文章目录
摘要
本周对transformer进行训练,并将transformer用于简单的机器翻译任务。
Abstract
Train the transformer this week and use the transformer for simple machine translation tasks.
1 transformer
之前多次尝试理解注意力机制和自注意力机制,顾名思义的理解是很简单的,就是关注重要的信息,忽略不重要的信息,但是将这个简单的概念,通过Q、K、V进行理解时,对我来说就会很困难,对一个查询query看与每个词的关联性,需要把这个Q和每个词的K矩阵相乘,得到一个权重,然后得到的权重与每个词的V矩阵相乘,这个query得到的结果就会包含每个关键词的信息。
1.1 注意力机制
注意力机制,在翻译时,对于生成的每一个英文词会生成一个Q,然后根据这个Q去和原句子每个词提供的K矩阵进行计算,得到英文词与哪个原单词联系更大。注意力机制主要应用于机器翻译。比如翻译'Good Morning',生成第一个词'好',就会对生成一个Q,根据这个Q去查询原句子的K和V就会得到与哪个词更匹配,然后翻译这个词就是这个'好',怎么这个'好'字呢,经过大量数据的训练,就像学英语一样,看到了I就会翻译成我,模型参数会匹配到这个'好'。
1.2 自注意力机制
自注意力机制,每个词都会生成自己的Q、K、V,然后每个词的Q会和自己以及其他的词进行相乘,然后得到一组注意力分数。自注意力机制是去理解一句话的意图,主要应用于transformer。比如,对于'苹果很甜'和'苹果手机'两句话,这两句话中的'苹果'的含义是不同的,自注意力机制会计算每一个词之间的联系,得到发现'苹果'和'甜'在一起出现,就会理解这句话的'苹果'是水果。模型怎么知道需要联系甜和苹果,模型接受了一个训练句子,'苹果很甜',最开始苹果的Q矩阵和甜的K矩阵是随机的, Q ⋅ K T Q\cdot K^T Q⋅KT是一个没什么意义的值。根据当前的参数,为每个词计算注意力分数,根据注意力分数预测'苹果很_'的下一个词,选择分数高的词进行预测,预测到的可能是'困',然后通过损失函数来计算'困'和'甜'的损失值。再通过反向传播调整参数。最后知道苹果和甜会联系在一起。
o u t p u t = s o f t m a x ( Q K T d k ) V output=softmax(\frac{QK^T}{\sqrt {d_k}})V output=softmax(dk QKT)V
1.3 掩码自注意力机制
对于训练数据集,所有的单词是同时出现的,不能让计算注意力分数的时候,看到后面的单词,应该是只能看见当前预测词之前的单词,所以需要添加一个掩码,来盖住后面的词,通常是乘以一个很大的负权重,这样后面的词就不起作用了。
1.4 多头自注意力机制
多头自注意力机制是从多个角度或者说通道去理解一句话,一句话是有情感、逻辑和语法的,比如'小猫太累了在睡觉',语法层面会理解到小猫是主语,逻辑层面理解到小猫睡觉是因为太累了,情感层面可以理解到小猫的疲惫。一个自注意力机制有三个Q、K、V,多头自注意力机制有多个Q、K、V,有n个头,就把原始的输入分成n份,然后用这n个Q、K、V来计算注意力分数,最后把这些结果拼接在一起,就会变成一个和原本输入维度相同的输出。
以上是transformer的核心内容。
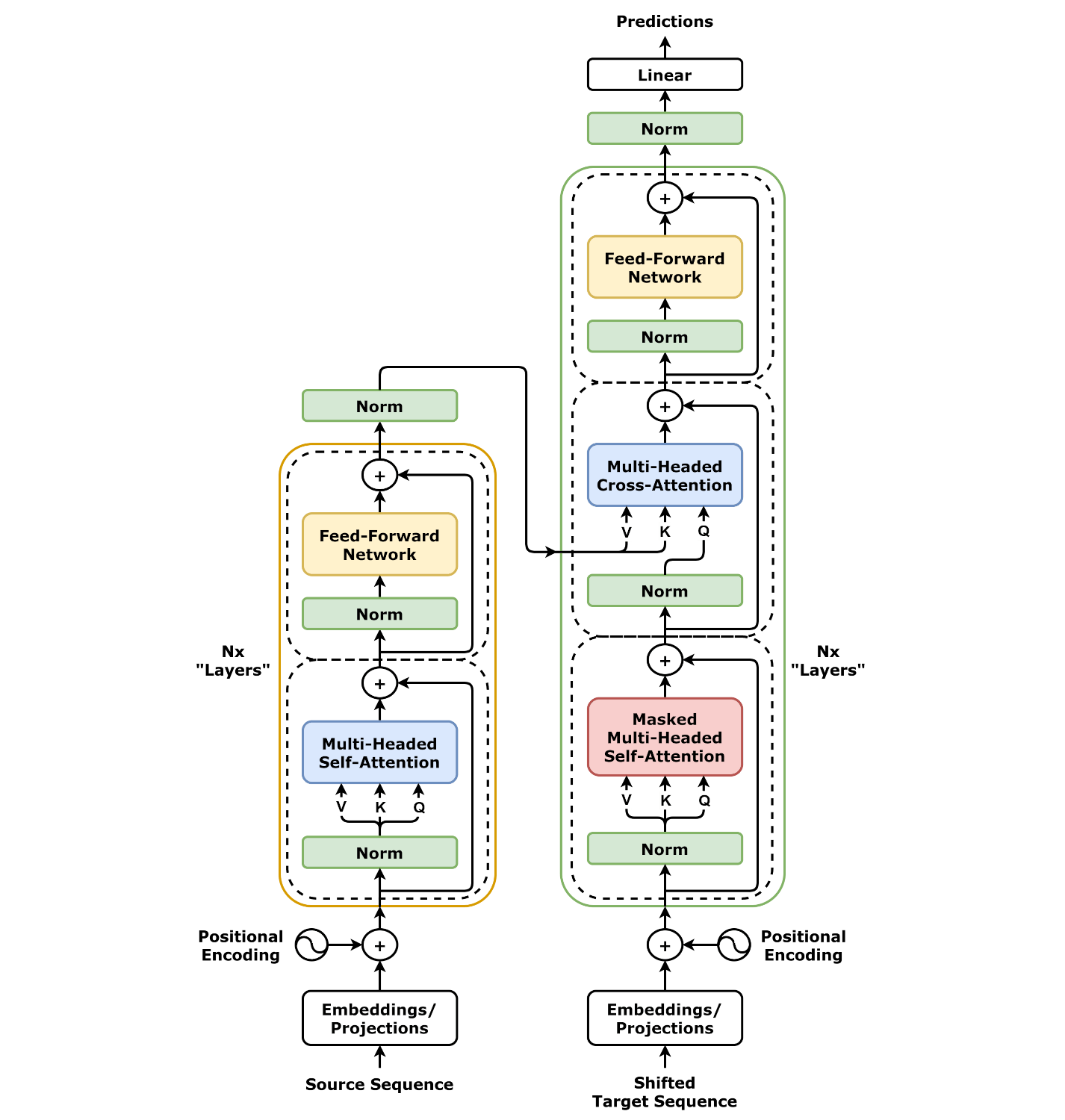
现在再回来看transformer模型,描述上稍微有点不同,解码器的第二步有一个多头交叉注意力机制,为了明确第二步的Q矩阵和K、V矩阵不是同源的双方不是来源于同一个词。理解上按照原来的理解也可以。
2 代码
python
# model.py
import torch
import torch.nn as nn
import math
from torch import optim
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
assert d_model % num_heads == 0, "d_model必须能被num_heads整除"
self.d_model = d_model # 模型维度(如512)
self.num_heads = num_heads # 注意力头数(如8)
self.d_k = d_model // num_heads # 每个头的维度(如64)
# 定义线性变换层(无需偏置)
self.W_q = nn.Linear(d_model, d_model) # 查询变换
self.W_k = nn.Linear(d_model, d_model) # 键变换
self.W_v = nn.Linear(d_model, d_model) # 值变换
self.W_o = nn.Linear(d_model, d_model) # 输出变换
def scaled_dot_product_attention(self, Q, K, V, mask=None):
"""
计算缩放点积注意力
输入形状:
Q: (batch_size, num_heads, seq_length, d_k)
K, V: 同Q
输出形状: (batch_size, num_heads, seq_length, d_k)
"""
# 计算注意力分数(Q和K的点积)
attn_scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k)
# 应用掩码(如填充掩码或未来信息掩码)
if mask is not None:
attn_scores = attn_scores.masked_fill(mask == 0, -1e9)
# 计算注意力权重(softmax归一化)
attn_probs = torch.softmax(attn_scores, dim=-1)
# 对值向量加权求和
output = torch.matmul(attn_probs, V)
return output
def split_heads(self, x):
"""
将输入张量分割为多个头
输入形状: (batch_size, seq_length, d_model)
输出形状: (batch_size, num_heads, seq_length, d_k)
"""
batch_size, seq_length, d_model = x.size()
return x.view(batch_size, seq_length, self.num_heads, self.d_k).transpose(1, 2)
def combine_heads(self, x):
"""
将多个头的输出合并回原始形状
输入形状: (batch_size, num_heads, seq_length, d_k)
输出形状: (batch_size, seq_length, d_model)
"""
batch_size, _, seq_length, d_k = x.size()
return x.transpose(1, 2).contiguous().view(batch_size, seq_length, self.d_model)
def forward(self, Q, K, V, mask=None):
"""
前向传播
输入形状: Q/K/V: (batch_size, seq_length, d_model)
输出形状: (batch_size, seq_length, d_model)
"""
# 线性变换并分割多头
Q = self.split_heads(self.W_q(Q)) # (batch, heads, seq_len, d_k)
K = self.split_heads(self.W_k(K))
V = self.split_heads(self.W_v(V))
# 计算注意力
attn_output = self.scaled_dot_product_attention(Q, K, V, mask)
# 合并多头并输出变换
output = self.W_o(self.combine_heads(attn_output))
return output
class PositionWiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff):
super(PositionWiseFeedForward, self).__init__()
self.fc1 = nn.Linear(d_model, d_ff) # 第一层全连接
self.fc2 = nn.Linear(d_ff, d_model) # 第二层全连接
self.relu = nn.ReLU() # 激活函数
def forward(self, x):
# 前馈网络的计算
return self.fc2(self.relu(self.fc1(x)))
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_seq_length):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_seq_length, d_model) # 初始化位置编码矩阵
position = torch.arange(0, max_seq_length, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * -(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term) # 偶数位置使用正弦函数
pe[:, 1::2] = torch.cos(position * div_term) # 奇数位置使用余弦函数
self.register_buffer('pe', pe.unsqueeze(0)) # 注册为缓冲区
def forward(self, x):
# 将位置编码添加到输入中
return x + self.pe[:, :x.size(1)]
class EncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads) # 自注意力机制
self.feed_forward = PositionWiseFeedForward(d_model, d_ff) # 前馈网络
self.norm1 = nn.LayerNorm(d_model) # 层归一化
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout) # Dropout
def forward(self, x, mask):
# 自注意力机制
attn_output = self.self_attn(x, x, x, mask)
x = self.norm1(x + self.dropout(attn_output)) # 残差连接和层归一化
# 前馈网络
ff_output = self.feed_forward(x)
x = self.norm2(x + self.dropout(ff_output)) # 残差连接和层归一化
return x
class DecoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout):
super(DecoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads) # 自注意力机制
self.cross_attn = MultiHeadAttention(d_model, num_heads) # 交叉注意力机制
self.feed_forward = PositionWiseFeedForward(d_model, d_ff) # 前馈网络
self.norm1 = nn.LayerNorm(d_model) # 层归一化
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout) # Dropout
def forward(self, x, enc_output, src_mask, tgt_mask):
# 自注意力机制
attn_output = self.self_attn(x, x, x, tgt_mask)
x = self.norm1(x + self.dropout(attn_output)) # 残差连接和层归一化
# 交叉注意力机制
attn_output = self.cross_attn(x, enc_output, enc_output, src_mask)
x = self.norm2(x + self.dropout(attn_output)) # 残差连接和层归一化
# 前馈网络
ff_output = self.feed_forward(x)
x = self.norm3(x + self.dropout(ff_output)) # 残差连接和层归一化
return x
class Transformer(nn.Module):
def __init__(self, src_vocab_size, tgt_vocab_size, d_model, num_heads, num_layers, d_ff, max_seq_length, dropout):
super(Transformer, self).__init__()
self.encoder_embedding = nn.Embedding(src_vocab_size, d_model) # 编码器词嵌入
self.decoder_embedding = nn.Embedding(tgt_vocab_size, d_model) # 解码器词嵌入
self.positional_encoding = PositionalEncoding(d_model, max_seq_length) # 位置编码
# 编码器和解码器层
self.encoder_layers = nn.ModuleList(
[EncoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers)])
self.decoder_layers = nn.ModuleList(
[DecoderLayer(d_model, num_heads, d_ff, dropout) for _ in range(num_layers)])
self.fc = nn.Linear(d_model, tgt_vocab_size) # 最终的全连接层
self.dropout = nn.Dropout(dropout) # Dropout
def generate_mask(self, src, tgt):
# 源掩码:屏蔽填充符(假设填充符索引为0)
# 形状:(batch_size, 1, 1, seq_length)
src_mask = (src != 0).unsqueeze(1).unsqueeze(2)
# 目标掩码:屏蔽填充符和未来信息
# 形状:(batch_size, 1, seq_length, 1)
tgt_mask = (tgt != 0).unsqueeze(1).unsqueeze(3)
seq_length = tgt.size(1)
# 生成上三角矩阵掩码,防止解码时看到未来信息
nopeak_mask = (1 - torch.triu(torch.ones(1, seq_length, seq_length), diagonal=1)).bool()
tgt_mask = tgt_mask & nopeak_mask # 合并填充掩码和未来信息掩码
return src_mask, tgt_mask
def forward(self, src, tgt):
# 生成掩码
src_mask, tgt_mask = self.generate_mask(src, tgt)
# 编码器部分
src_embedded = self.dropout(self.positional_encoding(self.encoder_embedding(src)))
enc_output = src_embedded
for enc_layer in self.encoder_layers:
enc_output = enc_layer(enc_output, src_mask)
# 解码器部分
tgt_embedded = self.dropout(self.positional_encoding(self.decoder_embedding(tgt)))
dec_output = tgt_embedded
for dec_layer in self.decoder_layers:
dec_output = dec_layer(dec_output, enc_output, src_mask, tgt_mask)
# 最终输出
output = self.fc(dec_output)
return output
python
# train.py
import re
from model import *
from collections import Counter
class TranslationDataset:
def __init__(self, src_file, tgt_file, src_vocab_size=5000, tgt_vocab_size=5000, max_length=100):
self.src_file = src_file
self.tgt_file = tgt_file
self.src_vocab_size = src_vocab_size
self.tgt_vocab_size = tgt_vocab_size
self.max_length = max_length
# 构建词汇表
self.src_vocab, self.tgt_vocab = self.build_vocabularies()
self.src_data, self.tgt_data = self.load_data()
def preprocess_text(self, text):
"""预处理文本"""
text = text.lower()
text = re.sub(r'\s+', ' ', text)
text = re.sub(r'([.,!?;:])', r' \1 ', text)
text = re.sub(r'\s+', ' ', text)
return text.strip()
def build_vocabularies(self):
"""构建源语言和目标语言的词汇表"""
src_sentences = []
tgt_sentences = []
with open(self.src_file, 'r', encoding='utf-8') as f_src, \
open(self.tgt_file, 'r', encoding='utf-8') as f_tgt:
src_lines = f_src.readlines()
tgt_lines = f_tgt.readlines()
for src_line, tgt_line in zip(src_lines, tgt_lines):
src_sentences.append(self.preprocess_text(src_line))
tgt_sentences.append(self.preprocess_text(tgt_line))
# 基于所有句子的词汇
src_all_words = []
tgt_all_words = []
for sentence in src_sentences:
src_all_words.extend(sentence.split())
for sentence in tgt_sentences:
tgt_all_words.extend(sentence.split())
# 构建词汇表
src_word_counts = Counter(src_all_words)
tgt_word_counts = Counter(tgt_all_words)
src_vocab = ['<pad>', '<unk>', '<sos>', '<eos>'] + \
[word for word, count in src_word_counts.most_common(self.src_vocab_size - 4)]
tgt_vocab = ['<pad>', '<unk>', '<sos>', '<eos>'] + \
[word for word, count in tgt_word_counts.most_common(self.tgt_vocab_size - 4)]
src_word2idx = {word: idx for idx, word in enumerate(src_vocab)}
tgt_word2idx = {word: idx for idx, word in enumerate(tgt_vocab)}
return src_word2idx, tgt_word2idx
def load_data(self):
"""加载并编码数据"""
src_sequences = []
tgt_sequences = []
with open(self.src_file, 'r', encoding='utf-8') as f_src, \
open(self.tgt_file, 'r', encoding='utf-8') as f_tgt:
src_lines = f_src.readlines()
tgt_lines = f_tgt.readlines()
for src_line, tgt_line in zip(src_lines, tgt_lines):
# 预处理
src_line = self.preprocess_text(src_line)
tgt_line = self.preprocess_text(tgt_line)
# 分词
src_words = src_line.split()[:self.max_length - 2] # 保留位置给<sos>和<eos>
tgt_words = tgt_line.split()[:self.max_length - 2]
# 编码
src_encoded = [self.src_vocab.get('<sos>', 2)] + \
[self.src_vocab.get(word, self.src_vocab.get('<unk>', 1)) for word in src_words] + \
[self.src_vocab.get('<eos>', 3)]
tgt_encoded = [self.tgt_vocab.get('<sos>', 2)] + \
[self.tgt_vocab.get(word, self.tgt_vocab.get('<unk>', 1)) for word in tgt_words] + \
[self.tgt_vocab.get('<eos>', 3)]
# 填充到最大长度
src_encoded = self.pad_sequence(src_encoded, self.max_length)
tgt_encoded = self.pad_sequence(tgt_encoded, self.max_length)
src_sequences.append(src_encoded)
tgt_sequences.append(tgt_encoded)
return torch.tensor(src_sequences), torch.tensor(tgt_sequences)
def pad_sequence(self, sequence, max_length):
"""填充序列到指定长度"""
if len(sequence) < max_length:
sequence = sequence + [0] * (max_length - len(sequence)) # 0是<pad>的索引
else:
sequence = sequence[:max_length]
return sequence
def __len__(self):
return len(self.src_data)
def __getitem__(self, idx):
return self.src_data[idx], self.tgt_data[idx]
class TranslationTrainer:
def __init__(self, model, dataset, batch_size=32):
self.model = model
self.dataset = dataset
self.batch_size = batch_size
self.criterion = nn.CrossEntropyLoss(ignore_index=0) # 忽略<pad>
self.optimizer = optim.Adam(model.parameters(), lr=0.0001, betas=(0.9, 0.98), eps=1e-9)
def train(self, epochs):
self.model.train()
for epoch in range(epochs):
total_loss = 0
num_batches = 0
# 简单的批次处理
for i in range(0, len(self.dataset), self.batch_size):
batch_src = self.dataset.src_data[i:i + self.batch_size]
batch_tgt = self.dataset.tgt_data[i:i + self.batch_size]
self.optimizer.zero_grad()
# 输入目标序列去掉最后一个词,用于预测下一个词
output = self.model(batch_src, batch_tgt[:, :-1])
# 计算损失时,目标序列从第二个词开始(即预测下一个词)
loss = self.criterion(
output.contiguous().view(-1, self.model.fc.out_features),
batch_tgt[:, 1:].contiguous().view(-1)
)
loss.backward()
self.optimizer.step()
total_loss += loss.item()
num_batches += 1
avg_loss = total_loss / num_batches
print(f"Epoch {epoch + 1}/{epochs}, Loss: {avg_loss:.6f}")
class Translator:
def __init__(self, model, src_vocab, tgt_vocab, max_length=100):
self.model = model
self.src_vocab = src_vocab
self.tgt_vocab = tgt_vocab
self.idx2word = {idx: word for word, idx in tgt_vocab.items()}
self.max_length = max_length
self.model.eval()
def translate(self, src_sentence):
"""翻译单个句子"""
# 预处理和编码源句子
src_sentence = self.preprocess_text(src_sentence)
src_words = src_sentence.split()
src_encoded = [self.src_vocab.get('<sos>', 2)] + \
[self.src_vocab.get(word, self.src_vocab.get('<unk>', 1)) for word in src_words] + \
[self.src_vocab.get('<eos>', 3)]
# 填充
src_encoded = self.pad_sequence(src_encoded, self.max_length)
src_tensor = torch.tensor(src_encoded).unsqueeze(0) # 添加batch维度
# 开始翻译
with torch.no_grad():
# 初始化目标序列(只有<sos>)
tgt_sequence = torch.tensor([[self.tgt_vocab.get('<sos>', 2)]])
for i in range(self.max_length - 1):
output = self.model(src_tensor, tgt_sequence)
# 获取最后一个词的预测
next_word_logits = output[0, -1, :]
next_word_idx = torch.argmax(next_word_logits).item()
# 如果遇到<eos>则停止
if next_word_idx == self.tgt_vocab.get('<eos>', 3):
break
# 将预测的词添加到序列中
next_word_tensor = torch.tensor([[next_word_idx]])
tgt_sequence = torch.cat([tgt_sequence, next_word_tensor], dim=1)
# 解码目标序列
translated_words = []
for idx in tgt_sequence[0][1:].tolist(): # 跳过<sos>
if idx == self.tgt_vocab.get('<eos>', 3):
break
word = self.idx2word.get(idx, '<unk>')
if word not in ['<sos>', '<eos>', '<pad>']:
translated_words.append(word)
return ' '.join(translated_words)
def preprocess_text(self, text):
text = text.lower()
text = re.sub(r'\s+', ' ', text)
text = re.sub(r'([.,!?;:])', r' \1 ', text)
text = re.sub(r'\s+', ' ', text)
return text.strip()
def pad_sequence(self, sequence, max_length):
if len(sequence) < max_length:
sequence = sequence + [0] * (max_length - len(sequence))
else:
sequence = sequence[:max_length]
return sequence
# 使用示例
def main():
# 创建数据集
dataset = TranslationDataset(
src_file='source.txt', # 源语言文件
tgt_file='target.txt', # 目标语言文件
src_vocab_size=2000,
tgt_vocab_size=2000,
max_length=50
)
# 创建模型
transformer = Transformer(
src_vocab_size=len(dataset.src_vocab),
tgt_vocab_size=len(dataset.tgt_vocab),
d_model=256,
num_heads=4,
num_layers=4,
d_ff=512,
max_seq_length=50,
dropout=0.1
)
# 训练
trainer = TranslationTrainer(transformer, dataset, batch_size=32)
trainer.train(epochs=25)
# 创建翻译器
translator = Translator(transformer, dataset.src_vocab, dataset.tgt_vocab,50)
# 测试翻译
test_sentence1 = "chinese boy"
translation1 = translator.translate(test_sentence1)
print(f"原文: {test_sentence1}")
print(f"翻译: {translation1}")
test_sentence2 = "i am chinese"
translation2 = translator.translate(test_sentence2)
print(f"原文: {test_sentence2}")
print(f"翻译: {translation2}")
if __name__ == "__main__":
main()以上代码是transformer的代码,通过训练用于翻译任务。
text
原文: chinese boy
翻译: 是 一个 男孩
原文: i am chinese
翻译: 我 是 中国人翻译的结果并不好,训练的epoch太小,文本数据量太少,超参数没有进行调整。但是至少代码跑起来了。
source.txt和target.txt放在了gitee
https://gitee.com/diskcache/transformer.git
总结
transformer是一个新的架构,和之前的神经网络都有很大不同,但是效果却是很好,而且可以用于图像处理中,下周将学习transformer用于图像处理。