引言(Introduction)
本章将介绍 Snowflake 生态中的人工智能(AI)与机器学习(ML)。内容涵盖核心 AI 概念、AI 与生成式 AI(Generative AI)的影响与工作原理;同时说明 Snowflake 作为云数据平台的角色,以及在数据科学与机器学习中的优势。
读完本章,你将理解 AI、ML 与生成式 AI 的基本原理及其对各行业的变革;也会了解 Snowflake 的架构及其在数据科学与机器学习工作流中的优势。此外,你将认识 Snowpark ML------一款用于在 Snowflake Data Cloud 内简化 ML 模型创建、训练与部署的 Python 库。
结构(Structure)
本章将覆盖以下主题:
- AI 革命(The AI Revolution)
- 生成式 AI 的崛起(The Rise of Generative AI)
- 作为云数据平台的 Snowflake 概览
- Snowflake 入门
- Snowflake Cortex 概览
- Snowpark ML 概览
- Snowpark ML 实战
AI 革命(The AI Revolution)
我们生活在一个被 AI 深刻塑造的世界:从流媒体推荐到导航系统,AI 已融入日常。究竟什么是 AI?为何被称为"革命性"?
从本质上看,AI 是让机器完成通常需要人类智能的任务,包括学习、问题求解、决策,以及理解与生成语言。与其说是"机器人接管世界",不如说是构建能分析海量数据、识别模式并进行预测的系统,且在很多方面超越人类能力。
"革命"的意义在于其变革潜力。如同工业革命改变制造业、数字革命改变通信,AI 正在重塑医疗、金融、交通、娱乐等行业。它不仅是对既有流程的自动化,更在于开启过去难以想象的新可能。
虽然 AI 的概念已存在数十年,但算力提升与数据激增推动了其飞速发展:包括机器学习算法的突破、互联网与物联设备产生的数据洪流、深度学习的崛起,以及生成式 AI 的爆发。
AI 在各行业的影响(The Impact of AI across Industries)
举例如下:
- 医疗:辅助诊断、药物发现、个性化医疗。
- 金融:反欺诈、算法交易、风险管理。
- 交通:自动驾驶有望重构出行方式。
- 制造:机器人与自动化提升效率与生产率。
- 客服:聊天机器人与虚拟助手提供 24/7 服务。
- 教育:个性化学习、批改自动化与强化辅导。
- 零售:个性化推荐、库存管理、需求预测。
- 农业:精准农业、作物健康监测、产量预测。
- 能源:能效优化、预测性维护、智能电网。
- 网络安全:实时威胁检测、强化防御、自动化响应。
生成式 AI 的崛起(The Rise of Generative AI)
在 AI 创新浪潮中,生成式 AI 尤为颠覆。传统 AI 侧重"分析、预测、识别模式",生成式 AI 则更进一步------生成。它可在文本、图像、音频、视频、代码、3D 模型等多模态上产出全新内容。
生成式 AI 的核心是强大的机器学习模型------如大语言模型(LLM)与扩散模型(diffusion models) ------在海量多样的数据上训练,学习数据的底层模式、语法与结构。一旦训练完成,模型即可生成与训练材料质量与风格高度一致的原创内容,往往与人类作品难以区分。
你可以把它类比为一位研究了成千上万幅画作的艺术家:吸收技法、风格与配色后,能创作出带有个人表达的新作品。类似地,生成式 AI 将所学知识与计算创造力相结合,产出新颖、有吸引力且高度个性化的结果。
这种规模化生成新内容的能力,正在营销、娱乐、软件开发、设计、教育、医疗等领域打开新空间。它不仅是技术飞跃,更在重构我们在 AI 时代的创作、沟通与问题求解方式。
生成式 AI 的工作原理概览
许多生成式模型基于深度学习,典型架构包括 生成对抗网络(GAN) 与 Transformer。
- GAN:由生成器与判别器两个网络博弈,生成器产出内容,判别器区分真伪。
- Transformer :擅长处理文本、音频等序列数据,凭借"注意力机制(attention) "在生成时关注输入的不同部分,已成为生成式 AI(尤其文本任务)的基石。
关键构件:
- 神经网络:AI(含生成式 AI)的基础,由多层互联"神经元"处理信息。
- 生成模型:用于生成与训练数据分布相似的新数据。
- GAN:生成器与判别器对抗训练。
- Transformer:基于注意力机制高效建模序列,生成质量与可控性突出。
生成式 AI 的影响与潜力
生成式 AI 的革命性不仅在技术,更在通用性与可迁移性:可适配多行业、多语言与多模态,理解具体上下文并进行个性化生成。其影响可比肩互联网或移动浪潮,正在重塑企业运营、专业决策与人与技术的交互方式。
- 医疗:加速药物设计、模拟疾病进程、个性化治疗方案。
- 制造:生成最优产品设计、用合成数据预测设备故障、创建高仿真训练环境。
- 金融:强化反欺诈、支持高频交易策略、为消费者提供超个性化的理财建议。
- 娱乐:生成写实角色、动态剧本、沉浸式游戏环境,甚至作曲。
- 零售:AI 生成推荐、虚拟试穿、智能库存优化。
- 教育:个性化学习、AI 家教、自适应内容。
- 科研:自动生成假设、复杂系统仿真、自治化数据分析。
而这仅是起点。随着技术成熟与普及,生成式 AI 将持续增强人类智能、促进创新并自动化创意 。要释放其潜能,企业需要安全、可扩展、深度对接数据生态的基础设施。
这正是 Snowflake Cortex 的价值所在。作为 Snowflake Data Cloud 内原生的 AI/ML 平台,Cortex 使组织能够在不挪动数据、不中断治理与安全 的前提下利用强大的生成式模型:从文档摘要与洞察生成,到智能对话与预测应用,在数据所在之处将生成式 AI 工业化落地,确保治理、性能与易用性。无论是 LLM 原型试验还是生产级 AI,上手与落地都更轻松。
作为云数据平台的 Snowflake 概览
在以数据为中心的当下,传统数据仓库难以应对数据规模(Volume) 、速度(Velocity)与多样性(Variety) 。Snowflake 不是"又一个数据库",而是完全托管、云原生 的数据平台,专为现代数据分析挑战而生,其独特架构将计算(Compute)与 存储(Storage)解耦,带来前所未有的弹性伸缩、灵活性与成本效益。
一个类比:传统数仓像把烤箱、炉灶、冰箱固定在一起的一体化厨房;Snowflake 则是模块化厨房------需要烤很多蛋糕(跑复杂查询)时就扩大"烤箱"(计算),只做三明治(轻量探索)时再缩回;数据变多了,就扩容"冰箱"(存储),而不会拖慢"烤箱"性能。
这种存储-计算分离是变革点:两者可独立伸缩、按需付费。需要在海量数据上运行复杂查询?临时放大计算,用完缩回。遇到数据激增?只扩容存储,查询性能不受影响。这种弹性对工作负载与数据量波动的企业至关重要。
除弹性外,Snowflake 还有这些优势:
- 全托管:平台负责基础设施、补丁、升级与安全,释放团队生产力;
- 多类型数据支持:结构化、半结构化(如 JSON、XML)乃至非结构化数据统一分析;
- 数据共享:在组织内外安全共享实时数据,解锁协作与数据变现新模式;
- 高并发:多用户与多应用可同时访问而互不干扰,分析师、数据科学家与业务用户共享同一事实来源。
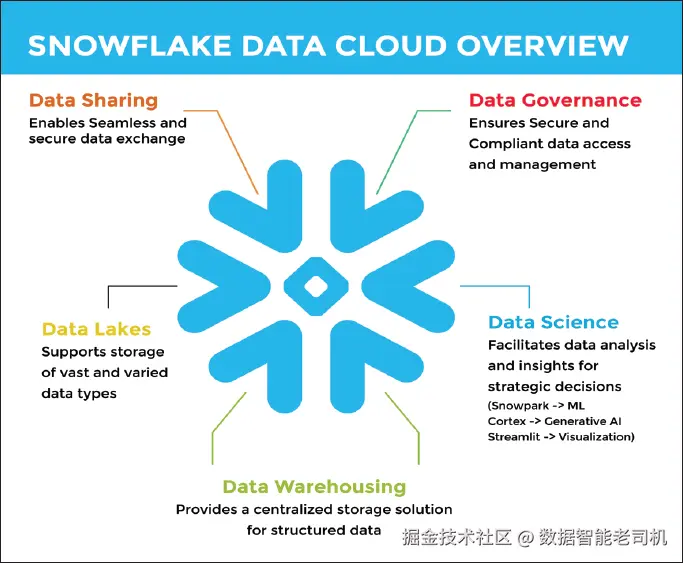
图 1.1:作为云数据平台的 Snowflake(Figure 1.1)
归根结底,Snowflake 为现代数据需求提供了云端解法:解耦计算与存储、支持多样数据、促进数据共享,以更高的可用性与易用性释放数据价值,是 AI(尤其生成式 AI)落地的关键使能平台,后文将进一步展开。
在当下监管环境中,健全的数据治理尤为关键。Snowflake 提供一整套功能以确保数据质量、安全与合规:
- 基于角色的访问控制(RBAC) 、数据掩码 、行级别安全,精细化控制"谁能看什么、如何使用";
- 数据血缘(Data Lineage) 帮助追溯数据来源与变更,利于审计与合规;
- 与多种治理工具的生态集成,便于融入既有治理框架。
Snowflake 中的数据科学(Data Science in Snowflake)
Snowflake 是一个稳健而强大的数据科学与机器学习平台,提供端到端能力,支持大规模构建智能应用。它既能处理超大规模数据集,又原生支持多种编程语言与工具,非常适合现代数据科学工作流。借助 Snowpark for ML ,数据科学家可以在 Snowflake 内部直接构建、训练并部署复杂的机器学习模型------无需把数据搬出平台 。这确保了在 Snowflake 弹性算力之上,使用熟悉的 Python 生态(如 Pandas 、Scikit-learn)进行安全且高性能的模型开发。
在生成式 AI(Generative AI)方面,Snowflake Cortex 提供原生的大语言模型(LLM)能力,使团队能够在受治理的企业数据之上直接构建有上下文感知 的助手、摘要工具、智能文档处理与问答系统。结合 Cortex Search 与 Cortex Analyst ,组织可以在非结构化 与结构化 数据之上打造强大的生成式 AI 对话式体验。为将洞察"可视化",Streamlit 让你在与 Snowflake 直连的前提下构建直观、交互式的可视化与 AI 应用,帮助团队实时探索结果、驱动决策。存储、处理、机器学习、生成式 AI 与可视化之间的紧密集成,显著加速了在单一统一平台上开发与上线 AI 应用的全流程。
本质上,Snowflake 为你的全部数据需求提供了现代化的云端方案:它具备传统数据仓库难以匹敌的可扩展性、灵活性与易用性。通过计算与存储解耦、支持多样化数据类型、启用数据共享,并提供强大的数据治理与数据科学能力,Snowflake 赋能组织释放数据的全部潜能,做出更优的业务决策。它为未来的数据分析而生,尤其是释放 AI(特别是生成式 AI) 能力的关键平台,后续章节将继续展开。
AI 革命仍处在早期阶段。人人理解 AI 基础正变得愈发重要。因此,本书聚焦如何在 Snowflake Data Cloud 内 harness(驾驭)AI 与生成式 AI 的力量。Snowflake 提供稳健、可扩展的平台以构建与部署 AI 解决方案;它处理海量数据的能力与对多种 AI/ML 工具的支持,是训练与部署生成式 AI 模型的关键。
在接下来的章节里,我们将深入讲解如何利用 Snowflake 释放数据潜能,并在你的组织内推动创新。
开始使用 Snowflake(Getting Started with Snowflake)
要上手 Snowflake,用户可注册免费试用账号,即可访问平台的全套功能,包括数据存储、处理与 ML 能力。步骤如下:
- 访问官网 :前往
www.snowflake.com,点击 Start for Free(免费开始)。 - 选择云厂商 :Snowflake 运行在 AWS、Azure、Google Cloud 上。请选择你偏好的云商。本书示例新特性以 AWS 为主。
- 选择区域 :选择 AWS West 区域(大多 LLM 相关特性在此区域可用)。
- 填写注册信息:包括姓名、邮箱、公司信息等。
- 邮箱验证:提交后查收验证邮件,按指引激活账号。
- 环境初始化:首次登录后,Snowflake 会提供向导,帮助你创建数据库(databases)、虚拟仓库(warehouses)以及初始配置。
认识 Snowflake 界面(Understanding the Snowflake Interface)
登录后,你将使用 Snowsight(Snowflake Web 界面)。核心模块包括:
- Databases :存放并管理结构化数据。
- Warehouses :用于查询与处理数据的虚拟计算资源。
- Worksheets :SQL 编辑器,可编写与执行查询。
- Notebooks :交互式笔记本 ,用于探索性数据分析、开发与 AI 工作流;类似 Jupyter Notebooks ,但原生内置于 Snowflake。
- Streamlit :使用 Python 与 Snowpark 在 Snowflake 内直接构建与部署交互式数据应用,无需搬移数据。
- Dashboards :用图表与表格可视化展示查询结果 ,将多种可视化组合为可交互、可分享 的单一界面,并且实时直连 Snowflake 数据。
- Apps(Snowflake Native Apps) :在 Snowflake 平台内构建与交付的安全、驻留数据的应用(如分析或 ML),让提供方向使用方交付功能而无需迁移数据。
- Admin Console:安全设置、角色管理、系统使用指标等。
- Monitoring :实时监控查询性能、仓库使用、用户活动与资源消耗,助你优化成本、排障并保障平台健康。
- AI/ML Studio :Snowsight 内的零/低代码 界面,可在平台内构建、训练、部署 分类、预测、异常检测等 ML 模型;也可微调 LLM 、构建 Cortex Search 与 Cortex Analyst 服务。
向 Snowflake 加载数据(Loading Data into Snowflake)
你可以通过以下方式加载数据:
- Snowsight(Web UI) :在"Load"功能中浏览或拖拽 CSV、JSON 等文件至目标表。
- SnowSQL :命令行工具,支持从本地进行批量数据加载。
- 外部云存储 :通过 Stage 与 COPY 命令,从 AWS S3 / Azure Blob Storage / Google Cloud Storage 等外部存储加载数据。
Snowflake Cortex 概览(Snowflake Cortex Overview)
现在你已完成 Snowflake 账号的搭建,我们来探索 Snowflake Cortex ,看看它如何简化并加速你的 AI/ML 计划。本节作为概览,后续章节将深入展开 Cortex 的各项能力。Snowflake Cortex 是 Snowflake Data Cloud 内的全托管服务,使用户能够在数据所在之处 直接开展机器学习与人工智能工作,原生集成大语言模型(LLMs)与生成式 AI(Generative AI) 。它打通了从数据准备、特征工程到模型训练、部署与监控的全生命周期 ,并覆盖 LLM 与生成式 AI 相关的复杂流程。通过在 Snowflake 内进行模型构建与执行,Cortex 免除了将数据迁出到外部系统的需要,显著提升效率,消除数据孤岛。对需要处理训练/微调 LLM 与生成式模型所需的超大规模数据集的场景而言,这种与数据的紧密耦合尤为有利。
Cortex 为 LLM 与生成式 AI 提供了一套完整的工具与功能:包含对预训练 LLM 的访问,并可在 Snowflake 内基于你的专有数据进行便捷微调,从而更轻松地适配文本生成、摘要、文档智能、搜索代理与问答等任务。面向生成式 AI,Cortex 提供训练与部署模型所需的基础设施与工具,覆盖图像生成、文本合成、代码生成等多种创作类应用,同时充分利用 Snowflake Data Cloud 原生的可扩展性与安全性。Cortex 的目标是让 AI 更加大众化:通过简化复杂的 ML 流程(尤其与 LLM 和生成式 AI 相关的部分),并将其与所需数据无缝集成,使数据科学家、数据工程师与业务分析师都能轻松上手。对于希望利用包括尖端 LLM 与生成式 AI 在内的 AI 技术,从数据中获取洞察、做出数据驱动决策并开辟创新路径的组织而言,Cortex 是关键工具。
Snowflake Cortex AI 的主要目标 是:在 Snowflake Data Cloud 内简化并加速 AI/ML 模型的构建、部署与管理;通过屏蔽大量传统 ML 工作流中的复杂性,让更多角色(数据科学家、数据工程师、甚至业务分析师)都能触达 AI。具体而言,Cortex 的核心作用包括:
- 消除数据搬移:无需将数据迁出 Snowflake 到外部系统执行 AI/ML 任务,从而避免数据孤岛、降低延迟并提升安全性;同时可充分利用平台的弹性与治理能力。
- 简化模型开发:提供预构建模型、支持自定义模型(含主流 ML 框架),并具备自动化训练与部署能力,降低非专家用户的门槛。
- 加速模型上线:精简部署流程,帮助组织更快迭代并将模型投入生产。
- 改进模型管理:提供监控与生命周期管理工具,确保模型长期保持准确与有效。
- AI 大众化:通过流程简化与平台整合,让更多内部角色能利用 AI 从数据中获得洞察并做出更优决策。
- 支持 LLM 与生成式 AI:提供获取与简化使用前沿 LLM 与生成式模型的能力,在 Snowflake 环境内处理文本生成、摘要、图像处理等任务;借助基于 LLM 的对话式 AI 与文档处理能力,让与数据的交互更简单、直观且强大。
简言之,Snowflake Cortex 旨在让 AI 更易用、高效、并与数据深度融合,帮助组织释放数据的全部价值,推动数据驱动的创新。
Snowpark ML 简介:在 Snowflake 中赋能数据驱动的机器学习
尽管本书主要讲解 Snowflake Cortex AI 的能力,这一节将简要概述 Snowpark ML 及其在 Snowflake 生态中的持续价值。Cortex 提供强大的预构建 AI/ML 与广泛的生成式 AI 能力,而 Snowpark ML 作为基础层,在 Cortex 体系下仍为特定场景提供灵活性、可定制性与更深的集成 。本章将简要介绍 Snowpark 与 Snowpark ML 的基本概念。
Snowpark:让计算更靠近你的数据
Snowpark 标志着你在 Snowflake 中与数据交互方式的转变:它允许你用熟悉的编程语言(Python、Java、Scala )在 Snowflake 环境内直接执行代码。也就是说,你可以在不抽取/不搬移数据 的前提下完成复杂的数据转换、聚合与自定义逻辑------这正是 Snowpark 的核心优势:将计算带到数据身边,从而在性能、安全与治理上获得新层级的能力。
Snowpark 的能力要点
- 强安全边界:Snowpark 代码在 Snowflake 的安全边界内执行,数据受严格安全策略保护,最大程度降低未授权访问与泄露风险,适用于敏感数据场景。
- 多语言支持:可按需选择 Python、Java 或 Scala,并通过语言特定 API 与 Snowflake 生态无缝衔接。
- 生态扩展性 :可使用丰富的库与包;在 Python 中可利用 Pandas 、NumPy 及专项领域库,处理仅凭 SQL 难以覆盖的复杂问题。
- 稳健的数据管道:直接在 Snowflake 内用 Snowpark 构建复杂的数据管道与转换,简化架构、降低传统 ETL 复杂度,并提升可维护性与适应性。
- 弹性算力:与 Snowflake 弹性计算引擎深度整合,面对海量数据与重计算任务可自动扩展,无需你管理底层基础设施。
- 统一生态:与表、视图、存储过程等原生组件顺畅集成,在既有 Snowflake 框架下用熟悉的编程范式与数据协作。
Snowpark 的工作方式
- 建立连接 :从你的客户端应用(如 Python 脚本)通过 Snowpark session 连接到 Snowflake。
- 提交代码:用所选语言编写数据处理逻辑并提交至 Snowflake 执行。
- 在 Snowflake 内执行:Snowflake 计算引擎接收代码,将其智能转换为优化后的查询,并直接在数据云中的数据上处理。
- 返回结果:处理结果返回到你的客户端应用。
Snowpark ML 的 Python API 在编写与执行 位置上提供灵活性:你既可以在 Snowflake Notebooks 或 Snowsight Worksheets 内直接工作,也可以在本地偏好的 Python IDE 中开发,并连接至 Snowflake 利用 Snowpark ML 的算力与能力。
数据云中的机器学习(Machine Learning in the Data Cloud)
Snowpark ML 构建在 Snowpark 之上,把机器学习能力直接带入 Snowflake 环境。它是一款 Python 库,旨在简化在数据云(Data Cloud)中、基于驻留于 Snowflake 的数据来创建、训练与部署机器学习模型。
图 1.2:Snowpark ML------关键特性(Key Features)
为了构建机器学习模型,Snowpark 提供 ML Modeling APIs 。这些 API 支持高效的数据加载、特征工程与模型训练,并可利用 CPU 或 GPU 的分布式处理 实现可扩展性。
在特征管理方面,Snowflake ML 提供 Feature Store (特征库)。这一集中式库帮助你组织、存储与共享特征 ,确保跨项目的一致性与复用。
借助 Snowflake 的 ML Modeling API ,你可以在 Snowflake 内部 、使用 scikit-learn、LightGBM、XGBoost 等主流 Python 框架直接构建机器学习模型。也就是说,从数据预处理、特征工程到模型训练,全程都无需离开 Snowflake 环境。
在模型部署与管理方面,Snowflake ML 提供 Model Registry (模型登记库)。它支持存储、版本化与跟踪你的模型,简化部署流程,并促进数据科学团队之间的协作。
Snowpark ML 的优势:
- 消除数据搬移瓶颈:Snowpark ML 直接在 Snowflake 内对数据进行操作,无需繁琐的数据抽取与传输,显著降低延迟、简化流程并强化数据安全。
- 可扩展的训练引擎 :利用 Snowflake 的弹性计算引擎,快速高效地在任意规模数据集上训练模型------不再为训练耗时数天而等待。
- 一站式 ML 全生命周期 :在 Snowflake 内部一地完成数据准备、特征工程、模型训练、部署乃至监控。
- 对数据科学家友好的接口 :Snowpark ML 的 API 贴近 scikit-learn 等流行库,便于数据科学家沿用既有经验快速上手。
- 无缝的模型部署与管理 :已训练模型可作为 Snowflake 对象 保存,并通过 UDF(用户自定义函数) 、存储过程(stored procedures)或 Snowpark Container Services 在 Snowflake 内无缝部署,支持实时打分或批量预测。
- 强力的数据安全:Snowpark ML 继承了 Snowflake 内建的安全能力,确保整个 ML 流水线中敏感数据始终受到保护。
Snowpark ML 实战(Snowpark ML in Action)
如上所述,Snowpark ML 让端到端的机器学习工作流直接 在 Snowflake 内完成,无需外部环境。通过结合 Snowpark 强大的数据处理能力与 Snowpark ML 原生的模型训练/部署能力,组织可以将 ML 无缝集成 进其数据管道。下面概述关键步骤,确保在 Snowflake 内实现高效、可扩展且安全的机器学习:
- 数据准备 :使用 Snowpark 在 Snowflake 内加载、预处理、变换并进行特征工程 。复杂数据整形常会用到 Pandas(在 Snowpark 执行环境中运行)。
- 模型训练 :利用 Snowpark ML 的 estimators(估计器) 在准备好的数据上训练模型。训练在 Snowflake 内进行,充分利用其分布式计算能力。
- 模型登记库(Model Registry) :在 Snowflake 内创建集中式库,用于管理与组织已训练的机器学习模型。
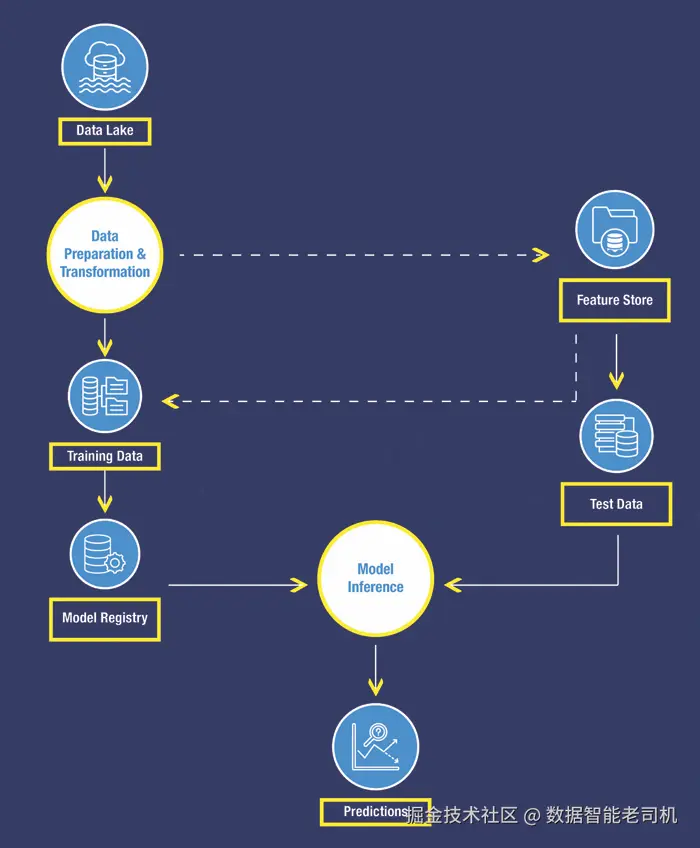 图 1.3:Snowpark ML 实战(in Action)
图 1.3:Snowpark ML 实战(in Action)
使用 Snowflake Notebooks
Snowflake Notebooks 提供在 Snowflake 内直接编写 SQL 与 Python 代码的交互式协作环境。它支持:
- 在统一界面中编写、执行与可视化 SQL / Python 脚本;
- 与 Snowpark 与 Snowflake Cortex 等 AI/ML 工具无缝集成;
- 实时协作,多位用户可同时在同一 Notebook 上工作;
- 版本与可复现性,便于跟踪变更、维护结构化工作流。
借助 Snowflake Notebooks,用户可以在 Snowflake 环境内高效原型、试验与部署 AI/ML 模型,无需外部 Jupyter Notebooks 或第三方工具。
使用 Snowpark ML 构建一个预测模型(示例:贷款审批)
为理解端到端流程,我们构建一个贷款审批概率 预测模型。数据集包含银行存量客户的基础信息及其财务属性(如收入、账户存续期等),用于预测其贷款是否可能获批 。在本书后续内容中,我们将基于该示例,演示 Snowpark ML 的预处理、建模与模型登记等能力。
前置条件(Prerequisites):
-
为本练习创建专用数据库:
iniCREATE DATABASE SNOWPARK_ML_DEMO; -
从 Dataset 文件夹导入
loan_data.csv至SNOWPARK_ML_DEMO.PUBLIC.LOAN_DATA(在 Snowsight 中定位该数据库,使用 Create -> Table -> from file ;加载时勾选 "First Line contains header" )。 -
新建 Notebook:
在 Snowsight -> Projects -> Notebooks 菜单中,选择 Import .ipynb ,导入 Scripts 文件夹提供的 "Predictive Model with Snowpark ML.ipynb" 。数据库选择 SNOWPARK_ML_DEMO ,并指定任一 warehouse,点击 Create。
-
下面按 Notebook 中的步骤执行。
步骤 1:导入所需库(Importing Required Libraries)
在右上角 Packages → Find Packages 安装以下两包:
snowflake-ml-pythonsnowflake-snowpark-python
在第一个单元格导入数据处理、机器学习与 Snowpark 相关库;同时用warnings抑制不必要的警告,提升可读性。
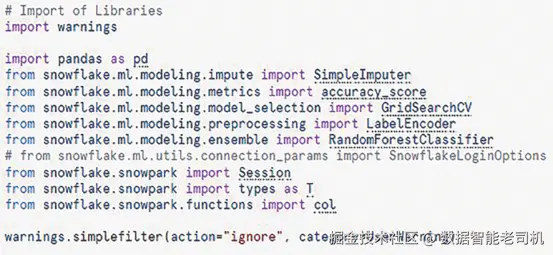
markdown
**图 1.4:导入所需库**步骤 2:导入 Snowflake ML Registry(模型登记库)
加载用于在 Snowflake 中存储、管理与检索已训练模型的 Registry 模块。

图 1.5:导入 Registry
步骤 3:获取活动的 Snowflake 会话(Active Session)
建立一个活动的 Snowflake 会话,以便执行 Snowpark 操作。

图 1.6:获取会话
步骤 4:将贷款数据加载为 DataFrame
从 LOAN_DATA 表读取数据,载入 Snowpark DataFrame ;使用 show() 展示数据样例。
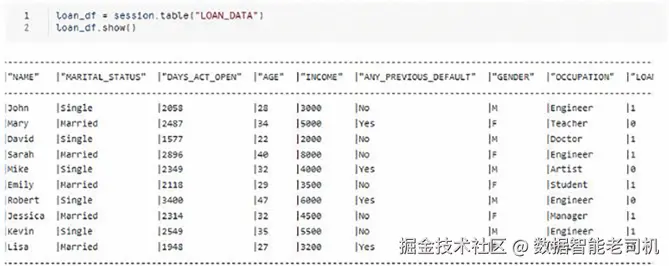
图 1.7:加载数据
步骤 5:区分类别与连续型变量
分别定义类别特征 与连续特征列,便于后续预处理。

图 1.8:区分类别/连续变量
步骤 6:缺失值填补(Imputation)
对类别列使用 SimpleImputer 以众数填补缺失值。

图 1.9:缺失值处理
步骤 7:类别变量编码(Label Encoding)
将类别取值转为数值表示(标签编码)。

图 1.10:标签编码
步骤 8:删除无用列
移除 NAME 列(与本次建模无关)。

图 1.11:删除无关列
步骤 9:数据集划分
按 80% 训练 / 20% 测试划分,并设置固定随机种子确保可复现。

图 1.12:训练/测试集划分
步骤 10:初始化并训练随机森林分类器
创建 Random Forest Classifier,指定输入特征、目标标签与输出列;在训练集上拟合模型。

图 1.13:训练随机森林
步骤 11:设置模型登记库(Model Registry)
在 Snowflake 中使用模型前,需要先将其登记 到 Model Registry。该安全的集中式仓库可管理任意来源/类型的模型及其元数据,并简化推理流程。以下命令初始化登记库,为记录模型做准备。

图 1.14:初始化 Registry
步骤 12:登记模型(Logging the Model)
将已训练模型以 V1 版本登记到 Snowflake 的模型登记库。

图 1.15:登记模型
步骤 13:列出已登记模型
查看登记库中保存的所有模型(此处仅有我们刚创建的一个)。

图 1.16:列出模型
步骤 14:列出模型版本
检索并展示 LOAN 模型的各版本(当前仅 V1;在真实环境中通常会有多个历史版本)。
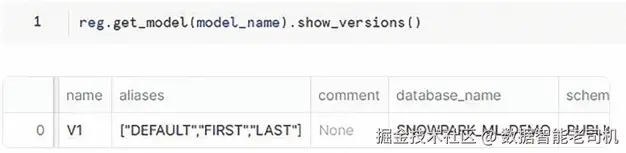
图 1.17:列出版本
步骤 15:设置默认模型版本
将 V1 设为部署与预测的默认版本。

图 1.18:设为默认版本
步骤 16:推理(Inference)
使用已登记模型对测试集进行贷款审批预测。

图 1.19:在测试集上预测
步骤 17:验证模型准确率
评估模型的准确率;可观察到模型表现较高。

图 1.20:验证准确率
步骤 18:将测试结果写回 Snowflake 表
将预测结果直接写入 Snowflake 表,以便后续分析。

图 1.21:将测试结果存表
本示例以清晰的"逐步操作 "展示了 Snowpark ML 的实际应用------从数据准备、模型构建、评估、登记与版本管理到推理,全流程都在熟悉的 Snowflake 环境中完成。
结语(Conclusion)
Snowpark ML 通过把计算直接带到 Snowflake 内部的数据之上,彻底改变了机器学习模型的开发与部署方式。它消除了数据搬移的需求,从而降低延迟 、提升数据安全 、并简化 整条 ML 工作流。借助 Snowpark 的分布式处理能力与 Snowflake 的可扩展架构,组织能够在任意规模与复杂度 的数据上高效 完成模型训练与部署。凭借对端到端 ML 流程的精简与贯通,Snowpark ML 让数据团队以前所未有的效率与可扩展性来构建、部署并运营化机器学习模型。
在奠定了 Snowpark ML 的基础、并明确其在自定义 AI/ML 方案中的角色之后,我们已准备好更深入地走进 Snowflake 更广泛的 AI 生态。如前所述,Snowflake Cortex 提供了一系列预构建 的 AI/ML 服务,用以补充与增强 Snowpark ML。自下一章起,我们将详细探索 Cortex ,了解它如何进一步简化你的 AI 规划 、并加速数据科学工作流。