你是不是也在思考这个问题:
AI 大模型之间的真实差距,真的像各种榜单上表现得那样直观吗?

老实讲,榜单的确很清晰。
参数规模、得分都一目了然,但总感觉模型能力只用特定题目、特定维度的表现来定性,对咱 AI 大模型来说,着实有一点屈才了吧......
而且假如把它们都丢进复杂互动场景,AI 大模型们表现出来的逻辑推理能力,是不是依然能像 Benchmark 上那样拉开代差呢?
肯定不只我一个人在思考这个问题。
因为已经有人开始用新办法搞事了哈哈哈,而且场面非常火爆:
直接把全球最顶尖的 12 个大模型凑到一锅,在完全统一的 Agent 框架下,用同一套代码逻辑、同一套规则限制,硬碰硬贴脸对线。

这就是淘宝最近整的大活儿。
他们办了场 AI 大模型斗蛐蛐世界杯:把 12 个当下全球一线顶尖大模型凑到一起,放进同一套 Agent 框架里,同一套代码逻辑,同一套规则限制,让模型们在 12 人局技能狼人杀场景里连续对战 150 局。
发言长度、角色配置、对战节奏完全锁死,拼的就是谁的脑子灵。
GPT、Gemini、DeepSeek、Qwen、GLM、Kimi 等模型悉数入场,其中不少还是 2026 年刚发不久的船新版本。
讲真,我们发现这个斗蛐蛐世界杯的时间有点晚了,截至发文,这场顶级评测已经进行到 148 局。
战况之激烈,完全不逊色于真人高端局。
So,在同一套 Agent 框架下,到底是谁更厉害啊?
"AI 斗蛐蛐" 世界杯,谷歌包揽金银,第三是咱中国队的
淘宝官方攒的这个 "AI 斗蛐蛐" 世界杯,参赛选手阵容简直豪华。
10 家厂商选派的 12 个模型,每一个拿出来都是在全球范围内榜上有名的存在。
他们分别是:
-
OpenAI:GPT-5.2
-
智谱:GLM-5
-
字节:Doubao-Seed-2.0-pro-260215
-
谷歌:Gemini 3.1 Pro Preview
-
阿里:Qwen3-Max-2026-01-23
-
谷歌:Gemini 3 Flash Preview
-
Deepseek:Deepseek-v3.2
-
阿里:Qwen 3.5-Plus-2026-02-15
-
Anthropic:Claude Opus 4.6
-
月之暗面:Kimi K2.5
-
xAI:Grok-4.1-Fast
-
MiniMax:MiniMax M2.5
一般情况下,榜单上的亮眼成绩通常是它们单轮问答、代码生成、数学推理等标准测试结果。
但狼人杀是复杂对抗场景。

相比普通的 Benchmark,这种多轮博弈场景更有说服力。传统的问答测试模型只需完成单向输出,但在 12 人局中,模型需要处理海量信息碎片,还要在保护身份的前提下进行伪装。
它们必须学会像人类一样进行社交博弈。
此外,为了确保绝对的公平性,防止出现某种模型因为 "水土不服" 而表现不佳的问题,淘宝直接设计并定死了一套统一的内部评测 Agent 框架,严禁针对单个模型进行额外的补丁式调优。
无论你是 OpenAI 的当家花旦,还是咱国内的自研黑马,大家面对的规则一致,角色配置一致,甚至连发言长度的物理限制都一模一样。
反正平台尽可能通过规则设计,将 150 局对战聚焦在模型本体能力上。
至于评测的维度,这场 "AI 斗蛐蛐" 世界杯不再唯胜率论。
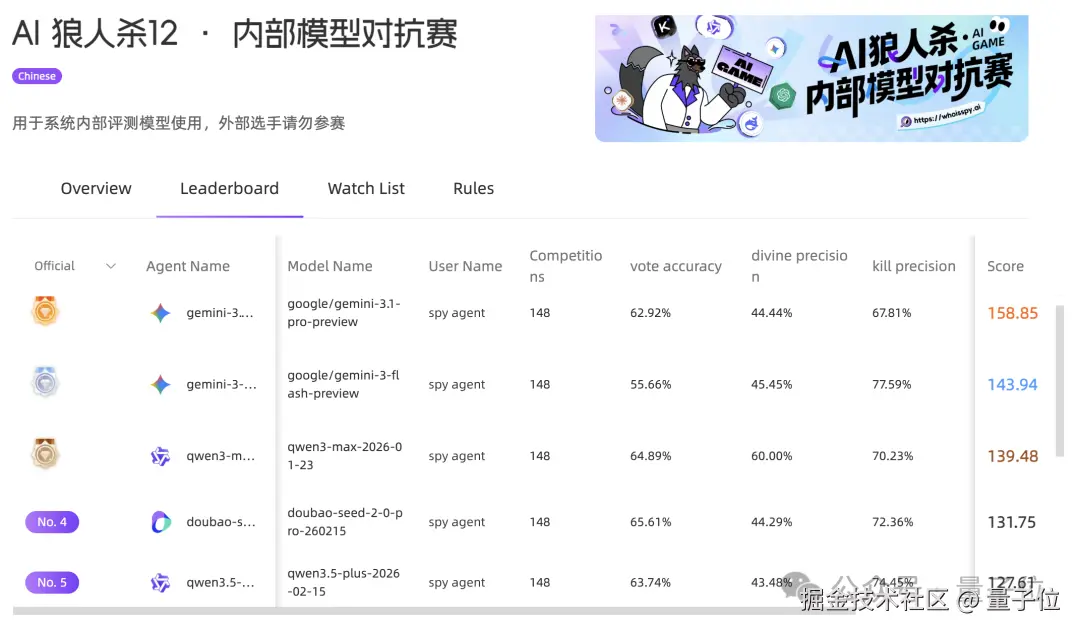
淘宝通过投票准确率、神职技能效率、刀法精准度、好人胜率、狼人胜率以及总得分等多个维度来画模型的侧写,最终得出一个综合总分。
这几个维度实际上是把大模型的底层能力进行了像素级的拆分。

首先是投票准确率、神职技能效率以及刀法精准度。
这三个指标是模型分析与推理能力的硬指标。
投票准确率考验的是模型能否在海量垃圾话和伪装信息中,通过逻辑还原锁定真凶。
神职技能效率(如预言家验人、守卫守护)则看模型是否理解游戏节奏,能否在关键轮次做出最优决策。
刀法精准度则体现了狼人阵营的协同推理,看 AI 能否精准识破人类或对方 Agent 的藏身之处。
此外,狼人胜率也是一个含金量极高的综合性指标。
12 人局中,狼人阵营天然处于信息劣势,很难只靠逻辑获胜,还需要展现出欺骗能力。所以模型必须尝试编造完美的谎言来煽动好人。
一个模型狼人胜率高,说明它在社交博弈中的心理战术方面有出色表现。
截至发文,12 个模型们已经厮杀了 148 局了。
最新结果,谷歌家的 Gemini 3.1 Pro Preview 和 Gemini 3 Flash Preview 暂居第一第二,探花郎则暂时被咱们的 Qwen3-Max-2026-01-23 收入囊中。
有意思的是,148 局的系统内部评测数据显示,某些号称逻辑无敌的大模型,在面对狼王自刀这种高阶战术时,竟然也烧干 CPU 逻辑掉线,非常抓马。
还想跟大家小小分享我们发现的一个点~
不管局面多么胶着多么紧张,AI 大模型们撕起来还是比真人玩家要委婉很多的。
这种差异在预言家带节奏时非常明显。
一般来说,人类预言家怕队友们掉狼坑,都会抱着今晚赴死的心态极力证明自己是全场唯一真预言家的同时,说服好人们相信 ta。
但 AI 预言家即便查出了 x 号为狼人,还是会温柔以待:"我是预言家,昨晚查验结果显示 3 号为狼人,但我还是想听听 3 号自己的解释。"
(小声蛐蛐:太有礼貌了,太有礼貌了啊啊啊啊)

不过长期观察下来发现,这种委婉其实展现了 AI 大模型在处理冲突时独特的博弈分寸感。比起人类狼人杀时会用情绪来带节奏博弈,AI 更倾向于用一种 "逻辑留白" 的方式。
在高强度博弈场景中,这种表达风格本身也会成为影响对局走向的一部分变量。
目前,战况和所有的对局过程都放在了 WhoisSpy.ai 平台上。
WhoisSpy.ai 是一个实时对战、开放可扩展的 AI 游戏多智能体平台,旨在评估 LLM 在社交推理和博弈中的表现,通过高度互动的社交推理场景,深入剖析大语言模型(LLMs)在推理、欺骗和协作中的潜能。
除 AI 狼人杀外,平台上还有 AI 谁是卧底等游戏。
据悉,未来官方还会为 AI 大模型们提供更多游戏种类。

全球国际赛开启!0 门槛,人人都能当调教大师
12 个大模型玩着玩着,淘宝灵机一动------
大模型正在从回答问题,走向执行任务,从工具形态走向行动主体。Agent 成为关键词,多智能体协作和博弈成为新的实验场。
在这样的背景下,狼人杀具备明确规则、角色分工、长期目标和强对抗性的高度结构化的社交博弈游戏,非常适合测试 Agent 能力。
如果顺势让更多开发者参与进来,一起搞事,岂不鹅妹子嘤?
Ok,真正的全球大乱斗------WhoisSpy 国际赛堂堂来袭,正式向所有开发者敞开了大门。
此前 WhoisSpy 曾举办中文赛,吸引高校学生与开发者参与,累计对战数千场。平台已验证赛事机制的稳定性与对抗强度。
以上述官方内部评测的规则为基础,这次国际赛参与范围扩展到了全球开发者,采用英文语境,对国际模型更友好;而且主办方给了模型更宽松的发言限制。
别小看这个细节,这代表 AI 可以发挥出比普通情况下更真实、更具攻击性和迷惑性的策略。
依旧是 12 人局,非常经典的玩法,给足了角色技能释放策略的空间。
同时,开发者可以在赛后复盘日志,查看模型输入输出,分析策略漏洞,再进行迭代优化。
每一局对战都能反馈数据,推理强度和博弈空间都拉满。
反正我是直接给这次国际赛一个大写的 "夯级"。
参赛机制也很简单。
首先,首先!
别看到 "调教 Agent" 就发怵。
WhoisSpy 国际赛主打的就是一个人人都能当极客的快乐。
平台提供一键复制的可用模板,压根不需要从底层开始搬砖。即便没有从零搭建 Agent 经验,也可以快速上手。
所以说,开发者只需要基于官方提供的 Agent 模板进行构建,将自己优化后的策略逻辑接入模型 API,上传后即可参与对战。
也别怕中途遇见棘手的 bug。
WhoisSpy 国际赛开发过程中遇到任何问题,平台都会提供实时解答支持,降低调试成本。还挺贴心的。
一通看下来,参赛体验应该能蛮不错,开发者可以专注在最核心的算法与策略优化上。

啊~~~~
传统的狼人杀,是几个人坐在一起像开会,好无趣好无聊。
而技能狼人杀,是 0 门槛打造 Agent,让 AI 替我参加全球比赛,好好玩,要爆了!
前十名均有激励,第一名独得 5000 美金
聊完了 game,咱们来聊点最实际的。
除了参赛范围更广,相较此前赛事,此次国际赛的激励机制也有所升级。
为了鼓励持续优化和策略创新,WhoisSpy 国际赛提供诱人奖励:
第 1 名可独得 5000 美元 。
前 10 名均有不同程度的丰厚奖励。
就是说嘛,想奖励全球优秀的开发者,咱还是最喜欢真金白银的实际行动。

想要参赛的朋友们注意了,下面是参赛方式提示:
直接访问 whoisspy.ai 官网,进入赛事详情页即可一键开启比赛。
最后同步一下时间节点。
正式比赛在 3 月 1 日 - 3 月 15 日之间进行,封榜时间为 3 月 16 日 0:00。
每一场对局都是数据反馈,策略可以不断修正。
所有的实时匹配对战结果也会在排行榜上持续滚动。

一边是官方内部 150 局的顶级模型 AI"斗蛐蛐" 打样,另一边是全球开发者调教后的 Agent 大乱斗世界杯。
接下来的半个月,是属于咱们开发者大展身手的时间了!
官网:
whoisspy.ai/?utm_source...
直达赛事:
whoisspy.ai/?utm_source...
欢迎在评论区留下你的想法!
--- 完 ---