数据提取
- 安装beautifulsoup4
- 获取节点
- [元素查找 find_all( )/find()](#元素查找 find_all( )/find())
- [css选择器查找元素 select( )/select_one()](#css选择器查找元素 select( )/select_one())
- 案例:获取飞卢小说网的数据(https://b.faloo.com/l/0/1.html)
- 技巧:检测内容编码,然后自动解码
- 查找元素技巧
安装beautifulsoup4
pip install beautifulsoup4创建BeautifulSoup对象
from bs4 import BeautifulSoup
# 需要识别的html
html='''
<!doctype html>
<html lang="zh-CN">
<head>
<meta charset="utf-8" /> <meta name="viewport" content="width=device-width,initial-scale=1" /> <title>文章卡片示例</title>
</head>
<body>
<article class="card" aria-labelledby="post-title-1"> <img src="https://picsum.photos/800/450?random=1" alt="文章封面图"/>
<div class="card-body"> <div class="meta">作者:小明 · 2025-10-07</div> <h2 id="post-title-1" class="title">如何快速上手 Playwright:入门与实战</h2>
<p class="excerpt">本文带你从安装、基本 API 到常见反爬处理,逐步构建稳定的浏览器自动化脚本,并示例演示常用技巧和调试方法。</p>
<div class="actions"> <a class="btn" href="#read" id="read-more">阅读更多</a>
<button class="btn ghost" id="bookmark">收藏</button>
</div> </div> <div>1234567 </div> </article></body>
</html>
'''
# 创建BeautifulSoup对象
soup= BeautifulSoup(html,'lxml') 获取节点
-
获取标题(默认获取第一个)
print(soup.title.string)
-
获取body
print(soup.body)
-
获取div
print(soup.div)
-
获取标签名
获取title标签名
print(soup.title.name)
获取img标签名
print(soup.img.name)
-
获取属性
获取div的class属性
print(soup.div.attrs['class'])
获取img的src属性
print(soup.img.attrs['src'])
-
美化输出
print(soup.prettify())
-
children只遍历直接子节点for i in soup.div.children:
print(i) -
descendants遍历所有后代节点for i in soup.div.descendants:
print(i)结果
作者:小明 · 2025-10-07如何快速上手 Playwright:入门与实战
如何快速上手 Playwright:入门与实战本文带你从安装、基本 API 到常见反爬处理,逐步构建稳定的浏览器自动化脚本,并示例演示常用技巧和调试方法。
本文带你从安装、基本 API 到常见反爬处理,逐步构建稳定的浏览器自动化脚本,并示例演示常用技巧和调试方法。阅读更多
阅读更多
收藏 -
获取父节点
print(soup.article.parent)
-
获取同级节点
for i in soup.div.parent:
print(i)
元素查找 find_all( )/find()
初始化内容换一下
html='''
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8"> <title>HTML 查找练习</title>
</head>
<body>
<div id="outer"> <p>这是第一段文字</p>
<div class="inner"> <p>内层段落1 <span>文字A</span></p>
<p>内层段落2 <b>文字B</b></p>
<div>内层段落1</div>
</div> <p>这是第二段文字</p>
</div><div class="df">你很骄傲</div>
<p>内层段落1</p>
<p>内层段落3</p>
</body>
</html>
'''
soup=BeautifulSoup(html,'lxml')-
获取第一个后的兄弟节点
for div in soup.div.next_siblings:
print(div) -
获取所有div标签
for div in soup.find_all('div'):
print(div)
print() -
获取所有class属性为inner的div标签
方法一
for div in soup.find_all('div',class_='inner'):
print(div)
print()方法二
for div in soup.find_all('div',attrs={'class':'inner'}):
print(div)
print() -
获取所有包含"内层段落1"的标签
print(soup.find_all(string='内层段落1'))
css选择器查找元素 select( )/select_one()
| 类型 | 语法 | 示例 | 说明 |
|---|---|---|---|
| 通用选择器 | * |
soup.select('*') |
选择所有元素 |
| 标签选择器 | tag |
div, p, span |
按标签名选择元素 |
| 类选择器 | .classname |
.inner, .content |
按类名选择元素 |
| ID 选择器 | #idname |
#main, #title |
按元素 id 选择 |
| 属性选择器 | [attr] |
[href], [title] |
含有该属性的元素 |
| 属性=值 | [attr=value] |
[type=text], [lang=zh] |
属性等于指定值 |
| 属性包含值 | [attr~=value] |
[class~=inner] |
class 属性中含 value |
| 属性以值开头 | [attr^=value] |
[src^=https] |
属性以某值开头 |
| 属性以值结尾 | [attr$=value] |
[src$=.jpg] |
属性以某值结尾 |
| 属性包含子串 | [attr*=value] |
[href*=baidu] |
属性包含指定字符串 |
| 层级选择器(后代) | A B |
div p |
A 内部的所有 B 标签 |
| 直接子元素 | A > B |
div > p |
A 的直接子元素 B |
| 相邻兄弟 | A + B |
h1 + p |
紧接在 A 后的第一个 B |
| 通用兄弟 | A ~ B |
h1 ~ p |
A 之后的所有兄弟 B |
| 多重选择器 | A, B |
div, p |
同时选择多个标签 |
| 伪类:第一个子元素 | :first-child |
li:first-child |
第一个 li |
| 伪类:最后一个子元素 | :last-child |
li:last-child |
最后一个 li |
| 伪类:第 n 个 | :nth-child(n) |
li:nth-child(2) |
第 2 个 li |
| 伪类:奇偶数 | :nth-child(odd/even) |
li:nth-child(odd) |
奇/偶位置元素 |
| 伪类:否定选择 | :not(selector) |
div:not(.inner) |
排除某些元素 |
| 组合使用 | div.inner > p.note |
同时限制标签、类、层级 | |
| 子属性组合 | a[href^="http"][target="_blank"] |
同时匹配多个属性条件 |
-
使用CSS选择器
for div in soup.select('div'):
print(div)
print() -
层级标签用空格隔开
for div in soup.select('body div'):
print(div)
print() -
搜索body的div子标签
for div in soup.select('body>div'):
print(div)
print()
案例:获取飞卢小说网的数据(https://b.faloo.com/l/0/1.html)
这里搜索需要查看的小说名
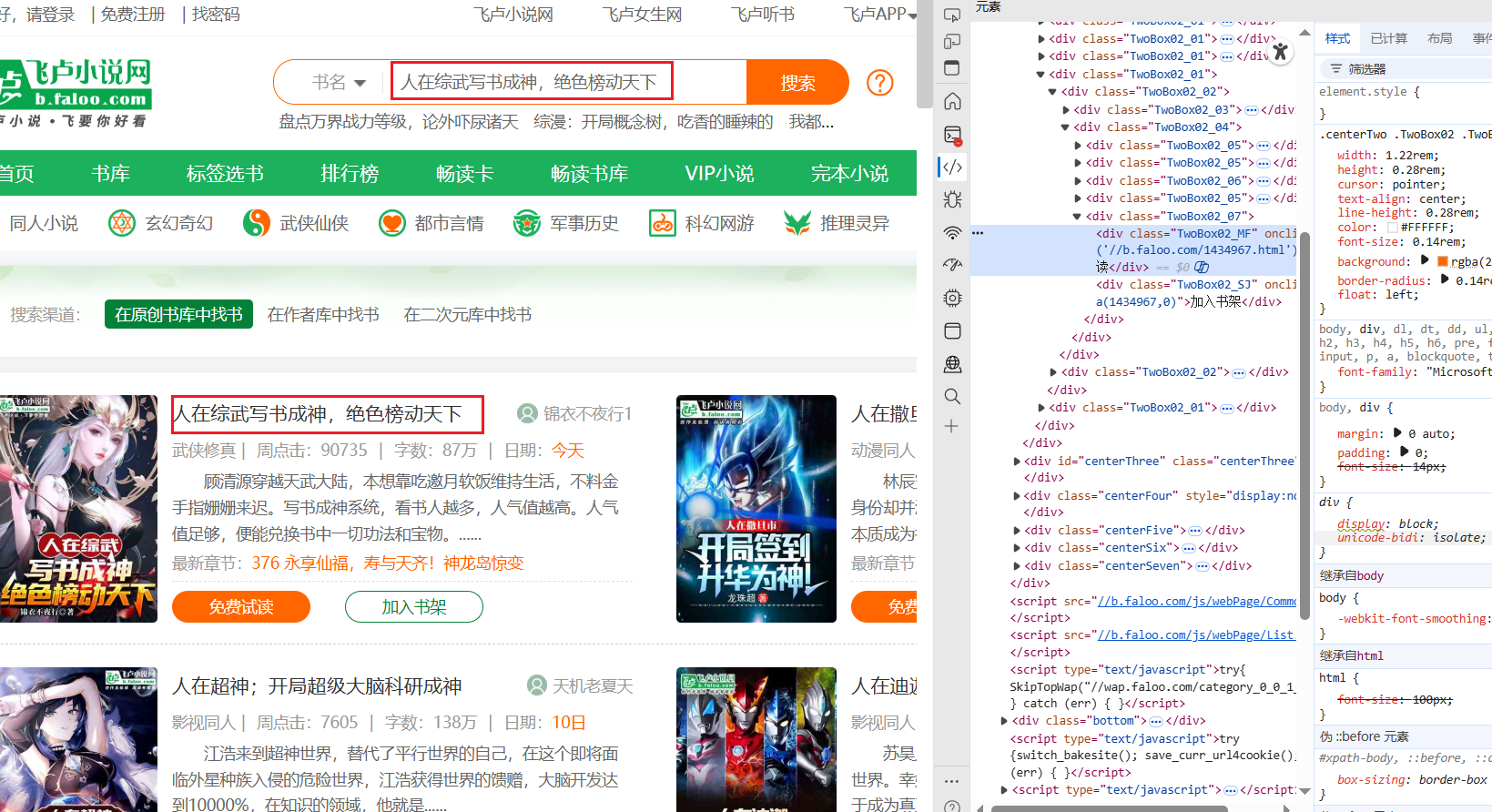
点击'免费试读'进入章节页面

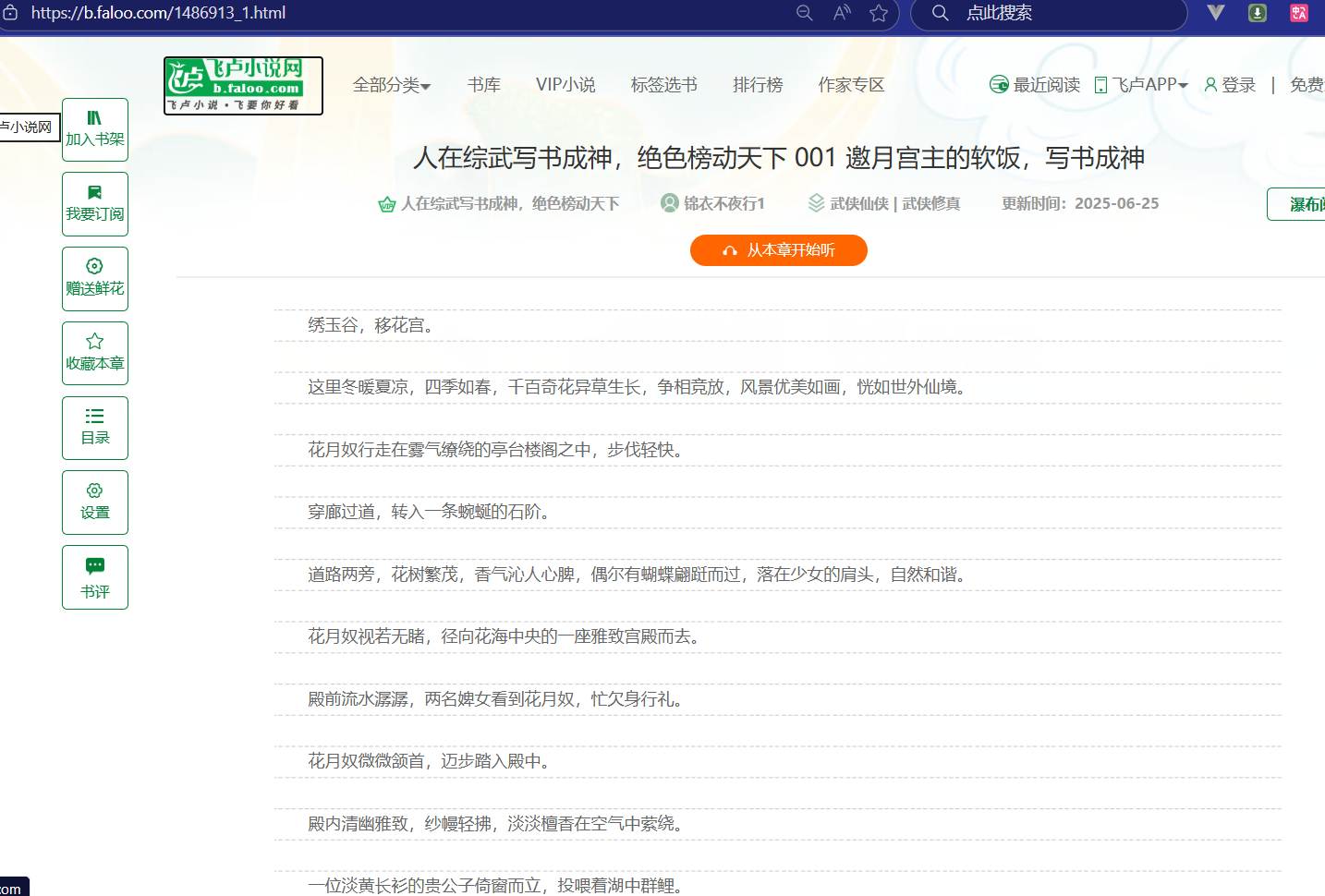
向下划就有章节

点击章节就是小说内容
模拟上述请求,获取指定的小说章节内容
import os
import urllib
import re
from bs4 import BeautifulSoup
from requests_html import HTMLSession
session=HTMLSession()
query_content=input('请输入小说名称:')
# pageNum=input('请输入页码:')
pageNum=1
url=f'https://b.faloo.com/l_0_{pageNum}.html'
params={
'k':urllib.parse.quote(query_content.encode("gb2312"))
}
headers={
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36 Edg/141.0.0.0',
'referer':'https://www.faloo.com/',
}
response=session.get(url=url,params=params,headers=headers)
if response.status_code==200:
# print('获取首页成功')
# print(response.content.decode('gb18030', errors='ignore'))
# 获取到html
content=response.content.decode('gb18030', errors='ignore')
soup=BeautifulSoup(content,'lxml')
# 获取标题
title=soup.select_one('.TwoBox02_02').select_one('.TwoBox02_03>a').get('title')
print(f"标题:{title}")
if(title!=query_content):
print('搜索出来的小说没有匹配的')
exit()
if not os.path.exists(title):
os.mkdir(title)
# 小说详情
detail_url = re.search(r"'(.*?)'",
soup.select_one('.TwoBox02_02').select_one('div.TwoBox02_07 > div.TwoBox02_MF').get(
'onclick'))
print(f'小说详情:https:{detail_url.group(1)}')
# 跳转到详情页
detail_response = session.get(url=f'https:{detail_url.group(1)}')
if detail_response.status_code == 200:
print('进入小说详情页面')
detail_content = detail_response.content.decode('gb18030', errors='ignore')
soup_detail = BeautifulSoup(detail_content, 'lxml')
# 获取章节
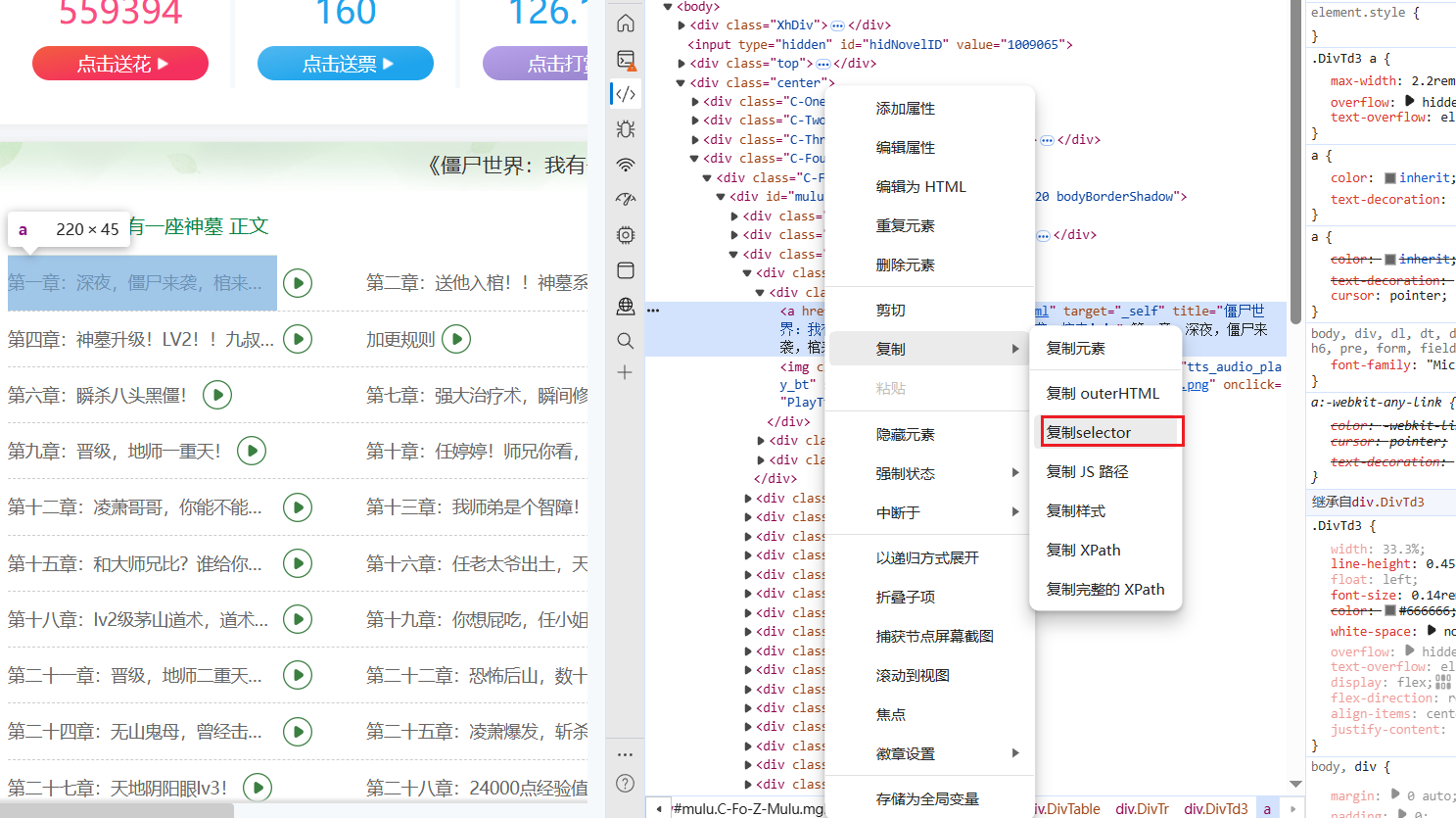
detail_chapters = soup_detail.select('.DivTable>.DivTr>.DivTd3')
# print(f'章节数:{len(detail_chapters)}')
for (i,detail_chapter) in enumerate(detail_chapters):
# 章节内容
chapter = detail_chapter.find('a').get_text(strip=True)
# 章节链接
chapter_url = 'https:' + detail_chapter.find('a').get('href')
tets=chapter.split(" ")
chapter_response = session.get(url=chapter_url)
if chapter_response.status_code == 200:
print(f'下载章节成功:{chapter}')
# i+1用于排序文件
with open(f'{title}/{i+1} {chapter}.txt','w',encoding='utf-8') as f:
chapter_soup = BeautifulSoup(chapter_response.content.decode('gb18030', errors='ignore'), 'lxml')
# 获取章节段落内容
for chapter_paragraph in chapter_soup.select('.noveContent>p'):
# print(chapter_paragraph.get_text(strip=True))
f.write(chapter_paragraph.get_text(strip=True))
f.write('\n')
f.write('\n')
else:
print(f'下载章节失败:{chapter}')
print('获取小说成功')
else:
print("获取小说详情页面失败")
else:
print('获取首页失败',response.content)获取结果
技巧:检测内容编码,然后自动解码
# 自动检测编码
detected = chardet.detect(response.content)
encoding = detected["encoding"]
print("检测到编码:", encoding)
# 自动解码
html = response.contet.decode(encoding, errors='ignore')
print(html)查找元素技巧

如果你在阅读过程中也有新的见解,或者遇到类似问题,🥰不妨留言分享你的经验,让大家一起学习。
喜欢本篇内容的朋友,记得点个 👍点赞,收藏 并 关注我,这样你就不会错过后续的更多实用技巧和深度干货了!
期待在评论区看到你的声音,我们一起成长、共同进步!😊