AI Agent 产品推荐方案:从需求分析到落地开发
一、企业业务痛点
您的企业是否曾面临这样的困境?
企业产品品类繁多,单个产品的参数常达数十上百个,类型各异(部分为数字类型,部分为文字类型),且参数重要性存在差异(例如发电机的 "输出功率" 权重远高于 "占地面积")。
客户下单渠道分散(个人微信、企微外部用户、邮件、Excel 文件等),需求描述完整性不一 ------ 部分描述详尽,部分仅为简洁表述。此时,员工需基于对全量产品的深度理解,从多渠道需求中筛选匹配度最高的产品推荐给客户,操作难度极大。
二、传统解决方案的局限
在大模型技术普及前,这类问题通常依赖经验丰富的员工手动处理:员工需投入大量时间响应多渠道需求,提供的推荐仅基于个人判断,无法确保综合考量企业所有产品及各参数权重,推荐结果的客观性与全面性难以保障。
2025 年作为 AI Agent 元年,我们可通过开发专属 AI Agent 解决这一场景,实现产品推荐的自动化与精准化。
三、AI Agent 范式选择
如同学生写作需区分议论文、说明文、记叙文的 "套路",AI Agent 开发也存在可遵循的标准范式(随技术迭代持续扩充)。以下重点介绍两类核心范式,并匹配业务场景选择最优方案。
RAG范式
适用场景:需查询多份非结构化材料(如行业专业文献、企业只读规章、产品说明书),或解答 SOP(标准作业流程)、FAQ(常见问题)类知识问题,且匹配需求为 "非严格匹配" 时,优先选择 RAG 范式。
核心流程:
- 后台处理:① 录入知识文本 → ② 文本预处理(切片、扩增) → ③ 特征提炼与向量转换 → ④ 向量库存储;
- 前台交互:① 选择知识领域并提问 → ② 提问内容特征提炼与向量转换 → ③ 向量库检索相关知识并排序 → ④ 关联知识传入大语言模型生成答案 → ⑤ 前端结构化呈现结果。
意图识别范式
适用场景:业务需通过自然语言触发系统操作,或需将模糊需求转换为系统操作参数,且操作可枚举、高频场景覆盖率高(多数用户需求可明确归类)时,适用意图识别范式。
核心流程:
① 对用户输入进行意图识别,关联外部数据库 / 知识库匹配特定 API;
② 调用大语言模型填充参数(需与外部数据库 / 知识库通信);
③ 权限控制下执行查询(含业务数据处理);
④ 后续业务逻辑处理;
⑤ 输出用户分析结论。
场景匹配结论
结合 "产品参数推荐" 场景特性,无需完整意图识别环节,仅需提取产品参数即可实现需求,因此简化后的意图识别范式为最优选择。
四、AI Agent 逐步开发流程
第0步:学习葡萄城市场的向量计算插件和对象与集合操作工具插件
葡萄城市场是葡萄城官方的生态聚集平台,其中活字格开发实验室店铺里面有两个插件是我们需要使用到的。


向量计算插件
向量归一化、哈达玛积(逐元素乘法)、欧几里得距离、余弦相似度、向量缩放(标量乘法)。
我们当下需要用到的是哈达玛积和余弦相似度。
哈达玛积(Hadamard product)
对于两个维度相等的向量A=ai和B=bi,向量ai\*bi为A和B的哈达玛积。
我们以这个向量计算插件举个例子

结果是

余弦相似度
描述的是两个向量的方向接近程度,取值范围是-1到1,-1表示完全相反,1表示完全相同,0表示互相没有关系。越接近1表示,方向越接近。
同样的,我们用向量计算插件举例子

显然,这两个向量是大小相等,方向相同的,那么计算出来的余弦相似度是多少呢?

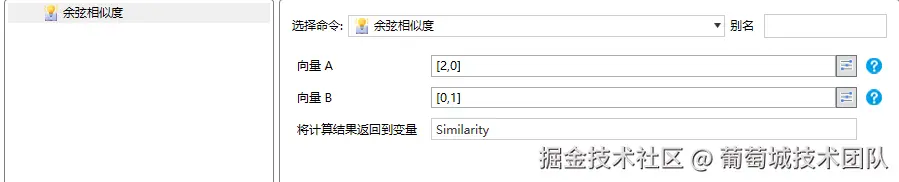
这两个向量是互相垂直的,它们的余弦相似度是多少呢?

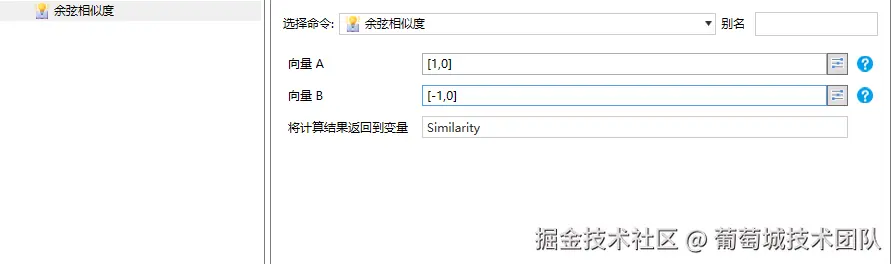
这两个向量互相相反,那么相似度是多少呢?

对象与集合操作工具
是用来处理数组、对象和字典等数据结构的。我们这个场景主要用的是数组操作、数组排序和在数组中查询

数组操作


我们来看下distinct、select和slice等。
Distinct

其中引用到的上下文变量arr是"1","2","3","1","2","333","",处理完成后的array是"1","2","3","333","",注意我的""是空串,不是空值,因此是没有去除的。
Select
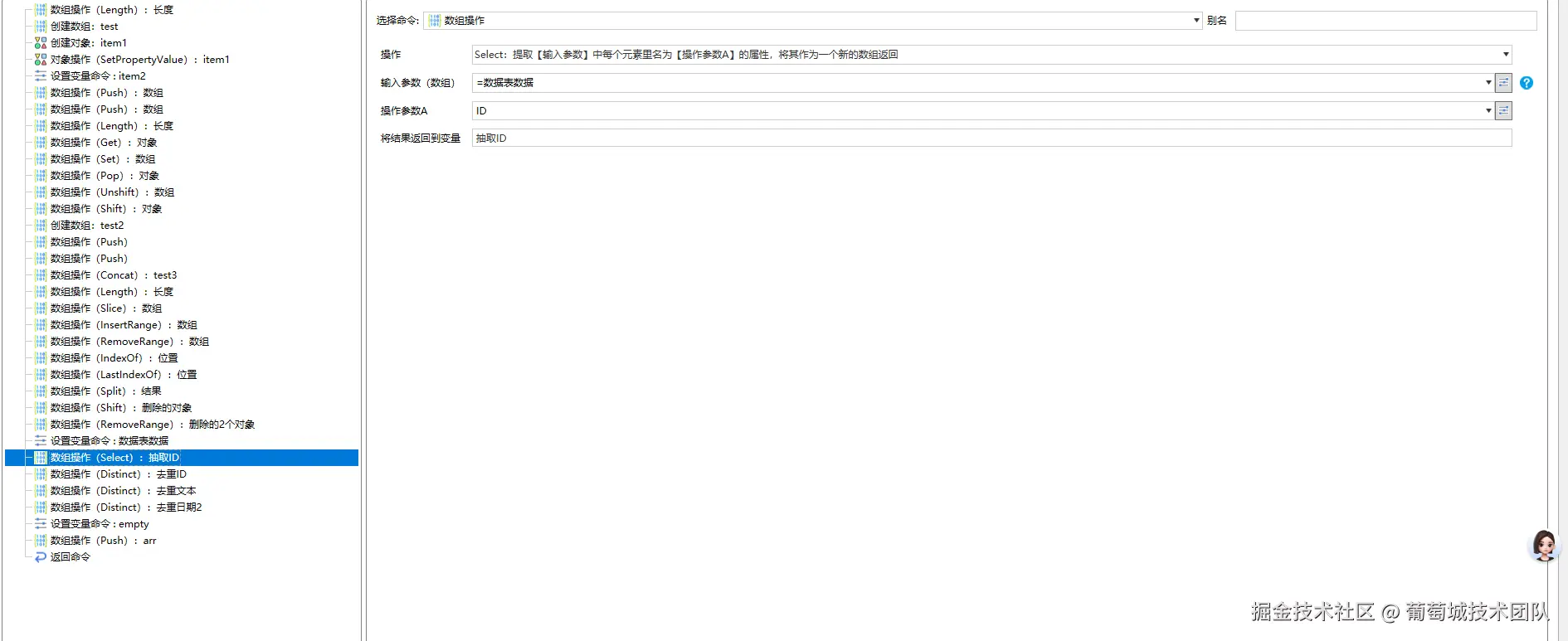
其中引用到的上下文变量数据表数据为
JSON
[
{
"ID": 1,
"文本": "AB",
"整数": 1,
"小数": 1.5,
"日期": 44927.75,
"是_否": 0
},
{
"ID": 2,
"文本": "BC",
"整数": 2,
"小数": 2.5,
"日期": 44927.99998842592,
"是_否": 1
},
{
"ID": 3,
"文本": "CD",
"整数": 3,
"小数": 3.5,
"日期": 44928,
"是_否": 0
},
{
"ID": 4,
"文本": "DE",
"整数": 4,
"小数": 4.5,
"日期": 44929,
"是_否": 1
},
{
"ID": 5,
"文本": "EF",
"整数": 5,
"小数": 5.5,
"日期": 44929,
"是_否": 0
},
{
"ID": 6,
"文本": "EF",
"整数": 6,
"小数": 6.5,
"日期": 45022,
"是_否": 1
}经过select操作,抽取ID数组为1,2,3,4,5,6。
Slice
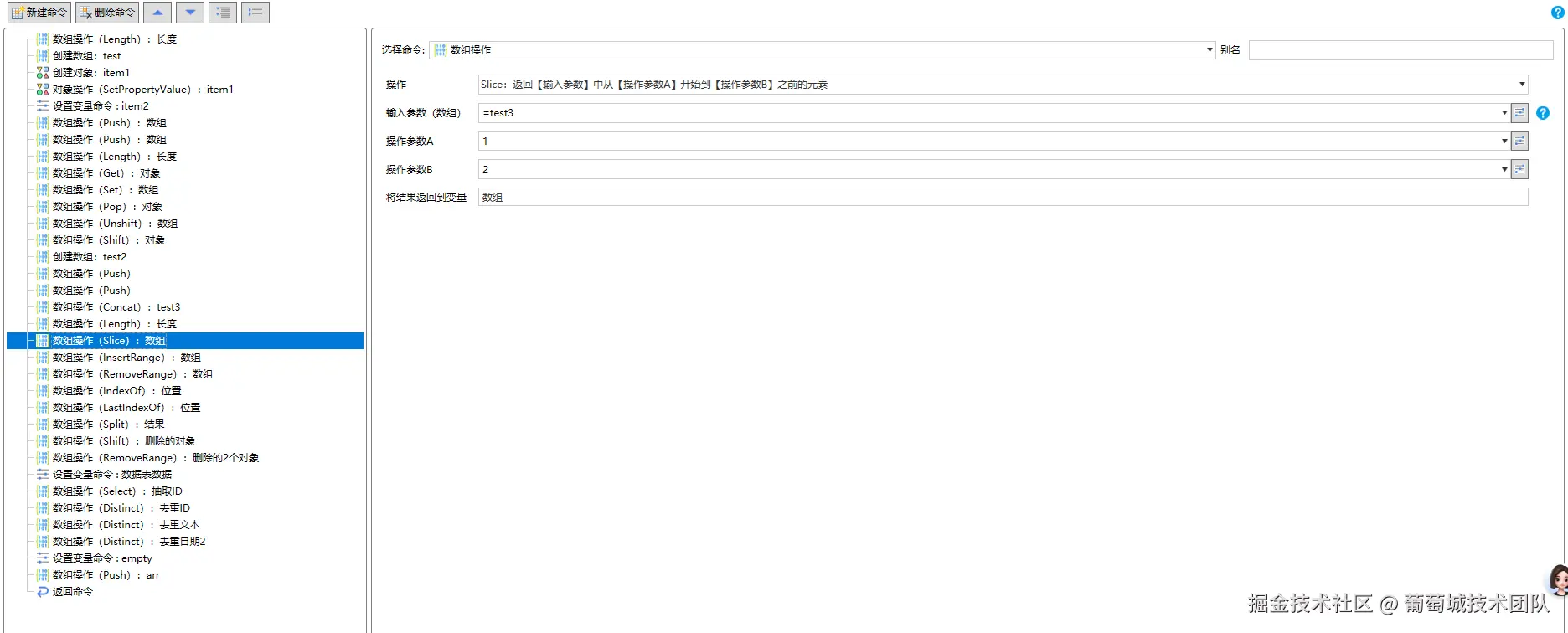
test3为 {"ping":"pong"},"2A","2B",slice后数组为"2A"
数组排序
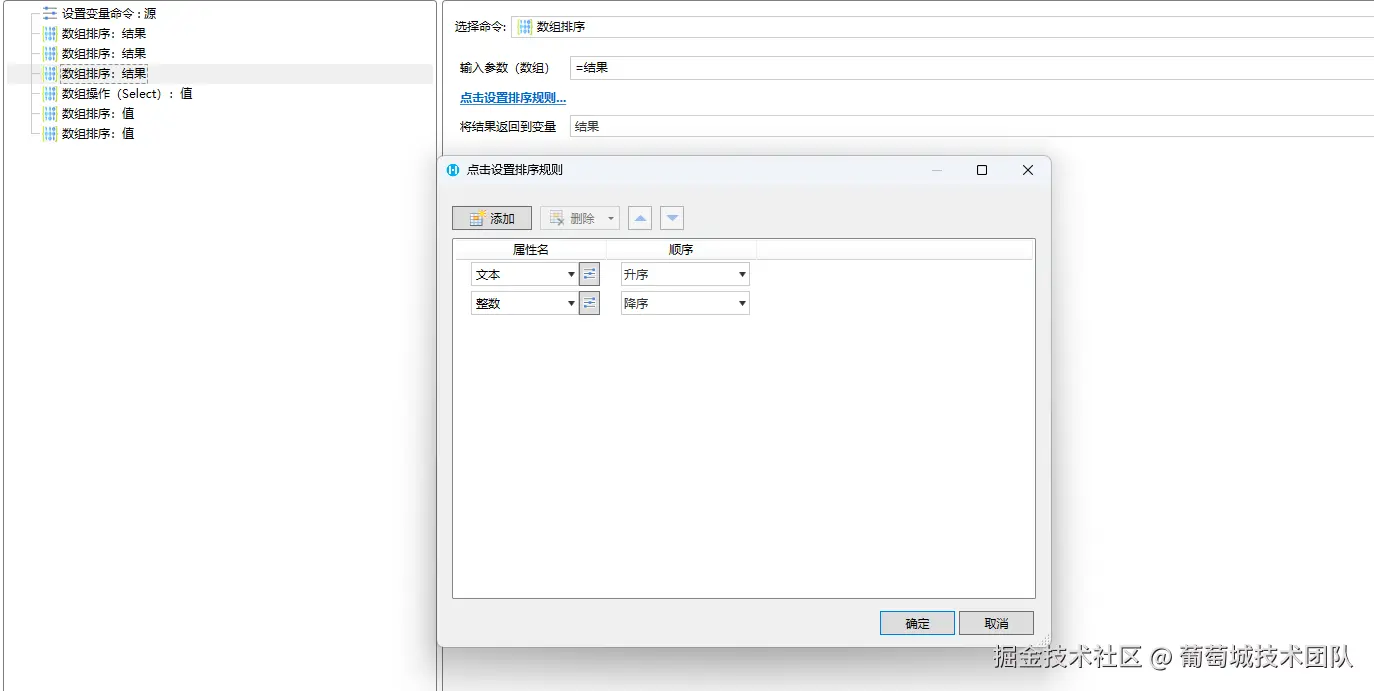
排序前数组为
JSON
[
{
"ID": 6,
"文本": "EF",
"整数": 6,
"小数": 6.5,
"日期": 45022,
"是_否": 1
},
{
"ID": 5,
"文本": "EF",
"整数": 5,
"小数": 5.5,
"日期": 44929,
"是_否": 0
},
{
"ID": 4,
"文本": "DE",
"整数": 4,
"小数": 4.5,
"日期": 44929,
"是_否": 1
},
{
"ID": 3,
"文本": "CD",
"整数": 3,
"小数": 3.5,
"日期": 44928,
"是_否": 0
},
{
"ID": 2,
"文本": "BC",
"整数": 2,
"小数": 2.5,
"日期": 44927.99998842592,
"是_否": 1
},
{
"ID": 1,
"文本": "AB",
"整数": 1,
"小数": 1.5,
"日期": 44927.75,
"是_否": 0
}
]排序后数组为
JSON
[
{
"ID": 1,
"文本": "AB",
"整数": 1,
"小数": 1.5,
"日期": 44927.75,
"是_否": 0
},
{
"ID": 2,
"文本": "BC",
"整数": 2,
"小数": 2.5,
"日期": 44927.99998842592,
"是_否": 1
},
{
"ID": 3,
"文本": "CD",
"整数": 3,
"小数": 3.5,
"日期": 44928,
"是_否": 0
},
{
"ID": 4,
"文本": "DE",
"整数": 4,
"小数": 4.5,
"日期": 44929,
"是_否": 1
},
{
"ID": 6,
"文本": "EF",
"整数": 6,
"小数": 6.5,
"日期": 45022,
"是_否": 1
},
{
"ID": 5,
"文本": "EF",
"整数": 5,
"小数": 5.5,
"日期": 44929,
"是_否": 0
}
]在数组中查询
支持where、first和last三个操作。
Where
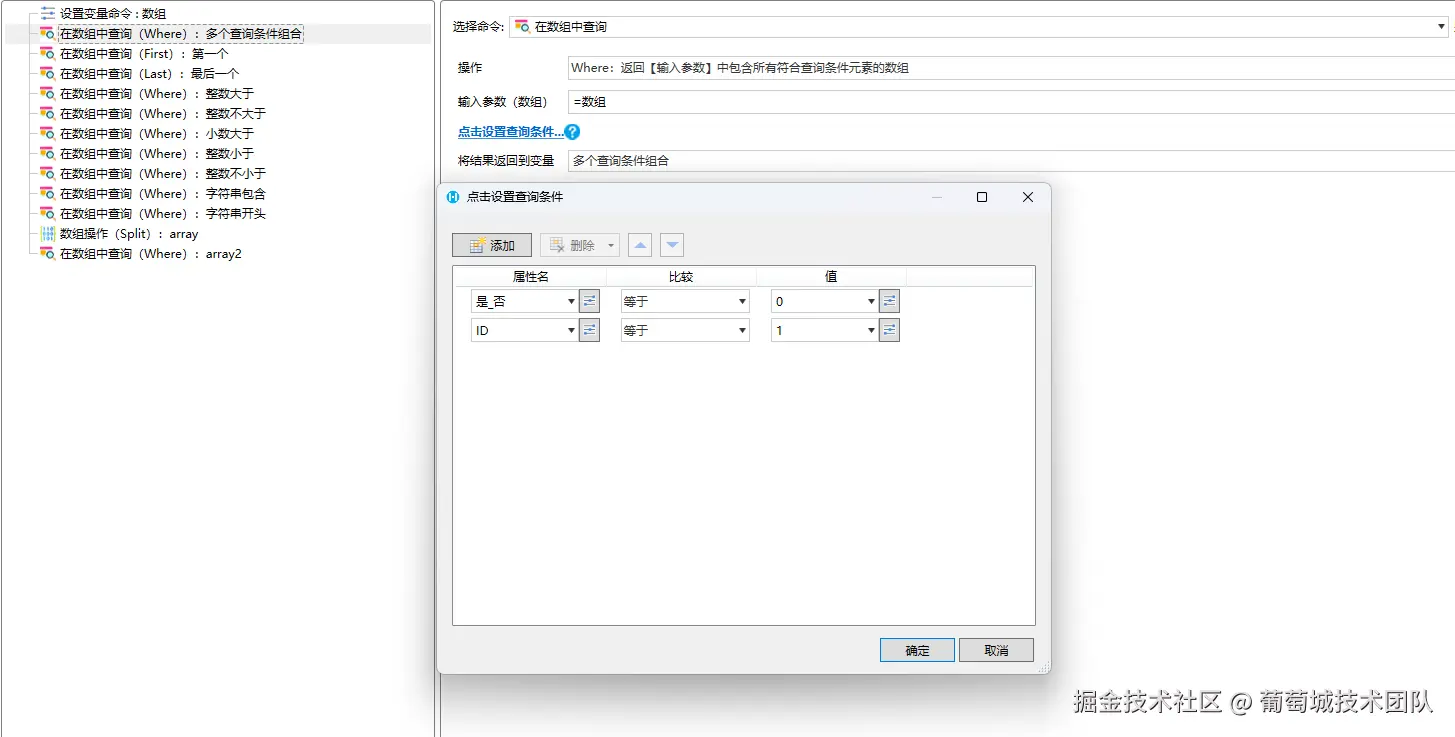
数组为
JSON
[
{
"ID": 1,
"文本": "AB",
"整数": 1,
"小数": 1.5,
"日期": 44927.75,
"是_否": 0
},
{
"ID": 2,
"文本": "BC",
"整数": 2,
"小数": 2.5,
"日期": 44927.99998842592,
"是_否": 1
},
{
"ID": 3,
"文本": "CD",
"整数": 3,
"小数": 3.5,
"日期": 44928,
"是_否": 0
},
{
"ID": 4,
"文本": "DE",
"整数": 4,
"小数": 4.5,
"日期": 44929,
"是_否": 1
},
{
"ID": 5,
"文本": "EF",
"整数": 5,
"小数": 5.5,
"日期": 44929,
"是_否": 0
},
{
"ID": 6,
"文本": "EF",
"整数": 6,
"小数": 6.5,
"日期": 45022,
"是_否": 1
}
]经过查询,多个查询条件组合为{"ID":1,"文本":"AB","整数":1,"小数":1.5,"日期":44927.75,"是_否":0}
First
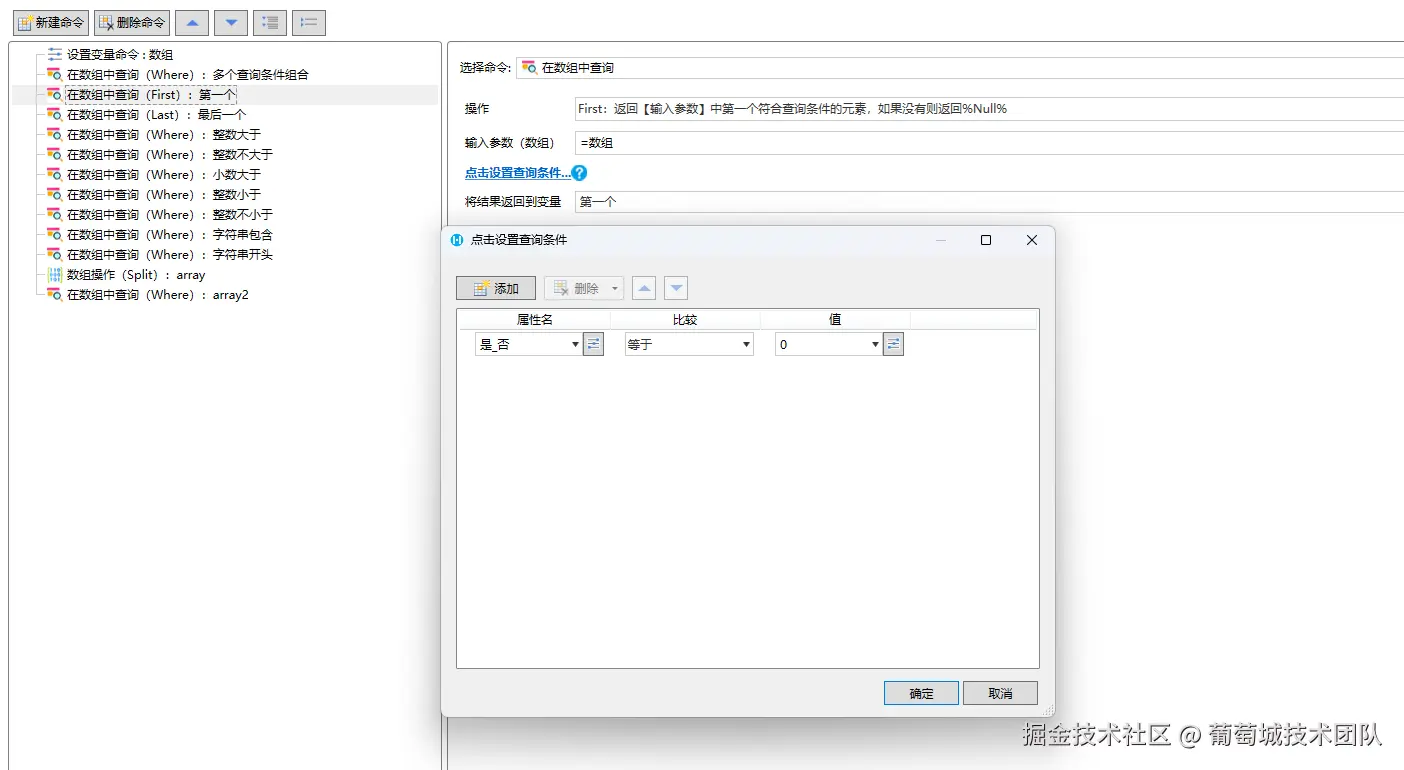
经过查询,第一个{"ID":1,"文本":"AB","整数":1,"小数":1.5,"日期":44927.75,"是_否":0}
Last
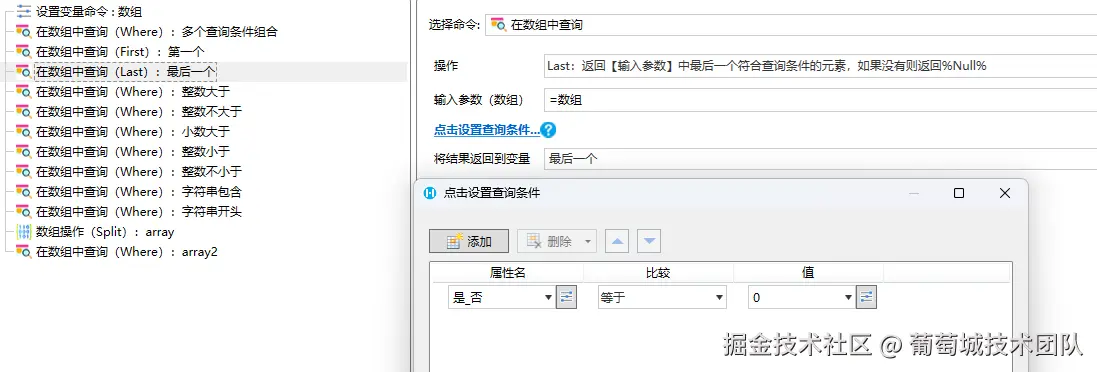
经过查询,最后一个{"ID":5,"文本":"EF","整数":5,"小数":5.5,"日期":44929.0,"是_否":0}
第1步:了解prompt在线管理
在AI Agent中,prompt是一个很关键的环节。在活字格自带的AI对话单元格、AI助手命令中,prompt是可以手动写入的,比较便捷。
但是这带来了一个比较麻烦的问题,就是如果应用已经发布,现在需要修改prompt,那么开发者需要打开设计器改动prompt,然后重新发布应用,比较繁琐而且容易出现发布失败。
因此更好的实践是把prompt存储到数据库,加入版本管理,并且给提示词编辑配置一个前端页面。如此,届时只需在前端页面里面改动即可生效,高效且相对安全。
一般提示词模块ER图如下
暂时无法在飞书文档外展示此内容
操作层面,必须熟练掌握两个工具:设置变量命令和SUBSTITUTE公式。设置变量命令可以用于页面的命令和服务端命令,详见www.grapecity.com.cn/solutions/h...
SUBSTITUE公式用法和excel保持一致,可以用于页面的单元格、命令和服务端命令。
前端页面部分,一般是根据项目需求,利用页面引擎进行定制,下图是AI筛选简历的样式

第2步:定义全局变量
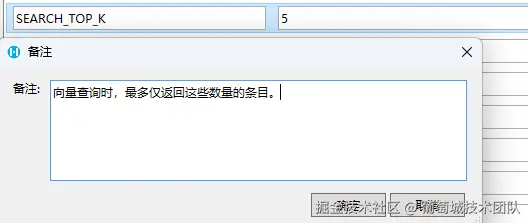
在AI Agent中,经常会用到一个关键值,最接近的数量,习惯上我们命名为TopK,这个值在各种地方频繁使用,如果我们都是直接写3或者5这种固定值的话,那么后期如果要更改起来很容易遗漏而且工作量不小。
因此,活字格提供了全局变量功能,可以为项目进行设置。

这是一个示例
第3步:进行数据库设计
由于前面已经分析了prompt底层表结构,我们此处仅仅展示业务数据表的ER图
暂时无法在飞书文档外展示此内容
第4步:开发重置同一值
我们需要开发一个服务端命令把数据库里面每个产品的每个参数根据其维度的上下限进行归一化处理,即映射到-1到1区间内,方便后续的距离运算。
在此之前,需要开发一个私有的服务端命令normalize,来进行给定维度ID和值后,进行归一化。显然normalize私有服务端命令的入参有两个:维度ID和值,出参是一个:同一值。
内部逻辑为:
- 根据维度ID查询量程上限和下限
- 利用excel公式进行同一化
=2*(LN(1+MIN(MAX(值,量程下限),量程上限)-量程下限)/LN(1+(量程上限-量程下限)))-1
- 返回同一值给调用方
接下来,我们需要开发重置同一值服务端命令,入参和出参都不需要。
内部逻辑为:
- 查询所有的产品规格参数,类型为对象数组,对象里面三个属性:ID、原始值、维度ID
- 遍历产品规格参数数组,把对象的维度ID和原始值传递给上面开发的私有的服务端命令normalize,拿到对应的同一值,紧接着根据对象的ID属性把产品规格参数表的同一值字段更新为刚刚返回的同一值
这样子,我们只需要调用下重置同一值服务端命令即可完成数据库里面各个产品的各个参数同一化了。
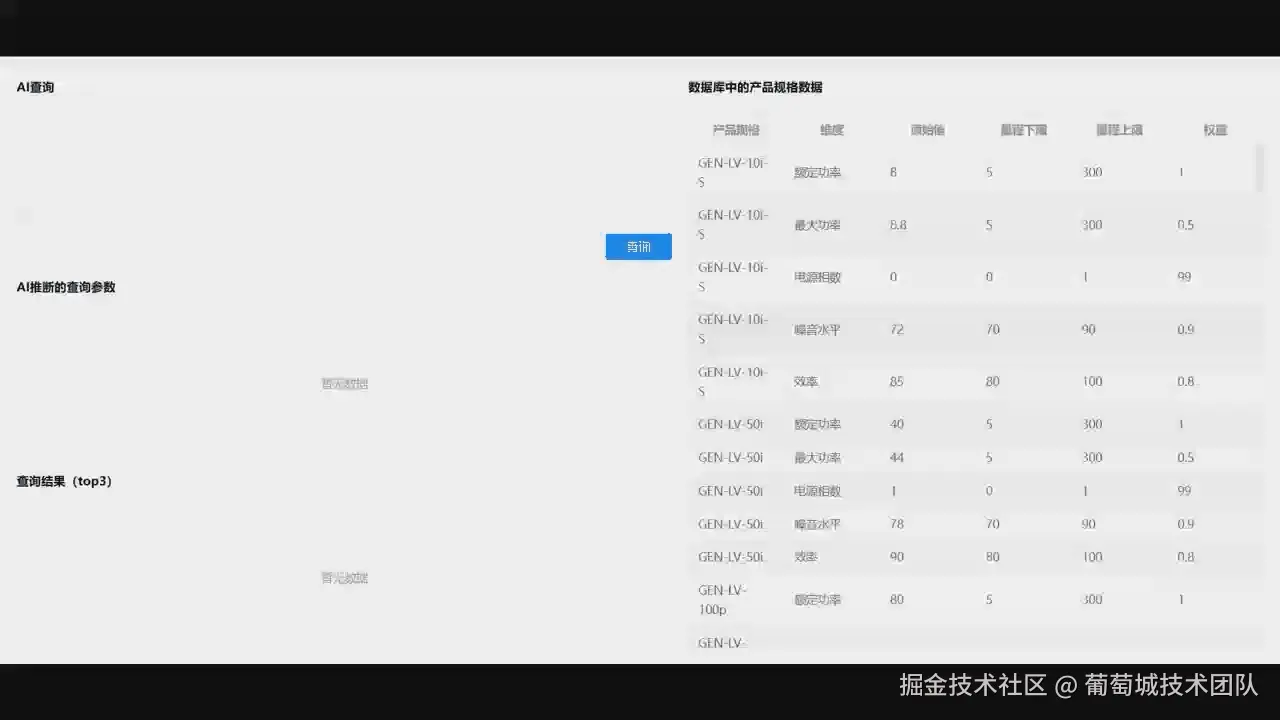
第5步:开发AI查询业务
(一)开发embedding私有服务端命令
我们需要对用户输入的查询条件进行同一化处理,并且由于我们的各个维度都是有权重的,因此需要按照各自的权重生成一个蒙版向量来体现权重区别。
入参为查询条件数组,出参有两个:查询向量和规格模板向量。
内部逻辑为:
- 将查询条件数组JSON反序列化为数组
- 创建两个数组queryEmbedding和filedMask,用来承载后面返回的查询向量和规格模板向量
- 查出来数据库里所有的维度信息

- 遍历维度信息数组,逐一进行如下处理
- 寻找查询条件数组中,和当前维度ID一致的第一个条件
- 若找不到或者找到了但是条件的值为空
- 把数字0从尾部推入queryEmbedding和filedMask数组
- 否则
- 调用重置同一值私有服务端命令,传入当前维度ID和查询条件的值,拿到同一化后的结果
- 将该条件值的同一化结果从尾部推入queryEmbedding数组
- 将当前维度的权重从尾部推入filedMask数组
- 返回queryEmbedding数组即查询向量和filedMask数组即规格蒙版向量给调用方
(二)开发query私有服务端命令
我们需要根据查询向量、规格蒙版向量和TopK,来为用户查询匹配的产品信息。
内部逻辑为:
- 创建result数组
- 从数据库中找到所有产品的规格参数,还记得吗,我们提前把同一值都填写进去了
- 在产品规格参数中,以产品规格ID为基准,进行数组distinct操作,记为产品规格ID数组
- 计算入参查询向量和规格蒙版向量的哈达玛积,即查询规格向量
- 遍历产品规格ID数组
- 在产品规格参数数组中,查找当前产品的所有参数,显然这也是数组
- 从上一步对象数组中,提取同一值为产品特征向量
- 计算产品特征向量和规格蒙版向量的哈达玛积,即产品规格向量
- 计算查询规格向量和产品规格向量的余弦相似度
- 从数据库中查询当前产品的规格信息对象
- 为规格信息对象增加一个属性,类型为float,名为相似度,值为之前计算好的余弦相似度
- 将规格信息对象从尾部推入result数组
- 以相似度降序规则对result数组排序
- 取排序后的前TopK个为新的数组top
- 返回top为和用户查询匹配的产品信息
(三)开发表单查询服务端命令
这个服务端命令用来根据参数数组生成产品清单。
内部逻辑为
- 调用私有的embedding服务端命令,传入参数数组,拿到查询向量和规格蒙版向量
- 调用私有的query服务端命令,传入查询向量、规格蒙版向量和TopK,拿到匹配的产品
- 返回匹配的产品为产品清单
(四)开发AI查询服务端命令
入参为用户输入,出参为产品清单和查询条件参数。
内部逻辑为
- 查询数据库中所有的维度信息
- 将维度信息数组JSON化,为AI调用提示词变量引入做准备
- 从提示词表中找到场景场景为参数提取的提示词模板
- 替换提示词模板中的text变量为用户输入,spec为维度信息JSON
- 调用AI助手命令,把替换完毕的提示词给到用户输入,并尝试提取AI返回的信息JSON,示例如下
JSON
[
{"id": 1, "value": 200},
{"id": 2, "value": null},
{"id": 3, "value": null},
{"id": 4, "value": 77},
{"id": 6, "value": null}
]- 对返回的JSON进行反序列化,形成数组query
- 调用表单查询服务端命令,入参即查询条件JSON,拿到返回的产品清单
- 创建查询条件数组
- 遍历query
- 如果当前query对象中的value属性不为空
- 在维度信息数组中查找第一个和当前query对象的ID属性一致的维度信息
- 创建对象q,属性有三个:维度、单位和值。其中维度和单位及上一步找到的维度信息中对应的值,值即当前query对象的value
- 从尾部把q对象推入查询条件数组
- 返回产品清单和查询条件数组
第6步:前后端联调
在页面侧,我们需要AI调用服务端命令来完成前后端联调。具体过程如下:
- 开启加载动画
- 调用AI查询服务端命令,传入页面上用户的输入,获取返回码、返回信息、产品清单和查询条件参数
- 结束加载动画
- 判断返回码是否为0,不为0直接提示出错
- 序列化查询条件参数和产品清单为JSON
- 将两个JSON分别导入到页面的EL表格内
效果展示