作为一个后端开发人员,在我们的日常工作中经常会给外部提供各种不同的服务端接口,形式各异有http、dubbo、grpc等等。
如果接口使用方客户,某天给你反馈说,你们接口的耗时较高,经常超时。你作为接口提供方,看到自己接口的耗时非常低,系统性能也没有啥压力。这两边的误差如何来解决呢?
现象
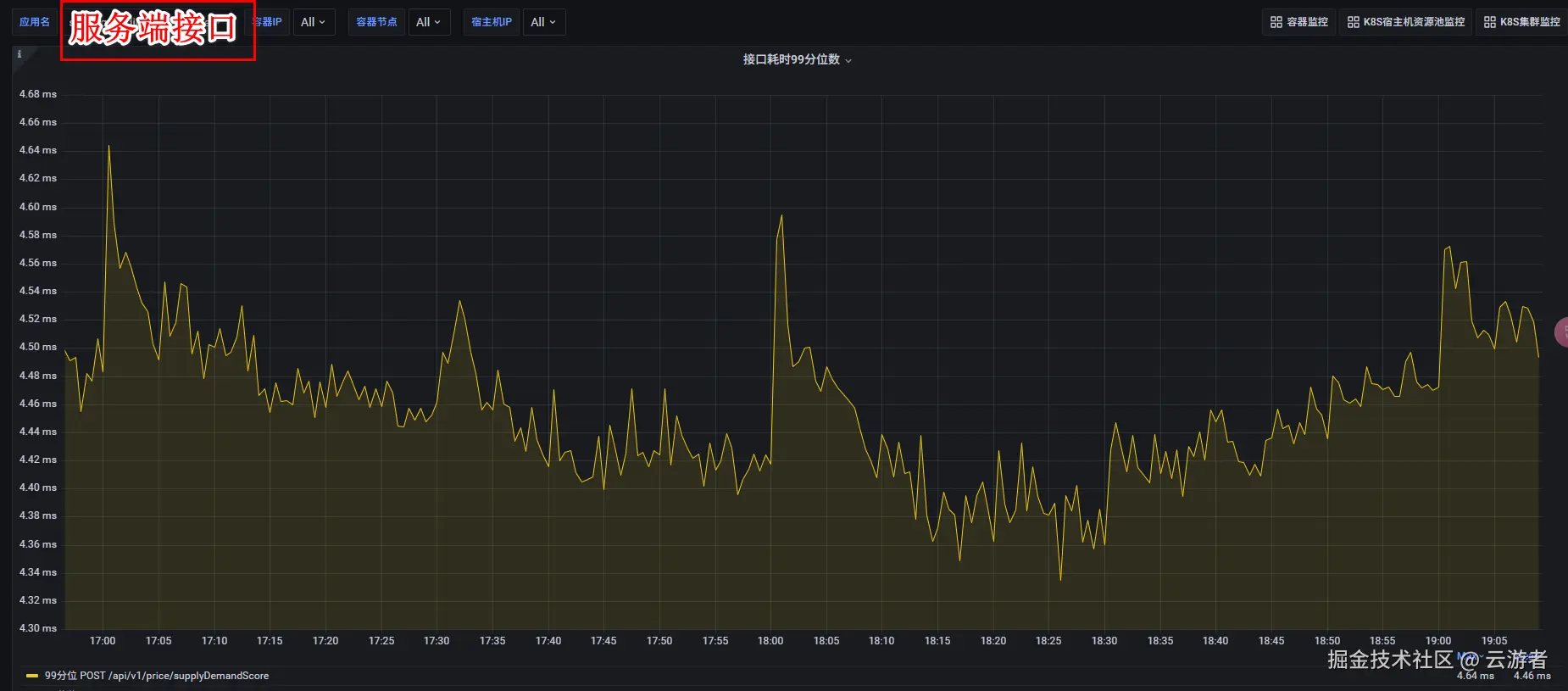
接口提供方的99分位耗时如下:
接口使用方的99分位耗时如下:
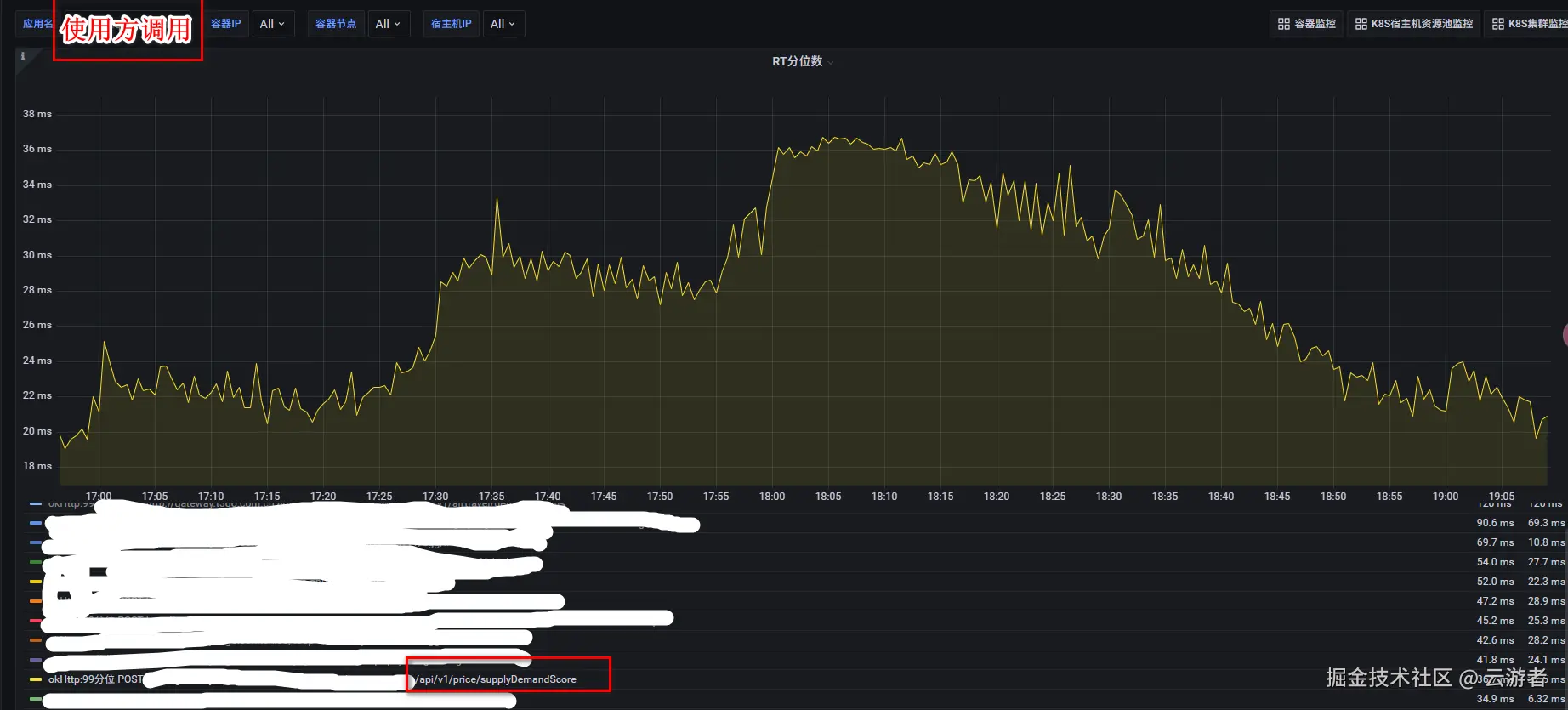
接口在服务端99分位的耗时只有5ms,在客户端99分位的耗时却高达35ms,这中间的gap在哪里,我们一步步来一探究竟。
服务端
接口提供方的定义如下:
js
@RestController
@RequestMapping(value = {"/api/v1/price"})
@Slf4j
public class PriceController {
@Autowired
private BizService bizService;
/**
* 查询接口
*
* @param request request
* @return Response<>
*/
@PostMapping(value = "/supplyDemandScore")
public Response<?> supplyDemandScore(@RequestBody ScoreRequest request) {
try {
return bizService.supplyDemandScoreCal(request);
} catch (Exception e) {
log.error(e);
return Response.createError("查询特征异常");
}
}
}服务端基于Springboot框架,提供RestController接口,使用Grafana来监控接口的99分位耗时。那么服务端的耗时包括哪些部分?
一个请求的完整路径和耗时构成,由以下步骤构成:
- 客户端发起请求 -> 发送网络传输 -> Tomcat接收请求 -> Spring MVC(拦截器、参数解析)-> Controller方法 -> BizService业务处理 -> 序列化响应 -> Tomcat发送响应 -> 响应网络传输 -> 客户端接收响应
Grafana监控服务端的99分位耗时: 从Tomcat接收请求开始,到 Tomcat发送完结束。
因此 Grafana上看到的服务端99分位耗时 = 请求反序列化 + Spring框架处理 + 业务逻辑执行 + 响应序列化。
客户端
接口调用方的逻辑如下:
js
/**
* 调用方封装请求
* @param url /网关地址/api/v1/price
* @param requestBody 请求参数
* @return ResponseData 返回结果
*/
public <ResponseData> ResponseData postJsonObjectAndGetResponse(String url, Object requestBody, TypeReference<TResponseData> responseDataClass) {
String requestBodyStr = JacksonUtils.toJsonString(requestBody);
MediaType mediaType = MediaType.parse("application/json;charset=UTF-8");
Request.Builder builder = (new Request.Builder()).url(url).addHeader("content-type", "application/json;charset=UTF-8");
RequestBody body = isBlank(requestBodyStr) ? RequestBody.create(mediaType, new byte[0]) : RequestBody.create(mediaType, requestBodyStr);
Request request = builder.post(body).build();
OkHttpClient client = (new OkHttpClient.Builder()).connectTimeout(1000, TimeUnit.MILLISECONDS).readTimeout(1000, TimeUnit.MILLISECONDS).writeTimeout(1000,TimeUnit.MILLISECONDS).connectionPool(new ConnectionPool(1, 1, TimeUnit.MINUTES)).build();
return client.newCall(request).execute();
}客户端的耗时 = 客户端请求序列化 + 请求网络传输 + 服务端处理耗时 + 服务端响应网络传输 + 服务端响应反序列化
客户端耗时比服务端增加的流程,来源于如上标记加粗的部分。
如何解决
- 服务端的99分位耗时约:5ms
- 客户端的99分位耗时约:30ms
- (客户端 - 服务端 )的99分位耗时约: 25ms
新增耗时的环节 = 客户端请求序列化 + 请求网络传输 + 服务端响应网络传输 + 服务端响应反序列化
- 客户端的序列化和反序列化,这个需要调用方优化暂时不考虑。
- 请求网络传输耗时,这个属于网络带宽问题暂时也不好优化。
这个问题没有办法解决了吗?
不是,新增耗时环节缺少了一个统计点: 服务端排队等待处理的时间。如果客户端机器数是服务端机器数的2倍,服务端接口的耗时虽然只有5ms,但是客户端请求的QPS过多达到几万或者几十万,而Tomcat本身的线程数只有200,没有抢占到Tomcat线程的请求就会排队等待。
这个时候水平扩展服务端机器的数量,就可以解决这个问题。把服务端机器数量增加到原来的2倍后,客户端的99分位耗时在高峰期下降到9ms左右。