tuning
https://spark.apache.org/docs/latest/tuning.html
data-locality
https://spark.apache.org/docs/latest/tuning.html#data-locality
memory-management
https://spark.apache.org/docs/latest/tuning.html#memory-management-overview
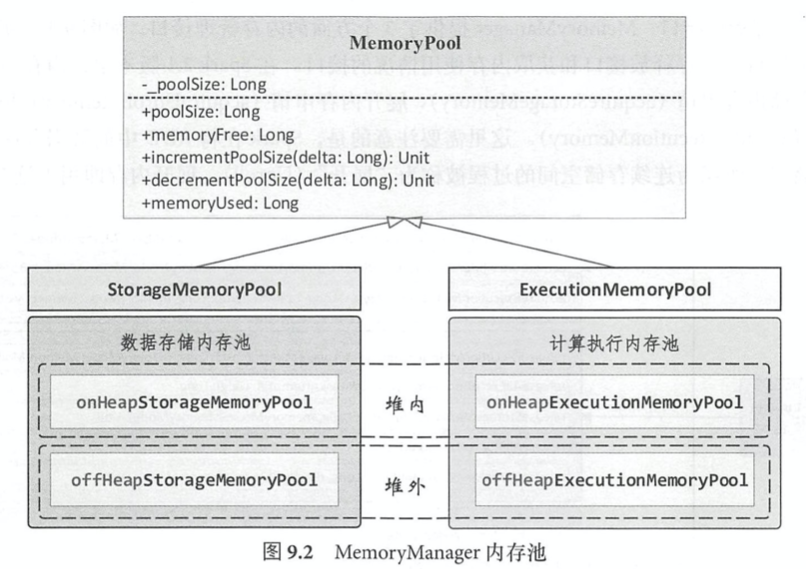
- Execution memory refers to that used for computation in shuffles, joins, sorts and aggregations,
- While storage memory refers to that used for caching and propagating internal data across the cluster.
https://linzebing.github.io/2020/10/30/spark-sql-9-memory.html