一、引 言
为什么进行源码角度的深度解析?
大家在项目中到处都在使用线程池做一些性能接口层次的优化,原先串行的多个远程调用,因为rt过高,通过线程池批量异步优化,从而降低rt。还有像RocketMQ中broker启动时,同时通过ScheduledThreadPoolExecutor线程池执行其他组件的定时任务,每隔一段时间处理相关的任务。线程池广泛的应用在外面各种实际开发场景中,我们很多同学可能在项目里只是简单的copy了一些前人的代码参数并不知道其中的含义,从而导致生产级别的bug。所以本篇文章,旨在帮助还不熟悉或者想要熟悉线程池的同学,分享我自己在学习线程池源码上的一些内容来更简单、快速的掌握线程池。
二、为什么使用线程池?
并发编程中,对于常见的操作系统,线程都是执行任务的基本单元,如果每次执行任务时都创建新的线程,任务执行完毕又进行销毁,会出现以下的问题:
- 资源开销:比如在Linux系统中,频繁的创建和销毁线程,一个是频繁的进行一个系统调用,另外是一些内存和CPU资源调度的占用。虽然有一些写时复制的策略防止lwp的创建时的内存占用,但是实际写入还是会申请系统内存的,何况一些页表等本身就有内存占用。
- 性能瓶颈:线程的创建需要系统调用,如果只是简单的计算任务,可能耗时还没创建的rt高,这里反而降低了系统的吞吐量。
- 缺乏资源管理:无限制的创建线程会导致内存溢出,java.lang.OutOfMemoryError: unable to create native thread,这里主要因为Java的线程其实Linux中是lwp线程,需要通过JNI进行系统调用创建,每个线程默认需要1MB的栈空间,很容易导致无休止的创建线程导致内存溢出,另外就是频繁的系统调用,导致的上下文切换,占用了过多的CPU,反而起到了相反的作用。
- 功能受限:手动管理线程难以实现更高级的功能,如定时任务、周期任务、任务管理、并发任务数的控制等。
通过上面的问题,我们其实可以清晰的感知到这些问题都是归拢到资源没有得到合理的分配和控制导致的,线程池出现的核心宗旨其实就是对资源的合理分配和控制。除了线程池,其实更多的也接触过数据库连接池、netty的对象池等池化技术,这些池化思想其实都是为了更好的降低资源的消耗以及更好的进行资源管理。
三、JDK线程池的架构设计
3.1 JUC并发包下的Executor框架的uml类图
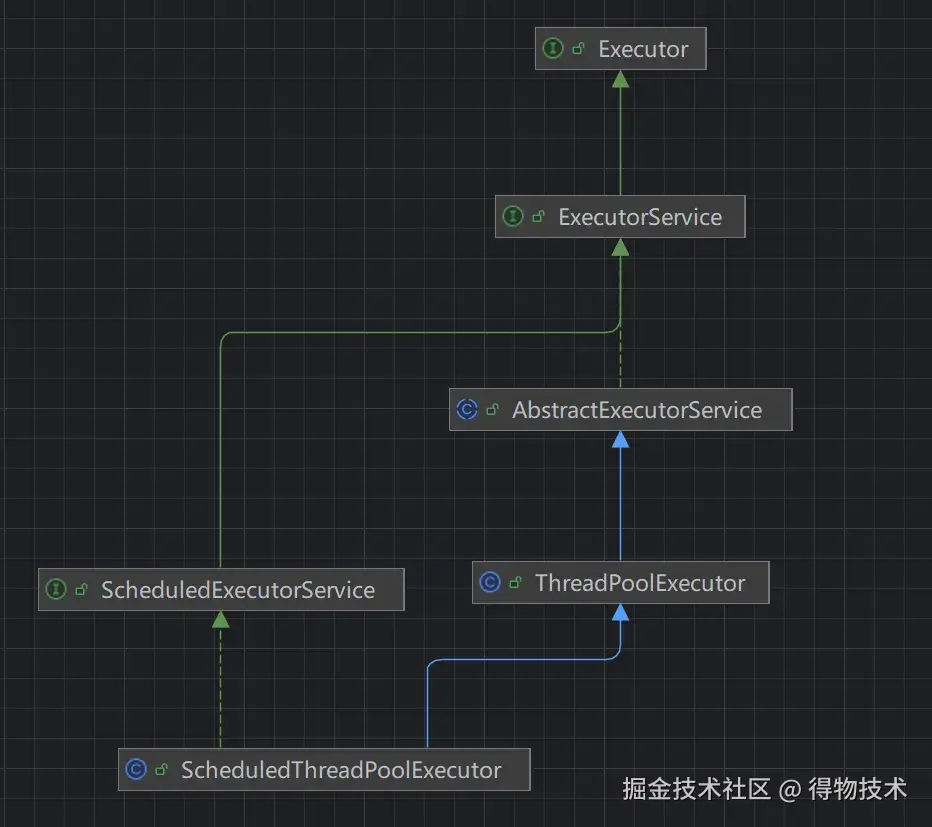
- Executor:任务执行的顶层接口,主要是分离任务提交与执行逻辑,支持同步/异步执行,遵循Java内存模型的 happen-before规则。
- ExecutorService:继承Executor接口,提供了更完善的生命周期管理能力,通过Future对象提供任务取消、状态查询、结果获取能力实现了任务监控。
- AbstractExecutorService:常见的设计模式为了简化线程池的开发,通常通过父类进行一些基础的默认实现让子类继承。
- ScheduledExecutorService:ExecutorService的扩展接口,支持延迟执行和周期性任务调度。
- ThreadPoolExecutor:是ExecutorService接口最核心和最常用的实现类,它提供了高度可配置的线程池,允许我们精细控制线程池的各种行为。
- ScheduledThreadPoolExecutor:是ScheduledExecutorService接口的实现类,它继承自ThreadPoolExecutor,专门用于处理定时和周期任务。
- Executors:一个静态工厂模式的工具类,提供了一系列静态方法来创建各种常见配置的线程池,newFixedThreadPool(), newCachedThreadPool(),等,简化了创建线程池的使用但是会带来一些问题,很多开发规范里都不建议大家直接使用。JDK内置的线程池如果我们不熟悉里面的参数很有可能导致出乎自己意料的结果,池大小设置、阻塞队列选择等等都是有考究的,这一点后续会进行一些详细说明。生产环境中建议谨慎使用或直接使用ThreadPoolExecutor构造函数自定义。
3.2 ThreadPoolExecutor的参数解析
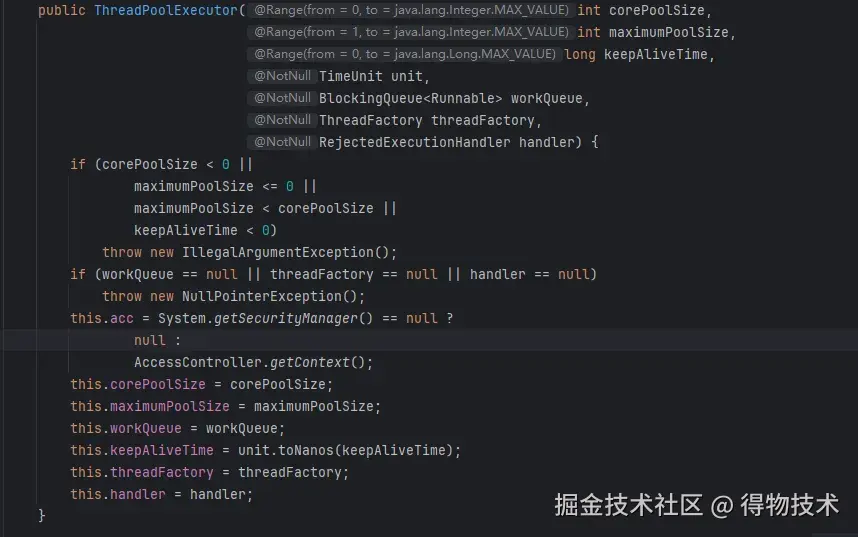
- corePoolSize 核心线程数:
-
- 线程池中还未退出的alive的核心线程数量。
- 虽然线程处于空闲状态(其实是阻塞在阻塞队列中),除非显示设置了allowCoreThreadTimeOut=true,否则这些线程不会从自己的run方法中退出被回收。
- 添加新任务时,如果当前工作线程小于coreSize,此时即使存在空闲的core线程,线程池也会通过addWorker方法创建一个新的线程。
- maximumPoolSize 最大线程数:
-
- 线程池可以创建的最大线程数。
- 如果是有界队列,当队列满时,仍然有任务进来,此时线程池会创建小于最大线程数的线程来完成任务,空闲。
- 如果是无界队列,那么永远不会出现第二点的情况,除了内存异常,否则会一直保持核心线程数,多余的任务会一直往队列中加入。
- keepAliveTime 线程空闲存活时间
-
- 线程数超过corePoolSize后创建的线程我们理解为非核心线程,对于这类线程,他的回收机制在于我们设置的keepAliveTime,线程会限期阻塞在队列中获取任务,如果超时未获取就会进行清理并退出。
- 另外如果设置allowCoreThreadTimeOut=true,所谓的核心线程在空闲时间达到keepAliveTime时也会被回收。
- unit 时间单位
-
- keepAliveTime参数的时间单位,TimeUnit中时分秒等。
- workQueue 任务队列
-
- 阻塞队列,核心线程数满时,新加入的任务,会先添加到阻塞队列中等待线程获取任务并执行。
- 常用的BlockingQueue实现有:
-
- ArrayBlockingQueue:数组实现的先进先出原则的有界阻塞队列,构造方法必须指定容量。
- LinkedBlockingQueue:链表实现的阻塞队列,构造传入容量则有界,未传则是无界队列,此时设置的最大线程数其实就不会有作用了。
- SynchronousQueue:一个不存储元素的阻塞队列。每个put操作必须等待一个take操作,反之亦然。它相当于一个传递通道,非常适合传递性需求,吞吐量高,但要求maximumPoolSize足够大。
- PriorityBlockingQueue:二叉堆实现的优先级阻塞队列,构造时可自行调整排序行为(小顶堆或大顶堆)。
- DelayQueue:支持延时的无界阻塞队列,主要用于周期性的任务,我们可以直接通过它来实现一些简单的延迟任务需求,复杂的周期性任务建议使用ScheduledThreadPoolExecutor。
- threadFactory 线程工厂
-
- 用于创建新线程的工厂。通过自定义ThreadFactory,我们可以为线程池中的线程设置更有意义的名称、设置守护线程状态、设置线程优先级、指定UncaughtExceptionHandler等。
- Executors.defaultThreadFactory()是默认实现。
- handler 拒绝策略
-
- ThreadPoolExecutor.AbortPolicy:默认的拒绝策略,简单粗暴,当execute中添加woker失败时,直接在当前线程抛出异常。
- JDK内置了四种拒绝策略:
-
- ThreadPoolExecutor.AbortPolicy:默认的拒绝策略,简单粗暴,当execute中添加woker失败时,直接在当前线程抛出异常。
- ThreadPoolExecutor.CallerRunsPolicy:提交任务的线程,直接执行任务。变相的背压机制,可以降低任务往线程中加入。
- ThreadPoolExecutor.DiscardPolicy:直接丢弃被拒绝的任务,不做任何通知,需容忍数据丢失。
- ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列中最旧的任务,然后重试提交当前任务,需容忍数据丢失。
- 实现RejectedExecutionHandler接口自定义拒绝策略,在实际生产应用中推荐使用,可以做一些打印观察日志的操作,告警、兜底的相关处理等。
3.3 运行机制详解
新任务通过execute()方法提交给ThreadPoolExecutor时,其处理流程如下:
判断核心线程数:如果当前运行的线程数小于corePoolSize,则创建新线程(即使有空闲的核心线程)来执行任务。
尝试入队:如果当前运行的线程数大于或等于corePoolSize,则尝试将任务添加到workQueue中。
- 如果workQueue.offer()成功(队列未满),任务入队等待执行。
尝试创建非核心线程:如果workQueue.offer()失败(队列已满):
- 判断当前运行的线程数是否小于maximumPoolSize;
- 如果是,则创建新的非核心线程来执行任务。
执行拒绝策略:
如果当前运行的线程数也达到了maximumPoolSize(即核心线程和非核心线程都已用尽,且队列也满了),则执行RejectedExecutionHandler所定义的拒绝策略。
参考网络中的经典执行图:
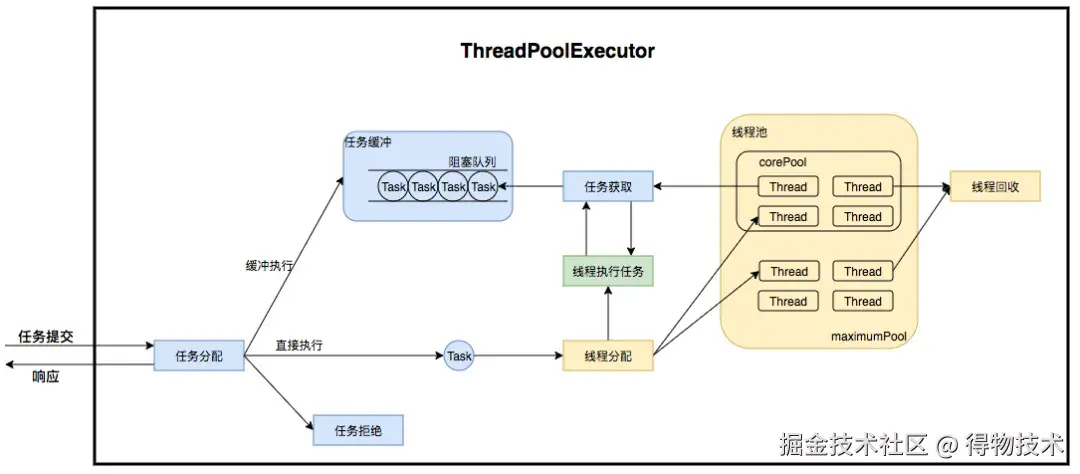
这个图能很好的表明运行原理,但是忽略了很多细节,比如所谓的缓冲执行是在什么条件下去走的呢?直接执行又是什么逻辑下执行呢?最后的任务拒绝又是怎么回事?带着这些疑问点,我们直接来进行一个源码级别的分析:
execute核心流程的源码分析
scss
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
//线程池状态 高3位表示线程状态 低29位代表线程数量
int c = ctl.get();
//判断当前线程池线程数量是否小于核心线程数
if (workerCountOf(c) < corePoolSize) {
//作为核心线程数进行线程的创建,并且创建成功线程会将command的任务执行--》对应图上的直接执行
if (addWorker(command, true))
return;
c = ctl.get();
}
//创建核心线程失败或者当前线程数量超过核心线程数
//当前线程池是否还在运行状态,尝试将任务添加到阻塞队列 --》对应图上的缓冲执行
//BlockingQueue队列的顶级抽象定义了offer不是进行阻塞添加而是立即返回,添加失败直接返回false,区别于put
if (isRunning(c) && workQueue.offer(command)) {
//重新获取线程池标志位
int recheck = ctl.get();
//如果线程此时不在运行状态中,那么将任务删除
if (! isRunning(recheck) && remove(command))
//删除任务成功,走拒绝策略拒绝掉当前任务
reject(command);
else if (workerCountOf(recheck) == 0)
//如果线程池中的工作线程都没有的时候,这里需要创建一个线程去执行添加到队列中的任务
//防止因为并发的原因工作线程都被终止掉了,此时任务在阻塞队列里等着,缺没有工作线程
addWorker(null, false);
}
//到这里那就是添加队列失败,或者线程池状态异常,但是这里仍然尝试进行创建一个worker
//如果创建失败,也是走拒绝策略拒绝当前任务
else if (!addWorker(command, false))
reject(command);
}接下来我们仔细看看addWorker这个方法具体是在做什么:
ini
//核心逻辑其实就是在无限循环创建一个worker,创建失败直接返回,创建成功,则将worker执行
// 因为worker有thread的成员变量,最终添加worker成功,会启动线程的start方法
//start方法最终会回调到外层的runWorker方法,改方法会不停的从阻塞队列里以阻塞的take方式
//获取任务,除非达到能被终止的条件,此时当前线程会终止
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
int wc = workerCountOf(c);
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
//不停的重试添加worker的计数,只有添加成功的才会进行后续的worker启动
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
//重试期间,如果其他线程导致线程池状态不一致了。重新回到第一个循环进行check判断
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
//这里加锁一个是workers.add时需要加锁,另外是防止其他线程已经在尝试修改线程池状态了
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
//将worker的引用添加到workers的hashSet中
workers.add(w);
int s = workers.size();
//更新线程池此时最大的线程数
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
//如果添加成功,就启动worker中的线程
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
//这里添加失败的话,需要把线程池的count数进行--,并且要把worker引用从hashSer中移除
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}3.4 线程池的生命周期
在介绍运行机制原理的源码分析时,其实是有提到线程池状态这个概念的。介绍这个状态其实也是让大家更方便的去管理线程池,比如我们关闭线程池时,怎么去优雅的关闭,使用不同的方法可能会有不同的效果,我们需要根据自己的业务场景去酌情分析、权衡使用。
java
//线程池的状态和计数采用一个Integer变量设置的
//这里之所以用一个变量来储存状态和数量,其实很有讲究的,因为我们在上面的运行原理上可以看到
//源码中有大量的进行状态以及数量的判断,如果分开采用变量的记录的话,在维护二者一致性方面
//可能就需要加锁的维护成本了,而且计算中都是位移运算也是非常高效的
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
//线程池的大小由ctl低29位表示,现成状态由ctl高3位表示
private static final int COUNT_BITS = Integer.SIZE - 3;
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// 线程池的状态通过简单的位移就能计算出来,状态只能从低到高流转,不能逆向
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
// 这里是获取线程状态以及获取线程数量的简单高效的位移方法
private static int runStateOf(int c) { return c & ~CAPACITY; }
private static int workerCountOf(int c) { return c & CAPACITY; }
private static int ctlOf(int rs, int wc) { return rs | wc; }接下来结合源码详细介绍下线程池的5种状态以及分别有什么不同的表现行为?
ini
先说下结论:
RUNNING 这个就是线程池运行中状态,我们可以添加任务也可以处理阻塞队列任务
SHUTDOWN 不能添加新的任务,但是会将阻塞队列中任务执行完毕
STOP 不能添加新的任务,执行中的线程也会被打断,也不会处理阻塞队列的任务
TIDYING 所有线程都被终止,并且workCount=0时会被置为的状态
TERMINATED 调用完钩子方法terminated()被置为的状态 shutdown状态源码分析:
scss
//线程池关闭
public void shutdown() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
//循环cas设置线程池状态,直到成功或状态已经state>=SHUTDOWN
advanceRunState(SHUTDOWN);
//这个是真正得出结论的地方
interruptIdleWorkers();
onShutdown(); // hook for ScheduledThreadPoolExecutor
} finally {
mainLock.unlock();
}
tryTerminate();
}
private void interruptIdleWorkers() {
interruptIdleWorkers(false);
}
//打断空闲的线程,如何判断线程是否空闲还是运行?
private void interruptIdleWorkers(boolean onlyOne) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
for (Worker w : workers) {
Thread t = w.thread;
//worker的线程没有被打断过,并且能获取到worker的aqs独占锁
if (!t.isInterrupted() && w.tryLock()) {
try {
//打断当前线程,如果线程在阻塞队列中阻塞,此时会被中断
t.interrupt();
} catch (SecurityException ignore) {
} finally {
w.unlock();
}
}
if (onlyOne)
break;
}
} finally {
mainLock.unlock();
}
}STOP状态分析
scss
//循环cas修改线程池状态为stop。打断所有线程,取出阻塞队列的所有任务
public List<Runnable> shutdownNow() {
List<Runnable> tasks;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
//检查线程的权限
checkShutdownAccess();
//将状态case为stop
advanceRunState(STOP);
//打断所有worker不管是不是正在执行任务
interruptWorkers();
tasks = drainQueue();
} finally {
mainLock.unlock();
}
tryTerminate();
return tasks;
}
//这里获取锁之后。打断了所有的线程
private void interruptWorkers() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
for (Worker w : workers)
w.interruptIfStarted();
} finally {
mainLock.unlock();
}
}TIDYING、TERMINATED 状态分析
scss
//这个方法在每个线程退出时都会进行调用,如果是运行中、或者状态大于等于TIDYING或者shutdown但是队列不为空都
//直接返回,如果不满足以上条件,并且线程数不为0的话,打断一个空闲线程
final void tryTerminate() {
for (;;) {
int c = ctl.get();
if (isRunning(c) ||
runStateAtLeast(c, TIDYING) ||
(runStateOf(c) == SHUTDOWN && ! workQueue.isEmpty()))
return;
if (workerCountOf(c) != 0) { // Eligible to terminate
interruptIdleWorkers(ONLY_ONE);
return;
}
//此时到这里,状态要么为STOP。要么是shutdown并且队列为空了
// 获取一个锁,尝试cas修改状态为TIDYING
//调用terminated()的钩子方法,
//修改线程池为终态TERMINATED,并且唤醒阻塞在termination队列上的线程
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
if (ctl.compareAndSet(c, ctlOf(TIDYING, 0))) {
try {
terminated();
} finally {
ctl.set(ctlOf(TERMINATED, 0));
termination.signalAll();
}
return;
}
} finally {
mainLock.unlock();
}
// else retry on failed CAS
}
}四、JDK内置线程池的问题
java.util.concurrent.Executors工厂类提供了一些静态方法,方便我们快速创建几种预设配置的线程池:
- Executors.newFixedThreadPool(int nThreads):
-
- 创建一个固定大小的线程池。corePoolSize和maximumPoolSize都等于nThreads。
- keepAliveTime为0L(因为线程数不会超过corePoolSize,所以此参数无效,除非allowCoreThreadTimeOut为true)。
- 使用无界的LinkedBlockingQueue作为工作队列。
- 问题:由于使用无界队列,当任务提交速度远大于处理速度时,队列会持续增长,可能导致内存溢出(OOM)。此时maximumPoolSize参数实际上是无效的,线程数永远不会超过nThreads。
- Executors.newSingleThreadExecutor():
-
- 创建一个只有一个工作线程的线程池。corePoolSize和maximumPoolSize都为1。
- 同样使用无界的LinkedBlockingQueue。
- 保证所有任务按照提交顺序(FIFO)执行。
- 问题:与newFixedThreadPool类似,无界队列可能导致OOM。
- Executors.newCachedThreadPool():
-
- 创建一个可缓存的线程池。
- corePoolSize为0。
- maximumPoolSize为Integer.MAX_VALUE (几乎是无界的)。
- keepAliveTime为60秒。
- 使用SynchronousQueue作为工作队列。这种队列不存储元素,任务提交后必须有空闲线程立即接收,否则会创建新线程(如果未达到maximumPoolSize)。
- 问题:如果任务提交速度过快,会创建大量线程(理论上可达Integer.MAX_VALUE个),可能耗尽系统资源,导致OOM以及频繁的上下文切换。
- Executors.newSingleThreadScheduledExecutor()、Executors.newScheduledThreadPool(int corePoolSize):
-
- 创建用于调度任务的线程池。
- 内部使用ScheduledThreadPoolExecutor实现,其任务队列是DelayedWorkQueue (一种特殊的PriorityQueue)。
- newSingleThreadScheduledExecutor的corePoolSize为1,maximumPoolSize为Integer.MAX_VALUE(但由于队列是DelayedWorkQueue,通常不会无限增长线程,除非有大量同时到期的任务且处理不过来)。
- newScheduledThreadPool可以指定corePoolSize。
- 问题:虽然DelayedWorkQueue本身是无界的,但ScheduledThreadPoolExecutor在任务执行逻辑上与普通ThreadPoolExecutor有所不同。主要风险仍然是如果corePoolSize设置不当,且大量任务同时到期并执行缓慢,可能导致任务积压。

某一线互联网Java开发手册
五、线程池中的问题与最佳实践
5.1 invokeAll 超时机制无效?
ExecutorService.invokeAll(Collection<? extends Callable> tasks, long timeout, TimeUnit unit)方法会提交一组Callable任务,并等待所有任务完成,或者直到超时。如果超时发生,它会尝试取消(中断)所有尚未完成的任务,然后返回一个List。
失效场景分析:
- 任务不响应中断(最常见):任务内部捕获 InterruptedException 后静默处理,或执行不检查中断状态的阻塞操作(如循环计算):
kotlin
Callable<String> task = () -> {
while (true) {
//缺少此检查将导致超时失效
if (Thread.interrupted()) break;
// 耗时计算...
}
return "done";
};- 使用非响应中断的API:任务调用了不响应 interrupt() 的第三方库或JNI代码(如某些IO操作)
ini
Callable<Integer> task = () -> {
Files.copy(in, path); // 某些NIO操作不响应中断
return 1;
};- 任务依赖外部资源阻塞:任务因外部资源(如数据库连接、网络请求)阻塞且未设置超时。
rust
Callable<Result> task = () -> {
//未设查询超时时间
return jdbcTemplate.query("SELECT * FROM large_table");
};- 线程池配置缺陷:核心线程数过大或队列无界,导致 invokeAll 超时前任务无法全部启动,任务堆积在队列,invokeAll 超时后仍有大量任务未执行。
arduino
new ThreadPoolExecutor(
100, 100, // 核心线程数过大
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<>() // 无界队列
);invokeAll超时失效demo:
arduino
import java.util.*;
import java.util.concurrent.*;
public class InvokeAllTimeoutDemo {
// 模拟耗时任务(可配置是否响应中断)
static class Task implements Callable<String> {
private final int id;
private final long durationMs;
private final boolean respectInterrupt;
Task(int id, long durationMs, boolean respectInterrupt) {
this.id = id;
this.durationMs = durationMs;
this.respectInterrupt = respectInterrupt;
}
@Override
public String call() throws Exception {
System.out.printf("Task %d started%n", id);
long start = System.currentTimeMillis();
// 模拟工作(检查中断状态)
while (System.currentTimeMillis() - start < durationMs) {
if (respectInterrupt && Thread.interrupted()) {
throw new InterruptedException("Task " + id + " interrupted");
}
// 不响应中断的任务会继续执行
}
System.out.printf("Task %d completed%n", id);
return "Result-" + id;
}
}
public static void main(String[] args) throws InterruptedException {
ExecutorService executor = Executors.newFixedThreadPool(2);
List<Callable<String>> tasks = Arrays.asList(
new Task(1, 2000, true), // 2秒,响应中断
new Task(2, 10000, false) // 10秒,不响应中断
);
System.out.println("Invoking with 3s timeout...");
try {
//设置3秒超时
List<Future<String>> futures = executor.invokeAll(tasks, 3, TimeUnit.SECONDS);
for (Future<String> f : futures) {
// 明确处理取消状态
if (f.isCancelled()) {
System.out.println("Task was cancelled");
} else {
try {
System.out.println("Result: " + f.get(100, TimeUnit.MILLISECONDS));
} catch (TimeoutException | ExecutionException e) {
System.out.println("Task failed: " + e.getCause());
}
}
}
} finally {
executor.shutdownNow();
System.out.println("Executor shutdown");
}
}
}当我们使用invokeAll(tasks, timeout) 提交多个任务时,如果出现某个任务对中断不响应或者响应不及时,那我们即使设置了超时时间,不响应中断的任务2仍在后台运行(即使调用了 shutdownNow())
5.2 submit()的异常消失了?
使用ExecutorService.submit()提交任务时,任务执行过程中如果抛出未捕获的异常(无论是受检异常还是运行时异常),这个异常会被Future的包装类如FutureTask重写的run()方法捕获并封装在返回的Future包装对象的成员变量中。
- 不显示调用Future.get(),该异常我们就无法感知,好像没有发生过一样。线程池的工作线程本身通常会有一个默认的未捕获异常处理器,可能会打印堆栈到控制台,但你的主业务逻辑不会知道。
- 显示调用Future.get(),抛出声明式的ExecutionException,其cause属性才是原始的任务异常。
- 如果调用Future.get(long timeout, TimeUnit unit)超时,向外抛出声明式的TimeoutException。此时任务可能仍在后台执行,可能错过了内部的异常。
submit()异常消失demo:
csharp
public class ThreadPoolExceptionDemo {
public static void main(String[] args) {
// 创建单线程线程池(便于观察异常)
ExecutorService executor = Executors.newSingleThreadExecutor();
// 场景1:Callable抛出异常(通过Future.get()捕获)
Future<String> future1 = executor.submit(() -> {
System.out.println("[Callable] 开始执行");
Thread.sleep(100);
throw new RuntimeException("Callable故意抛出的异常");
});
try {
System.out.println("Callable结果: " + future1.get());
} catch (ExecutionException e) {
System.err.println("捕获到Callable异常: " + e.getCause().getMessage());
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
// 场景2:Runnable抛出异常(同样通过Future.get()捕获)
Future<?> future2 = executor.submit(() -> {
System.out.println("[Runnable] 开始执行");
throw new IllegalArgumentException("Runnable故意抛出的异常");
});
try {
future2.get(); // Runnable成功时返回null
} catch (ExecutionException e) {
System.err.println("捕获到Runnable异常: " + e.getCause().getMessage());
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
// 场景3:未处理的任务异常(需设置异常处理器)
executor.submit(() -> {
System.out.println("[未捕获的任务] 开始执行");
throw new IllegalStateException("这个异常会被默认处理器处理");
});
executor.shutdown();
}
}5.3 异常处理实践
- Callable/Runnable catch处理异常:
-
- 不要捕获Throwable或Exception然后静默处理(只打日志) 。如果确实需要捕获,请考虑是否应该重新抛出(包装成业务允许的受检异常或运行时异常)。
- 禁止静默处理 InterruptedException:
- 在JDK的JUC底层源码中,我们可以看到很多声明了InterruptedException的方法,基本上都是对这类方法catch异常,要么继续往外抛出,或者处理完相关资源后,重置中断状态,绝对不要静默处理。
- 如果方法没有声明InterruptedException如Runnable.run(),在catch InterruptedException后最好调用Thread.currentThread().interrupt()来恢复中断标记。
- 正确处理中断:callable在耗时的loop任务处理中,如果出现了中断异常,因为Java代码中中断只是一种协作方式,其并没真的终止线程,所以一般都是需要我们进行一个中断标志的传递,如线程池中的shutdownNow()就依赖次机制处理。
- submit()执行的任务,谨慎处理Future:
-
- 使用带过期时间的future.get(long timeOut)获取结果,并要对该方法进行try cache防止其他异常抛出。
- 多个任务并行处理时,如果有下个请求依赖上个请求,务必使用get()让主线程等待这一结果执行完成后,流转到下一个异步任务。
- 实现线程Thread的UncaughtExceptionHandler属性,在自定义的TheadFactory中通过set方法赋值:execute()方法执行时,对于没有捕获的异常使用线程组的兜底统一处理机制。
java
//自定义当前线程组创建线程的统一异常处理,类似于controller的统一异常处理机制
ThreadFactory myThreadFactory = new ThreadFactory() {
private final AtomicInteger atomicInteger = new AtomicInteger(0);
private final String threadNamePrefix = "myThreadFactory-";
@Override
public Thread newThread(Runnable r) {
Thread t = new Thread(r,threadNamePrefix + atomicInteger.getAndIncrement());
t.setUncaughtExceptionHandler((thread, throwable) -> {
//异常的统一处理,日志打印、兜底处理、监控、资源释放等
System.err.println("线程[" + thread.getName() + "]异常: " + throwable);});
return t;
}
};
//构造方法时使用自定义的线程工厂
ExecutorService executor = new ThreadPoolExecutor(
corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
threadFactory,
handler
);- 使用自定义线程池时建议重写钩子方法afterExecute(Runnable r, Throwable t) :这个hook方法是用来解决当前任务线程发生的异常,默认是空实现,我们可以重写他,比如进行兜底的线程继续执行,打印日志记录,以及同步失败使用兜底异步处理等等方式。还要注意释放应用中的资源,比如文件锁的占用等,最好手动释放掉,避免底层操作系统线程对这类资源释放失败导致长期占用,最后只能重启Java进程的尴尬地步。
java
public class MyThreadPoolExecutor extends ThreadPoolExecutor {
public MyThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue);
}
@Override
protected void afterExecute(Runnable r, Throwable t) {
//需要特别注意任务是否为submit提交,如果是execute提交的任务,那这里很直接的知道任务是否发生异常以及后续去怎么处理
if(r instanceof Future){
if(((Future<?>) r).isDone() || ((Future<?>) r).isCancelled()){
//继续使用主线程完成任务,一般不建议,最好使用兜底方式:例如异步发消息,由后续的消费组统一处理异常的任务
}
}else if( t != null){
//execute异常处理
}
}
}
//FutureTask 把run方法进行了重写,并且catch住了异常,所以说afterExecute的t 如果是submit提交的方式
//那么t基本上就是null
public void run() {
//....
try {
Callable<V> c = callable;
if (c != null && state == NEW) {
V result;
boolean ran;
try {
result = c.call();
ran = true;
} catch (Throwable ex) {
result = null;
ran = false;
setException(ex);
}
if (ran)
set(result);
}
} finally {
//...
}afterExecute可以借鉴的示例:
java
import java.util.concurrent.*;
import java.util.concurrent.atomic.*;
import org.slf4j.*;
public class RobustThreadPool extends ThreadPoolExecutor {
private static final Logger logger = LoggerFactory.getLogger(RobustThreadPool.class);
private final AtomicLong failureCounter = new AtomicLong();
private final RetryPolicy retryPolicy; // 重试策略
private final ThreadLocal<Long> startTime = new ThreadLocal<>();
public RobustThreadPool(int corePoolSize, int maxPoolSize,
BlockingQueue<Runnable> workQueue,
RetryPolicy retryPolicy) {
super(corePoolSize, maxPoolSize, 60L, TimeUnit.SECONDS, workQueue);
this.retryPolicy = retryPolicy;
}
@Override
protected void beforeExecute(Thread t, Runnable r) {
logger.debug("开始执行任务: {}", r);
}
@Override
protected void afterExecute(Runnable r, Throwable t) {
// 1. 异常分类处理
if(r instanceof Future){
if(((Future<?>) r).isDone()){
//错误记录以及异常处理
failureCounter.incrementAndGet();
handleFailure(r, t, costTime);
}
}else if( t != null){
//execute异常处理
failureCounter.incrementAndGet();
handleFailure(r, t, costTime);
}
// 2. 资源清理
cleanThreadLocals();
}
private void handleFailure(Runnable r, Throwable t) {
// 1. 异常类型识别
if (t instanceof OutOfMemoryError) {
logger.error("JVM内存不足,终止任务: {}", t.getMessage());
System.exit(1); // 严重错误直接终止
}
// 2. 可重试异常处理
else if (isRetryable(t)) {
int retryCount = retryPolicy.getCurrentRetryCount(r);
if (retryCount < retryPolicy.getMaxRetries()) {
logger.warn("任务第{}次失败,准备重试...",
retryCount + 1, t);
retryPolicy.retry(r, this);
} else {
logger.error("任务超过最大重试次数({}),转入死信队列",
retryPolicy.getMaxRetries(), t);
DeadLetterQueue.add(r, t);
}
}
// 3. 不可重试异常
else {
logger.error("不可恢复任务失败", t);
Metrics.recordFailure(t.getClass()); // 上报监控
}
}
private boolean isRetryable(Throwable t) {
return t instanceof IOException ||
t instanceof TimeoutException ||
(t.getCause() != null && isRetryable(t.getCause()));
}
private void cleanThreadLocals() {
// 清理可能的内存泄漏
try {
ThreadLocal<?>[] holders = { /* 其他ThreadLocal */};
for (ThreadLocal<?> holder : holders) {
holder.remove();
}
} catch (Exception e) {
logger.warn("清理ThreadLocal失败", e);
}
}
// 重试策略嵌套类
public static class RetryPolicy {
private final int maxRetries;
private final long retryDelayMs;
private final Map<Runnable, AtomicInteger> retryMap = new ConcurrentHashMap<>();
public RetryPolicy(int maxRetries, long retryDelayMs) {
this.maxRetries = maxRetries;
this.retryDelayMs = retryDelayMs;
}
public void retry(Runnable task, Executor executor) {
retryMap.computeIfAbsent(task, k -> new AtomicInteger()).incrementAndGet();
if (retryDelayMs > 0) {
executor.execute(() -> {
try {
Thread.sleep(retryDelayMs);
} catch (InterruptedException ignored) {}
executor.execute(task);
});
} else {
executor.execute(task);
}
}
public int getCurrentRetryCount(Runnable task) {
return retryMap.getOrDefault(task, new AtomicInteger()).get();
}
public int getMaxRetries() {
return maxRetries;
}
}
}异常处理小结:要特别注意使用future.get()方法时,我们一定要注意设置超时时间,防止主线程无限期的阻塞避免边缘的业务查询影响了主业务造成得不偿失的效果,另外我们需要注意一个点就是submit()方法的提交任务时,afterExecute(Runnable r, Throwable t)中的t恒为null,如果是execute方法提交的任务,那么就是直接获取的任务执行的异常,对于submit提交的任务异常其被封装到了Futrure 包装对象中,一般需要我们再次判断任务时执行完毕还是异常或被取消了,如果发生了异常,Future.get()会抛出封装的ExecutionException异常,当然还可能是取消异常以及中断异常。invokeAll和invokeAny我们需要对返回的Future结果检查可能抛出的异常,对于callable 前面一再强调了要对InterruptedException不要静默处理,因为线程的中断标记只是一个协作方式,他并没有停止当前线程的运行,我们需要根据自身的场景对发生的中断进行快速响应以及传递中断标志。
5.4 拒绝策略实践
先带大家回顾一下策略是如何触发执行的流程:
scss
//添加任务,当不满足条件时会执行拒绝方法reject
public void execute(Runnable command) {
//...
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}
//这里就是拒绝的入口。handler是有构造方法传入
final void reject(Runnable command) {
handler.rejectedExecution(command, this);
}
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
//....
//指定拒绝策略
this.handler = handler;
}AbortPolicy:默认的拒绝策略,简单粗暴,当execute中添加woker失败时,直接在当前线程抛出异常。
typescript
public static class AbortPolicy implements RejectedExecutionHandler {
//直接抛出RejectedExecutionException
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
throw new RejectedExecutionException("Task " + r.toString() +
" rejected from " +
e.toString());
}
}优点:快速失败,立即暴露系统过载问题、避免任务静默丢失,便于监控系统捕获
缺点:需要调用方显式处理异常,增加代码复杂度,可能中断主业务流程
适用场景:适用于那些对任务丢失非常敏感,配合熔断机制使用的快速失败场景
CallerRunsPolicy:提交任务的线程,直接执行任务
typescript
public static class CallerRunsPolicy implements RejectedExecutionHandler {
//直接在提交任务的线程中执行任务
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
r.run();
}
}
}优点:任务都会被执行,不会丢任务,并且由于主线程执行任务,天然的流量控制,避免了大量的任务进入线程池。
缺点:调用线程可能被阻塞,导致上游服务雪崩。不适合高并发场景(可能拖垮整个调用链)。
适用场景:适用于处理能力不高,并且资源过载能够平滑过渡,同时不丢失任务的场景。如:低并发、高可靠性的后台任务(如日志归档)、允许同步执行的批处理系统。
DiscardPolicy:直接丢弃被拒绝的任务,不做任何通知。
typescript
public static class DiscardPolicy implements RejectedExecutionHandler {
//空实现
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
}
}优点:实现简单,无额外性能开销。避免异常传播影响主流程
缺点:数据静默丢失,可能会掩盖系统容量问题
适用场景:边缘业务的监控上报数据,统计类的uv、pv统计任务
DiscardOldestPolicy:丢弃队列中最旧的任务,然后重试提交当前任务。
typescript
public static class DiscardOldestPolicy implements RejectedExecutionHandler {
//丢弃队列中最旧的任务,重试当前任务
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
e.getQueue().poll();
e.execute(r);
}
}
}优点:优先保证新任务执行,避免队列堆积导致内存溢出。
缺点:可能丢失关键旧任务、任务执行顺序无法保证。
适用场景:适用于可容忍部分数据丢失,并且实时性要求高于历史数据的场景,比如:行情推送。
通过上线的介绍,我们可以看到JDK内置策略基本上只使用于简单处理的场景,在生产实践中一般推荐我们自定义拒绝策略,进行相关的业务处理。
1. 自定义RejectedExecutionHandler:
arduino
/**
* 带监控统计的拒绝策略处理器
*/
public class MetricsRejectedExecutionHandler implements RejectedExecutionHandler {
private static final org.slf4j.Logger logger = org.slf4j.LoggerFactory.getLogger(MetricsRejectedExecutionHandler.class);
// 统计被拒绝的任务数量
private final AtomicLong rejectedCount = new AtomicLong(0);
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
// 1. 采集线程池关键指标
int poolSize = executor.getPoolSize();
int activeThreads = executor.getActiveCount();
int corePoolSize = executor.getCorePoolSize();
int maxPoolSize = executor.getMaximumPoolSize();
int queueSize = executor.getQueue().size();
long completedTasks = executor.getCompletedTaskCount();
// 2. 递增拒绝计数器
long totalRejected = rejectedCount.incrementAndGet();
// 3. 输出警告日志(包含完整指标)
logger.warn("""
任务被拒绝执行!线程池状态:
|- 活跃线程数/当前线程数: {}/{}
|- 核心/最大线程数: {}/{}
|- 队列大小: {}
|- 已完成任务数: {}
|- 历史拒绝总数: {}
|- 被拒绝任务: {}
""",
activeThreads, poolSize,
corePoolSize, maxPoolSize,
queueSize,
completedTasks,
totalRejected,
r.getClass().getName());
// 4. 可选:降级处理(如存入数据库等待重试)
// fallbackToDatabase(r);
// 5. 抛出RejectedExecutionException(保持默认行为)
throw new RejectedExecutionException("Task " + r.toString() + " rejected");
}
// 获取累计拒绝次数(用于监控)
public long getRejectedCount() {
return rejectedCount.get();
}
}- 记录日志并告警:所有的异常处理中,最常见简单的方式无外乎,先记录个日志,然后有告警系统的进行相关的某书、某信以及短信等的告警信息推送,方便开发人员以及运维人员的及时发现问题并介入处理。
- 兜底处理机制:一般常见的就是通过异步的方式提交到MQ,然后统一进行兜底处理。
- 带超时和重试的拒绝:可以尝试等待一小段时间,或者重试几次提交,如果仍然失败,再执行最终的拒绝逻辑(如告警、持久化或抛异常)。
- 动态调整策略:根据系统的负载或任务类型,动态的执行兜底策略机制,就如前面写的源码示例方式。
2. 根据自身业务场景选择合适的拒绝策略:
- 核心业务,不容丢失:如果任务非常重要,不能丢失,可以考虑:
-
- CallerRunsPolicy:调用线程承担任务执行压力,是否可支撑;
- 自定义策略:尝试持久化到MQ或DB,然后由专门的消费组补偿任务处理;
- AbortPolicy:如果希望系统快速失败并由上层进行重试或熔断。
- 非核心业务,可容忍部分丢失:
-
- DiscardOldestPolicy:新任务更重要时,如行情推送;
- DiscardPolicy:边缘业务场景,比如一些pv统计等,丢失了无所谓;
- 及时的进行监控查看,了解任务的丢失情况。
3. 结合线程池参数综合考虑:
- 拒绝策略的选择也与线程池的队列类型(有界/无界)、队列容量、maximumPoolSize等参数密切相关。
- 如果使用无界队列LinkedBlockingQueue的无参构造,只有机器内存不够时才会进行拒绝策略,不过这种极端场景已经不是影响线程池本身,内存不够可能导致Java进程被操作系统直接kill可能。
- 如果使用有界队列,需要权衡队列的大小,核心场景甚至可以动态追踪阻塞队列大小,以及动态调整队列大小来保证核心业务的正常流转。
- 充分测试和监控:无论选择哪种策略,都必须在压测环境中充分测试其行为,并在线上环境建立完善的监控体系,监控线程池的各项指标(活跃线程数、队列长度、任务完成数、任务拒绝数等)。当拒绝发生时,应有相应的告警通知。
拒绝策略小结:
策略的选择跟我们大多数的系统设计哲学是保持一致的,都是在应对不同的场景中,做出一定的trade off。最好的策略需要根据业务场景、系统容忍度、资源等方面的综合考量,一个黄金的实践原则:拒绝事件做好监控告警、根据业务SLA定义策略,是否可丢失,快速失败等,定期的进行压力测试,验证策略的有效性。
5.5 池隔离实践
核心思想:根据任务的资源类型 、优先级和业务特性 ,划分多个独立的线程池,避免不同性质的任务相互干扰。
1. 隔离维度:
- 资源类型:CPU密集型 vs I/O密集型任务
- 执行时长:短时任务(毫秒级) vs 长时任务(分钟级)
- 实时性要求:高实时性 vs 可延迟(最终一致即可)
- 业务重要性:支付交易(高优先级) vs 日志清理(低优先级)
- 是否依赖外部资源:例如,访问特定数据库、调用特定第三方API的任务可以归为一类。
2. 不同业务场景线程池独立使用:在不同的业务场景下,为自己的特定业务,创建独立的线程池。
- 线程命名:通过ThreadFactory为每个线程池及其线程设置有意义的名称,例如netty-io-compress-pool-%d,excel-export-pool-%d, 主要方便区别不同的业务场景以及问题排查。
- 参数调优:不同的业务场景设置不同的参数。
-
- corePoolSize, maximumPoolSize:CPU密集型的计算任务可以设置小点减少上下文的切换,I/O密集型可以较大,在io阻塞等待期间,多去处理其他任务。
- 阻塞队列blockQueue:选择合适的队列类型,以及设置合理的队列大小。
- RejectedExecutionHandler:有内置的四种的策略以及自定义策略选择,一般建议做好日志、监控以及兜底的处理。
3. 自定义Executor避免线程池共用
scss
// 创建CPU密集型任务线程池(线程数=CPU核心数)
ExecutorService cpuIntensiveExecutor = new ThreadPoolExecutor(
Runtime.getRuntime().availableProcessors(), // 核心线程数=CPU核心数
Runtime.getRuntime().availableProcessors(), // 最大线程数=CPU核心数
30L, TimeUnit.SECONDS,
new LinkedBlockingQueue<>(500),
new ThreadFactoryBuilder()
.setNameFormat("cpu-pool-%d")
.setPriority(Thread.MAX_PRIORITY) // 提高优先级
.build(),
new ThreadPoolExecutor.AbortPolicy() // 直接拒绝
);
// 使用示例
CompletableFuture.supplyAsync(() -> {
// 矩阵计算等CPU密集型任务
double[][] result = matrixMultiply(largeMatrixA, largeMatrixB);
return result;
}, cpuIntensiveExecutor)
.thenAccept(result -> {
System.out.println("计算结果维度: " + result.length + "x" + result[0].length);
});线程池隔离小结:
专池专用的本质是通过物理隔离实现:
- 资源保障 :关键业务独占线程资源
- 故障隔离 :避免级联雪崩
- 性能优化 :针对任务类型最大化吞吐量
最终呈现的效果是像专业厨房的分区(切配区/炒菜区/面点区)一样,让每个线程池专注处理同类任务,提升整体效率和可靠性。
六、总结
线程池是Java并发编程的核心组件,通过复用线程减少资源开销,提升系统吞吐量。其核心设计包括线程复用机制 、任务队列和拒绝策略 ,通过ThreadPoolExecutor的参数(核心线程数、最大线程数、队列容量等)实现灵活的资源控制。线程池的生命周期由RUNNING、SHUTDOWN等状态管理,确保任务有序执行或终止。
内置线程池(如Executors.newCachedThreadPool)虽便捷,但存在内存溢出或无界队列堆积的风险,需谨慎选择。invokeAll的超时失效和submit提交任务的异常消失是常见陷阱需通过正确处理中断和检查Future.get()规避。
最佳实践包括:
- 异常处理:通过afterExecute来对发生的异常进行兜底处理,任务细粒度的try catch或UncaughtExceptionH捕获异常处理防止线程崩溃退出;
- 拒绝策略:根据业务选择拒绝策略或自定义降级逻辑,生产级应用建议尽量自定义处理;
- 线程隔离 :按任务类型(CPU/I/O)或优先级划分线程池,避免资源竞争。
合理使用线程池能显著提升性能,但需结合业务场景精细调参,确保稳定性和可维护性,希望这篇文章能给大家带来一些生产实践上的指导,减少一些因为不熟悉线程池相关原理生产误用导致的一些问题。
往期回顾
-
基于浏览器扩展 API Mock 工具开发探索|得物技术
-
破解gh-ost变更导致MySQL表膨胀之谜|得物技术
-
MySQL单表为何别超2000万行?揭秘B+树与16KB页的生死博弈|得物技术
-
0基础带你精通Java对象序列化--以Hessian为例|得物技术
-
前端日志回捞系统的性能优化实践|得物技术
文 /舍得
关注得物技术,每周更新技术干货
要是觉得文章对你有帮助的话,欢迎评论转发点赞~
未经得物技术许可严禁转载,否则依法追究法律责任。