AB复制又称主从复制,实现的是数据同步。如果要做MySQL AB复制,数据库版本尽量保持一致。如果版本不一致,从服务器版本高于主服务器,但是版本不一致不能做双向复制。MySQL AB复制有什么好处呢?有两点,第一是解决宕机带来的数据不一致,因为MySQL AB复制可以实时备份数据;第二点是减轻数据库服务器压力,这点很容易想到,多台服务器的性能一般比单台要好。但是MySQL AB复制不适用于大数据量,如果是大数据环境,推荐使用集群。
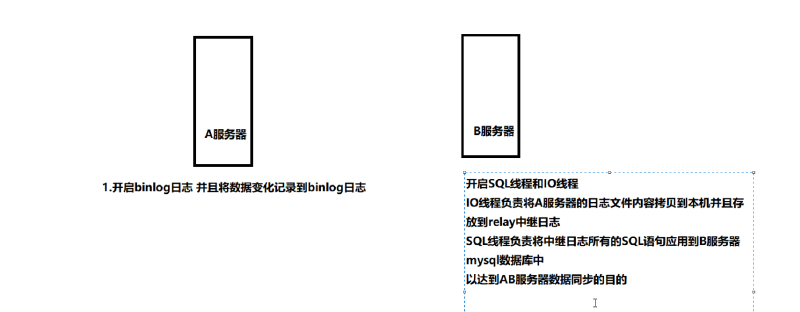
Mysql复制(replication)是一个异步的复制,从一个Mysql 实例(Master)复制到另一个Mysql 实例(Slave)。实现整个主从复制,需要由Master服务器上的IO进程,和Slave服务器上的Sql进程和IO进程共从完成。要实现主从复制,首先必须打开Master端的binary log(bin-log)功能,因为整个 MySQL 复制过程实际上就是Slave从Master端获取相应的二进制日志,然后再在自己slave端完全顺序的执行日志中所记录的各种操作。(二进制日志几乎记录了除select以外的所有针对数据库的sql操作语句)
主从复制的基本过程如下:
1)、Mysql Slave端的IO进程连接上Master,向Master请求指定日志文件的指定位置(或者从最开始的日志)之后的日志内容;
2)、Master接收到来自Slave的IO进程的请求后,负责复制的IO进程根据Slave的请求信息,读取相应日志内容,返回给Slave 的IO进程。并将本次请求读取的bin-log文件名及位置一起返回给Slave端。
3)、Slave的IO进程接收到信息后,将接收到的日志内容依次添加到Slave端的relay-log文件的最末端,并将读取到的Master端的 bin-log的文件名和位置记录到master-info文件中,以便在下一次读取的时候能够清楚的告诉Master"我需要从某个bin-log的哪mysq个位置开始往后的日志内容,请发给我";
4)、Slave的Sql进程检测到relay-log中新增加了内容后,会马上解析relay-log的内容成为在Master端真实执行时候的那些可执行的内容,并在自身执行。
(1.设置主机名 hostnamectl set-hostname
(2.彼此解析主机名 vim /etc/hosts
(3.关闭防火墙 systemct stop firewalld
(4.selinux关闭 getence vim /etc/selinux/config
(5.设置时间同步 ntpdate ntp.aliyun.com
(6.数据库都正常运行(并且数据同步)
主服务器:
A ip192.168.147.128
1.全逻辑备份 不区分引擎
2.将全备拷贝到从机,并且从机恢复数据
scp /mysql_backup/all.sql 192.168.147.129:/
从机 mysql -u slave -p123 < /root/all.sql
3.开启binlog日志
4.授权B服务器 可以传输binlog日志
grant replication slave on . to slave@'192.168.147.129' identified by '123';
从服务器:
groupadd -g 27 mysql
useradd -g 27 -u 27 -s /bin/nologin mysql
mkdir /var/lib/mysql
chown -R mysql.mysql /var/lib/mysql
B ip192.168.147.129
1.测试salve是否能正常链接A服务器
mysql -u slave -p123 -h 192.168.147.128
2.拷贝A服务器的全备,并且2.将全备拷贝到从机,并且从机恢复数据
3.配置A服务器链接地址及用户信息
vim /etc/my,cnf
[mysqld]
server-id=2
socket=/var/lib/mysql/mysql.sock
systemctl restart mysqldd
mysql -u root -p123
stop slave;
change master to
master_host='192.168.147.128',
master_user='slave',
master_password='123',
master_port=3306,
master_log_file='master.000001',
master_log_pos=154;
start slave;2.M-M互为主从
主服务器A:开启binlog日志
[mysqld]
server-id=1
log-bin=/mysql-log/master
log-bin-index=/mysql-log/master(1.全逻辑备份 不区分引擎
(2.将2.将全备拷贝到从机,并且从机恢复数据,并在从机完全恢复,保证主从数据一致性
(3.授权从机可以从主机复制数据:grant replication slave on . to slave@'192.168.147.129' identified by '123';
(4.查看主服务器日志状态:show master status\G;
从服务器B:
(1.完全恢复:mysql -u slave -p123 < /root/all.sql
(2.测试登录主服务器:mysql -u slave -p123 -h 192.168.147.128
(3.配置文件
vim /etc/my.cnf
[mysqld]
server-id=24.配置连接服务器
change master to
master_host='192.168.147.128',
master_user='slave',
master_password='123',
master_port=3306,
master_log_file='mysql-bin.000001',
master_log_pos=453;
start slave;
show slave status\G;
Slave_IO_Running: Yes
Slave_SQL_Running: Yes调换两台主机身份再做一次
从服务器B
(1.开启binlog日志
[mysql]
server-id=2
log-bin=slave
log-bin-index=slave(2.给主服务器授权
grant replication slave on . to master@'192.168.147.128' identified by '123';
主服务器A
change master to
master_host='192.168.147.129',
master_user='master',
master_password='123',
master_port=3306,
master_log_file='slave.000001',
master_log_pos=453;
start slave;
show slave status\G;3.mysql 半同步复制
Mysql 主从复制(半同步) 异步 同步
1.半同步复制
在说明半同步复制之前我们先来了解一下,什么是同步复制?同步复制:同步复制可以定义为数据在同一时刻被提交到一台或多台机器,通常这是通过众所周知的"两阶段提交"做到的。虽然这确实给你在多系统中保持一致性,但也由于增加了额外的消息交换而造成性能下降。使用MyISAM或者InnoDB存储引擎的MySQL本身并不支持同步复制,然而有些技术,例如分布式复制块设备(简称DRBD),可以在下层的文件系统提供同步复制,允许第二个MySQL服务器在主服务器丢失的情况下接管(使用第二服务器的复本)。了解了同步复制我们正下面来说一下,什么是半同步复制?
MYSQL 5.5开始,支持半自动复制。之前版本的MySQL Replication都是异步(asynchronous)的,主库在执行完一些事务后,是不会管备库的进度的。如果备库不幸落后,而更不幸的是主库此时又出现Crash(例如宕机),这时备库中的数据就是不完整的。简而言之,在主库发生故障的时候,我们无法使用备库来继续提供数据一致的服务了。Semisynchronous Replication(半同步复制)则一定程度上保证提交的事务已经传给了至少一个备库。Semi synchronous中,仅仅保证事务的已经传递到备库上,但是并不确保已经在备库上执行完成了。
此外,还有一种情况会导致主备数据不一致。在某个session中,主库上提交一个事务后,会等待事务传递给至少一个备库,如果在这个等待过程中主库Crash,那么也可能备库和主库不一致,这是很致命的。如果主备网络故障或者备库挂了,主库在事务提交后等待10秒(rpl_semi_sync_master_timeout的默认值)后,就会继续。这时,主库就会变回原来的异步状态。
MySQL在加载并开启Semi-sync插件后,每一个事务需等待备库接收日志后才返回给客户端。如果做的是小事务,两台主机的延迟又较小,则Semi-sync可以实现在性能很小损失的情况下的零数据丢失。
2.异步与半同步异同
默认情况下MySQL的复制是异步的,Master上所有的更新操作写入Binlog之后并不确保所有的更新都被复制到Slave之上。异步操作虽然效率高,但是在Master/Slave出现问题的时候,存在很高数据不同步的风险,甚至可能丢失数据。
MySQL5.5引入半同步复制功能的目的是为了保证在master出问题的时候,至少有一台Slave的数据是完整的。在超时的情况下也可以临时转入异步复制,保障业务的正常使用,直到一台slave追赶上之后,继续切换到半同步模式。
注:mysql5.5半同步插件是由谷歌提供,具体位置/usr/local/mysql/lib/plugin/下,一个是master用的semisync_master.so,一个是slave用的semisync_slave.so,下面我们就来具体配置一下。
配置:(先做AB异步复制,再改成半同步)
master端
安装半同步master插件:install plugin rpl_semi_sync_master soname 'semisync_master.so';
开启半同步插件:set global rpl_semi_sync_master_enabled=1;
设置同步超时时间:set global rpl_semi_sync_master_timeout=10000;
vim /etc/my.cnf
[mysqld]
server-id=1
log-bin=master
log-bin-index=master
rpl_semi_sync_master_enabled=1 控制是否启用半同步复制。当设置为1时,它启用了半同步复制
rpl_semi_sync_master_timeout=1000 主服务器等待从服务器确认事务写入二进制日志的最长时间slave端配置
安装半同步slave插件:install plugin rpl_semi_sync_slave soname 'semisync_slave.so';
开启半同步插件:set global rpl_semi_sync_slave_enabled=1;
[mysqld]
server-id=2
rpl_semi_sync_slave_enabled=1查询状态
master:SHOW GLOBAL STATUS LIKE 'rpl_semi%';
slave:SHOW GLOBAL STATUS LIKE 'rpl_semi%';
IO线程是NO,SQL是YES
1.uuid表示符
2.server-id不唯一,mysql有可能并没有加载my.cnf文件中的server-id
3.主库重启造成二进制文件(binlog日志)位置从库主库不一致
4.主从服务器版本不一致
5.防火墙
6.网络延时
7.主机未开放账户连接权限
8.配置从机连接语法错误
9.mysql账户密码错误
IO是YES,SQL是NO
1.主库没有进行写操作,从库进行写操作
2.从库落后于主库太多
3.复制错误
4.中继日志问题
SHOW SLAVE STATUS\G来诊断问题
4.GTID的组成
GTID = source_id:transaction_id
source_id,用于鉴别原服务器,即mysql服务器唯一的的server_uuid,由于GTID会传递到slave,所以也可以理解为源ID。
transaction_id,为当前服务器上已提交事务的一个序列号,通常从1开始自增长的序列,一个数值对应一个事务。
5.GTID的工作原理
1、当一个事务在主库端执行并提交时,产生GTID,一同记录到binlog日志中。
2、binlog传输到slave,并存储到slave的relaylog后,读取这个GTID的这个值设置gtid_next变量,即告诉Slave,下一个要执行的GTID值。
3、sql线程从relay log中获取GTID,然后对比slave端的binlog是否有该GTID。
4、如果有记录,说明该GTID的事务已经执行,slave会忽略。
5、如果没有记录,slave就会执行该GTID事务,并记录该GTID到自身的binlog,在读取执行事务前会先检查其他session持有该GTID,确保不被重复执行。
6、在解析过程中会判断是否有主键,如果有就用二级索引,如果没有就用全部扫描。
主服务器
vim /etc/my.cnf
gtid_mode=on #开启gtid模式
enforce_gtid_consistency=on #强制gtid一致性,开启后对于特定create table不被支持
从服务器
vim /etc/my.cnf
gtid_mode=on
enforce_gtid_consistency=on6.多源复制
使用多源复制的考虑:
1、灾备作用:将各个库汇总在一起,就算是其他库都挂了(整个机房都无法连接了),还有最后一个救命稻草;
2、备份:直接在这个从库中做备份,不影响线上的数据库;
3、减少成本:不需要每个库都做一个实例,也减少了DBA的维护成本;
4、数据统计:后期的一些数据统计,需要将所有的库汇总在一起。
实验环境:
1.关闭防火墙
2.关闭selinux
3.设置和解析主机名
192.168.0.13 master1.com
192.168.0.14 master2.com
192.168.0.11 slave.com
分别安装mysql
分别在master1 master2上建立不同的数据库做测试
master1
create database master1;
use master1
create table m1(id int);
insert into m1 values(1),(2);
master2
create database master2;
user master2;
create table m2(name char(10))
insert into m2 values('robin')('zorro')
分别在master1,master2导出需要同步的数据库
master1
mysqldump -u root -p123 --databases master1 > /tmp/master1.sql
master2
mysqldump -u root -p123 --databases master2 > /tmp/master2.sql
分布在master1 master2上创建复制账号和密码
master1
grant replication slave on . to salve1@192.168.147.128 identified by'123';
master2
grant replication slave on . to salve2@192.168.147.129 identified by'123';
在salve节点测试
mysql -u slave1 -p123 -h 192.168.147.128
mysql -u slave2 -p123 -h 192.168.147.129
修改slave my.cnf
master_info_repository=TABLE
relay_log_info_repository=TABLE
master_info_repository
开启MTS功能后,务必将参数master_info_repostitory设置为TABLE,这样性能可以有50%~80%的提升。这是因为并行复制开启后对于元master.info这个文件的更新将会大幅提升,资源的竞争也会变大。在之前InnoSQL的版本中,添加了参数来控制刷新master.info这个文件的频率,甚至可以不刷新这个文件。因为刷新这个文件是没有必要的,即根据master-info.log这个文件恢复本身就是不可靠的。在
MySQL 5.7中,推荐master_info_repository设置为TABLE,来减少这部分的开销。
relay_log_info_repository 同理
在线修改
stop slave
mysql> SET GLOBAL master_info_repository = 'TABLE';
mysql> SET GLOBAL relay_log_info_repository = 'TABLE';
将master1 master2 备份的sql语句拷贝并导入slave数据库
scp 192.168.147.128:/tmp/master1.sql /tmp/
scp 192.168.147.129:/tmp/master2.sql /tmp/
恢复
mysql -u root -p123 < /tmp/master1.sql
mysql -u root -p123 < /tmp/master2.sql
分别找出master1和master2的pos位置
show master status\G;
slave
登录Slave进行同步操作,分别change master到两台Master服务器,后面以FOR CHANNEL 'CHANNEL_NAME'区分
CHANGE MASTER TO MASTER_HOST='192.168.147.128',MASTER_USER='slave1', MASTER_PASSWORD='123',MASTER_LOG_FILE='master1.000001',MASTER_LOG_POS=154 FOR CHANNEL 'master1';
CHANGE MASTER TO MASTER_HOST='192.168.147.128',MASTER_USER='slave2', MASTER_PASSWORD='123',MASTER_LOG_FILE='master2.000001',MASTER_LOG_POS=154 FOR CHANNEL 'master2';
正常启动后,可以查看同步的状态:执行SHOW SLAVE STATUS FOR CHANNEL 'channel_name'\G
验证数据是否同步
master1:insert into m1 values(3);
master2:insert into m2 values('tom')
use master1
select * from m1
use master2
select * from m2