会议背景
近日,NeurIPS 2025公布了录用结果,该会议是机器学习与人工智能领域最具影响力的国际顶级学术会议之一。据悉本次会议共有21575篇投稿进入审稿阶段,最终5290篇论文被录用,录用论文中共有688篇论文(入选比例3%)被选为亮点文章(Spotlight)。
火山引擎多媒体实验室和北京大学合作的论文Q-Insight: Understanding Image Quality via Visual Reinforcement Learning ****被选为本次会议亮点文章。
Q-Insight:首个推理式画质理解大模型
论文背景
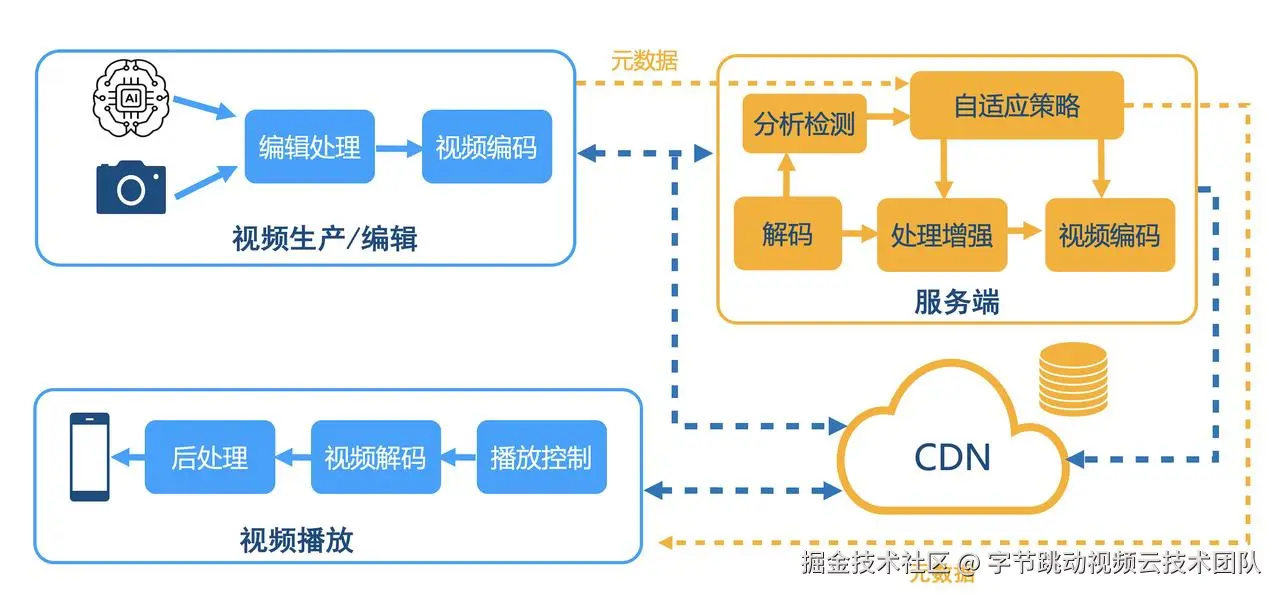
在音视频链路中,采集、压缩、处理、传输、播放等环节大多都基于一个核心问题展开,即人眼的画质感知。多模态大模型的快速发展为新时代的音视频技术带来了新的机遇,面对人眼感知的画质理解提供了一种全新的解决方案。
以往的画质理解的方法主要分为两类:(1)评分型方法,这类方法通常只能提供单一的数值评分,缺乏明确的解释性,难以深入理解图像质量背后的原因;(2)描述型方法,这类方法严重依赖于大规模文本描述数据进行监督微调,对标注数据的需求巨大,泛化能力和灵活性不足。
多任务群组相对策略优化
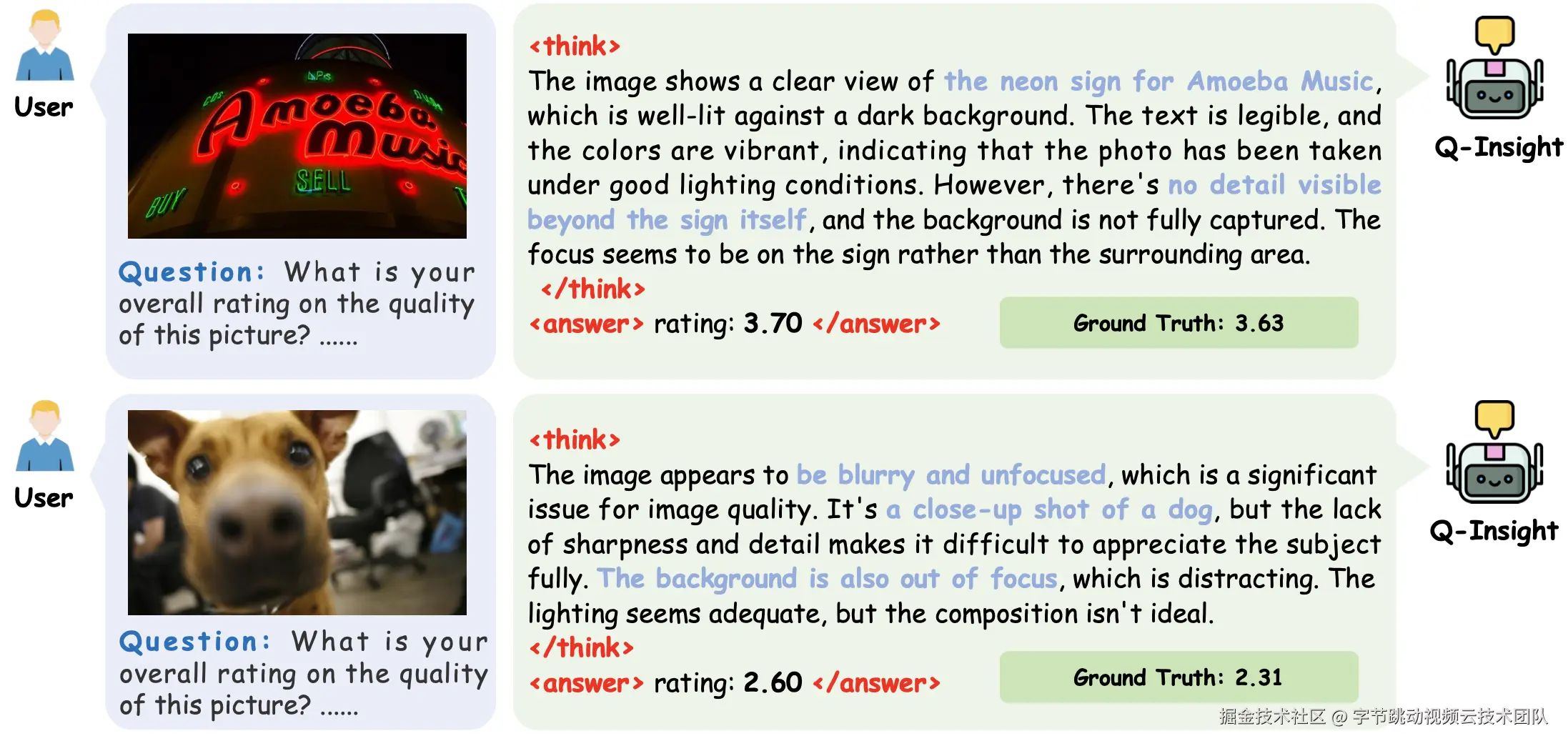
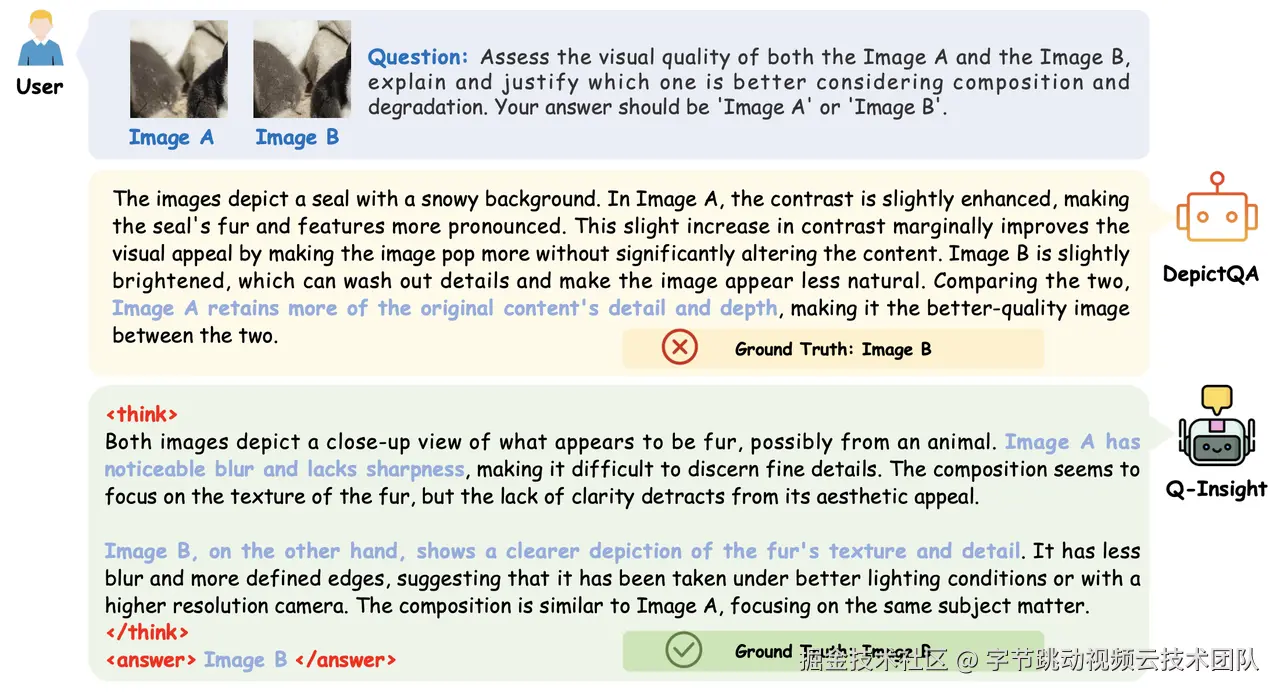
针对上述问题,北京大学与火山引擎多媒体实验室的研究人员联合提出了基于强化学习训练的多模态大模型图像画质理解方案Q-Insight。与以往方法不同的是,Q-Insight不再简单地让模型拟合人眼打分,而是将评分视作一种引导信号,创造性地运用了"群组相对策略优化"(GRPO)算法,不再依赖大量的文本监督标注,而是挖掘大模型自身的推理潜力,促使模型深度思考图像质量的本质原因。Q-Insight在质量评分、退化感知、多图比较、原因解释等多个任务上均达到业界领先水平,具备出色的准确性和泛化推理能力,并且不依赖大量高成本的文本数据标注。如图所示,Q-Insight不仅输出单纯的得分、退化类型或者比较结果,而是提供了从多个角度综合评估画质的详细推理过程。

在实际训练过程中,我们发现单独以评分作为引导无法充分实现良好的画质理解,原因是模型对图像退化现象不够敏感。为了解决这一问题,我们创新性地引入了多任务GRPO优化,设计了可验证的评分奖励、退化分类奖励和强度感知奖励,联合训练评分回归与退化感知任务。这种多任务联合训练的策略,显著提高了各个任务的表现,证明了任务之间存在的强互补关系。

实验结果
实验结果充分验证了Q-Insight在图像质量评分、退化检测和零样本推理任务中的卓越表现:在图像质量评分任务上,Q-Insight在多个公开数据集上的表现均超过当前最先进的方法,特别是在域外数据上的泛化能力突出,并能够提供完整详细的推理过程。
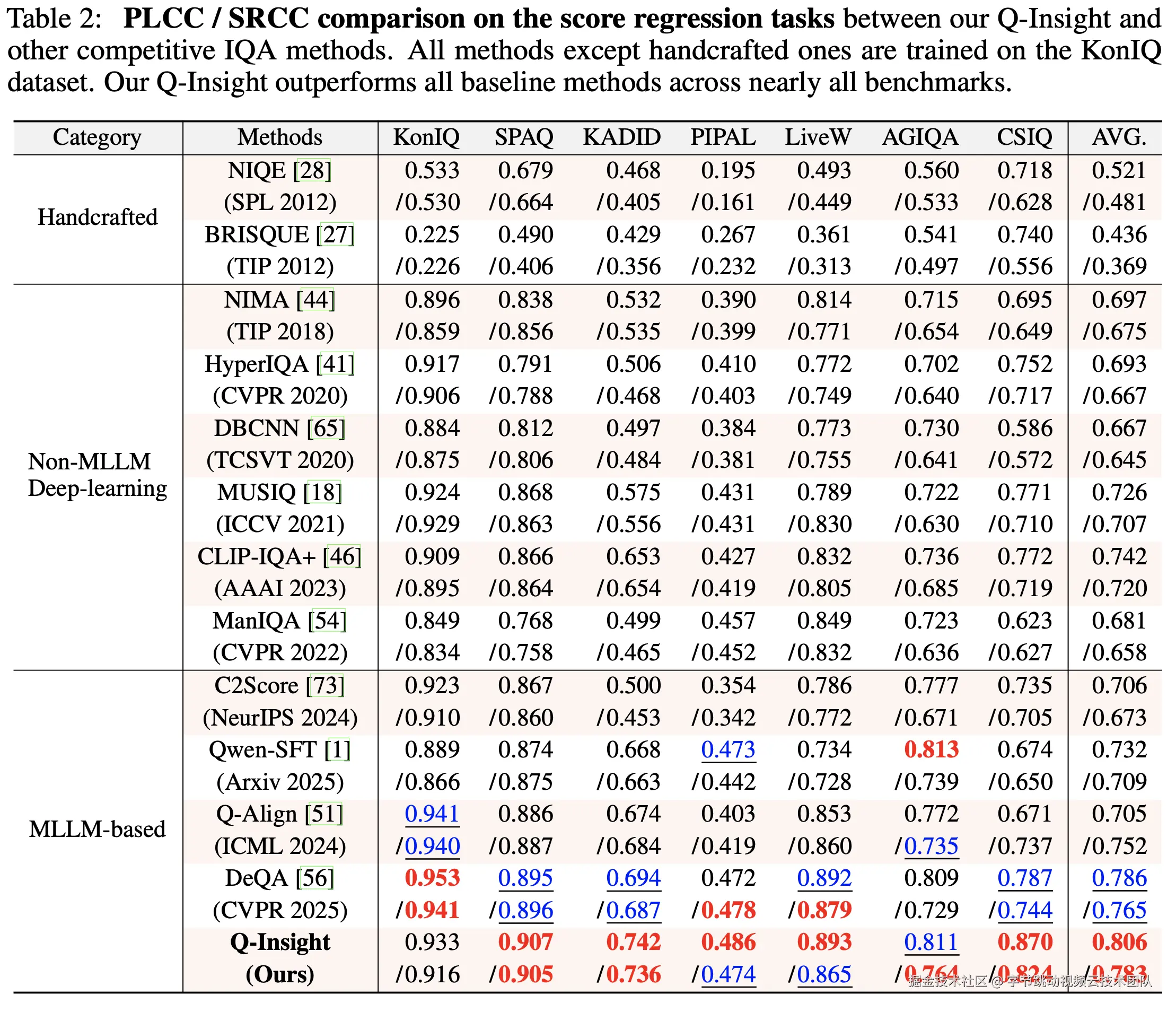
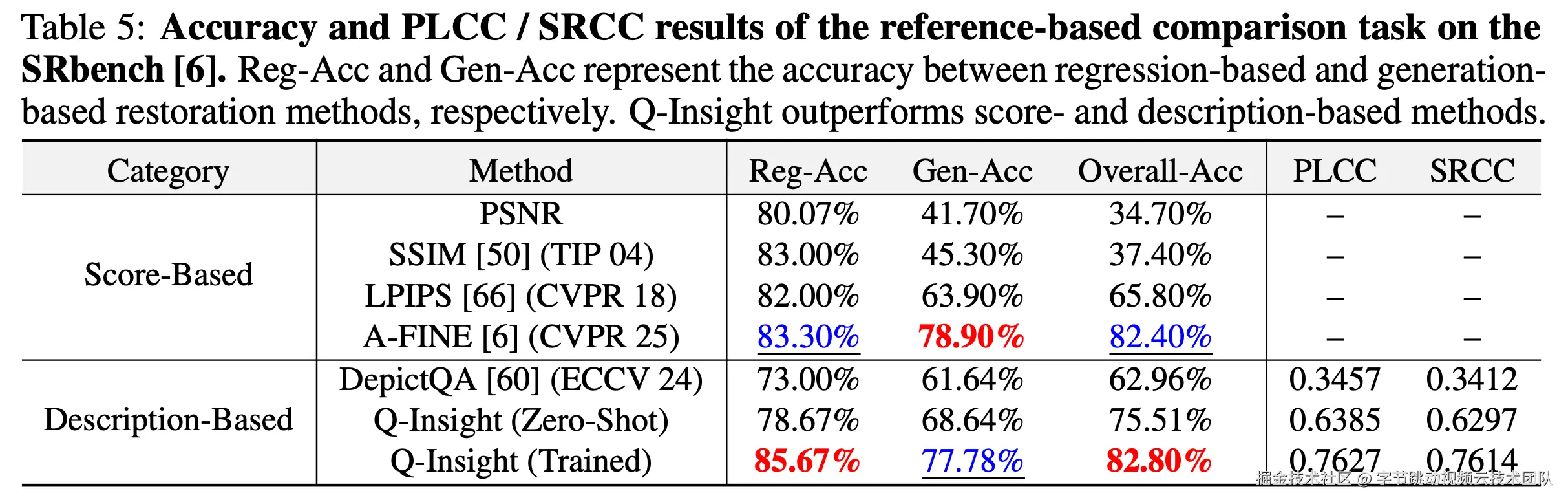
- 在图像质量评分任务上,Q-Insight在多个公开数据集上的表现均超过当前最先进的方法,特别是在域外数据上的泛化能力突出,并能够提供完整详细的推理过程。
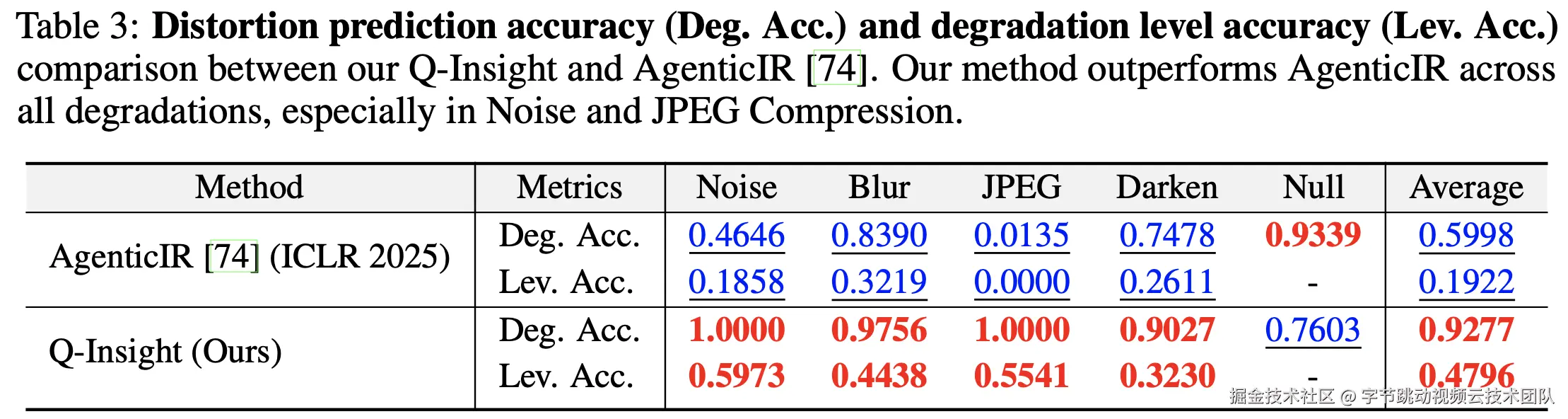
- 在退化感知任务上,Q-Insight的表现显著优于现有的退化感知模型,尤其是在噪声(Noise)和JPEG压缩退化类型识别的准确性上。
- 在图像比较推理任务上,Q-Insight可只需少量数据,即可超越当前最先进的图像比较方法。
从Q-Insight到VQ-Insight:AIGC视频画质理解大模型
图像只捕捉视频的一个切片,用户真实的视频观看体验还取决于时间维度:运动是否自然?色彩是否在动态中稳定?因此,我们把 Q-Insight 的"推理式 + 强化学习"思路,拓展到自然视频和AIGC视频的评估和偏好比较中,提出了 VQ-Insight。
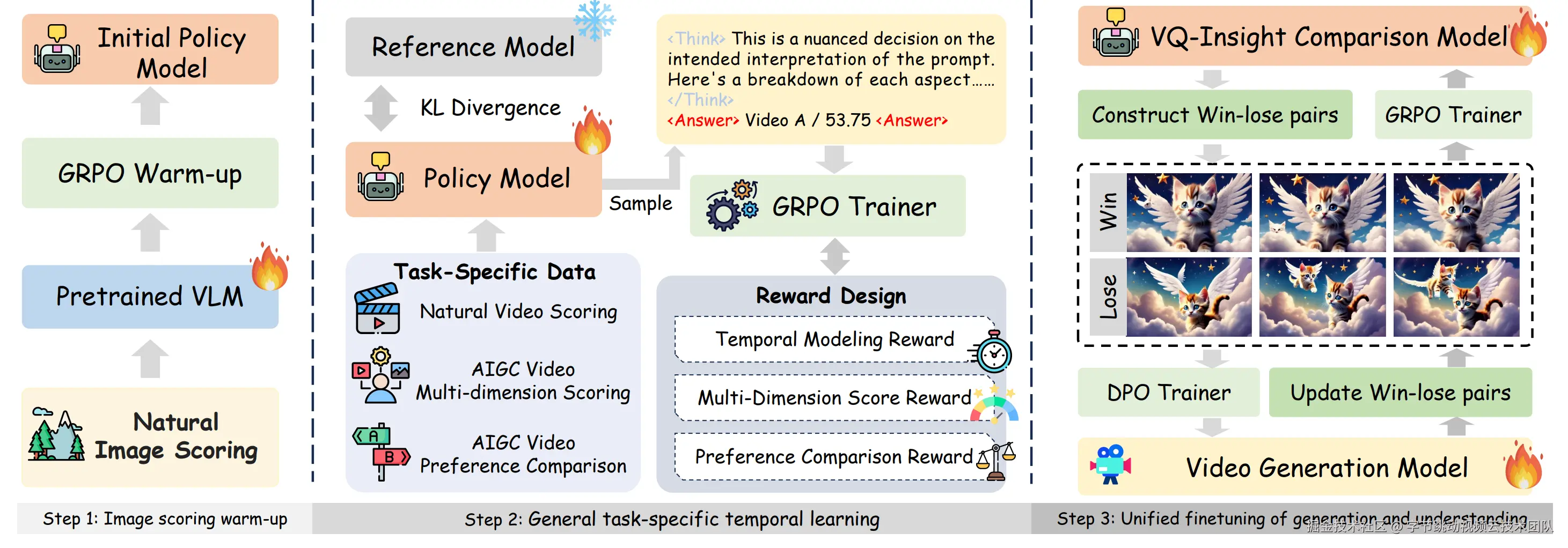
VQ-Insight强大的AIGC视频偏好比较能力,可直接应用于视频生成模型的直接偏好优化(DPO)。如图所示,基于VQ-Insight的方案相比于生成模型基线和对比方法,有效地缓解了错误生成的问题,并有着更鲜艳的色彩和动态。

相关链接
📄Q-Insight: arxiv.org/pdf/2503.22...
📄VQ-Insight: arxiv.org/pdf/2506.18...
⭐️训练与推理代码:github.com/bytedance/Q...
🤗开源模型:huggingface.co/ByteDance/Q...
总结
Q-Insight 将"感知-打分---比较---推理"统一到一个可解释的学习框架中,既给出可靠评分,也产出问题分析和可执行的改进线索;VQ-Insight 在此基础上把理解从帧内拓展到时域,支持真实/生成视频的连贯性与人类偏好一致性评估。未来,我们将进一步深度耦合强化学习与多模态推理------一方面,让 Q-Insight 走向更广任务(如图像美学评估),作为强判别信号驱动图像增强/重建,作为"质量评估中枢"联动各类重建工具;另一方面,让 VQ-Insight 成为生成视频训练的可插拔奖励与偏好模块,把"看得准"转化为"变得更好"。
团队介绍
多媒体实验室是字节跳动旗下的研究团队,致力于探索多媒体领域的前沿技术,参与国际标准化工作,其众多创新算法及软硬件解决方案已经广泛应用在抖音、西瓜视频等产品的多媒体业务,并向火山引擎的企业级客户提供技术服务。实验室成立以来,多篇论文入选国际顶会和旗舰期刊,并获得数项国际级技术赛事冠军、行业创新奖及最佳论文奖。