根据社区要求,最重要的任务是响应社区号召降低AI写作使用率,所有文章一直都在使用真实材料并进行人工审核,AI使用率一般在50%以下,后续需要保质前提下进一步优化作品,尽量用人工写作保证人工率,支持社区高质量建设更上新台阶。
本文总结以下最近一周常用的基础AI工具实机升级情况:
一、Cherry Stuido 1.6.4部分
从1.5.X版本升级到1.6.4
下载地址
-
GitHub 官方仓库 :https://github.com/CherryHQ/cherry-studio/releases
该版本于2025年10月11日发布,带来了多项新功能和改进。
该版本的功能亮点
1. 多模型支持与助手功能
-
新增 CherryIN 提供者:扩展了模型接入的多样性。
-
300+ 预配置 AI 助手:支持自定义助手创建和多模型同时对话。
2. 文档与数据处理
-
多格式支持:处理文本、图像、办公文件、PDF 等格式(注意目前仍然不支持CAJ格式,论文使用时尽量使用PDF等结构)。
-
WebDAV 文件管理与备份:提供文件管理和备份功能。
3. 实用工具集成
-
全局搜索功能:提升搜索效率。
-
主题管理系统:支持亮/暗主题和透明窗口。
-
拖放排序和小程序支持:增强用户体验。
4. 用户体验优化
-
完整 Markdown 渲染:支持 Markdown 渲染。
-
轻松内容分享:方便内容分享。
知识库导入分析测试,通过,不过目前仍然不支持CAJ模式文件,需要知识库导入的时候注意尽量使用PDF等格式:
简单测试翻译使用deepseek r1 32b本地版通过
升级测试通过
二、Ollama 0.12.5部分
截至2025年10月11日,Ollama 发布了0.12.5版本,进一步增强了其作为本地大型语言模型服务的功能。该版本延续了Ollama的核心优势,提供了类似OpenAI的API接口和聊天界面,可以方便地部署最新版本的大模型并通过接口使用。
主要特点和优势
-
热加载模型文件:支持无需重新启动即可切换不同的模型,实现热切换,提升了使用的灵活性和效率。
-
支持多种预训练模型:Ollama提供了多种预训练模型,这些模型已经在大量文本数据上进行了训练,用户可以直接使用这些模型进行各种自然语言处理任务,无需从头开始训练。
-
可扩展性:用户可以根据自己的需求对Ollama进行扩展,添加新的模型或者修改现有模型,满足不同场景的需求。
使用账户登录,使用云上模型,登录界面:
登录后效果:
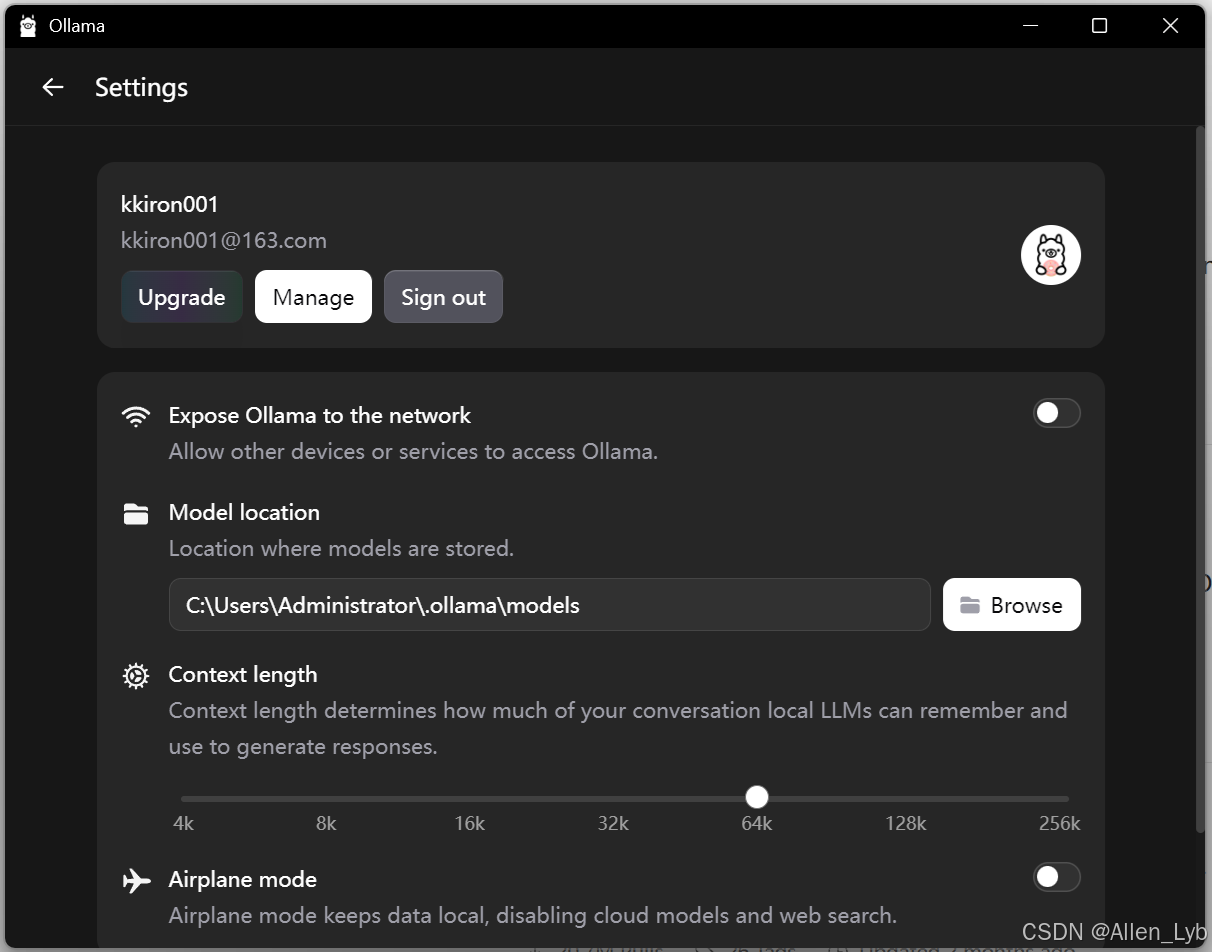
增加长上下文,支持到256k
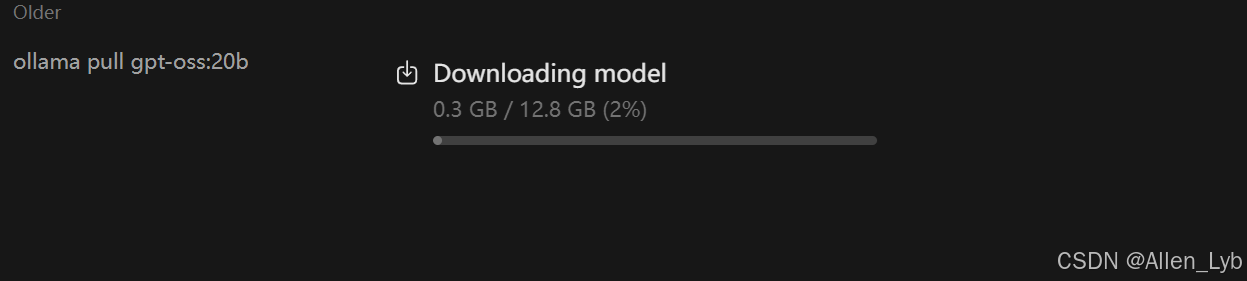
模型在程序内即可升级,不过下到70%~80%的时候变慢的老毛病仍然有,需要停掉服务重新进一下再下载。
新版功能测试:
使用r**ollama ** R包与Ollama 集成,可以在 R 环境中轻松调用Ollama模型进行数据标注和文档嵌入。这个过程通常涉及使用大型语言模型(如LLaMA、Mistral等)来对文本数据进行处理。以下分析是如何利用 rollama 包进行数据标注和嵌入的基本步骤。
1. 安装rollama R包
首先,需要在 R 环境中安装并加载rollama包。这个包提供了与Ollama API的接口,允许直接与本地的模型进行交互。
# 安装 rollama 包
install.packages("remotes")
remotes::install_github("ollama/rollama")
# 加载 rollama 包
library(rollama)2. 配置 Ollama 服务器
启动 Ollama 服务器:
ollama serve3. 使用 rollama 进行数据标注
rollama 包的一个主要用途是进行文本数据的标注。您可以通过提供模型名称和提示来生成文本内容。例如,使用一个训练好的语言模型来标注文本数据。
# 设置模型和提示
model_name <- "llama2" # 您可以根据需要更换为其他模型
prompt <- "给定这段文本,请进行总结:'Ollama 是一个本地运行的生成型语言模型,适用于文本生成、翻译和问答任务。'"
# 使用 rollama 进行文本标注
response <- rollama(prompt = prompt, model = model_name)
# 查看生成的结果
cat(response$generated_text)4. 文档嵌入
除了数据标注外,rollama 还可以进行文档嵌入(embedding)。通过将文本数据转化为向量表示,在机器学习和信息检索等应用中使用这些嵌入。
# 使用 rollama 进行文本嵌入
embedding_response <- rollama(prompt = "将以下文本转换为嵌入向量:'Ollama 是一个本地运行的生成型语言模型。'",
model = "llama2",
task = "embedding")
# 获取嵌入向量
embedding_vector <- embedding_response$embedding5. 调整参数和优化
您可以调整模型的参数,例如温度(temperature)、最大长度(max_tokens)等,以控制模型的生成行为。
# 调整生成参数
response <- rollama(prompt = prompt,
model = model_name,
temperature = 0.7,
max_tokens = 100)
# 输出结果
cat(response$generated_text)6. 处理批量数据
对于需要处理大量数据的情况,编写循环来批量处理文本数据。通过为每个输入文本生成标注或嵌入,高效地完成任务。
# 批量处理文本数据
texts <- c("文本1", "文本2", "文本3")
results <- lapply(texts, function(text) {
rollama(prompt = paste("为以下文本生成总结:", text), model = "llama2")
})
# 查看结果
results7. 错误处理和调试
在使用 rollama 时,如果遇到 API 请求错误或模型响应不符合预期,通过调试信息查看详细错误日志。
# 获取详细的错误信息
tryCatch({
response <- rollama(prompt = prompt, model = model_name)
}, error = function(e) {
message("出现错误:", e$message)
})通过这些步骤,使用rollama R包与 Ollama 进行数据标注和文档嵌入。
三、Dify 1.9.1版本
1、 1.9.1版本升级
-
2025 年 9 月 29 日,Dify 发布 1.9.1 版本。
-
相比 1.9.0,1.9.1 更偏重于 性能优化、修复、基础设施升级、开发者体验增强,而非像 1.9.0 那样的大架构变更。
-
版本号为 "v1.9.1 -- 1,000 Contributors, Infinite Gratitude" 的发布说明中就列出了几条关键变动:Next.js 升级、marketplace API 响应头、Security 报告流程等。
2、Dify 1.9.1 的主要更新内容
下面按模块维度来梳理。
| 模块 / 维度 | 主要改动 / 新增 | 说明 / 用途 |
|---|---|---|
| 基础设施 / 前端构建 | Next.js 升级到 15.5 ,在开发模式下启用 Turbopack | 加快开发构建流程、提升前端热重载等体验 |
| API / 可追溯性 | marketplace 接口响应中新增 X-Dify-Version 响应头 |
有利于版本追踪、调试与运维监控 |
| 安全 / 报告 | 引入了新的 安全报告流程 / 安全报告工作流 | 改善安全问题反馈机制与生命周期管理 |
| 流水线 & 引擎 | 多语言配置支持的流水线模板 | 使 pipeline 模板能支持多语言部署配置(例如不同语言环境) |
| 响应节点控制 | 在图执行引擎的流式传输过程中,会阻止(stop)某些响应节点,避免异常输出 | 用以提高图执行的可控性与稳定性 |
| 国际化 / UI 优化 | 更流畅的 UI 体验、加强国际化支持 | 在 GitHub issue "Align 1.9.1 release metadata" 中提及本次 release 包含 smoother UI 与 broader internationalization。 |
| Bug 修复 & 兼容性 | 各类性能、兼容性与代码结构优化修复 | 虽然官方没给出完整 list,但发布说明、社区 issue 提到了不少改动(见下面"已知问题 / 迁移注意") |
3、Dify 核心功能 / 方法详解(来自 1.9.0 与 1.9.1 的延续 + 优化)
看文档情况目前1.9.1并没有像1.9.0引入完全颠覆的新架构,很多核心方法来自1.9.0的知识管道(Knowledge Pipeline) 和 **基于队列的图执行引擎(Queue-based Graph Engine)**在1.9.1中主要还是在这些基础上做增强和修复。下面先回顾1.9.0的这些核心方法/机制,再指出在1.9.1中的优化 / 行为边界。
3.1 回顾:DIFY1.9.0的核心架构方法
为了理解1.9.1的改进,先简要回顾1.9.0引入的两个重要机制:
-
Knowledge Pipeline(知识管道)
-
将文档摄入、格式解析、索引构建、检索策略、后处理等环节模块化,形成可视化节点编排流程。
-
支持多模态检索(例如图片中的文字提取、图表识别)以弥补以往仅文本检索的局限性。
-
Q&A 结构分块:自动识别文档中的问答结构,将其作为语义单元进行索引 / 检索,提升准确性。
-
可插拔 / 扩展节点设计,方便自定义处理节点或接入第三方系统。
-
-
Queue-based Graph Engine(基于队列的图执行引擎)
-
用队列调度机制替代传统刚性图遍历,使工作流的并行分支、异步任务管理更灵活。
-
在执行图节点时支持命令控制、节点中断 / 跳过、失败重试等策略,提高稳定性与容错。
-
支持动态调度,避免静态顺序执行带来的瓶颈。
-
通过这两个机制,Dify 在1.9.0就大幅提升了在复杂 RAG(文档 + 模型问答)场景下的适用性、可扩展性与稳定性。
4 DIFY1.9.1对这些核心方法 / 架构的增强与行为细化
基于社区整理与 issue,可以归纳出在1.9.1中,对于上述架构的增强 / 注意点包括:
-
响应节点控制机制增强
-
在流式传输中对某些响应节点进行阻止(stop),避免出现异常或不期望的输出节点被触发。
-
这意味着在图执行过程中,某些节点的输出可以被安全截断或跳过,从而保证流程的干净与可控。
-
-
模板 / 多语言支持
-
流水线模板现在支持语言配置,这有利于在多语言环境 / 国际化部署环境中复用模板逻辑。
-
这可能影响 pipeline 中的节点名称、本地化文本等处理方式。
-
-
对工具 / 自定义插件 / API 兼容的注意点
-
在从1.8.x升级到1.9.1时,有社区报告自定义工具(custom tool)在界面上"消失"问题,可能因为数据库迁移中对
tool_api_providers表添加了唯一约束导致记录丢失/被过滤。 -
在升级过程中,可能会遇数据库迁移失败、缺少列或表、迁移报错等。社区 issue 建议:逐步删除出错的字段或表,然后 retry migration 命令。
-
升级后在部分环境下可能触发 "Internal Server Error",通常与环境变量(如 Some Boolean env 变量为空字符串无法 parse)有关,需要在
docker-compose.yaml中为这些环境变量设置默认值以避免解析失败(例如S3_USE_AWS_MANAGED_IAM)
-
-
UI 与 国际化改进
-
更平滑的界面交互、按钮 / 样式微调、国际化文本支持增强等。虽不是架构级变化,但能提升使用体验。
-
更好的版本追踪与调试支持(例如新增
X-Dify-Version响应头)辅助 UI / 运维层面。
-
-
回滚 / 兼容性注意
-
由于数据库迁移可能是不可回滚操作,升级前务必 完整备份数据库与 volumes
-
若升级失败,可考虑退回到 1.8.x 或之前版本,或干预迁移脚本 / 手动修复缺失表 / 列。社区 issue 中就有用户因迁移失败而需要反复调整的记录。
-
4、迁移 / 升级建议 & 常见问题
下面是一些社区实践中累积的经验 / 教训,供你在实际升级至1.9.1时参考。
-
提前备份
-
备份
volumes目录(包含数据库、存储) -
备份
.env与docker-compose.yml等配置文件 -
在生产环境中,最好先在测试环境跑一次升级演练
-
-
执行升级 / 迁移步骤(典型流程)
-
停止当前服务(
docker compose down) -
更新代码 / 镜像拉取
-
执行数据库迁移:
docker exec api flask db upgrade或类似命令 -
若有迁移脚本支持的数据转换(如之前版本到插件化的迁移脚本),依指南执行
-
启动新版本服务:
docker compose up -d -
检查日志、服务状态、接口可用性
-
-
针对特定错误的处理建议
-
Internal Server Error / Boolean 解析出错
如果环境变量是空字符串,在代码中可能
strconv.ParseBool("")失败引发错误。解决方法是给这些环境变量设置默认值(如:-false)以避免空串解析报错。 -
自定义工具丢失
若升级后自定义工具在界面上消失,可检查数据库中的
tool_api_providers表是否因为新增唯一约束或数据不满足约束而被过滤或删除。必要时可恢复之前的表数据或调整迁移脚本。 -
迁移失败报错(缺列 / 表)
社区建议对迁移报错信息中提示缺失的列 / 表,逐一手动干预(如删掉已存在冲突列 / 表或修补脚本)然后 retry migration。
-
-
逐步验证
-
升级后先在测试 / dev 环境验证核心工作流、RAG 管道、Agent 节点等是否如预期
-
使用新的
X-Dify-Version响应头验证服务确实升级成功 -
注意自定义插件 / 工具 / 节点在升级后是否还正常工作
-
-
注意版本界限 / 接口变动
虽然1.9.1在核心架构上延续1.9.0,但某些内部 API、数据库 schema 或工具表约束可能做了调整,二次开发插件或扩展,注意与官方文档 / migration 脚本对齐
升级完成情况: