版本控制
InnoDB 作为 MySQL 的默认存储引擎,最核心的特性之一就是多版本控制(MVCC)。它通过保留数据行的历史版本信息,高效支持事务的并发控制、回滚等核心功能。这些历史版本信息存储在系统表空间或独立撤消表空间的回滚段中,既用于事务回滚时的撤消操作,也用于构建数据的早期版本以实现一致性读取。
"多版本" 本质上是一种并发控制解决方案:
- 为同一份数据维护多个版本,每个版本对应特定的事务操作
- 允许读写操作并行执行,无需通过传统的读写锁阻塞彼此
- 从根本上解决了 "读阻塞写、写阻塞读" 的性能难题
为实现多版本控制,InnoDB 会在每一行记录中自动添加三个隐藏系统字段: DB_TRX_ID(6 字节) 标记最后一次更新该行记录的事务 ID。数据库每处理一个新事务,该值会自动递增。特别地,删除操作在内部会被视为一种特殊更新,仅通过设置行记录中的删除标记位实现。
DB_ROLL_PTR(回滚指针) 指向当前记录最新一次修改对应的 undo log(回滚日志)地址。事务回滚时,通过这个指针就能找到历史数据版本。
DB_ROW_ID(6 字节) 当表未指定主键时,InnoDB 会自动以该字段作为主键,生成聚集索引。若表已定义主键,则该字段可能不会出现。
如何实现多版本存储引擎?
1、undo log链
每个事务都有自己的一个id,就像其身份证一样唯一标记该事务。当事务启动的时候,向Innodb存储引擎进行申请。假设此时如果打南边来了个事务A,它的事务id为12,事务A对表中的数据字段count进行修改,修改后该条数据对应的事务id为12,同时回滚指针指向实际的undo log回滚日志的地址。
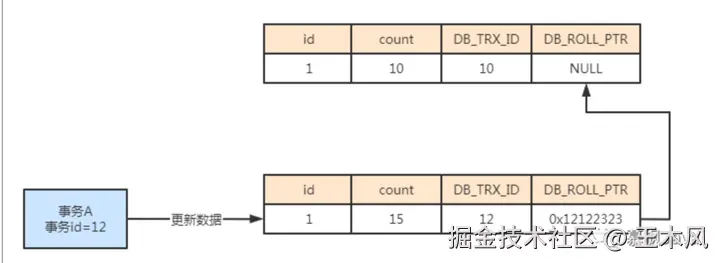
添加图片注释,不超过 140 字(可选)
此时打北边又来了个事务B,它的事务id为20,事务B将表中的数据字段count修改为21,对应数据的事务id变为20,回滚指针指向上一条undo log信息。如下图所示:
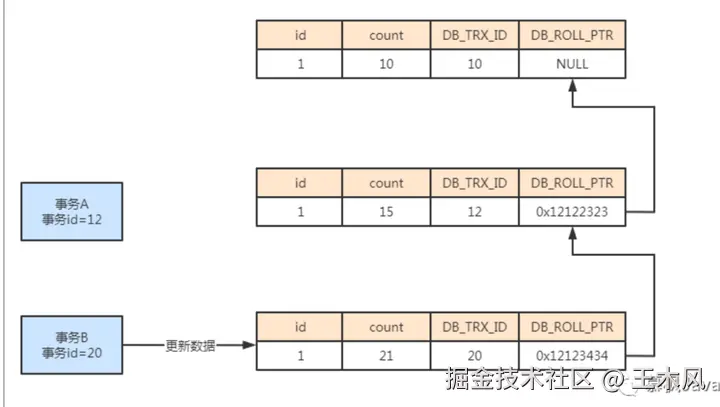
添加图片注释,不超过 140 字(可选)
2、ReadView实现事务隔离
Mysql执行事务的时候,会生成一个ReadView,其中会包含以下重要信息:
(1)m_ids:mysql中未提交的事务id集合;
(2)min_trx_id:集合中最小的事务id;
(3)max_trx_id,mysql下一个要生成的事务id,也就是事务id集合中最大的事务id加1;
(4)当前需要执行的事务id; 假设现在有事务A以及事务B两个事务,A事务需要读取数据,B事务需要修改数据。
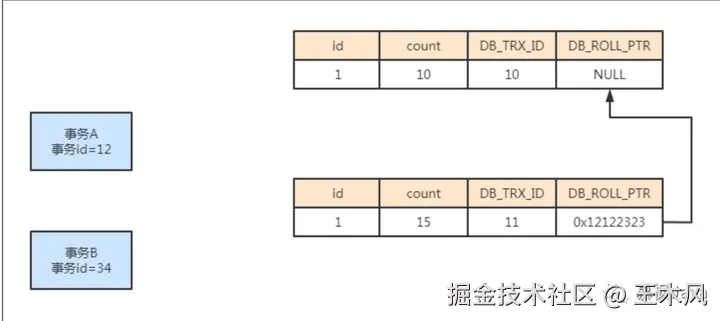
添加图片注释,不超过 140 字(可选)
当事务A需要读取数据时,开启ReadView。由于此时数据库活跃的事务为事务A以及事务B,那么对应的ReadView中m_ids={12,34},min_trx_id=12,max_trx_id=35,当前需要执行的事务id为12。此时事务A读取数据时,先判断当前的事务id为12,而数据中的事务id为11,小于当前事务A的id。说明当前读取的数据是在事务A开启之前提交的,因此可以正常进行数据读取。
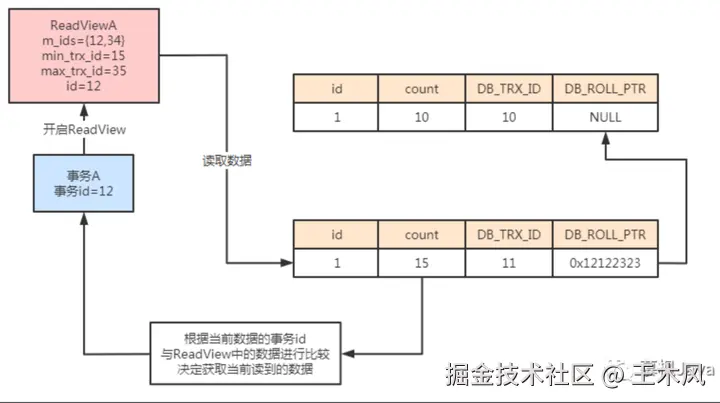
添加图片注释,不超过 140 字(可选)
如果此时事务B进行了数据修改,修改count为29。而事务A再次进行数据读取时,继续进行判断,发现当前数据对应的事务id为34比当前的查询事务要大,同时在m_ids中。说明该事务id对应的事务和事务A属于并发执行事务,因此不能进行数据读取。则根据undo log版本链,往上寻找undo log信息。如果找到的事务id小于当前读取数据的id则证明此时的数据是在当前开启查询事务之前提交的,因此可以进行数据的查询。
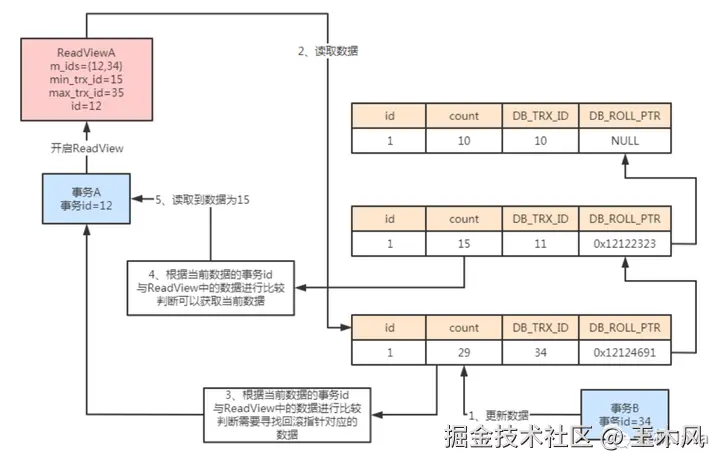
添加图片注释,不超过 140 字(可选)
那么另外一个问题又来了,RC级别又是如何实现的呢?所谓RC级别,就是当别人的事务提交后,你就可以读取到别人修改后的值。因此会发生不可重复读问题。当设置为事务级别为RC时,每次进行数据查询都会新开启一个新的ReadView。
添加图片注释,不超过 140 字(可选)
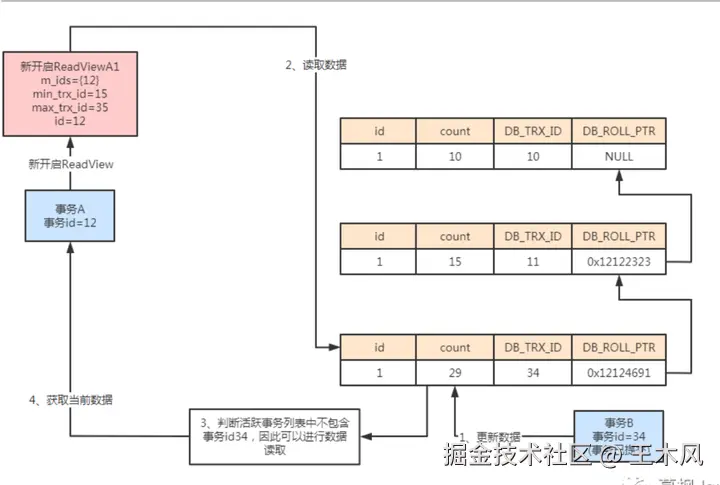
假设当前事务中活跃着两个事务,他们的事务id分别是12、34。此时事务id为34的事务更新了数据。此时数据更新为29。同时数据对应的事务id更新为34,同时回滚指针指向上一条数据。若此时事务id为12的事务进行数据查询,此时开启readview,进行检查,发现此时的数据中对应的事务id在活跃事务id中,说明是和查询事务差不多时机执行的,但是此时的事务还未提交。因此此时的数据不可以读,所以顺着undolog版本链条读取上一次的数据。同时进行判断。 如果事务B进行了提交,那么事务A再次进行数据查询的时候,会新开启一个ReadView,我们暂且称之为ReadViewA1,由于此时的事务B已经提交,所以ReadViewA1中对应的活跃列表中只有事务A对应的事务id为12。此时发现事务已提交,不再活跃事务列表中,因此可以进行数据读取。 InnoDB 回滚段中的撤消日志分为两类,其用途与丢弃规则存在差异:
- 插入撤消日志:仅在事务需要回滚时发挥作用,一旦事务提交,这类日志即可立即丢弃,不会长期占用资源。
- 更新撤消日志:除了支持事务回滚,还需用于实现 "一致读取" 功能。因此,它不能在事务提交后直接丢弃,只有当不存在任何已为其分配快照的事务时,才能被清理。
基于上述规则,建议定期提交所有事务------ 即使是仅执行一致读取(无数据修改)的事务也不例外。若事务长期不提交,InnoDB 无法正常丢弃更新撤消日志中的数据,会导致回滚段持续增大,最终可能填满其所在的表空间,影响数据库正常运行。 此外,当表中 "小批量插入行" 与 "小批量删除行" 的速率大致相同时,容易出现另一个问题:InnoDB 的清除线程(负责清理无效数据)可能会处理滞后,导致大量 "死行"(已被标记为删除,但尚未被清除的行)积累。这些死行会使表体积不断膨胀,最终让磁盘成为系统瓶颈,造成整体运行速度大幅变慢。 针对这种死行积累的情况,可通过以下方式优化:
- 调整系统变量 innodb_max_purge_lag:该变量可控制新行操作(插入、删除等)的速度,降低其值能让数据库优先加快旧死行的清除效率;
- 优化清除线程配置:增加清除线程的数量,或提高其运行优先级,确保死行能被更及时地清理,避免持续占用磁盘资源。
多版本和二级索引
1. 聚集索引的处理方式
聚集索引的记录会就地更新(直接在原位置修改数据),且每条记录都包含隐藏系统列(即此前提到的 DB_TRX_ID、DB_ROLL_PTR 等字段)。其中,DB_ROLL_PTR 会指向回滚段中的撤消日志条目,通过这些条目就能重建记录的早期版本,从而满足 MVCC 的一致性读取需求。
2. 二级索引的处理方式
与聚集索引不同,二级索引记录有两个关键特点: 不包含隐藏系统列,无法直接通过自身关联撤消日志; 不会就地更新:当二级索引列被更新时,旧的二级索引记录会被标记为 "删除",同时插入一条新的二级索引记录,被标记删除的旧记录会在后续由清除线程清理。
4. 对覆盖索引的影响
若二级索引记录被标记为删除,或其所在页被较新事务更新,覆盖索引技术将无法使用。此时,InnoDB 不会直接从二级索引结构中返回数据,而是必须先通过二级索引定位到聚集索引,再从聚集索引中读取完整记录(即 "回表" 操作)。