点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-31- 千呼万唤始出来 GPT-5 发布!"快的模型 + 深度思考模型 + 实时路由",持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年10月13日更新到: Java-147 深入浅出 MongoDB 分页查询详解:skip() + limit() + sort() 实现高效分页、性能优化与 WriteConcern 写入机制全解析 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解

章节内容
上节我们完成了如下的内容:
- Flink 并行度
- Flink 并行度详解
- Flink 并行度 案例

状态类型
Flink根据是否需要保存中间结果,将计算分为有状态计算和无状态计算两种类型:
-
有状态计算(Stateful Computation)
- 特点:需要保存中间结果或状态,依赖之前或之后的事件进行数据处理
- 状态类型:
- 键控状态(Keyed State):与特定键相关联的状态
- 算子状态(Operator State):与算子实例绑定的状态
- 典型应用场景:
- 窗口聚合(如计算5分钟内的平均温度)
- 模式检测(如检测异常登录序列)
- 数据去重(如电商订单去重处理)
- 状态后端支持:
- MemoryStateBackend(内存)
- FsStateBackend(文件系统)
- RocksDBStateBackend(嵌入式数据库)
-
无状态计算(Stateless Computation)
- 特点:每个数据记录的处理都是独立的,不需要保存中间状态
- 典型算子:
- Map(一对一转换)
- Filter(数据过滤)
- FlatMap(一对多转换)
- 应用场景:
- 简单的数据格式转换
- 数据过滤(如过滤掉日志中的调试信息)
- 数据拆分(如将CSV行拆分为多个字段)
- 优势:执行效率高,资源消耗低,可线性扩展
在实际应用中,Flink作业通常会混合使用这两种计算方式。例如,在实时推荐系统中,可能先用无状态的Map算子进行数据清洗,然后通过有状态的窗口聚合计算用户偏好。
根据数据结构不同,Flink定义了多种State,应用于不同的场景。
- ValueState:即类型为T的单值状态,这个状态与对应的Key绑定,是最简单的状态了。它可以通过update方法更新状态值,通过 value() 方法获取状态值
- ListState:即Key上的状态值为一个列表,可以通过add方法往列表中附加值,也可以通过get()方法返回一个Iterable来遍历状态值
- ReducingState:这种状态通过用户传入的ReduceFunction,每次调用add方法添加值的时候,会调用ReduceFunction,最后合并到一个单一的状态值。
- FoldingState:跟ReducingState有点类似,不过它的状态值类型可以与add方法中传入的元素类型不同(这种状态会在未来的Flink版本当中删除)
- MapState:即状态值为一个Map,用户通过put和putAll方法添加元素
State按照是否有Key划分为:
- KeyedState
- OperatorState
案例1 利用State求平均值
实现思路
- 读数据源
- 将数据源根据Key分组
- 按照Key分组策略,对流式数据调用状态化处理:实例化出一个状态实例,随着流式数据的到来更新状态,最后输出结果
编写代码
java
package icu.wzk;
public class FlinkStateTest01 {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Tuple2<Long, Long>> data = env
.fromElements(
Tuple2.of(1L, 3L),
Tuple2.of(1L, 5L),
Tuple2.of(1L, 7L),
Tuple2.of(1L, 4L),
Tuple2.of(1L, 2L)
);
KeyedStream<Tuple2<Long, Long>, Long> keyed = data
.keyBy(new KeySelector<Tuple2<Long, Long>, Long>() {
@Override
public Long getKey(Tuple2<Long, Long> value) throws Exception {
return value.f0;
}
});
SingleOutputStreamOperator<Tuple2<Long, Long>> flatMapped = keyed
.flatMap(new RichFlatMapFunction<Tuple2<Long, Long>, Tuple2<Long, Long>>() {
private transient ValueState<Tuple2<Long, Long>> sum;
@Override
public void flatMap(Tuple2<Long, Long> value, Collector<Tuple2<Long, Long>> out) throws Exception {
Tuple2<Long, Long> currentSum = sum.value();
if (currentSum == null) {
currentSum = Tuple2.of(0L, 0L);
}
// 更新
currentSum.f0 += 1L;
currentSum.f1 += value.f1;
System.out.println("currentValue: " + currentSum);
// 更新状态值
sum.update(currentSum);
// 如果 count >= 5 清空状态值 重新计算
if (currentSum.f0 >= 5) {
out.collect(new Tuple2<>(value.f0, currentSum.f1 / currentSum.f0));
sum.clear();
}
}
@Override
public void open(Configuration parameters) throws Exception {
ValueStateDescriptor<Tuple2<Long, Long>> descriptor = new ValueStateDescriptor<>(
"average",
TypeInformation.of(new TypeHint<Tuple2<Long, Long>>() {})
);
sum = getRuntimeContext().getState(descriptor);
}
});
flatMapped.print();
env.execute("Flink State Test");
}
}运行结果
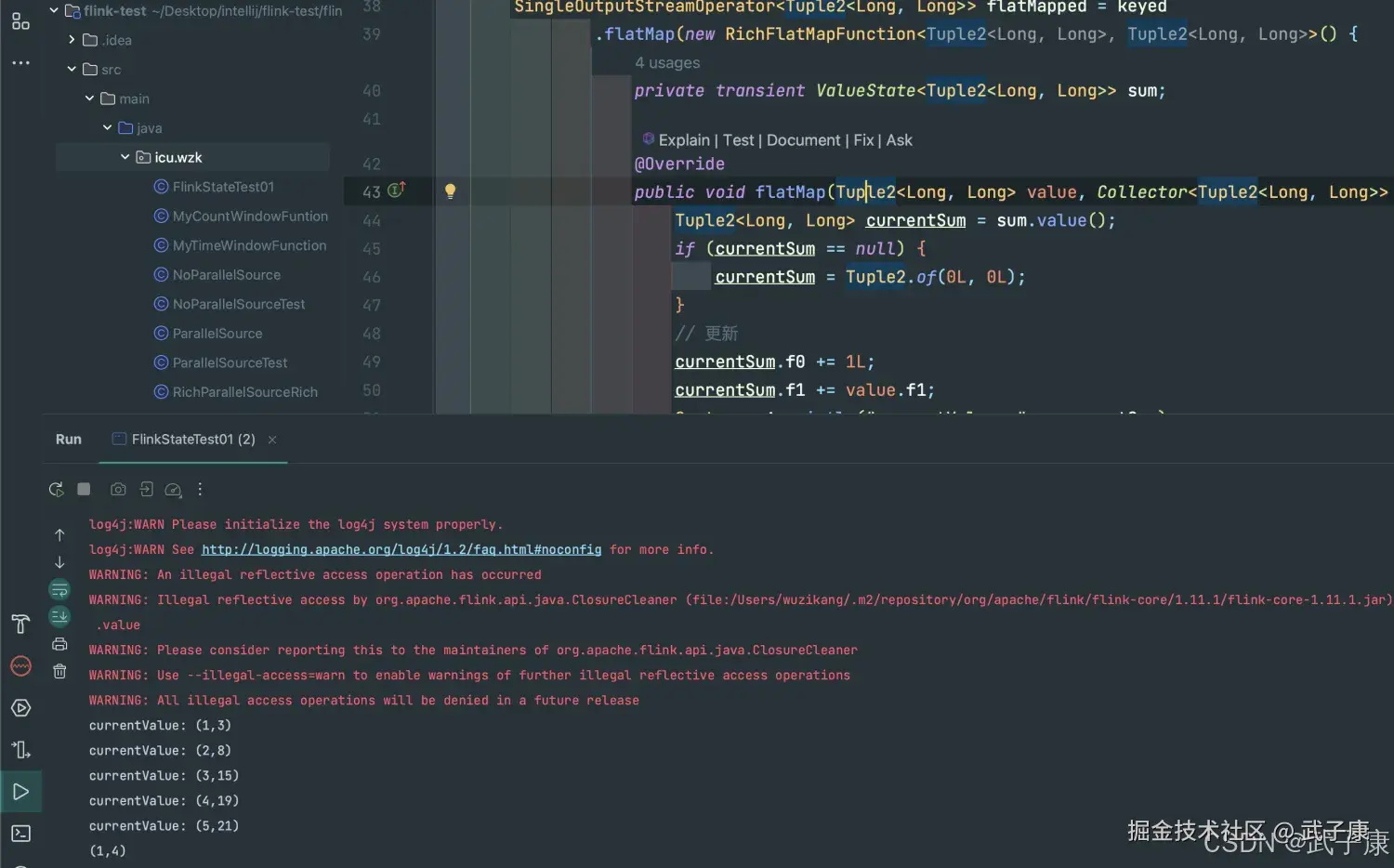
执行分析
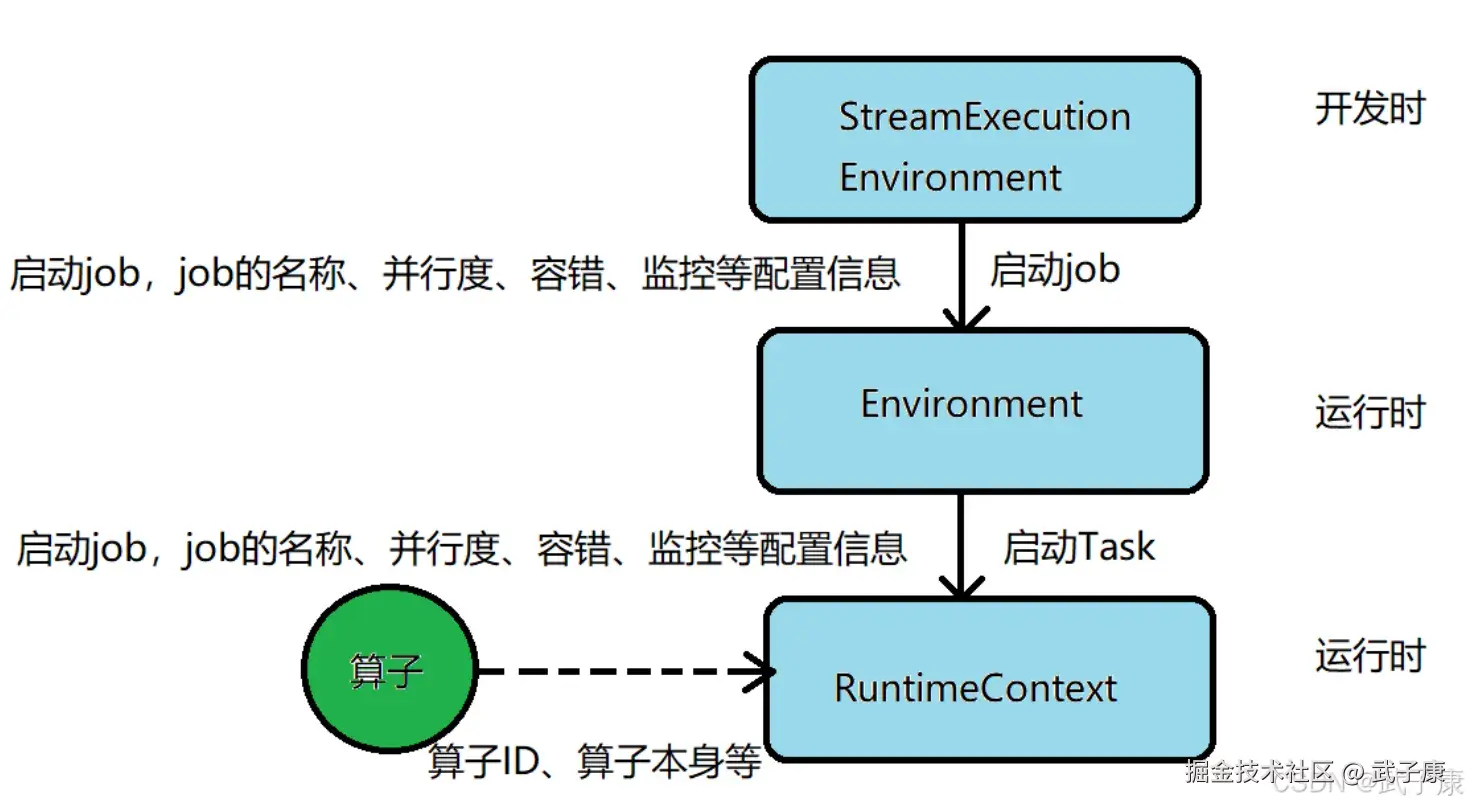
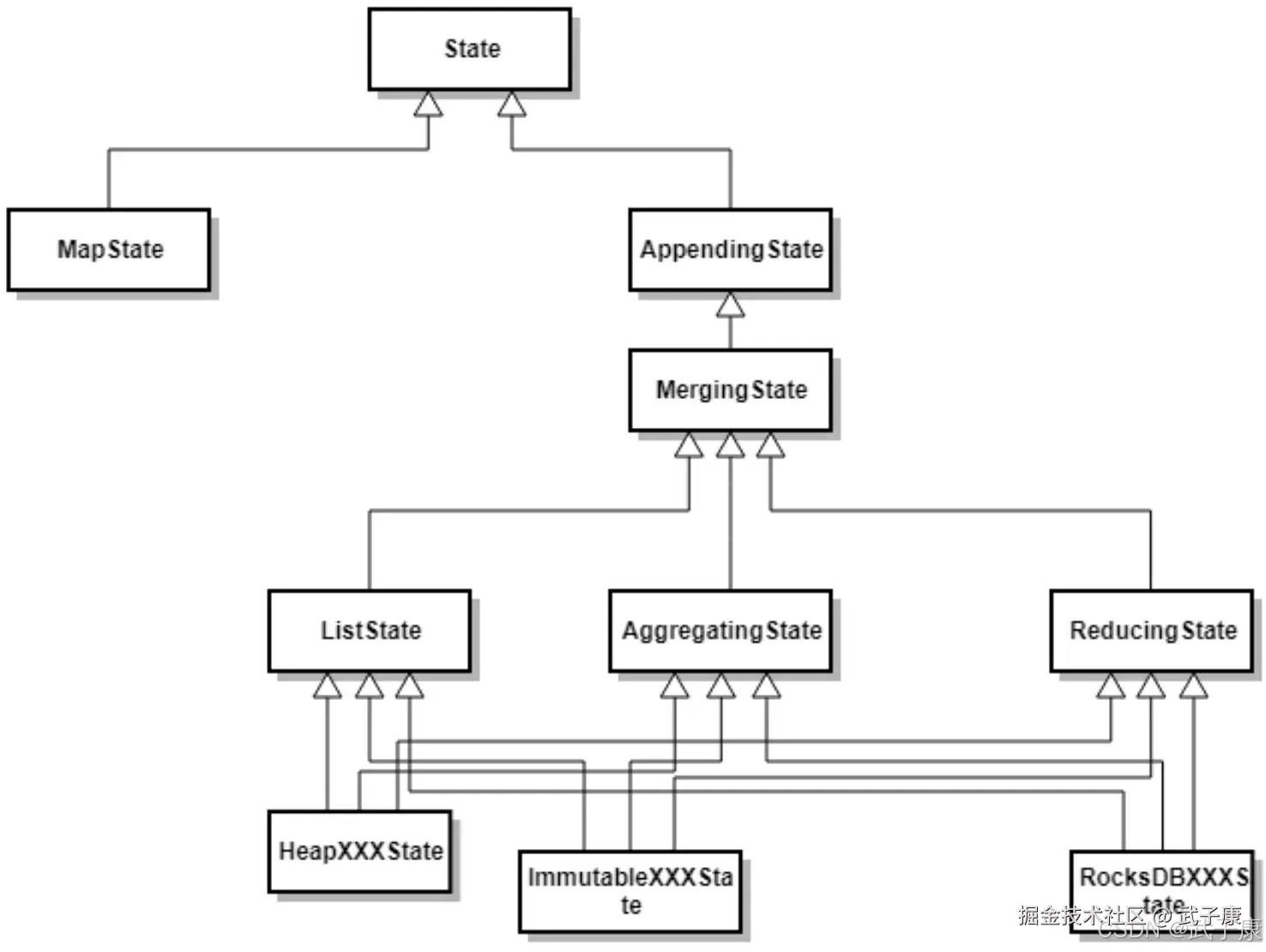
Keyed State
Keyed State 是 Flink 中一种与 Key 相关联的状态类型,它只能应用于 KeyedStream 类型的数据集所对应的 Function 和 Operator 上。KeyedState 实际上是 OperatorState 的一个特例,其关键区别在于 KeyedState 会事先按照 Key 对数据集进行区分,使得每个 KeyedState 仅对应一个特定的 Operator 和 Key 的组合。
核心特性
- Key 关联性:每个状态都严格绑定到特定的 Key,相同 Key 的数据会访问相同的状态实例
- 自动分区:状态会根据 Key 自动分区,保证相同 Key 的数据总是被路由到相同的并行任务实例
- 高效访问:通过 Key 可以直接定位到对应的状态,避免了全量扫描
管理机制
KeyedState 通过 KeyGroups 机制进行管理,这个机制主要服务于以下场景:
- 动态扩缩容:当算子的并行度发生变化时,系统会自动重新分布 KeyedState 数据
- 故障恢复:在故障恢复时确保状态正确分配到新的任务实例
KeyGroups 工作原理
- 分组策略:系统会将所有可能的 Key 通过哈希等方式分配到固定数量的 KeyGroups 中
- 动态分配:在运行时,一个 Keyed 算子实例可能负责处理一个或多个 KeyGroups 的 Keys
- 再平衡:当并行度变化时,系统会重新计算 KeyGroups 到任务实例的映射关系
典型应用场景
- 实时聚合计算:如计算每个用户的点击量统计
java
// 示例:使用 ValueState 实现用户点击统计
public class UserClickCounter extends KeyedProcessFunction<String, ClickEvent, Tuple2<String, Integer>> {
private ValueState<Integer> countState;
@Override
public void open(Configuration parameters) {
ValueStateDescriptor<Integer> descriptor =
new ValueStateDescriptor<>("clickCount", Integer.class);
countState = getRuntimeContext().getState(descriptor);
}
@Override
public void processElement(ClickEvent event, Context ctx, Collector<Tuple2<String, Integer>> out) throws Exception {
Integer currentCount = countState.value();
if (currentCount == null) {
currentCount = 0;
}
currentCount++;
countState.update(currentCount);
out.collect(new Tuple2<>(ctx.getCurrentKey(), currentCount));
}
}- 模式检测:如检测用户异常登录行为
- 会话窗口处理:跟踪用户会话活动
状态类型
Flink 提供了多种 KeyedState 实现:
- ValueState:存储单个值
- ListState:存储值的列表
- MapState:存储键值对映射
- ReducingState:存储聚合结果
- AggregatingState:支持更复杂的聚合
性能考量
- 状态后端选择:可选择 MemoryStateBackend、FsStateBackend 或 RocksDBStateBackend
- 状态序列化:优化状态序列化方式可以显著提升性能
- 状态清理:合理设置状态 TTL 避免状态无限增长
KeyedState 的这种设计使得 Flink 能够高效处理有键数据流的状态管理,同时保证了系统的弹性和可扩展性。
Operator State
Operator State(算子状态)是 Flink 中一种重要的状态类型,它与 Keyed State 有着本质区别。Operator State 直接与特定的算子实例(operator instance)绑定,而非依赖于数据中的 key。这种设计意味着:
-
状态分配机制:
- 每个算子实例维护自己处理的数据所对应的状态
- 状态数据在算子实例间是分区存储的
- 当并行度调整时,Flink 会自动重新分配状态数据
-
并行度适应性:
- 支持动态扩容/缩容场景
- 提供三种内置的重新分配策略:
- 均匀分配(Even-split redistribution):将状态均匀划分到所有新算子实例
- 全量广播(Union redistribution):将完整状态复制到每个新实例
- 自定义分配 :通过实现
ListCheckpointed接口实现
-
典型应用场景:
- 源算子(如 Kafka Consumer)记录消费偏移量
- 窗口算子维护窗口触发状态
- 自定义聚合算子保存中间结果
状态管理形式
在 Flink 中,无论是 KeyedState 还是 OperatorState 都支持两种管理形式:
托管状态(Managed State)
这是 Flink 推荐的使用方式,具有以下特点:
- 运行时管理:由 Flink 运行时环境统一管理状态
- 存储优化 :
- 自动转换为高效的内存数据结构(如 HashTables)
- 可选 RocksDB 作为状态后端实现大状态存储
- 持久化机制 :
- 通过 Checkpoint 机制定期持久化状态
- 提供精确一次(exactly-once)的状态保证
- 使用高效的序列化框架(如 Kryo)进行状态序列化
- 恢复流程 :
- 任务失败时自动从最近一次成功的 Checkpoint 恢复
- 支持增量 Checkpoint 减少恢复时间
原生状态(Raw State)
这种形式提供更大的灵活性但需要开发者承担更多责任:
- 自主管理:算子需要自行维护状态数据结构
- 序列化要求 :
- 开发者需要自己实现状态序列化逻辑
- 需要处理版本兼容性问题
- 检查点处理 :
- Checkpoint 触发时需要显式进行状态快照
- 恢复时需要自行反序列化状态数据
- 典型用例 :
- 需要特殊数据结构优化的场景
- 集成第三方库时需要保持特定格式的状态
状态后端比较
对于托管状态,Flink 提供多种状态后端实现:
| 特性 | MemoryStateBackend | FsStateBackend | RocksDBStateBackend |
|---|---|---|---|
| 存储介质 | JVM 堆内存 | 文件系统 | RocksDB |
| 状态大小限制 | <10MB | 单任务可达TB级 | 仅受磁盘容量限制 |
| 访问速度 | 最快 | 中等 | 相对较慢 |
| 适用场景 | 测试/小状态 | 常规生产环境 | 超大状态场景 |
DataStreamAPI支持使用ManagedState和RawState两种状态形式,在Flink中推荐用户使用ManagedState管理状态数据,主要原因是ManagedState能够更好地支持状态数据的重平衡以及更加完善的内存管理。
状态描述

State既然是暴露给用户的,那么就需要有一些属性需要指定:
- State名称
- Value Serializer
- State Type Info
在对应的StateBackend中,会去调用对应的create方法获取到stateDescriptor中的值。 Flink通过StateDescriptor来定义一个状态,这是一个抽象类,内部定义了状态名称、类型、序列化器等基础信息,与上面的状态对应,从StateDescriptor派生ValueStateDescriptor、ListStateDescriptor等等
- ValueState getState(ValueStateDescriptor)
- ReducingState getReducingState(ReducingStateDescriptor)
- ListState getListState(ListStateDescriptor)
- FoldingState getFoldingState(FoldingStateDescriptor)
- MapState getMapState(MapStateDescriptot)