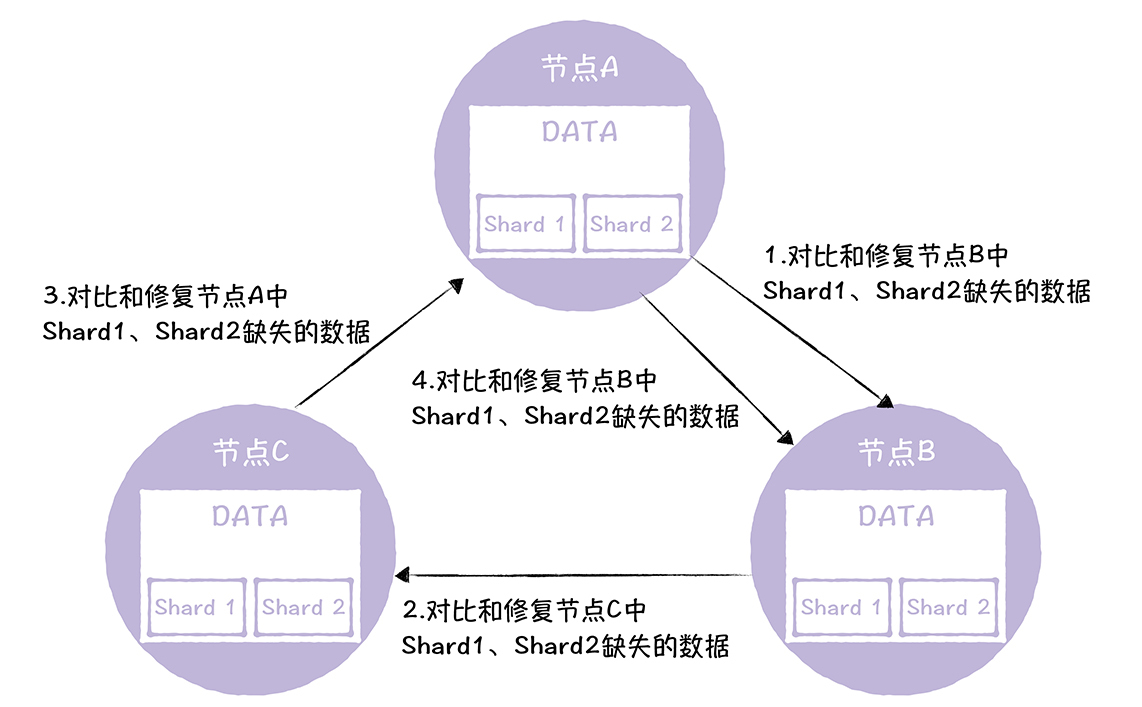
Quorum NWR算法
-
N:副本数,又叫做复制因子(Replication Factor)。也就是说,N表示
集群中同一份数据有多少个副本,就像下图的样子:
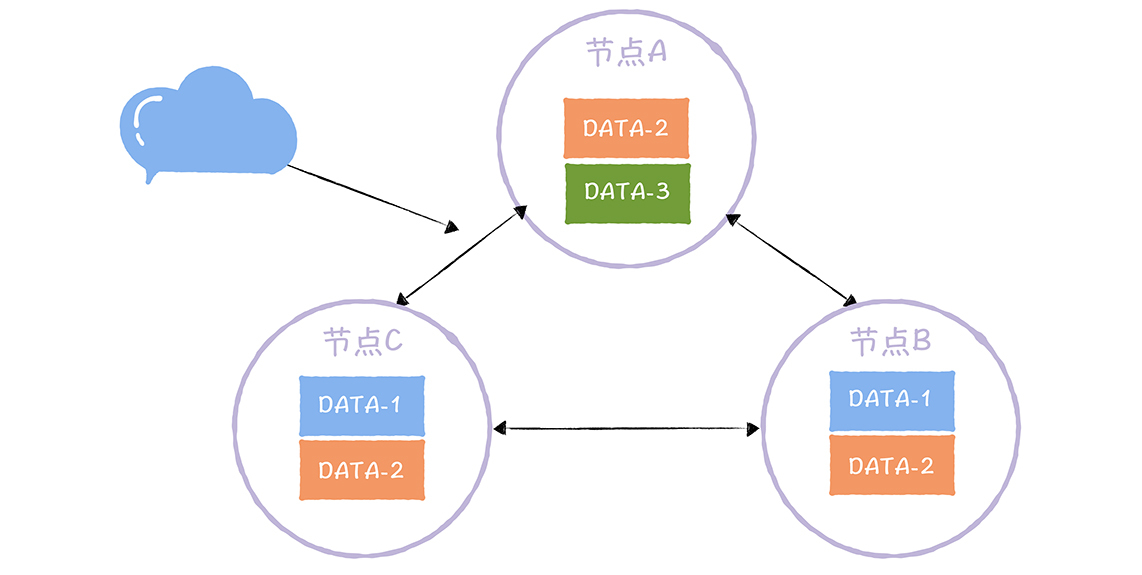 在这个三节点的集群中,DATA-1有2个副本,DATA-2有3个副本,DATA-3有1个副本。
在这个三节点的集群中,DATA-1有2个副本,DATA-2有3个副本,DATA-3有1个副本。 -
W:写一致性级别(Write Consistency Level),表示
成功完成W个副本更新,才完成写操作。一般而言,不推荐副本数超过当前的节点数,因为当副本数据超过节点数时,就会出现同一个节点存在多个副本的情况。当这个节点故障时,上面的多个副本就都受到影响了。
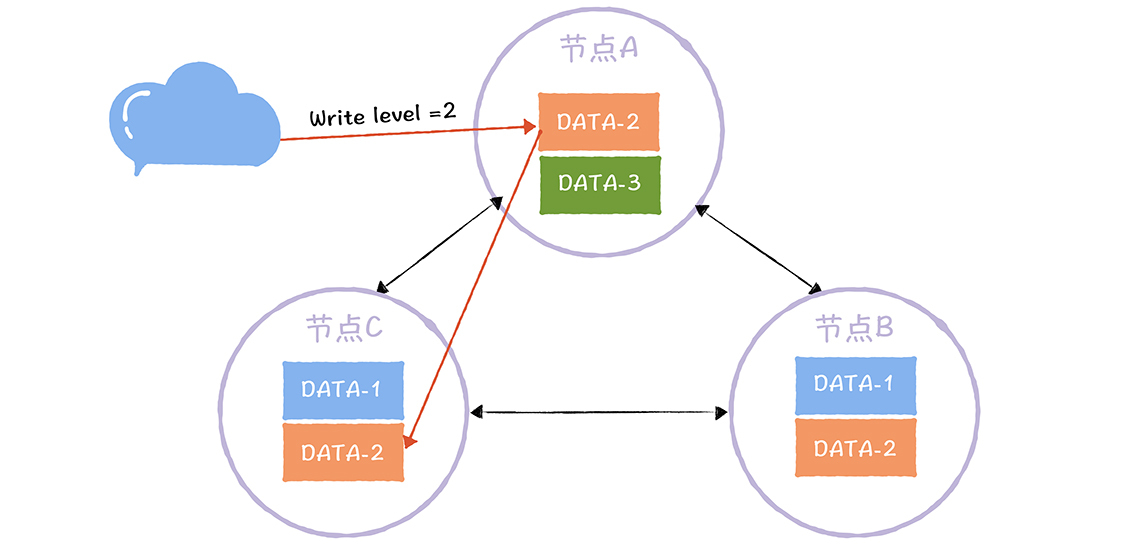
DATA-2的写副本数为2,也就说,对DATA-2执行写操作时,完成了2个副本的更新(比如节点A、C),才完成写操作。
-
R:读一致性级别(Read Consistency Level),表示读取一个数据对象时需要读R个副本。读取指定数据时,
要读R副本,然后返回R个副本中最新的那份数据。
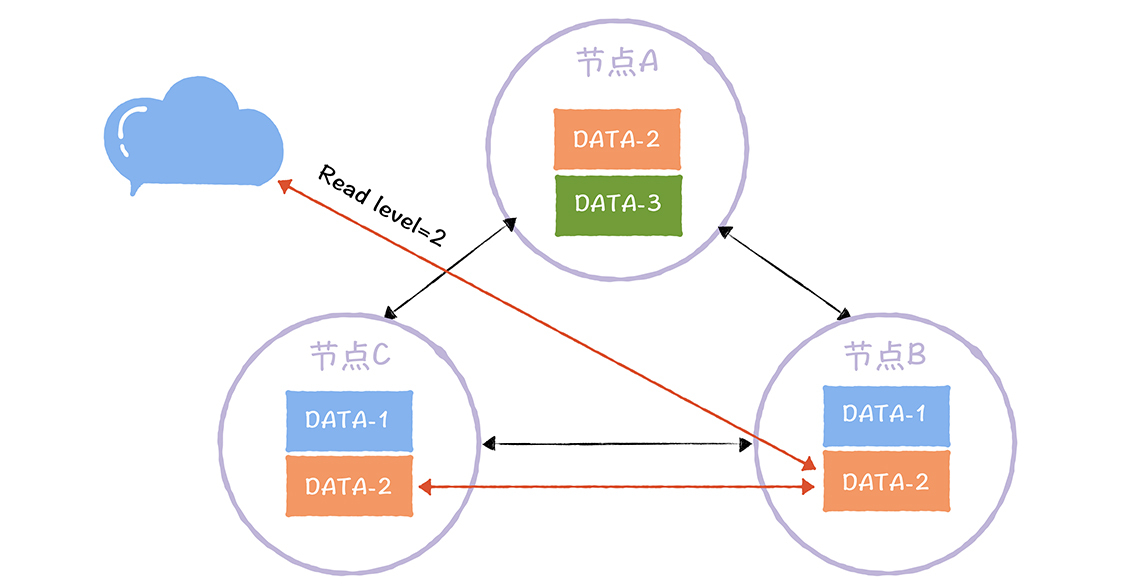
DATA-2的读副本数为2。也就是说,客户端读取DATA-2的数据时,需要读取2个副本中的数据,然后返回最新的那份数据。
最终效果:
- 当W + R > N的时候,对于客户端来讲,整个系统能保证强一致性,一定能返回更新后的那份数据。
- 当W + R <= N的时候,对于客户端来讲,整个系统只能保证最终一致性,可能会返回旧数据。
PBFT算法
口信消息型拜占庭问题之解的局限:如果将军数为n、叛将数为 f,那么算法需要递归协商 f+1轮,消息复杂度为O(n ^ (f + 1)),消息数量指数级暴增。这个算法存在"理论化"和"消息数指数级暴增"的痛点。
PBFT算法是通过签名(或消息认证码MAC)约束恶意节点的行为,采用三阶段协议,基于大多数原则达成共识的。另外,与口信消息型拜占庭问题之解(以及签名消息型拜占庭问题之解)不同的是,PBFT算法实现的是一系列值的共识,而不是单值的共识。
举例:假设苏秦制定的作战指令是进攻,而楚是叛徒。【所有的消息都是签名消息,也就是说,消息发送者的身份和消息内容都是无法伪造和篡改的,也就是说楚无法伪造一个假装来自赵的消息。】
(1)苏秦联系赵,向赵发送包含作战指令"进攻"的请求

(2)赵接收到苏秦的请求之后,会执行三阶段协议(Three-phase protocol)
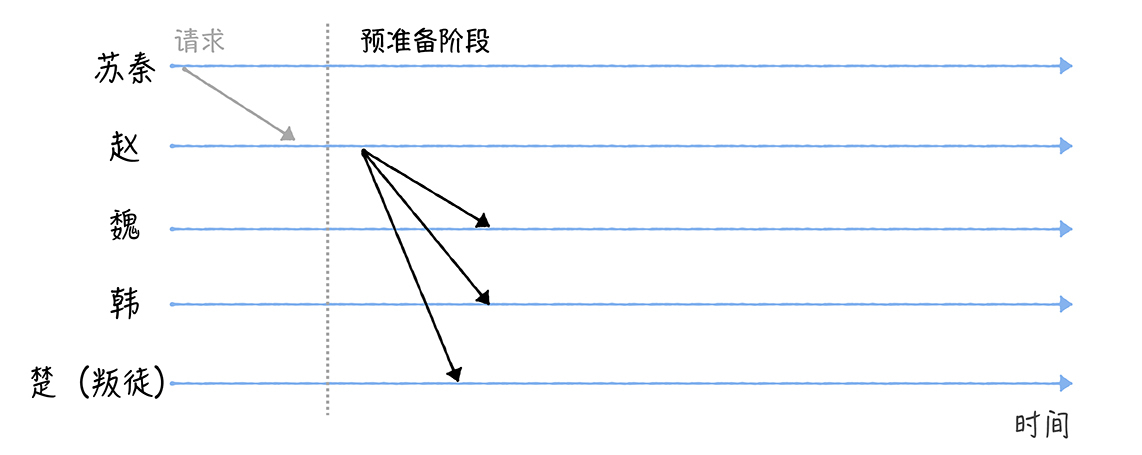
(2-1)赵将进入预准备(Pre-prepare)阶段,构造包含作战指令的预准备消息,并广播给其他将军(魏、韩、楚)。
(2-2)魏、韩、楚,收到消息后,不能确认自己接收到指令和其他人接收到的指令是相同的,所以不能直接执行指令。接收到预准备消息之后,魏、韩、楚将进入准备(Prepare)阶段,并分别广播包含作战指令的准备消息给其他将军。
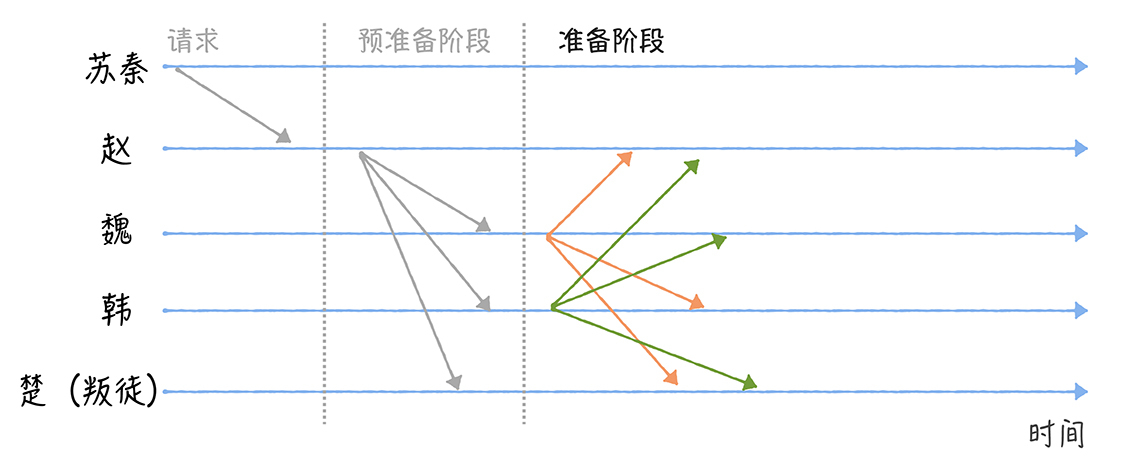
(2-3)因为魏不能确认赵、韩、楚是否收到了2f 个一致的包含作战指令的准备消息。也就是说,魏这时无法确认赵、韩、楚是否准备好了执行作战指令。所以进入提交阶段后,各将军分别广播提交消息给其他将军,也就是告诉其他将军,我已经准备好了,可以执行指令了。
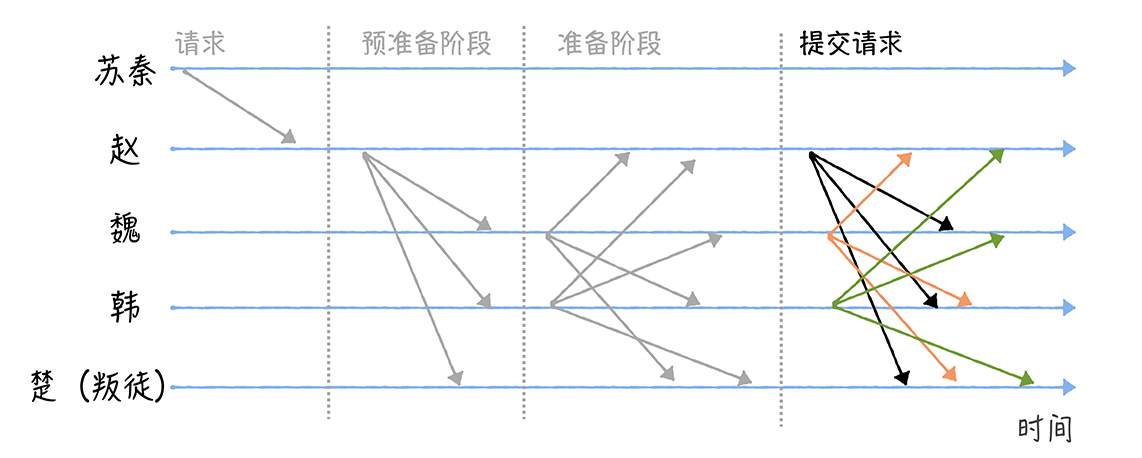
(3)当某个将军收到2f + 1个验证通过的提交消息后(包括自己,其中f为叛徒数,在我的演示中为1),也就是说,大部分的将军们已经达成共识,这时可以执行作战指令了,那么该将军将执行苏秦的作战指令,执行完毕后发送执行成功的消息给苏秦。
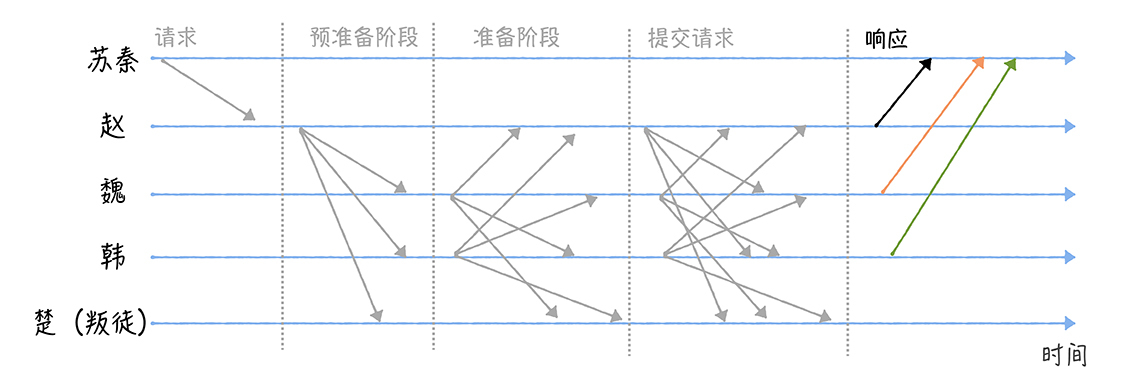
最后,当苏秦收到f+1个相同的响应(Reply)消息时,说明各位将军们已经就作战指令达成了共识,并执行了作战指令(其中f为叛徒数,在我的演示中为1)。
PoW算法
存在的问题:口信消息型拜占庭问题之解、PBFT算法虽然能防止坏人作恶,但只能防止少数的坏人作恶,也就是(n - 1) / 3个坏人 (其中n为节点数)。但是坏人可以不断增加节点数,轻松突破(n - 1) / 3的限制。
工作量证明
工作量证明(Proof Of Work,简称PoW):就是一份证明,用来确认你做过一定量的工作。比如,你的大学毕业证书就是一份工作量证明,证明你通过4年的努力完成了相关课程的学习。
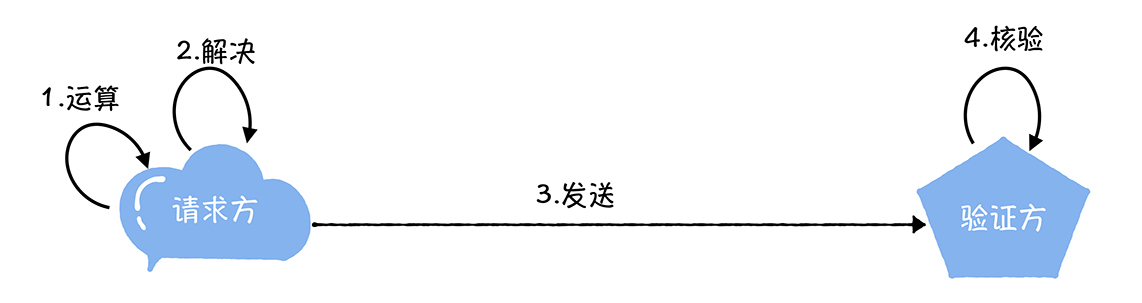
这个算法具有不对称性,也就是说,工作对于请求方是有难度的,对于验证方则是比较简单的,易于验证的。
区块链
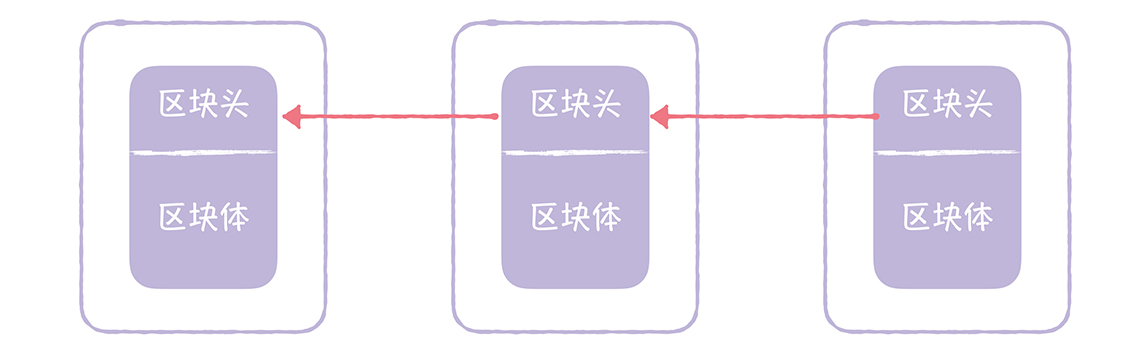
区块链的区块,是由区块头、区块体2部分组成的。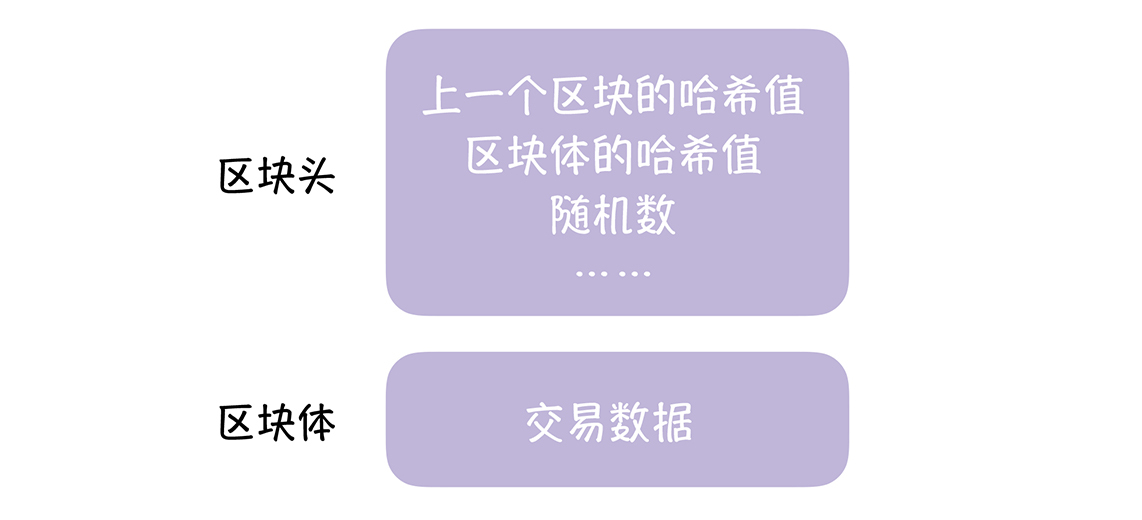
- 区块头(Block Head):区块头主要由
上一个区块的哈希值、区块体的哈希值、4字节的随机数(nonce)等组成的。 - 区块体(Block Body):区块包含的交易数据,其中的第一笔交易是
Coinbase交易,这是一笔激励矿工的特殊交易。
在区块链中是通过对区块头执行SHA256哈希运算,得到小于目标值的哈希值,来证明自己的工作量的。
计算出符合条件的哈希值后,矿工就会把这个信息广播给集群中所有其他节点,其他节点验证通过后,会将这个区块加入到自己的区块链中,最终形成一串区块链,就像下图的样子:
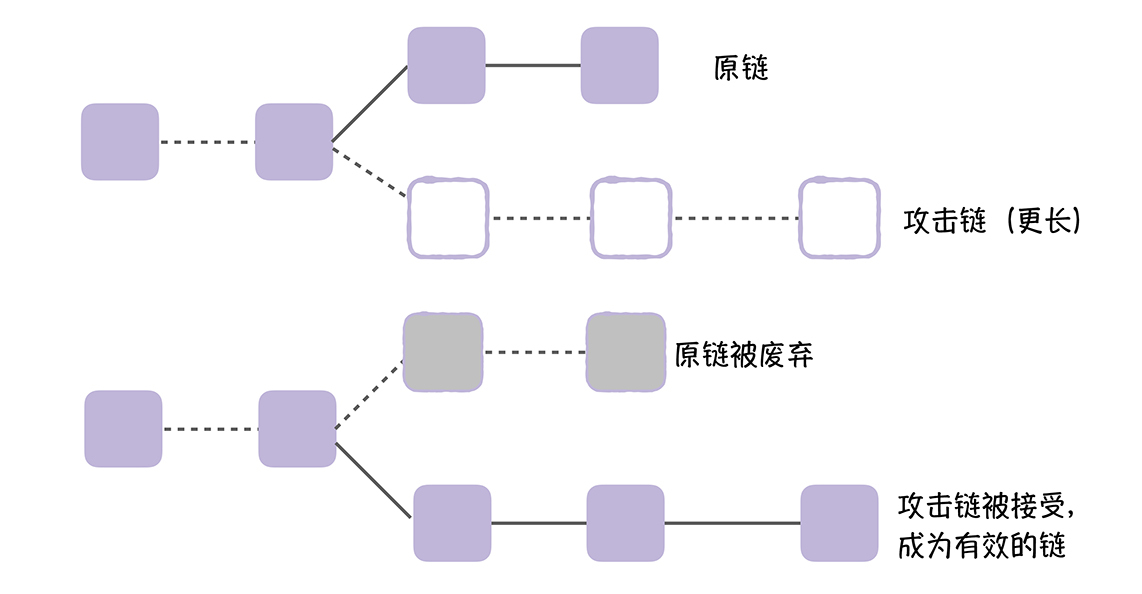
算力越强,系统大概率会越先计算出这个哈希值。这也就意味着,如果坏人们掌握了51%的算力,就可以发起51%攻击,比如,实现双花(Double Spending),也就是说,同一份钱花2次。
攻击者掌握了较多的算力,能挖掘一条比原链更长的攻击链,并将攻击链向全网广播,这时呢,按照约定,节点将接受更长的链,也就是攻击链,丢弃原链。
ZAB协议
问题:Multi-Paxos无法保证操作的顺序性。因为Multi-Paxos虽然能保证达成共识后的值不再改变,但它不关心达成共识的值是什么。
举例说明:假设当前所有节点上的被选定指令,最大序号都为100,那么新提议的指令对应的序号就会是101。
(1)节点A是领导者,提案编号为1,提议了指令X、Y,对应的序号分别为101和102,但是因为网络故障,指令只成功复制到了节点A。
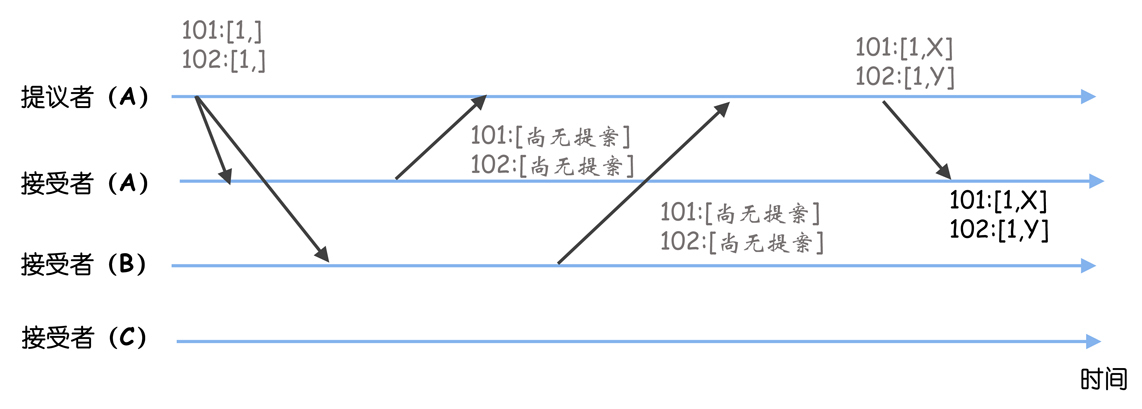
(2)这时节点A故障了,新当选的领导者为节点B。
(3)节点B当选领导者后,需要先作为学习者了解目前已被选定的指令。节点B学习之后,发现当前被选定指令的最大序号为100(因为节点A故障了,它被选定指令的最大序号102,无法被节点B发现),那么它可以从序号101开始提议新的指令。这时它接收到客户端请求,并提议了指令Z,指令Z被成功复制到节点B、C。
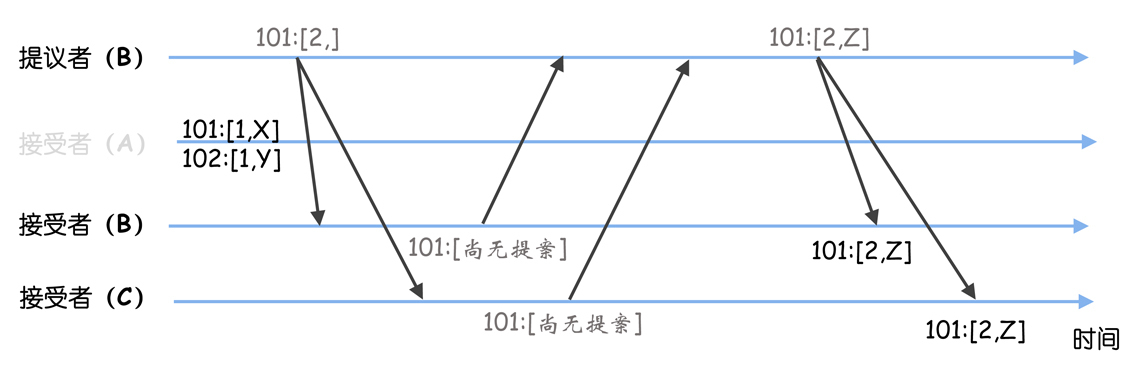
(4)节点B故障了,节点A恢复了。
(5)选举出领导者C后,节点B故障也恢复了。
(6)节点C当选领导者后,需要先作为学习者了解目前已被选定的指令,这时它执行Basic Paxos的准备阶段,就会发现之前选定的值(比如Z、Y),然后发送接受请求,最终在序号101、102处达成共识的指令是Z、Y。
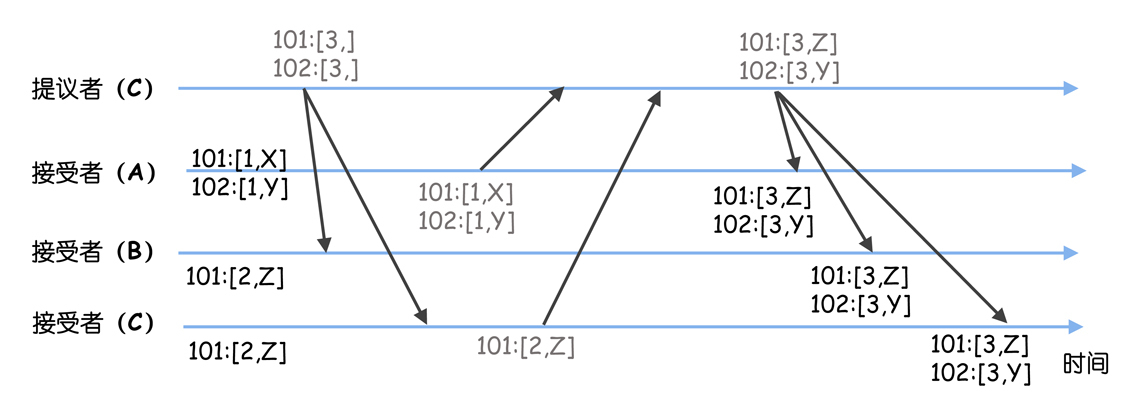
你可以看到,原本预期的指令是X、Y,最后变成了Z、Y。
ZAB协议的最核心设计目标:如何实现操作的顺序性。
举例:假设节点A为主节点,节点B、C为备份节点。【在ZAB中,写操作必须在主节点(比如节点A)上执行。如果客户端访问的节点是备份节点(比如节点B),它会将写请求转发给主节点。】
(1)当主节点接收到写请求后,它会基于写请求中的指令(也就是X,Y),来创建一个提案(Proposal),并使用一个唯一的ID(事务标识符,Transaction ID zxid)来标识这个提案。

其中,X、Y对应的事务标识符分别为<1, 1>和<1, 2>。
事务标识符是64位的long型变量,有任期编号epoch和计数器counter两部分组成,格式为<epoch, counter>,高32位为任期编号,低32位为计数器:
- 任期编号:创建提案时领导者的任期编号。当新领导者当选时,任期编号递增,计数器被设置为零。比如,前领导者的任期编号为1,那么新领导者对应的任期编号将为2。
- 计数器:具体标识提案的整数。每次领导者创建新的提案时,计数器将递增。比如,前一个提案对应的计数器值为1,那么新的提案对应的计数器值将为2。
这样设计的原因:事务标识符必须按照顺序、唯一标识一个提案,也就是说,事务标识符必须是唯一的、递增的。
(2)在创建完提案之后,主节点会基于TCP协议,并按照顺序将提案广播到其他节点。这样就能保证先发送的消息,会先被收到,保证了消息接收的顺序性。
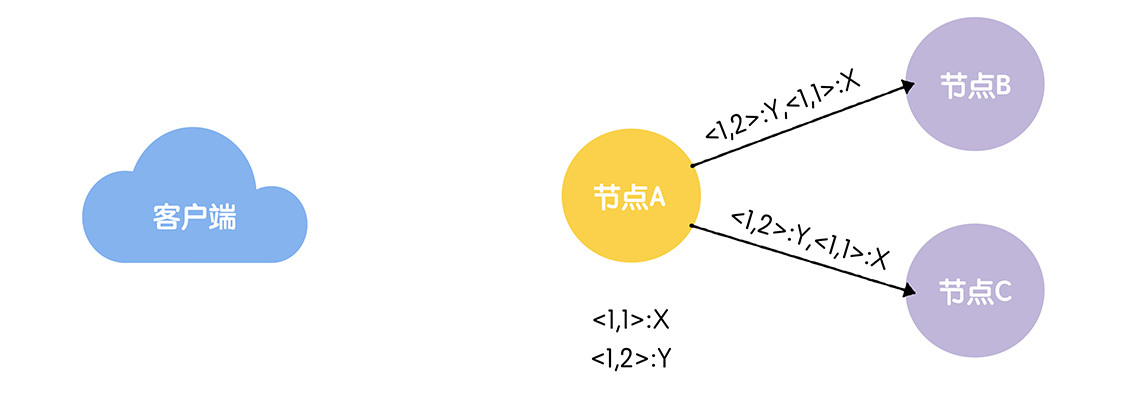
(3)当主节点接收到指定提案的"大多数"的确认响应后,该提案将处于提交状态(Committed),主节点会通知备份节点提交该提案。
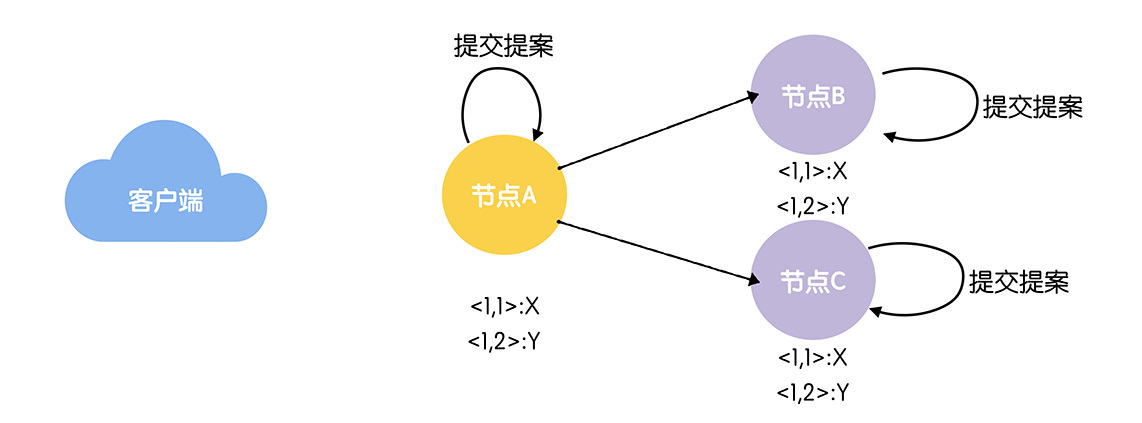
主节点提交提案是有顺序性的。主节点根据事务标识符大小,按照顺序提交提案,如果前一个提案未提交,此时主节点是不会提交后一个提案的。也就是说,指令X一定会在指令Y之前提交。
(4)主节点返回执行成功的响应给节点B,节点B再转发给客户端。
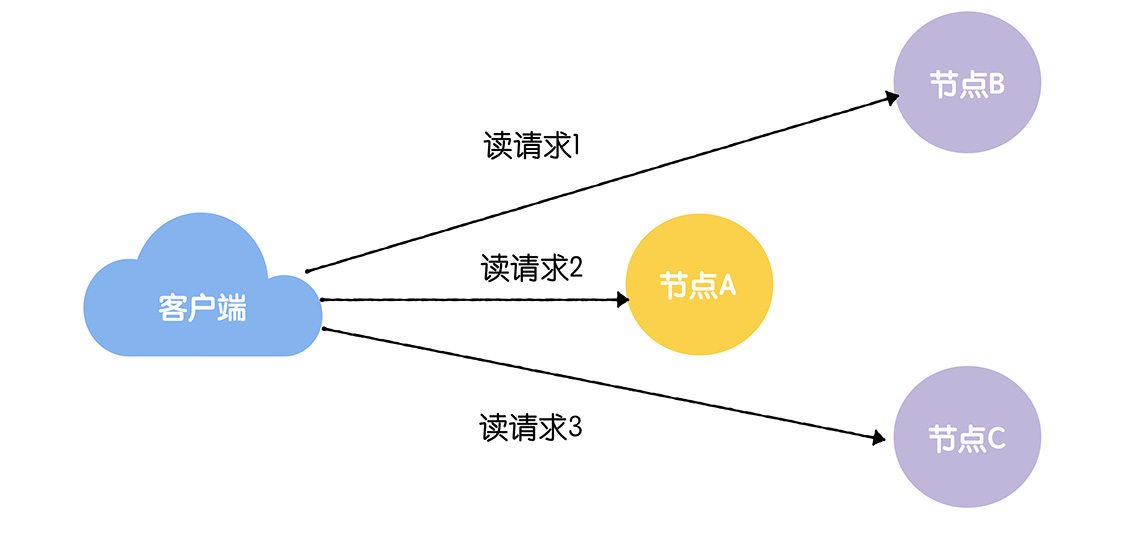
为了提升读并发能力,Zookeeper提供的是最终一致性,也就是读操作可以在任何节点上执行,客户端会读到旧数据。
如果客户端必须要读到最新数据,Zookeeper提供了一个解决办法,那就是sync命令。你可以在执行读操作前,先执行sync命令,这样客户端就能读到最新数据了。
往期精彩专栏内容,欢迎订阅:
🔗【八股消消乐】20250715:Redis过期时间机制设计
🔗【八股消消乐】20250712:Kafka集群 full GC 解决方案
🔗【八股消消乐】20250711:浅尝Kafka性能优化
🔗【八股消消乐】20250630:消息队列优化---重复消费
🔗【八股消消乐】20250629:消息队列优化---消息丢失
🔗【八股消消乐】20250627:消息队列优化---消息积压
🔗【八股消消乐】20250625:消息队列优化---消息有序
🔗【八股消消乐】20250624:消息队列优化---延迟消息
🔗【八股消消乐】20250623:消息队列优化---系统架构设计
🔗【八股消消乐】20250622:Elasticsearch查询优化
🔗【八股消消乐】20250620:Elasticsearch优化---检索Labubu
🔗【八股消消乐】20250619:构建微服务架构体系---保证服务高可用
🔗【八股消消乐】20250615:构建微服务架构体系---链路超时控制
🔗【八股消消乐】20250614:构建微服务架构体系---实现制作库与线上库分离
🔗【八股消消乐】20250612:构建微服务架构体系---限流算法优化
🔗【八股消消乐】20250611:构建微服务架构体系---降级策略全总结
🔗【八股消消乐】20250610:构建微服务架构体系---熔断恢复抖动优化
🔗【八股消消乐】20250609:构建微服务架构体系---负载均衡算法如何优化
🔗【八股消消乐】20250608:构建微服务架构体系---服务注册与发现
🔗【八股消消乐】20250607:MySQL存储引擎InnoDB知识点汇总
🔗【八股消消乐】20250606:MySQL参数优化大汇总
🔗【八股消消乐】20250605:端午节产生的消费数据,如何分表分库?
🔗【八股消消乐】20250604:如何解决SQL线上死锁事故
🔗【八股消消乐】20250603:索引失效与优化方法总结
🔗【八股消消乐】20250512:慢SQL优化手段总结
🔗【八股消消乐】20250511:项目中如何排查内存持续上升问题
🔗【八股消消乐】20250510:项目中如何优化JVM内存分配?
🔗【八股消消乐】20250509:你在项目中如何优化垃圾回收机制?
🔗【八股消消乐】20250508:Java编译优化技术在项目中的应用
🔗【八股消消乐】20250507:你了解JVM内存模型吗?
🔗【八股消消乐】20250506:你是如何设置线程池大小?
🔗【八股消消乐】20250430:十分钟带背Duubo中大厂经典面试题
🔗【八股消消乐】20250429:你是如何在项目场景中选取最优并发容器?
🔗【八股消消乐】20250428:你是项目中如何优化多线程上下文切换?
🔗【八股消消乐】20250427:发送请求有遇到服务不可用吗?如何解决?
📌 [ 笔者 ] 文艺倾年
📃 [ 更新 ] 2025.10.11
❌ [ 勘误 ] /* 暂无 */
📜 [ 声明 ] 由于作者水平有限,本文有错误和不准确之处在所难免,
本人也很想知道这些错误,恳望读者批评指正!