表的增删查改
CRUD : Create(创建), Retrieve(读取),Update(更新),Delete(删除)
1.create创建
- 语法:

方括号中内容是可以省略的
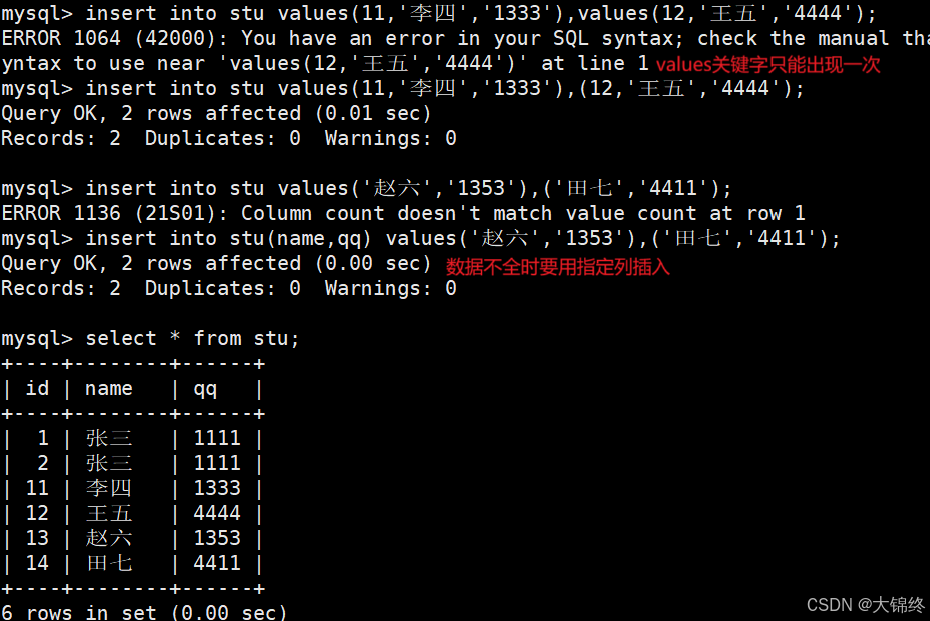
单行数据+全列插入+指定列插入
一次仅插入一条数据,数据的数量、顺序必须和定义表中的一致,如果每个数据都要插入那么就不用指定要插入数据的列,就叫全列插入,如果插入数据不全就要指定插入列

注意:insert into的into可以省略,但一般加上更直观
多行数据+全列插入+指定列插入
语法和单行数据一样,多行数据插入就是在单行后面用英文逗号隔开,注意values关键字只能出现一次,其余相同
插入否则更新
- 由于 主键 或者 唯一键 对应的值已经存在而导致插入失败:
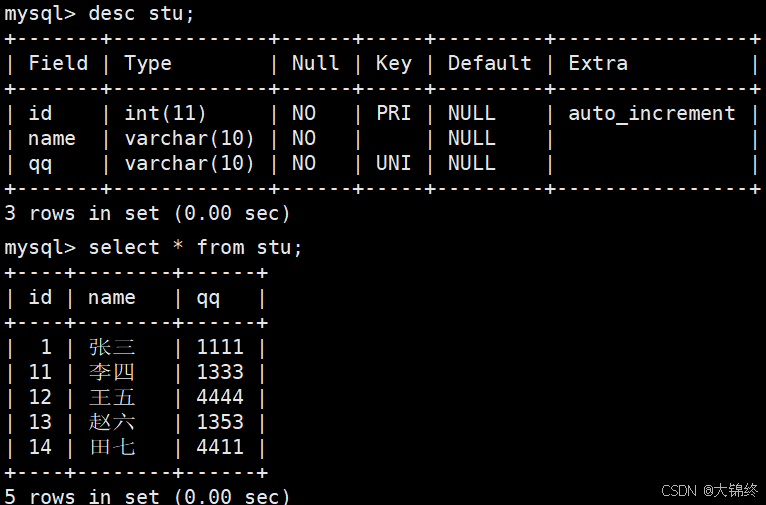
主键冲突:

唯一键冲突:

- 如果不想冲突时只是单纯的报错提示,而是想将当前数据覆盖更新原数据,那么可以选择进行同步更新语法
INSERT ... ON DUPLICATE KEY UPDATE
column = value , column = value ...
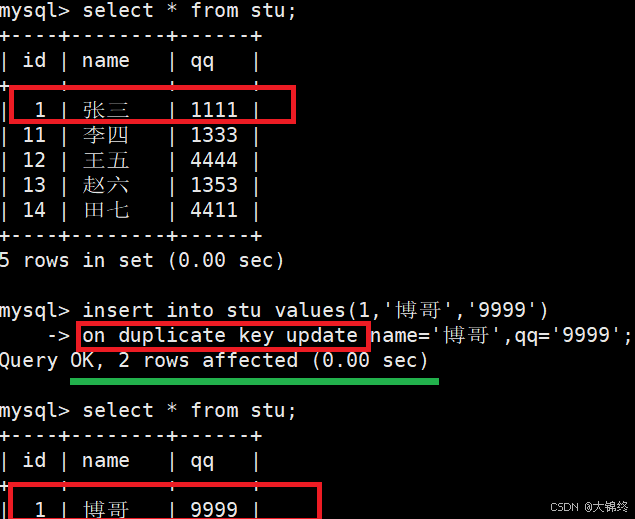
绿色线标记初的2 rows affected是什么意思?表中受到影响的数据行数,受影响不仅是数据冲突

0 行受影响:表数据没任何变化(可能是冲突,也可能是没匹配到数据、更新后值没变化);
1 行受影响:表中新增 / 删除 / 修改了 1 条数据(可能是无冲突插入,也可能是无冲突更新 / 删除);
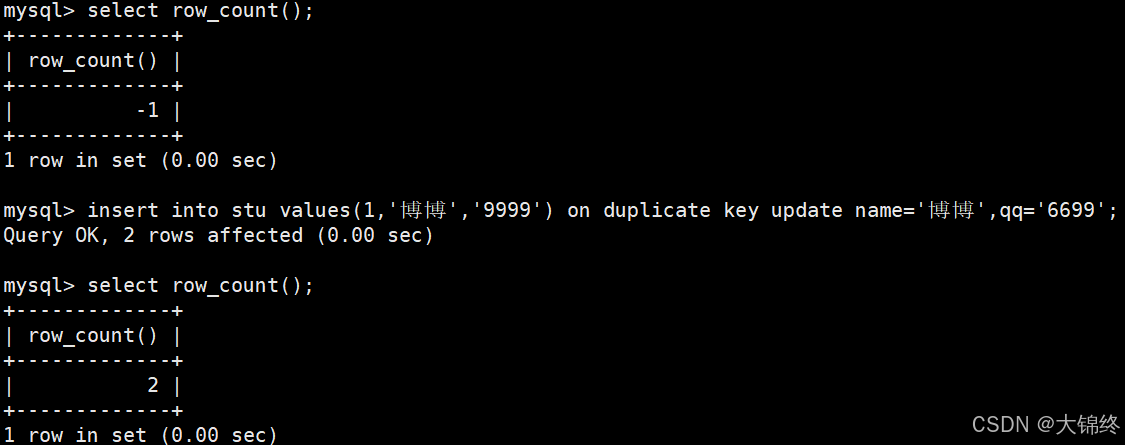
2 行受影响:表中新增 / 删除 / 修改了 2 条数据(可能是无冲突批量操作,也可能是冲突后通过特殊规则允许执行,比如 ON DUPLICATE KEY UPDATE)。 - 通过ROW_COUNT() 函数获取受到影响的数据行数
若不受影响返回-1,否则代表实际受到影响的行数
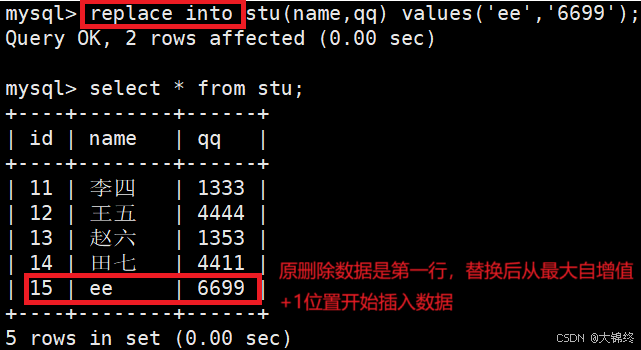
替换
- replace into语句
主键 或者 唯一键 没有冲突,则直接插入;
主键 或者 唯一键 如果冲突,则删除后再插入,注意新插入位置从当前最大子增值+1的位置处开始,相当于从表尾位置新插入数据,而不是原位置插入
2.retrieve读取
语法:

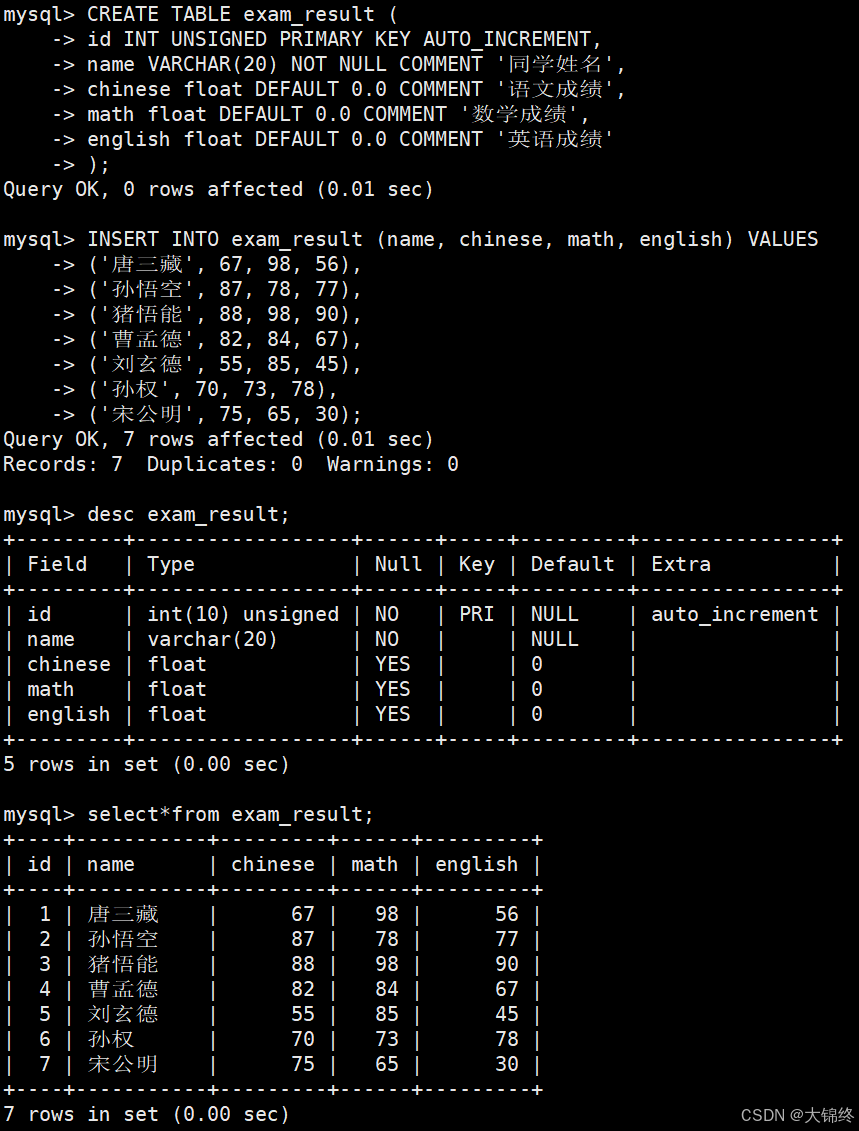
- 创建测试表结构,并插入测试数据
全列查询
- selec * from 表名;
通常情况下不建议使用进行全列查询,实际业务中数据量特别大,一定要加上筛选条件才能保证效率
1.查询的列越多,意味着需要传输的数据量越大;
2.可能会影响到索引的使用。
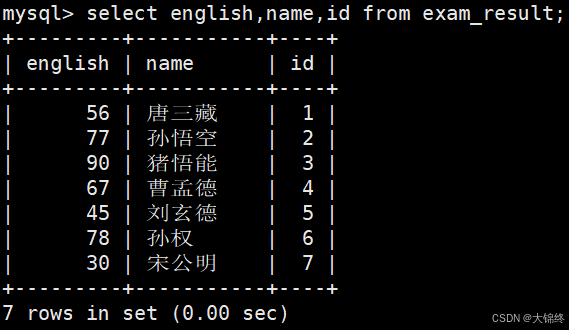
指定列查询
指定列的顺序不需要按定义表的顺序来
2.1查询字段可以为表达式
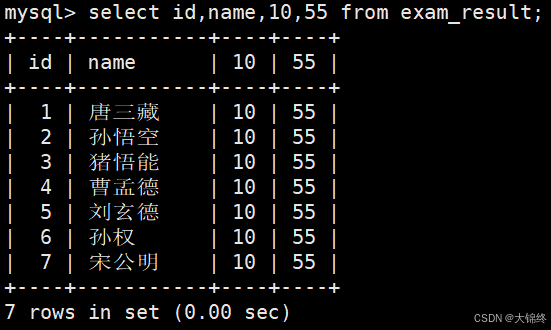
- select语句中允许直接输出常量值,这些常量值会作为 "虚拟列" 在结果集中重复显示,每行的取值都固定为你指定的常量。这种用法常用于生成辅助信息、测试场景(比如临时添加标记列)
- 表达式包含一个字段
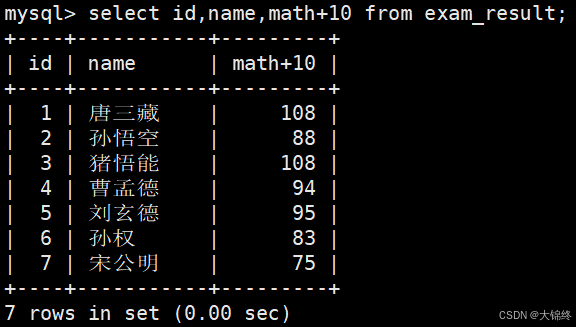
- 表达式包含多个字段:
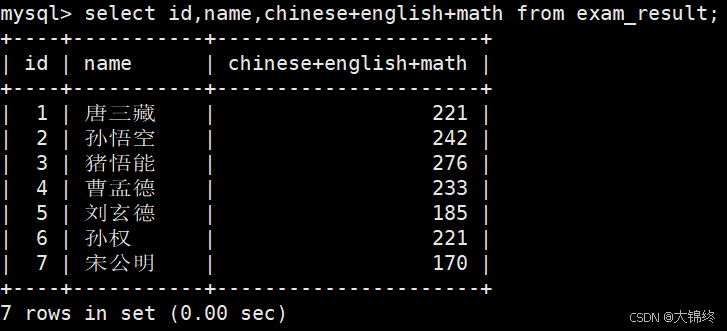
- 为查询结果指定别名:
语法:
SELECT column AS alias_name ... FROM table_name;
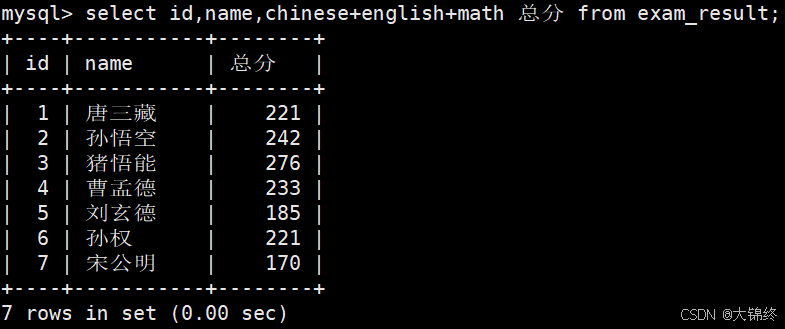
as可省略 - 对结果去重:
select后加上distinct选项:
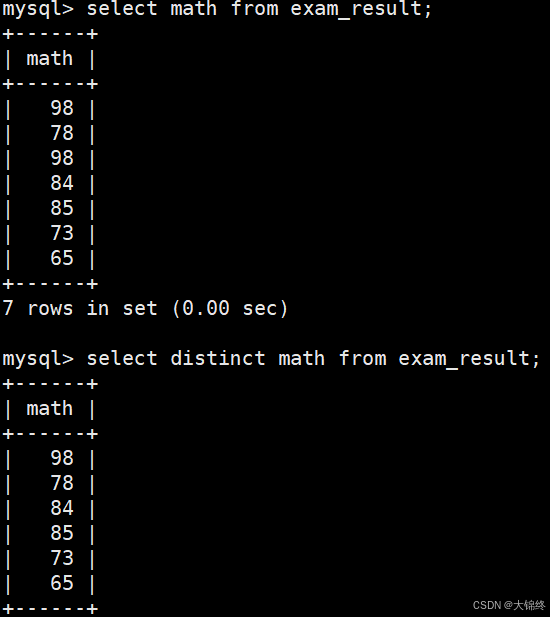
2.2where条件
运算符
- 比较运算符:
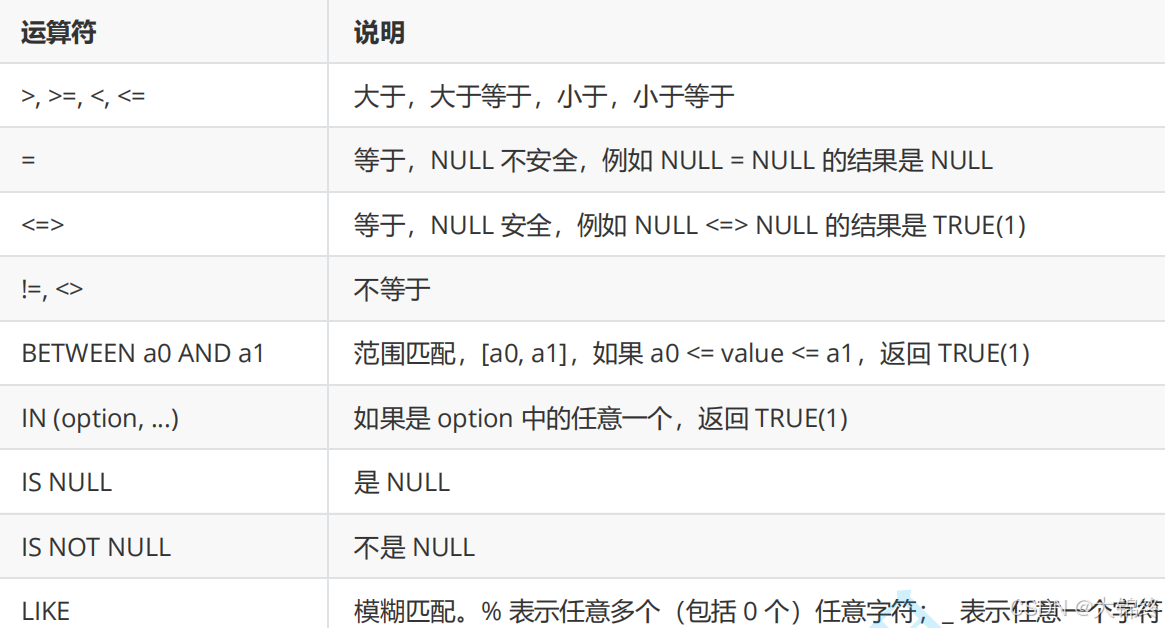
NULL 是 "未知",未知与任何事物(包括未知)都无法 "比较",只能 "判断是否为未知"(用 IS NULL)。<=> 解决 "两个值是否逻辑一致(含都未知)"。可以兼容null;IS NULL 解决 "某个值是否是未知"。
mysql中没有==判断是否相等,直接用=
- 逻辑运算符:
AND 多个条件必须都为 TRUE(1),结果才是 TRUE(1)
OR 任意一个条件为 TRUE(1), 结果为 TRUE(1)
NOT 条件为 TRUE(1),结果为 FALSE(0)
- 运算符使用测试:
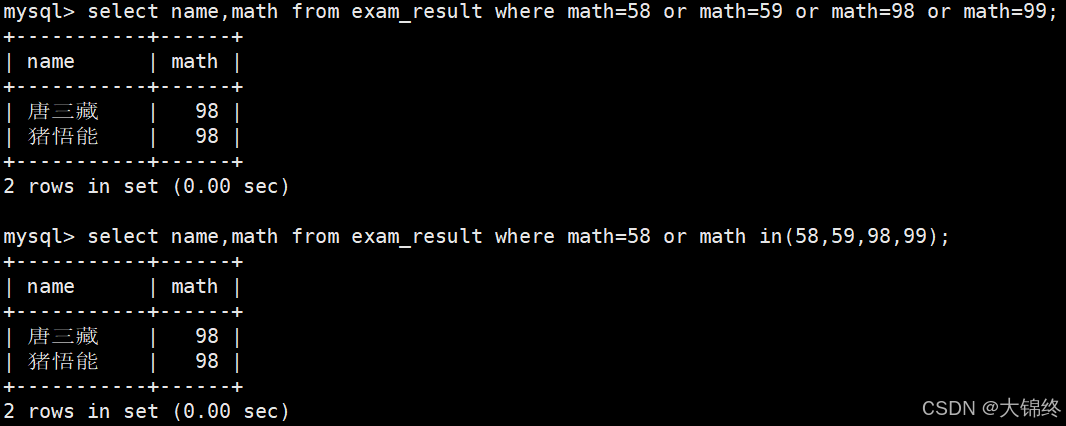
- 英语不及格的同学及英语成绩 ( < 60 )
思路:需要同学名字和科目成绩,所以选这两列,再按条件从这两列中筛选,下述测试都是按这种思路来
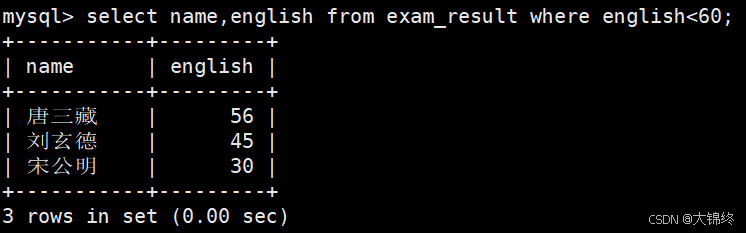
- 语文成绩在 80, 90 分的同学及语文成绩
使用and条件连接和between and
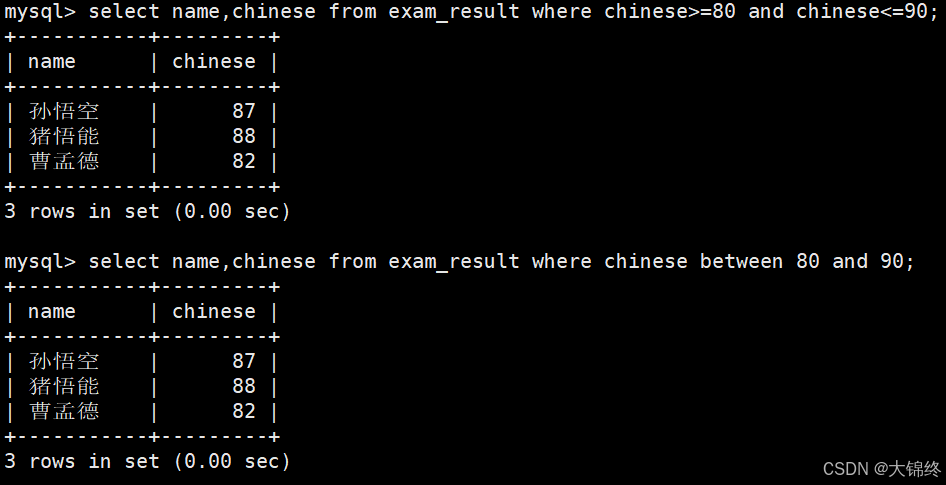
- 数学成绩是 58 或者 59 或者 98 或者 99 分的同学及数学成绩
使用or条件或in条件选择
- 姓孙的同学 及 孙某同学:
姓孙指名字可以有多个字,孙某规定只能两个字,需要模糊匹配like,分别用%和_。
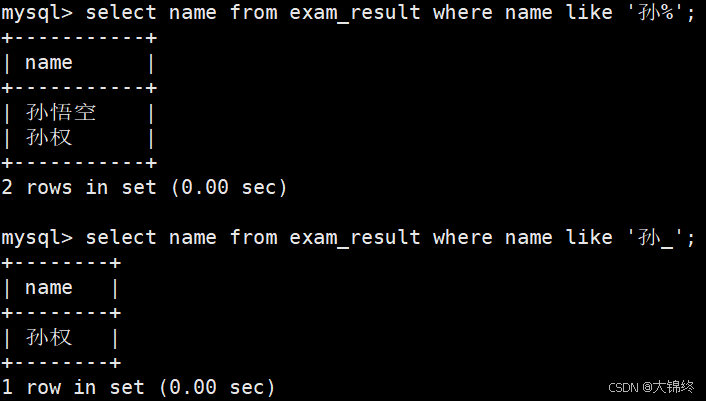
LIKE 的匹配目标是 "字符串模式",所以必须用单引号界定,否则数据库会把匹配内容当成 "字段名" 或 "关键字",导致语法错误。如果用字段来匹配可以不用单引号

where的别名问题
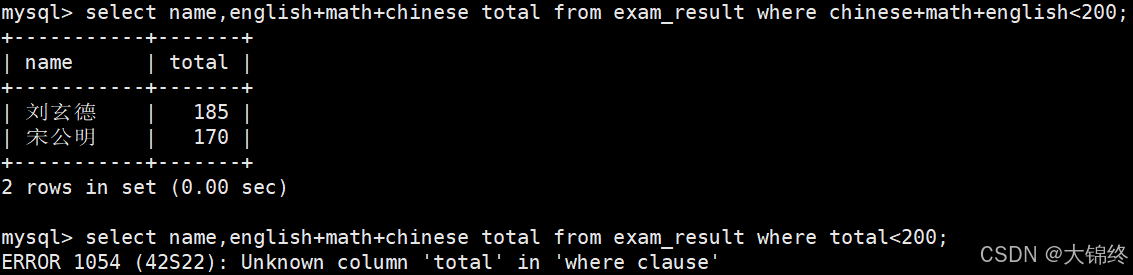
- 总分在 200 分以下的同学:
where条件中使用表达式,别名不能在where条件中?
要了解select的执行顺序:
FROM:先确定数据来源(表 / 视图),加载基础数据;
JOIN + ON:多表连接时,执行连接并过滤不符合连接条件的记录;
WHERE:对基础数据做 "行级过滤"(筛选满足条件的行);
GROUP BY:按指定字段分组(若有);
HAVING:过滤分组后的结果(若有,可使用聚合函数);
SELECT:选择要显示的列,此时才会定义别名(如 SELECT score+10 AS add_score);
ORDER BY:对最终结果排序(可使用 SELECT 定义的别名,因执行在 SELECT 之后);
LIMIT:限制返回结果行数(若有)。
所以原因是使用变量名的时机早于定义变量名的时机,那么是否能直接在where条件判断中定义别名,然后直接在select中使用别名?不行:
语法上:SQL 只允许 SELECT 定义列别名,WHERE 不支持别名定义;
逻辑上:WHERE 执行早于 SELECT,其临时计算结果不会保留给 SELECT,即使定义了别名也无法复用。
- 孙某同学,否则要求总成绩 > 200 并且 语文成绩 < 数学成绩 并且 英语成绩 > 80
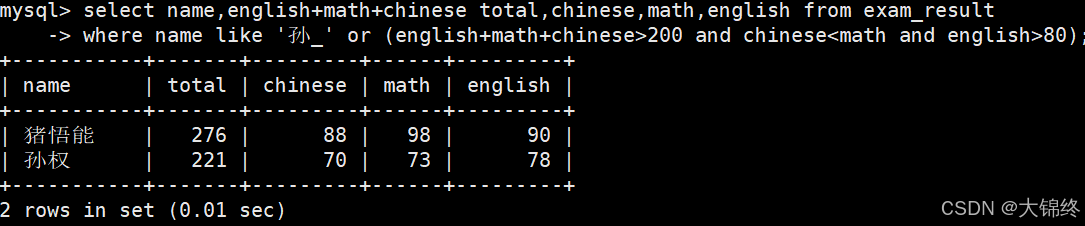
可以用括号将多个条件判断语句括起来
null的查询与比较
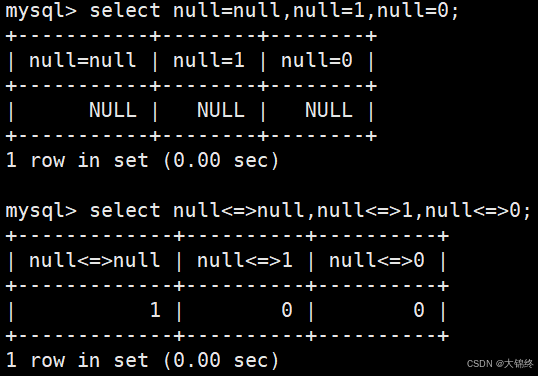
- null的查询:
一般使用where 字段名 is not null(is null) - null与null的比较
结果排序
- 语法:

ascending与descending
注意:
1.没有 ORDER BY 子句的查询,返回的顺序是未定义的,永远不要依赖这个顺序
2.null认为比任何值都小,升序出现在最上面,降序出现在最下面 - 查询单门成绩,按升降序来排列:
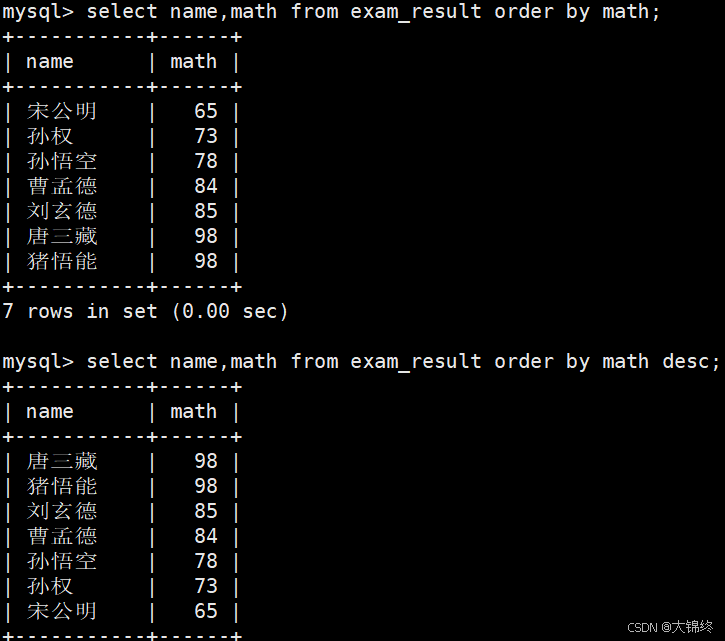
- 查询同学多门成绩,依次按 数学降序,语文升序,英语升序的方式显示
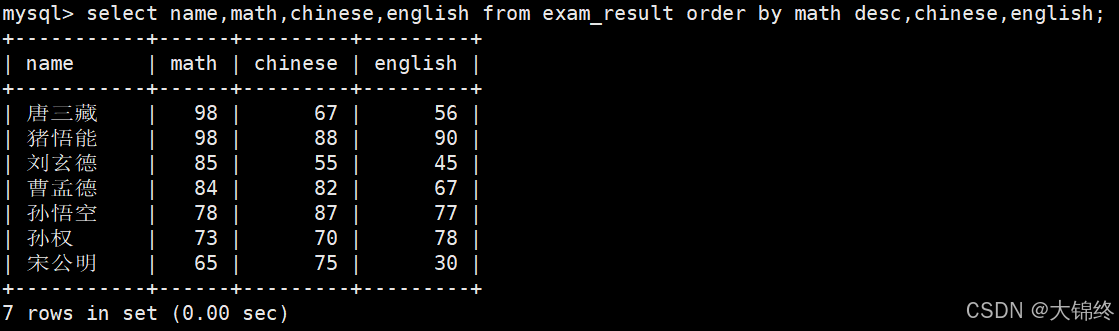
ORDER BY 后多个排序字段的核心规则是 "先按第一字段排序,第一字段值相同的记录,再按第二字段排序;第二字段值仍相同的,再按第三字段排序" ,三者是层层依赖的优先级关系
order by子句可用别名
- 查询总分:
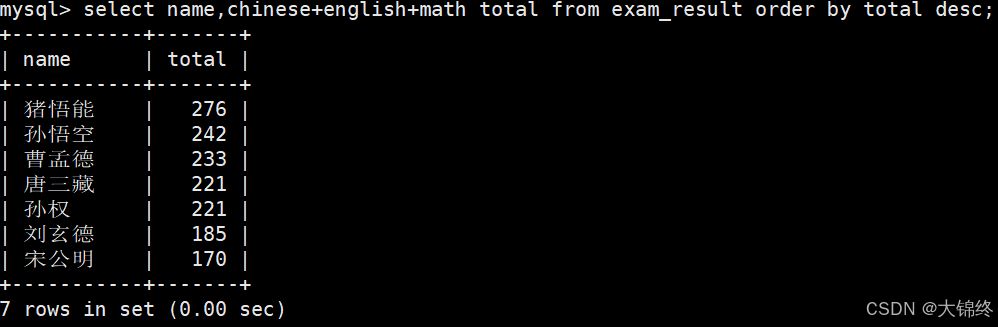
- order by子句中可以使用别名,为什么?
因为进行排序前需要先有数据,order by执行顺序在select之后,而where在执行select之前。
执行在 SELECT 之前的子句(FROM、JOIN、WHERE、GROUP BY、HAVING):看不到别名,不能复用;
执行在 SELECT 之后的子句(ORDER BY、LIMIT):能看到 SELECT 构造的结果集和别名,可以复用。
筛选分页结果
- 语法:
起始下标为 0
1.从 0 开始,筛选 n 条结果
SELECT ... FROM table_name WHERE ... ORDER BY ... LIMIT n;
2.从 s 开始,筛选 n 条结果
SELECT ... FROM table_name WHERE ... ORDER BY ... LIMIT s, n
3.从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用
SELECT ... FROM table_name WHERE ... ORDER BY ... LIMIT n OFFSET s;
建议:
对未知表进行查询时,最好加一条 LIMIT 1,避免因为表中数据过大,查询全表数据导致数据库卡死 - 从 0 开始,筛选 n 条结果
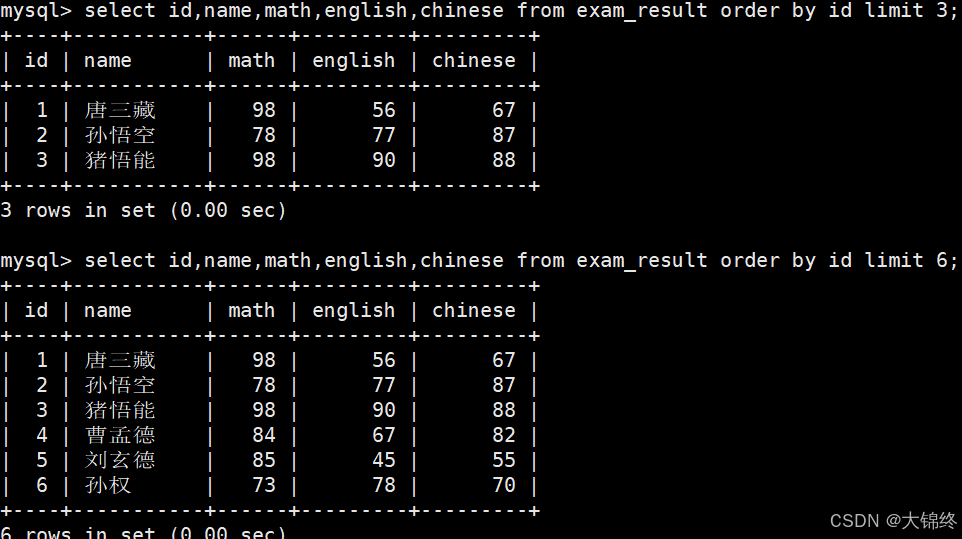
- 按 id 进行分页,每页 3 条记录

limit n offset s比第二种用法更明确,建议使用
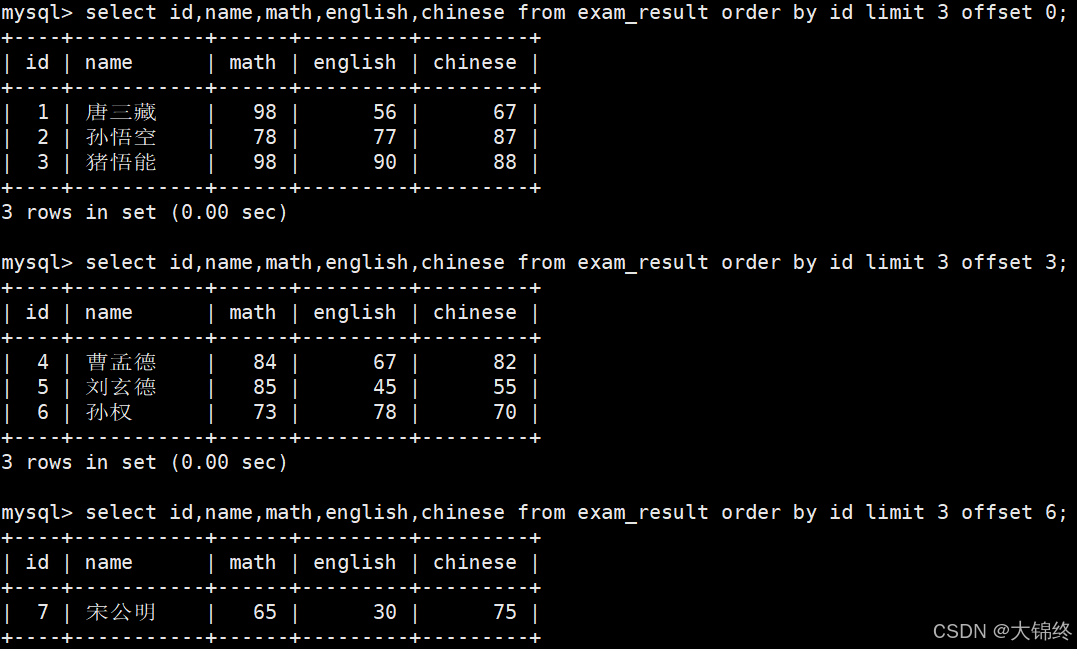
如果页结果不会有影响,limit的本质功能是显示,数据准备好了才需要显示,所以limit是最后一步执行的。
3.update更新
- 语法:
UPDATE table_name SET column = expr , column = expr ...WHERE ...\] \[ORDER BY ...\] \[LIMIT ...
- 将孙悟空同学的数学成绩变更为 80 分:

注意上图中set math后需要加限定条件,否则进行了全表更新,尽量不要这么做,也可以一次进行多次更新数据,在set后面用,隔开
- 将总成绩倒数前三的 3 位同学的语文成绩加上 30 分:
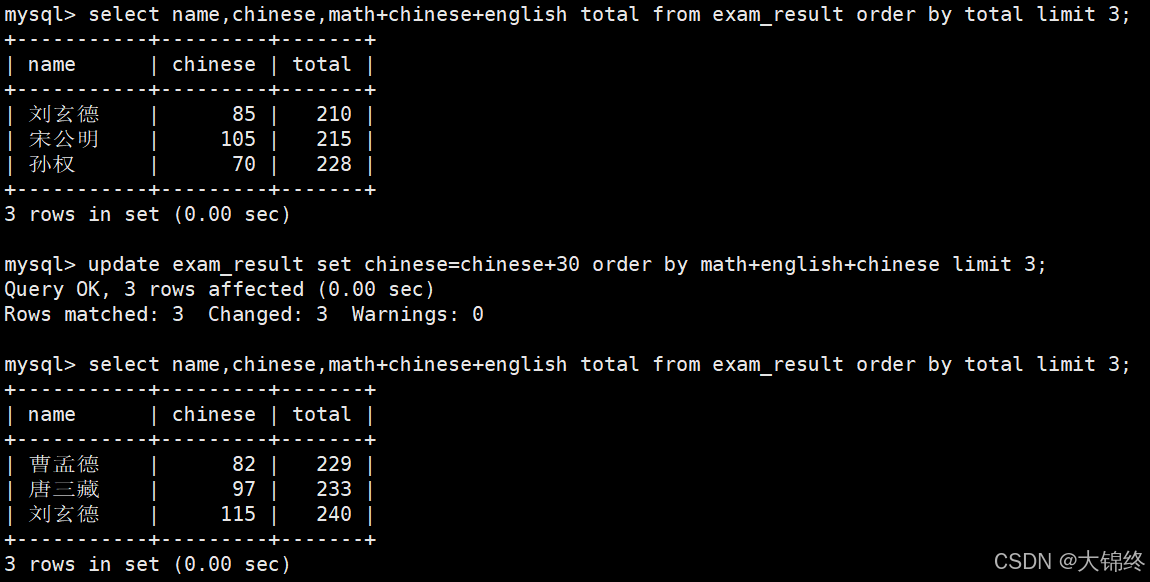
update可与where条件筛选、order by排序语句、limit分页语句等一起使用,更新成绩后总排名发生了变化。
注意:
数据更新,不支持 math += 30 这种语法,只允许math = math + 30
4.delete删除
- 语法:
DELETE FROM table_name WHERE ... ORDER BY ... LIMIT ... - 删除孙悟空同学的考试成绩
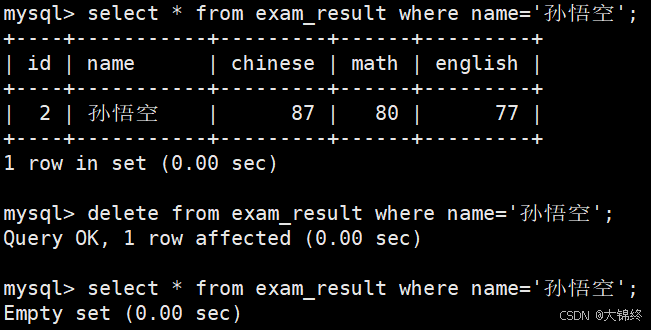
- 删除整张表的信息,测试:
准备测试表:
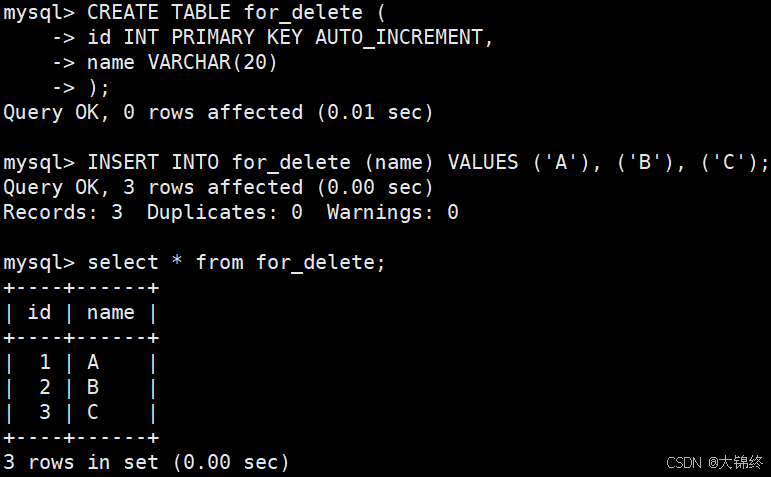
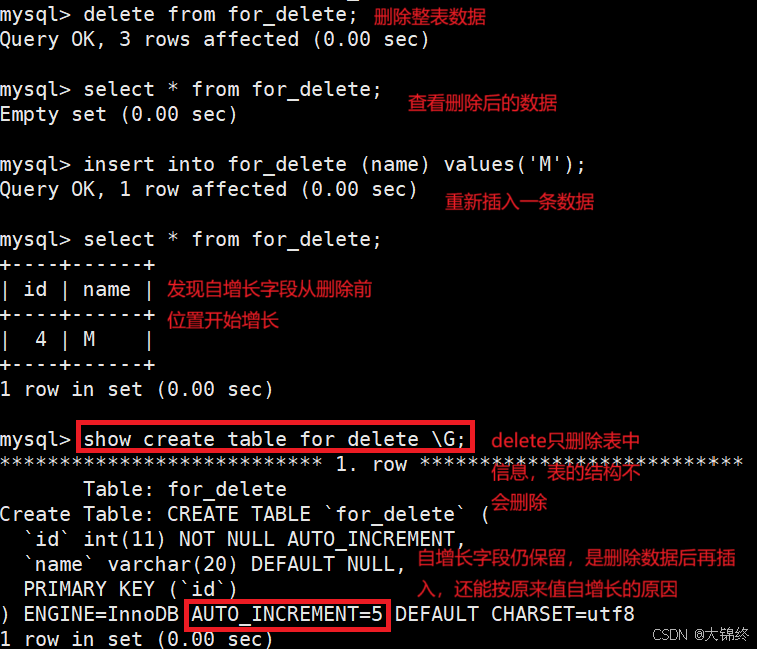
当删除整表时,若设置了自增长字段,通过show可以发现即使表数据都被删除了,但创建的字段信息都存在,并且自增长计数器不变,所以delete是dml语句(数据操纵语言)
截断表
- 语法:
TRUNCATE TABLE table_name
作用:
1.只能对整表操作,不能像 DELETE 一样针对部分数据操作,比如加上where条件筛选等;清空所有数据,重置表结构,结构更改主要是存储层面的 "重置"(自增主键、表空间、统计信息等),表的逻辑结构(列、索引、约束)完全保留;
2.实际上 MySQL 不对数据操作,所以比 DELETE 更快,但是TRUNCATE在删除数据的时候,并不经过真正的事物(后续学习),所以无法回滚
3.会重置 AUTO_INCREMENT 项
4.权限要求更高TRUNCATE 需要 "删除表" 的权限(DROP 权限),而 DELETE 只需要 "删除数据" 的权限(DELETE 权限)------ 因为它本质是对表存储结构的修改,而非单纯的数据删除。
- 测试:
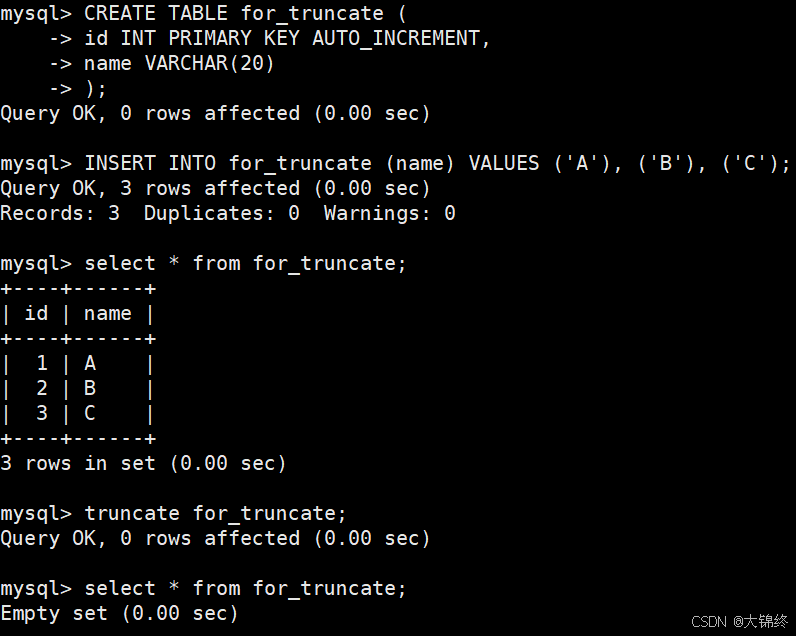
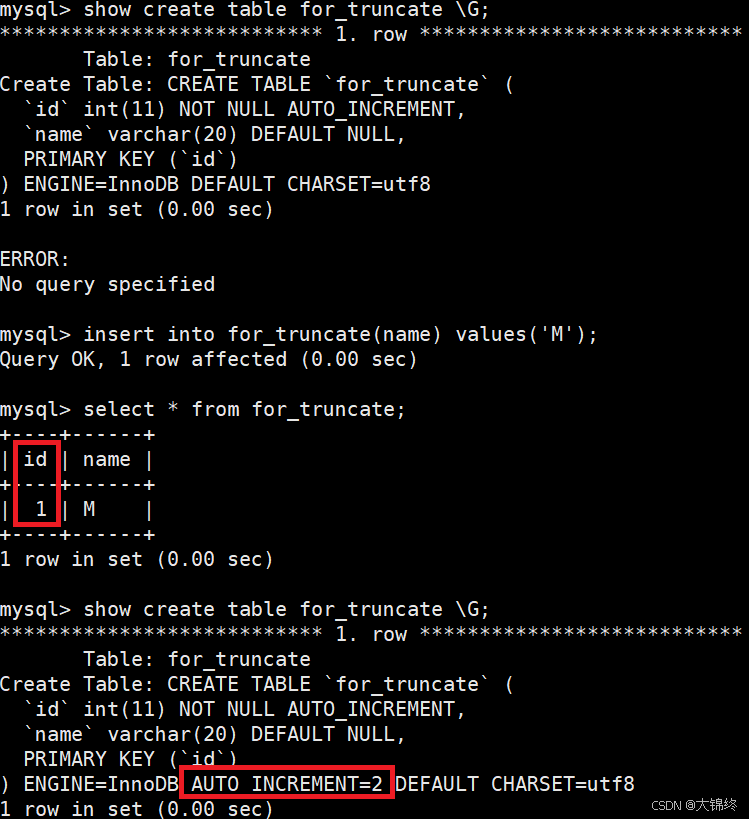
现象解释:
当对表执行 TRUNCATE 后,表数据被清空,同时自增计数器会被重置为初始状态(逻辑上回到未插入数据时的状态)。此时执行 show create table,AUTO_INCREMENT 字段会消失 ------ 因为 MySQL 认为自增计数器尚未被初始化。只有再次插入数据,MySQL 才会重新确定自增的起始值(从 1 开始),并在 show create table 中显示 AUTO_INCREMENT=2(下一次自增的目标值)。
插入查询结果
- 删除表中的的重复复记录,重复的数据只能有一份
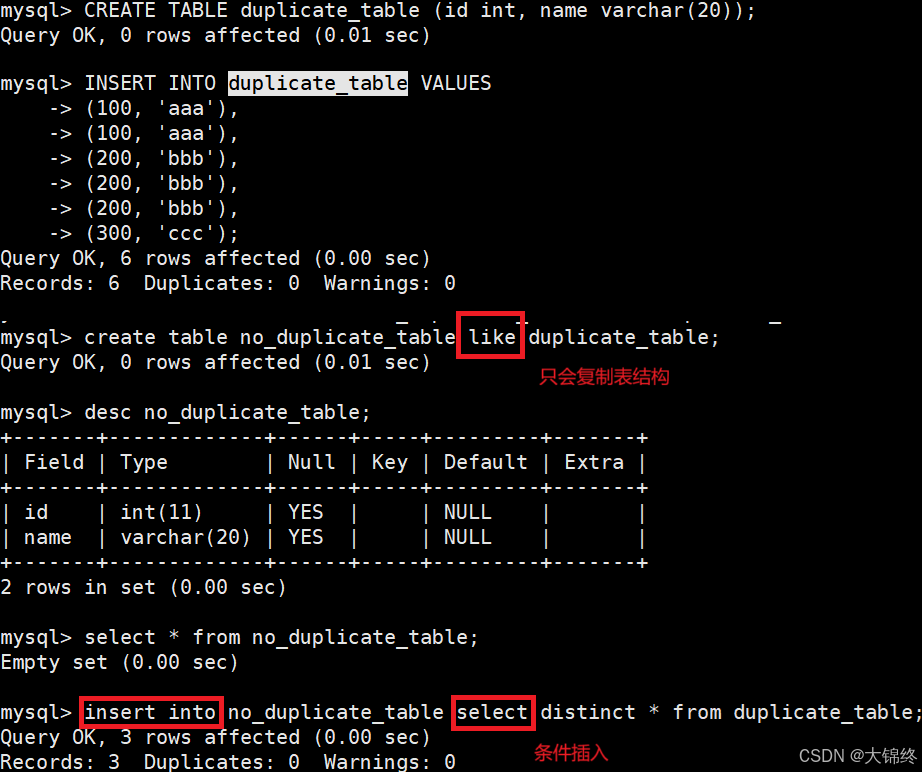
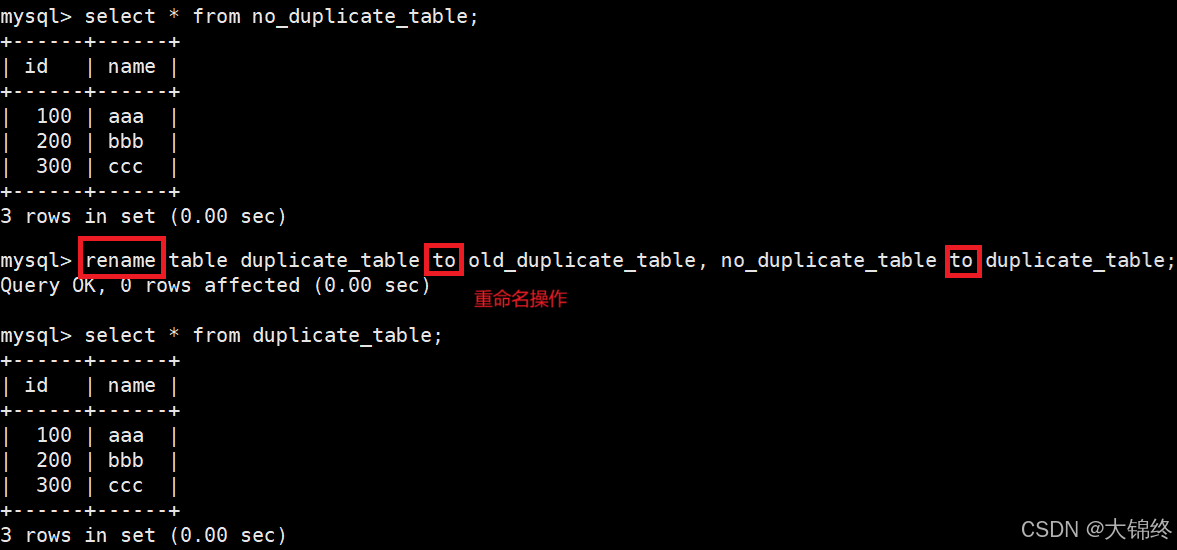
1.当创建表时想要和另一张表的结构一样时可以使用like,就不用重复再设置字段了,like不会复制数据内容
2.采用两张表的方式来实现,先创建一个空表,再将原表中去重数据添加进去,最后进行重命名完成。为什么这样?因为能确保操作和数据的稳定性,避免直接对原数据进行修改,如果出现错误可以直接删除新表,重新对原表进行操作,相当于留有备份
5.分组聚合
聚合函数
COUNT(DISTINCT expr) 返回查询到的数据的 数量
SUM(DISTINCT expr) 返回查询到的数据的 总和,不是数字没有意义
AVG(DISTINCT expr) 返回查询到的数据的 平均值,不是数字没有意义
MAX(DISTINCT expr) 返回查询到的数据的 最大值,不是数字没有意义
MIN(DISTINCT expr) 返回查询到的数据的 最小值,不是数字没有意义
- 具体测试样例:
- count的使用:统计总人数
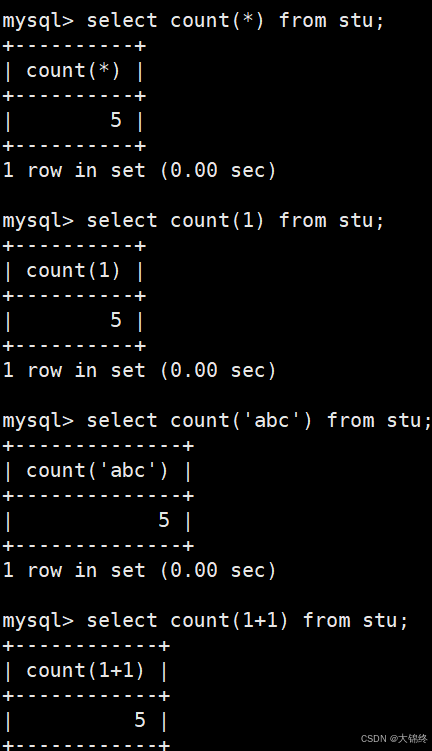
关于count本质:
1.COUNT(表达式) 只统计 "表达式结果非 NULL 的行数";
2.数字是 "永远非 NULL 的常量表达式",每一行都会被计数,最终等价于统计总行数;
3.不止数字,任何结果非 NULL 的常量表达式(如字符串、确定运算)都能实现同样效果。 - 关于其他聚合函数的使用都相同,以语句为例
1.统计平均总分:
SELECT AVG(chinese + math + english) 平均总分 FROM exam_result;
2.返回 > 70 分以上的数学最低分
SELECT MIN(math) FROM exam_result WHERE math > 70;
3.返回英语最高分:
SELECT MAX(english) FROM exam_result;
4.统计数学成绩总分
SELECT SUM(math) FROM exam_result;
group by子句的使用
- 在select中使用group by 子句可以对指定列进行分组查询:
select column1, column2, ... from table group by column; - 测试,准备一个雇员信息表
- 分组就是把一组按照一定条件拆成了多个组,进行各自组内的统计,也就是将一张表拆成子表,所以只要能完成对一张表的操作,就能完成多表的聚合操作
- 如何显示每个部门的平均工资和最高工资

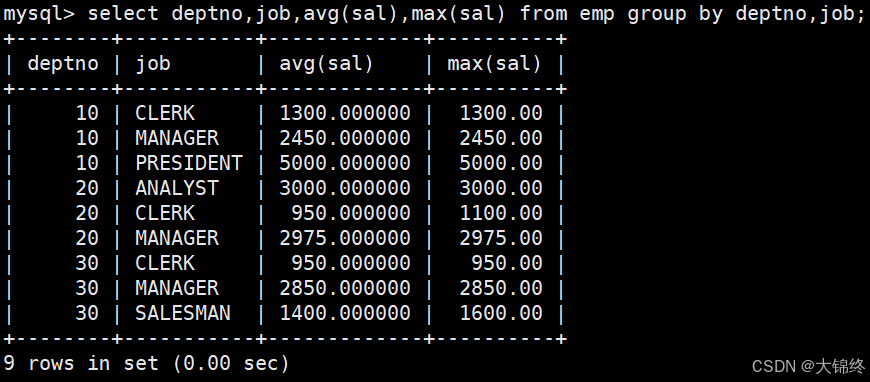
通过group by指定列名,实际是用该列的不同行数据来进行分组的 - 显示每个部门的每种岗位的平均工资和最低工资
- 显示平均工资低于2000的部门和它的平均工资

这里的having是对聚合后的统计数据,做条件筛选,作用类似where - having和where的区别?
主要体现在条件的筛选阶段

- having和where能否相互替代?
不行,二者是 "先后配合" 关系:先 WHERE 筛行,再 GROUP BY 分组聚合,最后 HAVING 筛组,缺一不可,无法替代。
简单记:WHERE 管行,HAVING 管组;聚合之前用 WHERE,聚合之后用HAVING
存在特殊情况:
无 GROUP BY 时,HAVING 会退化为 WHERE(MySQL 特有行为):
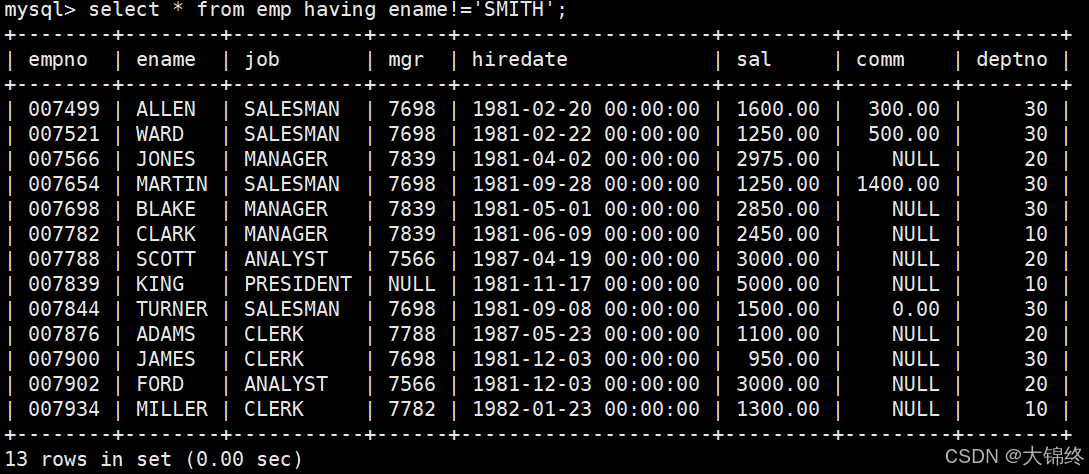
注意:
聚合时要求选择出来的所有字段都能进行聚合,name不能聚合。
只有在order by后面出现的字段才能在select中进行聚合,否则会报错
- 对查询结果的理解:
不仅仅是磁盘上表结构导入到mysql,真实存在的表才叫做表,通过语句中间筛选出来的包括最终结果,全部都是逻辑上的表,mysql一切皆表。
"一切皆表" 的核心体现:数据的 "输入"(物理表、系统表、临时表)和 "输出"(查询结果集),都统一为 "表" 的结构,SQL 语法可以无缝复用。
不是真的所有都是表,而是抽象为表
一切皆表是抽象层面的设计,不是说 MySQL 内部所有组件都是表:
比如日志文件(binlog、redo log)、索引结构(B + 树)、存储引擎的底层数据页,这些不是表;
但对用户 / 开发者来说,所有需要访问数据的操作,都通过 "表" 这个统一接口实现------ 不用关心底层存储,只用掌握 SQL 表操作,就能处理所有数据场景。
所以我们只要能处理好单表的CURD,所有的sql场景,我们全部能用统一的方式进行