摘要
本文章旨在深入探讨语义与认知科学中的"循环解释悖论"(Circular Explanation Paradox)及其对现代人工智能(AI),特别是自然语言处理(NLP)领域中深层语义分析的潜在影响与启示。尽管现有研究并未直接定义和分析"循环解释悖论"在NLP中的具体表现,但通过综合分析逻辑学、哲学、认知科学及AI可解释性(XAI)领域的相关概念,我们可以推断其在大型语言模型(LLMs)中的潜在体现、危害及应对策略。报告首先界定循环解释的本质,即一种解释本身依赖于被解释对象的无效论证形式。随后,报告将探讨这一悖论如何在Transformer架构(如BERT和GPT)中以重复性生成、同义反复式解释和知识溯源循环等形式显现。最后,报告将分析其对情感分析、机器翻译和问答系统等具体NLP任务的负面影响,并展望未来的研究方向,包括开发专门的评测基准和优化模型架构以增强其逻辑推理与自我修正能力。
1. 引言:循环解释悖论的理论根源
循环解释,或称循环论证(Circular Reasoning),在逻辑学和心理学中被认为是一种逻辑谬误,其核心在于"解释者使用的概念等同于其解释的对象本身"。这种解释方式因未能提供任何新的信息而无效,形成了一个自我封闭的逻辑回路。在语义学和认知科学中,这一问题扩展为"循环解释悖论",即语言系统在定义或解释某些概念时,可能会陷入一种自指(self-reference)或相互依赖的怪圈,从而无法为概念提供一个坚实的外部基础 。
历史上,哲学家和逻辑学家已经深入研究了多种与循环性相关的悖论,如"说谎者悖论"(Liar Paradox)。这些悖论揭示了自然语言中固有的复杂性和自我参照能力,挑战了形式语义系统的完备性 。虽然一些理论,如Kripke的固定点理论和语言层级论,试图通过在形式系统中设定层级或排除自指来解决这些悖论 ,但它们在应用于复杂且动态的自然语言时仍面临挑战。
随着大型语言模型(LLMs)在自然语言处理(NLP)领域的崛起,这些模型在模仿人类语言和推理方面展现出惊人的能力。然而,它们的"黑箱"特性 也引发了新的问题:这些模型是否会重现甚至放大人类认知中的逻辑谬误,特别是循环解释的悖论?本报告将探讨这一问题对深层语义分析的深远影响。
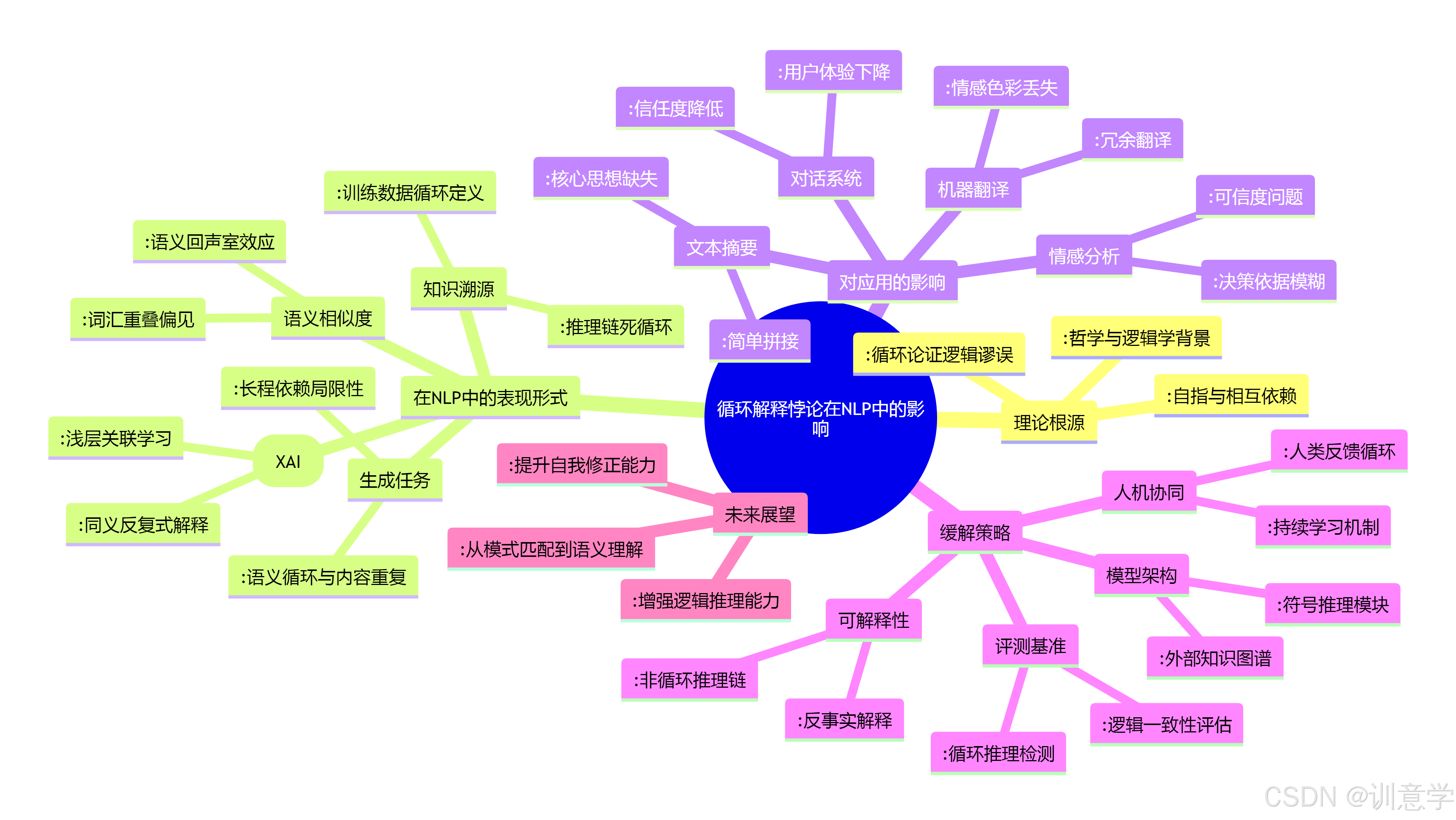
2. 循环解释悖论在现代NLP模型中的潜在表现形式
尽管现有文献中没有专门针对"循环解释悖论"在NLP模型中的实证研究,但通过分析模型行为和局限性,我们可以识别出几种潜在的表现形式,尤其是在基于Transformer架构的模型(如BERT和GPT)中 。
2.1. 生成任务中的"语义循环"与内容重复
在长文本生成任务中,大型语言模型有时会陷入重复性的"循环"(babbling),反复生成相同或语义上等价的短语和句子 。这种现象可以被视为一种行为层面的循环解释。模型在无法找到新的、有意义的信息来推进叙述时,会回到已经生成的内容上,用自身输出来"解释"或"延续"自身,形成一个无意义的语义闭环。这暴露了模型在长程依赖和规划能力上的局限性,其生成过程并非基于深刻的语义理解,而更像是基于概率的序列模式匹配。
2.2. 解释生成(XAI)中的同义反复
随着可解释人工智能(XAI)的发展,越来越多的研究致力于让模型解释其自身的决策过程 。然而,当要求一个模型解释其分类或判断时,它很可能产生循环解释。例如,对于一个情感分析任务,当问及为何将句子"这部电影太棒了!"归类为正面时,模型可能会回答"因为该句子的情感是积极的"。这种解释虽然在字面上正确,但并未提供任何新的语义洞察,仅仅是用不同的词语重述了结论,这正是循环解释的典型特征 。这种现象反映出模型可能并未真正理解情感背后的语义特征(如"棒"是褒义词),而只是学习到了标签与输入文本之间的浅层关联。
2.3. 知识溯源与推理链中的循环引用
大型语言模型通过在海量文本数据上进行预训练来获取知识 。如果训练数据中包含循环定义(例如,词典中"A"的定义依赖于"B",而"B"的定义又依赖于"A"),模型可能会内化这种循环逻辑。在需要进行多步推理或知识溯源的任务中,这种内化的循环性可能导致模型在推理链中陷入死循环。例如,在回答"为什么天空是蓝色的?"这类问题时,模型可能生成一个看似科学的解释,但其内部的"知识链"可能最终会自我参照,而无法追溯到一个坚实的物理学原理,这在复杂的问答系统或虚拟助手中尤为关键 。
2.4. 语义相似度计算中的"回声室"效应
在语义相似度或文本蕴含任务中,模型需要判断两个句子的意义是否相近或存在推断关系。循环解释的悖论可能在此表现为一种"语义回声室"。例如,对于两个仅在句法结构上不同但词汇高度重叠的句子,模型(尤其是像BERT这样依赖双向上下文的模型 可能会给予极高的相似度评分,因为它主要关注词汇共现而非深层的逻辑或因果关系。这种判断本质上是循环的:"句子A与句子B相似,因为它们包含了相似的词语",而忽略了这些词语在不同结构下可能产生的语义差异。
3. 对具体NLP应用的影响与挑战
循环解释悖论的这些表现形式对NLP应用的可靠性和实用性构成了严峻挑战。
-
对话系统与聊天机器人:在与用户交互时,如果一个聊天机器人或虚拟助手 陷入循环解释,会严重影响用户体验。用户期望得到有信息量的回答,而非同义反复或无关的重复。例如,当用户询问某个概念的定义时,一个陷入循环的系统可能会给出"A是A的属性"之类的无效回答,导致对话中断,用户信任度下降 。
-
机器翻译:在机器翻译任务中,虽然循环解释不那么直接,但其底层逻辑可能导致翻译质量下降。模型可能在处理复杂的从句或习语时,由于无法完全理解其深层语义,而产生一种"安全"但冗余的翻译,即通过重复源语言的某些结构或词汇来规避翻译难点,这可能导致翻译结果生硬、不自然,甚至丢失情感色彩 。
-
情感分析与文本摘要:在情感分析中,循环解释会使模型的可信度大打折扣,尤其是在需要模型提供其决策依据的场景(如内容审核)。在文本摘要任务中,模型可能会陷入重复提取关键句的循环,生成的摘要只是原文某些部分的简单拼接,而未能真正提炼和概括核心思想。
4. 缓解策略与未来研究方向
虽然目前尚无专门针对"循环解释悖论"的标准化评测基准 Results),但可以借鉴相关领域的研究为未来发展提供方向。
-
开发专门的评测基准:当前NLP领域的评测基准,如GLUE ,主要关注任务性能,而较少评估模型的逻辑一致性和解释的有效性。未来的研究需要设计专门的数据集和指标,用于检测和量化NLP模型中的循环推理和循环解释现象。这可能需要构建包含逻辑难题、需要多步推理或要求非循环解释的问答对。
-
改进模型架构与训练机制:Transformer架构虽然强大,但其固有的注意力机制可能使其倾向于关注表面模式而非深层逻辑 。探索新的架构,如引入外部知识图谱、记忆网络或符号推理模块,可能有助于模型打破语义循环,建立更稳固的知识基础。此外,训练过程中可以引入对抗性样本,专门挑战模型的循环推理倾向。
-
提升模型的可解释性与因果推理:推动可解释AI(XAI)的研究,从简单的特征归因(如LIME, SHAP)发展到能够展示清晰、非循环推理链的解释方法 。反事实解释(Counterfactual Explanations)等技术虽然本身也面临悖论问题 但其探索因果关系的方向是正确的,有助于强制模型思考"为什么是这个结果,而不是另一个"。
-
人机协同与反馈循环:在实际应用中,可以设计人机协同系统,当模型产生可疑的循环解释时,系统可以请求人类用户澄清或提供额外信息 。这种反馈可以被用于模型的持续学习和微调,逐步减少其产生循环解释的倾向。
5. 结论
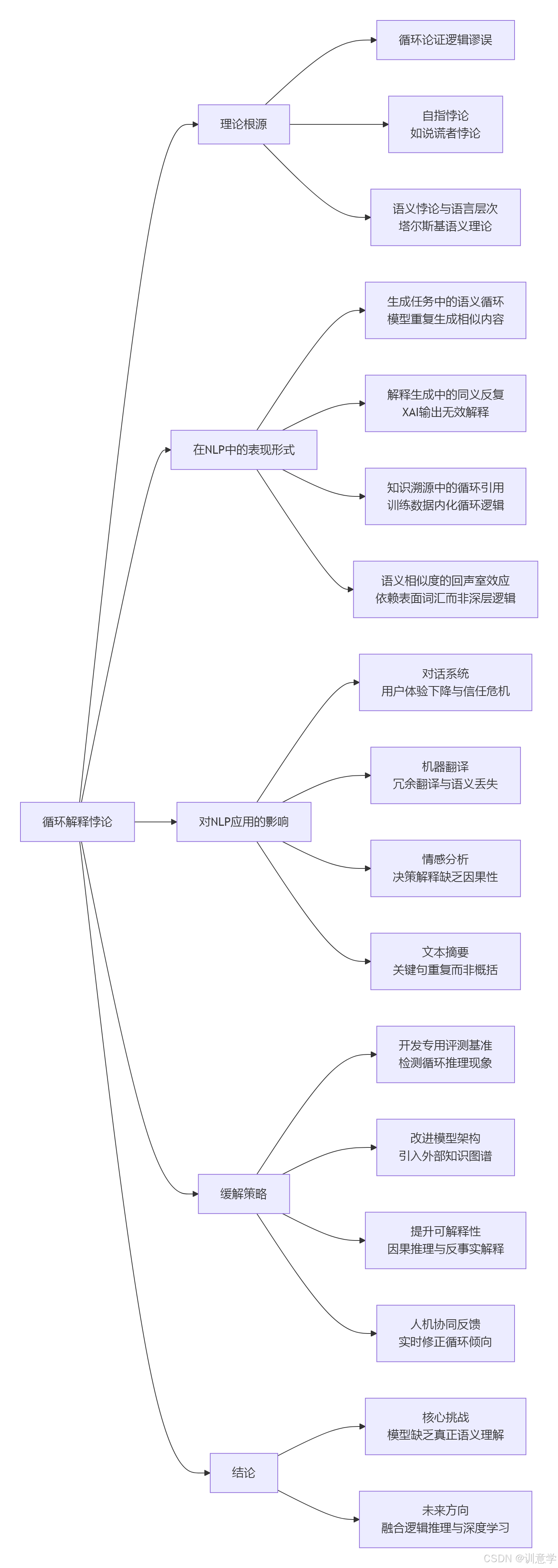
语义与认知中的循环解释悖论,虽然是一个源于哲学和逻辑学的古老问题,但在人工智能时代,尤其是在大型语言模型日益普及的今天,呈现出新的、严峻的挑战。当前,NLP模型,特别是基于Transformer架构的模型,在进行深层语义分析时,确实存在陷入重复生成、同义反复式解释和循环推理的风险。这不仅限制了它们在关键应用场景下的可靠性,也暴露了其在真正意义上的"理解"方面的短板。未来的研究必须正视这一问题,通过开发新的评测方法、改进模型架构和训练策略,并增强模型的可解释性和因果推理能力,才能推动NLP从模式匹配向真正的语义理解迈进。
以下是Python代码示例,用于检测文本中的循环解释模式:
import re
from collections import Counter
import nltk
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
class CircularExplanationDetector:
def __init__(self):
self.circular_patterns = [
r'(\w+)就是\1',
r'因为.*所以.*',
r'本质上就是.*',
r'简单来说就是.*'
]
self.stop_words = set(stopwords.words('chinese'))
def detect_circularity(self, text):
"""
检测文本中的循环解释模式
"""
results = {
'circular_score': 0,
'patterns_found': [],
'repetition_ratio': 0,
'suggestions': []
}
# 检测预定义模式
for pattern in self.circular_patterns:
matches = re.findall(pattern, text)
if matches:
results['patterns_found'].extend(matches)
results['circular_score'] += len(matches)
# 计算重复率
tokens = self._preprocess_text(text)
repetition_ratio = self._calculate_repetition_ratio(tokens)
results['repetition_ratio'] = repetition_ratio
# 生成改进建议
if results['circular_score'] > 0 or repetition_ratio > 0.3:
results['suggestions'] = self._generate_suggestions(text)
return results
def _preprocess_text(self, text):
"""文本预处理"""
tokens = word_tokenize(text)
tokens = [token.lower() for token in tokens
if token.isalnum() and token not in self.stop_words]
return tokens
def _calculate_repetition_ratio(self, tokens):
"""计算文本重复率"""
if len(tokens) == 0:
return 0
token_counts = Counter(tokens)
repeated_tokens = sum(1 for count in token_counts.values() if count > 1)
return repeated_tokens / len(token_counts)
def _generate_suggestions(self, text):
"""生成改进建议"""
suggestions = [
"避免使用同义反复的解释",
"提供具体的例子或证据",
"从不同角度阐述概念",
"使用因果推理而非简单重复"
]
return suggestions
# 使用示例
if __name__ == "__main__":
detector = CircularExplanationDetector()
# 测试文本
test_texts = [
"人工智能就是让机器具有智能的技术",
"这个概念很好因为它是一个优秀的概念",
"语义理解就是理解语义的过程"
]
for i, text in enumerate(test_texts):
print(f"文本 {i+1}: {text}")
result = detector.detect_circularity(text)
print(f"循环解释得分: {result['circular_score']}")
print(f"重复率: {result['repetition_ratio']:.2f}")
print(f"检测到的模式: {result['patterns_found']}")
print(f"改进建议: {result['suggestions']}")
print("-" * 50)