Week 20: 深度学习补遗:Transformer Decoder架构
摘要
本周跟随李宏毅老师的课程学习了Transformer Decoder方面的内容,针对其设计理念以及运作方式进行了一定的了解。
Abstract
This week, through Professor Hung-yi Lee's course, I studied the Transformer Decoder, gaining a solid understanding of its design philosophy and operational mechanisms.
1. Transformer Decoder - Autoregressive 自回归
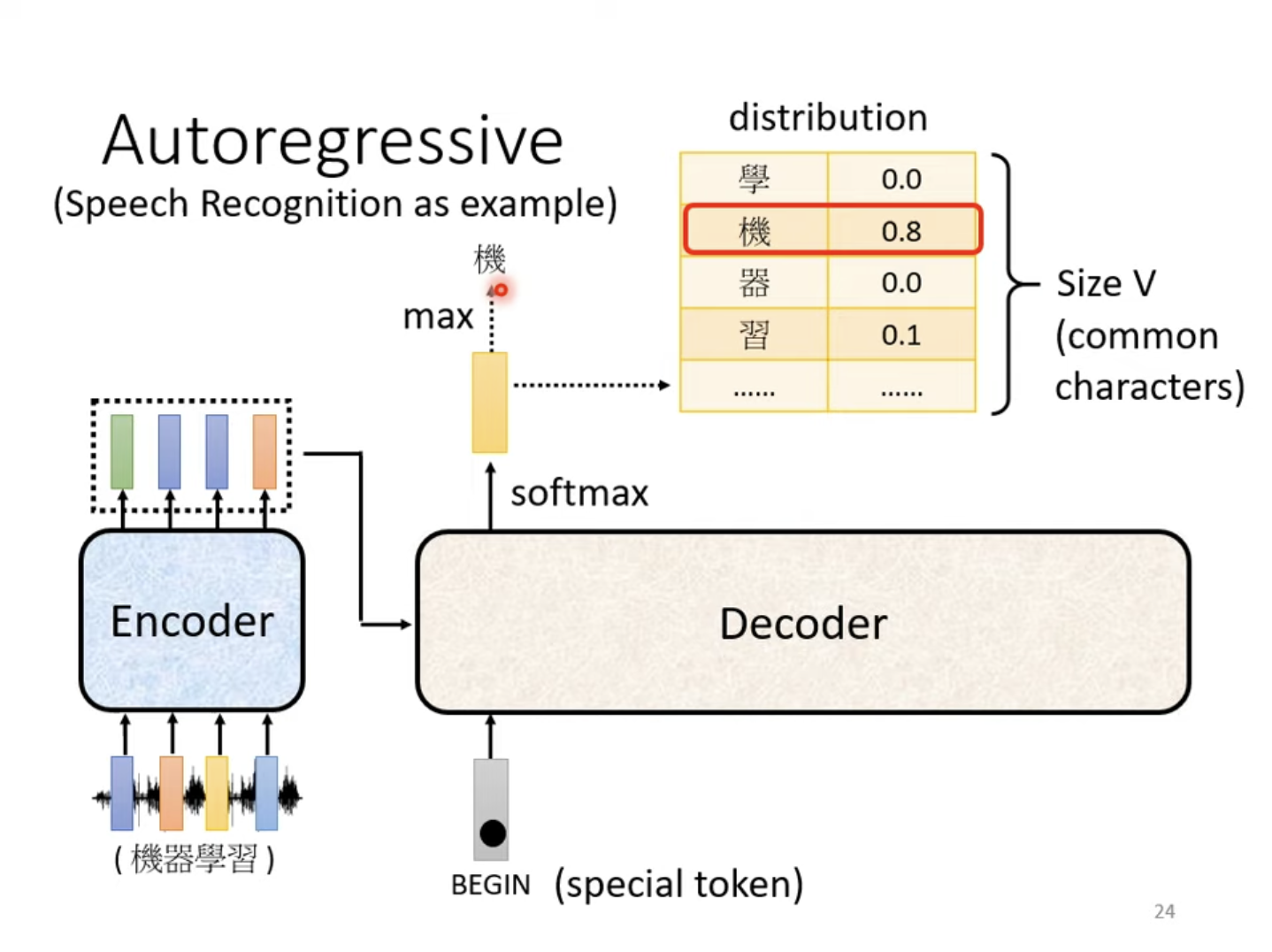
由Encoder导出一个向量输入Decoder后,先对Decoder输入一个Special Token "BEGIN"(或"BOS",Begin of Sentence),Decoder会输出一个概率分布向量,其尺寸VVV是常用词的大小,比如中文方块字的数量,代表下一个输出的概率,概率最大的那个即为模型的下一个输出。
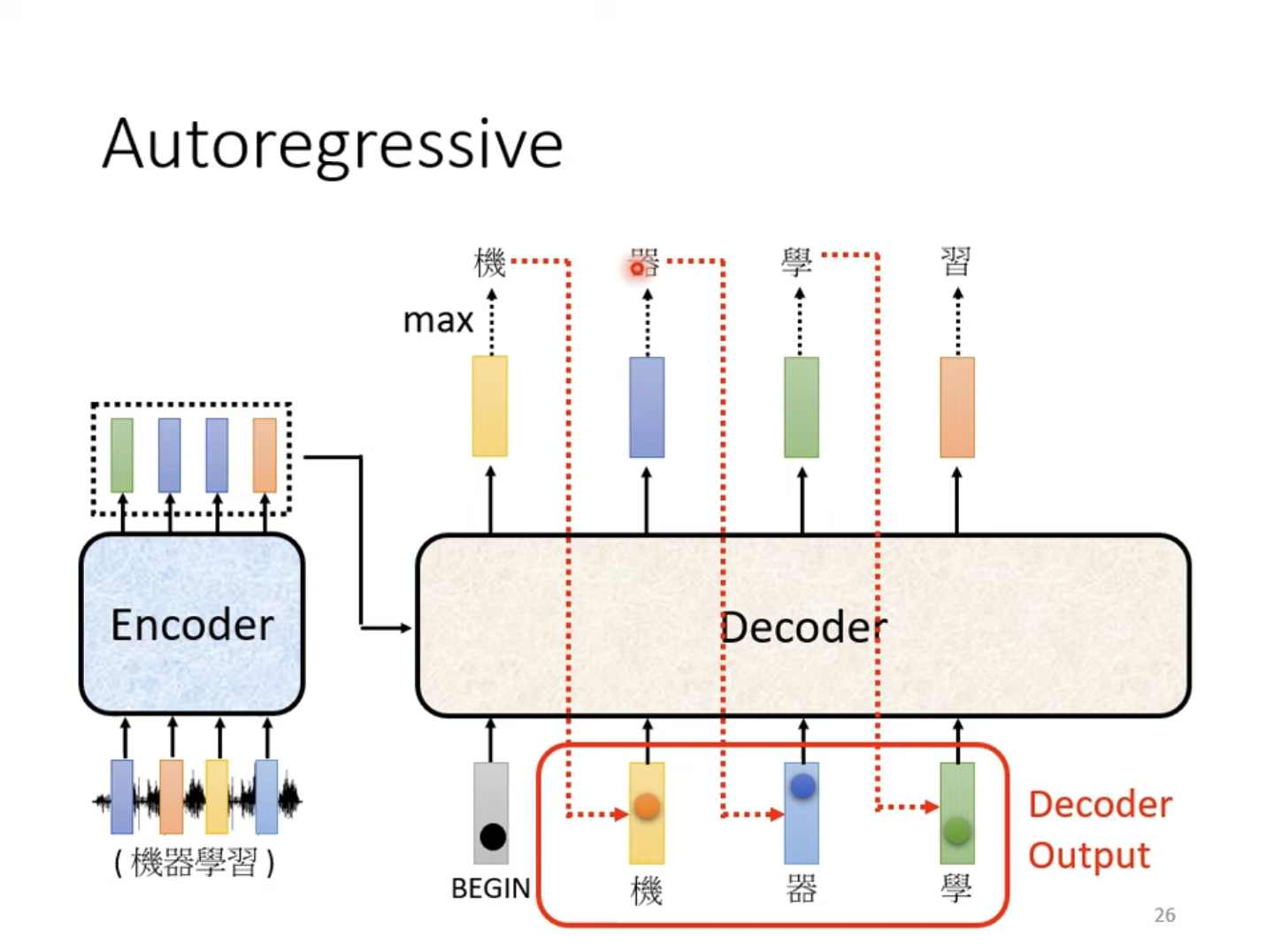
自回归描述的是,在产生"机"的输出后,将其作为Decoder的下一个输入输入Decoder,使其得出下一个输出,如此往复。代表着Decoder可能会产生错误的输出,但其会尝试在错误输出的基础上得出最终正确的结果。
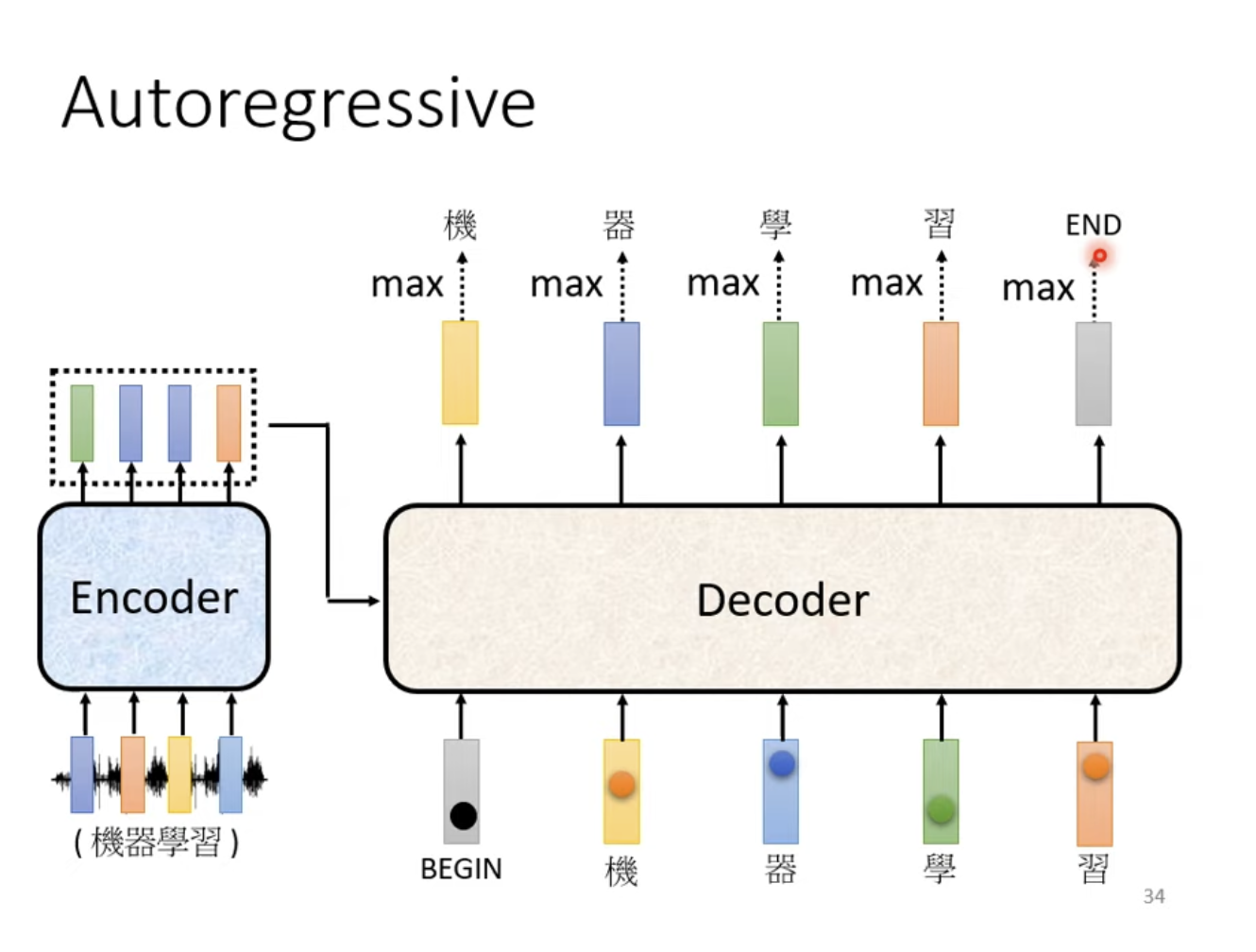
当输出产生特殊Token END时,输出结束。
2. Transformer Decoder - Masked Self-Attention
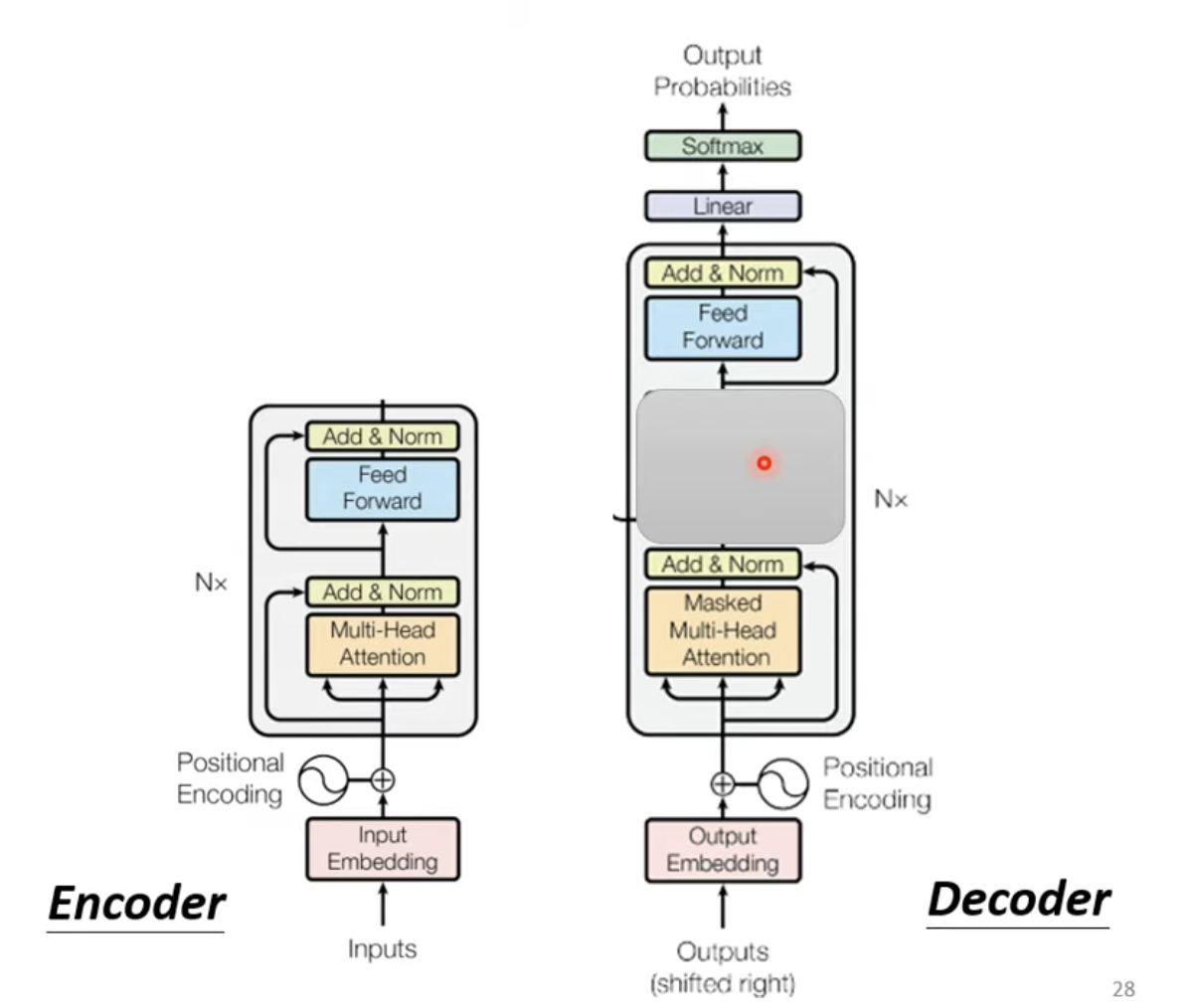
实际上,Transformer的Encoder和Decoder结构非常相似,遮掉中间的部分,区别主要就是Multi-Head Attention部分是否有Masked结构。
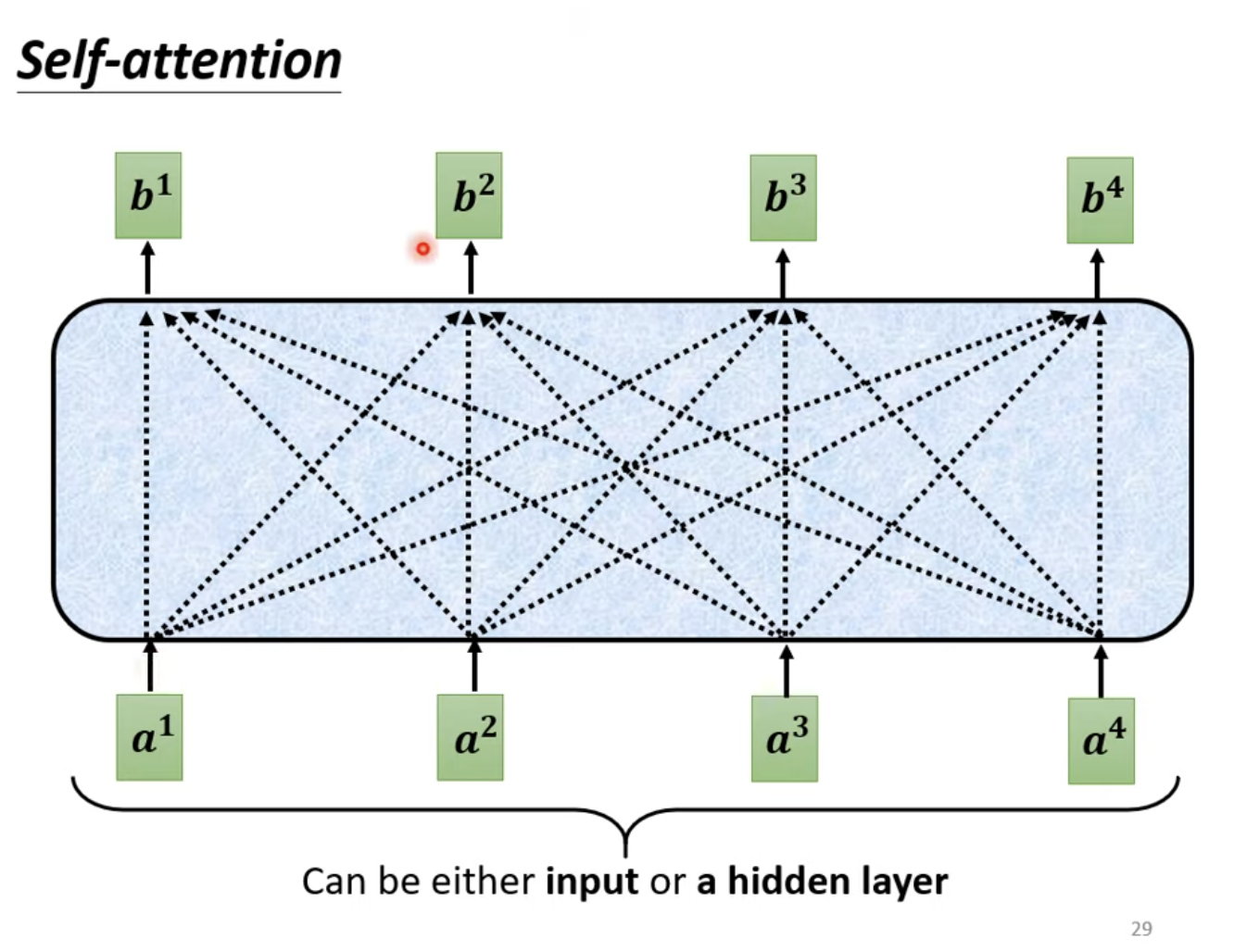
Masked结构其实非常简单,即在计算b1b^1b1时,只能采用a1a^1a1的信息;计算b2b^2b2时,只能采用a1a^1a1、a2a^2a2的信息,以此类推。
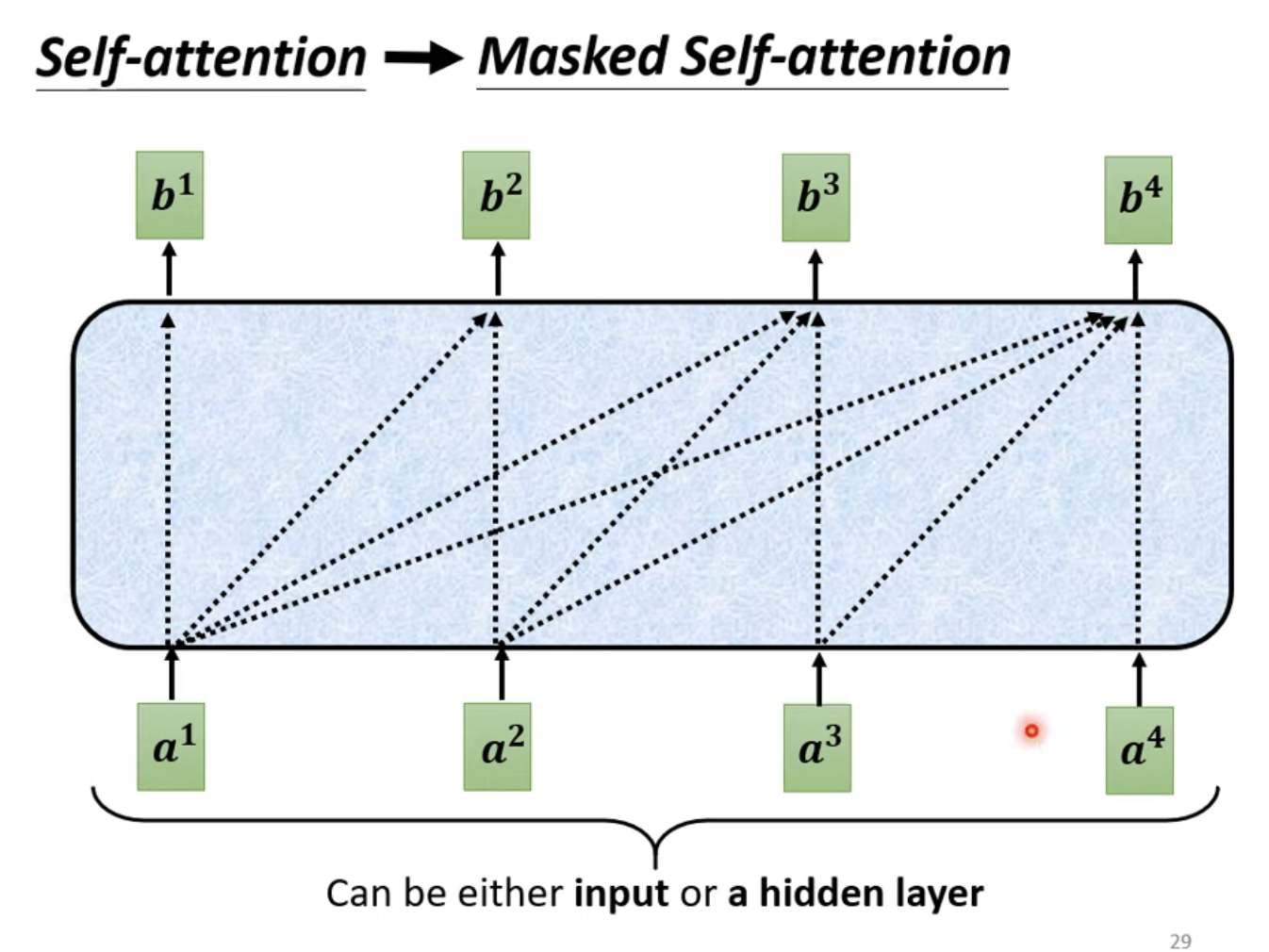
Masked的想法源于Decoder的运行方法,即由上一个输出的Token做为输入得到下一个Token的结构,为了避免"偷看"影响后续Token的输出,因此设计Masked结构在注意力层面保证后文不泄露。
3. Transformer Decoder - Non-Autoregressive 非自回归
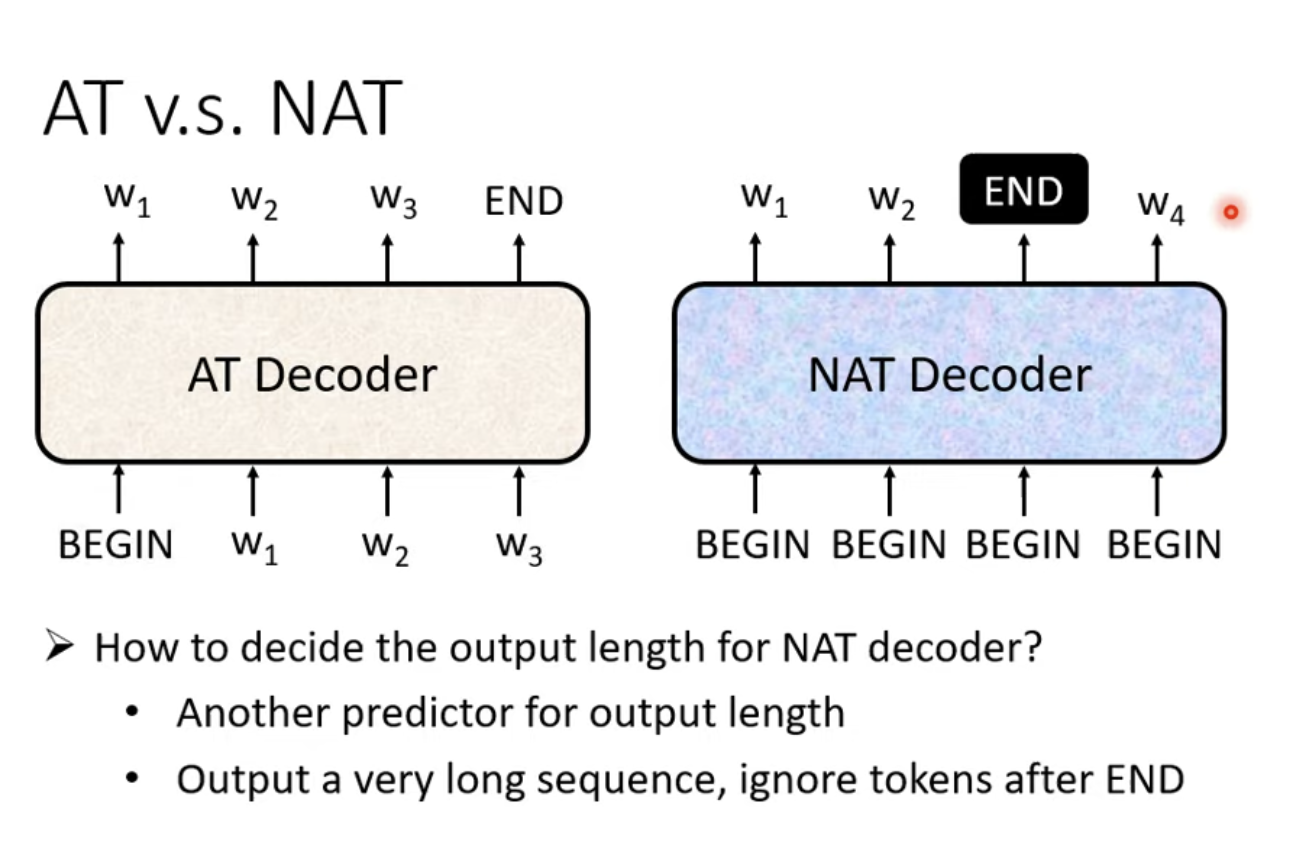
非自回归模型的实现方式是,对于需要的输出长度nnn,输入nnn个特殊Token BEGIN,每一个BEGIN都生成对应的输出。但也有显而易见的问题,即无法直接获知输出序列长度,一般有两种方法解决这个问题:第一种是训练一个神经网络,以输入序列为输入,输出一个数字,即期望输出的长度;第二种是以最大输出Token数量为准,输入nnn个BEGIN,最终将输出中的END以后的输出Token全部丢弃,这样也可以完成一个输出过程。
非自回归的一个显著优势是,其可以进行并行输出,有更高的效率。自回归依赖前文的输出来输出后文,然而非自回归可以同时输出所有Token,效率优势显著。并且非自回归可以控制输出长度,也是一个显著的优势。
但从经验上来看,NAT的Decoder的表现往往不如AT Decoder表现优秀。
3. Transformer Decoder - Cross-Attention 交叉注意力
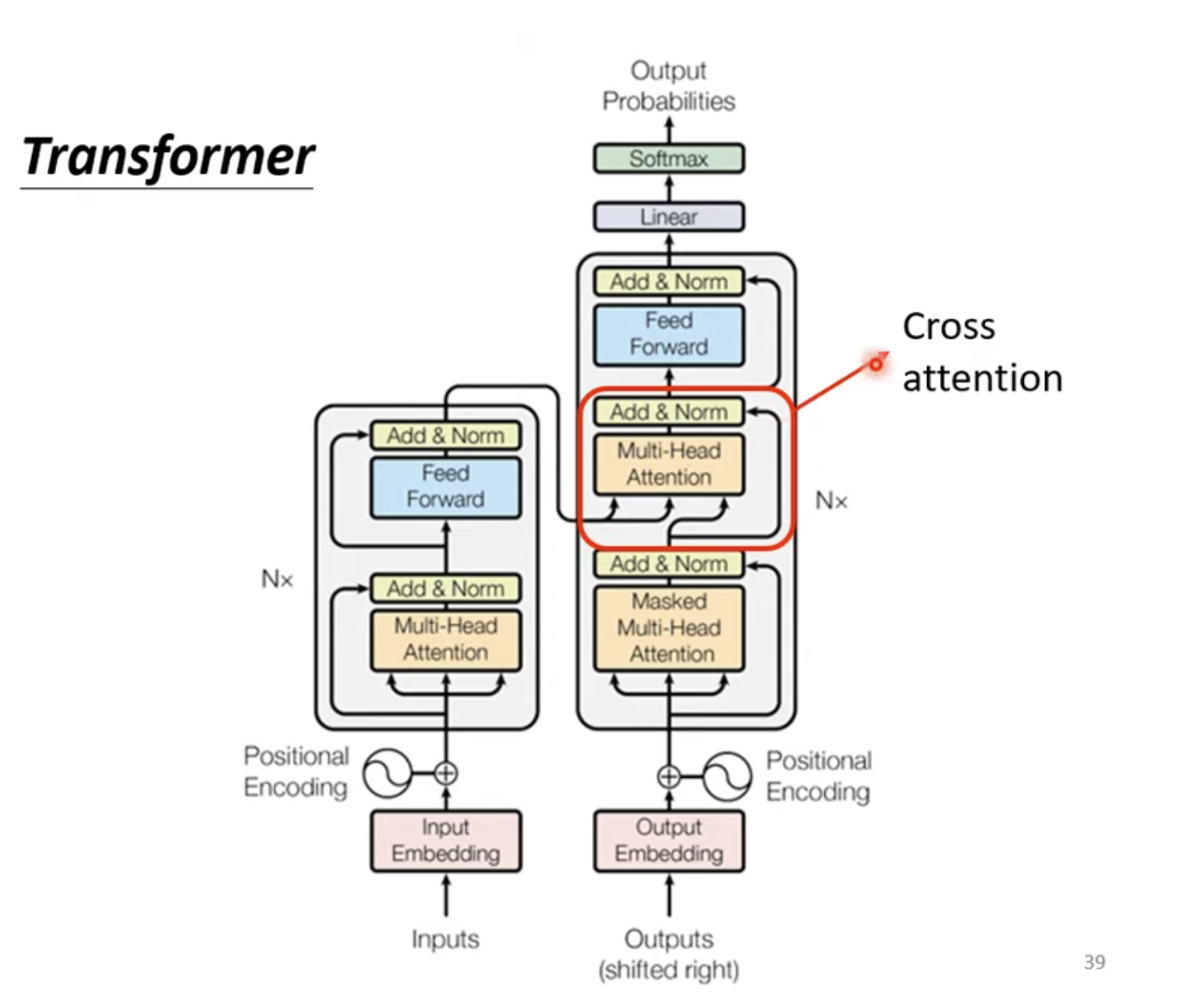
前文中被遮盖的部分实际上是交叉注意力,负责连接Encoder与Decoder。
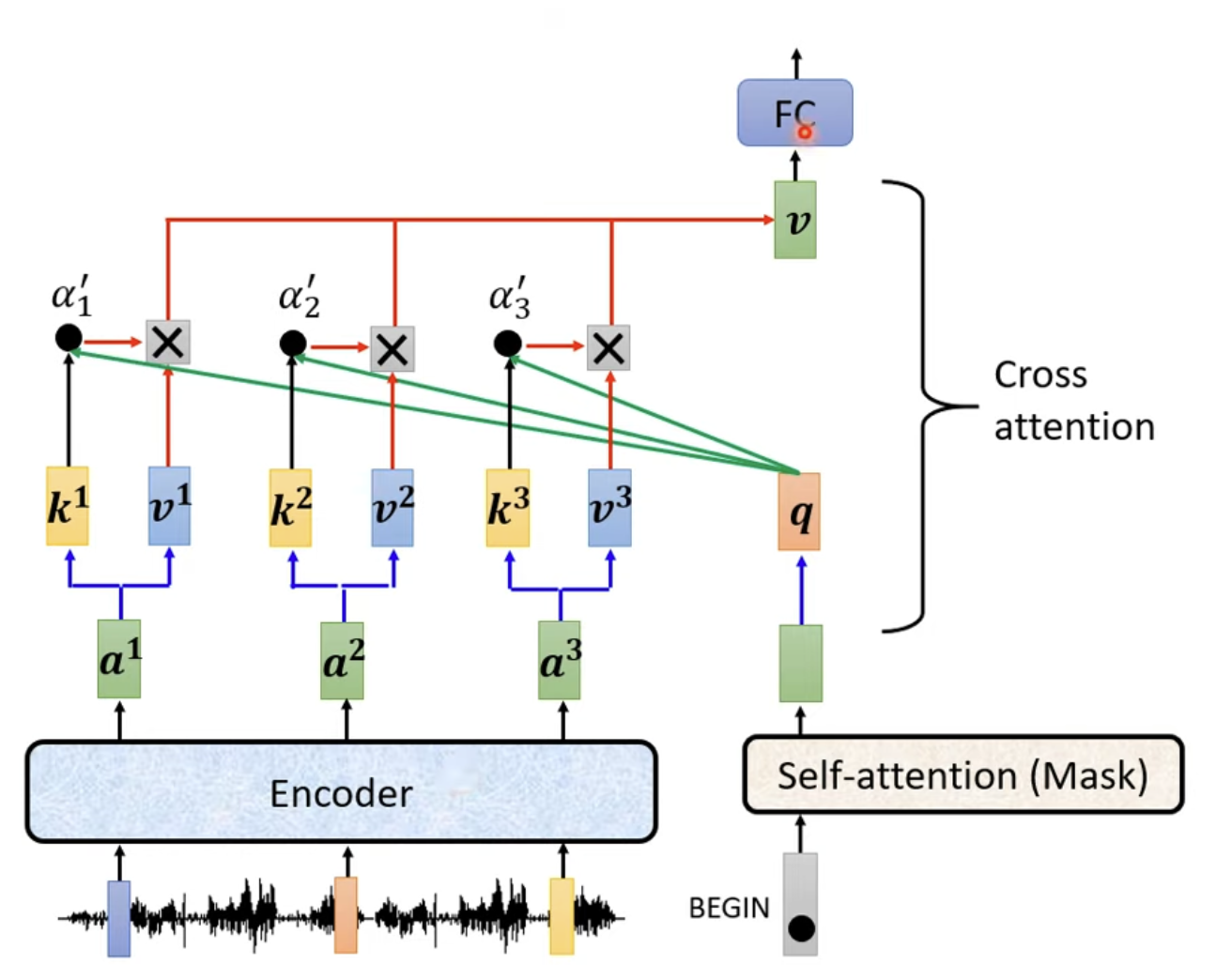
在上图可以看到,Transformer中的自注意力机制有两个输入来自于Encoder,一个输入来自于前序的Masked的多头注意力。实际在内部,是由Encoder输入产生KKK和VVV,再由前序Masked多头注意力机制产生QQQ计算而来,结合了Encoder输入和Masked自注意力的输入产生的最后注意力输出,因此称为交叉注意力。
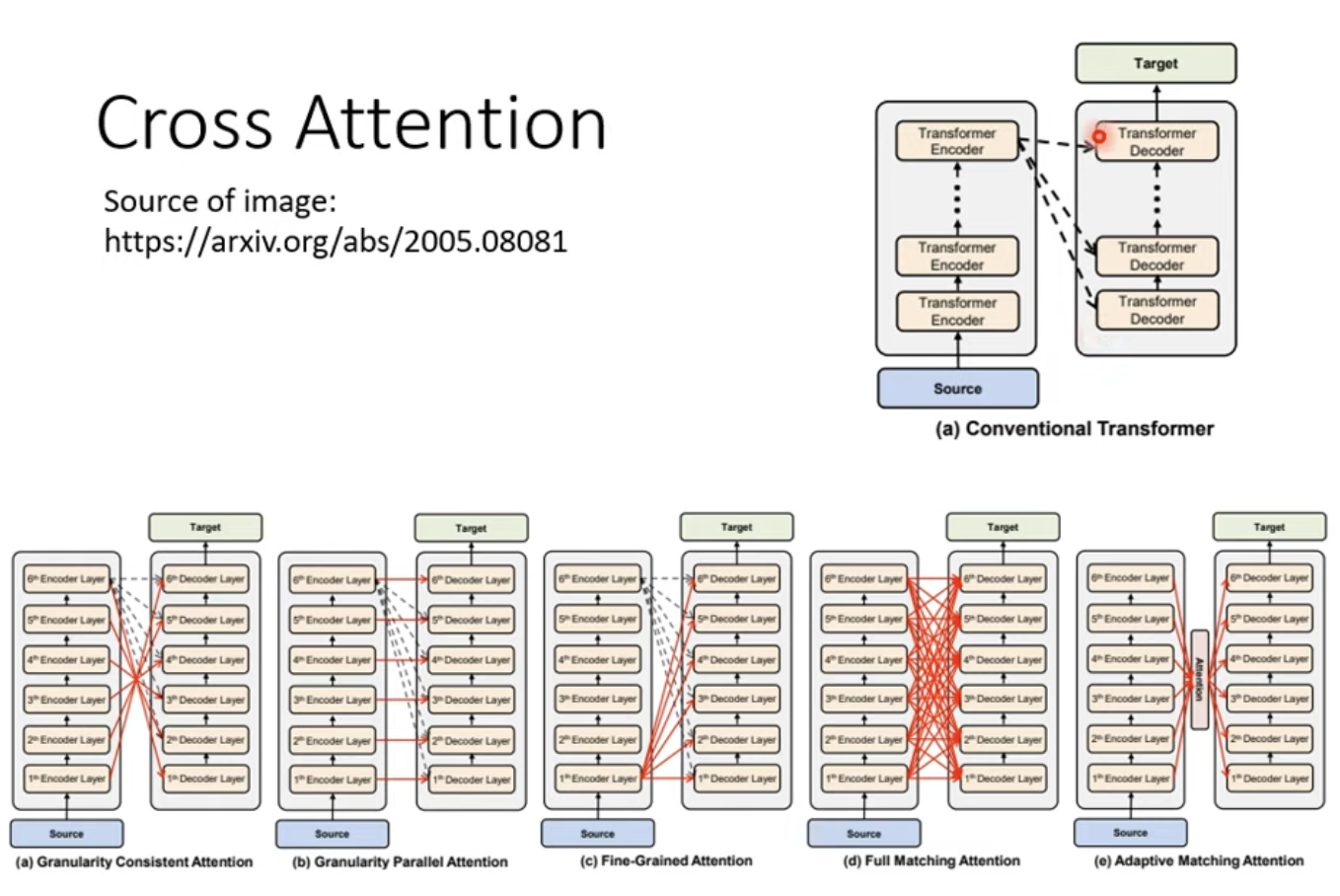
在原始的论文中,无论有多少层Encoder,Cross Attention都采用了最后一层Encoder,但实际上的实践中,可以有不同的操作,有多重的变种。
4. Transformer训练
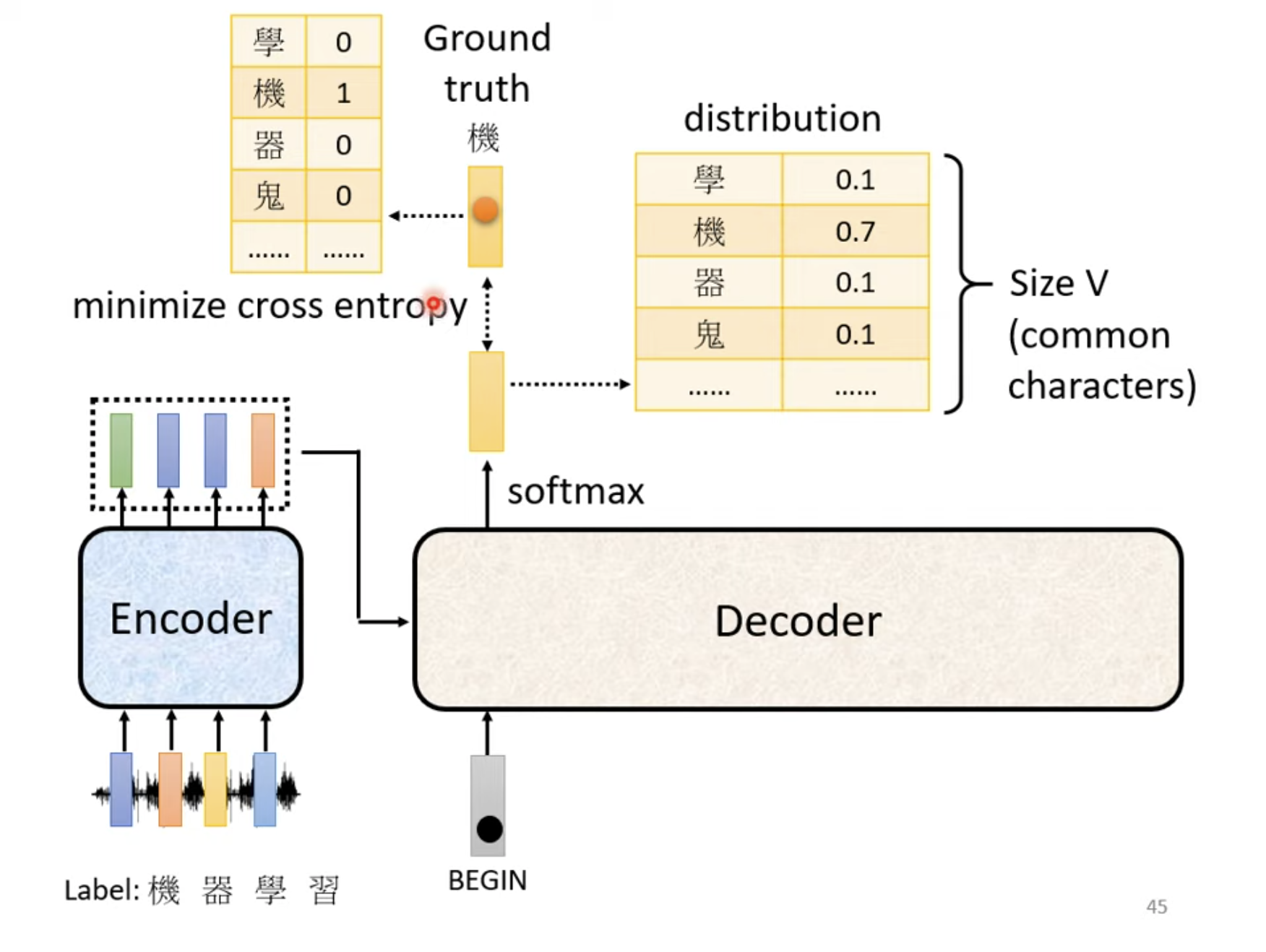
其训练过程本质就是针对VVV个类别的分类问题的训练,针对每一个字的输出,最小化其分布与实际字的交叉熵即可。
总结
本周对Transformer Decoder的结构与设计理念进行了进一步的深入了解,主要了解了自回归的机制与优缺点,并且与非自回归模型进行了对比。并且了解了Transformer Decoder中的交叉注意力模块的设计理念以及Masked自注意力的原理,最后简单了解了Transformer训练的目标和结构。下周预计对Transformer继续进行深入学习,更加深入的了解Transformer的训练Tips&Tricks。