Hudi系列:Hudi核心概念(版本1.0)
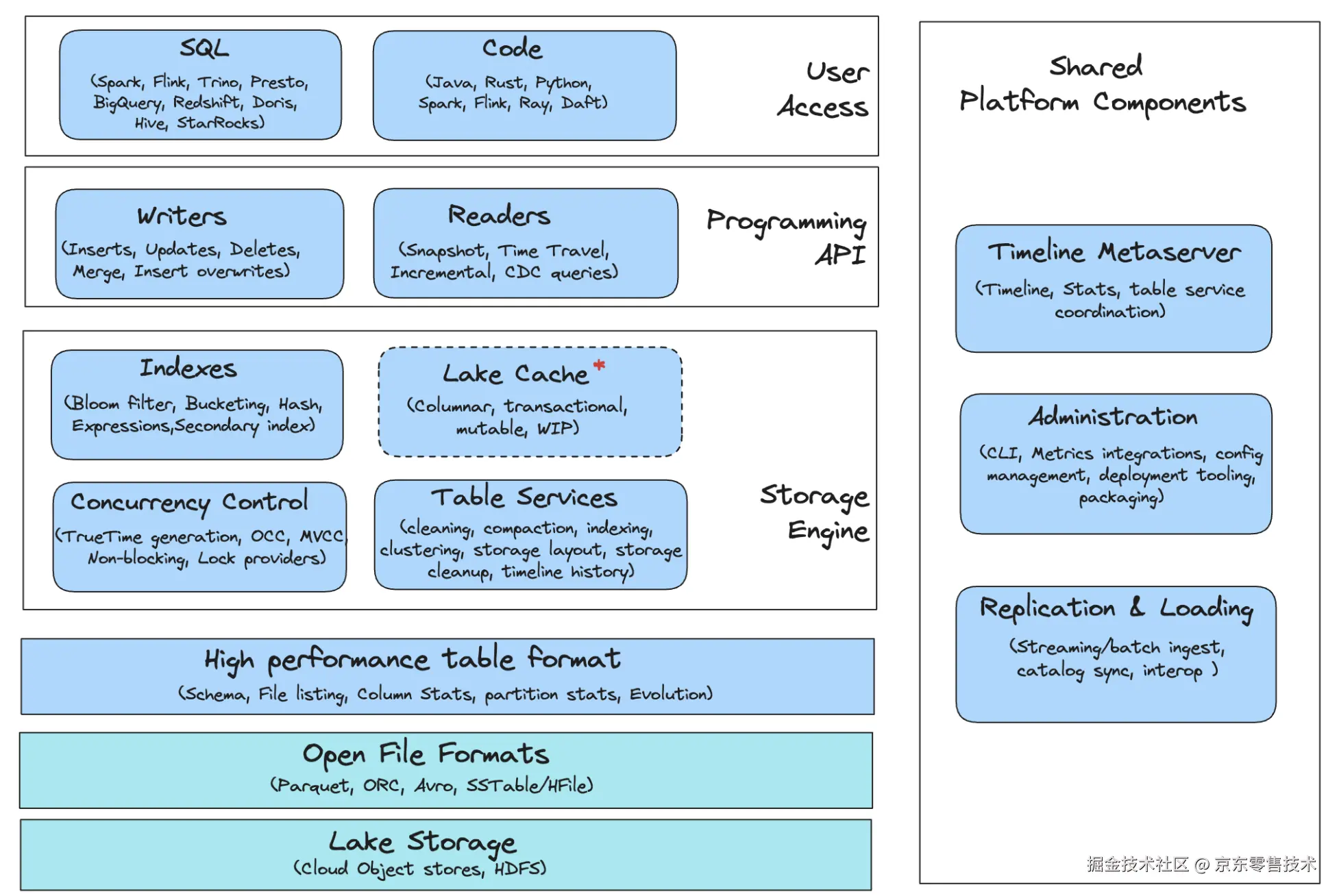
•Hudi架构
◦一. 时间轴(TimeLine)
▪1.1 时间轴(TimeLine)概念
▪1.2 Hudi的时间线由组成
▪1.3 时间线上的Instant action操作类型
▪1.4 时间线上State状态类型
▪1.5 时间线官网实例
◦二. 文件布局
◦三. 索引
▪3.1 简介
▪3.2 对比Hive没有索引的区别
▪3.3 Hudi索引类型
▪3.4 全局索引与非全局索引
◦四. 表类型
▪4.1 COW:(Copy on Write)写时复制表
▪4.1.1 概念
▪4.1.2 COW工作原理
▪4.1.3 COW表对表的管理方式改进点
▪4.2 MOR:(Merge on Read)读时复制表
▪4.2.1 概念
▪4.2.2 MOR表工作原理
▪4.3 总结了两种表类型之间的权衡
◦五. 查询类型
▪5.1 Snapshot Queries
▪5.2 Incremental Queries
▪5.3 Read Optimized Query
一. 时间轴(TimeLine)
1.1 时间轴(TimeLine)概念
Hudi的核心是维护在不同时刻(Instant)在表上执行的所有操作的时间轴,提供表的即时视图,同时还有效地支持按时间顺序检索数据
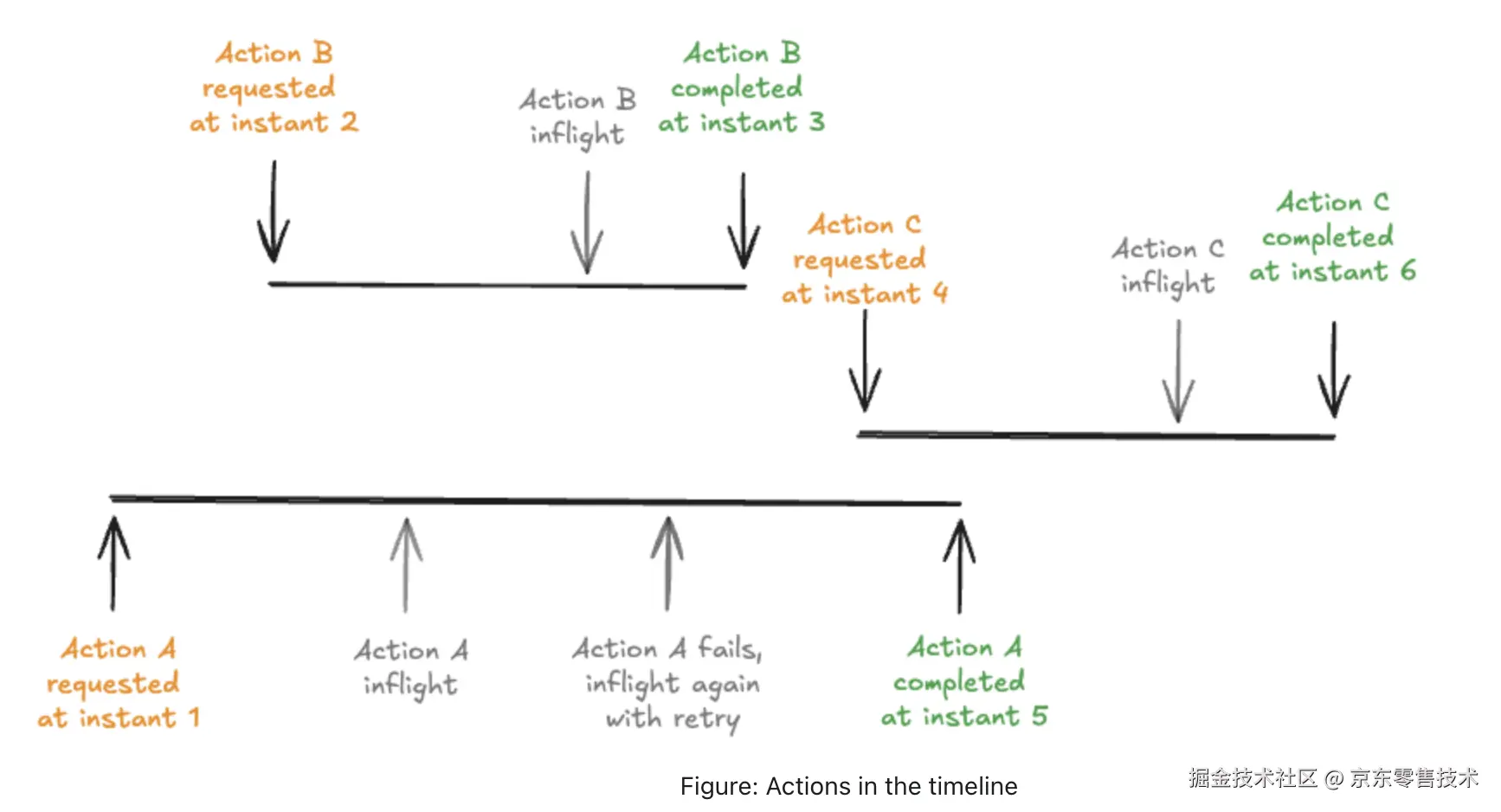
1.2 Hudi的时间线由组成
•requested instant :
表示在时间线上请求操作的时间并充当事务 ID 的即时时间。在请求操作之前,应该生成一个不可变的操作计划。 •completed instant :
表示时间轴上操作完成时间的即时时间。对表数据/元数据的所有相关更改都应在操作完成之前进行。•state :
动作的状态。在操作的生命周期中,有效状态为 REQUESTED、INFLIGHT 和 COMPLETED。•type :
执行的操作类型。1.3 时间线上的Instant action操作类型
hudi保证在时间线上的操作都是基于即时时间的,两者的时间保持一致并且是原子性的,以下是有效的操作类型。
•COMMIT -
写入操作表示将一批记录原子写入表中的基本文件中。•DELTA_COMMIT -
写入操作表示将一批记录原子写入读合并类型表,其中部分/全部数据可以仅写入增量日志。•REPLACE_COMMIT -
写入操作以原子方式将表中的一组文件组替换为另一个文件组。用于实现批量写入操作,如insert_overwrite、delete_partition等,以及表服务,如集群。•CLEANS -
表服务通过删除这些文件来从表中删除不再需要的旧文件切片。•COMPACTION -
表服务通过将增量文件合并到基本文件中来协调基本文件和增量文件之间的差异数据。•LOGCOMPACTION -
表服务将多个小日志文件合并到同一文件分片中的一个更大的日志文件中。 •CLUSTERING -
表服务以优化的排序顺序或存储布局重写现有文件组,作为表中的新文件组。•INDEXING -
表服务在表的列上构建请求类型的索引,与正在进行的写入完成时表的状态保持一致。•ROLLBACK -
表示回滚了不成功的写入操作,从存储中删除了此类写入期间生成的任何部分/未提交的文件。•SAVEPOINT -
将某些文件切片标记为"已保存",这样清理器就不会删除它们。在发生灾难/数据恢复场景时,它有助于将表恢复到时间线上的某个点,或者在这些时刻执行时间旅行查询。•RESTORE -
在发生灾难/数据恢复场景时,将表恢复到时间线上的给定保存点。1.4 时间线上State状态类型
任何给定的瞬间都可以处于以下状态之一
requested:表示一个动作已被安排,但尚未启动
inflight:表是当前正在执行操作
completed:表是在时间线上完成了操作
1.5 时间线官网实例
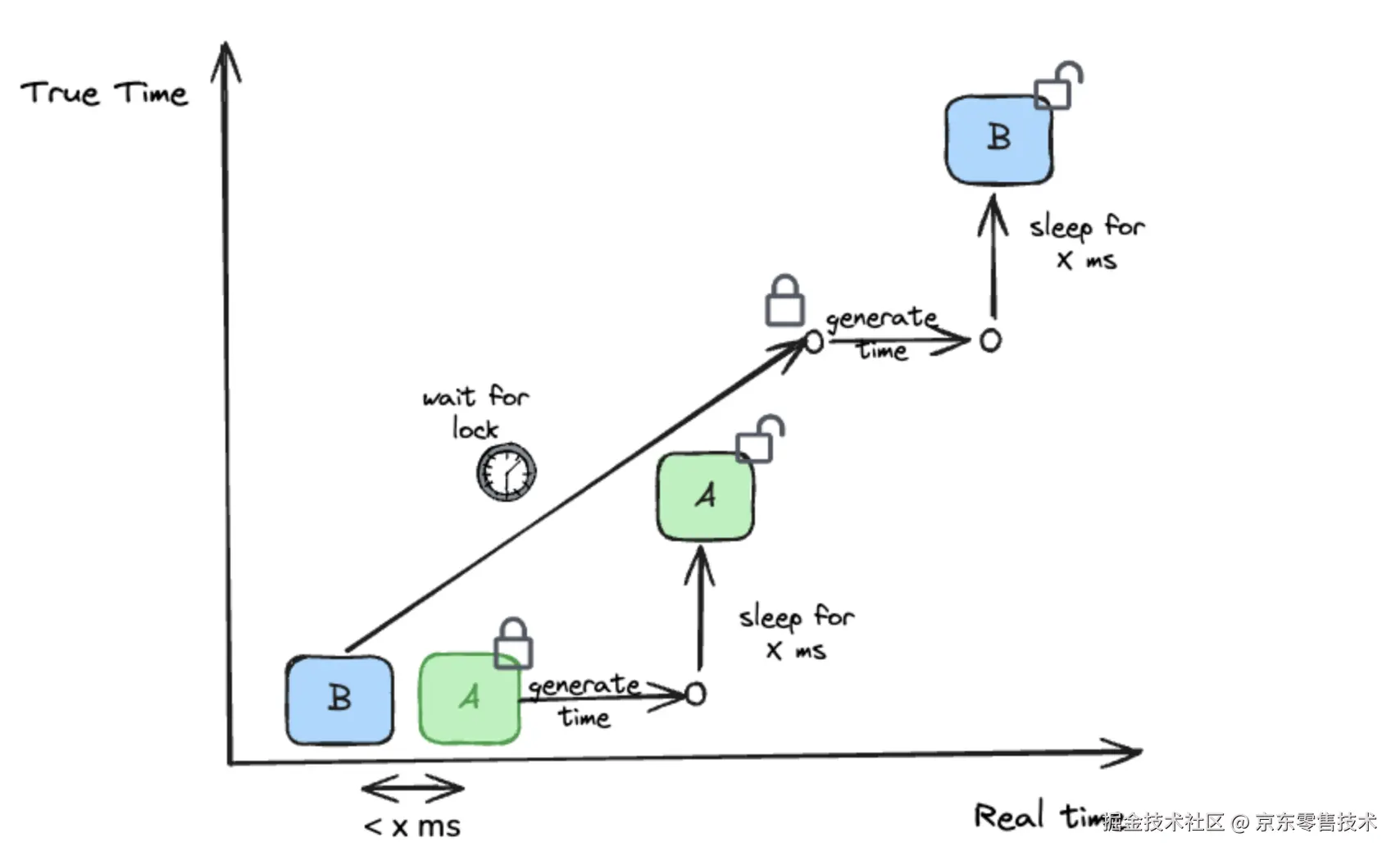
css
上图显示了进程 A 和 B 生成的时间如何单调增加,即使进程 B 在开始时的本地时钟比 A 低,但通过等待 x ms 的不确定性窗口过去。
事实上,考虑到 Hudi 的目标交易持续时间 > 1 秒,我们可以承受更高的不确定性界限(> 100 毫秒),从而保证极高保真度的时间生成。