引言(Introduction)
在深入探讨 Cortex 的生成式 AI(Generative AI)能力之前,先了解其原生机器学习(ML)函数 是有价值的,这将为理解平台的高级分析能力打下坚实基础。Snowflake 将人工智能(AI)与机器学习(ML)能力原生引入 Data Cloud,使企业能够将预测性分析 无缝集成到业务流程中。借助内置 ML 函数 ,用户无需深厚的数据科学背景,便可完成分类(classification) 、预测(forecasting) 、异常检测(anomaly detection)与 自动洞察(automated insights)等任务。这些函数为全托管 ,无需关心基础设施,同时确保可扩展性与性能。
这些函数可通过 SQL 查询 访问,便于熟悉数据库操作的数据分析师与数据工程师直接使用。通过将 ML 能力与数据仓库深度融合 ,Snowflake 免除了数据搬移,简化了从海量数据中提取价值洞察的过程。
本章将介绍 Snowflake 中的核心 ML 函数 ,说明它们如何简化数据驱动决策。读完本章,你将清楚地掌握如何在多种业务场景中使用这些 ML 函数。
结构(Structure)
本章将涵盖以下内容:
- Snowflake 机器学习函数的关键优势
- 将数据上传至表与 Stage 的流程
- Classification(分类)函数
- Forecasting(预测)函数
- Anomaly Detection(异常检测)
- Top Insights(关键洞察)函数
- 关于 Snowflake AI and ML Studio 的说明
Snowflake 机器学习函数的关键优势(Key Benefits)
Snowflake Cortex ML 函数正在改变企业在自身数据生态中使用机器学习的方式。它把高级分析 的能力直接带到熟悉的 Snowflake 环境里,让各类规模的组织更容易释放数据潜能。通过将 ML 与现有数据工作流无缝融合,Cortex ML 函数打破了采用门槛,为组织带来新可能。
无论你是经验丰富的数据科学家,还是首次尝试预测分析的业务分析师,这些函数都能简化复杂流程 、支持准实时洞察 ,满足数据驱动时代不断演进的业务需求。以下是让 Snowflake Cortex ML 成为"游戏规则改变者"的关键优势:
- 简单易用(Simplicity) :仅用 SQL 即可调用 ML 函数------无需大量编码或数据工程工作。
- 自动数据准备(Automatic Data Preparation) :常见预处理(缺失值处理、异常点检测、格式化等)自动完成,减少人工介入。
- 原生集成(Native Integration) :在 Snowflake 平台内原生执行 ML 任务,无需搬移数据或依赖外部工具。
- 协作友好(Collaboration) :直观的使用方式让技术与非技术角色都能参与 ML 项目,更好对齐业务目标,推动包容性的数据决策。
- 可扩展性(Scalability) :针对海量数据做了性能优化。
- 安全与治理(Security & Governance) :数据不离开 Snowflake,更易满足合规与治理要求。
- 运维高效(Operational Efficiency) :函数全托管,无需管理底层基础设施。
各函数分别面向不同类别的 ML 任务------从预测分析到自动化异常检测。下面将从分类函数开始,逐一展开。
说明 :本书在讲解 Snowflake Cortex AI 的过程中,会创建多种机器学习模型、函数与洞察。为确保结构化与高效的工作流,我们将在可能的情况下使用
CORTEX_AI_DB作为专用存储空间 来保存所有与 ML 相关的对象,并在该库的PUBLICschema 下创建对象。先创建该数据库:
iniCREATE DATABASE CORTEX_AI_DB;
将数据上传到表与 Stage 的流程(Process to Upload the Data to Tables and Stages)
在全书示例中,我们会把文件加载到表 或Stage。可参考以下步骤。
从文件加载为表(Load Table from File)
- 登录 Snowsight。
- 从提供的目录下载示例 CSV 文件。
- 在 Snowsight 左侧菜单选择 Data > Add Data。
- 选择 Load data into a Table。
- 选择并上传 CSV 文件。
- 选择 schema:
CORTEX_AI_DB.PUBLIC(或文中指定的其他 schema),并勾选 create a new table。 - 将新表名 设置为与文件名一致,点击 Next。
- 在左侧 File Format 下展开视图选项。
- 确认 Header 选项为 First Line contains Header。
- 点击 Load。
上传文件到 Stage(Upload Files to Stage)
- 登录 Snowsight。
- 在左侧导航选择 Data。
- 选择数据库
CORTEX_AI_DB(或指定的库)与 schemaPUBLIC。 - 打开 Stages ,选择目标 Stage(如
CORTEX_AI_STG)。 - 右上角点击 + Files。
- 拖放 或浏览选择文件。
- 点击 Upload 完成上传。
Classification 函数(Classification Function)
分类 是基础的 ML 任务,目标是预测样本的类别/标签 。Snowflake Cortex 支持在数据仓库内直接构建与应用 分类模型:根据训练数据学习到的模式,将样本归入预定义类别 。该函数支持二分类 与多分类 ,可对类别型与数值型特征进行高效处理。
当你在 Snowflake 中创建分类模型时,模型会作为schema 级对象 存储。为此,你的角色需要在目标 schema 上具备权限:
CREATE SNOWFLAKE.ML.CLASSIFICATION。其权限语义与创建表/视图等其他 schema 级对象类似。
关键特性(Key Features):
- 使用**梯度提升(gradient boosting)**算法进行训练
- 同时支持二分类 与多分类
- 二分类 采用 AUC(area-under-the-curve) 相关损失
- 多分类 采用 logistic loss(逻辑损失)
典型用例(Use Cases):
- 客户流失预测(Churn) :识别可能取消订阅的客户。
- 欺诈检测(Fraud Detection) :基于历史数据识别可疑交易。
- 情感分析(Sentiment Analysis) :将评论归类为正面/负面/中性。
- 网络安全威胁检测:判断行为是"正常"还是"潜在恶意",用于预防入侵。
实现(Implementation)
数据集:TRANSACTIONS.csv
为展示 Snowflake 的 ML 分类(classification)函数 ,本合成数据集模拟了 500 条交易记录 ,包含关键属性:交易金额、来源地点、设备类型及欺诈标签(0 = Legitimate,1 = Fraudulent)。可将该 CSV 文件加载到名为 TRANSACTIONS 的新表。数据已匿名化并结构化,适合用于基于交易模式的分类模型 预测。在执行以下步骤前,请先将数据加载到 TRANSACTIONS 表。本例用于说明 Snowflake ML Classification 的工作方式。
图 3.1:TRANSACTIONS 表快照(Snapshot)
第 1 步:创建训练集(CLASSIFY_TRAIN),随机抽样 TRANSACTIONS 的 80%
SAMPLE (80) 会随机选取约 80% 的行。
sql
CREATE OR REPLACE TABLE CLASSIFY_TRAIN AS
SELECT * FROM TRANSACTIONS SAMPLE (80);第 2 步:创建测试集(CLASSIFY_TEST),选取剩余 20% 数据,并移除无用列
NOT EXISTS 确保排除已进入训练集的记录。随后删除 TRANSACTION_ID 列(对建模无贡献)。
sql
CREATE OR REPLACE TABLE CLASSIFY_TEST AS
SELECT *
FROM TRANSACTIONS
WHERE NOT EXISTS (
SELECT 1
FROM CLASSIFY_TRAIN
WHERE TRANSACTIONS.TRANSACTION_ID = CLASSIFY_TRAIN.TRANSACTION_ID
);
ALTER TABLE CLASSIFY_TRAIN DROP COLUMN TRANSACTION_ID;第 3 步:使用分类函数创建模型
ini
CREATE OR REPLACE SNOWFLAKE.ML.CLASSIFICATION FRAUD_DETECTION_MODEL(
INPUT_DATA => SYSTEM$REFERENCE('TABLE', 'CLASSIFY_TRAIN'),
TARGET_COLNAME => 'FRAUDULENT'
);其中 SYSTEM$REFERENCE('TABLE', 'CLASSIFY_TRAIN') 指向包含 80% 抽样数据的训练表;TARGET_COLNAME 指定目标列 FRAUDULENT (0 = Legitimate,1 = Fraudulent)。
第 4 步:运行预测------创建结果表并存储测试集的预测输出
sql
CREATE OR REPLACE TABLE FRAUD_PREDICTION AS
SELECT
* EXCLUDE (FRAUDULENT),
FRAUD_DETECTION_MODEL!PREDICT(INPUT_DATA => OBJECT_CONSTRUCT(*)) AS prediction
FROM CLASSIFY_TEST;从 CLASSIFY_TEST 选取全部列,排除真实标签 FRAUDULENT ,便于后续独立对比。使用已训练模型 FRAUD_DETECTION_MODEL 对每条交易做预测。PREDICT 接收整行作为输入:OBJECT_CONSTRUCT(*) 将该行各列转换为用于推理的 JSON 对象。结果写入 FRAUD_PREDICTION 表。
第 5 步:查看预测结果表
sql
SELECT * FROM FRAUD_PREDICTION;
图 3.2:FRAUD_PREDICTION 表预览
如图所示,PREDICTION 列为 JSON ;需要解析其中的预测类别与概率以便展示。
第 6 步:解析预测结果到独立列
kotlin
SELECT
TRANSACTION_ID,
AMOUNT,
LOCATION,
DEVICE_TYPE,
prediction:class AS pred_class,
ROUND(prediction['probability'][prediction:class], 3) AS probability
FROM FRAUD_PREDICTION;从 prediction 对象中取出预测类别 prediction:class 为 pred_class;再从 prediction["probability"] 中取出该类别对应的概率 为 probability。
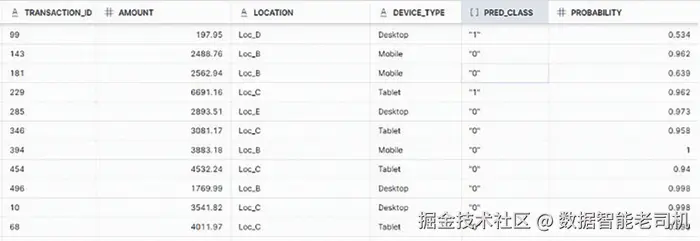
图 3.3:解析后结果预览
第 7 步:查看模型评估指标
scss
CALL FRAUD_DETECTION_MODEL!SHOW_EVALUATION_METRICS();该调用用于获取已训练分类模型的性能指标 (按预测类别给出),帮助在投产前评估准确性与有效性。
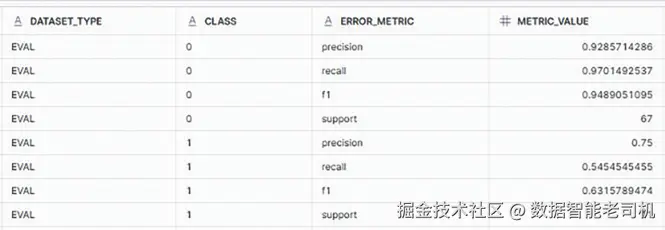
图 3.4:模型评估指标
第 8 步:理解特征重要性
scss
CALL FRAUD_DETECTION_MODEL!SHOW_FEATURE_IMPORTANCE();该调用返回各特征对欺诈预测的重要性排序,用于理解哪些因素对模型决策影响最大。

图 3.5:特征重要性
如图,AMOUNT(金额)影响最大,其次是设备类型 与交易来源地 。预期之内,TRANSACTION_ID 不应影响结果,可在建模脚本中排除。
上述实现展示了如何利用 Snowflake 原生 ML Classification 在 Snowflake Data Cloud 内端到端 地构建、训练与部署一个欺诈检测模型 。通过构建数据集 → 划分训练/测试 → 训练分类模型 → 运行预测 → 解析与解读结果 的结构化流程,可以看到 Snowflake Cortex ML 在真实业务任务中的简洁与高效 。接下来,我们将继续讲解 Forecasting(预测)函数。
Forecasting 函数(Forecasting Function)
Forecasting 函数 利用历史时间序列 数据预测未来的数值,对销售预测、需求预测、资源规划等业务场景极具价值。它采用包含**梯度提升(gradient boosting machines)**在内的复杂算法,来分析数据中的模式与趋势。
用户可用熟悉的 SQL 命令训练模型并生成预测,因而对数据分析师与精通 SQL 的从业者十分友好。该函数既支持单序列 ,也支持多序列数据,适配多种预测场景。
当你训练一个 Forecasting 模型时,模型会以schema 级对象 的形式存储。因此,创建模型的角色必须在目标 schema 上拥有 CREATE SNOWFLAKE.ML.FORECAST 权限,以确保模型能在该 schema 内被正确存取。
关键特性(Key Features):
- 分析指定指标随时间演化的方式
- 考虑多个因素对目标值的影响
- 基于识别到的趋势提供预测性洞察
- 支持**多序列(Multi-Series)**预测
典型用例(Use Cases):
- 销售预测:为库存管理预测产品需求
- 资源规划:基于使用模式预测人力或服务器需求
- 财务预测:为预算编制预测收入与支出
- 需求预测:前瞻产品需求以优化生产
- 工单量预测:预测客服工单的未来量级
实现(Implementation)
数据集:RETAIL_SALES.csv
为演示 Snowflake 的 ML Forecasting 函数,以下模拟数据集包含 90 天 的零售日销售 数据,包含两列:Date(时间戳)与 Sales(日收入)。通过分析历史销售模式,企业可生成数据驱动的预测,优化库存并有效规划营销策略。请先将该文件加载到名为 RETAIL_SALES 的新表中,再执行下述步骤。
第 1 步:查询销售表
该数据集适合使用 ML.FORECAST(Snowflake 内置的时间序列预测函数)来预测未来销售趋势。
sql
SELECT * FROM RETAIL_SALES;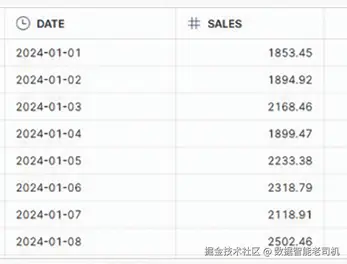
图 3.6:Daily Retail Sales 表
第 2 步:创建 Forecast 模型
ini
CREATE OR REPLACE SNOWFLAKE.ML.FORECAST SALES_FORECAST
(
INPUT_DATA => SYSTEM$REFERENCE('TABLE', 'RETAIL_SALES'),
TIMESTAMP_COLNAME => 'DATE',
TARGET_COLNAME => 'SALES',
CONFIG_OBJECT => { 'ON_ERROR': 'SKIP' }
);这里使用 SNOWFLAKE.ML.FORECAST 创建零售销售预测模型。
SYSTEM$REFERENCE('TABLE', 'RETAIL_SALES')指定输入数据表;TIMESTAMP_COLNAME设为DATE,保证时间序列结构;TARGET_COLNAME设为SALES,即待预测变量;- 可选的
CONFIG_OBJECT设置ON_ERROR: SKIP,遇到错误时跳过而不是整体失败。
第 3 步:生成预测并将结果落表
sql
BEGIN
CALL SALES_FORECAST!FORECAST(
-- 设置预测区间
FORECASTING_PERIODS => 14
);
-- 将预测结果落表
LET x := SQLID;
CREATE OR REPLACE TABLE RETAIL_SALES_FORECAST AS
SELECT * FROM TABLE(RESULT_SCAN(:x));
END;上述块调用 SALES_FORECAST!FORECAST 生成未来 14 天 预测,并通过 RESULT_SCAN(:x) 取回结果(:x 为该次执行的 SQLID),最终写入结构化表 RETAIL_SALES_FORECAST,便于后续分析、可视化或报表。
第 4 步:查询预测结果
sql
SELECT * FROM RETAIL_SALES_FORECAST;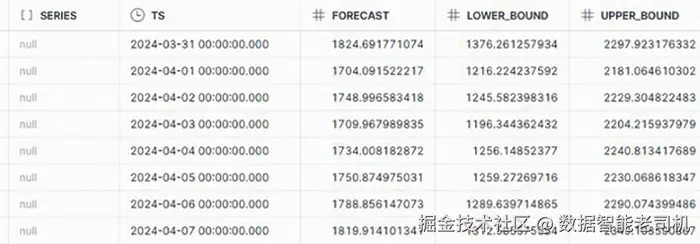
图 3.7:Retail Sales Forecast
series 列为 NULL 的原因是我们未定义类别列。若存在如 Sale_Category 的列,series 会将"电子产品""服装"等视为独立时间序列 ,从而产出分品类预测,无需为每个品类单独建模。
预测结果中的 上下界 表示置信区间(例如 95%):
- Upper Bound :区间上界,即预测可能达到的最高值;
- Lower Bound :区间下界,即预测可能达到的最低 值。
例如预测销售值为1000,上界1200、下界800,表示实际值大概率落在800--1200区间,用于弹性规划库存与资源。
第 5 步:可视化时间序列
可使用 Streamlit 构建小型应用,直观展示预测结果与历史曲线。
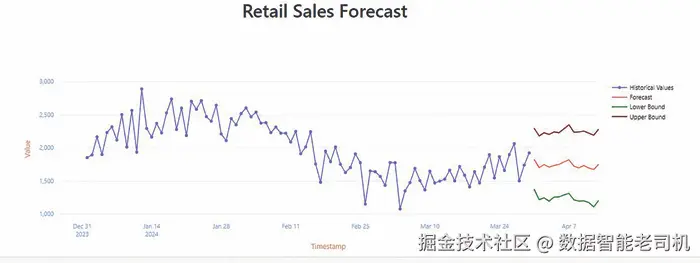
图 3.8:预测值可视化
如上所示,Snowflake 的 ML Forecasting 提供了强大、自动化且可扩展 的时间序列预测方案,并且完全在 Snowflake 环境内完成 。借助 SNOWFLAKE.ML.FORECAST,企业无需外部 ML 基础设施,即可无缝构建、部署与管理 预测模型。这种低代码、高性能 的方式,帮助组织做出数据驱动决策 ,优化库存、财务规划与资源调度 ,并在竞争中保持领先。同时,预测输出也可轻松集成到仪表盘与报表中。
接下来,我们将继续讲解 Anomaly Detection(异常检测)函数。
异常检测(Anomaly Detection)
Snowflake 的 ML 套件包含强大的异常检测 函数,帮助用户在时间序列 数据中识别离群点,而无需深厚的机器学习专业知识 。异常检测用于发现偏离预期模式 的数据点,对反欺诈、设备监控与网络安全等场景至关重要。
在 Snowflake 中创建异常检测模型需要相应权限。模型会作为schema 级对象 存储,因此用于创建模型的角色必须在目标 schema 上拥有 CREATE SNOWFLAKE.ML.ANOMALY_DETECTION 权限。这样可确保仅授权用户能在指定区域开发与保存异常检测模型,从而维护环境的安全与规范。
关键特性(Key Features):
- 基于 GBM(Gradient Boosting Machine) 算法
- 通过差分变换(differencing)建模非平稳趋势
- 引入自回归滞后项(auto-regressive lags)与历史滚动均值(rolling averages)
- 从时间戳自动生成周期性日历变量
- 结合自回归滞后项 与滚动均值进行趋势预测
典型用例(Use Cases):
- 金融反欺诈:标记可能暗示欺诈的异常交易
- 电商订单跟踪:发现异常发货时长或订单量,助力运营洞察
- 能耗分析:识别设施能耗的异常尖峰或骤降
- 库存管理:标记某商品异常库存或销售模式
- 异常登录追踪:检测异常认证行为,定位潜在安全威胁
实现(Implementation)
数据集:LOGIN_ANOMALY.csv
该数据集为用户登录行为的合成记录,用于演示 Snowflake ML 的异常检测。包含四列:
User_ID(用户唯一标识)Login_Time(登录时间戳)Login_Count(一定时间内的登录尝试次数)Is_Anomaly(二值标签:1=异常,0=正常)
请先将 LOGIN_ANOMALY.csv 加载到表 ANOMALY_DETECTION 中,再进行以下步骤。
第 1 步:查询数据表
sql
SELECT * FROM ANOMALY_DETECTION;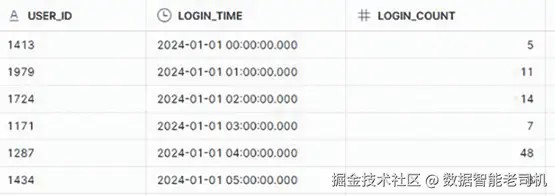
图 3.9:Anomaly Detection 表预览
该数据集将用于训练与评估异常检测模型,以识别短时间内过多登录等异常行为(可能表示可疑活动或安全入侵)。
第 2 步:划分训练与测试集
sql
CREATE OR REPLACE TABLE TRAIN_DATA_ANOMALY AS
SELECT * FROM LOGIN_ANOMALY
WHERE LOGIN_TIME <= '2024-01-19 07:00:00.000';
CREATE OR REPLACE TABLE TEST_DATA_ANOMALY AS
SELECT * FROM LOGIN_ANOMALY
WHERE LOGIN_TIME > '2024-01-19 07:00:00.000';上述语句按 LOGIN_TIME 时间戳切分原始 LOGIN_ANOMALY:
TRAIN_DATA_ANOMALY:包含截至 2024-01-19 07:00:00 的 440 行历史数据;TEST_DATA_ANOMALY:包含之后的 60 行 近期数据。
这样可用过去数据 训练异常检测模型,再用最近数据评估其识别能力。
第 3 步:创建异常检测模型
ini
CREATE OR REPLACE SNOWFLAKE.ML.ANOMALY_DETECTION LOGIN_ANOMALY_DETECTION(
INPUT_DATA => SYSTEM$REFERENCE('TABLE', 'ANOMALY_TRAIN'),
TIMESTAMP_COLNAME => 'LOGIN_TIME',
TARGET_COLNAME => 'LOGIN_COUNT',
LABEL_COLNAME => ''
);该语句使用内置 ML.ANOMALY_DETECTION 定义并训练名为 LOGIN_ANOMALY_DETECTION 的模型:
INPUT_DATA引用训练表(示例为ANOMALY_TRAIN);TIMESTAMP_COLNAME='LOGIN_TIME'表示考虑时间模式;TARGET_COLNAME='LOGIN_COUNT'指定要分析的目标序列(登录频次);LABEL_COLNAME=''为空,表示无监督(不依赖预先标注的异常标签),让模型基于历史模式自动识别异常。
注:如果你的表名是
TRAIN_DATA_ANOMALY,请相应替换INPUT_DATA的引用。
第 4 步:生成预测并落表
ini
BEGIN
-- 生成异常检测结果
CALL LOGIN_ANOMALY_DETECTION!DETECT_ANOMALIES(
INPUT_DATA => SYSTEM$REFERENCE('TABLE', 'ANOMALY_TEST'),
TIMESTAMP_COLNAME => 'LOGIN_TIME',
TARGET_COLNAME => 'LOGIN_COUNT',
-- 设置预测区间置信度
CONFIG_OBJECT => { 'prediction_interval': 0.95 }
);
-- 将检测结果写入表
LET x := SQLID;
CREATE OR REPLACE TABLE LOGIN_ANOMALY_DETECTION_RESULTS AS
SELECT * FROM TABLE(RESULT_SCAN(:x));
END;这里调用已训练模型对 ANOMALY_TEST 进行检测:prediction_interval=0.95 表示以 95% 预测区间来标记显著偏离 预期模式的点。结果通过 RESULT_SCAN(:x) 取回,并写入 LOGIN_ANOMALY_DETECTION_RESULTS ,其中包含异常评分/标记等信息,可供进一步分析与可视化。
第 5 步:校验预测结果
sql
SELECT TS, Y, IS_ANOMALY
FROM LOGIN_ANOMALY_DETECTION_RESULTS;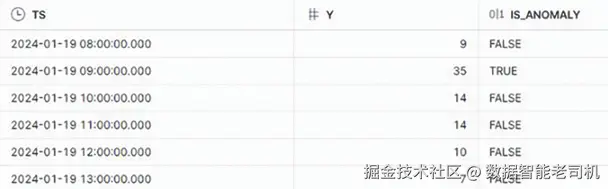
图 3.10:异常检测结果预览
可见包含 35 次登录尝试 的时间点被识别为异常。
如本例所示,ML.ANOMALY_DETECTION 为时间序列与数值数据提供了强大、可扩展且易用 的异常检测方案。企业可用简单 SQL 高效识别登录行为、交易模式、网络流量 等各类运营数据中的异常,而不必具备深厚 ML 专长。该函数与 Snowflake 现有数据无缝整合 ,支持快速训练、准实时检测与自动化落表;通过可配置的预测区间 等参数,用户还能调节灵敏度 以适配具体场景。先行发现离群点,能帮助组织提升安全、预防欺诈并优化系统性能。
接下来,我们将继续探索 Top Insights(关键洞察)函数。
Top Insights 函数(Top Insights Function)
Snowflake 的 Top Insights 机器学习函数可帮助企业更好地理解数据,找出指标随时间变化 或不同分组之间差异的主要原因。
Top Insights 尤其擅长定位关键业务指标 发生显著变化的驱动因素。比如,它可以解释上月销售额为何上升 ,或为何某些门店表现更好 。这能让企业基于事实而非猜测做出更明智的决策,并更容易制作清晰解释数据的报告与仪表盘。
借助 Top Insights ,企业可迅速聚焦最重要的信息,节省时间,让团队把精力放在真正能改进结果的事项上。
在创建模型的 schema 上,你需要具备
CREATE SNOWFLAKE.ML.TOP_INSIGHTS权限。
关键特性(Key Features):
- 快速定位随时间 或跨分群影响关键指标变化的因素
- 与熟悉的 SQL 命令无缝配合,无需深厚的机器学习背景
- 自动识别并监控对指标变化负责的关键分段,减少手工分析
- 使用决策树模型将数据集拆分为与目标指标行为相关、差异显著的分段
典型用例(Use Cases):
- 门店绩效对比:找出为何某些门店销售更高
- 网站流量分析 :理解访客量激增/下滑的原因
- 订阅续费模式:发现影响续费与否的关键因素
- 客户购买行为分析:识别驱动购买模式变化的主要因素,以优化销售策略
实现(Implementation)
数据集:PURCHASE_INSIGHTS.csv
该数据集包含 300 条客户购买 记录,用于演示 Snowflake ML Top Insights 函数。字段共六个:
Customer_ID(客户唯一标识)Age(年龄)Purchase_Amount(总购买金额)Category(商品品类,如 Electronics、Clothing、Grocery 等)Discount_Availed(是否使用折扣的二值标记)Membership_Status(会员类型,如 Regular 或 Premium)
该数据集适合识别关键购买趋势 及影响支出行为的重要因素 。请先将 PURCHASE_INSIGHTS.csv 加载为新表 PURCHASE_INSIGHTS,再执行以下步骤。
第 1 步:查询数据表
sql
SELECT * FROM PURCHASE_INSIGHTS;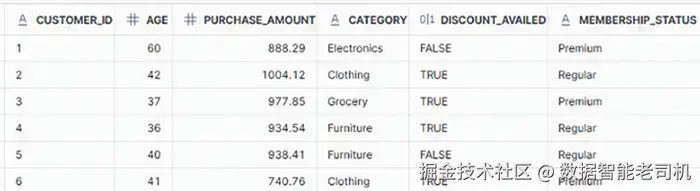
图 3.11:Purchase Insights 表预览
第 2 步:创建 Top Insights 模型
csharp
CREATE OR REPLACE SNOWFLAKE.ML.TOP_INSIGHTS my_insights_model();上述语句在 Snowflake 中初始化并创建 名为 my_insights_model 的 Top Insights 模型。我们将利用 ML.TOP_INSIGHTS 来识别影响 PURCHASE_AMOUNT 的最重要因素。
第 3 步:获取数据集的关键驱动因素(示例:折扣对购买的影响)
ini
CALL my_insights_model!get_drivers(
INPUT_DATA => TABLE(PURCHASE_INSIGHTS),
LABEL_COLNAME => 'DISCOUNT_AVAILED',
METRIC_COLNAME => 'PURCHASE_AMOUNT'
);CALL my_insights_model!get_drivers 会执行 my_insights_model,识别客户购买行为的关键驱动因素:
INPUT_DATA指定输入表PURCHASE_INSIGHTS;LABEL_COLNAME='DISCOUNT_AVAILED':分析折扣使用对购买的影响;METRIC_COLNAME='PURCHASE_AMOUNT':评估哪些变量最显著 地推动购买金额的升/降。
运行后,ML.TOP_INSIGHTS 将挖掘年龄、品类、会员状态 等变量在"折扣---支出"关系中的影响,帮助企业优化定价 、促销 与客户运营。
第 4 步:将结果落表
sql
CREATE OR REPLACE TABLE PURCHASE_INSIGHTS_RESULTS AS
SELECT * FROM TABLE (RESULT_SCAN(-1));把上一步 get_drivers 的最新结果保存到 PURCHASE_INSIGHTS_RESULTS 表中。RESULT_SCAN(-1) 用于提取最近一次查询的结果集。
第 5 步:查询结果并解读
sql
SELECT * FROM PURCHASE_INSIGHTS_RESULTS;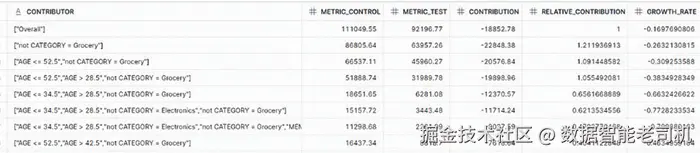
图 3.12:Purchase Insights 结果预览
在解读驱动因素时,常见指标包括:
CONTRIBUTION:度量每个驱动因素对购买的绝对影响,对比"使用折扣"与"未使用折扣"的差异,量化因素的直接影响。RELATIVE_CONTRIBUTION:相对贡献 ,即与其他因素相比的百分比影响,用于判断各因素的相对重要性。GROWTH_RATE:以百分比 衡量带标签与未带标签(如使用折扣 vs 未使用折扣)两组之间的增长/变化差异,反映标签的存在对指标的影响强度。
结果示例解读:
Top Insights 结果展示了"是否使用折扣"对购买金额的影响:
- 第 1 行(Overall Contribution)显示相较"未用折扣(False)","使用折扣(True)"对应的总购买额减少
$18,852.78,增长率下降16.98%; - 第 2 行指出排除 Grocery 品类 的购买,总支出减少
$22,848.38,对整体下降的贡献度 达121.14%。这暗示折扣对 Grocery 的拉动作用显著 ;当对 Grocery 不提供折扣时,总购买额会明显下滑。
Snowflake ML.TOP_INSIGHTS 为自动识别业务指标变化驱动因素 提供了强有力的手段,帮助组织高效 做出数据驱动决策。通过对结构化数据的分析,它能精准定位影响销售、客户行为、运营趋势 的关键因素,尤其适用于评估折扣策略、客户画像、品类结构等属性对结果变量的影响。
关于 Snowflake AI and ML Studio 的说明(A Note on Snowflake AI and ML Studio)
本章中,我们通过 SQL 命令 与脚本化的方式完成了模型创建与预测示例。以脚本驱动这些流程,有助于我们更深入地理解各个函数的工作原理:它允许把逻辑拆解为步骤并观察逐步执行的过程。我们的意图是帮助你充分把握每个函数的运作机制。
Snowflake AI and ML Studio 提供了直观的无代码(no-code)界面,简化了在 Snowflake 内部构建与部署机器学习模型的过程。该平台让用户无需大量编码知识即可利用先进的 AI 能力,从而覆盖更广泛的数据团队人群。
因此,借助 Snowflake AI and ML Studio ,用户可以轻松构建、测试并部署用于分类(classification) 、异常检测(anomaly detection)与 预测(forecasting)等任务的模型。无代码方式精简 了模型创建与评估流程,使组织能够更快地将 AI 融入数据工作流,并加速从开发到生产的迁移。
图 3.13:AI and ML Studio 中的 ML 函数
随着 Snowflake 持续增强其 AI/ML 能力,AI and ML Studio 将在普惠先进 AI 工具方面发挥关键作用,使更多团队得以利用机器学习的力量,推动各行业的创新。
结语(Conclusion)
本章我们介绍了 Snowflake 提供的机器学习函数套件 :分类(classification) 、预测(forecasting) 、异常检测(anomaly detection)与关键洞察(top insights) 。这些工具帮助数据分析师与数据科学家更深入地发掘数据价值,推动各业务领域的知情决策。
- Classification(分类) :将数据归入明确类别,支撑客户流失预测 、欺诈检测等场景。通过学习训练数据中的模式,企业能更好理解客户并预判潜在风险。
- Forecasting(预测) :利用历史数据预测未来趋势 ,帮助组织为即将到来的挑战与机遇做好准备。该能力在时间序列分析中尤为重要,能显著影响战略规划。
- Anomaly Detection(异常检测) :识别数据中的离群点 ,对发现可能暗示欺诈或系统故障 的异常模式至关重要。将其纳入数据管道,可在问题扩大前主动处置。
- Top Insights(关键洞察) :提供关键驱动因素分析 ,帮助组织理解指标随时间变化 的成因与关键分段,从而优化 BI 工作流的洞察产出。
综合来看,这些 ML 函数构成了一套完备的工具箱 ,助力数据驱动决策。将其融入业务运营,能够增强预测能力 、提升运营效率 ,并在快速演进的数据环境中驱动创新。随着机器学习不断发展,善用这些函数将日益成为保持竞争力、发掘数字时代新机遇的关键。
在接下来的章节中,我们将深入生成式 AI(Generative AI)的概念与应用,探讨其在生成新数据、增强创意与自动化复杂任务 方面的潜力;同时介绍 RAG(Retrieval Augmented Generation) 、**Prompt Engineering(提示工程)以及 向量检索(vector search)在信息检索中的作用。为理解 Cortex AI 更高级、尤其与大语言模型(LLMs)**相关的能力做好铺垫。